大模型只能说话,Agent 让它长出手脚做事
一、Agent 的本质
大模型能理解语言、能推理、能创作——但它只能输出文字。
你让它查天气,它只能回复"我可以帮你查天气"。你让它发消息,它只能说"建议你这样写"。它能给你建议,但留不下任何行动。
这是 Agent 系列要回答的核心问题:怎么把一个只会"预测下一个词"的系统,变成一个能帮人"做事"的系统?
答案很简单:给它装一个代理层。
过去,人与大模型的交互只有一条路:输入文字,输出文字。大模型再强,也只是一个能说会道的顾问——它分析问题、给出建议,但什么都留不在真实世界里。
Agent 系统改变了这一点。它成为人与大模型之间的代理:LLM 负责推理和决策,Agent 负责把决策变成真实操作——调接口、操作外部系统。模型不再只是回答问题,而是能真的帮人做事。
这个代理层由四个组件构成:
- • Function Calling:LLM 与 Agent 之间的"交互语言"
- • Skill:定义"遇到这个场景该怎么做"
- • MCP:定义"这个能力从哪来、怎么连接外部系统"
- • Memory:管理上下文,让模型"记得"之前说过什么、做过什么
整个 Agent 系统就是这四者的整合。
二、Function Calling:LLM 与 Agent 的对话语言
2.1 模型没有在"调用",它在"预测"
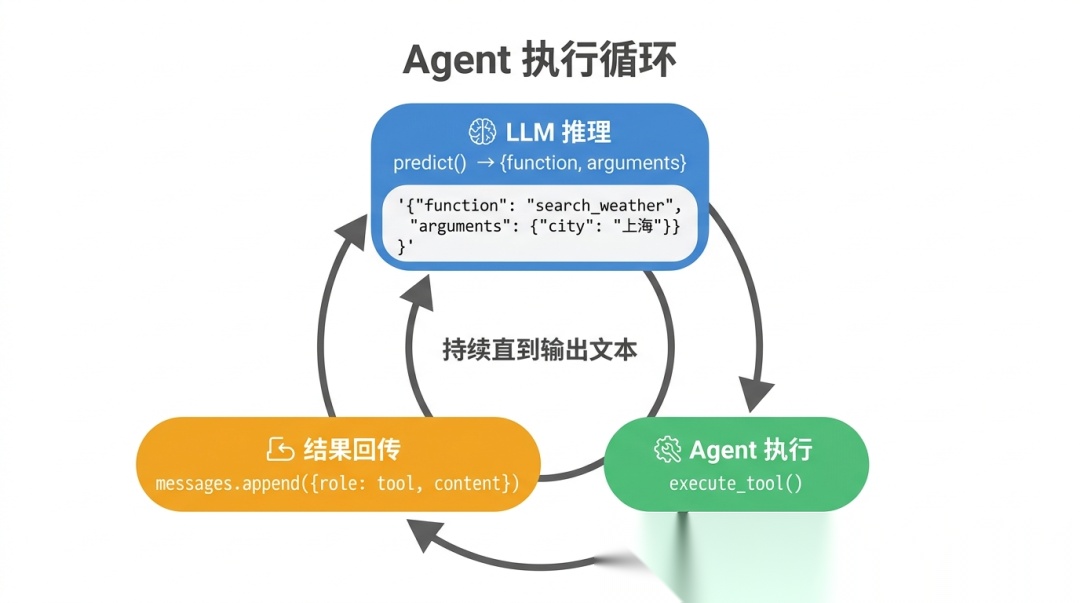
当你对 Agent 说"上海今天天气怎么样",大模型内部生成的不是一段回复,而是一段 JSON:
输入: "上海今天天气怎么样?"模型生成的(给代码看的,不是给人看的):{ "function": "search_weather", "arguments": {"city": "上海"}}
模型没有真的调用函数。它只是"预测"出了这段 JSON——就像它预测"今天天气晴,气温26°C"一样自然。真正执行这个调用的是外面的 Agent 代码:
# Agent 解析模型输出的 JSONtool_call = {"function": "search_weather", "arguments": {"city": "上海"}}# 真正执行搜索result = search_weather(city="上海") # → "晴,26°C"# 把结果塞回给模型,让它继续"想"messages.append({"role": "tool", "content": "晴,26°C"})
分工很清晰:LLM 做决策(决定调什么工具、传什么参数),Agent 做执行(真正调 API、读文件、跑命令)。
2.2 模型怎么学会输出 JSON
靠训练。SFT 阶段喂了大量这样的数据:
用户: 帮我查一下北京天气助手: {"function": "search_weather", "arguments": {"city": "北京"}}[工具返回: 晴,26°C]助手: 北京今天晴,气温26°C。
模型见过足够多这样的例子,就学会了:遇到"查天气"的请求,下一步应该输出 JSON 格式的工具调用——这和它学会"Thank you very → much"的机制完全一样。
Function Calling 不是新能力。它就是"预测下一个词",只不过这次预测出来的是一段函数调用的 JSON。
2.3 最小的 Agent:一个循环
整个 Agent 的核心,是一条 for 循环:
def run_agent(user_message, max_steps=10): messages = [ {"role": "system", "content": "你是一个能使用工具的助手。"}, {"role": "user", "content": user_message} ] for step in range(max_steps): response = llm.predict(messages, tools=available_tools) if response.type == "text": return response.text # 模型输出文字 → 任务完成 if response.type == "tool_call": result = execute_tool(response.function, response.arguments) messages.append({"role": "tool", "content": result}) # 执行后继续循环
每一次循环,消息历史都在增长——加入了新的工具调用和返回结果。模型看着这些内容继续推理,越来越接近最终答案。
但消息历史越来越长,上下文窗口是有限的。这就是后面 Memory 系统存在的理由。
三、Skill 与 MCP:能力定义与能力接入
Skill 和 MCP 解决的是两个不同层次的问题。
3.1 为什么需要 MCP:接入外部能力的代价
让 Agent 调用一个天气 API,看起来很简单。真正去做,问题才出来:
没有 MCP 之前:你的 Agent 要接 GitHub → 写一套 GitHub 集成代码你的 Agent 要接飞书 → 写一套飞书集成代码你的 Agent 要接数据库 → 写一套数据库连接代码换一个 Agent 平台 → 上面三套全得重写一遍
每个外部系统有自己的接口规范、认证方式、错误处理。接入一个系统平均要写几百行代码,换一个平台全部重来。工具只需要写一次,但每次换平台都要重写。
MCP 正是为了解决这个问题——它是统一的协议规范,只要工具按 MCP 实现一次,任何支持 MCP 的 Agent 都能直接用,不需要重复对接。
注意:MCP 是协议规范,GitHub Server、天气 Server 是实现了这个协议的具体工具。 USB 是接口标准,罗技鼠标是按标准造的设备。本文后续说的"MCP Server"都是指实现了 MCP 协议的具体服务。
3.2 MCP 的架构
MCP 的三层架构:
- • MCP Host:Agent 的运行环境,管理所有连接和通信
- • MCP Client:Host 内部与每个 Server 保持一对一连接
- • MCP Server:提供具体能力的独立服务,暴露 Tools / Resources / Prompts
其中 **Tools(工具)**是 Agent 与 LLM 交互的核心。每个 Tool 就是一个可被调用的函数,通过 Function Calling 格式暴露给模型:
{ "name": "search_weather", "description": "查询城市当前天气", "inputSchema": { "type": "object", "properties": { "city": {"type": "string"} } }}
3.3 为什么需要 Skill:能力怎么被正确使用
MCP 解决了"能力从哪来"的问题,但还有一个问题没有回答:模型怎么知道什么时候该用这个能力?
比如,Agent 接入了飞书 API,有发消息、查邮件、建日程三个 Tool。你说"帮我把会议纪要发给张总",模型面对三个 Tool,它怎么知道该用哪个?发到哪里?格式怎么写?
