图神经网络模型
图神经网络
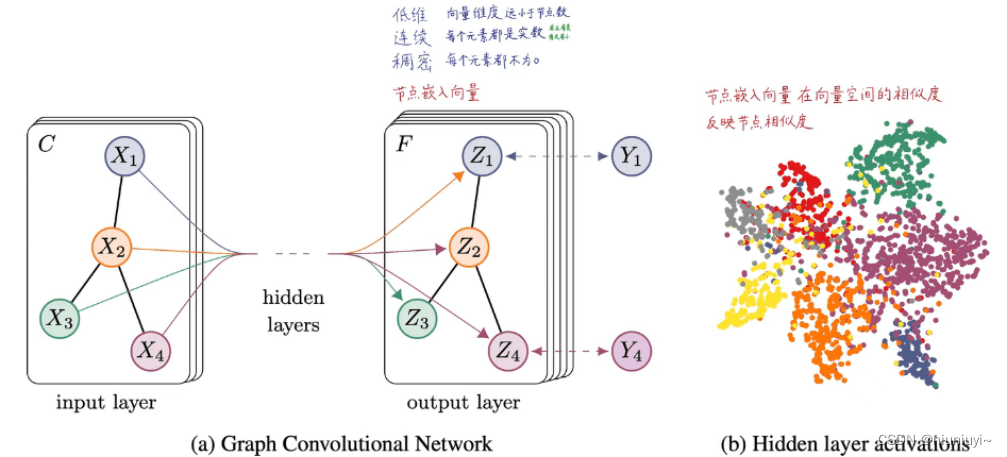
基本图神经网络
GCN(2016)

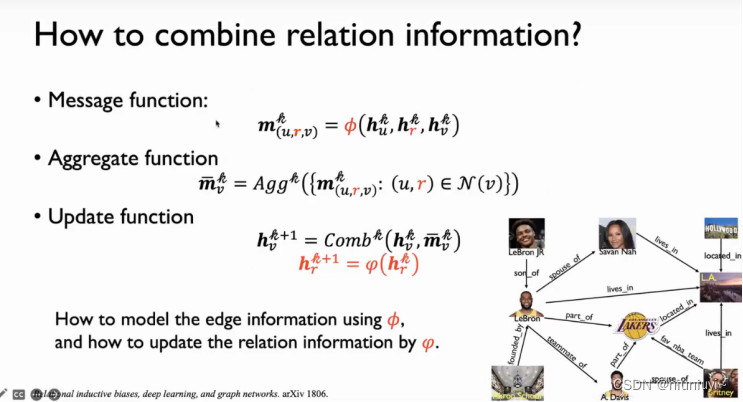
基本方法:
1)聚合邻居信息
2)通过邻域,构建计算图
3)节点逐元素取平均,更新
GCN层与层之间的传播公式: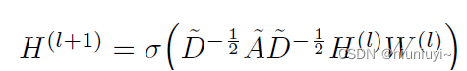
GCN的每一层通过邻接矩阵A和特征矩阵H(l)相乘得到每个顶点邻居特征的聚合,然后再乘上一个参数矩阵W(l),加上激活函数σ做一次非线性变换得到聚合邻接顶点特征的矩阵H(l+1)。
A·H邻接矩阵和特征矩阵相乘,表示聚合邻居信息
D波浪线是A的度矩阵,用于每个节点度的归一化,防止
度数高的节点对度数低的节点特征分布上产生较大差异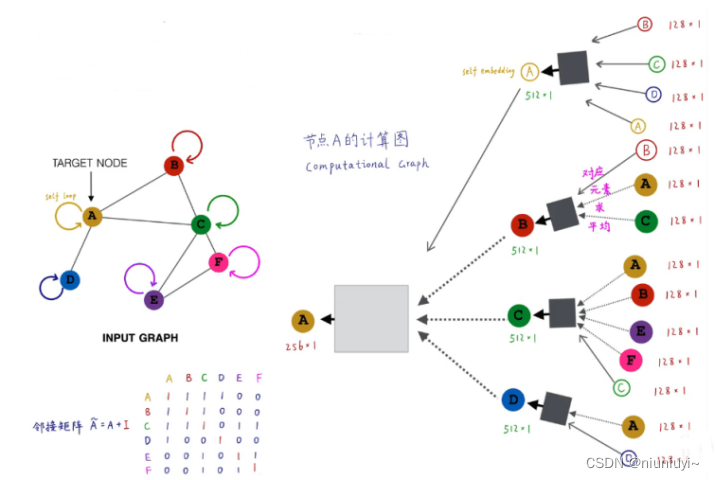
GAT(2017)
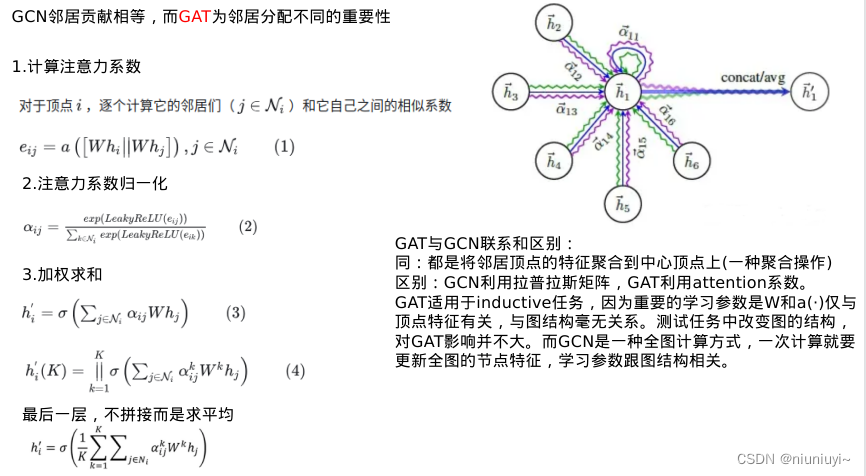
本质就是加权的GCN
归一化其实就是用个softmax
计算好注意力系数,把特征加权求和一下,但是attention还得靠多头来增强,
然后把K个注意力头的多头注意力过程concate一下
一定程度上来说,GAT会更强,因为顶点之间的相关性被很好融入模型
1.直推式的"transductive"通常指的是一种学习方法,仅在特定数据集上进行预测。直推式学习是基于所有已经观测到的训练和测试数据来建立模型的,这种方法是通过已经有标记的节点信息来预测无标记数据节点。
2.归纳的"inductive"通常指的是一种学习方法,其中模型在训练阶段学习到的特征和知识可以泛化到未见过的数据上。
