Agent 不再需要 Prompt,循环工程(Loop Engineering)完全指南
ps. Harness Engineering还没熟,Loop Engineering 又要来了…
Peter Steinberger,OpenClaw 的创建者,现在在 OpenAI 工作。
昨天他发了这样一段话:
“你不应该再手动给编码 Agent 写提示了。你应该设计循环,让循环来给 Agent 下指令。”
然后 Anthropic Claude Code 负责人 Boris Cherny 用另一种方式表达了同样的意思:
“我已经不再手动给 Claude 写提示了。我让循环在运行,由循环来驱动 Claude 并决定下一步做什么。我的工作就是写循环。”
这是当下最资深的两位 AI 工程师,传达的信息完全一致。
大多数人看完后会问:具体怎么理解?
我做了一番系统梳理。以下是完整的拆解,讲讲需要建立的思维模型。
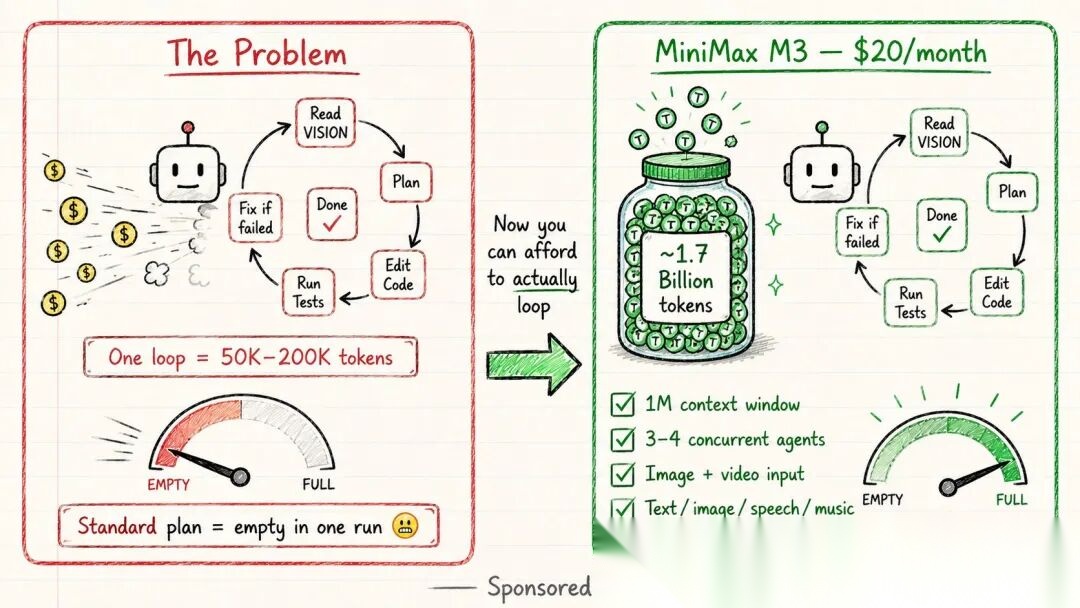
绕不开的成本问题
循环听起来很美好,直到你看到账单。
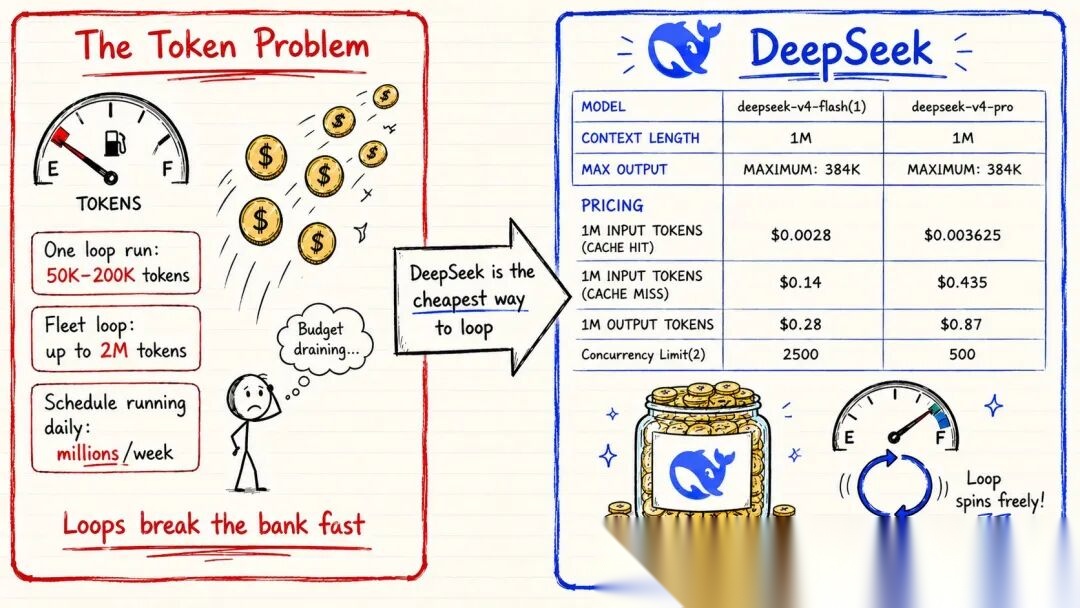
一个中等规模编码任务的单 Agent 循环:5 万到 20 万 token。一个带编排者和 3 个专业 Agent 的 Fleet 循环:50 万到 200 万 token。一个每天早上定时运行的循环:每周数百万 token。
按照标准 API 定价,认真做一周 Loop 工程的成本,可能超过大多数人整个月的 AI 预算。
这就是为什么 Peter Steinberger 的评论区里满是这样的回复:
“你说得轻松,你有无限量的 OpenAI 额度。”
他们说的没错。在正常预算下做循环工程,成本压力会很快浮现。每次重试、每次自我修正、每个子 Agent 调用、每次验证,都在消耗 token。
