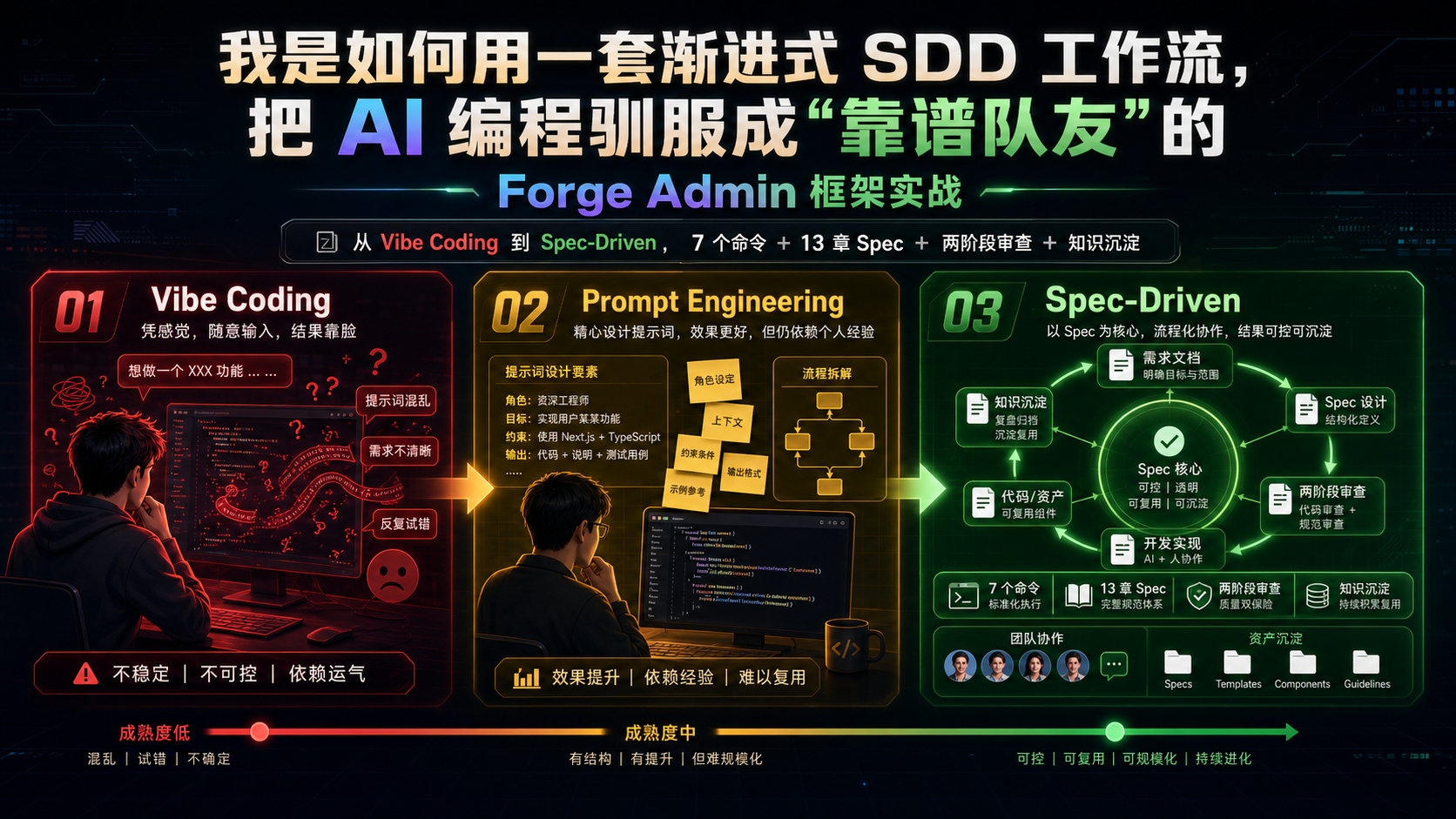
我是如何用一套渐进式 SDD 工作流,把 AI 编程驯服成“靠谱队友“的 —— Forge Admin 框架实战
从 Vibe Coding 到 Spec-Driven,7 个命令 + 13 章 Spec + 两阶段审查 + 知识沉淀,一套可以直接抄走的 AI 编程工程化方案。
写在前面
如果你和我一样,过去一年用 Cursor、Claude Code、OpenCode 这类 AI 编程工具写过几万行代码,大概率有过这些体验:
- AI 三秒生成了 500 行代码,看起来都对,跑起来全是坑;
- 同一个需求,今天问和明天问,AI 给的方案能差出三个版本;
- 修一个 Bug,AI 顺手"优化"了三个无关文件,回滚都不知道从哪开始;
- 让 AI 加个字段,结果它把现有逻辑改得面目全非,还美其名曰"重构";
- 项目越大,AI 越像新人,每次都要从头讲一遍业务背景。
我把这种放任 AI 自由发挥的开发模式,称为 Vibe Coding(凭感觉编程)。它写 Demo 的时候很爽,维护一个长期演进的企业级项目时,是灾难。
为了驯服 AI,我在 Forge Admin 这个开源中后台框架里,沉淀了一整套 渐进式 SDD(Spec-Driven Development,规格驱动开发)工作流。这套流程现在每天都在我的工作中跑,已经支撑了 30+ 个真实变更上线,包括多租户隔离加固、Flowable 流程版本管理、低代码业务对象设计器等复杂场景。
📌 本文目标:把这套工作流的设计哲学、命令链、模板规范、Sub Agent 审查、知识沉淀机制,毫无保留地讲透。文末附完整模板地址,欢迎直接抄走落地。
一、为什么是"渐进式 SDD"?
