机器学习:决策树和神经网络以及特征工程(搬运自kaggle网站)
目录
1.机器学习导论
1.1 模型的工作原理
1.1.1 基本决策树
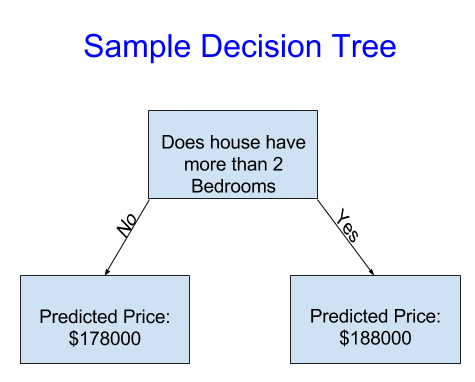
基本决策树将房屋划分为两类。对于任意待评估的房屋,其预测价格就是对应类别房屋的历史均价。
我们依托数据完成房屋分组,并确定每组的预测价格。这种从数据中挖掘规律的过程,称为模型拟合或模型训练,用于训练模型的数据则叫做训练数据。
模型拟合的具体细节(例如数据划分方式)较为复杂,我们后续再详细讲解。模型训练完成后,便可将其应用在新数据上,预测其他房屋的价格。
1.1.2 优化决策树
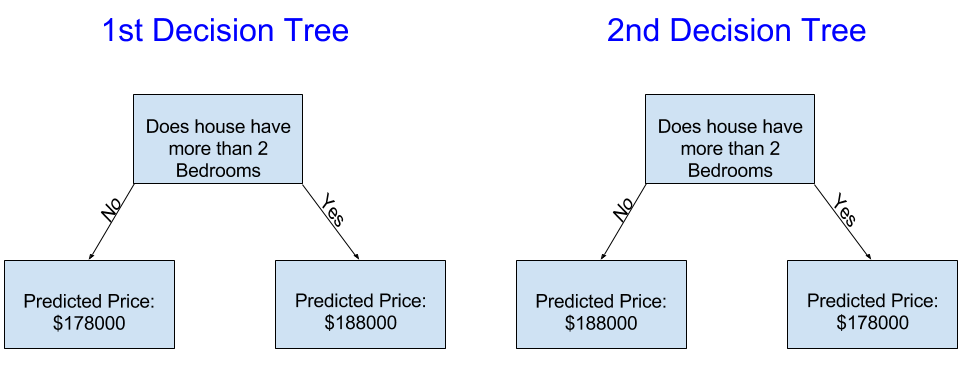
左侧的决策树更为合理,因为它反映了一个实际规律:卧室数量越多的房屋,售价往往越高。该模型最大的不足是未能涵盖影响房价的大部分因素,例如卫生间数量、地块面积、地理位置等。我们可以通过增加分支节点来纳入更多影响因素,这类树也被称作深度更大的决策树。
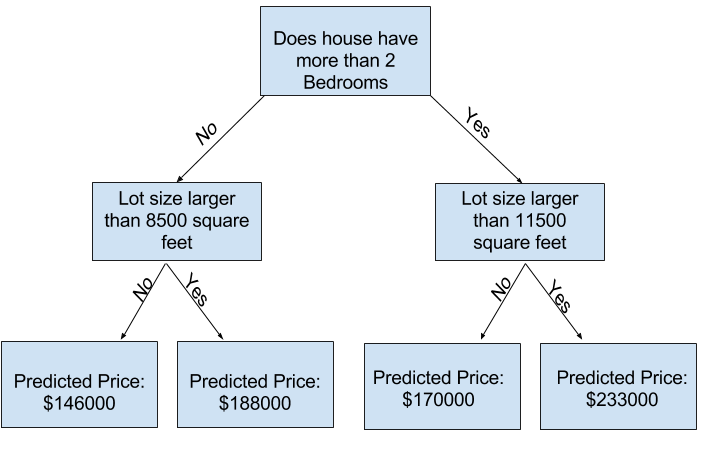
你只需沿着决策树、根据房屋特征选择对应分支,就能得出房价预测结果。树的末端节点即为该房屋的预测价格,这类用于输出预测结果的末端节点被称为叶节点。
数据会决定分支规则与叶节点的数值,接下来我们就来了解即将使用的数据集。
1.2 基础数据探索
1.2.1 利用 Pandas 熟悉数据集
开展任何机器学习项目,第一步都是熟悉数据。我们会使用 Pandas 库完成这项工作。
import pandas as pd
Pandas 库中最重要的部分是数据框(DataFrame)。DataFrame 可存储表格形式的数据,和 Excel 工作表、SQL 数据库里的数据表结构类似。
针对这类表格数据的各类操作,Pandas 都提供了功能强大的方法。
我们以澳大利亚墨尔本的房价数据为例进行演示。在实操练习中,你将用同样的方法处理另一套艾奥瓦州的房价数据集。
本次示例使用的墨尔本数据文件路径为:../input/melbourne-housing-snapshot/melb_data.csv。
接下来通过以下代码加载并查看这份数据:
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv' melbourne_data = pd.read_csv(melbourne_file_path) melbourne_data.describe()
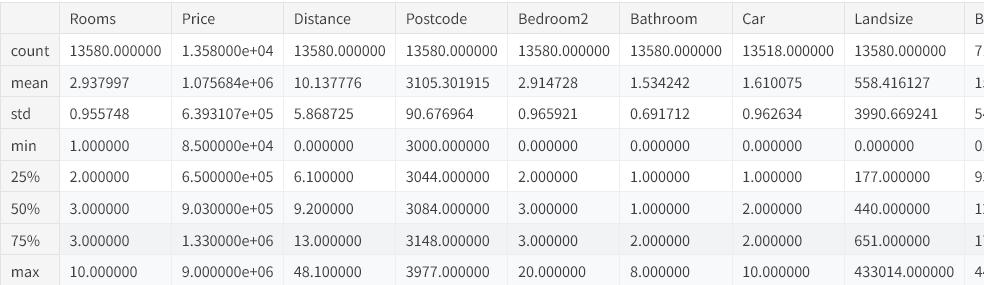
1.2.2 解读数据描述统计结果
输出结果会为原始数据集的每一列展示8 项统计指标。第一项是计数(count),代表该列中非缺失值的行数。
数据缺失的成因有很多。比如在统计一居室房屋信息时,就不会采集第二间卧室的面积。后续我们会详细讲解缺失数据的处理方法。
第二项是均值(mean),也就是平均值。其下方的标准差(std),用于衡量数据的离散程度。
再来解读最小值(min)、25%、50%、75% 和最大值(max)。我们可以假想将每一列数据按数值从小到大排序:排在首位的最小值就是最小值。从排序后的列表开头往后数四分之一位置,对应的数值大于整体 25% 的数据、小于其余 75% 的数据,这就是25 分位数。50 分位数、75 分位数的定义以此类推,而最大值就是整列数据里的最大数值。
1.3 第一个机器学习模型