这是很少被讨论的隐形障碍:循环的设计并不难,真正难的是在可控预算内持续运行。
这也是低成本模型(如 DeepSeek、Kimi、MiniMax)的价值所在:它们让 Agent 循环在经济上变得可行。百万级上下文窗口让长时间运行的循环保持连贯,低 token 定价则大幅降低了持续运行的门槛。
Part 1:旧方式 vs 新方式
过去两年,我们一次给 Agent 一个任务。
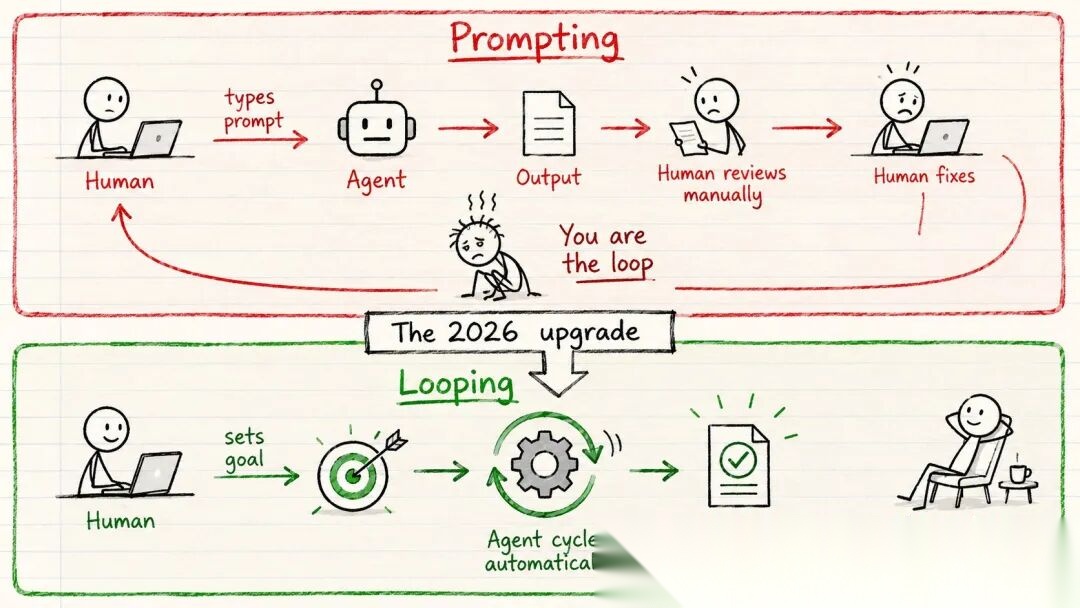
你输入一个提示,Agent 回应,你审查结果,修正错误的部分,再输入下一个提示。你自己就是那个循环。
这个模式正在改变。
以前你让 Agent 做一个落地页,然后自己驱动每一步。现在你设置一个循环来处理发现、规划、执行、检查和迭代,直到目标达成。
区别在于:
旧方式(逐步提示):
你 → 提示 → Agent → 输出 → 你审查 → 你修正 → 重复
新方式(循环驱动):
你设定目标 → 循环运行 → Agent 发现 → 规划 → 执行 → 验证 → 迭代 → 完成
你不再逐步下指令了,Agent 替你重复这个周期。
提示给 Agent 的是指令,循环给 Agent 的是一份工作。
Part 2:Loop 工程到底是什么
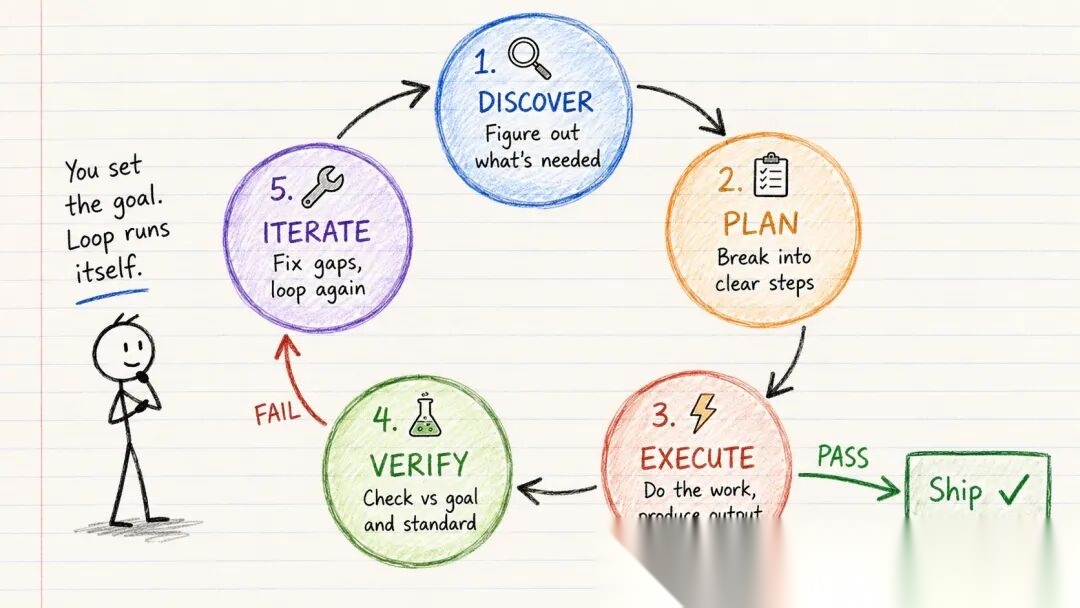
Loop 工程是一种设计可重复反馈循环的实践,引导 AI Agent 从尝试走向经过验证的结果,而不需要持续的人工干预。
循环是你构建的一套机制,几乎任何 Agent Harness 都能运行它,关键在于你怎么把它接起来。
最简单的形式是一个 Agent 对自己的工作进行迭代:
- 调研
- 起草
- 对照目标检查草稿
- 修正薄弱环节
