多模态 AI 应用的统一任务架构设计:从模型调用到生产可用
前言:AI 应用从 Demo 到生产,难点会发生变化
很多 AI 应用在 Demo 阶段看起来并不复杂:后端调用一个模型接口,拿到文本、图片或视频结果,再把结果展示给用户。对于早期验证来说,这种方式足够直接,也能很快看到效果。
但进入生产环境后,系统面对的问题会明显变化。真正的难点通常不是“能不能调通模型”,而是“能不能稳定地把结果交付给用户”。
尤其是多模态场景,系统可能同时接入文本、图像、视频、音频等模型。不同模型的调用方式、返回结构、耗时、失败形态和计费方式都不同。如果每接入一个模型,就在业务代码里写一套专用适配逻辑,短期看似推进很快,长期会让系统变得越来越重。
业务逻辑、模型调用、状态管理、文件处理、异常重试和成本统计混在一起后,后续每新增一个模型或功能,都可能牵动大量已有代码。系统不是因为功能太多而复杂,而是因为边界没有拆清楚。
因此,多模态 AI 应用从 Demo 走向生产时,需要优先考虑一件事:在业务层和模型层之间增加统一任务层,把一次模型调用抽象成一个可追踪、可重试、可交付的 Task。这样业务系统不再直接面对各类模型接口差异,而是面对一套稳定的任务协议。
本文尝试从工程设计角度,拆解多模态 AI 应用中统一任务架构的设计思路,包括任务抽象、异步状态、文件交付、可观测性、成本治理、调度策略和测试方案。
一、多模型接入的复杂度从哪里来
多模型接入的复杂度并不只是“接口多”。真正的问题是,每个模型背后的执行语义都可能不同。
1.1 接口形态不同
文本模型通常是同步返回,调用后很快得到结果;图像模型可能同步,也可能异步;视频模型大多是长耗时异步任务,通常先返回任务 ID,再通过轮询或回调获取最终结果。
如果业务代码直接依赖这些模型接口,就会出现同步逻辑、轮询逻辑、回调逻辑混杂在同一个服务里的情况。前期看起来只是多写几个适配函数,后期会逐渐变成维护负担。
1.2 返回结构不同
不同模型返回的数据结构差异也很明显。
| 模型类型 | 常见返回形式 | 典型后处理 |
|---|---|---|
| 文本模型 | 字符串、JSON、工具调用参数 | 解析结构、字段校验、敏感词处理 |
| 图像模型 | 图片 URL、Base64、文件 ID | 下载、转存、压缩、生成缩略图 |
| 视频模型 | 任务 ID、视频 URL、封面图、时长信息 | 轮询、转存、转码、截帧 |
| 音频模型 | 音频 URL、二进制流、字幕片段 | 转存、格式转换、时长统计 |
如果没有统一结果结构,业务层会充斥大量 if model == xxx 的分支判断。短期可以接受,长期会让业务代码逐渐失去可读性。
1.3 耗时差异明显
文本生成可能几秒完成,图片生成可能十几秒,视频生成可能几十秒甚至更久。如果所有请求都用同步 HTTP 等待,不仅前端体验不稳定,后端连接资源也容易被长任务占满。