这就要靠 Skill。
Skill 是一个 prompt 模板 + 元数据的封装,它告诉模型"遇到这个场景该怎么做"。
用一个真正复杂的业务场景来说明——会议纪要 Skill:
---name: meeting_notesdescription: 整理会议纪要并推动后续行动---# 会议纪要 Skill## 触发条件用户提供了会议内容、参会人,或提到"会议纪要"、"总结一下会议"。## 执行流程当模型判断应该使用此 Skill 时,按以下步骤工作:1. **整理纪要**:从用户提供的内容中提取关键讨论点和结论2. **提取行动项**:识别会议中明确的待办,包括负责人和截止时间3. **发送邮件**:调用飞书邮件工具,把纪要发给所有参会人 - 邮件标题:[会议纪要] {会议主题} - {日期} - 邮件正文包含:参会人、讨论要点、行动项清单4. **创建日程**:如果待办中有需要后续跟进的,调用飞书日历建提醒## 注意事项- 用户没有提供完整会议内容时,先反问补充- 提取不到负责人时,默认发给全部参会人确认
这个 Skill 做了 MCP 做不到的事:
- • 判断何时使用:用户提到"会议纪要"时触发
- • 编排多步流程:先整理 → 再提取 → 再发邮件 → 再建日程
- • 指定格式规范:邮件标题怎么写、正文包含什么
- • 处理边界情况:内容不全怎么办、负责人提取不到怎么办
MCP Server 暴露的是三个独立的 Tool(发邮件、查邮件、建日程),Skill 把它们编排成一个完整的业务能力。Skill 的核心价值:在 MCP 提供的原子能力之上,封装出模型能理解的业务逻辑。
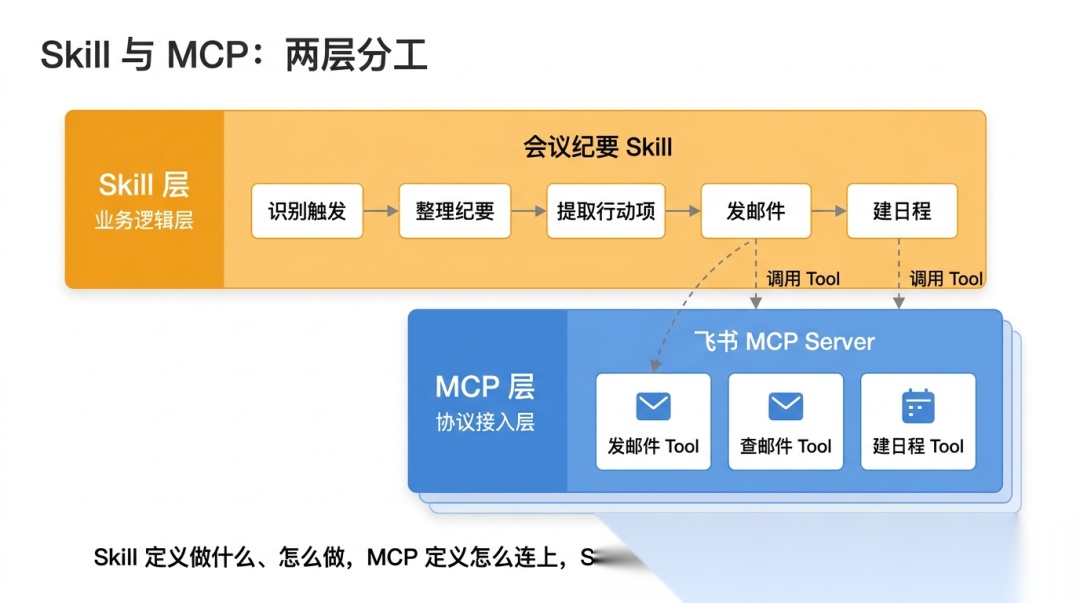
3.4 Skill 与 MCP 的关系
| Skill | MCP | |
|---|---|---|
| 本质 | prompt 模板(内容层) | 连接协议(传输层) |
| 回答的问题 | “遇到这个场景,Agent 该怎么做?” | “这个能力从哪来、怎么被发现?” |
| 类比 | 餐厅菜单(菜品 + 做法 + 点单规则) | 厨房接口标准(确保所有厨具能插上电) |
| 由谁定义 | 业务专家 / 开发者 | MCP 协议规范 |
Skill 定义"做什么、怎么做",MCP 定义"这个能力怎么被连上"。 两者各司其职:没有 MCP,Skill 无从落地;没有 Skill,MCP 的原子能力无法被正确编排成业务场景。
3.5 MCP 的生态
MCP 由 Anthropic 在 2024 年底推出,目前已经得到广泛支持:
- • 工具层面:GitHub、Notion、Google Drive、Slack、飞书等主流服务都有了 MCP Server 实现
