【Video Agent 14】(ICCV 2025)LVAgent: LVU by Multi-Round Dynamical Collaboration of MLLM Agents
【Video Agent】(ICCV 2025)LVAgent: Long Video Understanding by Multi-Round Dynamical Collaboration of MLLM Agents
写在前面:如果想了解更多关于长视频理解和视频智能体新工作,可以关注笔者的Github仓库:Awesome-Video-Agent。
论文简介 🍀
- 📖 题目:LVAgent: Long Video Understanding by Multi-Round Dynamical Collaboration of MLLM Agents
- 📅 来源:ICCV 2025
- 🏫 单位:中科院、中科大、清华、上海AI Lab
- 🌍 主页:https://arxiv.org/abs/2503.10200
- 💻 代码:https://github.com/64327069/LVAgent
- ✒️ 摘要:现有的 MLLM 在对长视频中的时间上下文进行建模时面临重大挑战。目前,主流的基于 Agent 的方法使用外部工具来辅助单个 MLLM 回答长视频问题。尽管有这种基于工具的支持,单个 MLLM 仍然只能对长视频提供部分理解,从而导致性能受限。为了更好地处理长视频任务,论文提出了 LVAgent,这是首个能够在长视频理解中实现 MLLM agents 多轮动态协作的框架。论文方法由四个关键步骤组成:
- 1)选择:根据不同任务,从模型库中预先选择合适的 agents,组成最优的 agent 团队。
- 2)感知:为长视频设计了一种有效的检索方案,在保持计算效率的同时,提高对关键时间片段的覆盖率。
- 3)行动:智能体回答长视频问题并交换理由。
- 4)反思:评估每个智能体在每轮讨论中的表现,并优化智能体团队以实现动态协作。智能体通过 MLLM 智能体的多轮动态协作迭代地完善其答案。
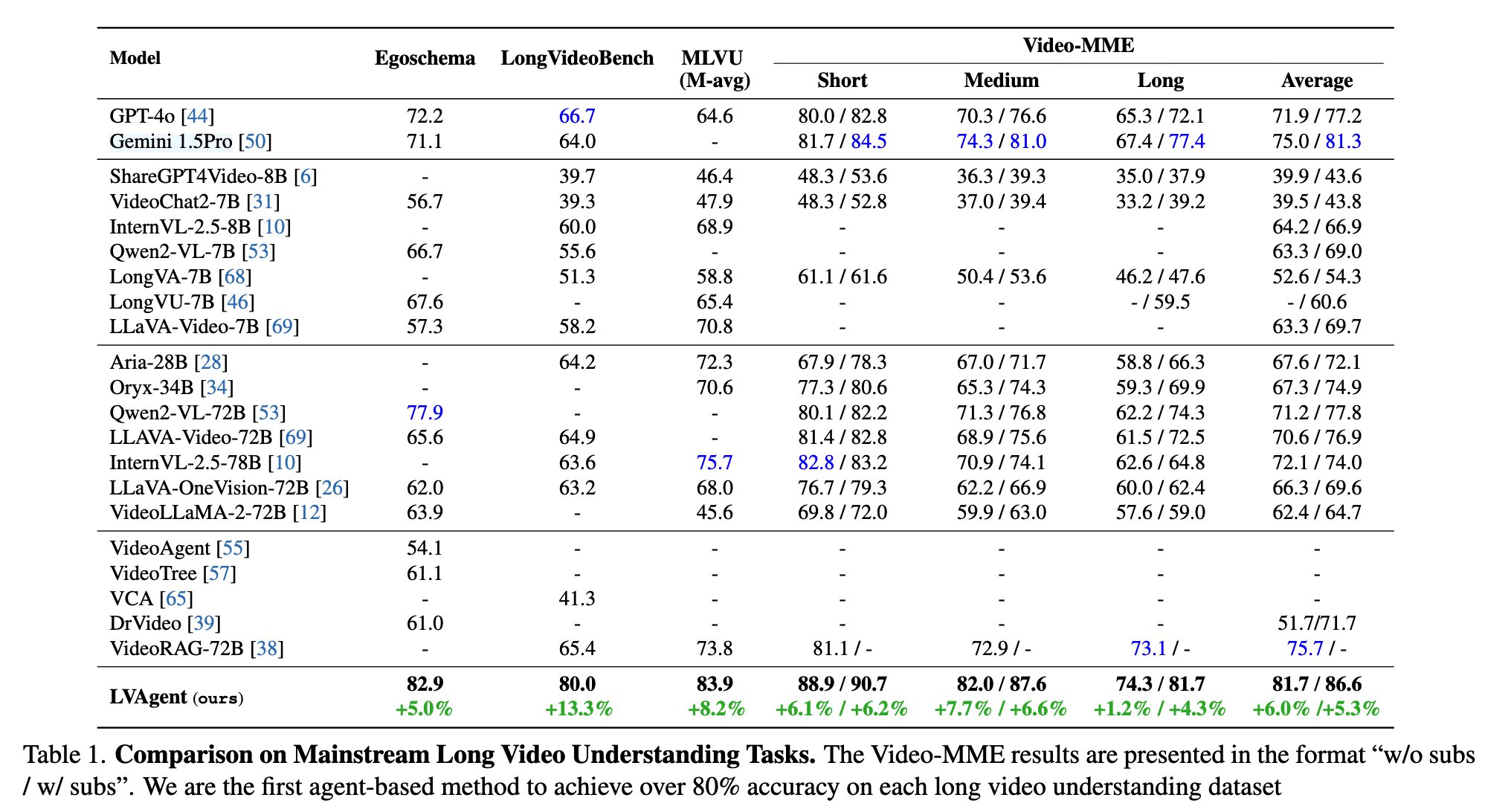
LVAgent 是首个在长视频理解任务上超越所有闭源模型(如 GPT-4o)和开源模型(如 InternVL-2.5 和 Qwen2-VL)的智能体系统方法。 LVAgent 在四个主流长视频理解任务上实现了 80% 的准确率。值得注意的是,LVAgent 在 LongVideoBench 上将准确率提升了 13.3%。代码见 https://github.com/64327069/LVAgent。
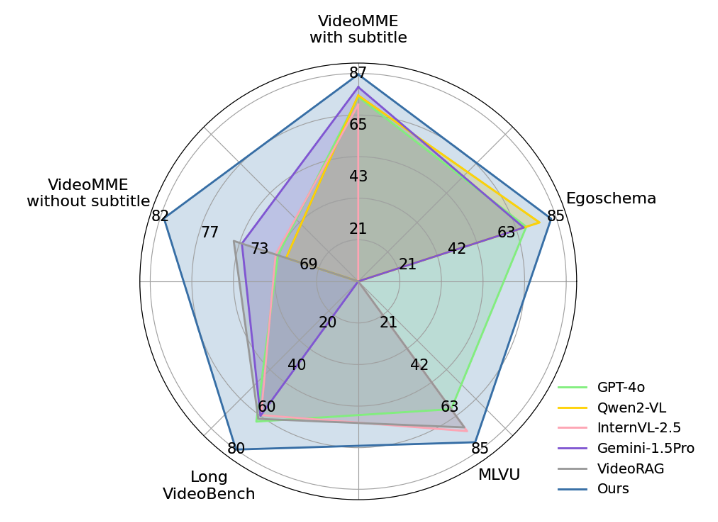
图 1. 与 SOTA 的比较。LVAgent 在长视频任务中优于所有闭源模型(包括 GPT-4o)和开源模型(包括基于 Agent 的方法)。