更合理的方式是把长耗时任务异步化,让用户请求和模型执行解耦。用户提交任务后,系统立即返回任务 ID;前端根据任务 ID 查询状态;任务完成后再展示结果。
1.4 限流和成本差异
不同模型的并发限制、失败成本和计费方式并不一致。一个模型适合低成本批量生成,另一个模型适合高质量最终输出。如果系统缺少统一统计,很难判断某个功能到底消耗了多少资源,也很难发现异常重试带来的隐性成本。
| 复杂度来源 | Demo 阶段表现 | 生产阶段表现 |
|---|---|---|
| 接口差异 | 写几个适配函数即可 | 适配代码散落,回归成本增加 |
| 异步任务 | 手动刷新或简单轮询 | 需要状态机、回调、超时控制 |
| 文件交付 | 直接使用模型 URL | 需要转存、鉴权、过期处理 |
| 成本统计 | 粗略看总账单 | 需要按模型、任务、业务拆分 |
| 失败处理 | 手动重试即可 | 需要幂等、限流、重试边界 |
这些问题说明,多模态系统不应该把模型接口直接暴露给业务模块。更好的方式是把底层模型调用先收敛为统一任务,再由业务围绕任务进行状态展示、结果消费和异常处理。
二、统一 Task 抽象:把模型调用变成工程对象
统一任务层的核心思路是:业务不直接关心底层调用的是哪个模型,而是关心一个任务从创建到完成的生命周期。
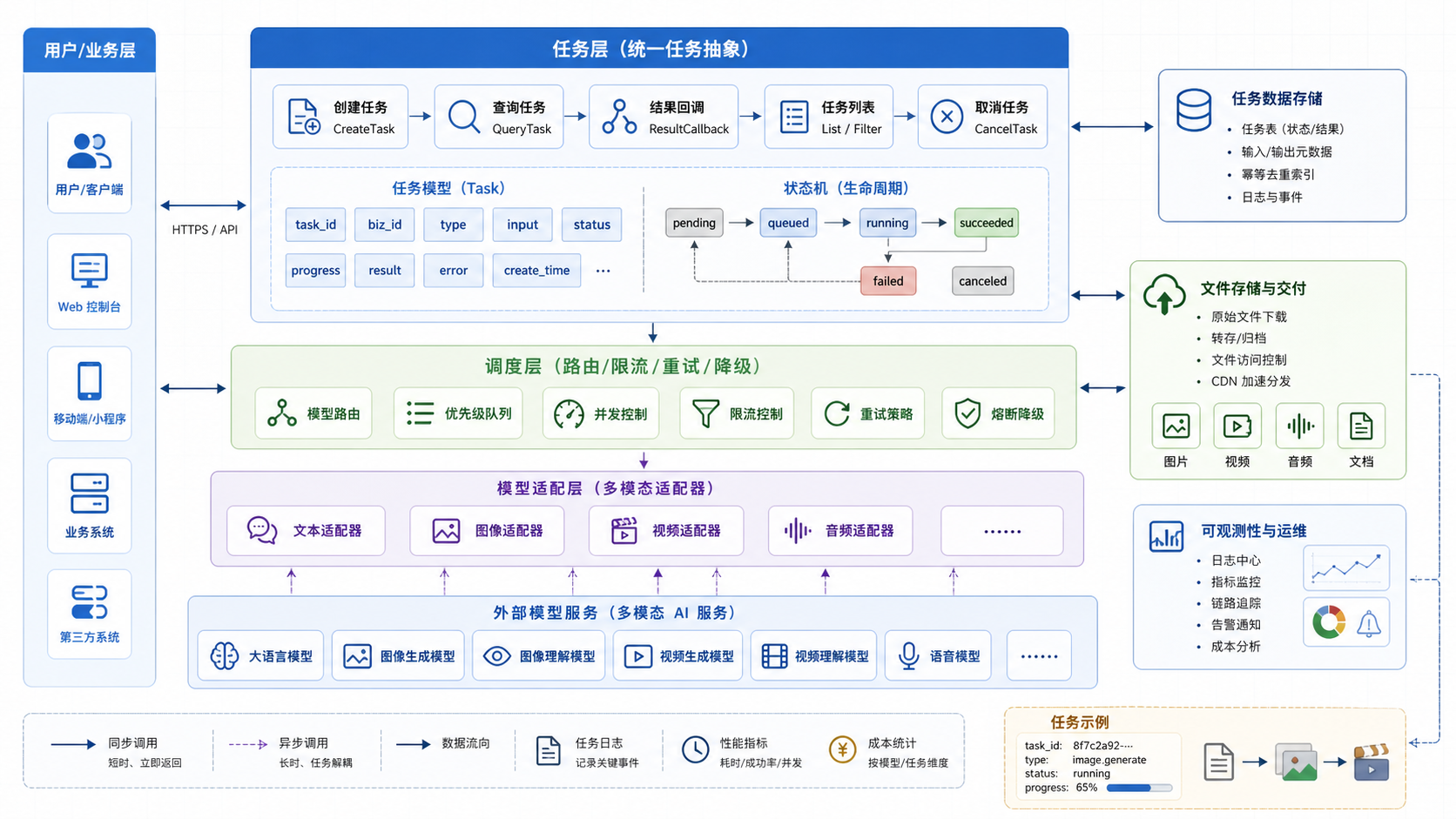
一个常见链路可以抽象为:
CreateTask -> QueryTask -> ResultCallback
从整体架构上看,可以把多模态 AI 应用拆成五层:业务入口、任务层、调度层、模型适配器和外部模型服务。任务层位于中间,负责把上层业务请求转换成可管理的任务对象。
其中:
| 阶段 | 作用 | 关键点 |
|---|---|---|
| CreateTask | 创建任务并持久化输入 | 幂等、参数校验、初始状态 |
| QueryTask | 查询任务当前状态 | 状态机、结果结构、错误信息 |
| ResultCallback | 接收异步结果通知 | 签名校验、重复回调、乱序处理 |
一个简化后的任务结构可以设计为:
{
"task_id": "task_xxx",
"biz_id": "order_or_request_id",
"type": "image_to_video",
"model": "vendor_model_name",
"status": "pending",
"input": {},
"output": {},
"error": {},
"created_at": 0,
"updated_at": 0
}
这里最关键的是 task_id。它是后续查询、日志关联、回调处理、失败重试和成本统计的统一入口。只要任务 ID 稳定,业务系统就不需要直接感知每个模型的内部实现。
三、任务状态机设计
状态机是统一任务层的核心。状态设计过少,无法表达真实执行过程;状态设计过多,又会增加业务判断复杂度。
