利用 Waymo自动驾驶数据集进行目标检测、跟踪及轨迹识别预测 自动驾驶数据集 利用LSTM或Transformer架构进行轨迹预测
利用 Waymo自动驾驶数据集进行目标检测、跟踪及轨迹识别预测 自动驾驶数据集 利用LSTM或Transformer架构进行轨迹预测
文章目录
以下文字及代码仅供参考学习。
数据集描述
waymo自动驾驶数据集
perception 1.4 数据集
的自动驾驶数据集
包含传感器数据、边界框数据、2D视频全景分割标签、关键点标签、3D语义分割标签、2D和3D边界框的关联
用于目标检测跟踪和轨迹识别预测
Waymo Open Dataset(尤其是你提到的 Perception 1.4 版本)确实是自动驾驶领域中非常全面且高质量的数据集之一,包含了丰富的传感器数据、标注信息等。这些数据对于研究和开发自动驾驶系统中的多个方面如目标检测、跟踪、轨迹预测等都具有极高的价值。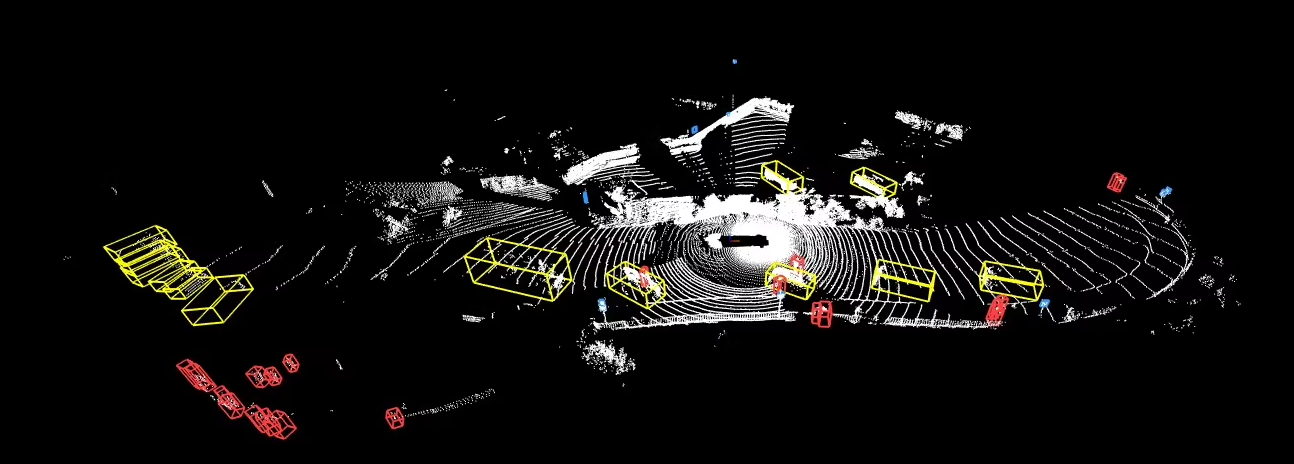
如何利用 Waymo 数据集进行目标检测、跟踪及轨迹识别预测。
一、准备工作
1. 安装依赖
首先确保安装了必要的库,包括 TensorFlow 和 Waymo 开放数据集的读取工具:
pip install waymo-open-dataset-tf-2-11-0 tensorflow matplotlib opencv-python
2. 下载数据集
访问 Waymo Open Dataset 网站下载数据集。根据需要选择适合的版本(Perception 1.4)。注意,由于数据集体积庞大,可能需要使用 Google Cloud Storage 或者 AWS S3 进行高效下载。
二、加载与解析数据
Waymo 数据集采用了特殊的 .tfrecord 格式存储,因此需要特定的方法来读取。
import tensorflow as tf
from waymo_open_dataset import dataset_pb2 as open_dataset
def parse_frame(proto):
frame = open_dataset.Frame()
frame.ParseFromString(bytearray(proto.numpy()))
return frame
def load_tfrecord_dataset(file_path):
dataset = tf.data.TFRecordDataset(file_path, compression_type='')
dataset = dataset.map(lambda x: parse_frame(x))
return dataset
# 示例:加载第一个训练集文件
train_dataset = load_tfrecord_dataset('path_to_your_downloaded_data/training/segment-1234567890123456789_1234_5678_9012_345678901234.tfrecord')
三、数据探索
Waymo 数据集中每个帧(frame)包含多种传感器信息(如相机图像、激光雷达点云)以及对应的标注(如2D/3D边界框、语义分割标签等)。可以通过以下代码查看某帧的信息:
for data in train_dataset.take(1):
print(data.context.name) # 场景名称
for camera_image in data.images:
print(camera_image.name) # 相机名称
# 显示前向摄像头图像
if camera_image.name == 1: # FRONT相机ID为1
import matplotlib.pyplot as plt
plt.imshow(tf.image.decode_jpeg(camera_image.image))
plt.show()
# 查看激光雷达点云数据
range_images, camera_projections, seg_labels, ri_index = (
frame_utils.parse_range_image_and_camera_projection(data))
四、目标检测与跟踪
对于目标检测任务,可以基于 Waymo 提供的标注信息直接训练模型,或者使用预训练模型进行微调。例如,使用 TensorFlow Object Detection API 或者 PyTorch 中的相关库。
训练目标检测模型
选择模型架构,比如 Faster R-CNN 或者 SSD,接下来可以使用 Waymo 数据集中的标注信息来训练模型。
跟踪算法应用
在完成目标检测后,可以应用多目标跟踪算法,如 SORT 或 DeepSORT 来对检测到的目标进行连续帧间的关联,从而实现对车辆、行人等动态物体的持续跟踪。
五、轨迹预测
轨迹预测是自动驾驶中的一个重要环节,它涉及对未来几秒内其他道路使用者运动路径的估计。基于历史位置、速度、加速度等特征,可以构建机器学习模型来进行预测。
示例:简单的线性外推法
虽然简单但有效的一种方法是基于当前的速度和方向做线性外推:
def predict_linear(track_history, future_steps=5):
last_position = track_history[-1]
velocity = (last_position - track_history[-2]) / 0.1 # 假设每帧间隔为0.1秒
predictions = [last_position + i * velocity * 0.1 for i in range(1, future_steps+1)]
return predictions
更复杂的模型可能涉及到 LSTM 或 Transformer 等深度学习架构,以捕捉长时间序列依赖关系,并结合环境上下文信息做出更准确的预测。
为了利用LSTM或Transformer架构进行轨迹预测,我们将以一个简化的例子来说明如何构建模型。这里,我们假设已经有了从Waymo数据集中提取的车辆轨迹历史数据,并且这些数据已经被适当地预处理(例如归一化、填充缺失值等)。我们将分别展示如何使用LSTM和Transformer来进行轨迹预测。
一、环境配置
首先确保安装了必要的库:
pip install numpy pandas tensorflow matplotlib
二、准备数据
