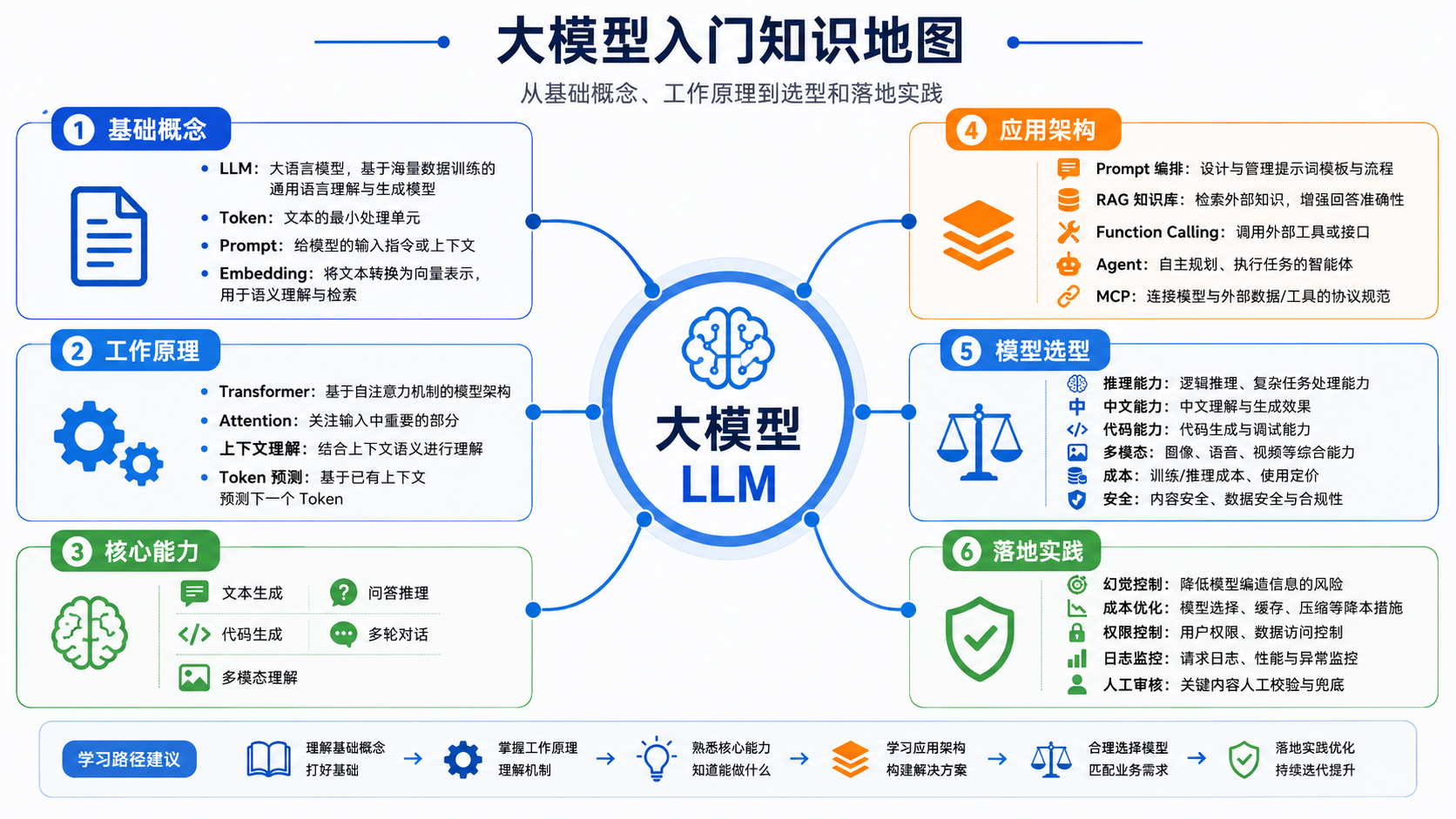
大模型的介绍
一文看懂大模型:从基础概念、工作原理到选型和落地实践
前言
过去两年,大模型从“技术热点”逐渐变成了企业应用、智能客服、办公自动化、代码助手、数据分析等场景里的基础能力。很多人听过 ChatGPT、DeepSeek、通义千问、Claude、Gemini,但真正要把大模型用起来时,往往会遇到几个问题:
- 大模型到底是什么?