一、论文阅读
1.1 引言(Introduction)
长视频在互联网数据中至关重要,并且在医疗、教育和娱乐等领域也很重要。在当前数据驱动的时代,正确且高效地理解长视频具有重大意义。尽管已经在大规模多模态数据集上进行了预训练,多模态大语言模型(MLLMs)在建模长视频(时长从几分钟到几小时)的长期时间上下文方面仍然面临困难。将大量视频帧(例如按1帧/秒)直接输入单个MLLM会带来高昂的计算成本和大量冗余信息,从而导致性能较差。以图3为例,论文将整个视频输入到Gemini 1.5Pro、GPT-4o、Qwen2VL和InternVL-2.5 中,而由于冗余的混淆信息,所有这些模型都无法给出正确答案。

图3 LVAgent的可视化。不同模型对特定问题的响应及其答案的原因的可视化结果,关键部分以不同的颜色突出显示。
基于智能体的方法在长视频理解方面具有巨大潜力,因为智能体可以将复杂问题简化,并自主调用各种工具,从长视频中提取关键信息,以辅助长视频理解。然而,当前基于智能体的长视频任务方法仍有很大的改进空间。一些方法使用 CLIP 检索关键帧来进行长视频理解。然而,CLIP 难以检索长期时序信息,而且其预训练数据与长视频之间存在领域差距。一些方法使用外部工具(例如 memory bank、RAG)来帮助 MLLMs 进行长视频理解。即使有工具的支持,仅依赖单个 MLLM 来回答关于长视频的问题,也只能对视频内容形成部分理解,从而导致性能受限。总之,长视频理解主要存在两个挑战。第一个挑战是如何根据查询更好地检索包含关键信息的视频片段。第二个挑战是如何利用多智能体协作来更好地理解长视频。
为了解决这些挑战,论文提出了一种面向智能体的四步动态协作范式,即 Selection、Perception、Action 和 Reflection。
- (1) Selection。从一个包含 Qwen2-VL 和 InternVL-2.5 等主流 MLLMs 的智能体库中,预先选择最优的智能体团队。通过选择过程,只有最合适的模型会参与后续流程,从而节省计算资源并提高效率。
- (2) Perception。针对 CLIP 在检索长视频时间信息方面的能力,提出了一种自适应帧提取方法,并设计了一种针对长视频的有效检索方法。该流程旨在在不牺牲计算效率的前提下,增强对关键时间片段的覆盖。
- (3) Action。在检索到与查询相关的视频片段后,智能体回答长视频问题并给出理由。
- (4) Reflection。为了使多个智能体之间能够更好地协作,从而更好地理解长视频,论文引入了一个反思过程,用于评估每个智能体在每一轮讨论中的表现。基于表现,对智能体进行评分和筛选,从而为每个查询实现动态协作。这个反思过程有助于促进更好的协作,排除错误推断,并达成共识。
