从 3GB 到 900MB:MCAP + ZSTD 实战,以及一条把 GPU 喂饱的自动驾驶数据飞轮
在机器人与自动驾驶领域,数据采集是一切的起点,也是最容易失控的成本黑洞。一次录制会话动辄 3GB、一辆测试车一天产出 TB 级数据——存储在涨、传输在堵、ETL 在堵。本文从一个最实在的问题切入:如何用一段 Python 脚本把 3GB 的 MCAP 文件无损压到 900MB;再往上一层,讲清楚为什么车端要用 MCAP 而不是传统 ROS Bag;最后往下游延伸,说明为什么不能把 MCAP 直接甩给训练团队,以及业界标准的数据飞轮长什么样。
一、先认识主角:MCAP 是什么,为什么文件大小是个大问题
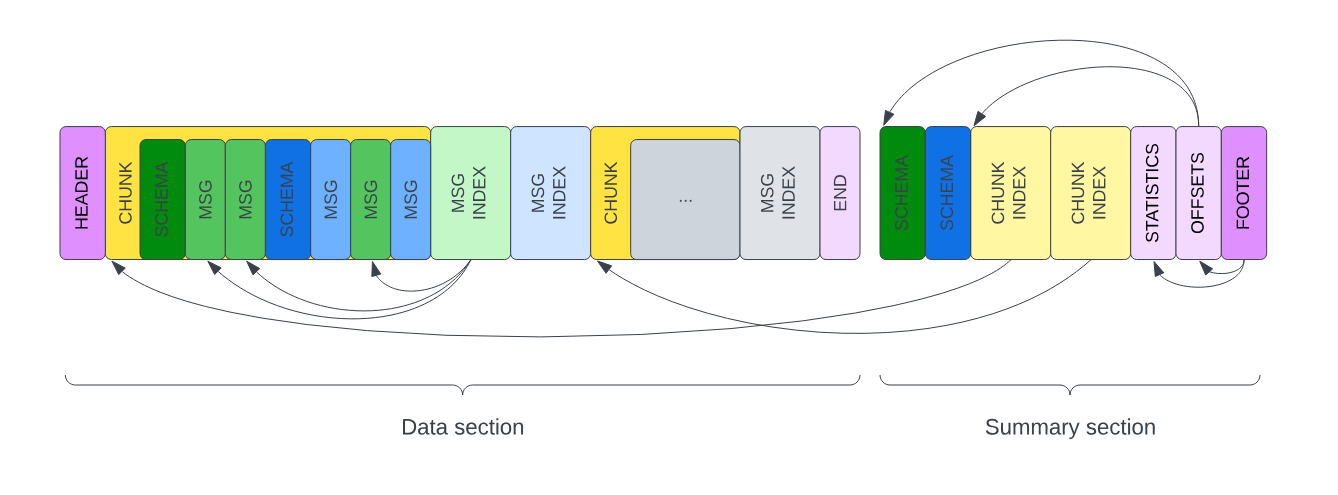
MCAP(Modular Container for Arbitrary Protocols)是一种为"带时间戳的异构数据"设计的容器格式。它把消息按块(Chunk) 组织,支持多种编码,并且是自包含的——消息的 Schema 直接内嵌在文件里,读取时无需外部依赖。
值得澄清一个常见说法:MCAP 从 ROS 2 Iron Irwini(2023 年 5 月)起,已正式成为 rosbag2 的默认存储插件,在 Jazzy 中仍是默认值;不过传统的 SQLite3(.db3)格式依旧受官方完整支持,并没有被弃用。所以更准确的描述是:MCAP 是 ROS 2 当前推荐且默认的存储格式,而非唯一选择。
问题出在数据本身。来自高保真传感器的原始负载——LiDAR 点云、800 万像素相机图像、高频 Radar 报文——会让文件迅速膨胀。一个长会话产出 3GB 的 MCAP 毫不稀奇,由此带来三重代价:
- 存储成本高:云厂商按 GB 计费,车载/边缘设备存储很快被填满。
- 传输缓慢:上传、共享、回灌数据都变得繁琐。
- 运维开销大:数据越多,处理与归档耗时越长。
压缩,是把这条链路重新理顺的第一步。而在这件事上,ZSTD 表现尤为出色。
二、ZSTD:为什么它特别适合 MCAP
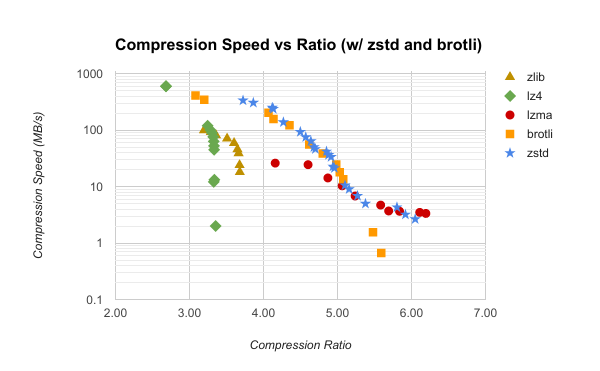
ZSTD(Zstandard)由 Meta 开发,是一种无损压缩算法,压缩比优于 LZ4、速度又远快于 gzip,非常适合实时场景。它特别擅长处理传感器日志里大量重复、冗余的二进制模式——例如结构高度相似的点云、连续相近的视频帧。
在 MCAP 中,压缩发生在块级别:算法只针对每个 Chunk 内的冗余负载做压缩,不改动底层消息、时间戳或元数据。这带来三个关键收益:
| 维度 | ZSTD 在机器人数据上的表现 |
|---|---|
| 压缩比 | 对传感器数据常能达到 3:1 甚至更高 |
| 速度 | 压缩/解压快,CPU 开销可控 |
| 完整性 | 完全无损——视频帧、点云每一位都被保留 |
在实测中,一份包含视频与点云的 3GB 未压缩 MCAP,压到了约 900MB——减小约 70%。下面给出可复现的脚本。
三、动手:用 Python 压缩并(可选)分割 MCAP
我们使用 mcap Python 库来读取、压缩、并按时间切分文件。只要 Schema 是自包含的,这一步无需安装完整的 ROS 2 环境。
3.1 准备
pip install mcap==1.1.1 mcap-ros2-support==0.5.1准备好你的 MCAP 文件(例如 rosbag_156_20250831_232404_1.mcap)。下面是完整脚本,支持在指定时间点切分并对每段做 ZSTD 压缩。如果只想压缩、不想分割,把 split_time 设成大于文件总时长的值即可。
3.2 完整脚本
from mcap.reader import make_reader
from mcap.writer import Writer, CompressionType
from mcap.records import Schema, Channel
def split_mcap(input_file, output_prefix, split_time):
