一次性搞懂 CDN、对象存储、反向代理、函数计算和边缘计算 --- Cloudflare 免费服务到底能用到什么程度
文章目录
CDN、反向代理与边缘函数
CDN 本质是一套分布式内容分发网络,通过遍布各地的节点让用户就近访问资源,从而降低延迟、提升加载速度。但在实际工程里,CDN 并不是简单 “把文件丢到几千个节点”,而是一整套包含源站、缓存、回源、代理、边缘计算的协作体系。
CDN 是什么,实际怎么工作?
CDN:Content Delivery Network 内容分发网络:它由大量分布在不同地域、不同运营商的节点组成。用户离节点越近,理论访问速度就越快、稳定性越高。
很多人会有一个直观误区:
把前端打包后的静态资源直接上传到 CDN,绑定域名就能加速。
但真实架构不可能这么做:
- CDN 可能有数千个节点,一次性全量推送成本极高
- 发布更新时同步所有节点,时效性和网络开销都无法接受
- 大量重复存储会严重浪费节点容量
所以工业界标准做法是:静态资源 → 上传到对象存储(作为源站) → CDN 按需回源拉取并缓存
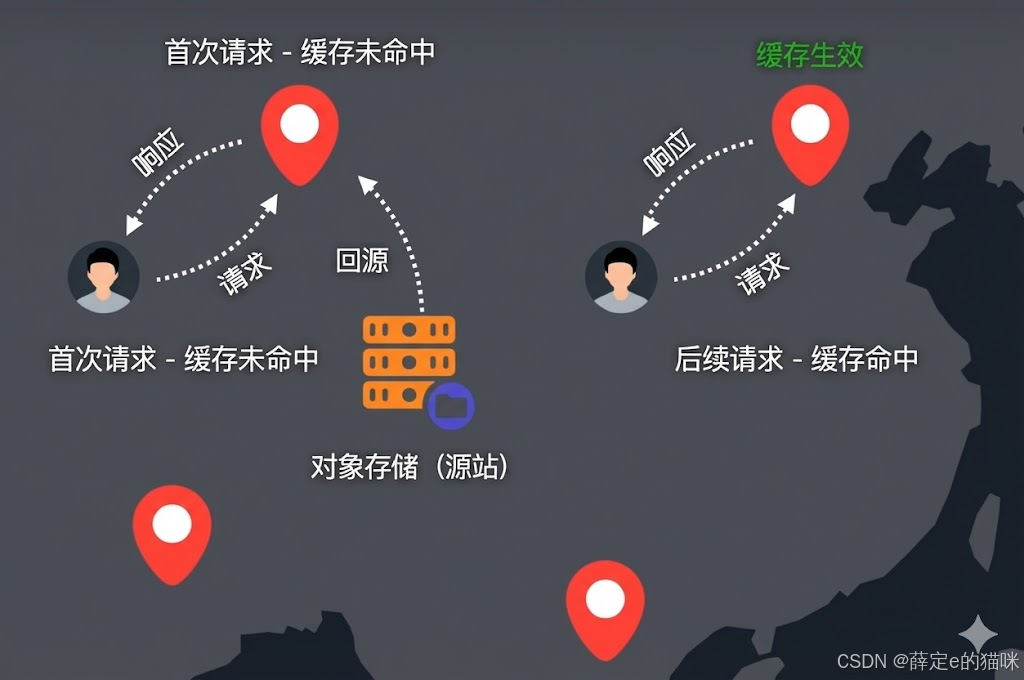
标准 CDN 缓存流程
- 用户第一次请求资源
- 对应 CDN 节点检查本地缓存,发现未缓存 / 已过期
- CDN 节点回源到对象存储获取文件
- 节点将文件缓存,并返回给用户
- 后续相同请求直接命中缓存,就近快速响应,不再访问源站
这就是 “被动缓存” 模型,也是绝大多数公有云 CDN 的默认工作方式。除此之外,实际工程还会涉及:缓存策略、缓存有效期、缓存预热、多层回源、跨域配置等。
CDN 本质是带缓存的反向代理
CDN 可以理解为:分布式 + 大规模缓存 + 就近访问的反向代理集群。
反向代理:
用户只访问代理服务器,代理服务器再把请求转发到后端真实服务,并把结果返回给用户。用户完全感知不到后端源站的存在。

如何用一个函数来描述代理的过程,可以写成如下的形式:

用户请求 request 经过代理函数加工、路由、缓存、改写后,返回最终响应 response。
CDN 就是在这个模型上增加了:就近节点调度;多级缓存;自动回源;带宽汇聚与防攻击能力。
下面用标准 Web API 模拟一个极简 CDN 缓存逻辑:接收图片请求 → 查缓存 → 未命中则回源对象存储 → 缓存并返回。
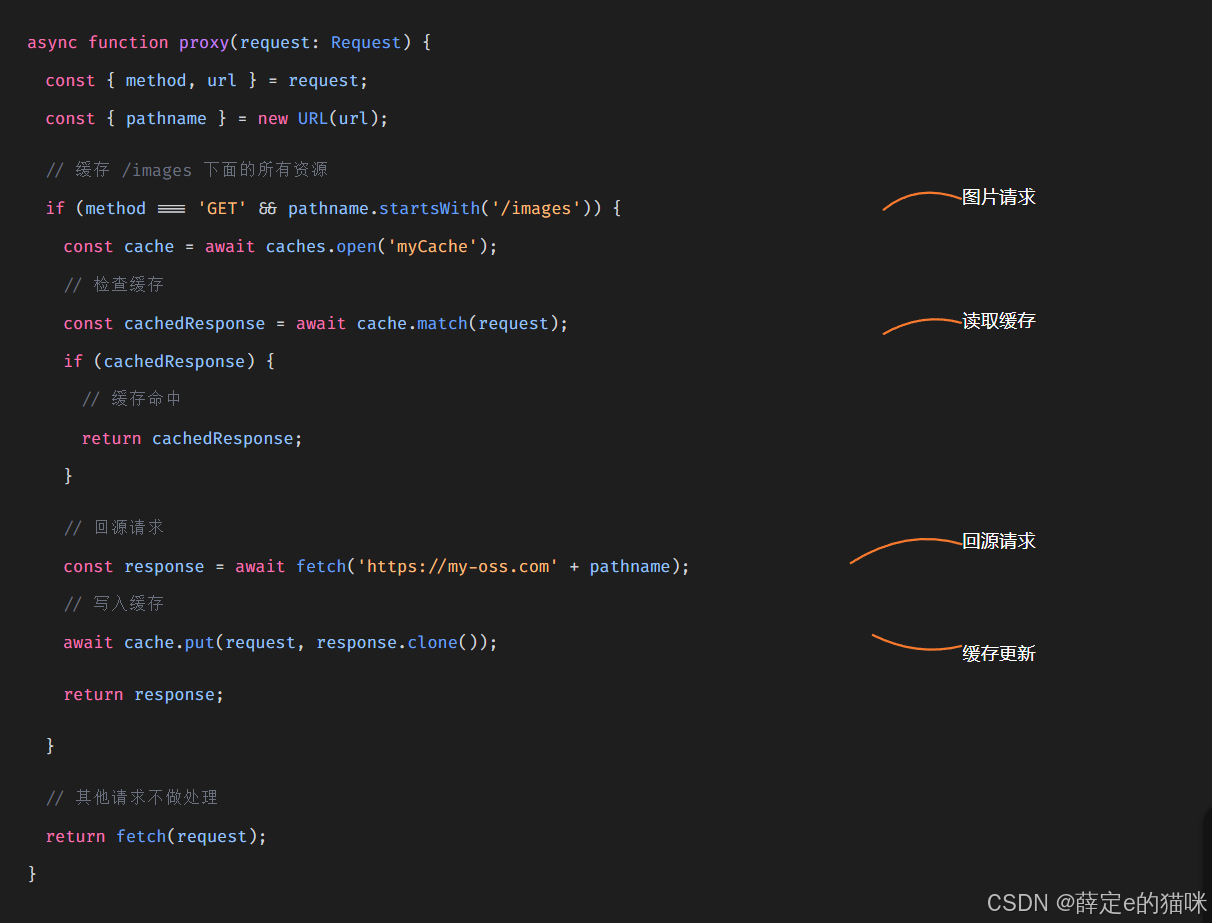
上面代码用到的所有API都是标准Web API,在这个例子中,我们接收前端用户的图片请求,检查缓存的存在性,不存在则回源到对象存储,随后更新缓存,这样用户在下一次访问时便可直接读取缓存,而不用访问原服务器。
从函数计算到边缘计算
函数计算:
函数是 Serverless 架构中最小执行单元,专注完成一件具体任务:
- 图片格式转换
- 日志处理与转存
- AI 推理
- Web 请求处理(页面渲染、接口响应)
Serverless = Serverless Computing 直译是无服务器计算。但不是真的没有服务器,而是开发者不用管服务器。------- 平台厂商负责服务器运维、扩容、宕机、带宽、安全、系统更新等所有底层工作,开发者只写业务代码。
- FaaS(Function as a Service) 函数即服务
最常见的 Serverless 形态,比如阿里云函数计算、腾讯云 SCF、Cloudflare Workers、AWS Lambda。
主流云厂商都提供 Web 函数,可以直接接收 HTTP 请求,返回 HTML/JSON/ 文件等。当大量并发请求进来时,Serverless 平台会自动启动多个函数实例并行处理,实现弹性扩缩容。