一个相对通用的状态机可以这样设计:
| 状态 | 含义 | 是否终态 | 可进入状态 |
|---|---|---|---|
| pending | 任务已创建,等待调度 | 否 | running、failed、canceled |
| running | 模型或后处理正在执行 | 否 | success、failed、timeout |
| success | 任务完成,结果可用 | 是 | 无 |
| failed | 任务失败,已有明确原因 | 是 | 无 |
| timeout | 任务超过最大等待时间 | 是 | 无 |
| canceled | 用户或系统取消任务 | 是 | 无 |
对于图像、视频等长任务,也可以在内部记录更细的原始状态,例如 queued、generating、transcoding、uploading,但对业务侧暴露时可以收敛成更简单的状态。
这样做有两个好处:
第一,业务系统不需要理解所有底层细节。前端只要知道任务是否还在执行、是否成功、是否失败即可。
第二,后端仍然保留足够的排查信息。研发人员可以通过原始状态判断问题到底发生在模型生成阶段,还是文件转存阶段。
四、幂等、重试与失败边界
很多 AI 应用上线后成本失控,并不是因为用户量突然暴增,而是因为重复提交和异常重试没有控制好。
4.1 创建任务要支持幂等
用户可能重复点击按钮,前端可能超时重发请求,服务间调用也可能因为网络抖动重试。如果 CreateTask 不支持幂等,就可能为同一个业务请求创建多个生成任务,既影响结果一致性,也会增加成本。
实践中可以让业务侧传入 biz_id 或 request_id,任务层根据该字段判断是否已经创建过相同任务。
| 场景 | 无幂等设计 | 有幂等设计 |
|---|---|---|
| 用户重复点击 | 创建多个任务 | 返回同一个 task_id |
| HTTP 超时重试 | 可能重复扣费 | 查询已有任务状态 |
| 服务间重放请求 | 结果不确定 | 结果可追踪 |
4.2 重试要区分请求失败和任务失败
请求创建失败可以安全重试,但任务已经进入执行状态后,是否重新提交就需要谨慎判断。对于长耗时任务,重复提交往往意味着重复计费和重复占用队列资源。
更稳妥的做法是先查询原任务状态:
| 当前状态 | 建议策略 |
|---|---|
| pending / running | 不重新创建,继续等待 |
| success | 直接返回已有结果 |
| failed | 根据错误类型判断是否可重试 |
| timeout | 查询上游最终状态,再决定是否重跑 |
失败也要分类。参数错误不应该重试,限流可以延迟重试,网络错误可以短间隔重试,内容安全拦截则应该直接失败并返回明确原因。
五、异步任务与媒体文件交付