在这四个过程中,智能体通过讨论、检索关键视频片段,并与其他预先选定的智能体整合信息来优化答案。论文在四个长视频理解数据集上验证了其有效性:EgoSchema、VideoMME、MLVU、LongVideoBench。实验表明,LVAgent 在主流长视频任务上实现了超过 80% 的准确率。论文的贡献可以概括为三个方面:
- 首先,论文提出了 LVAgent,这是一个用于长视频理解的长视频多智能体协作流水线。
- 其次,LVAgent 是一种新颖的 MLLM Agents 多轮次、多步骤动态协作流水线。LVAgent 使多个 MLLM agents 能够动态地处理和整合长期时间上下文,以实现更全面且稳健的长视频理解。
- 最后,实证结果表明,LVAgent 具有更优的准确性。LVAgent 在四个主流长视频理解任务上的准确率均超过 80%。它是首个多轮动态多智能体协作流水线,在长视频理解任务上超越了所有闭源模型(包括 GPT)和开源模型(包括 InternVL-2.5 和 Qwen2VL)。值得注意的是,在 LongVideoBench 数据集上,LVAgent 相比 SOTA 将准确率最高提升了 13.3%。
1.2 方法(Method)
在接下来的章节中,将全面介绍论文提出的 LVAgent 范式,并以详细且循序渐进的方式阐述四个关键过程,即 Selection、Perception、Action 和 Reflection。
1.2.1 选择(Selection)
为了回答关于长视频的问题,论文利用流行的 MLLMs 来建立一个 Agent Library,其中包含当前流行的 MLLMs,即 Qwen2VL、InternVL-2.5、LongVU 和 LLaVAVideo(LV)。在多智能体系统中,智能体在不同任务和领域中的表现往往各不相同,表现不佳的智能体会破坏协作并增加计算成本。为了解决这一问题,论文提出了一种基于伪标签投票的智能体预选择方法,以高效识别适用于某项任务的最优智能体团队,如图4所示。
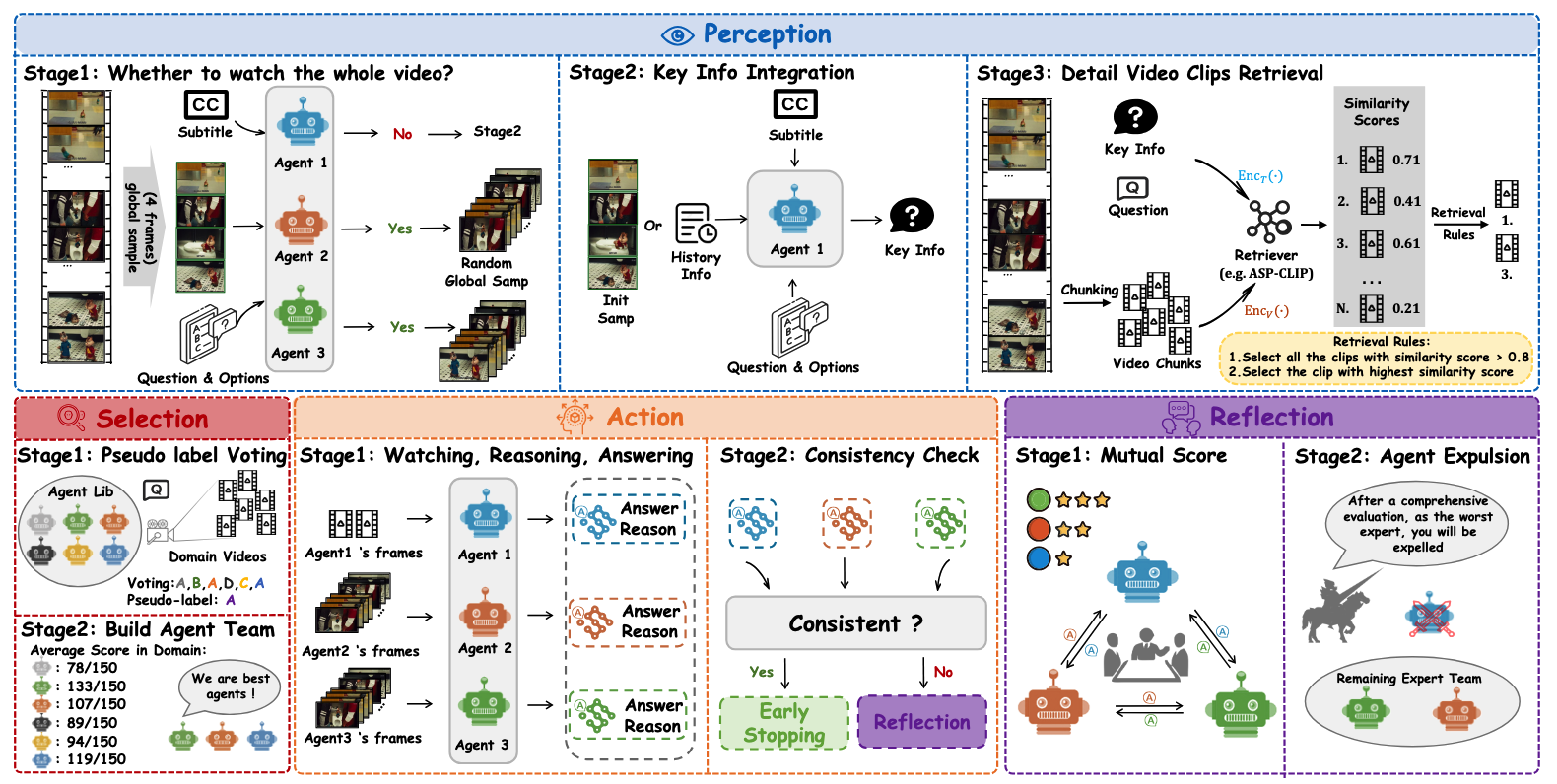
图4 LVAgent框架。此图说明了LVAgent协作框架的四个关键步骤:选择、感知、动作和反思。
为了快速评估每个智能体 A i ( i = 1 , 2 , . . , N ) A_i(i = 1, 2, .., N) Ai(i=1,2,..,N)的性能,其中 N N N 是智能体库中的智能体总数,论文从任务数据集 D D D 中随机采样一个包含 150 个视频、且不带标签的子集 S S S。对于子集 S S S 中每个带有问题 Q Q Q、视频字幕 T T T 和选项 O O O 的视频样例 V ∈ S V ∈ S V∈S,通过采用 Perception 和 Action 过程来获得视频 V V V 的答案集合 S a n s = a n s 0 , a n s 1 , . . . , a n s n S_{ans} = {ans_0, ans_1, ..., ans_n} Sans=ans0,ans1,...,ansn。Perception 和 Action 过程将在后文详细介绍。在该集合 S a n s S_{ans} Sans 中出现频率最高的答案被用作视频 V V V 的伪标签 L v L_v Lv,论文用准确率来衡量每个智能体 Ai 在伪标签下的性能,如下式所示:
A c c ( A i ) = 1 ∣ S ∣ ∑ V ∈ S [ A i ( Q , T , O , V s a m p ) = L V ] ( 1 ) \mathrm{Acc}(A_i) = \frac{1}{|S|}\sum_{V \in S} \left[ A_i(Q, T, O, V_{\mathrm{samp}}) = L_V \right] \quad(1) Acc(Ai)=∣S∣1V∈S∑[Ai(Q,T,O,Vsamp)=LV](1)
论文选择伪标签准确率最高的前三个智能体组成最优团队。该智能体预筛选过程确保只有能力最强的智能体进入后续阶段,从而最大化协作推理框架的有效性。
1.2.2 感知(Perception)
为了减少冗余信息的干扰,检索视频中的关键区域,并更有效地回答问题,论文提出了一种新颖的三阶段感知流水线,如图4所示。
图4 LVAgent框架。此图说明了LVAgent协作框架的四个关键步骤:选择、感知、动作和反思。
在阶段 1 中,智能体被赋予自主判断在回答问题之前是否有必要观看整个视频的能力。论文首先随机采样 4 帧 v ^ \hat{v} v^,使每个智能体 A i A_i Ai 对视频 V V V 有一个粗略的理解。然后,基于 v ^ \hat{v} v^、 Q Q Q、 T T T、 O O O, A i A_i Ai 判断是否需要观看整个视频:
D i = A i ( v ^ , Q , T , O ) ( 2 ) D_i = A_i(\hat{v},Q,T,O) \quad(2) Di=Ai(v^,Q,T,O)(2)
如果模型决定观看整个视频(即 D i D_i Di 为“Yes”),则通过全局采样提取 16 帧。相反,如果模型认为没有必要观看整个视频,那么它将进入阶段 2。
在阶段 2 中,LVAgent基于粗略视觉信息 v ^ \hat{v} v^、问题 Q Q Q 和选项 O O O,总结用于回答该问题的关键信息。在第一轮协作中,各个智能体生成视频的关键信息,其形式化表示为:
K i = A i ( v ^ , Q , T , O ) ( 3 ) K_i = A_i(\hat{v}, Q, T, O) \quad (3) Ki=Ai(v^,Q,T,O)(3)
在第一轮协作之后,各个智能体将生成历史信息 H i n f o H_{info} Hinfo。 H i n f o H_{info} Hinfo 由每个智能体的答案、理由、得分以及是否需要被移除组成,如图 5 所示。下一轮感知过程的关键信息表述为:
K i = A i ( H i n f o , Q , T , O ) ( 4 ) K_i = A_i(H_{info}, Q, T, O) \quad(4) Ki=Ai(Hinfo,Q,T,O)(4)
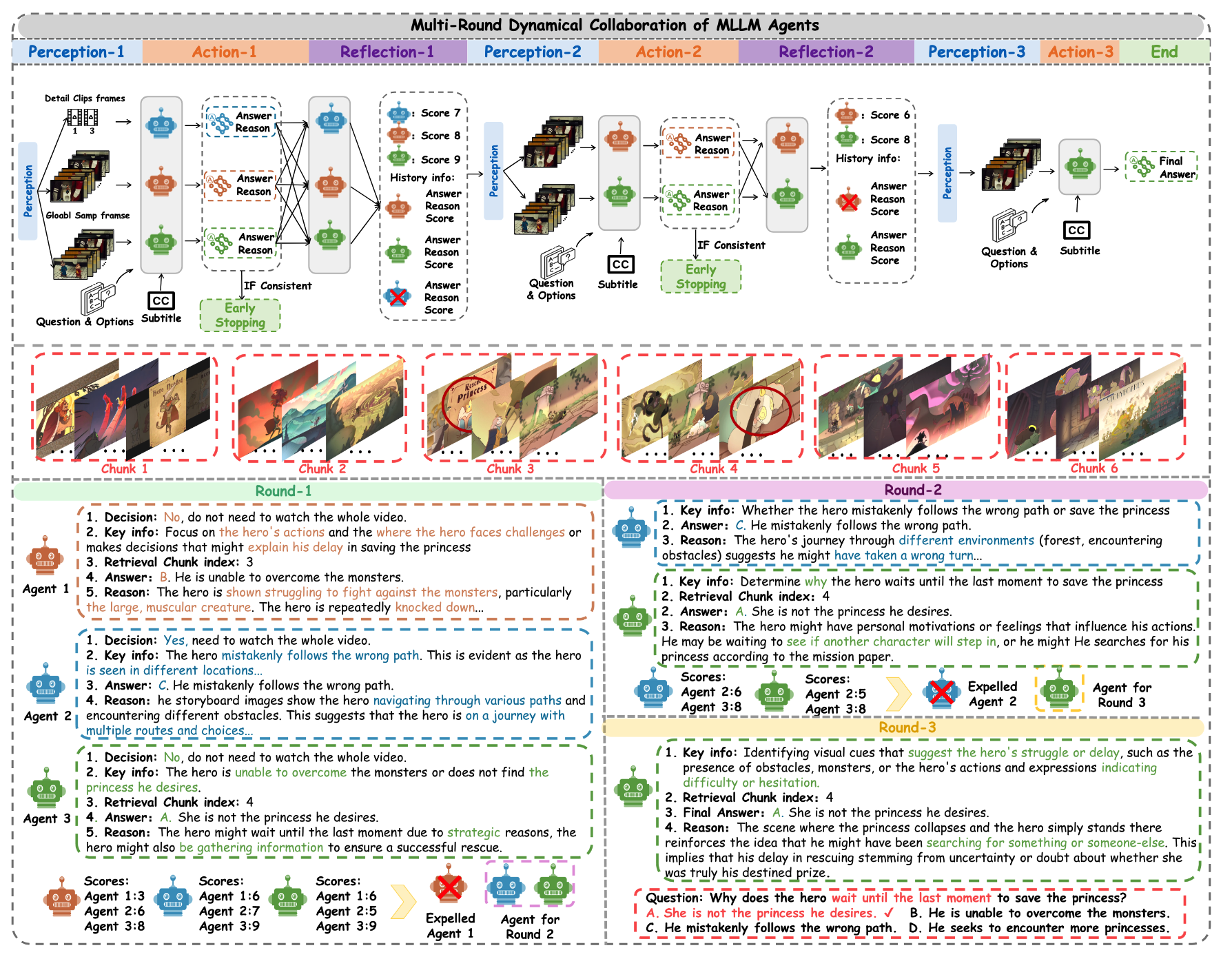
图5. LVAgent的多轮动态协作。上图是论文的协作框架,针对这个问题进行了3轮讨论。下图是每轮讨论的结果和讨论细节。详细提示见补充文档。
K i K_i Ki 使检索模型能够执行检索。需要注意的是,由于个体智能体之间存在差异,关键信息 K i K_i Ki 以及是否观看整个视频的判定 D i D_i Di 可能会不同。
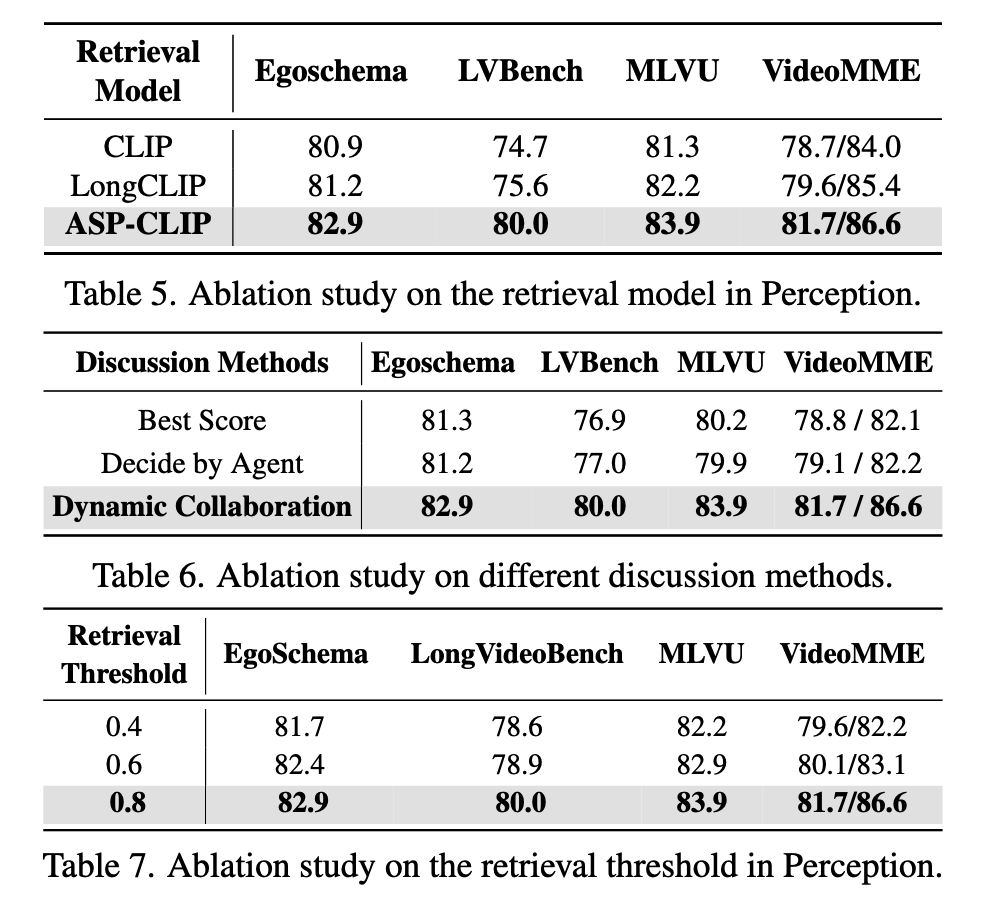
在阶段 3 中,LVAgent执行细节视频块检索。通过消融实验,将视频划分为六个相等的块 c h k 1 , c h k 2 , . . . , c h k 6 {chk_1, chk_2, ..., chk_6} chk1,chk2,...,chk6。对于每个块,随机采样 16 帧以形成一个帧集合 S f r a m e = f 1 , f 2 , . . . , f 6 S_{frame} = f1, f2, ..., f6 Sframe=f1,f2,...,f6。然后,论文使用在收集的 LongVR 数据集上微调的 ASP-CLIP 模型来计算每个视频块的 CLIP 分数。
S i m ( c h k i ) = A S P ( f i , K i ) + A S P ( f i , Q ) ( 5 ) Sim(chk_i) = ASP (f_i, K_i) + ASP (f_i, Q) \quad (5) Sim(chki)=ASP(fi,Ki)+ASP(fi,Q)(5)
如果一个分块的整体 CLIP 分数大于 0.8,则选择该分块 c h k i chk_i chki 中采样的帧 f i f_i fi。如果没有某个 chunk 的分数大于 0.8,就选择该 chunk 中 CLIP 分数最高的采样帧。
这种方法通过将长视频检索问题转化为具有六个类别(chunks)的简单多分类问题,有效降低了检索难度。消融实验表明,论文提出的感知过程提高了模型处理长视频的准确性。
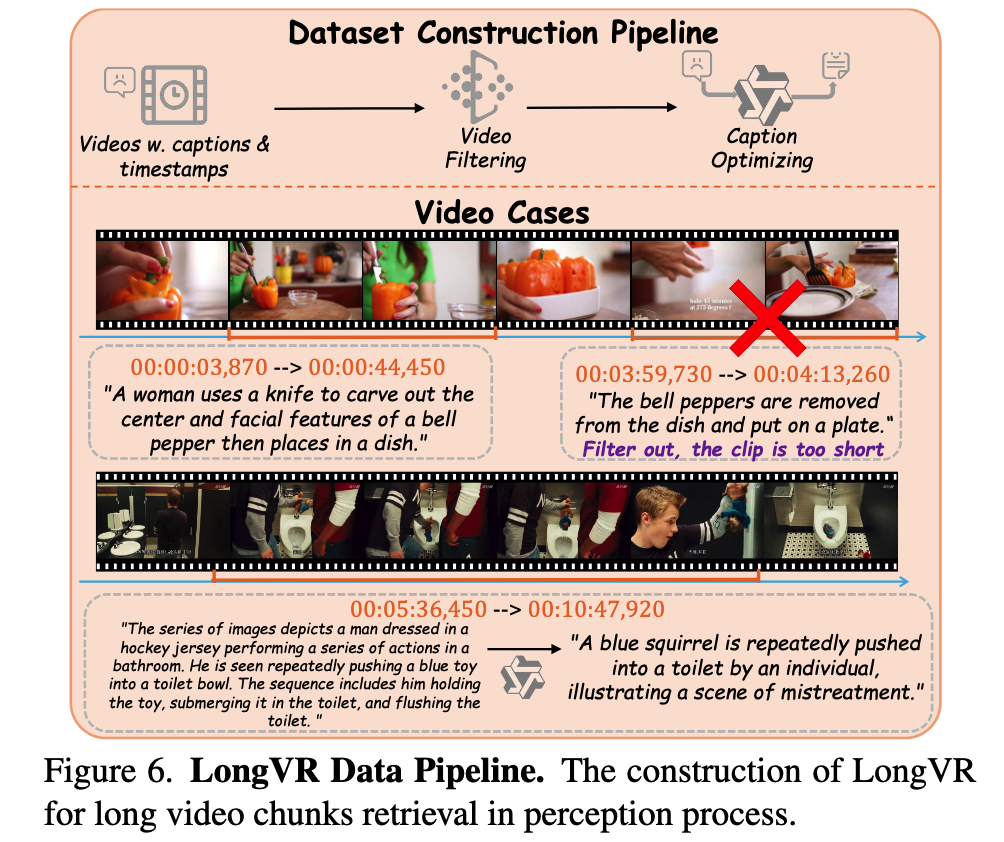
用于长视频检索的 LongVR 数据集。为了增强 ASP-CLIP 的检索能力,使其更好地辅助长视频任务,论文整理了一个用于微调 ASP-CLIP 模型的多样化数据集,如附录中的表 8 所示,该数据集由来自五个数据集的 82k 个视频片段组成。该集合覆盖了广泛的场景、主题和视频质量,为训练视频检索模型提供了坚实的基础。论文从 ActivityNet、OpenVid-1M 、ViTT、MovieChat-Caption 和 Youcook2 的数据集中提取长视频用于检索任务,如图 6 所示。