1.3.1 选取建模数据
数据集里的变量数量繁多,不仅难以梳理,也不方便完整展示。该如何精简数据,让内容变得清晰易懂?
我们先凭借经验挑选部分变量,后续课程会介绍借助统计方法自动筛选重要变量的技巧。
如需选择变量(列),可以查看数据集的全部列名,借助 DataFrame 的 columns 属性即可实现,对应代码见下文最后一行。
import pandas as pd melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv' melbourne_data = pd.read_csv(melbourne_file_path) melbourne_data.columns

1.3.2 选择预测目标
选取数据子集的方法有很多。Pandas 专项课程会对此展开详细讲解,这里我们先介绍两种常用方式:
- 点语法:用于选取预测目标
- 列名列表选取:用于选取特征
可以使用点语法提取单个变量。这一列数据会以序列(Series)形式存储,它可以理解为仅包含单列数据的 DataFrame。我们将通过点语法选出需要预测的列,该列即为预测目标。按照行业惯例,预测目标通常用变量 y 表示。
y = melbourne_data.Price
1.3.3 选择特征
输入到模型中、后续用于开展预测的列,被称作特征。在本案例中,特征就是用来判断房价的各项数据列。有时我们会把除预测目标外的所有列都当作特征,而有时选用少量特征效果会更好。
现阶段,我们仅选取部分特征来构建模型。后续你会学习如何迭代调整特征,并对比不同特征组合训练出的模型。
选取多个特征时,可在方括号内传入列名列表,列表中的每个列名都需要用引号包裹,格式为字符串。按照惯例,将特征数据记作 X。
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude'] X = melbourne_data[melbourne_features]
我们先用 describe 和 head 方法快速查看待用于房价预测的数据集,其中 head 方法会展示数据的前几行内容。
X.describe()
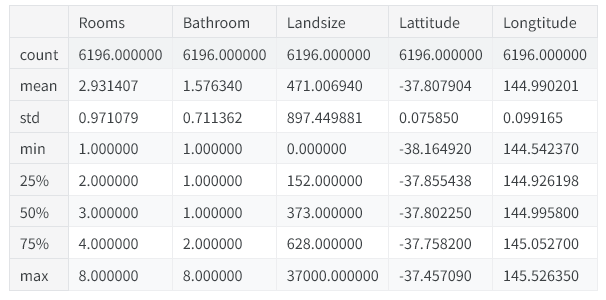
X.head()
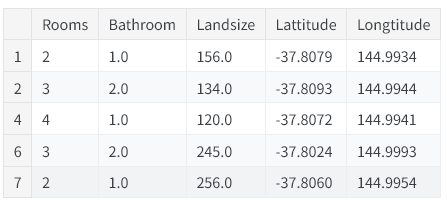
1.3.4 构建机器学习模型
你将使用 scikit-learn 库来搭建模型,代码中通常简写为 sklearn,示例代码里会看到这种写法。对于存储在数据框(DataFrame)中的常规数据建模,scikit-learn 是目前最主流的工具库。
搭建并使用模型主要分为四个步骤:
- 定义:确定模型类型,比如决策树或其他模型,同时设置模型的相关参数。
- 拟合:从已有数据中挖掘规律,这是建模的核心环节。
- 预测:顾名思义,使用模型输出预测结果。
- 评估:检验模型预测结果的准确度。
下面举例演示如何借助 scikit-learn 定义决策树模型,并使用特征数据和目标变量完成模型拟合。
from sklearn.tree import DecisionTreeRegressor # 定义模型 melbourne_model = DecisionTreeRegressor(random_state=1) # 拟合模型 melbourne_model.fit(X, y)
1.4 模型验证
你已经搭建好了模型,但它的效果究竟如何?
