AI 编译器后端优化:从计算图到硬件指令的 TensorRT 编译链路
AI 编译器后端优化:从计算图到硬件指令的 TensorRT 编译链路
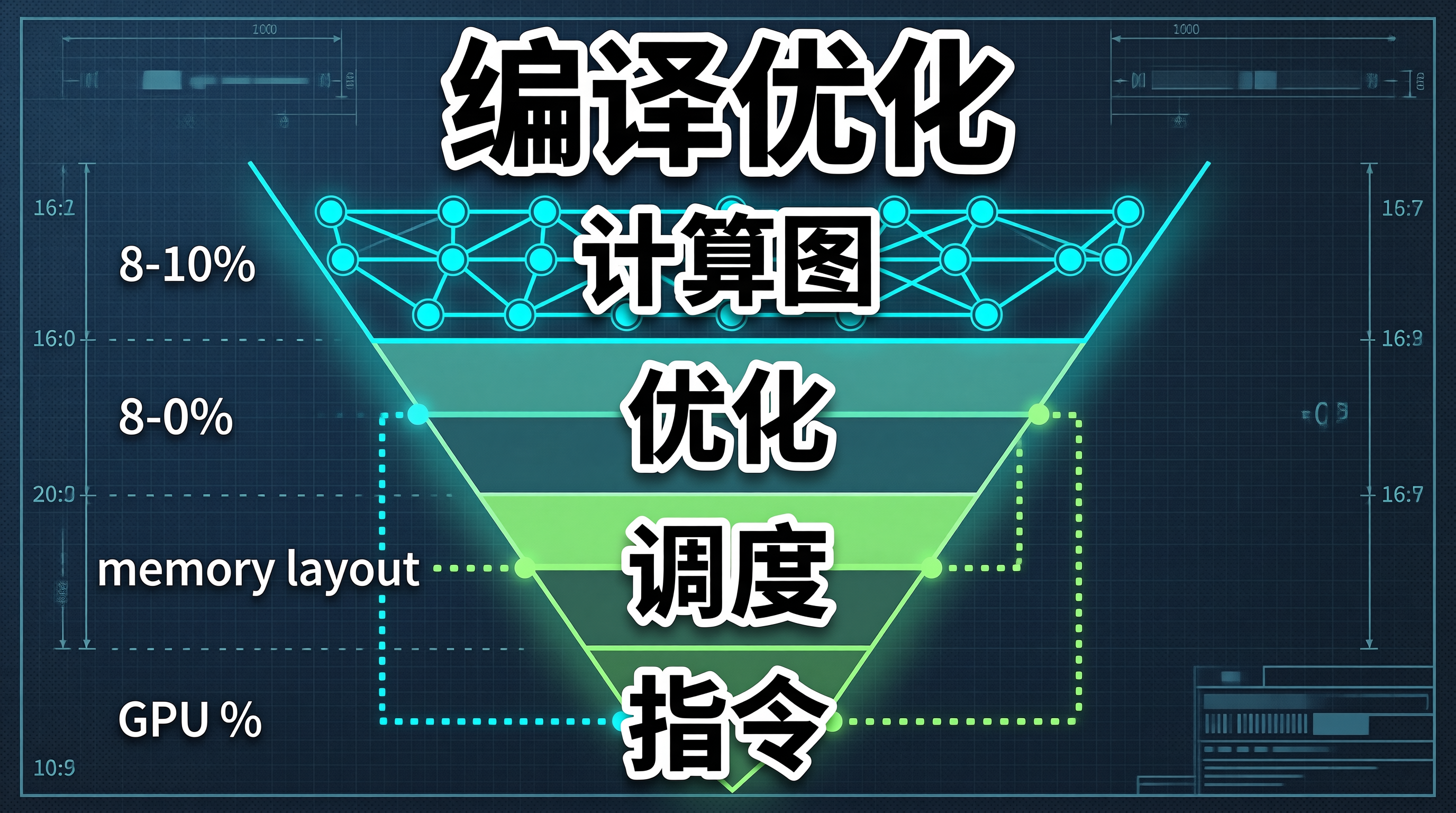
一、通用推理引擎的性能天花板:为什么"能跑"和"跑得快"是两回事
ONNX Runtime 和 TFLite 可以在多种硬件上运行 AI 模型,但"能跑"不等于"跑得快"。通用推理引擎为了保证跨平台兼容性,无法针对特定硬件做深度优化——内存布局、指令调度、缓存策略都是通用方案,而非针对 GPU 架构的定制方案。在 A100/H100 这类高端 GPU 上,通用引擎的算力利用率通常只有 40-60%,大量计算资源被浪费在内存搬运和指令等待上。
TensorRT 是 NVIDIA 专为 GPU 推理优化的编译器,核心能力是将 ONNX 计算图编译为针对特定 GPU 架构的优化指令序列。通过层融合、精度校准、内核自动调优和动态显存管理,TensorRT 可以将 GPU 算力利用率提升到 80% 以上。这不是微调参数就能达到的,而是编译器级别的深度优化。
二、TensorRT 编译优化链路
TensorRT 的编译过程分为四个阶段:解析 ONNX 图 → 图优化与层融合 → 精度校准 → 内核自动调优。每个阶段都有明确的优化目标。
flowchart TD
A[ONNX 模型] --> B[解析阶段: Builder]
B --> C[图优化阶段: Optimizer]
C --> D[层融合: Conv+BN+ReLU → 单算子]
C --> E[精度标注: FP16/INT8 混合精度]
C --> F[内存布局优化: NHWC → NCHW4]
D --> G[内核选择阶段: Kernel Selection]
E --> G
F --> G
G --> H{内核自动调优}
H --> I[遍历候选内核]
I --> J[实测延迟]
J --> K[选择最优内核]
K --> L[序列化引擎: .engine 文件]
L --> M[部署到生产环境]
subgraph 精度校准
N[校准数据集] --> O[INT8 校准器]
O --> P[逐层激活值范围]
P --> E
end
style C fill:#bbf,stroke:#333
style H fill:#f9f,stroke:#333
style L fill:#bfb,stroke:#333
关键优化手段:
- 层融合(Layer Fusion):将 Conv + Bias + BatchNorm + ReLU 融合为单个 CUDA 内核,减少全局内存访问次数
- 精度校准(Precision Calibration):对每层选择最优精度(FP32/FP16/INT8),在精度和速度之间自动权衡
- 内核自动调优(Kernel Auto-Tuning):对每个算子遍历所有可用的 CUDA 内核实现,实测延迟后选择最快的
- 动态显存管理:分析张量生命周期,复用不再需要的显存,将峰值显存占用降低 30-50%
三、生产级代码实现
3.1 ONNX 到 TensorRT 引擎的编译流程
# trt_compiler.py
# ONNX 模型编译为 TensorRT 引擎
import tensorrt as trt
import numpy as np
import os
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
class TRTCompiler:
"""TensorRT 编译器"""
def __init__(
self,
onnx_path: str,
engine_path: str,