归纳式学习企图基于已观测训练数据,建立一个通用模型,用来预测任何新数据节点。你可以预测任何数据节点,不局限在无标记数据上。
GAT仅仅是应用在了单层图结构网络上,我们是否可以将它推广到多层网络结构呢?
这里我们假设一个有N层网络的结构,每层网络都定义了相同的节点,但是节点之间的关系有所差异。举一个简单的例子,假设有一个用户关系型网络,每层网络的节点都被定义成了网络中的用户,网络的第一层视图的关系可以定义为,两个用户之间是否具有好友关系;网络的第二层视图可以定义为,你评论过我的动态;网络的第三层视图可以定义为你转发过我的动态;第四层关系可以定义为,你at过我等等。
通过这样的定义我们就完成了一个多层网络的构建,他们共享相同的节点,但又分别具有不同的邻边,如果我们分别处理每一层视图视图,然后将他们得出的节点表示单纯相加的话,就可能会失去不同视图之间的协作关系,降低分类(预测)的精度。
基于以上观点,我们提出了一种新的方法:首先在每一层单视图中应用GAT进行学习,并计算出每层视图的节点表示。之后再不同视图之间引入attention机制来让网络自行学习不同视图的权重。之后根据学习的权重,将各个视图加权相加得到全局节点表示并进行后续的诸如节点表示,链接预测等任务。
同时,因为不同视图共享同样的节点,即使每一层视图都表示了不同的节点关系,最终得到的每一层的节点嵌入表示应具有一定的相关性。基于以上理论,我们在每层GAT的网络参数间引入正则化项来约束参数,使其向互相相近的方向学习。大致的网络流程图如下: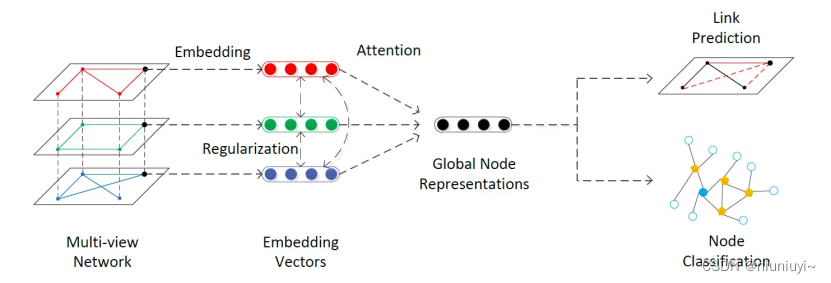
GAE
编码器:输入节点输出向量
解码器:向量点乘数值 反映相似度
优化目标:节点之间的相似度 相似的大不相似的小(与下游任务无关,学习好了可以用于下游任务)
HGNN
基于图的卷积神经网络(GCN)