- 再次运行这个周期,直到工作满足要求
每个循环,无论多简单或多复杂,都经过相同的 5 个阶段:
发现 → 规划 → 执行 → 验证 → 迭代
通过验证就交付,未通过就继续循环。
整个思路就是这样。本文后续的所有内容,都是在讲如何正确地构建这个周期。
Part 3:单 Agent 循环 vs Fleet 循环
循环有两种规模:
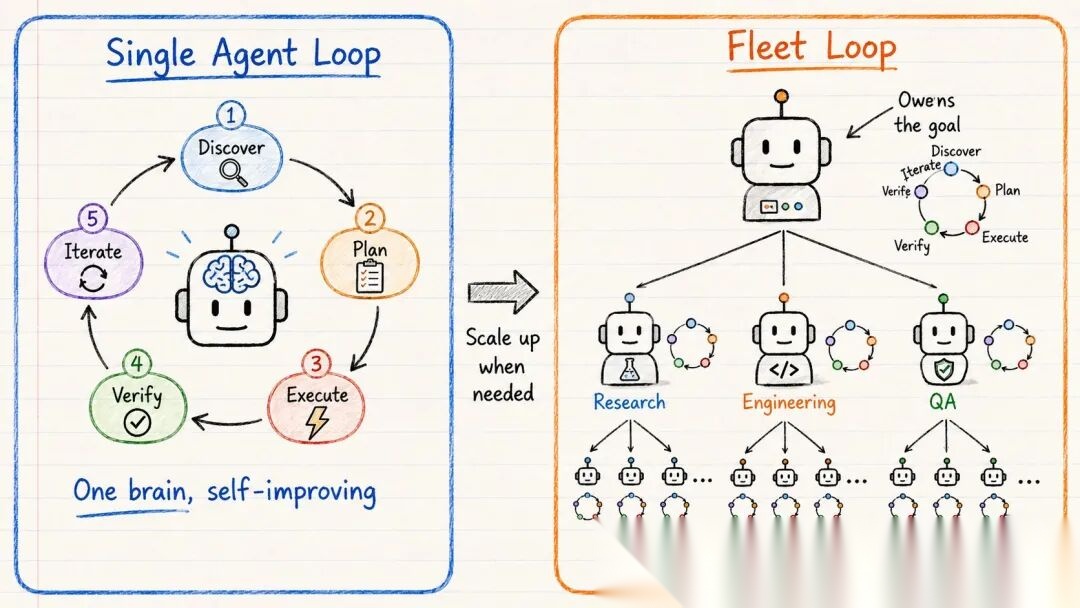
单 Agent 循环
一个 Agent 独立运行整个周期。
可以理解为一个人反复修改自己的草稿。它发现需要做什么,规划工作,执行,验证质量,如果有问题就迭代。
适用场景:聚焦的任务、明确的目标、有限的范围。适合一个 Agent 独立完成闭环迭代的情况。
Fleet 循环
更大的版本是 Fleet 循环。
你给编排者 Agent 一个目标,它把目标拆成若干部分,每个部分交给一个专业 Agent。这些专业 Agent 又把更小的工作交给自己的子 Agent。
整棵树持续循环执行发现、规划、执行和验证,直到目标达成。
可以理解为一整个团队端到端地推进一个项目。
结构如下:
- 编排者负责目标
- 专业 Agent 负责步骤
- 子 Agent 负责具体的细粒度工作
- 评估门禁确保产出质量
示例:“构建一个效率工具应用”
编排者(负责整体目标) ├── 调研专家 │ └── 网络检索 ├── 工程专家 │ └── 代码编写 + 调试 └── QA 专家 └── 测试编写 + Bug 追踪
树中的每个 Agent 都运行相同的 5 阶段循环:发现 → 规划 → 执行 → 验证 → 迭代。
关键区别:单 Agent 循环像一个人反复修改自己的草稿,Fleet 循环则是一整个团队端到端地推进项目。
Part 4:开放循环 vs 封闭循环
这是 2026 年实践中最重要的区分:
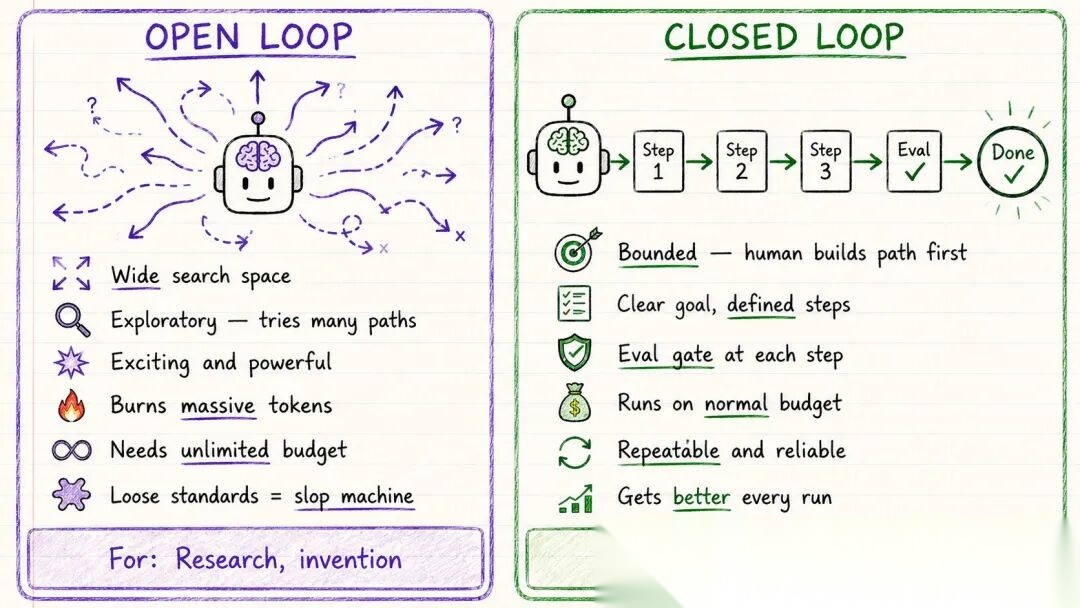
不是所有循环都一样,有两种类型。
开放循环
探索式的,活动空间很大。
你给 Agent 一个目标,让它自由探索。它可以尝试不同的路径,发现新的东西,构建出你没有完全定义的成果。
Peter Steinberger 等人在 OpenAI 就是这样工作的。但问题在于 token 消耗量巨大。对于大多数没有充裕 API 预算的团队来说,开放循环目前还不够实用。如果指向质量标准不够严格的项目,很容易产出大量低质量内容。
封闭循环
有边界的。由人先设计好端到端的路径。
- 明确的目标
- 定义好的步骤
- 每一步都有评估
- 有明确的停止点或交还给人的节点
Agent 仍然在循环,但是在你构建的框架内运行。每次运行都会变得更好,因为每一轮的结果会反馈给下一轮。它在正常预算内就能运行,因为路径是收紧的。
没有质量门禁,AI 会漂移。有了质量门禁,AI 会改进。
对于当前大多数实际工作来说,封闭循环才是真正有回报的选择。
应该用哪种?
从封闭循环开始。先构建一个可靠运行的紧凑系统。等你有了完善的质量门禁之后,再逐步放开。
Part 5:好循环的 6 个构建模块
每个能持续运行的循环都有这 6 个要素:

概念上循环有 5 个阶段,但要让它真正运行起来,你需要构建 6 样东西。Claude Code 和 Codex 现在都已经具备了这些能力。
1. 自动化(Automations)
触发"发现"阶段、让循环启动的机制。
自动化是循环的心跳。它让循环真正成为循环,而不只是你执行了一次的操作。
你定义一个提示、一个运行节奏和一个目标。循环按计划运行,结果推送给你。
-
/loop按照设定的节奏反复运行
-
/goal持续运行直到你写的条件真正满足