首先,裁剪带有字幕的视频片段。如果一个视频已被预先标注为多个片段,就将这些片段及其字幕作为论文数据集的组成部分。其次,为了更好地适应长视频场景,过滤掉时长短于 5 秒或长于 12 分钟的视频片段。只保留长度合适的片段及其字幕。最后,考虑到 CLIP 的上下文长度有限,为了防止由于字幕过长而导致 clip-text 编码器中的信息截断,使用 Qwen2-VL 对字幕进行优化。此外,如果一条字幕中的 token 数少于 20,论文也会过滤掉这条数据,因为如此短的字幕不足以概括相对较长视频的内容。在对字幕进行人工筛选后,得到的长视频数据集的平均视频时长为 145.6 秒。数据集中的字幕平均长度为 71 个 token。总体而言,论文构建了一个包含 82K 个样本的长视频检索数据集,并在 LongVR 上对 ASP-CLIP 进行了微调,取得了显著提升。有关数据集构建和数据处理方案的详细信息可参见补充文档。
1.2.3 动作(Action)
在图4所示的 Action 过程中,论文首先基于 Perception 过程中提取的帧获得答案和原因:
a n s i , R i = A i ( V s a m p , Q , T , O ) ( 6 ) ans_i, R_i = A_i(V_{samp}, Q, T, O) \quad (6) ansi,Ri=Ai(Vsamp,Q,T,O)(6)
对于所选智能体团队中的所有智能体,获取一组答案 S a n s = { a n s 0 , a n s 1 , . . . , a n s n } S_{ans} = \{ans_0, ans_1, ..., ans_n\} Sans={ans0,ans1,...,ansn},以及相应的一组理由 S R = { R 0 , R 1 , . . . , R n } S_R = \{R_0, R_1, ..., R_n\} SR={R0,R1,...,Rn},这些理由是每个智能体用来得出其各自答案的。在 Action 过程的第 2 阶段,进行一致性检查。如果智能体给出的某个答案所占比例超过智能体总数的一半,则会触发提前停止机制,并将该答案选为最终答案。如果智能体未能达成共识,将触发 Reflection 机制。
1.2.4 反思(Reflection)
如式 8 所示,论文已经在 Action 过程中获得了答案集 S a n s S_{ans} Sans 和推理集 S R S_R SR。然后,要求每个智能体对其自身以及其他智能体为得出答案所进行的推理过程进行评分,其形式化表示为:
S c o r e ( A i ) = ∑ j = 1 n A j ( Q , S a n s , S R ) ( 7 ) \mathrm{Score}(A_i)=\sum_{j=1}^{n}A_j(Q,S_{\mathrm{ans}},S_R) \quad(7) Score(Ai)=j=1∑nAj(Q,Sans,SR)(7)