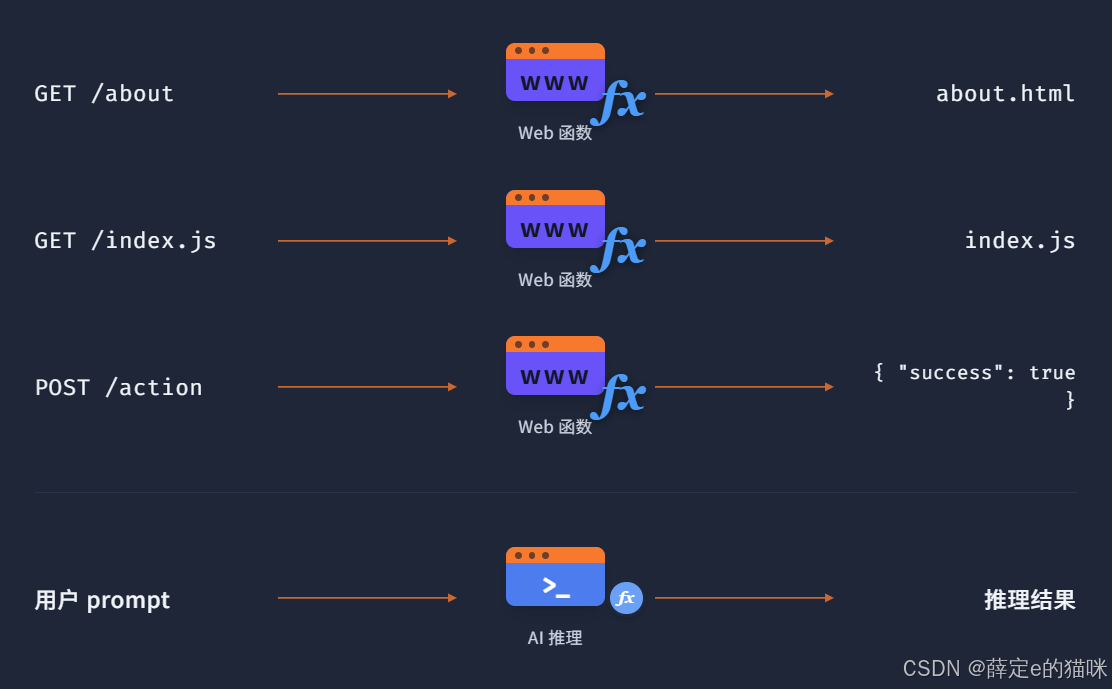
边缘计算 = 分布式的函数计算
把函数计算从 “中心机房” 部署到 CDN 边缘节点 上,就变成了边缘计算。它天生具备:
- 分布式部署
- 就近执行
- 低延迟
- 高并发
- 无状态弹性扩缩
现代 CDN 几乎都集成了边缘函数能力,让开发者可以在节点上直接运行代码,实现各种灵活逻辑:
- 图片自适应格式(WebP/AVIF)
- 请求改写与重定向
- A/B 测试
- 鉴权与防盗链
- 地域分流
- 缓存控制
边缘函数实战:图片防盗链
利用边缘函数,可以非常简单地实现防盗链,防止其他网站直接引用你的图片资源。
实现思路:浏览器在加载跨域图片时,会自动带上 Referer 请求头,表示当前图片所在页面的地址。
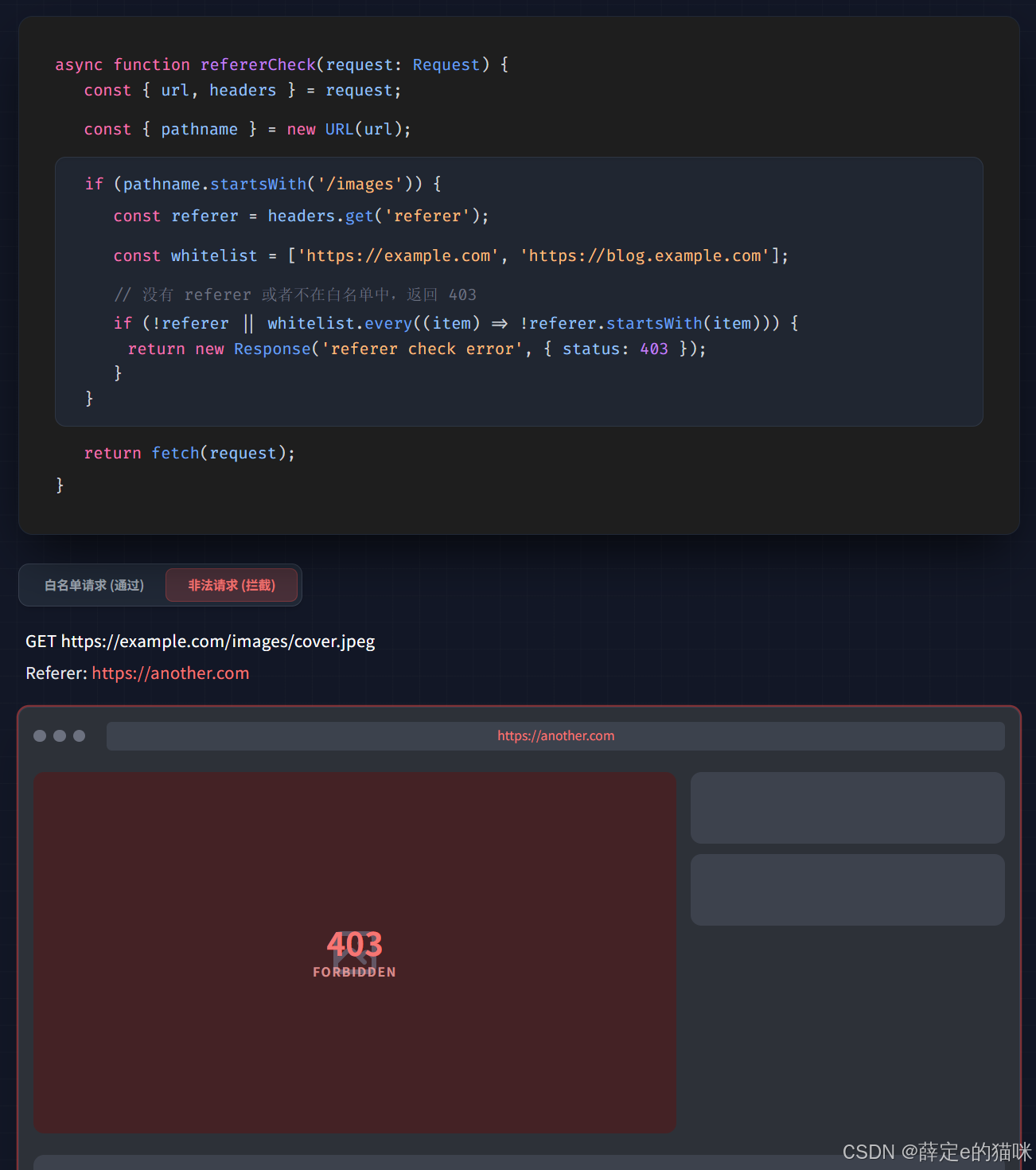
在下面这个函数中,入参request表示从游览器发起的请求,随后从url上取出pathname,并判断前缀是否为images,因为在这个函数中我们只对图片请求进行处理。
接着获取referer请求头来判断它是否在白名单中,如果不满足条件则返回403响应,表示拒绝访问图片。之所以可以这样判断,是因为游览器发起图片请求时,会自动在Referer头中带上该图片所在的页面地址。在盗猎网站中Referer头指向异常地址,如此,便无法通过函数判断达到防止第三方网站引用源站图片的目的。
Cloudflare 免费服务全汇总
很多刚接触 Cloudflare 的朋友都会有一个困惑:哪些服务是真正免费的?免费额度在哪看?一不小心操作错了会不会莫名扣费?
