Credits 与 Token 到底是什么关系? 一文说清 AI 工具的计费逻辑
为什么你的 AI 积分总是不够用?Token、Credit、上下文窗口一次说清
如果你用过 WorkBuddy、CodeBuddy 这类 AI 工具,大概率被这几个词搞晕过:Token、Credit、上下文窗口、缓存命中……账单上扣的是 Credit,但底层的计价单位是 Token;明明同一个问题问了两次,为什么第二次反而更便宜?对话长了 AI 为什么突然"失忆"?这篇文章用「人话」把这些问题一次讲清楚。
一、Token:AI 世界里的"字"
人类读书按"字",AI 读书按"Token"
我们人类读一篇文章,眼睛扫过去是一个个汉字、一个个单词。但对大模型来说,它根本不认识"字"——它只能处理数字。所以文本在喂给模型之前,必须先做一件事:分词(Tokenization),把人类语言切成一个个小块,每个小块就是一个 Token。

不同语言的分词规则完全不同:
| 语言 | 分词规则 | 换算比例 |
|---|---|---|
| 中文 | 大多以单个汉字为单位拆分,少数高频词组(“人工智能”“了解”)合并为一个 Token | 1 个汉字 ≈ 1 Token |
| 英文 | 以单词、词根、词缀为单位拆分 | 1 Token ≈ 0.75 个英文单词 |
| 代码 | 按运算符、关键字、标识符拆分 | 1 Token ≈ 2-5 个字符 |
| emoji / 标点 | 单独计为 1 个 Token | 🔥 = 1 Token |
2026 年 3 月,国家数据局正式将 Token 的标准中文译名确定为 “词元”。
Token 是 AI 的"通用货币"
所有大模型服务都按 Token 计价,采用「输入+输出」分离计费模式。一次完整的交互包含两部分:
- 输入 Token:你发给 AI 的所有内容(提问 + 历史对话上下文 + 系统提示词)。输入 Token 的计费相对便宜,因为模型只需要"看懂"这段文本。
- 输出 Token:AI 逐字逐句回复你的所有内容。输出 Token 的计费更贵,因为模型需要逐个生成每个 Token——背后是一次完整的神经网络前向计算。
输出通常比输入贵 2-4 倍。这不是厂商随便定价,而是硬件的物理规律决定的:生成一个 Token 需要模型从头算到尾,而"阅读"一个 Token 可以利用并行计算一次搞定很多个。打个比方——你读一篇文章可以扫读、跳读,不怎么费劲;但让你自己写一篇,得一个字一个字敲,每个字都要动脑。模型也一样。
以 2026 年主流模型的公开定价为例:
| 模型 | 输入单价(每百万 Token) | 输出单价(每百万 Token) | 输出/输入倍数 |
|---|---|---|---|
| 通义千问 Turbo | 0.14 元 | 0.14 元 | 1 倍(特例,输入输出同价) |
| DeepSeek-V4-Flash | 1 元 | 2 元 | 2 倍 |
| GPT-5 Mini | 0.81 元 | 3.24 元 | 4 倍 |
| Claude Opus 4 | 32.4 元 | 108 元 | 3.3 倍 |
这意味着什么? 如果你让 AI 写一篇 1000 字的文章(约 1000 输出 Token),用 GPT-5 Mini 的成本约 0.003 元;但如果你的输入(提问+贴的参考文档)本身就 5000 Token,加上 1000 输出 Token,总成本是输入成本的 4 倍——输入越臃肿,总成本越高。所以精简提问、清理无关上下文能实打实地省钱。
长对话的"回头税":为什么聊得越久越贵?
