Codex 开始接入数据分析工具后,开发者别只盯着自动写 SQL
一、热点发生了什么:Codex 不再只是写代码,开始进入数据分析工作流
最近 OpenAI 发布了 Codex for every role, tool, and workflow,其中很值得开发者关注的一点是:Codex 不再只围绕代码生成和开发任务,而是开始通过插件进入更具体的业务工作流。
其中数据分析插件尤其值得看。官方说明里提到,这类插件可以帮助分析师和业务团队回答数据问题、探索产品和业务数据、解释关键指标为什么变化,并创建报告和 dashboard。它还能连接 Snowflake、Databricks Genie、Hex、Tableau 等数据和 BI 工具。
这说明一个趋势:AI 正在从“帮开发者写 SQL”升级为“帮业务团队完成一次数据分析任务”。
但这里面最容易被忽略的是,数据分析不是简单生成一条 SQL。一个真实的数据分析流程通常包含:明确业务问题、确认指标口径、判断数据权限、找到对应表和字段、生成查询、检查 SQL 安全、执行查询、解释结果、生成图表或报告、保留可追溯记录。
如果开发者只盯着“AI 能不能写 SQL”,很容易低估风险。
因为自然语言查数看起来很方便,但一旦接入真实数据库,问题就变成了工程问题:权限怎么管?口径怎么统一?SQL 怎么限制?结果怎么校验?查询成本怎么控制?用户看到的解释怎么避免胡说?
这篇文章就围绕这个问题展开:如果要设计一个可控的 AI 数据分析助手,开发者应该怎么拆流程、设边界、写 Prompt、做校验?
二、为什么开发者要关心:自然语言查数会改变数据平台入口
过去数据分析系统通常有几个入口:数据分析师写 SQL,业务人员看 BI dashboard,产品或运营提交取数需求,开发者维护指标平台,管理层看固定报表。
AI 数据分析助手出现后,入口会变成一句自然语言:
帮我看一下上周新用户留存为什么下降。
这句话对业务人员来说很自然。但对系统来说,它至少涉及五个技术问题:“新用户”口径是什么;“留存”是次日留存、7 日留存,还是周留存;“上周”按自然周还是最近 7 天;数据来自哪张表;用户有没有权限看这类数据。
如果 AI 直接生成 SQL 并执行,风险很大。它可能把“新用户”理解成注册用户,也可能理解成首次下单用户;可能把“留存下降”归因到渠道质量,也可能忽略节假日、版本发布、埋点缺失、样本量变化等因素。
AI 数据分析助手是一个带权限、口径、查询、校验和解释约束的数据工作流系统。
三、最容易被误解的地方:SQL 能跑,不等于分析可信
很多人试用 AI 查数时,会先看模型能不能生成 SQL。能生成,很惊喜;能跑通,更惊喜;还能生成图表,就觉得可以上线了。
但数据分析里最危险的问题,往往不是 SQL 语法错误,而是结果看起来很合理,但口径是错的。
业务问:
昨天付费转化率为什么下降?
AI 可能生成:
SELECT
COUNT(DISTINCT paid_user_id) * 1.0 / COUNT(DISTINCT user_id) AS pay_conversion_rate
FROM user_events
WHERE event_date = CURRENT_DATE - INTERVAL '1 day';
这条 SQL 可能能跑,但问题很多:paid_user_id 是否存在;user_id 是否代表访问用户、注册用户还是活跃用户;付费事件是否应该从订单表取;是否要排除退款订单;是否要区分新用户和老用户;是否要按渠道拆分;是否要对比前 7 天均值,而不是只看前一天;是否存在埋点延迟。
数据分析助手的关键不在于“把 SQL 写出来”,而在于它有没有能力先澄清问题、对齐口径、检查字段、说明假设。
四、真实使用场景:运营想查“新手引导完成率下降”的原因
假设一个 SaaS 产品团队里,运营同学发现最近新用户激活变差,想问 AI:
最近新手引导完成率是不是下降了?如果下降,帮我分析原因。
这个问题看起来很适合 AI,但不能直接查。因为它至少需要先确认几个点:“最近”是最近 7 天、14 天还是自然周;“新用户”是注册用户还是首次进入工作台的用户;“新手引导完成”对应哪个事件;是否按渠道、版本、设备、地区拆分;是否有埋点变更;是否需要排除测试账号;是否有权限查看用户行为明细。
更合理的流程是:AI 先把业务问题拆成指标定义;系统从指标字典中匹配可用口径;AI 生成候选查询计划;权限层判断用户能否访问这些数据;SQL 检查器限制查询范围;查询引擎执行只读 SQL;AI 根据结果生成解释;输出结论时标注假设、口径和不确定性。
五、AI 数据分析助手推荐架构
| 层级 | 作用 | 关键问题 | 不建议交给模型自由决定 |
|---|---|---|---|
| 用户问题层 | 接收自然语言问题 | 用户到底想问什么 | 直接假设业务口径 |
| 指标语义层 | 匹配指标定义 | 指标口径是否统一 | 临时编造指标 |
| 权限控制层 | 判断数据访问范围 | 用户能看哪些数据 | 绕过权限查明细 |
| 查询生成层 | 生成 SQL 或查询计划 | 是否只读、是否限量 | 生成危险 SQL |
| 查询校验层 | 检查 SQL 安全和成本 | 是否全表扫、是否越权 | 直接执行任意 SQL |
| 结果解释层 | 解释数据变化 | 是否有统计依据 | 编造因果关系 |
| 报告输出层 | 生成图表和总结 | 是否可追溯 | 隐藏口径和假设 |