能够使用神经网络模型对不同输入数据的图结构进行编码,有表示学习方面的优势。
局限:数据相关性可能比成对关系更复杂,这很难用图结构来建模。
数据表示倾向多模态的,视觉连接、文本连接。需要更通用的数据结构模型来学习表示。
超图神经网络(HGNN:Hypergraph Neural Networks) G =(V,E,W)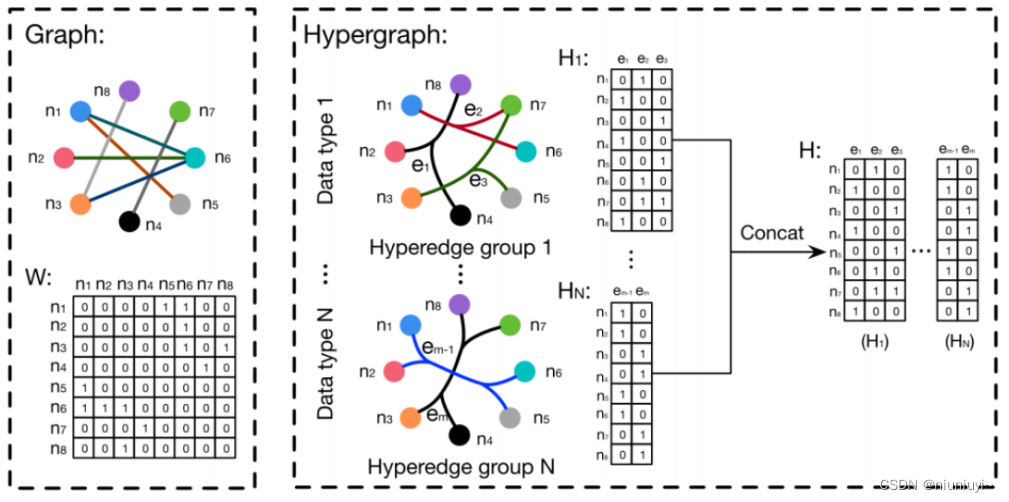 节点-边-节点变换
节点-边-节点变换
超图:允许一条边(超边)链接两个或两个以上的结点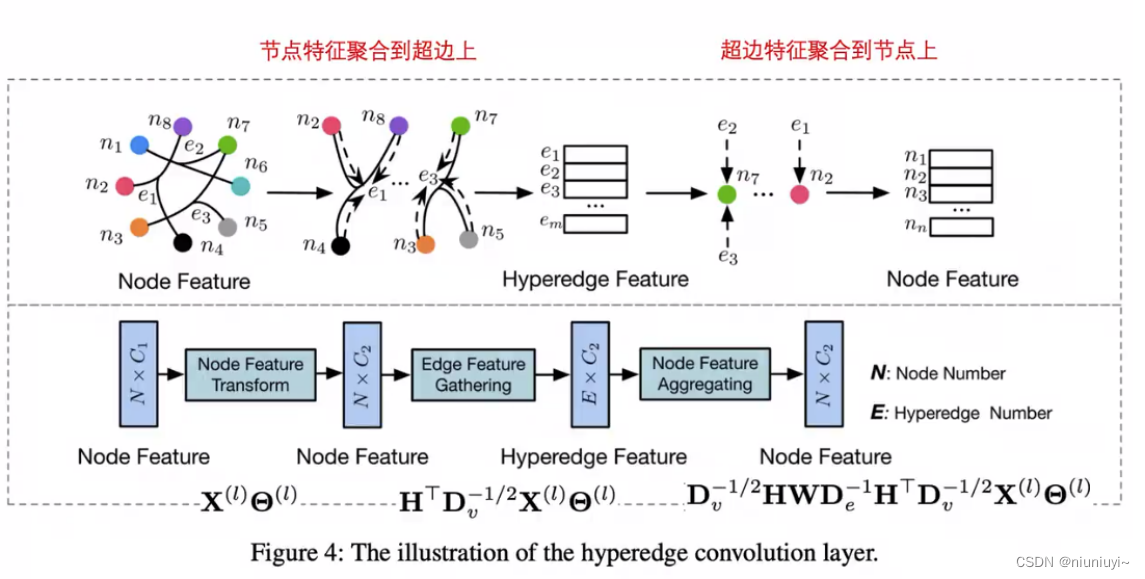
Transformer
Transformer模型的核心思想是计算输入序列中每一个元素和其他的元素之间的相似度,经过加权表示之后,捕获输入序列中元素之间的关系。
采用残差连接和层归一化技术,加权表示学习的能力和稳定性。
避免了使用循环神经网络和卷积网络,从而增加了并行性提高了运算速度。
改进扩展
R-GNN
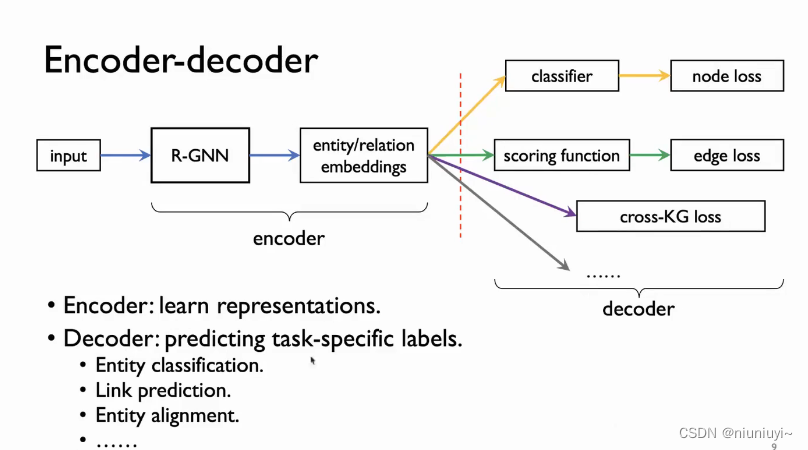
KBGAT(2019)
Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs
之前的卷积网络模型都是单独处理三元组,没有引入 KG 中邻近实体表示中包含的潜在的丰富的语义关系。
要么通过仅关注实体特征来学习KG嵌入,要么以不相交的方式考虑实体和关系的特征。
KBGAT目标:
1)捕捉给定节点的多跳关系
2)压缩某实体在不同关系下的多样性
3)加强现有的知识表示在语义相似关系簇的效果
提出的图注意力模型从整体上捕获了 KG 中任何给定实体的 n 跳邻域中的多跳和语义相似的关系
尽管GAT取得了成功,但由于它们忽略了关系(边缘)特征(它们是KG不可或缺的一部分),因此它们不适合KG。