这里有一个很容易被忽略的事实:大模型每一次请求都是"无状态"的——它不记得上一轮说了什么。 为了让你感觉它在"连续对话",系统会把整个历史对话重新打包塞进下一轮请求,让模型从头再读一遍:
第 1 轮输入:系统提示词 + 你的提问①
第 2 轮输入:系统提示词 + 你的提问① + AI回复① + 你的提问②
第 3 轮输入:系统提示词 + ①的完整对话 + ②的完整对话 + 你的提问③
这就是 Token 消耗的滚雪球效应。假设每轮新增 1K Token(提问 0.5K + 回复 0.5K),用 128K 上下文窗口:
| 轮次 | 输入 Token(塞了多少历史) | 输出 Token | 本轮合计 |
|---|---|---|---|
| 第 1 轮 | 0.5K | 0.5K | 1K |
| 第 2 轮 | 1.5K(含第1轮全部) | 0.5K | 2K |
| 第 3 轮 | 2.5K(含前2轮全部) | 0.5K | 3K |
| 第 10 轮 | 9.5K | 0.5K | 10K |
| 第 50 轮 | 49.5K | 0.5K | 50K |
| 第 128 轮 | 127.5K | 0.5K | 128K |
注意:第 50 轮和第一轮问的内容可能毫无关系——但前 49 轮的所有对话照样原封不动塞进去。系统不判断相关性,它只是机械地把窗口里的一切搬过去。
不过大可放心——上述是极端场景。日常几百字的问答聊天,几十轮下来累计 Token 也就一两毛钱、折合不到 1 个 Credit。只要你不是一个窗口从早挂到晚、每轮都在贴大文件,聊天的 Token 账单增长很慢的;
以DeepSeek-V4 公开 API 定价为例:输入 1 元/百万 Token,输出 2 元/百万 Token。
WorkBuddy 专业版 58 元 = 2000 Credits,也就是 1 Credit 的"成本价"约 0.029 元。
粗略计算:1 Credit ≈ 2 万 Token(DeepSeek-V4 对话场景)。
但这只是"API 原价倒推"的理论值。WorkBuddy 后台有平台溢价、多模型混用、推理加成等变量,实际可能在这个数量级的附近波动。日常聊天一次几百 Token,一个 Credit 能撑几十轮,不用担心。
二、上下文窗口:AI 的"短期记忆"
什么是上下文窗口?
在你和 AI 的每一次对话中,AI 并不是"读完就忘、只回答最后一句话"——它会把你之前说的所有内容(包括它自己的回复)都打包放在一个叫"上下文窗口"的地方。这个窗口能放的内容总量是有限的,就是"上下文长度限制"。
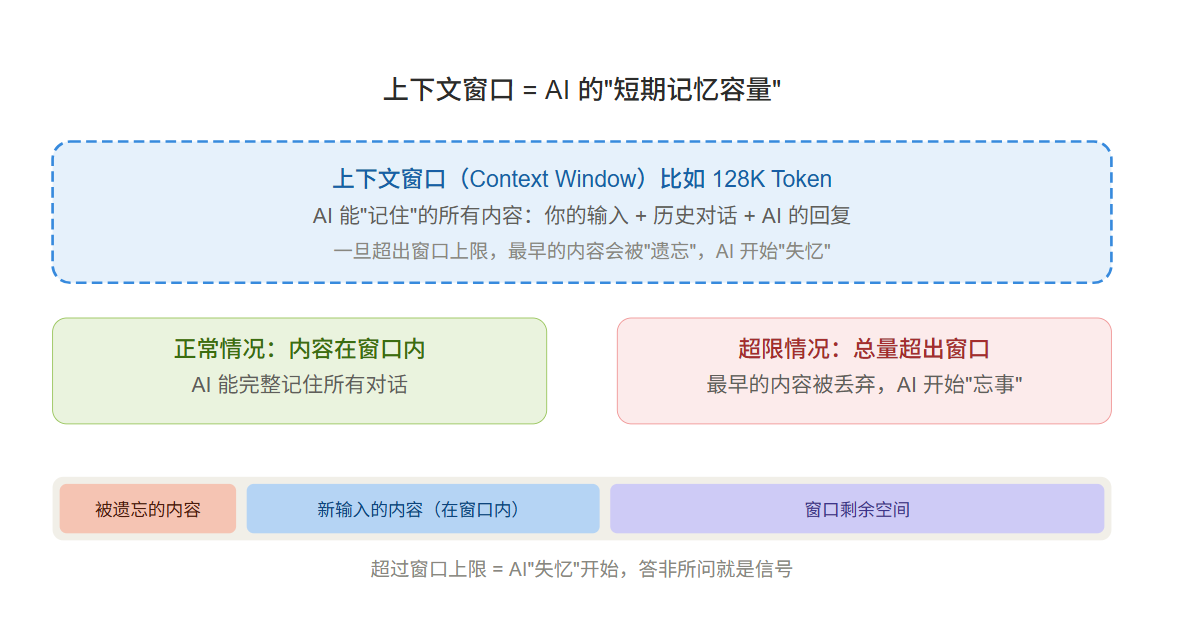
打个比方:上下文窗口就像 AI 面前的"临时便签纸"。每轮对话都会往这张纸上写字,纸写完就不能再加了——AI 会自动擦掉最上面的内容,给新内容腾地方。所以当对话变得特别长时,你会发现 AI 开始"忘事"——那是因为最早的内容已经被擦掉了。
各大模型的上下文窗口有多大?