precision: str = "fp16",
max_batch_size: int = 8,
max_workspace_size: int = 4 << 30 # 4GB
):
self.onnx_path = onnx_path
self.engine_path = engine_path
self.precision = precision
self.max_batch_size = max_batch_size
self.max_workspace_size = max_workspace_size
def compile(
self,
calibration_data: np.ndarray = None
) -> bool:
"""执行编译流程"""
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network(
1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
)
parser = trt.OnnxParser(network, TRT_LOGGER)
# 解析 ONNX 模型
with open(self.onnx_path, "rb") as f:
if not parser.parse(f.read()):
for i in range(parser.num_errors):
trt_logger.log(
trt.Logger.ERROR,
parser.get_error(i).desc()
)
return False
# 配置编译器
config = builder.create_builder_config()
config.max_workspace_size = self.max_workspace_size
# 精度设置
if self.precision == "fp16":
if builder.platform_has_fast_fp16:
config.set_flag(trt.BuilderFlag.FP16)
config.set_flag(trt.BuilderFlag.STRICT_TYPES)
print("启用 FP16 精度")
elif self.precision == "int8":
if builder.platform_has_fast_int8:
config.set_flag(trt.BuilderFlag.INT8)
if calibration_data is not None:
config.int8_calibrator = Int8Calibrator(
calibration_data
)
print("启用 INT8 精度")
# 动态 batch 维度配置
profile = builder.create_optimization_profile()
input_tensor = network.get_input(0)
shape = input_tensor.shape
min_shape = (1,) + shape[1:]
opt_shape = (self.max_batch_size // 2,) + shape[1:]
max_shape = (self.max_batch_size,) + shape[1:]
profile.set_shape(
input_tensor.name, min_shape, opt_shape, max_shape
)
config.add_optimization_profile(profile)
# 编译引擎(耗时操作,自动调优在此阶段执行)
print("开始编译 TensorRT 引擎...")