在KG中,实体根据与之关联的关系扮演不同的角色。
为此,文章提出了一种新颖的嵌入方法,将关系和相邻节点的特征整合到注意力机制中。定义了一个单独的注意力层,这是模型的基础。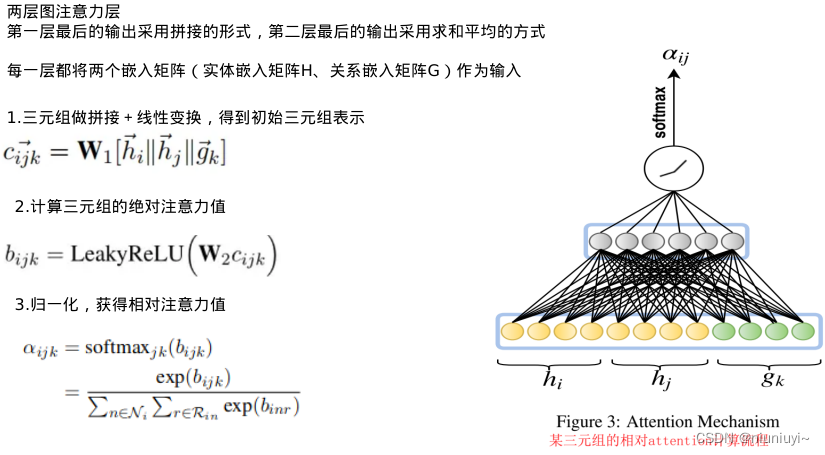
参考了GAT的原理,但是GAT只是学习了节点的嵌入,因此本模型对原有的注意力模型进行了修改,GAT更新节点的方式是注意力系数乘以邻居节点的表示,然后求和;而本模型计算方式是注意力系数乘以该节点所在三元组的表示,然后求和
1、为了获得实体ei的新嵌入,学习与ei关联的每个三元组的表示。我们通过对对应于特定三元组tkij=(ei,rk,ej)的实体和关系特征向量的串联执行线性变换来学习这些嵌入,对应模型W1 表示线性变换矩阵中的初始块。这里的cijk就类似于 GAT 中计算两节点之间的注意力的拼接形式,不过这里加入了关系嵌入gk。W1 表示线性变换矩阵
2.这里的bijk可以理解为在关系rk上实体ei对实体ej的重要性。权重矩阵 W2 参数化的线性变换,LeakyReLU非线性
图显示了单个三元组的相对注意力aijk的计算
原始GAT更新方程3仅聚合来自1跳邻域的信息,而我们的广义GAT使用来自n跳邻域的信息
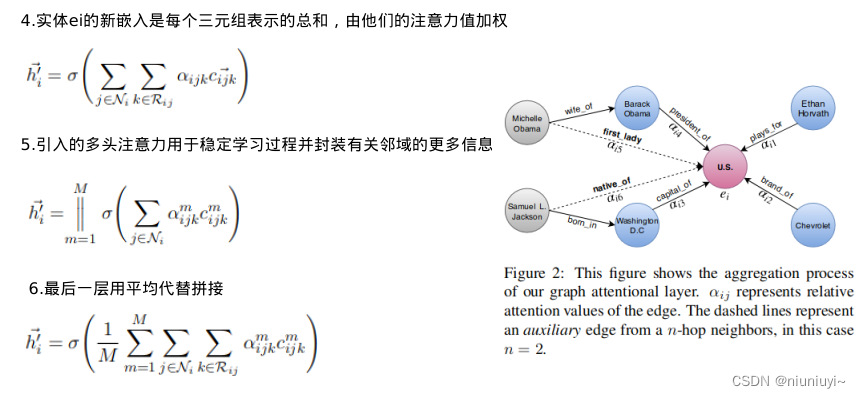
5.M个独立的注意力机制计算嵌入,然后将它们拼接起来
架构中,我们通过为两个实体之间的 n 跳邻居引入辅助关系,将边的概念扩展到有向路径。这个辅助关系的嵌入是路径中所有关系的嵌入的总和。我们的模型迭代地从实体的远邻积累知识。