例如设定:“test/auth 下所有测试通过,lint 也干净。” 然后你就可以放手了。
2. Worktree
让多个"执行"阶段并行运行而不互相干扰的机制。
当你运行多个 Agent 时,文件冲突立刻就会出现。两个 Agent 写同一个文件,和两个工程师在没有沟通的情况下提交同一段代码,是同样的问题。
Git worktree 给每个 Agent 一个独立的工作目录和独立的分支,共享相同的仓库历史,零冲突。
3. Skills
让"发现"阶段更快的机制,Agent 在启动前就已经了解你的项目。
Skill 是一个包含 SKILL.md 的文件夹,里面记录了项目规范、构建步骤、以及"因为之前出过事故,我们不这样做"之类的约定。写一次,每次循环都读取。
没有 Skills,循环每个周期都要从零推导你的整个项目。有了 Skills,知识会累积,Agent 在开始之前就已经了解你的项目。
- VISION.md 定义成功是什么样的
- ARCHITECTURE.md 定义技术栈和目录结构
- RULES.md 定义 Agent 绝对不允许做的事
4. 插件和连接器(Plugins and Connectors)
让"执行"阶段真正落地的机制,循环在你的实际环境中行动,而不仅仅是在文件系统里。
基于 MCP 构建的连接器让 Agent 可以读取你的 issue tracker、查询数据库、调用 staging API、在 Slack 里发消息。
这就是"Agent 说’这是修复方案’"和"循环自己提 PR、关联 Linear ticket、CI 通过后在频道里发通知"之间的区别。
5. 子 Agent(Subagents)
让"验证"阶段保持诚实的机制,检查者和制作者永远不是同一个 Agent。
生成代码的模型在验证自己的产出时,往往会倾向于通过。引入一个持有不同指令的第二个 Agent,有时甚至使用不同的模型,能捕捉到第一个 Agent 因自身偏差而忽略的问题。