在实际应用中,将Waymo数据集中的轨迹数据转换为适合模型训练的格式。这里我们简化这个过程,直接生成一些模拟数据作为示例。
import numpy as np
import pandas as pd
# 模拟一些轨迹数据,每个样本包含过去10个时间步长的位置信息(x, y)
np.random.seed(42)
num_samples = 1000
sequence_length = 10
data = np.random.rand(num_samples, sequence_length, 2) # (样本数, 时间步长, 特征数)
# 划分训练集和测试集
train_size = int(len(data) * 0.8)
train_data, test_data = data[:train_size], data[train_size:]
def create_dataset(data, look_back=10):
X, y = [], []
for i in range(len(data)-look_back-1):
X.append(data[i:(i+look_back)])
y.append(data[i + look_back])
return np.array(X), np.array(y)
X_train, y_train = create_dataset(train_data)
X_test, y_test = create_dataset(test_data)
三、使用LSTM进行轨迹预测
构建并训练LSTM模型
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
model_lstm = Sequential()
model_lstm.add(LSTM(units=50, return_sequences=True, input_shape=(X_train.shape[1], X_train.shape[2])))
model_lstm.add(Dropout(0.2))
model_lstm.add(LSTM(units=50, return_sequences=False))
model_lstm.add(Dropout(0.2))
model_lstm.add(Dense(units=2)) # 预测下一个位置的x, y坐标
model_lstm.compile(optimizer='adam', loss='mean_squared_error')
history_lstm = model_lstm.fit(X_train, y_train, epochs=20, batch_size=32, validation_split=0.1)
使用模型进行预测
predictions_lstm = model_lstm.predict(X_test)
# 可视化部分结果
import matplotlib.pyplot as plt
plt.figure(figsize=(10,6))
plt.plot(y_test[:100,0], y_test[:100,1], label="True")
plt.plot(predictions_lstm[:100,0], predictions_lstm[:100,1], label="Predicted")
plt.title("LSTM Predictions vs True Values")
plt.legend()
plt.show()
四、使用Transformer进行轨迹预测
Transformer架构相对复杂一些,但非常适合处理序列数据中的长期依赖关系。
定义Transformer模型
def transformer_model(input_shape):
inputs = tf.keras.Input(shape=input_shape)
x = tf.keras.layers.Dense(50, activation='relu')(inputs)
transformer_block = tf.keras.layers.Transformer(
num_heads=2, key_dim=50, units=50, dropout=0.1)(x)
x = tf.keras.layers.GlobalAveragePooling1D()(transformer_block)
outputs = tf.keras.layers.Dense(2)(x) # 输出预测的位置
model = tf.keras.Model(inputs=inputs, outputs=outputs)
return model
model_transformer = transformer_model((X_train.shape[1], X_train.shape[2]))
model_transformer.compile(optimizer='adam', loss='mean_squared_error')
history_transformer = model_transformer.fit(X_train, y_train, epochs=20, batch_size=32, validation_split=0.1)
注意:上述代码仅提供了一个基础框架,实际的Transformer实现可能更复杂,包括多层编码器和解码器结构。
使用模型进行预测
predictions_transformer = model_transformer.predict(X_test)
# 可视化部分结果
plt.figure(figsize=(10,6))
plt.plot(y_test[:100,0], y_test[:100,1], label="True")
plt.plot(predictions_transformer[:100,0], predictions_transformer[:100,1], label="Predicted")
plt.title("Transformer Predictions vs True Values")
plt.legend()
plt.show()
使用LSTM和Transformer进行轨迹预测的基本框架。需要根据具体需求调整模型参数、优化超参数以及采用更复杂的特征工程方法来提高预测精度。此外,对于真实世界的应用,还需考虑如何有效地整合来自不同传感器的数据,以及如何处理数据中的噪声和不完整性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)