本节课将学习使用模型验证来评估模型质量。评估模型优劣,是迭代优化模型的关键。
1.4.1 什么是模型验证
几乎所有搭建的模型都需要进行评估。在绝大多数应用场景中,衡量模型优劣的核心标准是预测准确率,也就是模型的预测结果与实际情况是否接近。
很多人在评估预测准确率时会犯一个严重错误:直接用训练数据做预测,再将预测结果和训练数据里的真实目标值进行比对。下文会讲解这种做法存在的问题以及对应的解决办法,我们先了解一下这个错误的评估方式。
首先,需要用直观的方式量化模型效果。假如对比一万套房屋的预测房价与真实房价,结果必然有准有偏差。逐一查看这上万组数据毫无意义,因此我们需要用单一指标来综合评判模型。
评估模型效果的指标有很多,这里先介绍平均绝对误差(MAE)。我们从该指标里的 “误差” 一词开始拆解解释。
举个例子:一套房屋实际售价为 15 万美元,而你的预测值是 10 万美元,那么误差就是 5 万美元。
计算平均绝对误差(MAE)时,我们会先取每个误差的绝对值,让所有误差都变为正数,再对这些绝对值求平均值,以此评判模型效果。通俗来讲就是:
平均来看,我们的预测结果与实际值相差 X。
计算平均绝对误差前,首先需要训练好模型。
from sklearn.tree import DecisionTreeRegressor
# Define model. Specify a number for random_state to ensure same results each run
melbourne_model = DecisionTreeRegressor(random_state=1)
# Fit model
melbourne_model.fit(X, y)
# Data Loading Code Hidden Here
import pandas as pd
# Load data
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# Filter rows with missing price values
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# Choose target and features
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.tree import DecisionTreeRegressor
# Define model
melbourne_model = DecisionTreeRegressor()
# Fit model
melbourne_model.fit(X, y)
得到模型后,我们可以按照以下方式计算平均绝对误差:
from sklearn.metrics import mean_absolute_error predicted_home_prices = melbourne_model.predict(X) mean_absolute_error(y, predicted_home_prices)
结果显示:

1.4.2 样本内评分存在的问题
我们刚刚计算出的指标属于样本内评分。也就是使用同一批房屋数据,既用来训练模型,又用来评估模型效果。这种做法存在明显弊端,原因如下:
试想在真实的房产市场中,房门颜色和房价其实毫无关联。
但如果你的训练数据里,恰好所有绿色房门的房屋价格都很高。模型的作用是挖掘数据中用于预测房价的规律,它就会捕捉到这一现象,并默认绿色房门的房子都价值不菲。
由于该规律仅来自训练数据,模型在这份数据上的表现看起来会十分准确。
可一旦面对新数据,这条虚假规律不再成立,模型在实际应用中的预测结果就会严重失准。
模型的实际价值,体现在对全新数据做出预测。因此,我们要使用未参与模型训练的数据来评估性能。最直接的办法就是:拆分出一部分数据不用于训练,再用这份模型从未接触过的数据检验预测准确度,这部分数据就叫做验证集。
1.4.3 拆分数据集为训练集和验证集
scikit-learn 库提供了 train_test_split 函数,可将数据集拆分为两部分。一部分作为训练集用于拟合模型,另一部分作为验证集来计算平均绝对误差。
from sklearn.model_selection import train_test_split # 固定随机比例拆分原数据集 train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0) # 定义模型 melbourne_model = DecisionTreeRegressor() # 拟合模型 melbourne_model.fit(train_X, train_y) # 评估模型 val_predictions = melbourne_model.predict(val_X) print(mean_absolute_error(val_y, val_predictions))

该模型在样本内数据上的平均绝对误差约为 500 美元,而在样本外数据上的误差却超过了 25 万美元。
二者差距悬殊:一个模型看似预测结果近乎完美,另一个却基本无法投入实际使用。参考数据来看,验证集中房屋的均价为 110 万美元,也就是说模型在新数据上的误差达到了房屋均价的四分之一。
想要优化这个模型有很多方法,比如尝试筛选更优质的特征,或是更换不同类型的模型。
1.5 欠拟合与过拟合
1.5.1 尝试不同模型
如今你已经掌握了可靠的模型精度评估方法,接下来可以尝试各类不同模型,从中挑选预测效果最佳的那一个。那么我们有哪些模型可以选择呢?