模型可以参与每一层,但不能主导每一层。尤其是指标语义、权限控制、SQL 校验这三层,必须由系统规则兜底。
六、Prompt 块 1:先做问题澄清,不允许直接写 SQL
你现在是一个数据分析需求澄清助手,不要生成 SQL。
用户问题:
最近新手引导完成率是不是下降了?如果下降,帮我分析原因。
请你完成以下任务:
1. 将用户问题拆解成可查询的数据分析问题。
2. 列出需要确认的指标口径。
3. 列出需要的维度拆分。
4. 列出可能影响分析结果的异常因素。
5. 不要编造字段名、表名和数据结果。
6. 如果信息不足,请明确提出需要补充的问题。
输出格式:
- 业务问题理解
- 需要确认的指标口径
- 建议拆分维度
- 需要排查的异常因素
- 需要补充的信息
这个 Prompt 的重点是:先澄清,不查数。AI 数据分析助手如果跳过澄清阶段,就会把模糊业务问题变成模糊 SQL。
七、输入示例:给 AI 的指标字典和表信息
{
"metric_dictionary": {
"onboarding_completion_rate": {
"name": "新手引导完成率",
"definition": "完成新手引导的用户数 / 进入新手引导的用户数",
"numerator_event": "onboarding_completed",
"denominator_event": "onboarding_started",
"default_window": "7d",
"owner": "growth_team"
}
},
"allowed_tables": [
{
"table": "analytics.user_events_daily",
"description": "用户行为事件日表",
"allowed_fields": [
"event_date",
"user_id",
"event_name",
"channel",
"app_version",
"device_type",
"is_test_user"
]
}
],
"permission_scope": {
"can_access_user_level_data": false,
"can_access_aggregated_data": true,
"max_date_range_days": 30
}
}
这里的关键点:指标定义来自指标字典,不让 AI 自己编;可用表和字段是白名单;权限范围明确;不允许访问用户级明细;最大查询范围限制为 30 天。
八、Prompt 块 2:生成查询计划,而不是直接执行
你现在是一个 SQL 查询计划生成助手。
业务问题:
分析最近 7 天新手引导完成率是否下降,并尝试定位可能原因。
已确认指标:
新手引导完成率 = onboarding_completed 用户数 / onboarding_started 用户数
可用表:
analytics.user_events_daily
可用字段:
event_date, user_id, event_name, channel, app_version, device_type, is_test_user
权限限制:
1. 只能查询聚合数据。
2. 不允许输出 user_id 明细。
3. 查询日期范围不能超过 30 天。
4. 只能生成 SELECT 查询。
5. 需要排除 is_test_user = true。
请输出:
1. 查询目标。
2. 分析维度。
3. SQL 草稿。
4. 结果解释时需要注意的假设。
5. 可能需要补充的数据。
真实系统中,SQL 还需要进入校验器。
九、输出示例:比较理想的 SQL 草稿
WITH daily_funnel AS (
SELECT
event_date,
channel,
app_version,
device_type,
COUNT(DISTINCT CASE WHEN event_name = 'onboarding_started' THEN user_id END) AS started_users,
COUNT(DISTINCT CASE WHEN event_name = 'onboarding_completed' THEN user_id END) AS completed_users
FROM analytics.user_events_daily
WHERE event_date >= CURRENT_DATE - INTERVAL '14 days'
AND event_date < CURRENT_DATE
AND is_test_user = false
AND event_name IN ('onboarding_started', 'onboarding_completed')
GROUP BY
event_date,
channel,
app_version,
device_type
)
SELECT
event_date,
channel,
app_version,
device_type,
started_users,
completed_users,
completed_users * 1.0 / NULLIF(started_users, 0) AS completion_rate
FROM daily_funnel
ORDER BY
event_date DESC,
channel,
app_version,
device_type;