- • 框架层面:Claude Code、Cursor、Cline 等 AI 编程工具已原生支持 MCP
- • 社区层面:GitHub 上涌现了大量开源 MCP Server,覆盖数据库、文件系统、邮件、日历等场景
四、Memory:LLM 其实没有记忆
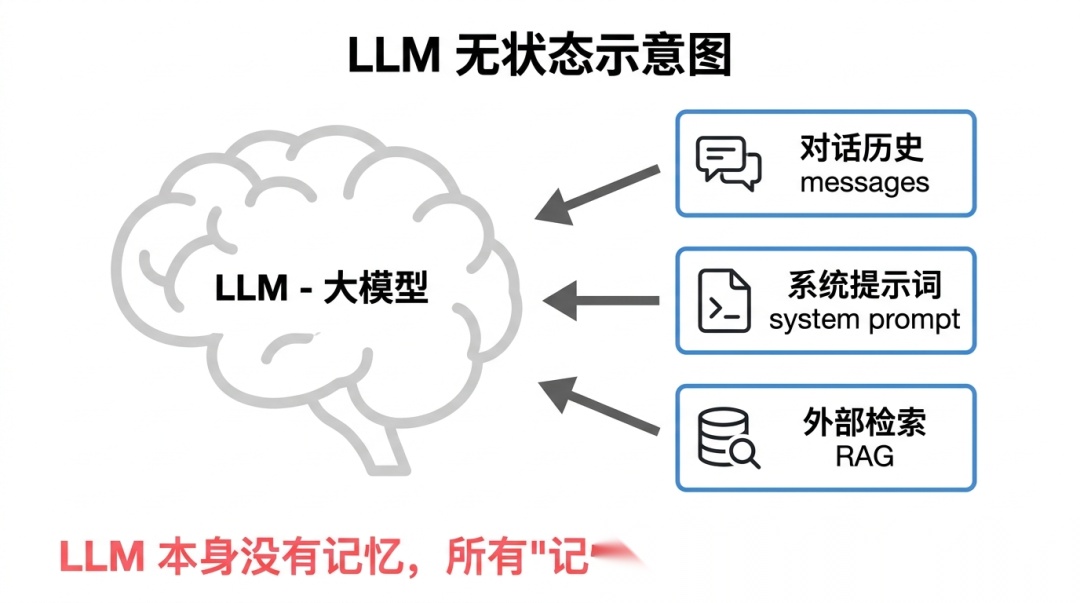
4.1 核心前提:LLM 本身是无状态的
大模型本身没有记忆。它的所有"记忆"都来自于输入的上下文。
你问"我们刚才聊了什么",Agent 能回答,不是因为它记住了上一次对话——而是因为上一次对话的内容被当作输入传给了它。
无论是对话历史、系统提示词,还是外部检索回来的知识——本质上都是把信息塞进输入里,让模型感觉它有记忆。
这才是理解 Agent Memory 的关键:问题不是"Agent 记不记得上次的事",而是"这次请求的输入里有没有包含上次的信息"。
4.2 记忆的三个来源
理解了无状态的前提之后,Agent 的"记忆"实际来自三个地方:
对话历史:当前会话的所有交互记录。用户说了什么、Agent 回复了什么、调用了哪些工具、返回了什么结果——都在消息历史里。
系统提示词:Agent 的角色设定、行为规则、边界约束。每次请求都会带上这部分内容,是最稳定的"记忆"。
外部检索(向量数据库 / RAG):跨会话场景下,从外部存储检索相关内容拼入上下文。通过向量相似度匹配实现。
4.3 记忆的管理策略
输入长度有限,Agent 必须主动管理"记什么":
摘要压缩:消息历史太长时,用模型把它压缩成一段摘要,替换原始内容。在有限窗口内塞更多轮对话。
选择性写入:不是所有信息都值得记住。Agent 可以只把真正重要的信息(用户偏好、关键决策、结论)写入外部存储。
分层存储:标准化信息(用户名、公司名)用 KV 数据库精确匹配;模糊知识用向量检索。不同信息用不同的存储和召回策略。
4.4 召回精度问题
向量检索基于语义相似性,但"相似"不等于"相关"。用户说"跟上次一样处理",可能召回完全不相关的内容。
解决方案:元数据过滤(按时间、类别筛一遍再检索)、重排(Rerank 先选 20 条候选再用精准模型选出 3 条)、混合检索(向量 + 关键词 + 元数据一起用)。
五、完整架构
到这里,四个组件都讲清楚了。来看它们怎么整合成一个完整系统:
用户输入: "帮我查一下上海天气,然后发给张总" ┌─────────────────────────────────┐ │ Agent 系统 │ ┌─────────────┐ │ ┌──────────┐ ┌──────────────┐ │ │ 用户输入 │───────►│ │ Memory │ │ Skill Registry│ │ └─────────────┘ │ │ 召回相关 │ │ 工具列表 │ │ │ │ 记忆 │ │ │ │ │ └────┬─────┘ └──────┬───────┘ │ │ │ │ │ │ ┌────▼───────────────▼───────┐ │ │ │ LLM(大模型) │ │ │ │ 理解输入 + 参考记忆 │ │ │ │ 做决策(Function Calling) │ │ │ └────────────┬───────────────┘ │ │ │ │ │ Function Calling 输出 │ │ {"function": "search_weather", │ │ "arguments": {"city": "上海"}}│ │ │ │ │ ┌─────────────▼────────────┐ │ │ │ MCP Client(客户端) │ │ │ │ 按 MCP 协议路由到外部 │ │ │ └─────────────┬────────────┘ │ │ │ MCP 协议 │ └───────────────┼──────────────────┘ │ ┌─────────────────────────────▼────────────────────┐ │ 外部系统(MCP Servers) │ │ ┌───────────┐ ┌──────────┐ ┌──────────────┐ │ │ │ 天气服务 │ │ 消息系统 │ │ GitHub │ │ │ │ (外部 API)│ │(外部 API)│ │ (外部 API)│ │ │ └───────────┘ └──────────┘ └──────────────┘ │ └─────────────────────────────────────────────────┘
流程:用户输入 → Memory 召回相关记忆 → LLM 推理,决定调用 search_weather(Function Calling 输出 JSON)→ MCP Client 通过 MCP 协议连接到外部天气服务 API → 执行结果写回 Memory → LLM 继续推理,决定调用发消息工具 → 通过 MCP 调用外部消息系统 → 返回结果。
5.1 用一个人来比喻
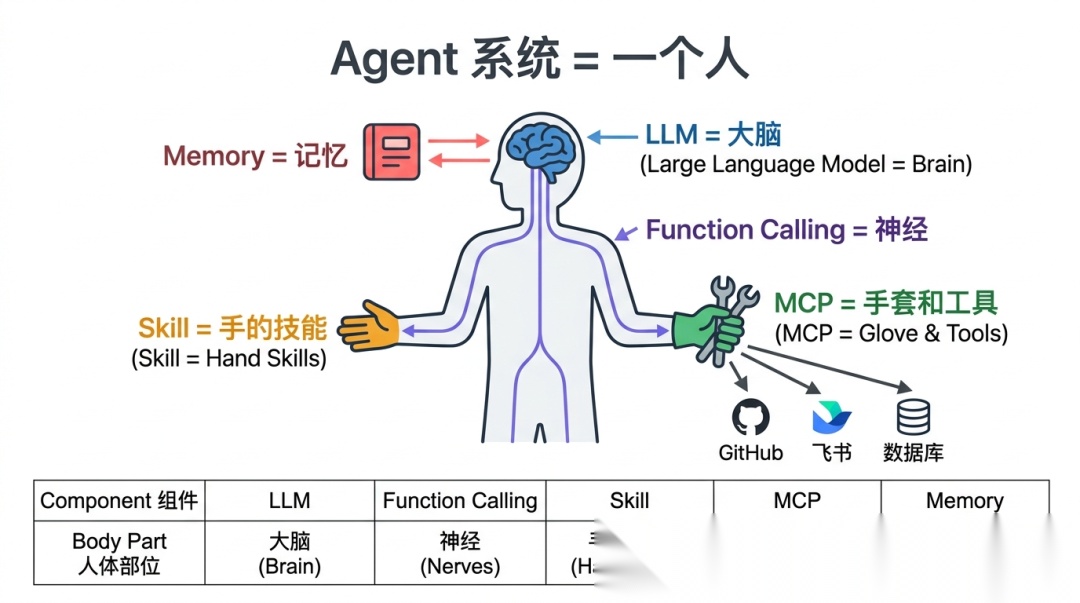
把 Agent 系统想象成一个人:
- • LLM = 大脑。它能思考、能推理、能做决策,但光有大脑只是一个悬浮的思维体。
- • Function Calling = 神经。大脑的决策通过神经传递给身体——FC 就是大脑向 Agent 身体传递"决定"的通道。
- • Skill = 手的技能。大脑知道要做什么,手知道怎么做——Skill 就是手(Agent)知道的各种操作能力。
- • MCP = 手套和工具。手本身能做的事有限,戴上手套、拿起工具,就能做更多的事——MCP 就是 Agent 连接到外部系统的能力扩展。