| Token 上限 | 约等于汉字数 | 能做什么 |
|---|---|---|
| 4K Token | 约 3,000 汉字 | 短对话、简单问答 |
| 32K Token | 约 2.4 万汉字 | 长文档总结、代码分析 |
| 128K Token | 约 10 万汉字 | 一次性处理长篇小说,复杂多轮对话 |
| 1M Token | 约 70-80 万汉字 | 超长篇文档与大规模知识库检索 |
WorkBuddy 中如果你发现 AI 突然"答非所问"“忘记前面说过的话”——这就是上下文窗口溢出的信号。 此时应该开新对话,而不是继续在当前对话里追问。
为什么上下文窗口不能无限大?
核心原因是 注意力机制(Attention Mechanism)的计算复杂度为 O(n²)。
这句话用人话翻译就是:模型在处理文本时,需要计算每两个 Token 之间的"关联度"——第 1 个 Token 和第 2 个、第 3 个……一直到第 n 个,全都要两两配对算一遍。所以如果有 n 个 Token,就要做 n × n = n² 次计算。如果 Token 数量翻倍,计算量不是翻倍,而是翻 4 倍;翻 10 倍,计算量翻 100 倍。
具体地看:
| Token 数 | 需要计算的"关联对"数量 | 相比 4K 的倍数 |
|---|---|---|
| 4K (4,096) | ~1,678 万对 | 基准 |
| 32K | ~10.7 亿对 | 64 倍 |
| 128K | ~16,384 亿对 | 1,024 倍 |
| 1M | ~10,000 亿对 | 62,500 倍 |
这就是为什么越大的上下文窗口,一次对话消耗的 Credits 越多:不仅 Token 数量在涨(线性),单个 Token 的处理成本也在暴涨(平方级)。 128K 窗口不是 4K 窗口的"32 倍成本",而是接近"1000 倍"。这也解释了为什么现在所有大模型都在拼命优化注意力机制(FlashAttention、稀疏注意力等)——不是为了让窗口变大,而是为了让大窗口用得起。
三、缓存机制:为什么同一个问题问第二遍更便宜?
这是本次最有意思的知识点。先看一个场景:
你上传了一份 5000 字的合同让 AI 分析,问:“帮我总结关键条款”。AI 读完合同、给出总结,消耗了约 8000 Token。
紧接着你又问:"第三个条款有没有风险?"AI 这次没有从头读合同——因为它已经把合同的处理结果"缓存"起来了,直接复用。
这就是缓存机制的核心:同样的内容不重复计算,省时间又省钱。
缓存命中 vs 缓存未命中

当我们说"缓存"时,指的是 KV 缓存(KV Cache):模型在处理文本时,会为每个 Token 生成 K(Key)和 V(Value)两组向量数据。这些数据占显存,但未来如果遇到相同的前缀内容,可以直接复用而不用重新计算。
| 状态 | 含义 | 计费(显式缓存) | 计费(隐式缓存) |
|---|---|---|---|
| 缓存命中 | 请求的文本前缀与已有缓存匹配 | 标准价的 10% | 标准价的约 20% |
| 缓存未命中 | 文本前缀无匹配,需新建缓存 | 标准价的 125% | 标准价的 100% |
一句话理解:第一次问按全价(甚至多收 25% 建缓存费),第二次问同样的前缀按 1 折,比第一次便宜 10 倍以上。
翻词典的比喻
这就像翻词典:第一次查一个生词,你要翻开目录,找到页码,翻到那一页,读解释——这是"缓存未命中"(全价 + 建缓存成本)。如果你马上又查同一个词,手指还夹在那一页——这是"缓存命中"(1 折),因为你没有重新走全套流程。
缓存的几个关键规则
- 有效期 5 分钟(显式缓存):命中后重置,5 分钟没人用就过期
- 最少 1024 Token 才能触发显式缓存;最少 256 Token 触发隐式缓存
- 前缀必须一致:缓存只匹配"开头相同的部分",如果改动了系统提示词的第一句话,整个缓存就失效了
- 账号间隔离:你的缓存只有你自己能用,不会跟别人共享
这个对 WorkBuddy 用户意味着什么?
- 多轮对话天然省钱:你在同一对话里连续追问,AI 缓存了之前的内容,后续请求的输入 Token 命中率高得多
- 复制粘贴后追问也是省钱的:你贴了一份长文档让 AI 分析,再追问几次,第二次开始自动命中
- 不要随便改动前几句话:如果每次提问都先换系统提示词,缓存就白建了
四、Credit:套在 Token 外面的"壳"
为什么要多这一层?