如图 2 所示,在我们模型的第一层中,所有实体都从它们直接流入的邻居那里获取信息。在第二层中,美国从实体巴拉克奥巴马、伊桑霍瓦特、雪佛兰和华盛顿特区收集信息,这些实体已经从前一层获得了有关其邻居米歇尔奥巴马和塞缪尔 L.杰克逊的信息。通常,对于 n 层模型,输入信息是在 n 跳邻域上累积的。下图 还显示了学习新实体嵌入和在 n 跳邻居之间引入辅助边的聚合过程。
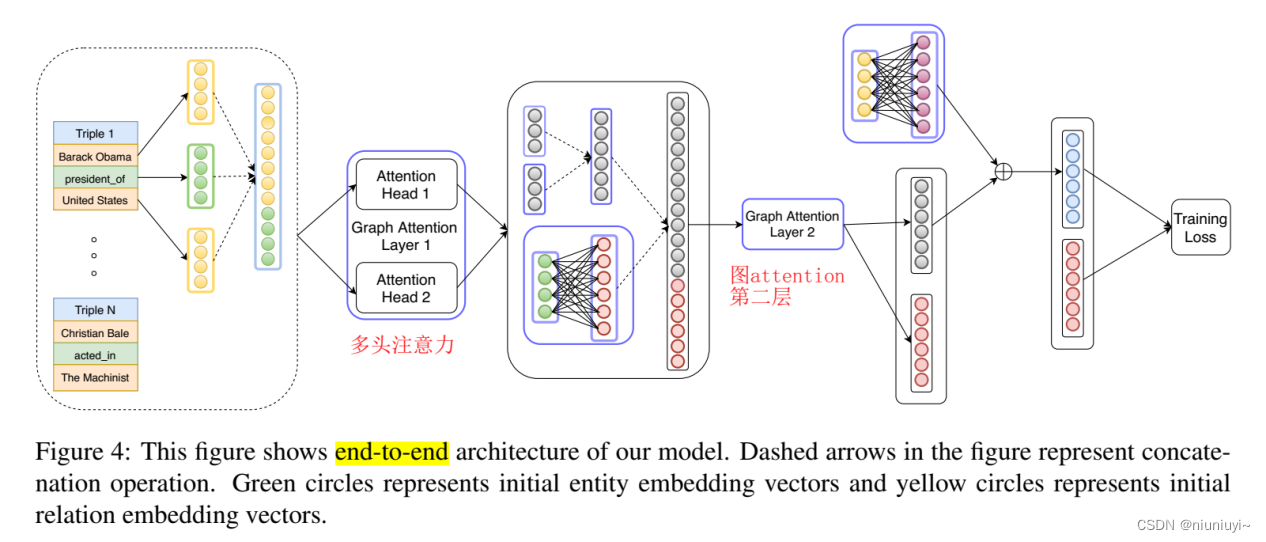
编码器-解码器 GAT-ConvKB
本模型采用了两层图注意力层,第一层最后的输出采用拼接的形式,第二层最后的输出采用求和平均的方式(如果还是拼接,会导致维度过大)
有论文基于此改进 2020CCKS(联合图注意力网络和卷积神经网络的连接预测方法)
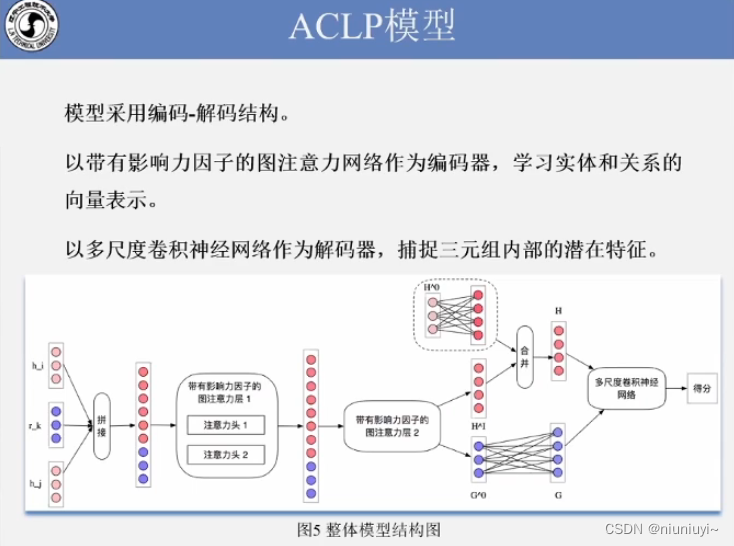

ConvKB 结构:每个三元组表示为一个三列的矩阵,输送到卷积层,多个卷积核对其进行卷积操作输出 feature maps,feature maps 拼接为一个单个的特征向量表示输入,特征向量与一个权重向量相乘,返回三元组得分。
卷积层的目的是分析三元tikj在每个维度上的全局嵌入性质,并推广我们模型中的过渡特征。其中ω m表示第m个卷积滤波器,Ω是表示所用滤波器数目的超参数,*是卷积算子,W∈R Ω k × 1表示用于计算三元组最终得分的线性变换矩阵。
总结

GraIL(2020)
Inductive Relation prediction by subgraph Reasoning
GraIL的核心要点就是提出了用子图去建模,以及inductive推理,并通过注意力机制,将不同的边区分开。它的缺点也比较明显,就是效率比较低且可解释性不够。
RED-GNN(2022)
Knowledge Graph Reasoning with Relational Digraph