本篇就把日常最常用的 6 大免费服务 一次性讲清楚,包含免费额度、查看用量的方法,以及使用注意事项,让你安心白嫖不踩坑。

免费 CDN + DNS 解析
这是 Cloudflare 最基础、最核心的免费服务,无限流量,永久免费。
DNS:(Domain Name System):网络通信靠 IP 地址(如 220.shturl.cc/R)定位服务器,但数字难记,DNS 负责把好记的域名(如 baidu.com)翻译成对应的 IP 地址,让你能正常访问网站。
- 你在浏览器输入 baidu.com;
- 设备向 DNS 服务器查询这个域名对应的 IP;
- DNS 服务器返回 IP 地址;
- 你的设备拿着 IP 去连接目标服务器,完成访问。
使用方法
- 把域名的 DNS 服务器修改为 Cloudflare 提供的地址
- 在 Cloudflare 后台添加域名并完成解析
- 解析记录开启橙色云朵代理
橙色 = 启用 CDN + 防护
灰色 = 仅 DNS 解析,不走 Cloudflare CDN
只要正常接入并开启代理,即可全程使用免费 CDN 加速与 DNS 服务,无流量限制。
具体操作和详细内容可以参考之前写过的一篇文章: 【大模型开发】低成本获得域名,使用 Cloudflare 搭建反向代理,本地(国内)通过 API 直接调用 Gemini 语言模型
Workers & Pages
这两项服务有免费额度,超出才计费,普通个人使用基本足够。
- Workers
免费计划里常见额度是每天 100,000 次请求、最多 100 个 Worker、每次调用 10 ms CPU、128 MB 内存。这里的 CPU 时间不是网络等待时间,fetch() 等远程接口返回通常不算 CPU;
真正消耗 CPU 的是 JSON 大量处理、加解密、压缩、循环计算这些东西。所以 Workers 很适合做“入口层”,但不适合把传统后端整套搬上去。