如果 WorkBuddy 直接按 Token 计价,会出现一个问题:同样是 1000 Token,用便宜模型只要几分钱,用高端模型可能要几毛钱。 作为用户,每次都要算"我用的是什么模型、这个模型多少钱、我这次对话花了多少 Token"——太累了。
所以 WorkBuddy 引入了一层封装:Credit(积分)。它把所有模型的差异打包进去,用户只需要看一个数字。
两条完全不同的计费路径
这里是最容易混淆的地方:WorkBuddy 内部其实有两条完全不同的计费路径,换算比例天差地别。
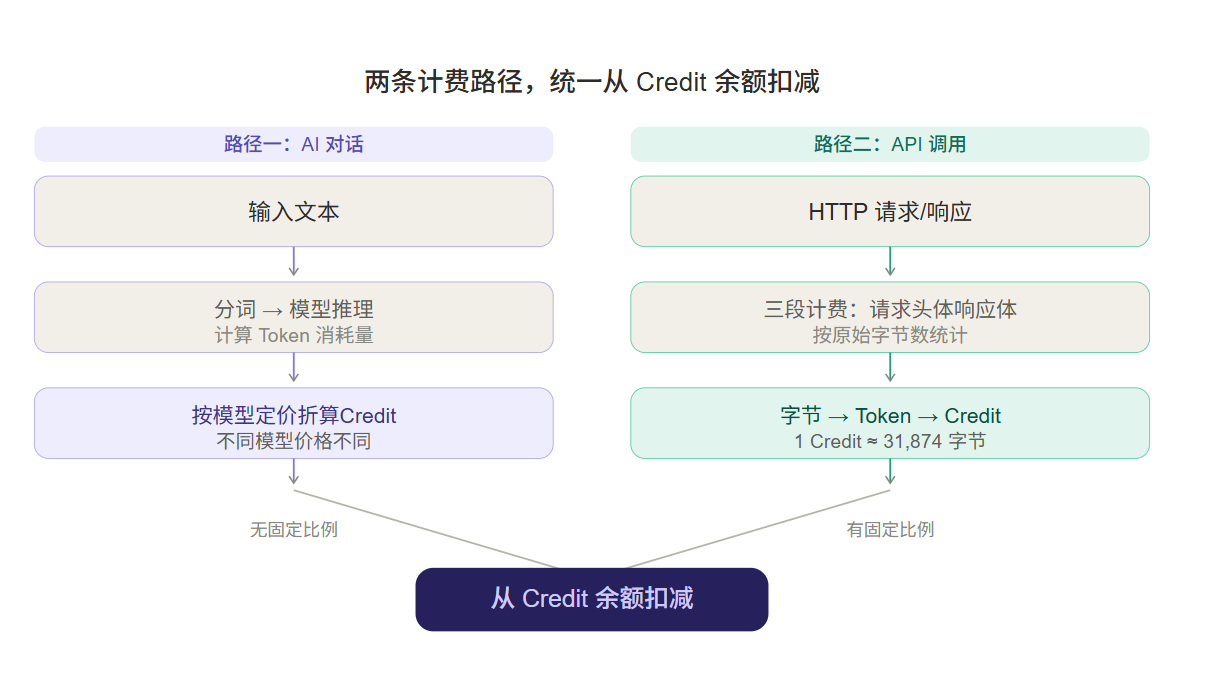
路径一:AI 对话 —— 因模型而异,没有固定比例
这是你日常使用的场景:和 AI 聊天、让它写代码、分析文档。
同一个问题用不同模型问,同样的 Token 数,Credit 消耗完全不同:
| 场景 | 使用模型 | Token 消耗 | Credit 消耗(估算) |
|---|---|---|---|
| 问"今天星期几" | DeepSeek-V4-Flash(轻量) | ~50 Token | ~0.02 Credit |
| 问同一个问题 | GLM-5.0-turbo(强力) | ~50 Token | ~0.5 Credit |
| 分析一篇 3000 字长文 | DeepSeek-V4-Flash | ~8,000 Token | ~2 Credit |
| 分析同一篇长文 | Claude(推理增强) | ~8,000 Token | ~10 Credit |
结论:对话场景里,没有 “1 Credit = 多少 Token” 的固定答案。 官方文档原文也说:“具体消耗数量因任务复杂度及所用高级模型而异。”
路径二:API 连接器调用 —— 按字节折算,有固定比例
这是你在 WorkBuddy 里调用飞书、GitHub、企业微信等外部接口时的场景。这里的计费逻辑完全不同——不算模型、不算推理,纯按 HTTP 请求/响应的字节数来算。
API 调用的"三段计费模型":
| 组成部分 | 计费方式 |
|---|---|
| 请求头 + URL + 查询参数 | 按字符数折算为 Token |
| 请求体(Body) | 按 UTF-8 原始字节数折算 |
| 响应体(Response Body) | 按原始字节数全额计入(无论你是否用到) |
三步相加 → 折算为 Token → 再折算为 Credit:
1 Credit ≈ 31,874 字节
一个具体例子:
| 操作 | 数据量 | Token 消耗 | Credit 消耗 |
|---|---|---|---|
| 发一条飞书消息(URL + 请求体 + 响应 ≈ 232 字节) | ~232 字节 | ~232 Token | < 0.01 Credit |
| 调用一个返回 1MB JSON 的内部 API | ~1,048,576 字节 | ~100 万 Token | 30+ Credits |
同样的 Credit,在对话场景可能聊好几轮,在 API 场景可能一个重响应就没了。 这也是为什么很多人觉得 Credits 跑得莫名其妙快——很可能是因为工作流里某个连接器返回了大量不必要的数据。
五、一张图看清完整模型

回到最核心的问题:为什么 WorkBuddy 不直接说 “1 Credit = X Token” ?