有效的分工是:
- 一个 Agent 探索
- 一个 Agent 实现
- 一个 Agent 对照规格进行验证
这也是 /goal 底层的运作方式。由一个全新的模型来判断循环是否完成,而不是做这件事的那个模型。
6. 记忆(Memory)
让循环具备持久性的机制。第 47 次运行的"发现"阶段知道前 46 次运行已经尝试过什么。
记忆是整个循环的脊柱。它可以是一个 markdown 文件、一个 Linear 看板,任何存在于单次对话之外的东西。
模型在运行之间会遗忘一切,但仓库不会。记忆文件记录着:什么已经尝试过、什么已经通过、什么还没完成。
第二天早上,循环从昨天停下来的地方继续。这个机制看似简单,但每个长时间运行的循环都离不开它。
Part 6:实际循环示例
循环在实践中是什么样的:
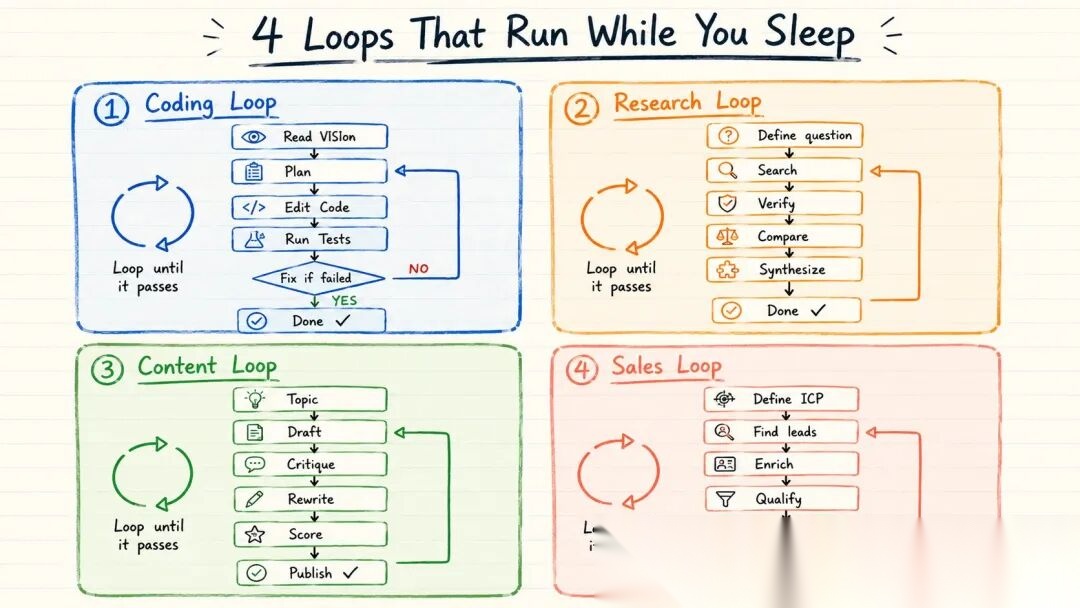
编码循环
读取 VISION.md + ARCHITECTURE.md↓规划下一个变更↓编辑代码↓自动运行测试↓如果测试失败 → 读取错误 → 修复 → 重新测试↓如果测试通过 → 总结变更内容↓停止
中间不需要人参与。Agent 自己编写、测试、修复和验证。
调研循环
定义调研问题 → 搜索信息源 → 总结发现 → 对照原始来源验证结论 → 比对矛盾信息 → 综合最终答案 → 当置信度达到阈值时停止
内容循环
定义主题 + 受众 + 目标 → 生成草稿 → 评审 Agent 审查草稿 → 基于评审意见重写 → 对照成功标准打分 → 通过则发布,未通过则再次重写
销售外联循环
定义 ICP(理想客户画像) → 寻找匹配线索 → 用企业数据补充信息 → 资质筛选 → 个性化消息定制 → 质量审查 → 发送或上报给人工处理