1.1 三种 AI 编程的姿势
我把 AI 编程的成熟度分成三个阶段:
|
阶段 |
工作模式 |
代码质量 |
可维护性 |
团队协作 |
|
🔴 Vibe Coding |
自然语言 → 代码 |
看脸 |
几乎为零 |
无法协作 |
|
🟡 Prompt Engineering |
精心设计 Prompt → 代码 |
中等 |
依赖个人经验 |
难以传承 |
|
🟢 Spec-Driven |
需求 → Spec → 审查 → 代码 → 沉淀 |
可控 |
文档即资产 |
团队可复用 |
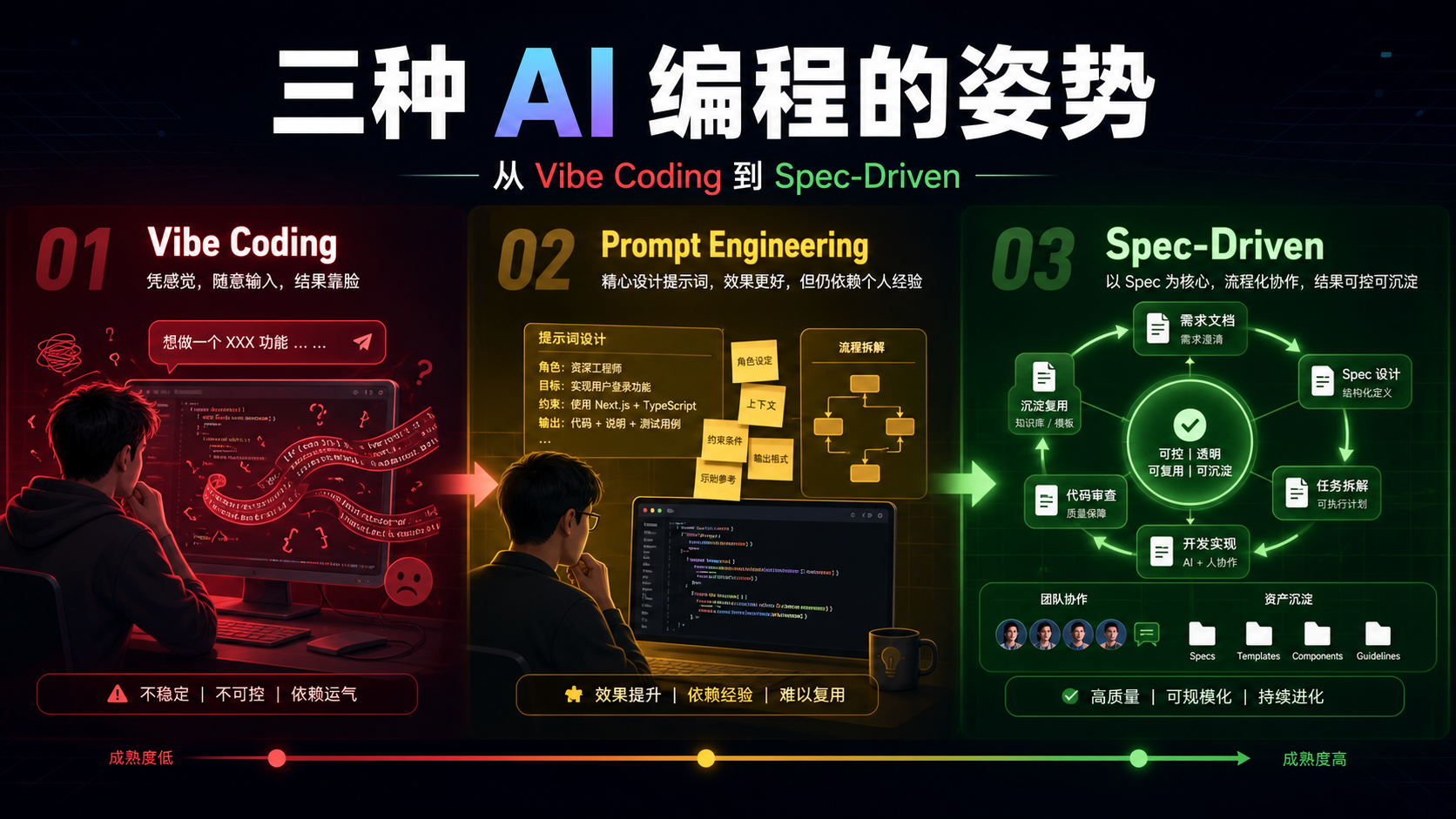
渐进式 SDD 的核心信念只有一句话:
代码是廉价的消耗品,Spec(规格文档)才是昂贵的核心资产。
代码可以让 AI 一键重生,但需求决策、技术选型、踩坑记录、业务规则——这些才是项目的护城河。
1.2 五大核心原则
在 Forge Admin 的 AGENTS.md 里,我把 SDD 的原则浓缩成了 5 条铁律:
|
原则 |
说明 |
|
No Spec, No Code |
没有确认的 Spec,不准写代码 |
|
Spec is Truth |
Spec 和代码冲突时,错的一定是代码 |
|
Reverse Sync |
执行中发现 Spec 与实际不符,先修 Spec 再修代码 |
|
代码现状必须有出处 |
每个结论必须标注文件路径和类名/方法名 |
|
变更即记录 |
任何代码变更完成后都必须同步更新对应文档 |
这五条听起来朴素,每一条都是踩了无数坑总结出来的。比如"代码现状必须有出处",是因为 AI 太擅长幻觉式编码——它会非常自信地告诉你"这个项目里有个 UserManager 类",但其实根本不存在。
1.3 为什么强调"渐进式"
"Spec-Driven"听起来像瀑布开发的回潮,但渐进式三个字是关键区别:
- 不要求一次性写完整需求文档:每个变更只写自己范围内的 Spec,5-15 分钟能产出;
- Spec 和代码同步演化:执行中发现偏差,立刻反向修 Spec(Reverse Sync);
- 以变更(Change)为最小单位:不是按版本,不是按 Sprint,而是按一个可独立交付的功能切片。
这种节奏既保留了文档驱动的严谨性,又保留了敏捷开发的灵活性。
二、工作流全景:7 个命令 + 1 条主线
整个 SDD 工作流由 7 个斜杠命令串联,对应 6 个阶段:
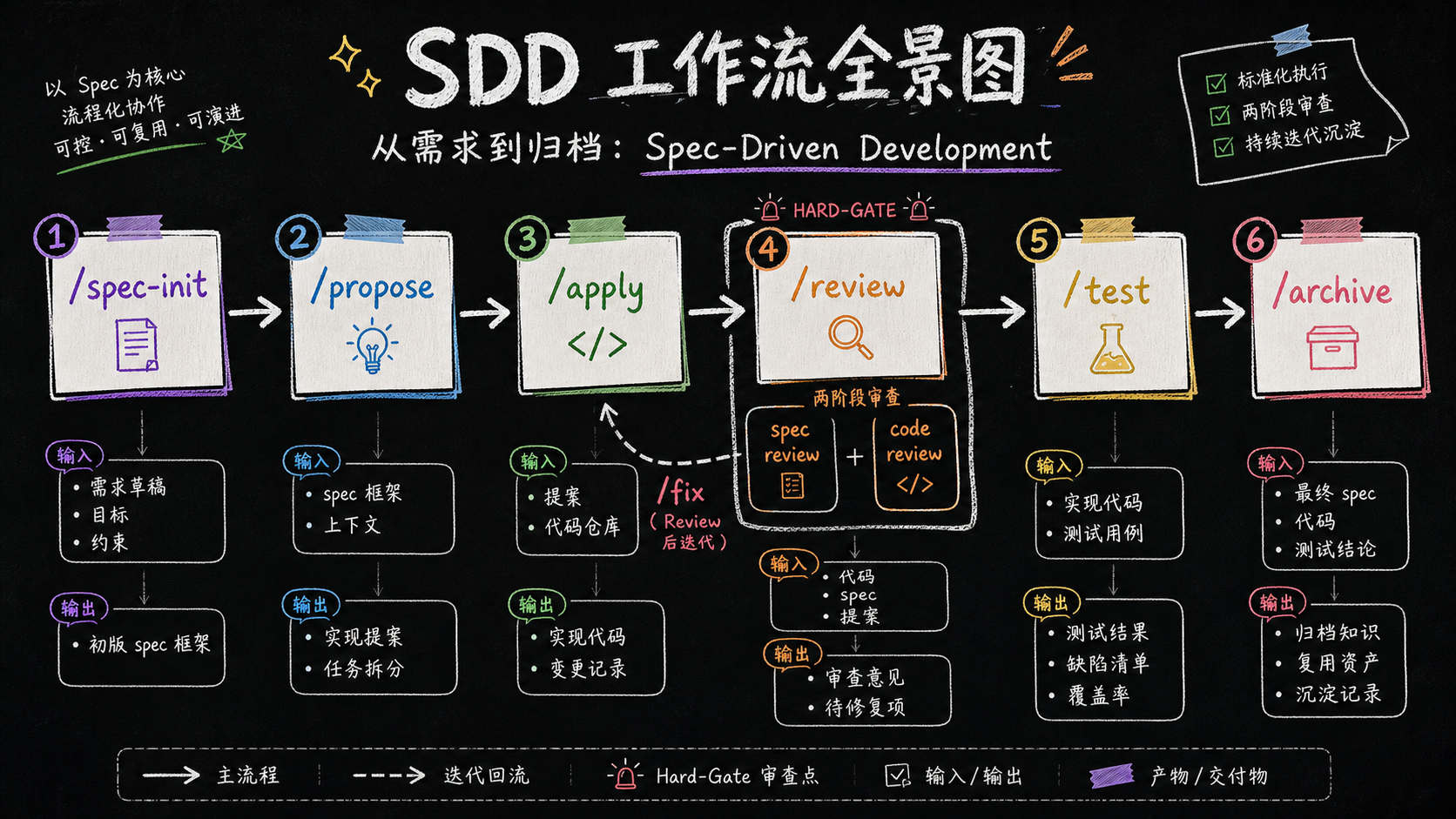
