R 语言 逻辑斯蒂回归
逻辑斯蒂回归用于二分类(0/1 因变量),因变量 y:只能取 0 或 1,事件发生概率,范围 (0,1)
# 加载内置数据集:mtcars(二分类变量vs:0=V型,1=直列)
data(mtcars)
# 查看数据
head(mtcars)
# 目标:用mpg、wt、hp预测 vs(0/1二分类)
# glm() 通用线性模型,family = binomial 就是逻辑斯蒂回归
logit_model <- glm(
formula = vs ~ mpg + wt + hp, # 因变量~自变量
data = mtcars,
family = binomial(link = "logit")
)
# 输出模型详细结果
summary(logit_model)
Call:
glm(formula = vs ~ mpg + wt + hp, family = binomial(link = "logit"), data = mtcars)
Deviance Residuals: # 偏差残差,越小拟合越好
Min 1Q Median 3Q Max
-2.0157 -0.4043 -0.0158 0.4775 1.8834
Coefficients: # 核心系数表
Estimate Std. Error z value Pr(>|z|)
(Intercept) 18.57445 7.38663 2.515 0.01192 *
mpg -0.11965 0.14794 -0.809 0.41879
wt -4.24346 1.86899 -2.270 0.02317 *
hp -0.03237 0.01821 -1.778 0.07539 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
- Estimate:回归系数(beta)
- 正数:自变量越大,(y=1)概率越大
- 负数:自变量越大,(y=1)概率越小
- Std.Error:系数标准误
- z value:Z 检验统计量
- Pr(>|z|):P 值
- (P<0.05):自变量显著影响分类结果
# 提取优势比 exp(系数)
exp(coef(logit_model))
# 置信区间
exp(confint(logit_model))Waiting for profiling to be done...
2.5 % 97.5 %
(Intercept) 1.720775e-22 1.062851e+09
mpg 7.432421e-01 5.813725e+00
wt 2.934997e-01 2.461978e+05
hp 8.035275e-01 9.713645e-01
共有25个警告 (用warnings()来显示)
(OR>1):自变量增大,发生事件概率上升
(OR<1):自变量增大,发生事件概率下降
预测与评价
# 1. 训练集内预测概率
pre_prob <- predict(logit_model, type = "response")
# 2. 转为0/1分类结果(阈值0.5)
pre_class <- ifelse(pre_prob > 0.5, 1, 0)
head(pre_class)
# 真实值 vs 预测值
table(真实值=mtcars$vs, 预测值=pre_class)
# 计算准确率
acc <- mean(pre_class == mtcars$vs)
acc
预测值
真实值 0 1
0 16 2
1 0 14
> # 计算准确率
[1] 0.9375
可视化
# 1. 生成自变量序列(连续取值,用于画平滑曲线)
wt_seq <- seq(min(mtcars$wt), max(mtcars$wt), length.out = 100)
# 2. 构造预测数据集(其余自变量取均值,控制变量)
new_data <- data.frame(
wt = wt_seq,
mpg = mean(mtcars$mpg),
hp = mean(mtcars$hp)
)
# 3. 预测概率
prob_pred <- predict(logit_model, newdata = new_data, type = "response")
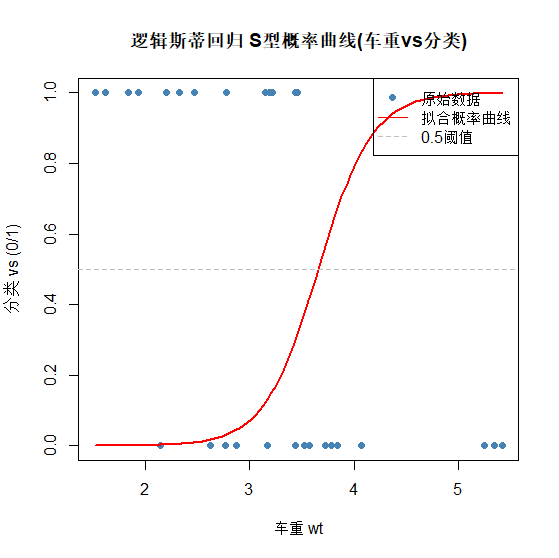
# 4. 绘图:原始散点 + 拟合S曲线
plot(
x = mtcars$wt,
y = mtcars$vs,
main = "逻辑斯蒂回归 S型概率曲线(车重vs分类)",
xlab = "车重 wt",
ylab = "分类 vs (0/1)",
pch = 16, col = "steelblue"
)
# 绘制拟合曲线
lines(wt_seq, prob_pred, lwd = 2, col = "red")
# 添加0.5阈值线
abline(h = 0.5, lty = 2, col = "gray")
legend("topright", legend = c("原始数据", "拟合概率曲线", "0.5阈值"),
col = c("steelblue", "red", "gray"), pch = c(16, NA, NA), lty = c(NA, 1, 2))

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)