每个循环都有相同的骨架:目标 → 行动 → 检查 → 修正 → 重复直到完成。
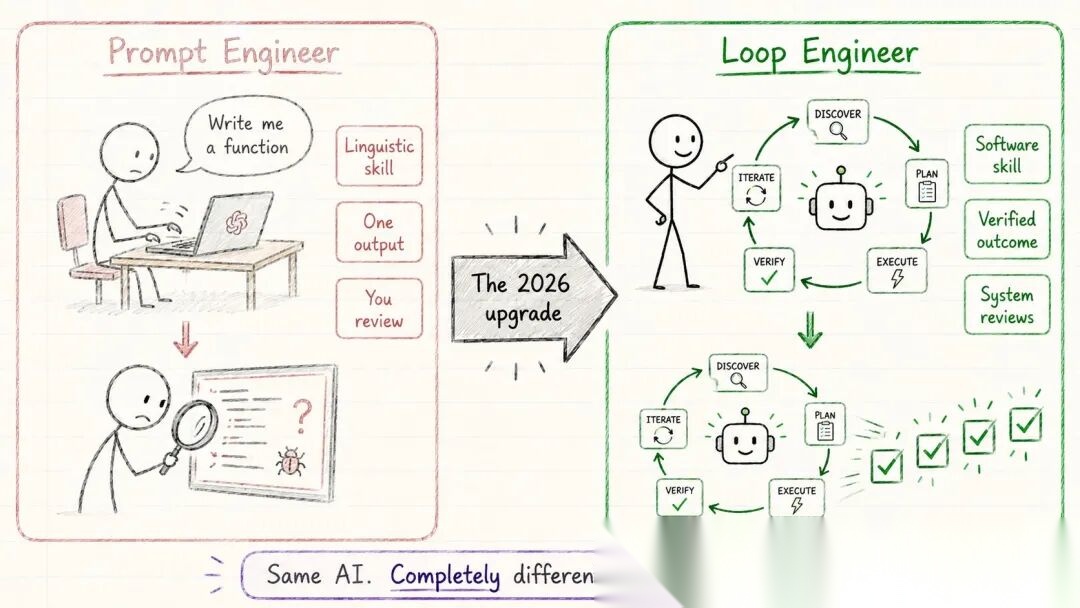
Part 7:Prompt 工程师 vs Loop 工程师
2026 年正在拉开的技能差距:
Prompt 工程师:
- 精心打磨更好的指令
- 核心是语言能力
- 更好的提示带来更好的单次输出
- 每次运行后仍需手动审查输出
- 你自己就是反馈循环
Loop 工程师:
- 设计更好的反馈周期
- 核心是软件工程能力
- 更好的循环带来可靠的、经过验证的结果
- 系统自动运行、检查和自我修正
- 系统本身就是反馈循环
Prompt 工程师说:“帮我写一个函数。”
Loop 工程师说:“写代码 → 跑测试 → 修到全绿。”
工具是一样的,但思维方式完全不同。
Prompt 工程师向 AI 索要输出。Loop 工程师设计产出经过验证的结果的系统。
2026 年高薪的 AI 工程师,不是写最好的prompt的人。他们写的是控制 Agent 如何发现、规划、检查自身工作、以及如何判断任务已完成的逻辑。
总结
以上就是 Loop 工程的全貌。
过去两年我们一次给 Agent 一个任务,现在我们设计循环来运行整个周期。你需要构建 6 样东西:自动化、Worktree、Skills、插件和连接器、子 Agent、记忆。循环有两种规模(单 Agent vs Fleet)和两种类型(开放 vs 封闭)。
Peter Steinberger 说得对:不要再给你的 Agent 写提示了,开始设计循环。因为一个可靠的循环,胜过一千个完美的提示。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献195条内容
已为社区贡献195条内容

所有评论(0)