2.1 命令速查表
|
命令 |
作用 |
关键产物 |
|
|
分析项目结构,生成上下文 |
|
|
|
把自然语言需求变成结构化 Spec |
|
|
|
按 Spec 逐 Task 执行编码 |
代码变更 + Git 提交 + 文档同步 |
|
|
Review 后增量修正 |
增量代码 + 文档更新 |
|
|
Sub Agent 两阶段审查 |
审查报告(PASS/FAIL) |
|
|
Red/Green TDD 增量生成测试 |
|
|
|
归档变更并沉淀知识 |
|
2.2 目录结构:所有产物都有地方放
code-copilot/
├── rules/ # 全局规则
│ ├── project-context.md # 项目上下文(/spec-init 生成)
│ ├── coding-style.md # 编码规范
│ ├── domain-rules.md # 业务领域约束
│ ├── security.md # 安全红线
│ └── automated-testing-standard.md # 自动化测试标准
├── changes/ # 所有变更
│ ├── templates/ # 模板
│ │ ├── spec.md
│ │ ├── tasks.md
│ │ ├── log.md
│ │ └── test-spec.md
│ ├── <变更名>/ # 进行中的变更
│ │ ├── spec.md # 13 章规格文档
│ │ ├── tasks.md # 原子化任务拆分
│ │ ├── execution-log.md # 执行日志
│ │ └── test-spec.md # 测试策略
│ └── archive/ # 归档变更
│ └── YYYY-MM-DD-<名称>/
├── knowledge/ # 知识沉淀
│ ├── index.md
│ ├── tech-spring-boot-autoconfig.md
│ ├── tech-spel-expression.md
│ └── ...
└── agents/ # Sub Agent 定义
├── spec-reviewer.md
└── code-quality-reviewer.md这个目录结构本身就是工作流的物化。所有 AI 编程的中间产物都有地方放、可以追溯、可以审计——这是和 Vibe Coding 最本质的区别。
三、/propose:把"我想要个功能"变成 13 章 Spec