RED-GNN提出了一个新的结构,该结构是基于关系路径path的优化。如图所示,如果我们要预测节点a到节点f的信息,那么在做完添加反向边和自环这些预处理之后,我们可以抽取从节点a到节点f的所有路径。之后再合成一个规整的关系子图结构,即relational digraph,之后可以基于这个子图结构去预测节点a和节点f之间是否存在链接关系。
但该做法的时间代价依然很高,我们碰到的现实问题通常是给定了头实体和关系,需要去对所有的尾实体做打分排序,因此这个方法也比较难应用到实际问题中。所以我们进一步对该方法做了改进,运用递归的思路,对节点a的邻居展开去建模,经过一次传播可以获得多个实体的子图表示,具体比较如下图所示。
大规模模型
预训练模型
KG-BERT(2019)
知识图谱补全的常用方法是利用知识图谱嵌入,而已有的知识图谱嵌入往往仅仅利用了知识图谱的图结构,难以很好地表示稀疏的实体。虽然有些知识图谱嵌入方法利用了文本信息,比如实体描述、关系描述和单词共现,但是它们忽略了上下文信息,也没有利用外部的大规模语料信息。针对上述问题,论文提出KG-BERT,首先将实体、关系和三元组视为文本序列,并将知识图补全转化为序列分类问题。然后在这些序列上微调BERT模型,以预测三元组或关系的合理性/似然性。
论文提出了两种KG-BERT模型。一种是输入三元组的文本序列,输出用于预测三元组的合理性(KG-BERT(a));另一种是输入头实体和尾实体的文本序列,输出用于预测关系(KG-BERT(b))。
K-BERT(2020)
参考
在前面的论文解读中提到过ERNIE使用基于自注意力机制来克服异构向量的融合,而KEPLER更进一步,将实体的描述文本作为训练语料,利用文本编码器生成实体的初始化语料,避免了异构语义向量的生成。
那么除了这一方式以外,是否还存在别的方式在注入异构知识的过程中解决异构向量的问题呢?