with open(input_file, "rb") as input_f:
reader = make_reader(input_f)
summary = reader.get_summary()
if summary:
schemas = list(summary.schemas.values())
channels = list(summary.channels.values())
else:
# 没有 summary 时,遍历一遍把 schema / channel 收集出来
schemas_dict = {}
channels_dict = {}
for schema, channel, message in reader.iter_messages(log_time_order=False):
if schema and schema.id not in schemas_dict:
schemas_dict[schema.id] = schema
if channel.id not in channels_dict:
channels_dict[channel.id] = channel
schemas = list(schemas_dict.values())
channels = list(channels_dict.values())
input_f.seek(0)
reader = make_reader(input_f)
schema_map = {}
channel_map = {}
# 第一段 writer,开启 ZSTD 压缩
writer1_f = open(output_prefix + '_part1.mcap', "wb")
writer1 = Writer(writer1_f, compression=CompressionType.ZSTD)
writer1.start(profile="ros2", library="python-mcap")
for schema in schemas:
new_schema_id = writer1.register_schema(
name=schema.name,
encoding=schema.encoding,
data=schema.data,
)
schema_map[schema.id] = new_schema_id
for channel in channels:
new_schema_id = schema_map.get(channel.schema_id, 0)
new_channel_id = writer1.register_channel(
schema_id=new_schema_id,
topic=channel.topic,
message_encoding=channel.message_encoding,
metadata=channel.metadata,
)
channel_map[channel.id] = new_channel_id
start_time = None
part = 1
message_count = 0
for schema, channel, message in reader.iter_messages():
message_count += 1
if start_time is None:
start_time = message.log_time / 1_000_000_000
relative_time = (message.log_time / 1_000_000_000) - start_time
# 到达切分点:收尾第一段,开启第二段
if relative_time > split_time and part == 1:
writer1.finish()
writer1_f.close()
writer2_f = open(output_prefix + '_part2.mcap', "wb")