这是整个工作流最关键的一步。它解决的核心问题是:让 AI 在动手写代码之前,先和你把需求聊清楚。
3.1 完整流程
用户:/propose 给流程审批加一个超时自动通过的功能
AI 按顺序执行:
1. Research → 扫描代码库,定位 forge-plugin-flow 的相关入口
2. 逐个提问 → "超时时间是按节点配置还是按流程配置?"(一次只问一个)
3. YAGNI 裁剪 → "你提到的'超时短信通知'是否本期必须?"
4. 分三段生成 → 背景目标 → 业务规则 → 数据接口(每段确认后再生成下一段)
5. 生成 Tasks → 每个 Task 3-5 个文件,可独立提交
6. HARD-GATE → "请确认是否进入 /apply 阶段"3.2 Spec 文档的 13 章结构
我设计的 spec.md 模板,固定包含 13 个章节:
|
章节 |
内容 |
为什么需要 |
|
1. 背景与目标 |
为什么做 + 可验证的结果描述 |
防止做着做着忘了初心 |
|
2. 代码现状 |
相关入口、现有实现、风险(必须带代码出处) |
杜绝 AI 幻觉式编码 |
|
3. 功能点 |
输入 → 处理 → 输出 |
明确边界 |
|
4. 业务规则 |
业务约束 |
防止技术方案违背业务 |
|
5. 数据变更 |
表名、字段、索引 |
DBA 友好 |
|
6. 接口变更 |
路径、方法、变更内容 |
前后端协作 |
|
7. 影响范围 |
受影响的模块和文件 |
评估风险半径 |
|
8. 风险与关注点 |
⚠️ 资金/状态流转/权限变更必须标注 |
安全红线 |
|
8.5 测试策略 |
测试范围和覆盖率目标 |
测试可落地 |
|
9. 待澄清 |
必须全部解决才能进入 /apply |
HARD-GATE |
|
10. 技术决策 |
方案选择及理由 |
决策可追溯 |
|
11. 执行日志 |
Task 状态、实际改动文件 |
进度透明 |
|
12. 审查结论 |
两阶段审查结果 |
质量门禁 |
|
13. 确认记录 |
HARD-GATE 确认信息 |
责任明确 |
3.3 三个最反直觉的设计
① 一次只问一个问题
AI 默认会一次抛 5-6 个问题给你,看起来效率高,但实际你会漏答、答错。强制"一次一个",配合"提供选项 + 推荐方案",决策质量高得多。
❌ 反例:
"请告诉我:1) 超时时长?2) 通知方式?3) 是否记录日志?4) 权限范围?"
✅ 正例:
"请问超时时长应该如何配置?