查阅 scikit-learn 官方文档就能发现,决策树模型包含大量参数(短期内你未必都会用到)。其中树的深度是最关键的参数。回顾本课程第一部分内容,树的深度指模型在得出预测结果前进行数据切分的次数。下图展示的就是一棵层数较少的浅决策树。
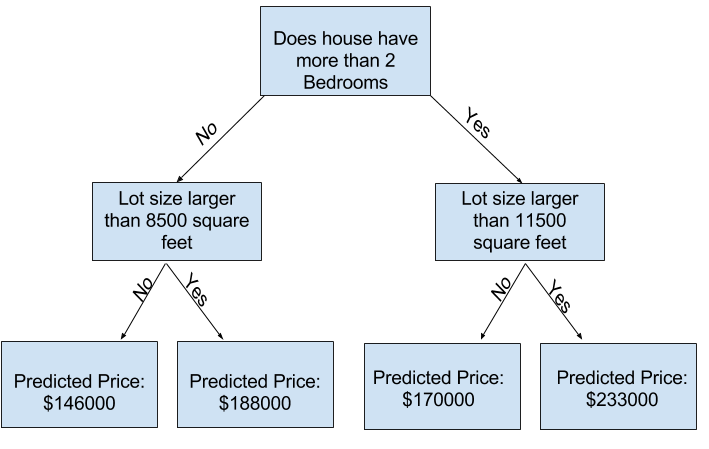
在实际应用中,从根节点(全部房屋数据)到叶节点,决策树进行 10 次划分是很常见的。树的深度越大,划分出的每个叶节点包含的房屋样本就越少。 只进行 1 次划分,数据会被分为 2 组;每组再划分一次,就得到 4 组数据;继续划分则会产生 8 组。每多一层划分,分组数量就翻倍,当达到第 10 层时,一共会产生 210 也就是 1024 个叶节点。
当数据被划分成大量叶节点后,每个节点内的样本数量会变得极少。这类节点对训练数据的预测结果会和真实值高度接近,但面对新数据时预测结果会极不可靠,因为其预测依据仅仅是少量样本。
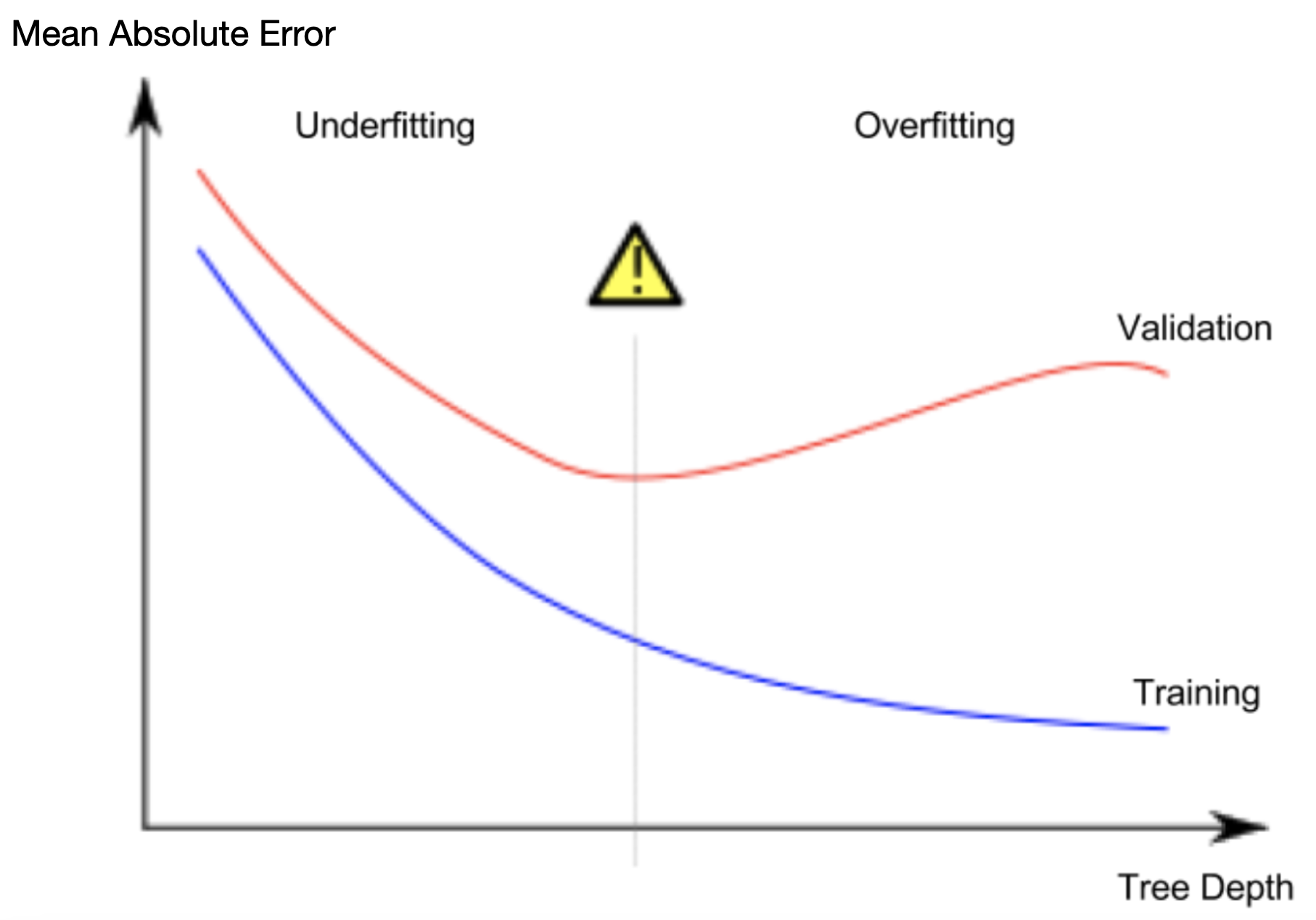
这种情况就是过拟合:模型几乎完美适配训练数据,却在验证集和其他新数据上表现糟糕。反之,如果决策树层数过浅,就无法将房屋数据划分成特征差异明显的组别。
极端情况下,若整棵树只划分出 2 到 4 个分组,每个组内的房屋样本依然五花八门。此时即便在训练数据上,大部分房屋的预测结果也会偏差很大,在验证集上的表现同样不佳。模型无法捕捉数据中关键的特征与规律、哪怕在训练集上效果也很差,这种现象称为欠拟合。
我们的目标是提升模型在新数据上的预测精度(以验证集结果作为评判标准),因此需要在欠拟合与过拟合之间找到最优平衡点。对应下图中,就是红色验证曲线的最低点。
1.5.2 尝试不同深度的决策树模型
控制决策树深度有多种方式,部分方式允许树中不同分支的深度存在差异。而 max_leaf_nodes(最大叶节点数)参数,是平衡过拟合与欠拟合的实用方法。模型允许生成的叶节点数量越多,模型就会从上图中的欠拟合区间逐步偏向过拟合区间。
我们可以借助工具函数,对比不同 max_leaf_nodes 取值对应的平均绝对误差(MAE)。
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))

可以看到在所列参数中,500 是最优的叶节点数量。
1.6 随机森林
使用决策树时总会面临一个两难选择:节点繁多的深树容易出现过拟合,因为每个预测结果仅依据叶节点中少量房屋的历史数据;而叶节点稀少的浅树又表现不佳,无法充分挖掘原始数据中的各类特征差异。
即便是如今最先进的建模技术,也同样要面对欠拟合与过拟合之间的矛盾。不过不少模型通过巧妙的设计实现了更优的效果,接下来我们就以随机森林为例进行讲解。
随机森林由多棵决策树组成,它会综合每一棵子树的预测结果并取平均值,以此得到最终预测。相比单一决策树,随机森林的预测精度通常更高,且使用默认参数就能达到不错的效果。如果你继续深入学习,还会接触到更多性能更出色的模型,但这类模型大多对参数调优有较高要求,如果不想在建模调参上浪费大量时间,那么随机森林会是不错的选择。
from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_absolute_error forest_model = RandomForestRegressor(random_state=1) forest_model.fit(train_X, train_y) melb_preds = forest_model.predict(val_X) print(mean_absolute_error(val_y, melb_preds))