这条 SQL 比较合理,因为它只做 SELECT,使用聚合结果,排除了测试用户,限制了日期范围,保留了渠道、版本和设备维度,使用 NULLIF 避免除零,没有输出用户级明细。
十、SQL 安全校验:不要让模型说了算
可以用一个简单的 Python 校验器做第一层规则拦截。实际生产环境建议用 SQL parser 或网关策略。
import re
FORBIDDEN_KEYWORDS = [
"insert", "update", "delete", "drop", "alter", "truncate",
"create", "grant", "revoke", "merge", "call"
]
ALLOWED_TABLES = {
"analytics.user_events_daily"
}
def validate_sql(sql: str) -> dict:
normalized = sql.lower()
for keyword in FORBIDDEN_KEYWORDS:
if re.search(rf"\b{keyword}\b", normalized):
return {
"ok": False,
"reason": f"Forbidden keyword detected: {keyword}"
}
if not normalized.strip().startswith(("select", "with")):
return {
"ok": False,
"reason": "Only SELECT or WITH queries are allowed"
}
referenced_tables = set(re.findall(r"from\s+([a-zA-Z0-9_.]+)|join\s+([a-zA-Z0-9_.]+)", normalized))
flattened_tables = {item for pair in referenced_tables for item in pair if item}
for table in flattened_tables:
if table not in ALLOWED_TABLES:
return {
"ok": False,
"reason": f"Table not allowed: {table}"
}
if "user_id" in normalized and "group by" not in normalized:
return {
"ok": False,
"reason": "User-level output is not allowed"
}
return {
"ok": True,
"reason": "SQL passed basic validation"
}
更完整的生产方案还应该包含 SQL parser、表级和字段级权限、查询成本估算、LIMIT 强制注入、超时控制、审计日志、敏感字段脱敏、查询缓存、结果行数限制、异常告警。
十一、错误示例:危险 SQL 看起来也可能很合理
SELECT
user_id,
event_date,
event_name,
channel,
app_version,
device_type
FROM analytics.user_events_daily
WHERE event_date >= CURRENT_DATE - INTERVAL '90 days'
AND event_name IN ('onboarding_started', 'onboarding_completed');
它的问题包括:输出了 user_id 明细;查询范围超过权限限制;没有排除测试用户;没有聚合;可能泄露用户行为数据;查询成本可能过高。即使这条 SQL 语法正确,也不能执行。
十二、结果解释阶段:AI 不能随便归因
假设查询结果显示:最近 7 天整体完成率从 62% 降到 48%;iOS 端下降明显;下降主要集中在 app_version = 5.8.0;渠道维度差异不大。
AI 可以给出这样的解释:
从聚合结果看,新手引导完成率下降主要集中在 iOS 端的 5.8.0 版本。
渠道维度没有明显集中异常,因此暂时不支持“渠道质量下降”这个判断。
更可能的方向是版本更新后引导流程、页面性能或埋点上报发生变化。
建议进一步检查 5.8.0 版本的新手引导页面改动、崩溃率、页面加载耗时和埋点发布记录。
这个解释是相对克制的。不建议 AI 直接写成“新手引导完成率下降是因为 iOS 5.8.0 版本存在页面性能问题”。除非系统已经提供性能数据、崩溃数据或发布记录,否则这就是过度归因。
| 类型 | 示例 | 是否可直接输出 |
|---|---|---|
| 事实描述 | iOS 5.8.0 完成率下降明显 | 可以 |
| 合理推测 | 可能与版本更新有关 | 可以,但要标注不确定性 |
| 因果结论 | 是页面性能导致下降 | 需要额外证据 |
模型擅长把结果说得很顺,但数据分析需要证据链。
十三、报告输出:别只生成漂亮 dashboard
# 新手引导完成率分析报告
## 1. 分析问题
分析最近 7 天新手引导完成率是否下降,并定位可能原因。
## 2. 指标口径
新手引导完成率 = 完成新手引导用户数 / 进入新手引导用户数。
## 3. 数据范围
最近 14 天聚合数据,排除测试用户。
## 4. 主要发现
- 整体完成率最近 7 天下降。