- • Memory = 记忆。大脑没有记忆,所有知识都来自输入——Memory 就是把信息管理好,随时准备塞进大脑。
| 组件 | 回答的问题 | 人的比喻 |
|---|---|---|
| LLM | “这件事该怎么分析、怎么决策?” | 大脑 |
| Function Calling | “大脑的决策怎么传递出去?” | 神经 |
| Skill | “遇到这件事,手该怎么做?” | 手的技能 |
| MCP | “手怎么连接和使用外部工具?” | 手套和工具 |
| Memory | “之前知道什么、还记得什么?” | 记忆 |
5.2 模块化的价值
这四个组件的模块化,是 Agent 架构最重要的设计:
- • 换模型:Skill/MCP/Memory 不变,只需要改 LLM 的调用方式
- • 换工具:只需要开发新的 MCP Server,Agent 端无需修改
- • 换记忆策略:Memory 的接口不变,换底层实现(换向量库、调召回算法)不影响 Agent 其他部分
六、工程挑战
6.1 上下文窗口爆炸
每次工具调用,消息历史增长一次。20 轮调用的任务,上下文已经相当长——Prefill 越来越慢,最终可能超出窗口容量。
应对:摘要压缩(超阈值时压缩历史)、滑动窗口(只保留最近 N 条)、模型分流(简单决策用小模型)。
6.2 记忆召回精度不足
向量检索的"语义相似"不等于"任务相关"。
应对:混合检索(向量 + 关键词 + 元数据)、上下文感知召回(让模型先理解任务再去检索)、记忆质量控制(写入前过滤)。
6.3 Skill 编排混乱
多 Skill 协作时,模型可能调用顺序不对、重复调用、漏掉关键步骤。
应对:工作流编排(用规则预定义标准流程)、子 Agent 分工(复杂任务拆给专业子 Agent)、安全 Hook(执行前加权限校验)。
6.4 成本控制
多轮、多 Skill 调用,token 消耗可能是普通对话的 10 倍以上。
应对:小模型前置过滤(意图识别用小模型)、结果缓存、步数限制(防止失控)。
七、总结
大模型本质上只做一件事:预测下一个 token。
Agent 系统把它变成了能做事的能力:
- • LLM 负责推理和决策,通过 Function Calling 输出"决定"
- • Skill 定义每个能力"怎么做"
- • MCP 把能力连接到外部系统
- • Memory 管理上下文,让模型能"记得"之前说过的话
Agent = LLM + Function Calling + Skill + MCP + Memory
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献204条内容
已为社区贡献204条内容

所有评论(0)