![]()
模型仍有进一步优化的空间,但对比最优决策树 25 万美元的误差,本次结果已有大幅提升。和调整单棵决策树的最大深度类似,你也可以通过参数设置来改变随机森林的表现。而随机森林最大的优势之一,就是即便不进行参数调优,通常也能取得不错的效果。
2. 深度学习导论
2.1 一个单一神经元
2.1.1 什么是深度学习
近年来,人工智能领域诸多亮眼的突破都诞生于深度学习方向。机器翻译、图像识别、博弈对战等任务中,深度学习模型的表现已接近甚至超越人类水平。
那么到底什么是深度学习?深度学习是机器学习的一个分支,核心特点是多层级的计算堆叠。正是这种多层计算结构,让深度学习模型能够解析现实复杂数据中存在的层级化、高复杂度规律。
凭借强大的拟合能力与可扩展性,神经网络成为了深度学习的核心模型。神经网络由一个个神经元构成,单个神经元仅执行简单运算,而神经网络的强大能力,来源于神经元之间复杂的连接关系。
2.1.2 线性单元
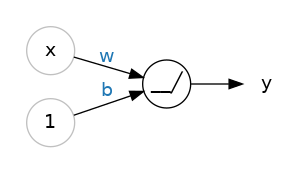
我们先从神经网络的基础单元 —— 单个神经元开始学习。下图展示了仅有一个输入的神经元(也称作单元)结构:
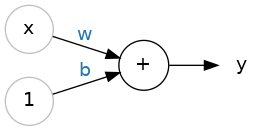
输入值为 x,它与神经元之间的连接对应权重 w。数据在连接中传递时,会乘以该连接的权重。因此输入 x 传递到神经元的结果为 w⋅x。神经网络正是通过调整权重来完成学习。
b 是一种特殊权重,我们称之为偏置。偏置没有对应的输入数据,示意图中会标注数值 1,这样传入神经元的值就等于 b(因为 1×b=b)。借助偏置,神经元可以脱离输入、独立调整输出结果。
y 是神经元最终的输出值。神经元会将所有连接传入的数值相加,得到输出。该神经元的激活公式为: y=wx+b
2.1.3 示例 —— 作为模型的线性单元
单个神经元通常只是大型网络的组成部分,但我们常把单神经元模型当作基准模型来入门。单神经元模型本质上属于线性模型。
以80 种谷物数据集为例来看实际应用:我们将 “糖分”(每份所含糖的克数)作为输入,“热量”(每份所含卡路里)作为输出训练模型,最终得到偏置 \(b=90\)、权重 \(w=2.5\)。据此,我们可以计算出每份含糖 5 克的谷物的热量,计算方式如下:

2.1.4 多输入
80 种谷物数据集除了 “糖分” 外,还有诸多其他特征。如果我们想在模型中加入膳食纤维、蛋白质含量等指标,该如何实现?方法很简单:只需为神经元新增输入连接,每个特征对应一条连接。计算输出时,将每个输入值与对应连接的权重相乘,再把所有结果相加即可。
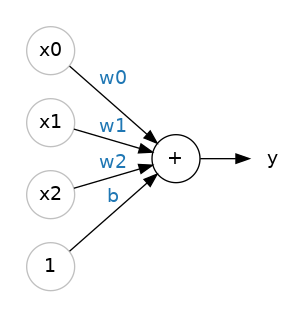
该神经元的计算公式为: \(y = w_0x_0 + w_1x_1 + w_2x_2 + b\)
拥有两个输入的线性单元可以拟合一个平面,而输入数量更多的线性单元则会拟合出超平面。
2.1.5 Keras 中的线性单元
在 Keras 中搭建模型最简便的方式是使用 keras.Sequential,它可以按层堆叠的形式构建神经网络。上文这类模型,都可以通过全连接层实现(下节课会详细讲解)。
下面我们来定义一个线性模型:接收糖分、膳食纤维、蛋白质这三个输入特征,最终输出卡路里数值,代码写法如下:
from tensorflow import keras
from tensorflow.keras import layers
# 创建单一神经元网络
model = keras.Sequential([
layers.Dense(units=1, input_shape=[3])
