最强AI Agent也扛不住真本事?这场“终极考试“把顶尖模型考哭了
2026年6月10日,人工智能行业迎来了一场"震撼性"的评测结果发布。由加州大学伯克利分校联合250余位行业专家共同提出的新评测基准——Agents' Last Exam(简称ALE),给当下火热的AI Agent技术泼了一盆冷水。

一场"不讲情面"的考试
和以往常见的AI测试不同,ALE不再是在抽象的数学题或逻辑题上打转,而是直接给AI布置"真实工作"。这项测试收集了1490个来自真实从业者日常工作的任务,涵盖制造、法律、医疗、视觉媒体等多个领域。比如"画3D模型"、"达芬奇绿幕合成"、"音乐转谱生成PDF总谱"等,都是真实行业里每天在发生的工作。
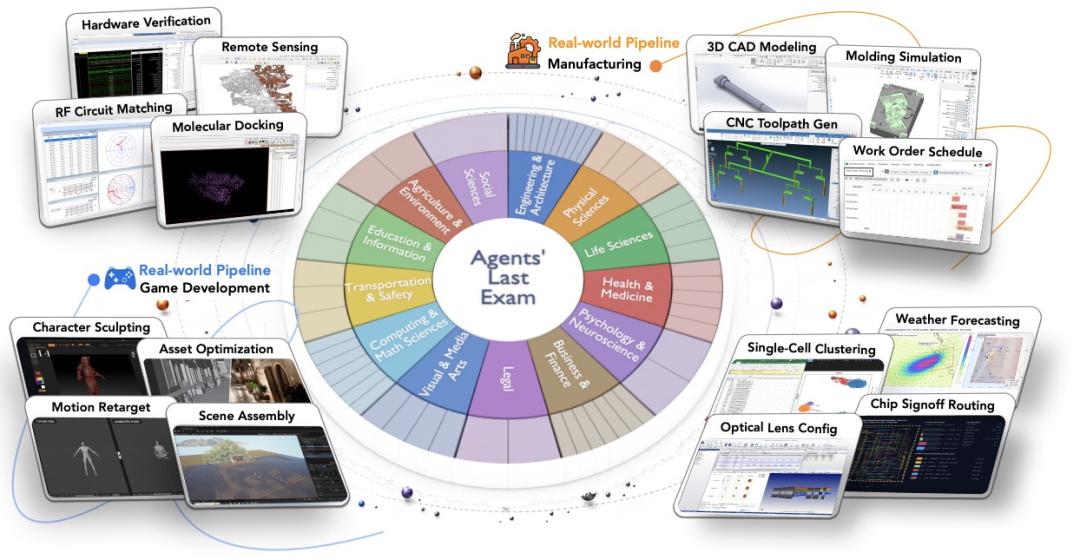
评测对象是Generalist Computer-Use Agent(通用计算机使用代理),这类AI需要会操作界面、运行命令行、处理文件、写代码、调用工具——也就是真正像一个"数字员工"一样去干活。
成绩单让人咋舌
成绩出来,整个行业都安静了。
主流模型在ALE最难层级的平均完整通过率仅为2.6%。就算是目前业界公认的最佳配置组合(Codex + GPT-5.5),完整通过率也只有8.6%。更令人咋舌的是,Claude Code这个被寄予厚望的工具,直接"挂零",一分未得。
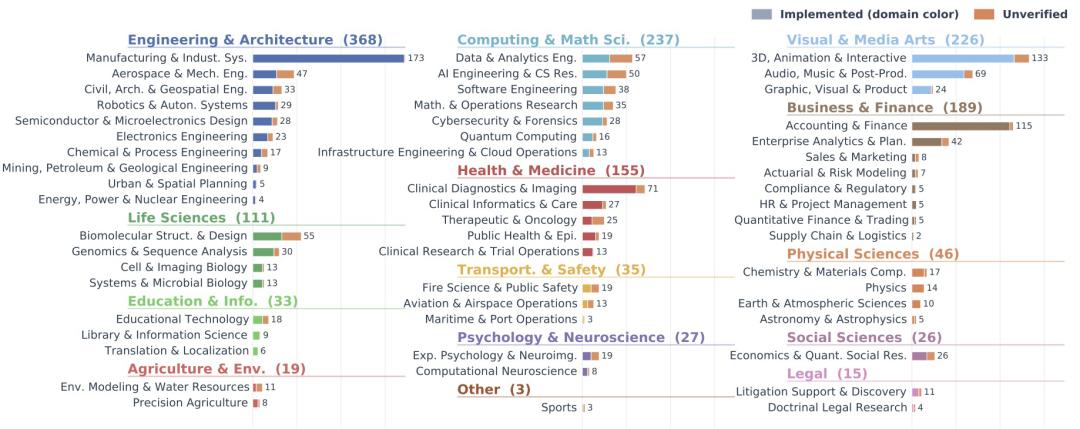
具体来说,Claude Opus 4.7在106个任务中,只完整完成了4个,完全通过率仅3.8%。Kimi K2.5和Gemini 3.1 Pro更是全军覆没,通过率为0%。
考不好,是因为"不够聪明"吗?