论文可以得到一个评分集合 S s c o r e S_{score} Sscore,如图 4 的反思阶段 1 所示。如果某个智能体的推理被认为不充分,它将获得较低分数。 S s c o r e S_{score} Sscore 中的最低分表示该智能体在这个特定长视频问题上的表现不佳。然后,在这个问题的后续讨论中,该智能体将被排除,如图 4 的反思阶段 2 所示。最后,每个剩余的智能体都会独立总结上一轮中所有智能体给出的答案,以及与该问题相关的历史信息。利用这些历史信息,每个智能体随后会重新生成回答该问题所需的关键信息。
K i = A i ( S S c o r e , S R , S a n s ) ( 8 ) K_i = A_i(S_{Score}, S_R, S_{ans}) \quad (8) Ki=Ai(SScore,SR,Sans)(8)
随后,利用这个新生成的关键信息 K i K_i Ki 来启动下一轮检索,从而使模型能够迭代地改进其回答长视频问题的方法。
1.2.5 多轮动态协作(Multi-Round Dynamical Collaboration)
为了更全面地理解长视频,论文引入了一种多轮动态协作流程。MLLM 智能体多轮动态协作的整体步骤如图5所示。图5的上半部分展示了论文多轮讨论的整个过程。在第一轮协作中,三个智能体分别执行感知、行动和反思过程,以相互交互。之后,随后的每一轮协作都包含这三个过程的循环。图5的下半部分给出了每个智能体的具体输出结果。在第一轮和第二轮讨论中,这些模型并未达成统一结果。然而,经过多轮讨论后,这些模型得到了正确结果。
1.2.5 结论(Conclusion)
针对现有单模型方法推理能力不足的局限性,本文介绍了一个面向长视频理解的多智能体协作框架LVAgent。LVAgent通过四个关键步骤实现MLLM智能体之间的多轮动态协作:最佳代理团队的选择,具有有效时间检索的感知,用于问题回答和推理交换的动作,在VideoMME、EgoSchema、MLVU和LongVideoBench上的实验证明了LVAgent的优越性,在LongVideoBench上实现了超过80%的任务准确率和高达13.3%的改进。LVAgent是第一个多轮动态多代理协作管道,其性能优于所有闭源模型(包括GPT-4 o)和开源模型(包括InternVL-2.5和Qwen 2-VL)在长视频理解任务中的应用。这些结果突出了论文的多智能体方法在长视频理解任务中的优势。
1.3 实验(Experiments)
1.3.1 评测基准(Benchmark)
论文在四个长期视频问答基准上评估 LVAgent。
- EgoSchema 由来自 Ego4D 的 5,031 多个人工整理的问答对组成。EgoSchema 要求根据一段三分钟的视频片段为每个问题给出正确答案。
- VideoMME 包含 900 个视频,总时长 254 小时,共有 2,700 个问答对。视频时长范围从 11 秒到 1 小时,平均时长为 1024 秒。