- Pages
Pages 的好处是顺手。你把仓库接上去,Cloudflare 帮你构建和发布,预览部署、回滚、自定义域名都在一个流程里。它对静态资源分发非常宽松,但不是“无限构建”。
免费计划常见限制是每月 500 次构建、1 个并发构建、单次构建 20 分钟、单站点 20,000 个文件、单文件 25 MiB。普通博客很难撞到这些限制,但如果你频繁 push,或者把视频、模型文件、压缩包直接放进项目,就很容易出问题。
R2 对象存储
R2 可以理解成 Cloudflare 的对象存储,定位类似 OSS、COS、S3。它适合放图片、附件、导出文件、构建产物、PDF、压缩包。R2 最吸引人的地方是 Internet 出网流量免费,这一点对个人站长很友好,尤其是博客图片和下载文件。
但 R2 不是“所有东西都免费”。免费层常见额度是 10 GB-month 标准存储、每月 100 万次 A 类操作、每月 1000 万次 B 类操作,出网流量免费。A 类操作大致偏写入、列举、复制、创建这类动作;B 类操作更偏读取和对象元信息查询。也就是说,如果一张公开图片被别人盗链,带宽本身可能不收费,但读请求次数仍然会涨。
所以 R2 最好和缓存策略一起用。公开图片可以走 Cloudflare Cache,热点资源尽量让边缘缓存命中;需要控制访问的文件,可以用 Workers 做签名 URL 或防盗链。
D1 免费数据库
D1 是 Cloudflare 原生 SQL 数据库,体验上很像 serverless SQLite。它适合放小型结构化数据,比如评论、留言、订阅邮箱、用户配置、任务状态、博客元数据。它不适合放图片、PDF、视频这类大对象,这些应该放 R2,D1 只存文件地址和元数据。