A. 全局统一配置(推荐,简单)
B. 按流程定义配置(灵活,但要加表字段)
C. 按节点配置(最灵活,但配置成本高)"② Spec 分三段生成,每段确认再继续
一次性生成完整 Spec,用户很难逐章 review。拆成"背景目标 → 业务规则 → 数据接口"三段,每段不超过 200 行,确认后再继续。这样一旦发现方向不对,能立刻刹车。
③ HARD-GATE:没确认就是没确认
Spec 的第 13 章是确认记录,必须显式填写"确认时间 + 确认人"。在 .opencode/command/apply.md 里我加了硬校验:检测不到这个章节有内容,就拒绝执行 /apply。这条规则简单粗暴,但杜绝了"AI 自作主张开始写代码"的情况。
四、/apply:原子化 Task + 一 Task 一 Commit
Spec 确认后,/apply 命令登场。它的核心理念是:Plan 是合同,严格按 Spec 执行,零偏差。
4.1 Task 拆分的"原子化"原则
tasks.md 模板里有一条铁律:
每个 Task = 可独立提交的原子变更(3-5 个文件)
拆分顺序:数据模型 → 接口协议 → 底层实现 → 上层编排 → 入口层
为什么是 3-5 个文件?这是我反复实验出来的最佳粒度:
- 少于 3 个文件:Task 颗粒太细,commit 历史会爆炸;
- 多于 5 个文件:审查成本飙升,AI 也容易写飞;
- 3-5 个文件:刚好能在一次 commit 里完成一个有意义的功能切片。
4.2 真实的 Task 拆分案例
以"流程审批超时自动通过"为例:
## Task 1: 数据库迁移 - 添加超时配置字段
- 涉及文件:
- forge/db/migration/V1.0.5__add_timeout_config.sql — 新增 Flyway 脚本
- forge-plugin-flow/.../entity/FlowTimeoutConfig.java — 新增实体
- forge-plugin-flow/.../mapper/FlowTimeoutConfigMapper.java — 新增 Mapper
## Task 2: 超时检测 Manager
- 涉及文件:
- forge-plugin-flow/.../manager/FlowTimeoutManager.java — 新增超时检测
- forge-plugin-flow/.../service/impl/FlowTaskServiceImpl.java — 注入 Manager
- 单元测试 FlowTimeoutManagerTest.java
## Task 3: 定时任务调度
- 涉及文件:
- forge-plugin-flow/.../job/FlowTimeoutCheckJob.java — Quartz 任务
- forge-plugin-flow/.../config/FlowTimeoutJobConfig.java — 任务注册
## Task 4: 配置接口 + 前端页面
- 涉及文件:
- forge-plugin-flow/.../controller/FlowTimeoutConfigController.java
- forge-admin-ui/src/views/flow/timeout/index.vue
- forge-admin-ui/src/api/flow-timeout.ts四个 Task,每个独立可编译、独立可测试、独立可回滚。即使某个 Task 写飞了,影响范围也被严格控制在 3-5 个文件里。
4.3 验证铁律:每个 Task 完成必须展示编译通过证据
这是 /apply 命令里写死的硬规则。AI 完成一个 Task 后,必须执行实际编译并贴出结果:
# 后端 Task
mvn -pl forge-admin-server -am package -DskipTests
# 前端 Task
nvm use v20.19.0 && NODE_OPTIONS=--max-old-space-size=8192 pnpm build执行结果必须在 execution-log.md 里留痕。"我看了一下,应该没问题"这种话,在 SDD 流程里是不允许出现的。
4.4 文档同步:变更即记录
每个 Task 完成后,AI 必须同步更新三个地方:
spec.md§11 执行日志:填写 Task 状态、实际改动文件、备注tasks.md:把对应 Task 勾选完成execution-log.md:追加执行时间、命令、结果
这就是"变更即记录"原则的落地。它带来的好处是:任何人(包括未来的你)回过头看,都能从文档里完整还原这次变更的来龙去脉。
五、/review:两阶段审查 + Sub Agent 上下文隔离
写代码的 AI 不能既当运动员又当裁判员。所以我把审查环节交给两个独立的 Sub Agent:
5.1 阶段一:Spec Compliance Reviewer
职责:逐条验证 Spec §3 功能点是否在代码中真实落地。
核心理念:不信报告,只信代码 — reviewer 必须独立读实际代码验证,不能轻信 /apply 阶段的执行日志。
审查维度:
- 缺失实现:Spec 要求了但代码没做的
- 多余实现:Spec 没要求但代码多做了的(YAGNI 违规)
- 理解偏差:做了但做错了方向的
- 业务规则落地:Spec §4 中的规则是否全部体现在代码中
- 数据变更准确性:Spec §5 中的表/字段变更是否准确落地
输出格式:
#### 功能点逐条验证
- ✅ 功能 1:已实现,见 `XxxService.java:L42`
- ❌ 功能 2:未实现(缺少 XX 逻辑)
- ⚠️ 功能 3:实现方式与 spec 描述有偏差
#### 结论:✅ Spec 合规 / ❌ 不合规(附具体问题)5.2 阶段二:Code Quality Reviewer
前置条件:阶段一必须 PASS 后才启动。这条规则的意义是——Spec 都没对上,谈代码质量没意义。
审查分级:
|
级别 |
含义 |
示例 |
|
🔴 Critical(阻塞) |
必须修复 |
安全漏洞、资金逻辑错误、并发安全、数据丢失风险 |
|
🟡 Important(应修复) |
建议修复 |
异常被吞、缺少参数校验、魔法值、方法过长、命名不清 |
|
🟢 Minor(建议) |
可选 |
Javadoc 缺失、注释过时、import 未清理 |
5.3 为什么必须用 Sub Agent?