因为给了反而误导。真实原因是:
Credit 消耗 = 模型单价 × 任务复杂度 × Token 数量
↑ ↑ ↑
可选的 变化的 可衡量的
Token 是唯一的确定量,另外两个变量在每次对话中都可能不同。 再加上上下文窗口越用越满、缓存有时命中有时不命中——实际消耗是一个动态的、多变量叠加的结果。所以任何固定比例都只能是参考值。
六、实际使用参考
与其纠结换算公式,不如看实际效果。以下是社区实测的大致参考:
| Token 消耗量 | 典型场景 | Credit 消耗(DeepSeek-V4) |
|---|---|---|
| ~50 Token | 轻量对话(问路、问天气) | ~0.02 Credit |
| ~1,000 Token | 中等任务(写函数、改 Bug) | ~0.5-2 Credit |
| ~8,000 Token | 长文档分析(3000 字文章) | ~3-10 Credit |
| ~50,000 Token | 大型项目(重构模块 + 多轮对话) | ~20-60 Credit |
关于缓存的实际效果:如果你在同一对话里连续追问同一个长文档,第二问开始的 Token 大多数会命中缓存,实际 Credit 消耗只有第一问的 10%-20%。这也是为什么"多轮追问"比"每次开新对话然后贴文档"更省钱。
七、六个省钱的实用技巧
对话场景
- 经常开新对话:历史对话越长,每次请求的输入 Token 越多。长对话不会因为缓存而完全免费——缓存的只是 KV 数据(算力成本),Token 本身的计价依然存在。
- 轻量模型先试、强力模型再求精:用 DeepSeek-V4-Flash 先跑思路,确认没问题了再用高端模型优化输出。
- 开启推理(Thinking)会显著增加 Token 消耗:能用普通模式搞定的就别开推理。
API 调用场景
- 精简请求体:删掉
"timestamp"、"debug": true这种无关字段。 - 限制响应大小:在连接器里勾选「仅提取指定路径」,手动填入
$.data——避免加载整棵 JSON 树。 - 关掉不必要的「失败重试」:一次失败 × 3 次重试 = 3 倍费用,而且错误响应(如 500 页面的 HTML)往往比正常响应更大。
八、一句话总结
| 概念 | 一句话 |
|---|---|
| Token | AI 世界里的"字",1000 汉字 ≈ 1000 Token,输入和输出分开计价 |
| 上下文窗口 | AI 的"临时便签纸",写满了最早的内容就会被擦掉,越大越贵(O(n²)) |
| 缓存命中 | 同样的内容第二遍只收 1 折,因为读缓存不重算 |
| 缓存未命中 | 初次计算要加收 25% 建缓存费,但下次就便宜了 |
| Credit | WorkBuddy 套在所有概念外面的统一消费单位,你不需要关注底层怎么算 |
| 二者的关系 | 对话无固定比例,API 有固定比例。记住:轻量模型省钱、短上下文省钱、缓存命中更省钱 |
版权声明:本文中关于 Credits 与 Token 的相关数据来自腾讯云 CodeBuddy 官方文档、阿里云百炼平台 Context Cache 技术文档、PHP中文网技术分析及社区实测,仅供参考,不代表官方换算标准。不同模型、不同版本的实际消耗比例可能存在差异。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)