- 它为什么能理解和生成文本?
- RAG、Agent、Function Calling、MCP 这些概念分别解决什么问题?
- 企业开发时应该怎么选模型?
- 落地大模型应用时要注意哪些坑?
这篇文章尽量用通俗的方式,把大模型从基础概念、工作原理、核心技术到落地实践梳理一遍。
一、大模型是什么?
大模型通常指参数规模巨大、训练数据规模巨大、具备较强泛化能力的人工智能模型。现在大家常说的大模型,多数是指大语言模型,也就是 LLM,Large Language Model。
简单理解,大模型不是传统意义上的“问答数据库”,它并不是提前存好所有答案,然后根据关键词查出来,而是通过大量文本训练,学会语言之间的规律、上下文关系和知识表达方式,从而根据用户输入生成合理的回复。
例如用户问:
帮我写一段 Java 后端面试自我介绍。
大模型并不是查找某个固定模板,而是会结合“Java 后端”“面试”“自我介绍”这些上下文,生成一段符合语境的文本。
大模型常见能力包括:
- 文本生成:写文章、写邮件、写总结。
- 信息抽取:从合同、简历、公告中提取字段。
- 问答推理:根据上下文回答问题。
- 代码生成:生成代码、解释代码、修复 bug。
- 多轮对话:保持上下文连续交流。
- 多模态理解:部分模型可以理解图片、音频、视频等内容。
二、大模型为什么“看起来会思考”?
大模型的核心机制可以粗略理解为:根据上下文预测下一个最可能出现的 Token。
Token 可以是一个字、一个词,也可以是词的一部分。模型接收到用户输入后,会把文本切分成 Token,再通过神经网络计算每个 Token 与上下文之间的关系,最终不断生成后续 Token,组成完整回答。
这听起来像“文字接龙”,但由于训练数据规模巨大,模型学习到的不只是词语搭配,还包括大量知识、表达方式、推理模式和代码结构,所以表现出来就像具备理解和推理能力。
大模型能力的基础主要来自三个方面:
1. 海量训练数据
模型需要阅读大量文本,例如网页、书籍、代码、文档、论文等,从中学习语言规律和知识分布。
2. Transformer 架构
Transformer 是当前大语言模型的核心架构。它的关键机制是 Attention,也就是注意力机制。
注意力机制可以让模型在处理一句话时,判断哪些词和当前内容关系更强。
例如:
小明把书放进书包,因为它太重了。
这里的“它”大概率指“书”,模型需要根据上下文判断指代关系。
3. 大规模参数
参数可以理解为模型内部学习到的“知识权重”。参数规模越大,模型表达复杂规律的能力通常越强,但成本也更高,并不意味着所有场景都必须用最大模型。
三、大模型的基本工作流程
一个典型的大模型调用流程大致如下:
- 用户输入 Prompt。
- 系统将文本切分为 Token。
- 模型结合上下文进行推理。
- 模型逐步生成输出 Token。
- 应用层对结果进行展示、过滤或后处理。
在实际业务系统中,大模型通常不会单独存在,而是和数据库、搜索系统、知识库、工具接口一起工作。
例如一个企业知识库问答系统,流程一般是:
- 用户提问。
- 系统先从知识库中检索相关文档。
- 把检索结果和用户问题一起交给大模型。
- 大模型基于资料生成回答。
- 返回结果,并附带引用来源。
这类模式就是常见的 RAG。
四、几个核心概念
1. Prompt:提示词
Prompt 是用户给模型的输入,也是控制模型输出效果的重要方式。
一个简单 Prompt:
介绍一下大模型。
一个更好的 Prompt:
请用 Java 后端开发者能理解的方式,介绍大模型的基本概念、工作原理和企业应用场景,要求结构清晰,语言通俗。
Prompt 的关键不是越长越好,而是要明确:
- 角色:让模型以什么身份回答。
- 任务:要完成什么事情。
- 背景:有什么业务上下文。
- 约束:输出格式、字数、风格。
- 示例:必要时给出参考样例。
2. RAG:检索增强生成
RAG,全称 Retrieval-Augmented Generation,检索增强生成。
它解决的问题是:大模型本身不一定知道企业内部知识,也可能产生幻觉,所以在回答前先从知识库中检索相关内容,再让模型基于检索结果回答。
典型流程:
- 文档切分。
- 向量化存储。
- 用户问题向量化。
- 相似度检索。
- 拼接上下文。