如果让同一个 AI 既写代码又审查代码,它会陷入自洽偏见——它会下意识维护自己刚写的代码。
Sub Agent 的关键优势是上下文隔离:它只看到 Spec 文档和最终代码,看不到 /apply 过程中的思考、犹豫、妥协。这种"无知"反而带来了客观性。
在 Forge Admin 里,这两个 Agent 的定义放在 code-copilot/agents/ 下,每个文件不超过 20 行:
code-copilot/agents/
├── spec-reviewer.md # 阶段一审查员定义
└── code-quality-reviewer.md # 阶段二审查员定义Agent 定义文件越短越好,这能强制 Agent 聚焦在单一职责上。
5.4 /fix:Review 后增量修正
Review 给出 FAIL 后,不要让 AI 重写代码,而是用 /fix <变更名> [描述] 增量修正:
- 读取当前 spec/tasks/log 文档
- 增量修改,不重写
- 验证编译通过
- 同步更新所有文档
- 自动 git commit
这种"小步快跑"的修复模式,配合两阶段审查,能让代码质量稳定提升而不引入新的副作用。
六、/test:增量优先的自动化测试哲学
很多团队在 AI 编程时栽在测试上:每改一行代码都跑全量测试,CI 时长爆炸;或者干脆不测,靠人肉验证。
我在 code-copilot/rules/automated-testing-standard.md 里定义了一套增量优先的测试哲学:
6.1 五大核心原则
|
原则 |
说明 |
|
增量优先 |
先读已有 |
|
证据优先 |
不能只写"已通过",必须记录命令、关键输出、接口返回 |
|
最小闭环 |
验证范围跟随本轮改动的风险面扩展,不做无意义全量验证 |
|
可复跑 |
命令必须可复制执行,环境变量、Token、服务启动方式写清楚 |
|
不污染环境 |
只停止本轮启动的服务,不清理其他进程和数据 |
6.2 按变更类型决定验证范围
这是整个测试标准的精髓——一张变更类型 × 验证矩阵:
|
变更类型 |
必跑验证 |
条件增强验证 |
|
仅文档/Spec/Task |
|
关键文档链接和状态一致性 |
|
Java 后端 |
相关 Maven 模块 |
涉及业务逻辑补单测 |
|
Mapper XML / SQL |
后端编译 + XML 语法检查 |
有数据库时执行接口验证 |
|
Flyway 脚本 |
SQL 防重复检查 + Flyway 实跑 |
检查 |
|
前端 JS/Vue |
|
改 UI 时启动 Vite + Playwright 截图 |
|
API 协议 |
后端启动 + curl 验证 |
涉及鉴权时验证加密链路 |
|
流程/消息 |
后端 + Flow 服务 + 主路径验证 |
验证关联表/任务表落库 |
核心思想:默认不全量跑 mvn test 或完整 E2E,只有共享基础能力、状态流转、权限、安全、数据迁移这些场景才升级到全量。
6.3 Red/Green TDD:测试必须能真正验业务
/test 命令支持两种模式:
- Spec 先行(推荐) — 先生成
test-spec.md,列出 P0/P1/P2 测试点,再生成测试代码 - 直接生成 — 适合简单场景
无论哪种模式,必须遵守 Red/Green 规则:
测试必须先 Red(失败),再 Green(通过)。跳过 Red 的测试无法证明有效。
我见过太多 AI 生成的"通过测试",其实根本没断言任何有意义的东西。Red/Green 强制要求测试能真正发现问题。
七、/archive:知识沉淀的飞轮
变更完成后,不是简单地 git push 就结束。/archive 命令负责把这次变更里产生的知识抽取出来,沉淀为团队资产。
7.1 归档流程
1. 展示 execution-log.md 中的「知识发现」清单
2. 用户确认哪些条目需要沉淀
3. 写入 code-copilot/knowledge/tech-*.md
4. 移动变更目录到 code-copilot/changes/archive/YYYY-MM-DD-<名称>/
5. 设置 Spec 状态为 done7.2 Forge Admin 已沉淀的知识文章
这是真实的 code-copilot/knowledge/ 目录:
|
文件 |
内容 |
|
|
Spring Boot 自动配置注册的坑 |
|
|
Maven 多模块添加 Starter 的标准姿势 |
|
|
SpEL 表达式解析与缓存 |
|
|
AOP 参数名发现机制(-parameters 编译参数) |
|
|
全局异常处理的优先级陷阱 |
|
|
Flowable 多版本流程模型管理 |
|
|
流程版本数据库设计 |
|
|
版本状态机设计 |
每篇知识文章都来源于一次真实的踩坑,包含「问题 → 根因 → 解决方案 → 代码示例」四要素。新人接手项目,读完这些文章就能避开 80% 的坑。
7.3 三层记忆系统
除了 knowledge/,还有 .opencode/memory/ 三件套:
|
文件 |
用途 |
|
|
踩坑记录(短期记忆) |
|
|
项目决策(中期记忆) |
|
|
用户偏好(个性化) |
每次新对话开始,AI 都会主动读取这三个文件,30 秒内进入项目上下文。这就是"知识飞轮"——每次变更都让 AI 变得更懂你的项目。
八、Forge Admin 实战:完整流程跑一遍
讲了这么多方法论,最后用一个真实变更展示完整流程。
8.1 案例:多租户隔离加固
背景:审计时发现部分查询未正确触发 TenantLineInnerInterceptor,存在跨租户数据泄露风险。
完整流程:
# 1. 创建变更提案
/propose 加固多租户隔离,识别所有未走拦截器的查询并补全
# AI 执行:
# - Research:扫描所有 Mapper XML,识别未带 tenant_id 条件的查询
# - 提问:是补 SQL 还是改用 LambdaQueryWrapper?
# (AI 推荐:补 SQL,因 DataScopeInterceptor 按 mapperMethod 精确匹配)
# - 生成 spec.md(13 章)+ tasks.md(按模块拆分 8 个 Task)
# - HARD-GATE 等待确认
# 2. 确认后执行编码
/apply harden-multi-tenant-isolation
# AI 执行:
# - Task 1:补 forge-plugin-system 模块的 6 个 Mapper XML
# - 编译验证:mvn -pl forge-plugin-system -am compile ✅
# - 同步文档 + git commit
# - Task 2-8 依次执行...
# 3. 两阶段审查
/review harden-multi-tenant-isolation
# Spec Reviewer:✅ 8 个功能点全部落地
# Code Quality Reviewer:⚠️ Task 5 中有一个 SQL 缺少 tenant_id 索引覆盖
# 4. 修正
/fix harden-multi-tenant-isolation Task 5 索引补充
# 5. 测试
/test harden-multi-tenant-isolation
# 6. 归档
/archive harden-multi-tenant-isolation8.2 真实产出物
整个流程结束后,仓库里会留下:
code-copilot/changes/archive/2026-04-15-harden-multi-tenant-isolation/
├── spec.md # 13 章规格文档(status: done)
├── tasks.md # 8 个 Task 全部勾选完成
├── execution-log.md # 完整执行记录、命令、结果
└── test-spec.md # 测试策略 + 测试用例清单
code-copilot/knowledge/
└── tech-tenant-interceptor-mapper-method-match.md # 新沉淀的知识
git log:
9f3c2a1 [harden-multi-tenant-isolation] Task 8: 归档与文档收尾
8e2b3d4 [harden-multi-tenant-isolation] Fix: Task 5 索引补充
7d1a4e5 [harden-multi-tenant-isolation] Task 7: 增加跨租户回归测试
...(一 Task 一 Commit)
1a2b3c4 [harden-multi-tenant-isolation] Task 1: 补 system 模块 Mapper这才是 AI 编程应有的样子:有规划、有审查、有测试、有沉淀,每一步都可追溯。
九、为什么这套流程能落地:Forge Admin 框架的支撑
很多人看完会问:方法论我懂了,但要在自己项目里落地很难——AI 不熟悉我的代码、规范不统一、没人维护文档。
这套 SDD 工作流之所以能在 Forge Admin 里跑得动,是因为框架本身就为 AI 编程做了大量准备:
9.1 清晰的分层架构
Forge Admin 采用 微内核 + 插件化 架构:
forge-framework/
├── forge-plugin-parent/ # 业务插件(system/generator/job/message/flow/ai)
└── forge-starter-parent/ # 技术启动器(auth/cache/orm/tenant/crypto 等 20 个)每个插件、每个 Starter 都有清晰的职责边界。AI 在做 /propose 的 Research 阶段,能快速定位变更应该落在哪个模块——架构清晰是 AI 编程的前提。
9.2 统一的编码规范
项目根目录的 AGENTS.md 把所有关键约定都写死了:
- SQL 必须写在 Mapper XML 中(不能用 LambdaQueryWrapper 构建查询)
- 业务数据
tenant_id必须为1(不能为0) - 分页参数必须用
pageNum/pageSize(不能用page) - AiCrudPage 占位符必须用冒号格式
:id(不能用{id}) - 字典禁止硬编码,必须用
DictSelect/DictTag/useDict - ...