既然造成异构向量的原因在于使用不同的表示学习方式对不同结构的对象进行表示学习,那么一个直接的思路就是将不同结构的对象转换成同一结构,从而使用同一种表示学习方式对其编码。
K-BERT使用BERT模型作为基础模型,为下游任务构造含有知识的句子树作为输入序列,并通过下游任务的目标函数微调模型。
K-BERT模型主要包括知识层(knowledge layer)、表示层(embedding layer)、可见层(seeing layer)和编码器(mask-Transformer encoder)四个组成模块。
其中知识层负责知识的注入以及句子树的生成;表示层负责将句子树这一输入序列投影成表示向量;可见层通过使用可见矩阵记录向量的可见范围,解决知识噪音的问题;编码层则负责基于注入的三元组知识所提供的信息编码表示向量。
LP-BERT(2022)
Multi-task Pre-training Language Model for Semantic Network Completion
论文提出的LP-BERT模型分为预训练和微调两部分。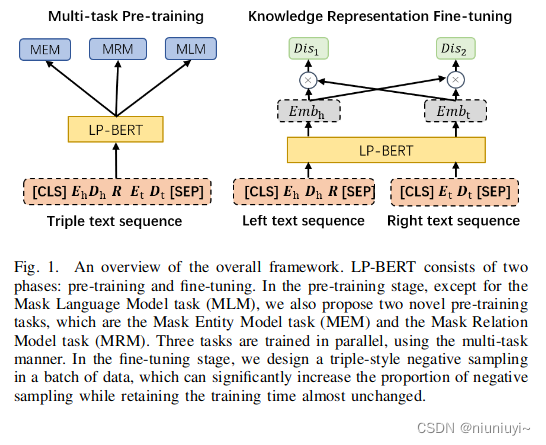
多任务预训练
为了能同时利用文本信息和知识图谱的结构信息,模型除了利用MLM(Masked Language Model),还提出了MEM(Masked Entity Model)和MRM(Maked Relation Model)。预训练是包含了MEM, MRM, MLM三个任务的多任务学习。预训练模型的整体结构如下: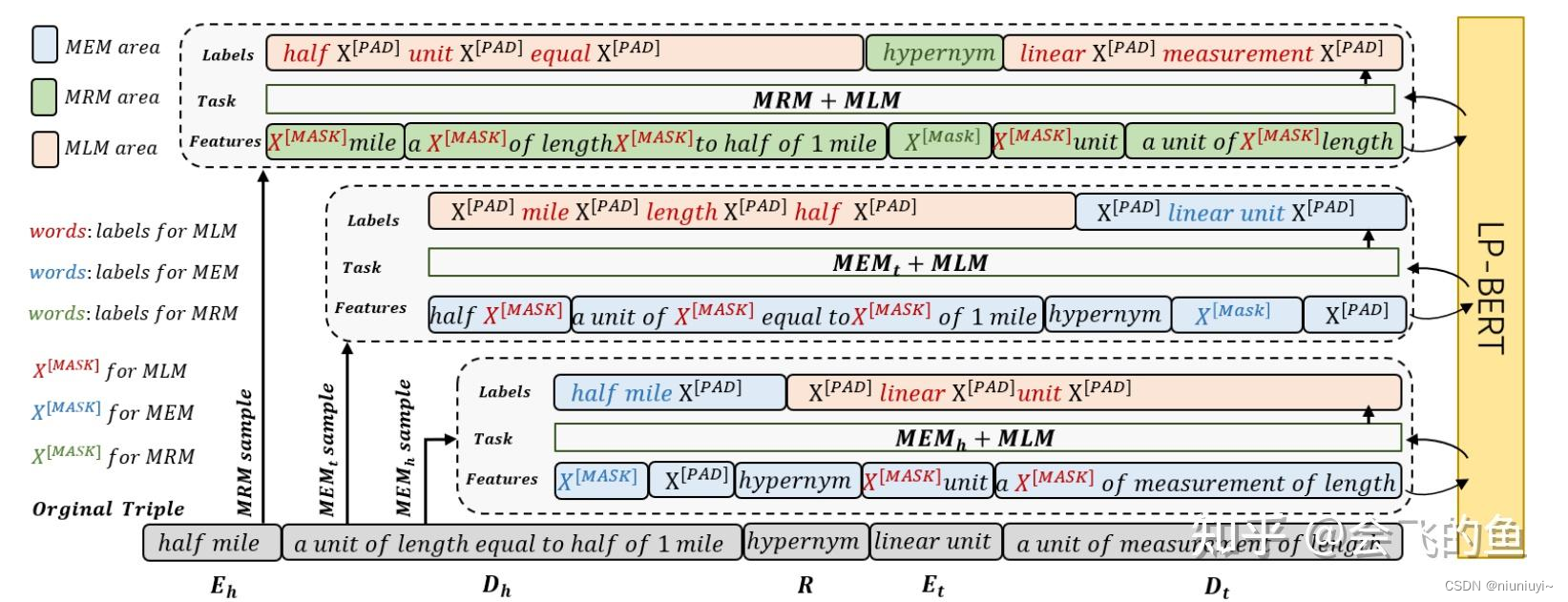
知识图谱微调
Knowledge Representation. 微调阶段的样本构造方法不同于预训练阶段。受StAR的启发,对于三元组样本,连接Eh和R文本。预训练的LP-BERT模型使用siamese来分别编码 EtR和Et文本。通过使positive vector pair更接近和negative vector pair对进一步微调模型来计算梯度更新模型参数。