多模态任务中,图像和视频最容易暴露工程问题。模型生成成功,并不代表用户已经拿到了可用结果。生成之后还涉及文件下载、转存、访问权限、过期时间、前端刷新等环节。
比较稳妥的链路可以拆成几个阶段:
创建任务 -> 模型执行 -> 获取原始结果 -> 转存文件 -> 更新任务结果 -> 通知前端
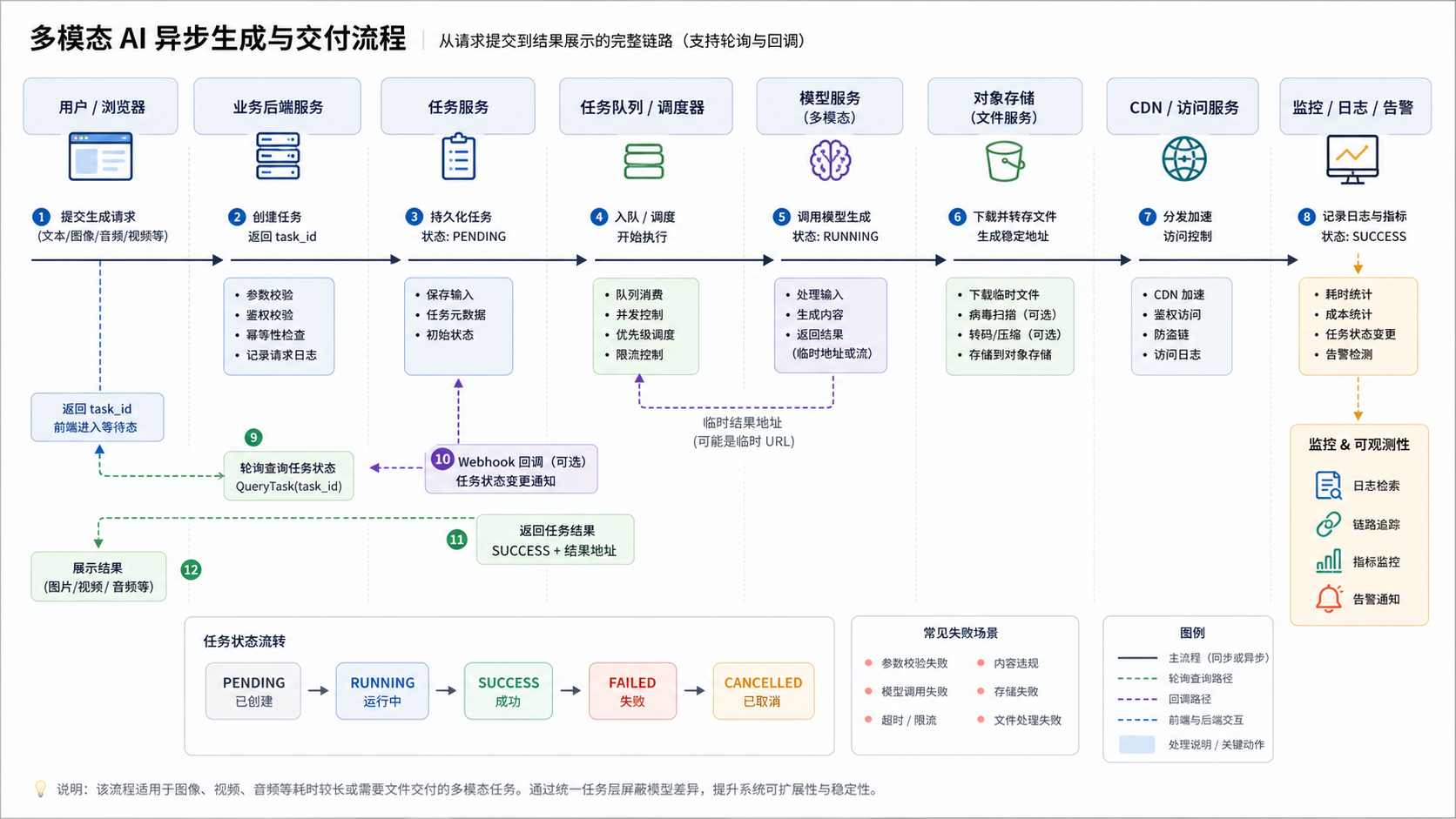
对于图像、视频这类媒体任务,可以把“生成”和“交付”拆成两条相互衔接的链路。模型侧负责生成,业务侧负责保存、鉴权和稳定访问。这样即使上游返回的是临时 URL,最终交付给用户的仍然是业务系统可控的资源地址。
模型返回的结果不一定适合直接交给前端使用。有些 URL 是临时地址,可能几小时后过期;有些地址需要鉴权,前端无法直接访问;有些文件体积较大,需要转存到自己的对象存储,再通过 CDN 或文件服务提供稳定访问。
因此,生产系统更建议把模型返回结果收敛到自己的文件服务中,再把稳定资源地址写入任务结果。
| 文件处理策略 | 优点 | 风险 |
|---|---|---|
| 直接返回模型 URL | 实现简单 | URL 过期、权限不可控、跨域问题 |
| 后端下载后转存 | 访问稳定、权限可控 | 增加存储和带宽成本 |
| 流式转存 | 减少本地落盘 | 实现复杂度更高 |
| 延迟转存 | 降低短期成本 | 用户访问时可能遇到源文件失效 |
对于正式业务,通常建议采用“后端转存 + 稳定资源地址”的方式。这样即使上游模型调整文件地址策略,业务侧也不会受到太大影响。
六、轮询与 Webhook:不要只选一种
前端状态同步一般有两种方式:轮询和 webhook。
轮询实现简单,前端或后端定期查询任务状态即可。它适合任务规模不大、状态更新频率不高的系统。缺点是会产生额外请求,并且状态更新存在一定延迟。
Webhook 的实时性更好,模型侧或任务层在任务完成后主动通知业务系统。但 webhook 需要处理更多工程细节,例如签名校验、重复回调、乱序回调和回调失败重试。
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 前端轮询 | 实现简单,容易调试 | 请求量较高,实时性一般 | 低频任务、小规模系统 |
| 后端轮询 | 前端逻辑简单 | 后端需要调度查询 | 中等规模任务 |
| Webhook | 实时性好,请求量低 | 要处理签名、重放、乱序 | 长任务、大规模系统 |
| Webhook + 兜底轮询 | 稳定性较好 | 实现成本更高 | 生产环境推荐 |
实际项目中,两者可以结合使用:webhook 作为主动通知,轮询作为兜底查询。这样即使某次回调丢失,系统也能通过查询任务状态恢复一致性。
七、调度层:不要把路由写死在业务里
当系统只接入一个模型时,业务代码里直接调用模型问题不大。但一旦接入多个模型,就需要考虑调度层。
调度层负责根据任务类型、模型可用性、成本、质量和延迟等因素选择执行路径。它不一定要很复杂,但应该从业务代码中独立出来。