writer2 = Writer(writer2_f, compression=CompressionType.ZSTD)
writer2.start(profile="ros2", library="python-mcap")
schema_map = {}
for schema in schemas:
new_schema_id = writer2.register_schema(
name=schema.name,
encoding=schema.encoding,
data=schema.data,
)
schema_map[schema.id] = new_schema_id
channel_map = {}
for channel in channels:
new_schema_id = schema_map.get(channel.schema_id, 0)
new_channel_id = writer2.register_channel(
schema_id=new_schema_id,
topic=channel.topic,
message_encoding=channel.message_encoding,
metadata=channel.metadata,
)
channel_map[channel.id] = new_channel_id
part = 2
new_channel_id = channel_map[channel.id]
if part == 1:
writer1.add_message(
channel_id=new_channel_id,
log_time=message.log_time,
data=message.data,
publish_time=message.publish_time,
sequence=message.sequence,
)
else:
writer2.add_message(
channel_id=new_channel_id,
log_time=message.log_time,
data=message.data,
publish_time=message.publish_time,
sequence=message.sequence,
)
if part == 1:
writer1.finish()
writer1_f.close()
else:
writer2.finish()
writer2_f.close()
print(f"Total messages processed: {message_count}")
# 示例:在第 60 秒处切分,并对两段分别做 ZSTD 压缩
split_mcap('rosbag_156_20250831_232404_1.mcap', 'output', 60)python split_mcap.py只想压缩、不想分割? 把
split_time设成大于文件总时长的值,脚本就只输出一个压缩后的output_part1.mcap。
3.3 如果你更想用 ROS 2 自带工具
对新录制,直接在录制时开启文件级 ZSTD 压缩:
ros2 bag record -a --storage mcap --compression-mode file --compression-format zstd对已有文件,用 ros2 bag convert 搭配一份指定 ZSTD 的 YAML 配置进行转换即可。
3.4 结果与校验
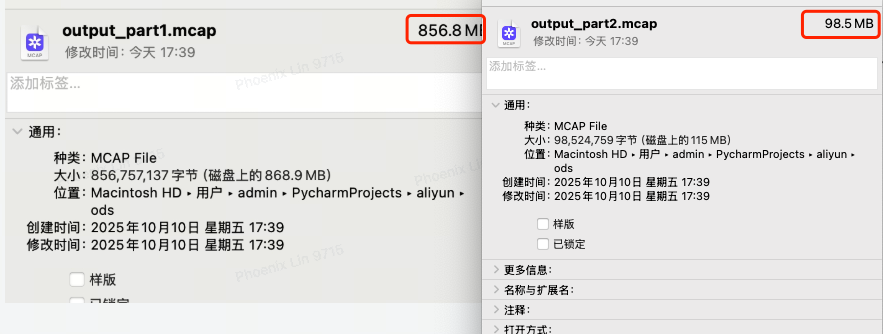
| 项目 | 数值 |
|---|---|
| 原始大小 | 3GB(未压缩或轻压缩) |
| 压缩后 | 总计约 900MB(如 800MB + 100MB 两段) |
| 压缩比 | 约 3:1 |
| 耗时 | 标准机器上几分钟 |
压缩完成后,务必校验完整性,确认视频帧、点云数据无任何损失:
mcap validate output_part1.mcap这一切之所以成立,是因为 ZSTD 精准命中了消息负载中的冗余二进制模式,在块级别做了高效压缩——用更少的字节,表达同样的信息。