Contrastive Learning. 对于批中的每个样本,LP-BERT对知识表示进行编码,然后成对计算距离。批量的大小被定义为n。批量中的每个实体元素都有一个正例和n-1个负例。负例构造如下图所示。
Triple Augmentation. (EhR,Et)pair-based 知识图谱表示方法存在着不能表示(Eh,REt)的限制,所以论文中提出了,对于每个关系R,定义Rrev,对于 (Eh,REt)用(Et,Rrev,Eh)pairs去扩充数据,从而使得预测头部实体任务的知识图谱向量表示方法与预测尾部实体任务的知识图谱向量表示方法一致,大大提高了采样的多样性和模型的鲁棒性。
Mixed Precision. 使用fp16和fp32的混合精度策略来减少梯度计算的GPU内存使用,提高n的大小和负采样率。
Fine-tuning Loss Designing. 设计了两种距离计算方法来联合计算损失函数:
大语言模型用于知识图谱补全
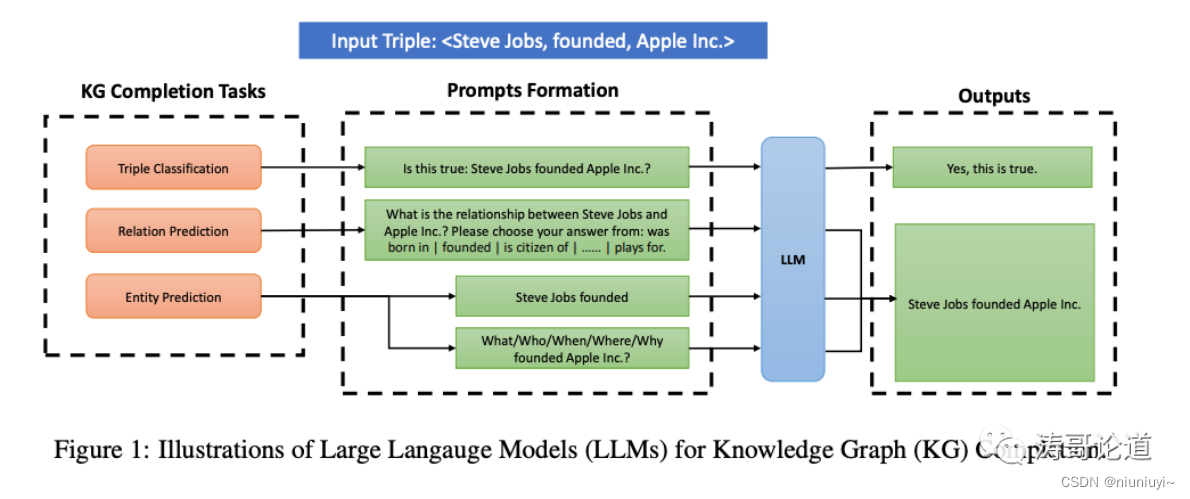 三元组分类 提示的格式会是“这是否正确:史蒂夫乔布斯创立了苹果公司?”。LLM的理想输出将是“是的,这是正确的
三元组分类 提示的格式会是“这是否正确:史蒂夫乔布斯创立了苹果公司?”。LLM的理想输出将是“是的,这是正确的
关系预测 提示的格式会是“史蒂夫乔布斯和苹果公司之间的关系是什么?请从以下中选择你的答案:出生于 | 创立 | 是公民 | … | 效力于。”理想的回复将是“史蒂夫乔布斯创立了苹果公司。
实体(链接)预测 提示的格式将是“史蒂夫乔布斯创立”来询问尾实体,和“创立苹果公司的是谁/什么/何时/何地/为何”来询问头实体。理想的回复将是“史蒂夫乔布斯创立苹果公司。”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)