这些规则被 AI 在每次对话开始时主动读取,生成的代码天然符合项目规范。
9.3 Flyway + 统一脚本
数据库变更全部走 forge/db/migration/ 的 Flyway 脚本,命名规范 V<版本>__<描述>.sql,必须幂等。配合 SDD 流程,每次数据变更都有 Spec、有 Migration、有审查、有验证。告别"我在本地手动改了下数据库"。
9.4 内置组件极大降低生成代码量
AiCrudPage— 零代码 CRUD 页面,配置即生成DictSelect/DictTag— 字典选项零硬编码RegionTreeSelect— 行政区划树选择器AuthImage— 鉴权图片(自动带 Token)@ApiEncrypt/@ApiDecrypt— 接口加解密注解@OperationLog— 操作日志注解@Idempotent— 幂等控制注解@FlowBind/@FlowStart— 流程客户端注解
生成代码越少,AI 越不容易出错。Forge Admin 把企业后台 80% 的重复代码都做成了组件和注解,AI 只需要做配置和编排。
十、写在最后:SDD 不是银弹,但它是底线
10.1 这套流程的代价
老实说,渐进式 SDD 有几个代价:
|
代价 |
缓解 |
|
每个变更要花 5-15 分钟写 Spec |
复杂变更省下的返工时间远超于此 |
|
AI 提问会让你慢下来 |
慢思考避免后期大规模返工 |
|
团队需要学习 7 个命令 |
命令链一周熟悉,模板可直接抄 |
|
文档维护成本 |
文档由 AI 自动同步,不是人工维护 |
10.2 适合什么场景?
✅ 强烈推荐:
- 长期演进的企业级项目
- 多人协作的团队项目
- 涉及资金、权限、状态机的高风险代码
- 需要审计追溯的合规场景
⚠️ 可以简化:
- 个人玩具项目(跳过 review/test/archive)
- 一次性脚本(直接对话生成)
- 纯 UI 调整(用 /fix 直接迭代)
10.3 三条核心建议
如果你只能记住三件事:
- 永远不要让 AI 在没 Spec 的情况下写超过 3 个文件的代码
- 永远不要让写代码的 AI 自己审查自己的代码
- 永远不要让一次变更结束于"代码提交",而要结束于"知识沉淀"
做到这三条,你的 AI 编程体验会有质变。
🔗 资源与传送门
|
资源 |
地址 |
|
Forge Admin 源码(Gitee) |
|
|
Forge Admin 源码(GitHub) |
|
|
在线体验 |
企业级中后台基础框架 / 123456) |
|
项目文档 |
|
|
AI 大屏设计器 |
|
|
SDD 工作流文档 |
|
|
完整 Spec 模板 |
|
|
自动化测试标准 |
|
直接抄走
code-copilot/ 目录是这套 SDD 工作流的完整实现,包括:
- ✅ 4 个模板文件(spec / tasks / log / test-spec)
- ✅ 2 个 Sub Agent 定义(spec-reviewer / code-quality-reviewer)
- ✅ 5 份规则文档(project-context / coding-style / domain-rules / security / automated-testing-standard)
- ✅ 8 篇知识沉淀(tech-*.md)
- ✅ 30+ 个真实归档变更(archive/)
Clone 项目,把 code-copilot/ 整个目录复制到你的项目里,改改 AGENTS.md 里的技术栈描述,就能跑起来。
🎁 Forge Admin 项目简介
最后再花一分钟介绍 Forge Admin —— 这套 SDD 工作流的"宿主",本身也是一个值得收藏的开源框架。
Forge Admin 是一套面向企业后台、SaaS 管理端、数据可视化平台和内部低代码工具的中后台框架,基于 Vue 3 + Spring Boot 3 构建。
三大亮点
|
亮点 |
说明 |
|
🏗️ 微内核插件化 |
核心轻量,系统/生成器/任务/消息/流程/AI 等能力以插件方式组合 |
|
🤖 AI 数据大屏 |
自然语言生成大屏,支持组件拖拽、主题定制、真实 API 数据接入 |
|
⚡ AI 代码生成 |
面向表单和 CRUD 场景,0 代码配置 + 代码包二次开发 |
完整能力清单
- 基础能力:RBAC、多租户、数据权限、操作日志、动态配置、文件存储、Excel 导入导出
- 业务能力:用户/角色/菜单/部门/岗位/字典/通知/任务/消息 + Flowable 工作流
- 开发者工具:AI 代码生成、模板市场、API 配置、数据源管理、Excel 配置
- AI 大屏:拖拽式画布、内置 30+ 组件、AI 生成、6+ AI 供应商支持
技术栈
- 后端:Java 17 + Spring Boot 3.2 + MyBatis-Plus + Sa-Token + Flowable 7.0 + Redis
- 前端:Vue 3.5 + Naive UI + Vite 7 + Pinia + UnoCSS + ECharts + BPMN.js
如果你正在搭建一个长期演进的企业级中后台系统,欢迎来 Star ⭐:
- Gitee:https://gitee.com/ForgeLab/forge-admin
- GitHub:GitHub - yaomindong1996/forge-admin: AI编码,SpringBoot 3.x + JDK 17 构建的轻量化企业级管理系统基础框架,以配置驱动为核心设计理念,追求简洁高效、开箱即用,助力开发者快速搭建稳定可靠的企业级应用,极简开发、高效迭代、生产可用 · GitHub
📮 联系作者
📷 截图位 11:微信二维码 + 微信群二维码(用于读者扫码加入交流群)
如果这篇文章对你有帮助,欢迎:
- ⭐ 给 Forge Admin 一个 Star
- 💬 加入微信交流群一起讨论 AI 编程工程化
- 📝 在评论区分享你的 SDD 实践经验

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)