])
第一个参数 units 用于指定输出数量。本例中我们仅预测 “卡路里”,因此设置 units=1。
第二个参数 input_shape 用来告知 Keras 输入数据的维度。设置 input_shape=[3],表示该模型接收三个特征作为输入(糖分、膳食纤维、蛋白质)。
2.2 深度神经网络
本节我们将学习如何构建神经网络,使其能够学习深度神经网络所擅长挖掘的复杂数据关联。
本节的核心思路是模块化:用简单的功能单元搭建出复杂网络。此前我们已经了解线性单元如何计算线性函数,接下来我们将学习如何组合、改造这些基础单元,以此拟合更复杂的映射关系。
2.2.1 神经网络层
神经网络通常会将神经元划分成不同层。把一组共享相同输入的线性单元组合在一起,就构成了全连接层。
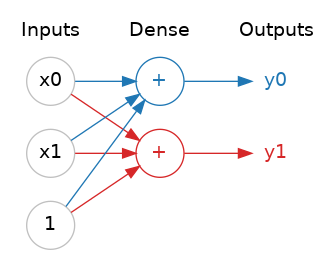
你可以将神经网络中的每一层理解为执行一种相对简单的变换。通过多层堆叠,神经网络能够对输入数据进行愈发复杂的转换。在训练完善的神经网络中,每一层的变换都会让结果一步步逼近最终答案。
2.2.2 激活函数
但实际上,两个全连接层直接相连,效果并不会优于单个全连接层。单纯的全连接层,始终只能拟合直线与平面这类线性关系。我们需要引入非线性元素,而实现这一作用的就是激活函数。
激活函数就是作用于网络层每个输出值(即激活值)的函数。其中最常用的是整流函数,表达式为 max(0,x)。
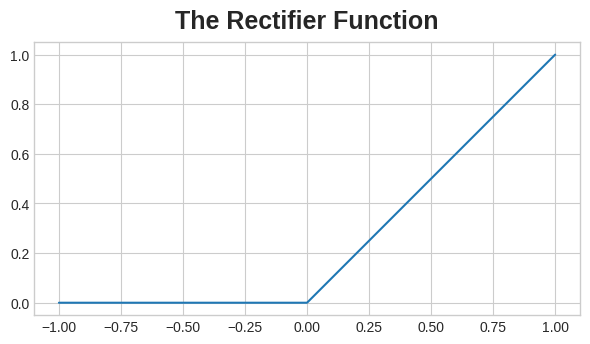
整流函数的图像是一条折线,负数部分会被 “修正” 为 0。将该函数作用于神经元的输出,能让数据产生弯折,突破单纯的线性形态。
在线性单元上搭配整流函数,就得到修正线性单元(ReLU)。因此整流函数也常被称作 ReLU 函数。
2.2.3 堆叠全连接层
有了非线性能力之后,我们再来学习如何通过层堆叠实现复杂的数据变换。
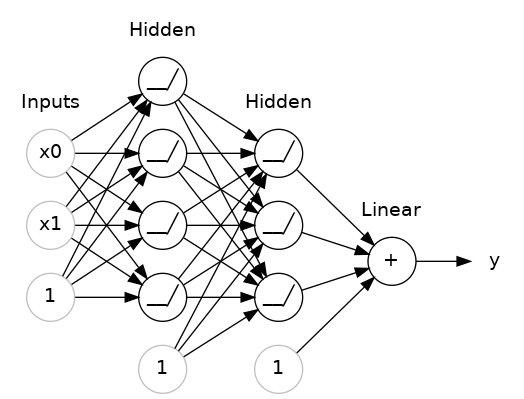
输出层之前的网络层有时被称为隐藏层,因为我们无法直接查看它们的输出结果。
可以注意到,最后一层(输出层)使用的是线性单元,也就是未设置激活函数。这种结构适用于回归任务,这类任务的目标是预测任意数值。而分类等其他任务,则通常需要在输出层搭配激活函数。
2.3.4 构建序贯模型
我们一直使用的序贯模型(Sequential)会按顺序拼接一系列网络层:第一层接收输入数据,最后一层输出结果,由此搭建出上图所示的网络模型。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
# 隐藏层
layers.Dense(units=4, activation='relu', input_shape=[2]),
layers.Dense(units=3, activation='relu'),
# 输出层
layers.Dense(units=1),
])
2.3 随机梯度下降
我们学习了如何通过堆叠全连接层来搭建全连接网络。网络初始化时,所有权重都会被随机赋值,此时网络还不具备任何学习能力。本节课我们将讲解神经网络的训练过程,揭秘神经网络的学习原理。
和所有机器学习任务一样,训练首先需要准备训练数据集。数据集中的每一条样本都包含特征(输入)和预期目标值(输出)。训练网络的本质,就是不断调整权重,让模型能够根据输入特征推算出目标结果。以 80 种谷物数据集为例,我们希望模型能依据每份谷物的糖分、膳食纤维、蛋白质含量,预测出对应的热量值。如果训练成功,网络的权重就会以某种形式,体现出训练数据里特征与目标值之间的关联规律。