一个简单的调度策略可以包含:
| 策略维度 | 示例 |
|---|---|
| 任务类型 | 文生图、图生图、图生视频分别走不同模型池 |
| 用户等级 | 免费用户走低成本模型,付费用户走高质量模型 |
| 失败率 | 某模型失败率升高后临时降权 |
| 延迟 | 超过 SLA 的模型暂时减少分配 |
| 成本 | 高成本模型只用于最终生成,不用于批量试错 |
这里要注意,调度策略不应该散落在各个模型适配器里。适配器只负责把统一参数转换成模型参数,不应该决定业务优先级。否则模型越多,策略越难维护。
八、模型适配器与业务层的边界
统一任务层并不意味着所有逻辑都放在一个模块里。比较清晰的分层方式是:
业务层 -> 任务层 -> 调度层 -> 模型适配器 -> 第三方模型服务
各层职责可以这样划分:
| 层级 | 职责 | 不应该做的事 |
|---|---|---|
| 业务层 | 用户权限、业务参数、结果展示 | 直接解析模型私有返回 |
| 任务层 | 生命周期、状态机、幂等、日志 | 写死模型选择策略 |
| 调度层 | 路由、降级、熔断、成本策略 | 处理具体 HTTP 细节 |
| 适配器层 | 参数转换、接口调用、返回归一 | 承载业务规则 |
| 文件层 | 下载、转存、鉴权、CDN 地址 | 参与模型路由决策 |
这样做的好处是边界清晰。新增模型时,只需要增加一个适配器;修改业务功能时,不需要关心底层接口细节;任务状态和日志规则也能保持一致。
在一些统一多模态平台中,例如 crun ai,可以看到类似的设计思路:不同模型能力被收敛到统一任务入口,再围绕任务做状态、日志、用量和文件管理。这里值得关注的不是具体平台,而是这种任务化抽象对工程复杂度的收敛方式。
九、可观测性要前置设计
当任务链路变长后,可观测性必须前置设计。否则系统出问题时,只能看到“生成失败”,却不知道失败发生在哪一步。
建议每个任务至少记录以下字段:
| 字段 | 作用 |
|---|---|
| task_id | 串联任务生命周期 |
| biz_id | 关联业务请求 |
| task_type | 区分任务类型 |
| model | 记录实际调用模型 |
| status | 当前任务状态 |
| input_hash | 判断是否相同输入 |
| start_time / finish_time | 计算耗时 |
| duration_ms | 性能统计 |
| retry_count | 判断异常重试 |
| error_code | 失败归因 |
| cost_units | 成本统计 |
| file_size | 文件处理成本评估 |
| callback_status | 回调是否成功送达 |
日志也不应该只记录最终状态。对于复杂任务,至少要记录几个关键事件:
task_created
model_request_sent