3.5 这笔账省在哪
- 存储:少 70% 空间,意味着 S3 / Azure 账单直接下一个台阶,大规模车队一年可省下可观费用。
- 工作流:文件更小,上传/下载更快,分析与协作随之提速。
- 边缘设备:机器人、无人机的板载存储压力骤减。
- 可扩展性:无需升级硬件,就能扛住更多数据。
对每天吞吐 TB 级数据的团队,这是基础设施级别的改善。
四、往上看一层:车端为什么是 MCAP,而不是传统 ROS Bag
如果你从 Parquet(云端训练格式)一路问到 ROS Bag(车端录制格式),再敏锐地察觉到 MCAP,其实正在重走过去几年头部自动驾驶公司的数据架构演进之路。
一句话概括:ROS Bag(尤其是 ROS 2 的 SQLite3 格式)是上一代通用标准,而 MCAP 是为海量传感器数据痛点专门设计的现代工业级格式。 下面从五个核心维度对比。
1. 相机 / LiDAR / Radar 等高频大体积数据
- ROS Bag (SQLite3):关系型数据库的本意是存结构化短文本。把每秒 30 帧的 800 万像素图像、几兆的 128 线点云、高频 Radar 报文这些巨大的二进制块(BLOB)塞进 SQLite 树形结构,会带来严重的写入延迟和文件碎片化,实车录制时极易丢帧。
- MCAP:仅追加(Append-only)、分块压缩的格式,天生为大二进制载荷而生。数据进来后被迅速打包成 Chunk,打上时间戳、用 ZSTD/LZ4 压缩后顺序落盘,吃满磁盘顺序写带宽,从容应对多传感器高并发。
2. 时间索引与寻址
- ROS Bag:ROS 1 索引常因异常退出而损坏,需要漫长 reindex;ROS 2 的 SQLite 虽有 B-Tree 索引,但在数十 GB 大文件上做时间范围查询仍有瓶颈。
- MCAP:在文件尾部(Footer)与内部维护多级索引树(Chunk Index & Message Index),不仅记录时间戳,还记录每个 Topic 在文件中的绝对字节偏移量。想看"第 50 分钟的 LiDAR"时,读取器无需扫描,直接
seek()到对应字节,接近 O(1) 的极速跳转——哪怕文件有 100GB。
3. 回放与可视化
- ROS Bag:强绑定 ROS 运行环境,回放需要一整套 ROS 系统,还得有当初录制用的自定义
.msg源码才能正确解析。 - MCAP:自描述格式,把 Protobuf / ROS / JSON Schema 等结构定义直接内嵌进文件头,可脱离 ROS 环境。配合 Foxglove Studio,浏览器里拖入一个 MCAP 即可流畅拖动进度条回放点云与图像。
4. 仿真
- ROS Bag:云端大规模并行仿真时,要启动成千上万个
rosbag play进程,顺序读取慢,容易成为整个集群的 I/O 瓶颈。 - MCAP:字节级索引 + 高压缩率,非常适合在 S3 等对象存储上做范围读取(Range Requests)。仿真引擎无需下载整个 50GB 包,只需按 HTTP 请求拉取"接管前后那 10 秒"对应的 Chunk,大幅加速流水线。
5. 感知样本抽取(ETL)
- 用 ROS Bag:要抽特定相机帧、点云用于训练,得用 Python 一帧帧
read_messages(),CPU 密集且缓慢,拖慢数据飞轮。 - 用 MCAP:官方提供高度优化的 C++/Python/Rust 读取库,块级设计让 ETL 可以只解压、只抽取指定 Topic。把 MCAP 当成一座高速数据矿场,精准挖出所需样本即可。
对比总表
| 维度 | ROS 2 Bag (SQLite3) | MCAP |
|---|---|---|
| 底层架构 | 关系型数据库 | 仅追加、分块压缩的定制日志格式 |
| 大体积传感器数据 | 写入效率低、易碎片化 | 专为图像/点云等大 BLOB 优化 |
| 随机寻址(Seek) | 受限于数据库查询,较慢 | 基于字节偏移,微秒级跳转 |
| 依赖环境 | 强绑定 ROS 与 .msg 定义 |
自包含,脱离 ROS 也能解析与可视化 |