- MLVU 包含 1,730 个视频和 9 个类别中的 2,174 个问题,专门为理解长视频而设计。视频时长在 3 分钟到超过 2 小时之间,平均长度为 930 秒。
- LongVideoBench(LVBench)在验证集划分中包含 1,337 个带有字幕的问答对,主题多样。这些视频涵盖四个逐步递进的时长组:8-15 秒、15-60 秒、3-10 分钟和 15-60 分钟,平均时长为 473 秒。
1.3.2 实施细节(Implication Details)
论文构建的模型库包括 Qwen2-VL7B/72B、LLaVA-Video-72B、LongVU-7B、InternVL-2.5-7B/78B、Oryx 和 Aria。为避免结果中的随机性,在处理时,论文将所有 MLLM 的 temperature coefficient 调整为 0.01,并统一将生成的新 token 最大数量设置为 168,从而防止生成过多冗余信息。对于检索模型,使用 ASP-CLIP 模型,以获得更好的时序上下文建模能力。按照先前的方法,论文使用预训练的 CLIP 来初始化视觉编码器和文本编码器。为构建时序信息,论文采用了一个具有 8 个 attention heads 的四层 temporal transformer。文本编码器和视频编码器的初始学习率均设置为 1e-7,而对于其他参数,则设置为1e-4。论文的ASP-CLIP使用Adam 优化,批量大小为64。模型使用余弦学习率计划训练10个epoch。训练过程和在LVAgent上的实验基于Pytorch,配备8个A800-80G GPU。
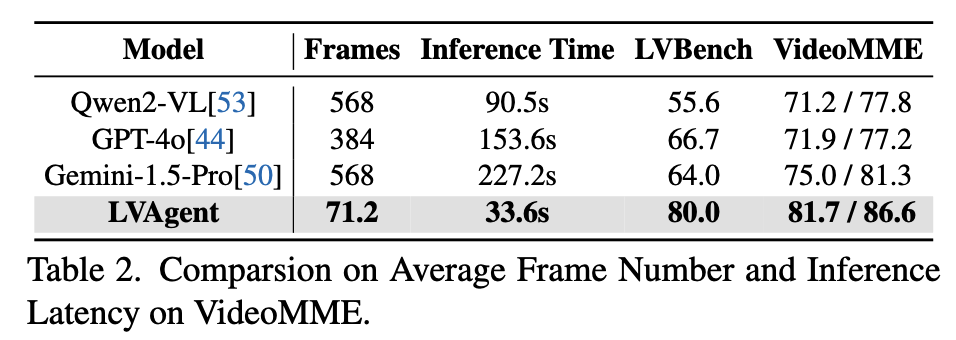
1.3.3 对比实验(Comparison with State-of-the-arts)
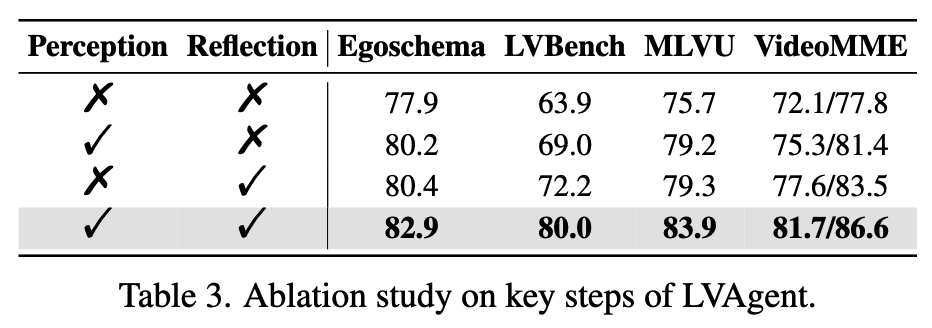
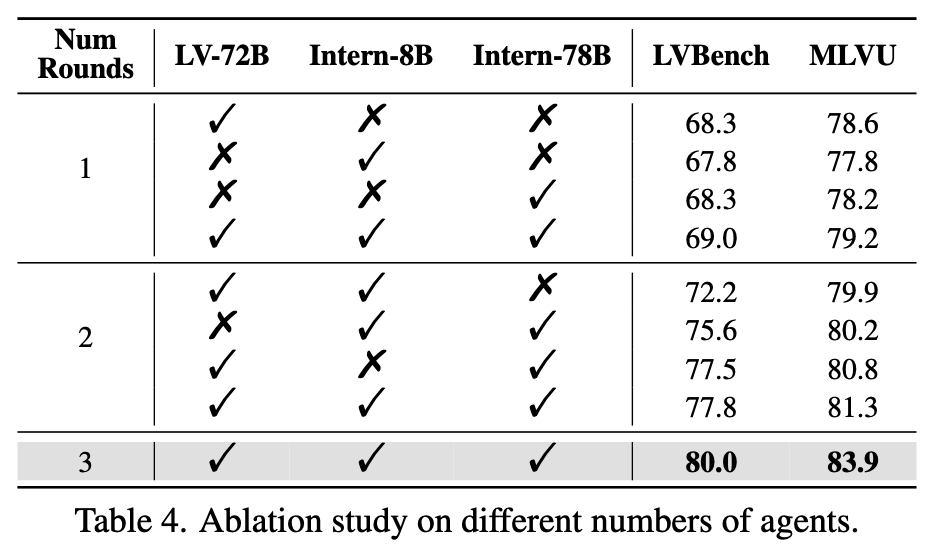
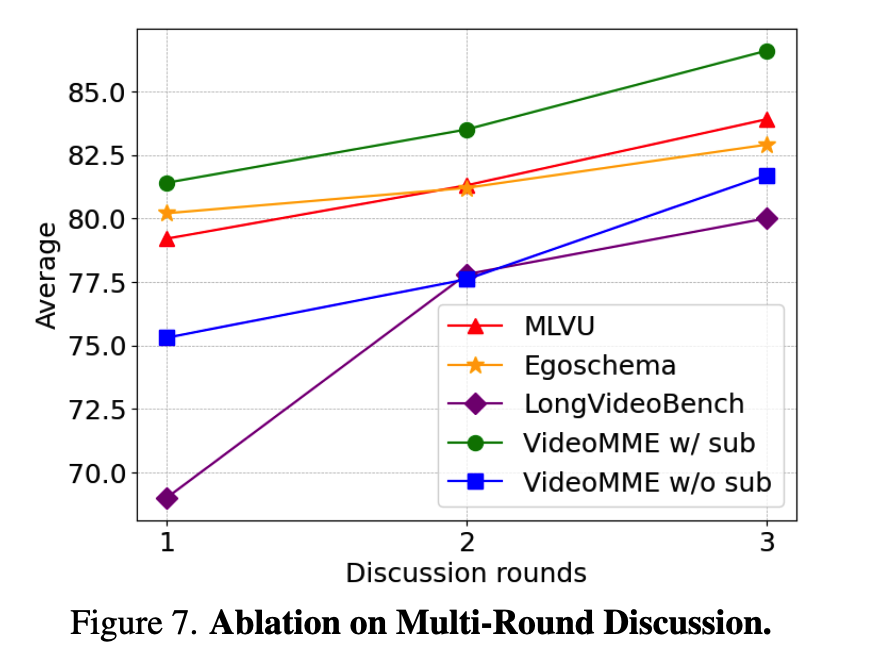
1.3.3 消融实验(Ablation Study)
二、论文理解&总结
三、代码学习
暂时省略,用到再分析。
写在最后
由于笔者🖊️精力有限且本文更多的目的是通过📒博客记录学习过程并分享更多知识,因此文中部分描述不太具体,如有不太理解💫的地方可在评论区👀留言。非特殊赶deadline⏰或假期⛱️期间,笔者会经常上线回复💬。如有不便之处,请海涵~
如果想了解更多关于长视频理解和视频智能体新工作,可以关注笔者的Github仓库:Awesome-Video-Agent。
另外,创造不易,转载请注明出处💗💗💗~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)