model_response_received
file_transfer_started
file_transfer_finished
task_finished
callback_sent
这些事件可以串成一条完整链路。当用户反馈某个任务失败时,研发人员可以根据 task_id 直接定位:是模型没有返回,还是文件转存失败;是回调没有送达,还是前端没有刷新状态。没有这条链路,排查只能依赖猜测。
十、成本治理:不能只看总账单
多模态任务的成本治理比文本应用更复杂。文本生成通常按 token 统计,成本相对容易拆解;图片和视频生成则可能按次数、时长、分辨率、模型档位计费。再叠加失败重试、用户重复提交、批量生成等场景,实际成本可能和业务预期差距很大。
成本统计不应只看总账单,而要拆到三个维度:
| 维度 | 关注问题 |
|---|---|
| 模型维度 | 哪个模型成本最高、失败率最高、平均耗时最长 |
| 任务类型维度 | 文生图、图生视频、语音合成分别消耗多少 |
| 业务维度 | 哪个功能、用户群、活动来源消耗最多 |
可以设计一个简化成本模型:
task_cost = model_unit_cost * generation_count + retry_cost + file_transfer_cost + storage_cost
这个公式不一定精确,但有助于提醒团队:模型费用不是全部成本。文件传输、对象存储、CDN、失败重试和重复提交,都可能成为实际成本的一部分。
十一、示例压测数据:如何评估统一任务层
下面给出一组示例压测口径,用于说明应该如何观察系统表现。数据为模拟场景,不代表任何平台或模型的真实指标。
测试场景:同时提交 1000 个多模态任务,其中 60% 为文生图,30% 为图生视频,10% 为语音合成。对比“业务直连模型”和“统一任务层”两种架构。
| 指标 | 业务直连模型 | 统一任务层 | 观察结论 |
|---|---|---|---|
| 平均创建耗时 | 420ms | 95ms | 任务层先入队,创建请求更轻 |
| P95 创建耗时 | 1800ms | 210ms | 长任务不阻塞用户请求 |
| 状态查询成功率 | 92.4% | 99.1% | 状态统一后查询更稳定 |
| 重复任务比例 | 6.8% | 0.7% | 幂等键降低重复提交 |
| 失败定位平均耗时 | 18min | 4min | task_id 串联日志后更容易排查 |
| 异常重试成本占比 | 14.5% | 5.2% | 重试边界更清晰 |
这类测试的重点不是追求某个绝对数值,而是验证架构是否真的改善了以下问题:
- 用户请求是否被长任务阻塞。
- 重复提交是否被控制。
- 失败后能否定位到具体阶段。
- 异常重试是否被记录和限制。
- 文件交付是否稳定。
如果任务层只是换了一层接口,但没有解决状态、幂等、日志和成本统计问题,那么它并没有真正发挥作用。