| ETL 到 Parquet | 抽取慢、计算开销大 | 提取极快,是云端 AI 数据飞轮的理想前置 |
车端直接录制 MCAP、云端 ETL 精准切片转 Parquet 用于大模型训练,已是被广泛验证的工程最佳实践组合。
五、关键提醒:别把 MCAP 直接甩给训练团队
技术上可行,但在工程架构上这是一个反模式(Anti-pattern)——会让你花大价钱买来的 GPU 算力,活活饿死在 I/O 上。
MCAP 在录制和ETL 抽取环节是神器,但它不适合直接作为"口粮"喂给分布式训练框架(PyTorch / JAX / Spark / Ray)。原因有三:
1. Dataloader 的"反序列化"地狱
MCAP 本质是以时间轴为主线的消息日志。Dataloader 读它时,必须先解开压缩 Chunk、再把 Protobuf/ROS 消息反序列化、最后拼装成 Tensor——极度消耗 CPU。而 Parquet 配合 PyArrow 可做到接近零拷贝:磁盘上已是按列紧凑排列,读取时直接映射进内存即可消费。用 MCAP,GPU 经常 0% 利用率,干等 CPU"剥壳"。
2. 多模态训练的"列裁剪"需求
训练 VLA 这类端到端模型时,数据集录了 Radar、点云、12 路相机、底盘 CAN,但某个实验可能只需要 [前向相机图像, 方向盘转角, 加速踏板] 三列。
- 用 MCAP:哪怕只要 10% 的数据,也得把整个 Chunk 拉下来、解压、再丢弃 90%——巨大的带宽与 I/O 浪费。
- 用 Parquet:列式存储让引擎只读取那三列的物理字节,完全跳过点云和其他相机。这种列级读取,是支撑海量多模态训练的基石。
3. 全局 Shuffle 与分布式 Sharding 灾难
分布式训练(DDP/FSDP)要求全局打乱,每个 GPU 节点随机捞取不同时段的样本。MCAP 的核心优势是"时间连续性",让 8 台机器在同一个 MCAP 里随机跳读,会彻底打破顺序读取优势,I/O 性能直线跳水。
标准解法:在数据准备阶段,用分布式集群把连续时间序列切碎,转成 Parquet 宽表,或打包成 WebDataset(基于 tar、专为 PyTorch 流式高吞吐优化的格式),让各 GPU 节点直接拉取独立分片(Shards)高效训练。
六、数据飞轮的标准分工
把上面所有环节串起来,现代自动驾驶 / 具身智能数据平台最合理的链路是:
- 车端录制(Ingestion):用 MCAP。吃满顺序写带宽,应对多传感器高并发,绝不丢帧。
- 云端处理(ETL):集群高速解析 MCAP,做时间戳对齐、抽帧、自动打伪标签。
- 特征落盘(Storage):将对齐后的多模态特征转存为 Parquet 或 WebDataset。
- 模型训练(Training):PyTorch 集群直接挂载读取 Parquet/WebDataset,利用列式特性与零拷贝,让 GPU 跑满。
直接把 MCAP 交给训练团队,相当于把没剥壳的稻谷端上餐桌。作为底层引擎与架构的设计者,用一道 ETL 流水线提前剥好这层"壳",才是保障模型迭代效率的正解。
七、结论
ZSTD 压缩能把笨重的 MCAP 文件变成精简、可管理的资产,而不牺牲任何质量——3GB 到 900MB 只是开始。但真正的价值在于把 MCAP 放回它该在的位置:车端录制与云端 ETL 的最佳载体,而非训练阶段的最终格式。
录制选 MCAP、压缩用 ZSTD、训练前转 Parquet/WebDataset——这条链路,正在被越来越多团队验证为标准答案。如果你也在做机器人或自动驾驶数据基建,不妨用上面的脚本先把压缩这一关跑通。
延伸阅读: Foxglove 的 MCAP 指南 或 ROS 文档中的 rosbag2_storage_mcap。
关键词:ROS2 MCAP 压缩 · ZSTD 无损压缩 · 减小 ROS bag 大小 · 自动驾驶数据飞轮 · MCAP vs Parquet

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)