- 大模型生成答案。
RAG 适合以下场景:
- 企业知识库问答。
- 产品文档助手。
- 法务、合同、制度查询。
- 客服问答。
- 内部运维手册查询。
RAG 的重点不是“把文档丢给模型”,而是如何做好文档切分、召回、排序、上下文压缩和答案可信度控制。
3. Function Calling:函数调用
Function Calling 可以让大模型不只是回答文本,还能调用外部工具。
比如用户说:
帮我查一下订单 10086 的物流状态。
模型本身不知道订单状态,但它可以识别用户意图,然后调用后端接口:
{
"name": "query_order",
"arguments": {
"orderId": "10086"
}
}后端拿到参数后查询数据库或第三方系统,再把结果交给模型组织语言返回。
Function Calling 解决的是“大模型连接业务系统”的问题,常见于:
- 查询订单。
- 创建工单。
- 调用支付接口。
- 查询库存。
- 执行业务审批。
- 调用搜索、计算、数据库工具。
4. Agent:智能体
Agent 可以理解为具备“任务规划 + 工具调用 + 多轮执行”能力的大模型应用。
普通问答是用户问一句,模型答一句。
Agent 更像是:
- 理解目标。
- 拆解任务。
- 选择工具。
- 调用工具。
- 观察结果。
- 继续下一步。
- 最终完成任务。
例如用户说:
帮我分析这个项目的代码结构,并生成一份技术说明文档。
Agent 可能会自动读取文件、分析目录、总结模块、生成文档,而不是只给一个泛泛的回答。
Agent 适合复杂任务,但也更需要控制边界,比如权限、工具调用次数、失败重试、日志审计和人工确认。
5. MCP:模型上下文协议
MCP,Model Context Protocol,可以理解为一种让大模型应用统一连接外部工具和数据源的协议。
过去每接一个系统,都要单独写适配逻辑。MCP 的思路是把工具、资源、上下文暴露成标准化能力,让模型应用更容易接入不同外部系统。
简单理解:
- Function Calling 更偏“模型调用某个函数”。
- MCP 更偏“统一管理和暴露工具、资源、上下文”。
它适合用于连接代码仓库、数据库、浏览器、文件系统、企业系统等外部能力。
五、主流模型怎么选?
选择大模型时,不应该只看“哪个最强”,而是要看业务场景。
常见模型包括 OpenAI GPT 系列、Anthropic Claude、Google Gemini、DeepSeek、通义千问 Qwen、Kimi 等。不同模型在推理、长上下文、代码、多模态、中文能力、成本和私有化支持上各有侧重。
可以从以下几个维度判断:
1. 通用问答和复杂推理
如果场景需要较强推理能力,比如复杂问答、方案设计、代码分析,可以优先选择推理能力更强的模型。
关注点:
- 推理质量。
- 幻觉控制。
- 长文本理解。
- 工具调用能力。
- 输出稳定性。
2. 中文业务场景
如果主要面向中文用户,比如客服、运营、企业知识库,需要重点看中文表达、中文文档理解和本土化知识能力。
关注点:
- 中文语义理解。
- 中文长文档处理。
- 对业务术语的适配能力。
- 成本和并发能力。
3. 代码开发场景
如果是代码助手、代码解释、单元测试生成、代码迁移,要重点关注代码能力。
关注点:
- 是否支持多语言代码。
- 是否能理解项目上下文。
- 是否支持长上下文。
- 生成代码是否稳定。
- 是否容易接入 IDE 或研发流程。
4. 多模态场景
如果要处理图片、票据、截图、视频、语音,就要选择支持多模态输入的模型。
关注点:
- 图片理解能力。
- OCR 能力。
- 图表理解能力。
- 视频或音频支持。
- 输出结构化结果的稳定性。
5. 企业落地场景
企业落地还要考虑工程因素:
- API 稳定性。
- 成本预算。
- 响应速度。
- 并发限制。
- 数据安全。
- 私有化或本地部署需求。
- 日志审计和权限控制。
一个比较实用的选型原则是:
先用强模型验证业务效果,再根据成本、速度和稳定性选择合适模型做生产落地。
六、大模型应用开发的常见架构
一个较完整的大模型应用通常包括以下部分:
用户入口
↓
业务后端
↓
Prompt 编排 / Agent 编排
↓
模型服务
↓
知识库 / 数据库 / 工具接口