engine = builder.build_engine(network, config)
if engine is None:
print("编译失败")
return False
# 序列化保存
with open(self.engine_path, "wb") as f:
f.write(engine.serialize())
print(f"编译完成: {self.engine_path}")
print(f"引擎大小: {os.path.getsize(self.engine_path) / 1e6:.1f} MB")
return True
class Int8Calibrator(trt.IInt8EntropyCalibrator2):
"""INT8 精度校准器"""
def __init__(
self,
calibration_data: np.ndarray,
batch_size: int = 32,
cache_file: str = "calibration.cache"
):
self.data = calibration_data
self.batch_size = batch_size
self.cache_file = cache_file
self.current_index = 0
def get_batch_size(self):
return self.batch_size
def get_batch(self, names):
if self.current_index >= len(self.data):
return None
batch = self.data[
self.current_index:self.current_index + self.batch_size
]
self.current_index += self.batch_size
# 转换为 GPU 可用的连续内存
return np.ascontiguousarray(batch)
def read_calibration_cache(self):
if os.path.isfile(self.cache_file):
with open(self.cache_file, "rb") as f:
return f.read()
return None
def write_calibration_cache(self, cache):
with open(self.cache_file, "wb") as f:
f.write(cache)
3.2 TensorRT 推理封装
# trt_inference.py
# TensorRT 引擎推理封装
import tensorrt as trt
import numpy as np
import pycuda.driver as cuda
import pycuda.autoinit
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
class TRTInference:
"""TensorRT 推理封装"""
def __init__(self, engine_path: str):
# 加载序列化引擎
runtime = trt.Runtime(TRT_LOGGER)
with open(engine_path, "rb") as f:
self.engine = runtime.deserialize_cuda_engine(f.read())
self.context = self.engine.create_execution_context()
self.stream = cuda.Stream()
# 分配 GPU 内存
self.inputs = []
self.outputs = []
self.bindings = []
for i in range(self.engine.num_bindings):
name = self.engine.get_binding_name(i)
dtype = trt.nptype(self.engine.get_binding_dtype(i))
shape = self.engine.get_binding_shape(i)
size = np.prod(shape)
# 分配 Host 和 Device 内存
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
self.bindings.append(int(device_mem))
if self.engine.binding_is_input(i):
self.inputs.append({
"name": name, "host": host_mem,
"device": device_mem, "shape": shape
})
else:
self.outputs.append({
"name": name, "host": host_mem,
"device": device_mem, "shape": shape
})
def infer(self, input_data: np.ndarray) -> np.ndarray:
"""执行推理"""
# 设置动态 batch 维度
self.context.set_binding_shape(
0, input_data.shape
)
# 拷贝输入数据到 GPU
np.copyto(self.inputs[0]["host"], input_data.ravel())
for inp in self.inputs:
cuda.memcpy_htod_async(
inp["device"], inp["host"], self.stream
)
# 执行推理
self.context.execute_async_v2(
bindings=self.bindings,
stream_handle=self.stream.handle
)
# 拷贝输出数据回 Host
for out in self.outputs:
cuda.memcpy_dtoh_async(
out["host"], out["device"], self.stream
)
self.stream.synchronize()
return self.outputs[0]["host"].reshape(
self.context.get_binding_shape(
self.engine.num_bindings - 1
)
)
3.3 编译性能对比基准
# trt_benchmark.py
# ONNX Runtime vs TensorRT 性能对比
import time