有人可能会问:AI不是能下棋赢人类吗?怎么连这种考试都过不去?
研究团队给出的答案很明确:问题不在AI本身,而在评估体系。之前的benchmark已经无法衡量AI在真实、长流程、具备经济价值工作中的表现。
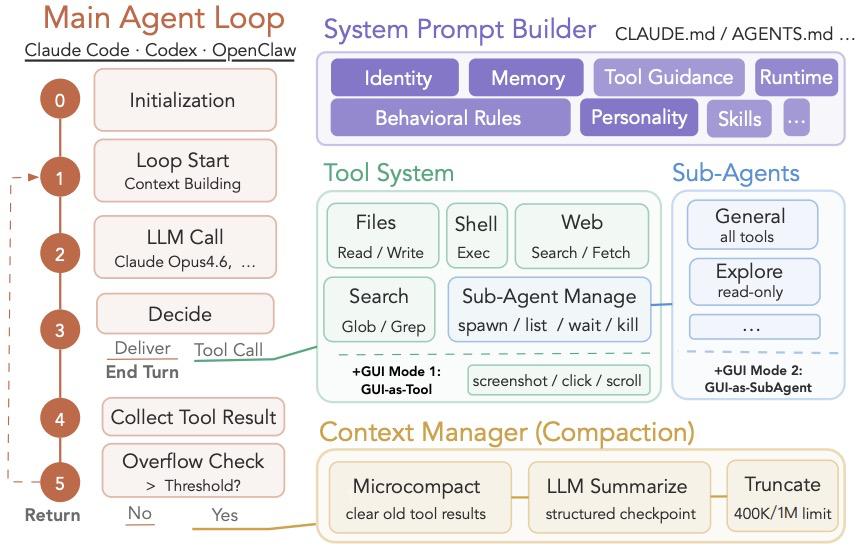
ALE还深入分析了AI失败的原因。以Claude Code + Opus 4.7为例:
理解问题占比31%
方法问题占比47%
执行问题占比22%
两项合计高达78%的问题出在理解和规划上,说明瓶颈在于领域知识,而不是AI会不会执行。换句话说,AI不是不能干活,是不知道"怎么干"和"干这个活需要哪些专业知识"。
行业反思与未来
测试发起人加州大学伯克利分校团队表示,ALE只是一个开始。该基准将持续更新,任务池会扩展至新行业和新工作流,并定期将私有任务轮换进入公开集,确保评测始终走在技术前沿。
目前该测试已公开部分任务,公开集与完整任务池的通过率相关系数为0.89,意味着测试结果具有较好的代表性。
结语
这场"最后的考试"给整个行业敲响了警钟:AI的进步不能只看benchmark上的数字,更要看能不能真正帮人类把活儿干好。正如测试团队所说,"只有当AI真的能通过这场考试,才算具备了持续完成真实专业工作的能力,benchmark上的提升才更有价值"。
未来AI Agent的战场,不在抽象的分数板上,而在真实的业务场景里。谁能在这场"真本事"的较量中胜出,谁才能赢得市场的认可。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)