↓
结果后处理 / 权限控制 / 日志审计其中比较关键的是:
1. Prompt 管理
不同业务场景要有不同 Prompt,比如客服问答、合同总结、代码解释、数据分析,不能所有功能都共用一个模板。
2. 知识库建设
知识库质量直接影响 RAG 效果。文档切分太碎,容易丢上下文;切分太大,又会影响召回精度和 Token 成本。
3. 工具调用控制
模型调用工具时必须有边界,尤其是涉及订单、支付、审批、删除数据等高风险操作时,应该增加权限校验和人工确认。
4. 结果校验
大模型输出不应该完全裸奔。重要场景需要做格式校验、敏感词过滤、事实核验、引用来源展示。
5. 监控与评估
需要记录模型调用耗时、Token 消耗、失败率、命中率、用户反馈等指标,用来持续优化。
七、大模型落地常见问题
1. 幻觉问题
大模型可能生成看似合理但实际错误的内容。
解决方式:
- 使用 RAG 提供可靠上下文。
- 要求模型基于资料回答。
- 对关键结论增加引用。
- 对高风险结果加入人工审核。
2. 成本问题
大模型调用通常按 Token 计费,长文本、多轮对话、高并发都会增加成本。
优化方式:
- 控制上下文长度。
- 做文档摘要和压缩。
- 使用缓存。
- 简单任务用小模型,复杂任务用强模型。
- 对高频问题做标准答案缓存。
3. 响应速度问题
模型生成需要时间,复杂推理和长上下文会更慢。
优化方式:
- 使用流式输出。
- 拆分任务。
- 减少无效上下文。
- 对常见问题预计算。
- 合理选择模型。
4. 数据安全问题
企业场景中,用户数据、客户资料、内部文档不能随意暴露。
解决方式:
- 控制上传内容。
- 做敏感信息脱敏。
- 做权限隔离。
- 保留调用日志。
- 优先选择符合合规要求的服务或私有化方案。
八、开发者应该怎么学习大模型?
如果是后端开发者,可以按下面路线学习:
- 先理解 LLM、Token、Prompt、Embedding、RAG 等基础概念。
- 学会调用一个模型 API,完成简单对话。
- 做一个基于本地文档的知识库问答。
- 加入 Function Calling,让模型能调用业务接口。
- 尝试 Agent,让模型完成多步骤任务。
- 学习评估、监控、成本优化和安全控制。
- 最后结合真实业务做一个可落地的小项目。
不要一开始就纠结模型训练。对于大多数应用开发者来说,先把“大模型怎么接入业务系统、怎么稳定回答、怎么控制成本和风险”搞清楚,更有实际价值。
总结
大模型不是简单的聊天机器人,而是一种可以理解上下文、生成内容、调用工具、辅助决策的基础能力。
它的核心价值不在于“会聊天”,而在于可以和企业知识库、业务系统、办公流程、研发工具结合,提升信息处理和自动化效率。
入门大模型,可以先抓住这条主线:
基础模型负责理解和生成,RAG 负责补充企业知识,Function Calling 负责连接业务系统,Agent 负责完成复杂任务,工程体系负责稳定、安全、低成本地落地。
真正的大模型应用,不只是调一个 API,而是把模型能力放进真实业务流程里,让它解决具体问题。
参考资料
- OpenAI Models 官方文档:https://platform.openai.com/docs/models
- Anthropic Claude Models 官方文档:https://docs.anthropic.com/en/docs/about-claude/models
- Google Gemini Models 官方文档:https://ai.google.dev/gemini-api/docs/models
- DeepSeek API 官方文档:Your First API Call | DeepSeek API Docs
- Alibaba Cloud Model Studio 模型文档:Supported Models and Capabilities Overview - Model Studio - Alibaba Cloud - Alibaba Cloud Model Studio - Alibaba Cloud Documentation Center

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)