- 下降主要集中在 iOS 端 app_version = 5.8.0。
- 渠道维度未发现明显异常集中。
## 5. 可能原因
- 可能与 5.8.0 版本的新手引导流程变化有关。
- 需要结合崩溃率、页面加载耗时和埋点变更记录进一步确认。
## 6. 不确定性
当前分析未接入性能数据、崩溃日志和版本发布记录,因此不能直接得出因果结论。
## 7. 下一步建议
- 检查 5.8.0 新手引导页面改动。
- 对比 iOS 5.7.x 与 5.8.0 的页面加载耗时。
- 核对 onboarding_completed 埋点是否正常上报。
一份可用的数据分析报告应该保留指标口径、数据范围、查询假设、分析维度、证据和不确定性、下一步验证建议。
十四、工程实现建议:最小可用版本可以这样做
如果团队想做一个最小可用的 AI 数据分析助手,可以先不要追求全自动。建议从这个 MVP 开始:用户输入自然语言问题;AI 只做问题澄清和指标匹配;系统从指标字典中返回可用指标;AI 生成查询计划;SQL 校验器检查安全性;人工确认后执行;AI 根据结果生成解释草稿;分析师审核后发布报告。
def ai_data_analysis_flow(user_question, user_context):
clarified = llm_clarify_question(user_question)
metric = match_metric_dictionary(clarified)
if not metric:
return {
"status": "need_human_input",
"reason": "No matched metric definition"
}
permission = check_user_permission(user_context, metric)
if not permission["allowed"]:
return {
"status": "denied",
"reason": "User has no permission to access this metric"
}
query_plan = llm_generate_query_plan(
question=clarified,
metric=metric,
permission=permission
)
validation = validate_sql(query_plan["sql"])
if not validation["ok"]:
return {
"status": "blocked",
"reason": validation["reason"]
}
result = execute_readonly_query(query_plan["sql"])
explanation = llm_explain_result(
question=clarified,
metric=metric,
query_result=result
)
return {
"status": "review_required",
"metric": metric,
"sql": query_plan["sql"],
"result": result,
"explanation_draft": explanation
}
注意最后的状态是 review_required,不是 done。AI 输出仍然需要人工审核。
十五、和长文档处理、资料整理有什么关系?
很多人以为数据分析助手只和 SQL 有关,其实不是。真实企业里的数据分析经常要结合大量上下文材料:指标口径文档、埋点设计文档、版本发布记录、实验方案、需求说明、历史复盘、运营活动记录、BI 看板说明。
这些材料本身就涉及长文档处理和资料整理。如果只让 AI 访问数据库,而不给它正确的业务背景,它很容易做出错误解释;如果只让 AI 读文档,而不给它受控的数据查询能力,它又只能停留在文字总结。
| 信息来源 | 用途 | 风险 |
|---|---|---|
| 指标字典 | 统一口径 | 过期口径导致误判 |
| 数据表 schema | 生成查询 | 字段理解错误 |
| BI 看板说明 | 对齐已有分析方式 | 看板逻辑不透明 |
| 发布记录 | 辅助解释指标变化 | 不能直接证明因果 |
| 埋点文档 | 判断事件含义 | 埋点实际实现可能偏差 |
| 查询结果 | 提供事实依据 | 样本量不足或延迟 |
| 历史复盘 | 提供经验参考 | 旧结论不一定适用 |
十六、不建议怎么做
第一,不建议让 AI 直接连生产库自由查询。即使只读,也可能造成高成本查询、越权访问或敏感数据泄露。
第二,不建议让 AI 自己编指标口径。指标应该来自指标字典或数据治理系统,而不是模型临时生成。
第三,不建议把 SQL 执行权完全交给模型。SQL 必须经过安全校验、权限判断和查询成本控制。
第四,不建议把 AI 解释当成最终结论。AI 可以生成分析草稿,但涉及经营决策时必须有人复核。
第五,不建议只追求“自动生成 dashboard”。图表漂亮不代表分析正确。数据范围、口径、假设和不确定性必须写清楚。
十七、明确结论:AI 数据分析助手的核心不是自动化,而是可控性
Codex 开始接入数据分析工具,短期看是功能扩展,长期看是数据平台入口的变化。未来业务人员可能不再只打开固定 BI 看板,而是直接问:为什么转化率下降?哪个渠道质量变差?新版本是否影响激活?这次活动拉来的用户有没有留存?哪个页面的流失最严重?