除训练数据外,我们还需要另外两个核心组件:
- 损失函数:用于评估模型预测结果的优劣;
- 优化器:指导网络如何更新权重。
2.3.1 损失函数
我们已经学习了如何设计网络结构,但还不清楚如何让网络明确要解决的问题,这正是损失函数的作用。
损失函数用于衡量模型预测值与真实目标值之间的差距。
不同的任务需要搭配不同的损失函数。此前我们接触的是回归任务,这类任务的目标是预测数值,比如谷物数据集里的热量、红酒品质数据中的评分。房价预测、汽车油耗预估也都属于回归任务。
回归任务中常用的损失函数是平均绝对误差(MAE)。对于每个预测值 ypred,平均绝对误差通过计算 |y_{真实值} - y_{预测值}|,来衡量其与真实值 y_{真实值}的偏差。
整个数据集的总平均绝对误差,就是所有样本绝对差值的平均值。
除平均绝对误差(MAE)外,回归任务中还常会用到均方误差(MSE)和休伯损失(Huber loss),这两种损失函数在 Keras 中均可以直接使用。
训练过程中,模型会以损失函数为依据调整权重,损失值越低代表模型效果越好。简单来说,损失函数定义了网络的优化目标。
2.3.2 优化器 —— 随机梯度下降
我们已经明确了网络需要解决的问题,接下来就要确定求解方法,这便是优化器的工作。优化器是一种算法,通过调整权重来最小化损失值。
深度学习中使用的优化算法,基本都属于随机梯度下降这一算法体系。这类算法以迭代方式分步训练网络,单次训练步骤如下:
- 抽取部分训练数据,输入网络得到预测结果;
- 计算预测值与真实值之间的损失;
- 沿着能降低损失的方向更新权重。
不断重复以上流程,直到损失值达到预期标准(或不再继续下降)即可。
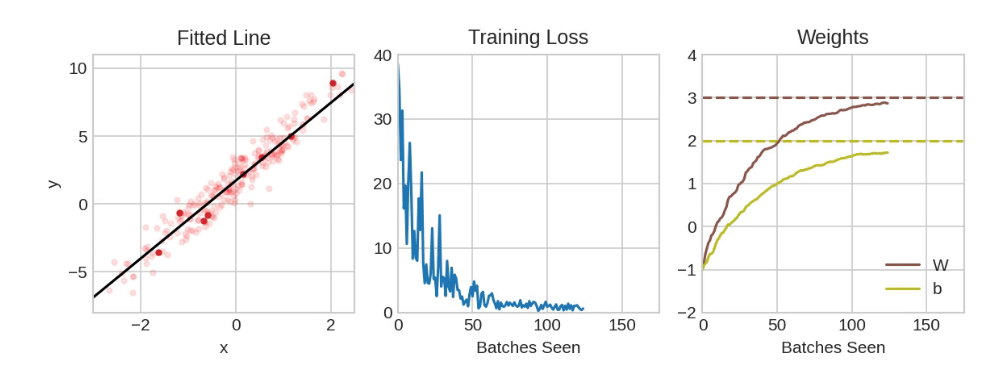
每一轮迭代所抽取的训练数据样本被称为小批量数据(也常简称为批次),而完整遍历一遍全部训练数据的过程则叫做轮次。训练设置的轮次数量,代表网络会将每一条训练样本学习多少次。
2.3.3 学习率与批次大小
学习率决定了每次调整的幅度。学习率越小,网络就需要处理更多小批量数据,权重才能收敛到最优值。
学习率和小批量数据的大小,是对随机梯度下降(SGD)训练过程影响最大的两个参数。二者的相互作用通常较为微妙,想要选出合适的参数并不容易(我们会在练习中探究它们带来的影响)。
好在大多数场景下,无需大范围搜索超参数也能得到理想效果。Adam 是一种改进的随机梯度下降算法,它具备自适应学习率特性,基本无需手动调参就能适配绝大多数任务,某种意义上可实现 “自动调参”,是适用性极强的通用优化器。
2.3.4 配置损失函数与优化器
定义好模型后,可通过模型的 compile 方法来指定损失函数和优化器:
model.compile(
optimizer="adam", # 优化器
loss="mae", # 损失函数
)
2.3.5 实战案例:红酒品质预测
至此,我们已经掌握了训练深度学习模型的全部基础知识,接下来就动手实操。本次使用红酒品质数据集。
该数据集收录了约 1600 款葡萄牙红酒的理化检测指标,同时附带每款红酒通过盲测得出的品质评分。我们尝试根据这些检测数据,预测红酒的感官品质。
数据预处理的代码放在下方,这部分内容并非本节重点,你可以直接跳过。有一点需要留意:我们已将所有特征值归一化至 [0, 1] 区间。第五课会详细讲解,输入数据统一到相同尺度时,神经网络通常能达到最优效果。
数据预处理部分的代码:
import pandas as pd
from IPython.display import display
red_wine = pd.read_csv('../input/dl-course-data/red-wine.csv')