import numpy as np
import onnxruntime as ort
from trt_inference import TRTInference
def benchmark(
engine,
input_shape: tuple,
num_warmup: int = 20,
num_iterations: int = 200
) -> dict:
"""通用基准测试函数"""
dummy_input = np.random.randn(*input_shape).astype(np.float32)
# 预热
for _ in range(num_warmup):
if isinstance(engine, ort.InferenceSession):
engine.run(None, {
engine.get_inputs()[0].name: dummy_input
})
else:
engine.infer(dummy_input)
# 正式测试
latencies = []
for _ in range(num_iterations):
start = time.perf_counter()
if isinstance(engine, ort.InferenceSession):
engine.run(None, {
engine.get_inputs()[0].name: dummy_input
})
else:
engine.infer(dummy_input)
latencies.append((time.perf_counter() - start) * 1000)
latencies.sort()
return {
"avg_ms": round(np.mean(latencies), 2),
"p95_ms": round(latencies[int(len(latencies) * 0.95)], 2),
"p99_ms": round(latencies[int(len(latencies) * 0.99)], 2),
"qps": round(1000.0 / np.mean(latencies), 1)
}
if __name__ == "__main__":
input_shape = (1, 3, 224, 224)
# ONNX Runtime FP32
ort_session = ort.InferenceSession(
"model.onnx",
providers=["CUDAExecutionProvider"]
)
ort_result = benchmark(ort_session, input_shape)
print(f"ONNX Runtime (FP32): {ort_result}")
# TensorRT FP16
trt_engine = TRTInference("model_fp16.engine")
trt_result = benchmark(trt_engine, input_shape)
print(f"TensorRT (FP16): {trt_result}")
# TensorRT INT8
trt_int8 = TRTInference("model_int8.engine")
trt_int8_result = benchmark(trt_int8, input_shape)
print(f"TensorRT (INT8): {trt_int8_result}")
# 加速比
speedup_fp16 = ort_result["avg_ms"] / trt_result["avg_ms"]
speedup_int8 = ort_result["avg_ms"] / trt_int8_result["avg_ms"]
print(f"FP16 加速比: {speedup_fp16:.1f}x")
print(f"INT8 加速比: {speedup_int8:.1f}x")
四、TensorRT 编译的工程代价:编译耗时、GPU 绑定与调试黑盒
TensorRT 不是万能的,以下 Trade-offs 需要在架构决策中提前评估:
编译耗时。TensorRT 的内核自动调优阶段需要遍历所有候选内核并实测延迟,对于复杂模型(如 LLM),编译时间可能长达数小时。这意味着模型更新频率受限——如果每天需要更新模型,编译时间会成为瓶颈。缓解手段:使用 trtexec 工具预编译并缓存引擎,模型更新时只重新编译变更的子图。
GPU 架构绑定。TensorRT 编译出的 .engine 文件与特定 GPU 架构强绑定。在 A100 上编译的引擎无法在 V100 上运行,甚至同一架构不同驱动版本也可能不兼容。多 GPU 集群中,需要为每种 GPU 型号分别编译引擎,增加了部署复杂度。建议在 CI/CD 中为每种目标 GPU 架构建立独立的编译流水线。
调试黑盒。TensorRT 编译后的引擎是二进制文件,无法反编译回可读的计算图。当推理结果与 ONNX Runtime 不一致时,很难定位是哪一层的精度问题。TensorRT 提供了 polygraphy 工具进行逐层精度对比,但使用门槛较高。生产环境中建议保留 ONNX Runtime 作为对照基准,对关键模型做双路推理对比。
动态形状支持有限。TensorRT 对动态 batch 维度的支持需要通过 Optimization Profile 预声明范围,且范围过大会降低优化效果。对于输入形状变化剧烈的场景(如 NLP 中序列长度从 32 到 2048),TensorRT 的性能优势会大幅缩水。此类场景建议按序列长度分桶,为每个桶编译专用引擎。
五、总结
TensorRT 的核心价值在于将通用推理引擎的"跨平台兼容"升级为"GPU 架构深度优化",通过编译器级别的层融合、精度校准和内核调优,将 GPU 算力利用率从 40-60% 提升到 80% 以上。落地要点如下:
- 精度选择:FP16 是性价比最高的选择(2-3x 加速,精度损失 < 0.1%),INT8 适合对延迟极致要求的场景(3-5x 加速,精度损失 1-2%)
- 校准数据:INT8 量化必须使用与生产数据分布一致的校准集,建议 500-1000 个样本
- 编译缓存:预编译引擎并缓存,避免运行时编译的长时间等待
- 多架构编译:为每种目标 GPU 架构建立独立编译流水线,CI/CD 中自动化处理
- 双路对比:保留 ONNX Runtime 作为精度基准,对关键模型做 TensorRT vs ORT 的输出对比

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)