D1 免费计划常见限制包括每个账号 10 个数据库、单库 500 MB、账号总存储 5 GB、每日 500 万行读取、每日 10 万行写入、7 天 Time Travel。这里最关键的是“行”,不是“请求”。一次没有索引的查询,如果扫了很多行,就算最后只返回几条,也会消耗 rows read。
Zero Trust 零信任安全
Zero Trust 是 Cloudflare One 里的一整套安全产品线,名字听起来有点大。个人用户最先用到的通常是 Tunnel 和 Access。Tunnel 负责把内网服务接到 Cloudflare,Access 负责在访问前加身份验证。
传统做法里,如果你想从外网访问家里的 NAS、开发机、后台面板,往往要开公网端口、配反代、处理证书,还要担心源站 IP 暴露。Tunnel 的思路反过来:内网机器运行 cloudflared,主动连到 Cloudflare,外部请求再由 Cloudflare 转进来。这样你不需要把 80、443、SSH 这些端口直接暴露出去。
官方账号限制里,Tunnel 相关额度对个人用户非常宽松,例如 tunnel、route、virtual network 的账号级限制都很高。实际使用时,真正要小心的不是额度,而是安全策略。不要把没登录保护的后台直接映射到公网域名。至少配 Access,用邮箱、身份提供商、一次性 PIN 或其他策略拦一下。
如果只是临时给别人看本地项目,Tunnel 很方便;如果是长期暴露 NAS、后台、内部文档,那就应该把 Access 一起配好。Tunnel 解决“怎么连进来”,Access 解决“谁能进来”。这两个东西配在一起,才是 Zero Trust 对个人用户最有用的部分。
Turnstile 人机验证