这些问题当然可以让 AI 参与,但开发者必须提前设计好边界。真正可用的 AI 数据分析助手,不是“用户问什么,模型就查什么”,而是用户问题先澄清,指标口径有来源,数据权限可控制,SQL 查询可校验,查询成本可限制,结果解释有证据,报告输出可追溯,最终结论有人审核。
如果一个团队只是想尝鲜,可以让 AI 生成 SQL 草稿。如果一个团队真的要上线,就必须把它做成工程系统。
如果你平时已经在处理数据分析、长文档处理、资料整理这类高频任务,并且需要稳定使用 ChatGPT 或 Codex 相关能力,可以把 gpt0424.com 当成开通前的信息核对参考,重点看清周期、使用边界和异常说明,而不是只看某个插件能不能“一句话生成报表”。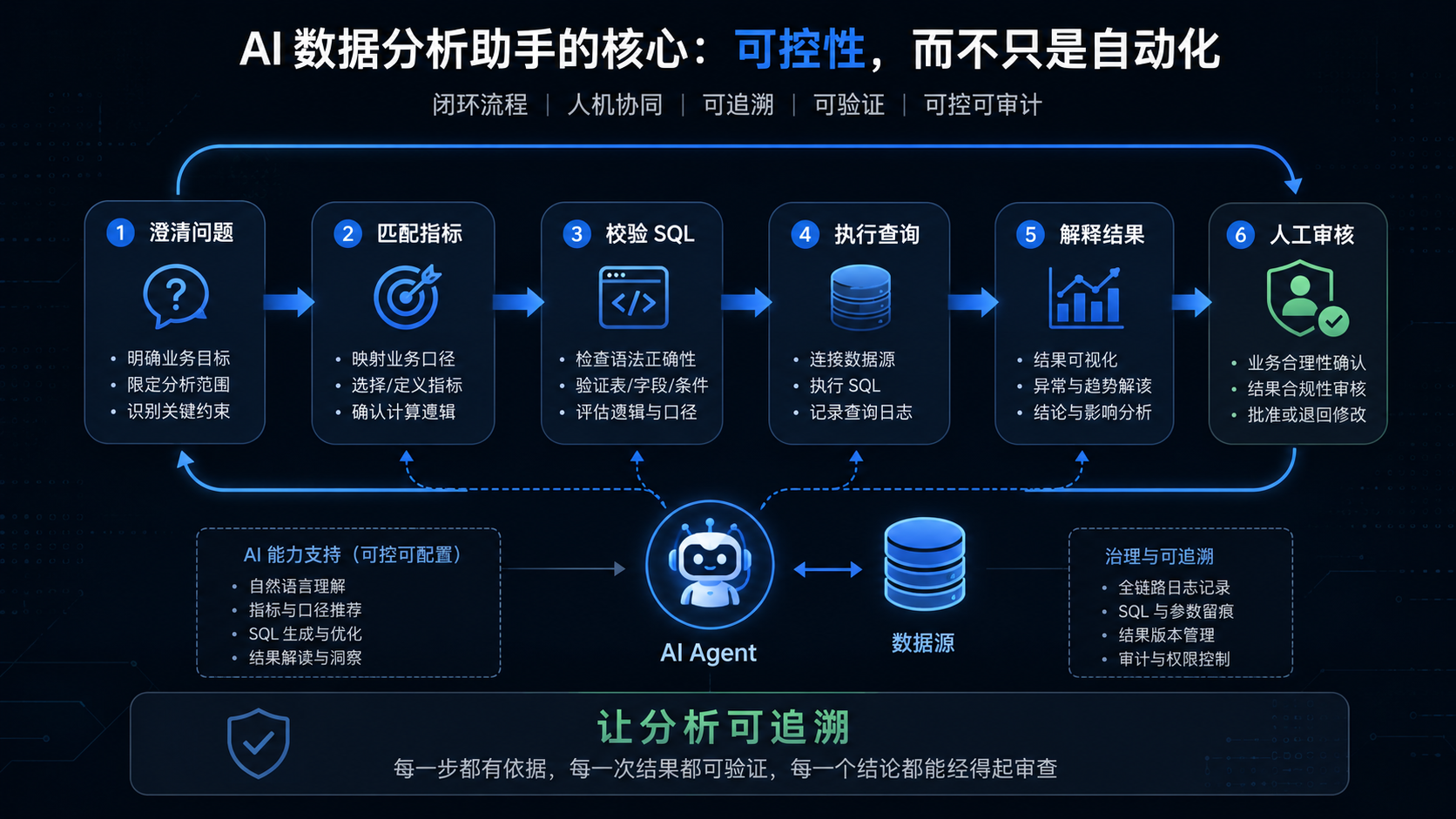

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)