十二、对比测试:不同模型不应该直接由业务判断
多模型系统中,经常会遇到“哪个模型效果更好”的问题。这个问题不能只靠主观判断,也不能完全写死在业务代码里。
比较合理的方式是建立小规模对比测试机制。比如针对同一批输入,分别调用不同模型,记录成功率、耗时、人工评分、成本等指标。
示例表如下,数据同样为说明口径:
| 模型组 | 成功率 | 平均耗时 | P95 耗时 | 单任务成本指数 | 人工质量评分 |
|---|---|---|---|---|---|
| image_model_a | 98.2% | 8.4s | 15.6s | 1.0 | 7.6 |
| image_model_b | 96.9% | 11.2s | 21.3s | 1.4 | 8.3 |
| image_model_c | 93.5% | 6.1s | 12.8s | 0.7 | 6.9 |
如果是批量生成草稿,可能优先选择成本指数低、耗时短的模型;如果是最终交付,可能优先选择质量评分高的模型。调度层应该能承载这种策略,而不是让业务代码散落各种判断。
十三、异常处理与降级策略
生产环境中,模型不可用、响应变慢、返回异常都是常态。系统设计的目标不是让错误完全消失,而是让错误发生时仍然可控。
常见异常可以分为几类:
| 异常类型 | 示例 | 建议处理 |
|---|---|---|
| 参数错误 | 输入格式不合法 | 直接失败,不重试 |
| 内容拦截 | 输入或输出触发安全策略 | 返回明确业务错误 |
| 限流 | 上游返回 429 | 延迟重试或切换模型 |
| 网络错误 | 请求超时、连接失败 | 短间隔有限重试 |
| 任务超时 | 长时间无结果 | 标记 timeout,进入人工或自动补偿 |
| 文件失败 | 下载或转存失败 | 重试文件阶段,不重复生成 |
这里有一个重要原则:能只重试后处理,就不要重跑模型。比如模型已经生成成功,只是文件转存失败,那么应该重试文件转存,而不是重新生成。否则不仅浪费成本,还可能导致用户得到和原来不同的结果。
十四、安全与权限设计
多模态任务经常涉及用户上传文件、生成内容和结果下载,因此安全设计不能忽略。
至少需要考虑以下几点:
- API Key 或访问凭证不能暴露在前端。
- Webhook 必须校验签名,避免伪造回调。
- 文件访问地址应有权限控制,避免越权访问。
- 用户上传文件要做大小、格式和内容校验。
- 任务查询接口要校验任务归属,不能只凭 task_id 返回结果。
- 日志中避免记录完整敏感输入,必要时存摘要或脱敏字段。
很多系统在 Demo 阶段会直接把结果 URL 返回给前端,这在生产环境里风险较高。更稳妥的方式是由后端生成受控访问地址,并在查询任务时进行权限判断。
十五、测试方案:不仅要测模型效果
多模态 AI 应用的测试不能只看生成效果,还要覆盖任务生命周期。
建议测试用例至少包括:
| 测试类型 | 重点 |
|---|---|
| 创建任务测试 | 参数校验、幂等、重复提交 |
| 状态流转测试 | pending 到 success / failed 是否正确 |
| 回调测试 | 签名、重复回调、乱序回调 |
| 轮询测试 | 查询频率、超时、终态一致性 |
| 文件测试 | 下载失败、转存失败、URL 过期 |
| 重试测试 | 可重试错误和不可重试错误区分 |
| 成本测试 | 重试次数、重复任务、模型用量统计 |
| 并发测试 | 多任务同时执行时状态是否错乱 |
其中,乱序回调和重复回调特别容易被忽略。真实环境中,系统可能先收到成功回调,又收到较早的处理中回调。如果没有状态版本或终态保护,任务状态可能被旧回调覆盖。
一个简单原则是:终态不能被非终态覆盖。任务一旦进入 success、failed、timeout、canceled,后续回调必须经过严格判断,不能随意更新状态。
十六、常见反模式
最后总结几个多模态 AI 系统中常见的反模式。
16.1 业务代码直接调用所有模型
这是最常见的问题。前期最快,后期最难维护。每个模型的参数、错误、返回结构都进入业务层,系统会迅速耦合。
16.2 只记录最终成功或失败
很多日志看起来很多,但真正排查时发现没有关键事件。对于长任务,只记录最终状态远远不够,必须记录中间阶段。
16.3 失败后一律重跑
这会导致成本放大,也会破坏结果一致性。应该区分模型失败、文件失败、回调失败和前端查询失败。
16.4 直接使用上游临时 URL
短期实现方便,但长期会遇到过期、权限、跨域和审计问题。正式系统应尽量转存到自己的文件服务。
16.5 没有成本维度
只看总账单无法指导优化。成本必须能拆到模型、任务类型和业务功能,否则无法判断问题来源。
结语
统一任务层的本质,是把不稳定、差异化、长耗时的模型调用,转换成业务系统可管理的工程对象。
它带来的价值主要有三点。
第一,降低业务耦合。业务模块只处理任务创建和结果消费,不直接依赖具体模型接口。模型更新、接口调整、供应商变化,都可以尽量收敛在适配器和任务层中。
第二,提升问题定位效率。每次调用都有任务记录,失败时可以知道是参数问题、模型问题、文件问题,还是回调问题。对于生产环境来说,能定位问题往往比单次调用成功更重要。
第三,便于后续扩展。新增模型时,只需要实现新的适配器,并接入统一任务协议。新增业务场景时,也可以复用已有任务状态、文件交付和日志体系。
多模态 AI 应用从 Demo 到生产,最大的变化不是模型能力,而是工程边界。只要系统开始涉及异步、媒体文件、并发、重试和成本,就应该尽早引入统一任务抽象。无论是自建任务层,还是参考 crun ai 这类平台的实现方式,核心目标都是一致的:让模型调用从一次请求,变成一个可追踪、可治理、可交付的任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)