Turnstile 是 Cloudflare 的人机验证服务,可以理解成更轻量的验证码替代方案。它不要求你的网站必须接入 Cloudflare CDN,普通网站也能嵌入。免费计划常见能力包括最多 20 个 widget、无限验证请求、每个 widget 10 个 hostname、最多 7 天 Analytics 回看。
Turnstile 最适合放在登录、注册、评论、联系表单、敏感写接口前面。用户在前端通过验证后,会拿到一个 token;后端或者 Worker 必须拿这个 token 去调用 siteverify。只有验证通过,才继续写数据库、发邮件或提交表单。
这里千万不要只做前端校验。前端显示了 Turnstile,不代表接口安全了。攻击者完全可以绕过页面,直接请求你的 API。所以 Turnstile 的正确接入方式一定是“前端拿 token,服务端验 token”。如果你的后端就是 Workers,那验证逻辑放在 Worker 里会很自然。
总结
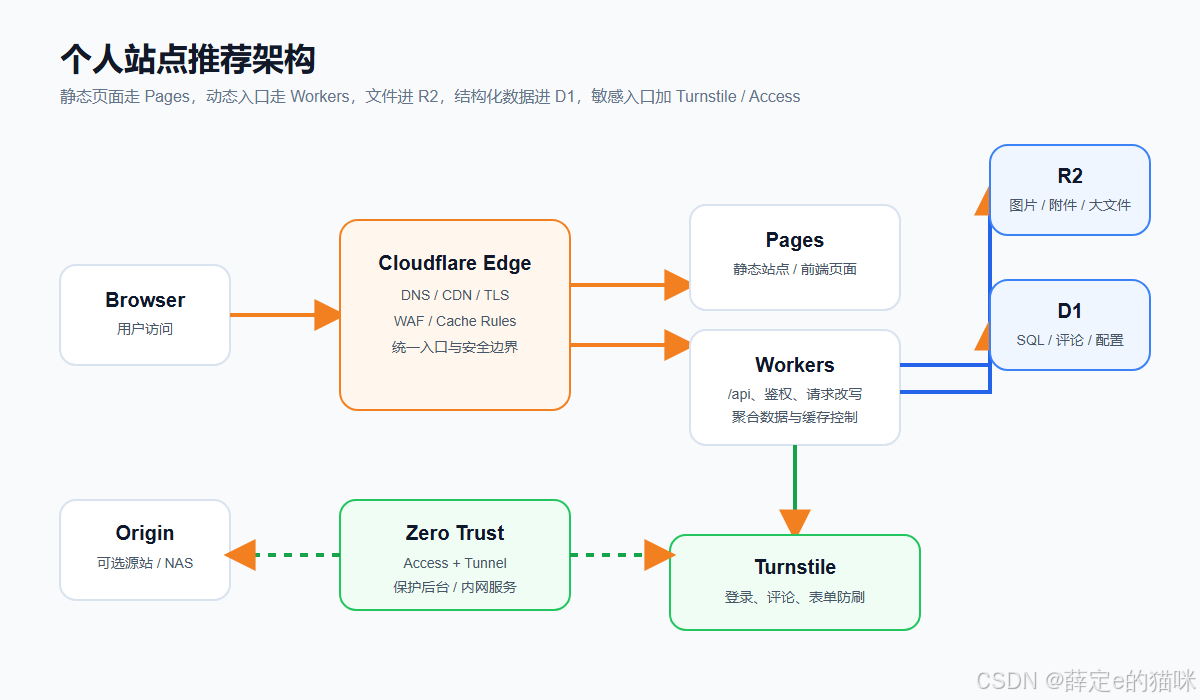
Cloudflare 对个人用户友好,是因为它把很多原本要自己搭的基础能力放到了同一个平台里。DNS、CDN、TLS、边缘函数、对象存储、SQL 数据库、人机验证、内网穿透,这些东西单独看都不复杂,但组合起来就能撑起一个很完整的小型网站。
真正要记住的不是一堆额度数字,而是几条边界:Pages 管站点,Workers 管入口逻辑,R2 管文件,D1 管结构化数据,Turnstile 管人机验证,Tunnel 和 Access 管内网与后台入口。免费额度只是起点,长期稳定靠的是把东西放对位置,并且定期看用量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)