# 拆分训练集和验证集
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
display(df_train.head(4))
# 映射到[0, 1]
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)
# 拆分特征与目标向量
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']

这个网络需要设置多少个输入节点?我们可以查看数据矩阵的列数来确定。注意不要把目标值(quality,品质评分)算在内,仅统计输入特征列。
print(X_train.shape)

一共 11 列,对应 11 个输入节点。
我们搭建了一个三层网络,神经元总数超 1500 个,该网络足以学习数据中较为复杂的关联规律。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
完成模型定义后,接着配置优化器与损失函数。
model.compile(
optimizer='adam',
loss='mae',
)
训练模型:我们设置 Keras 每次向优化器输入 256 行训练数据(即批次大小),并完整遍历整个数据集 10 轮(即训练轮数)。
history = model.fit(
X_train, y_train, # 训练数据
validation_data=(X_valid, y_valid), # 每轮训练结束后测试训练效果
batch_size=256, # 批次大小
epochs=10, # 训练轮数
)
模型训练过程中,Keras 会实时输出损失值。
不过,将损失值绘制成图表往往是更直观的查看方式。fit 方法会把训练过程中的损失数据保存在 History 对象里。我们可以将这些数据转为 Pandas 数据框,方便后续绘图。
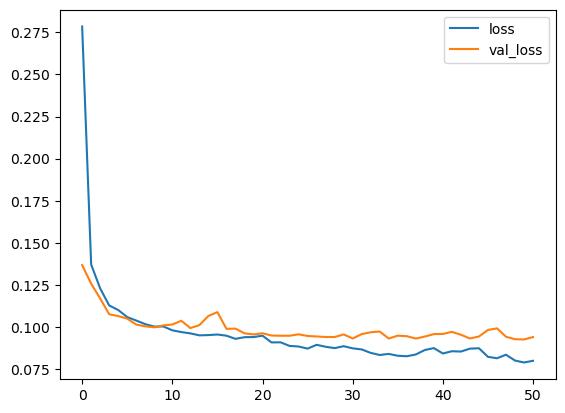
import pandas as pd history_df = pd.DataFrame(history.history) history_df['loss'].plot();
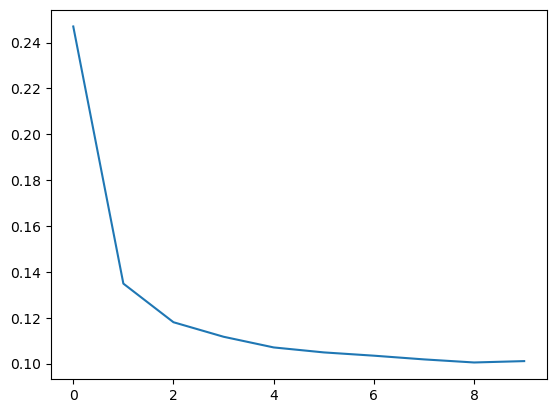
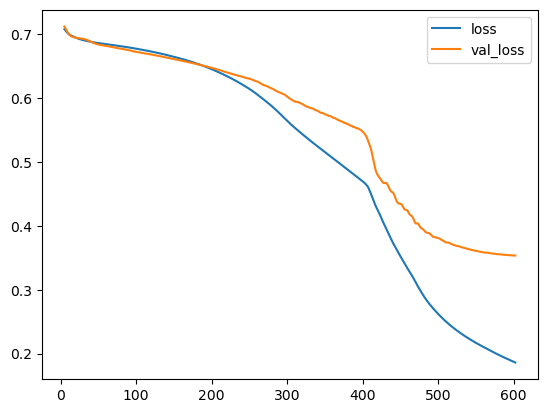
可以看到,随着训练轮次增加,损失值逐渐趋于平稳。当损失曲线呈现水平状态时,说明模型已经达到学习上限,继续增加训练轮次也不会再有提升。
2.4 过拟合与欠拟合
回顾上一节的示例可以知道,Keras 会记录模型训练过程中每一轮的训练损失与验证损失。本节课我们将学习如何解读学习曲线,以及如何借助它指导模型优化。我们会重点通过学习曲线判断模型是否出现欠拟合、过拟合问题,并介绍对应的解决办法。
2.4.1 解读学习曲线
训练数据中包含两类信息:有效特征与噪声。 有效特征具备泛化能力,能帮助模型对新数据做出预测;而噪声仅存在于训练集当中,来源于真实数据里的随机波动,或是一些偶然出现、不具备参考价值的规律,看似有用,实则无法提升模型的预测能力。
训练模型的本质,就是不断调整权重与参数,让模型在训练集上的损失值降至最低。但想要客观评判模型效果,就必须使用全新的数据集 ——验证集进行评估(如需回顾,可参考机器学习入门课程中关于模型验证的内容)。
此前我们会逐轮绘制训练集的损失变化,现在我们再补充绘制验证集的损失曲线,这类曲线图就统称为学习曲线。想要高效训练深度学习模型,学会解读学习曲线至关重要。
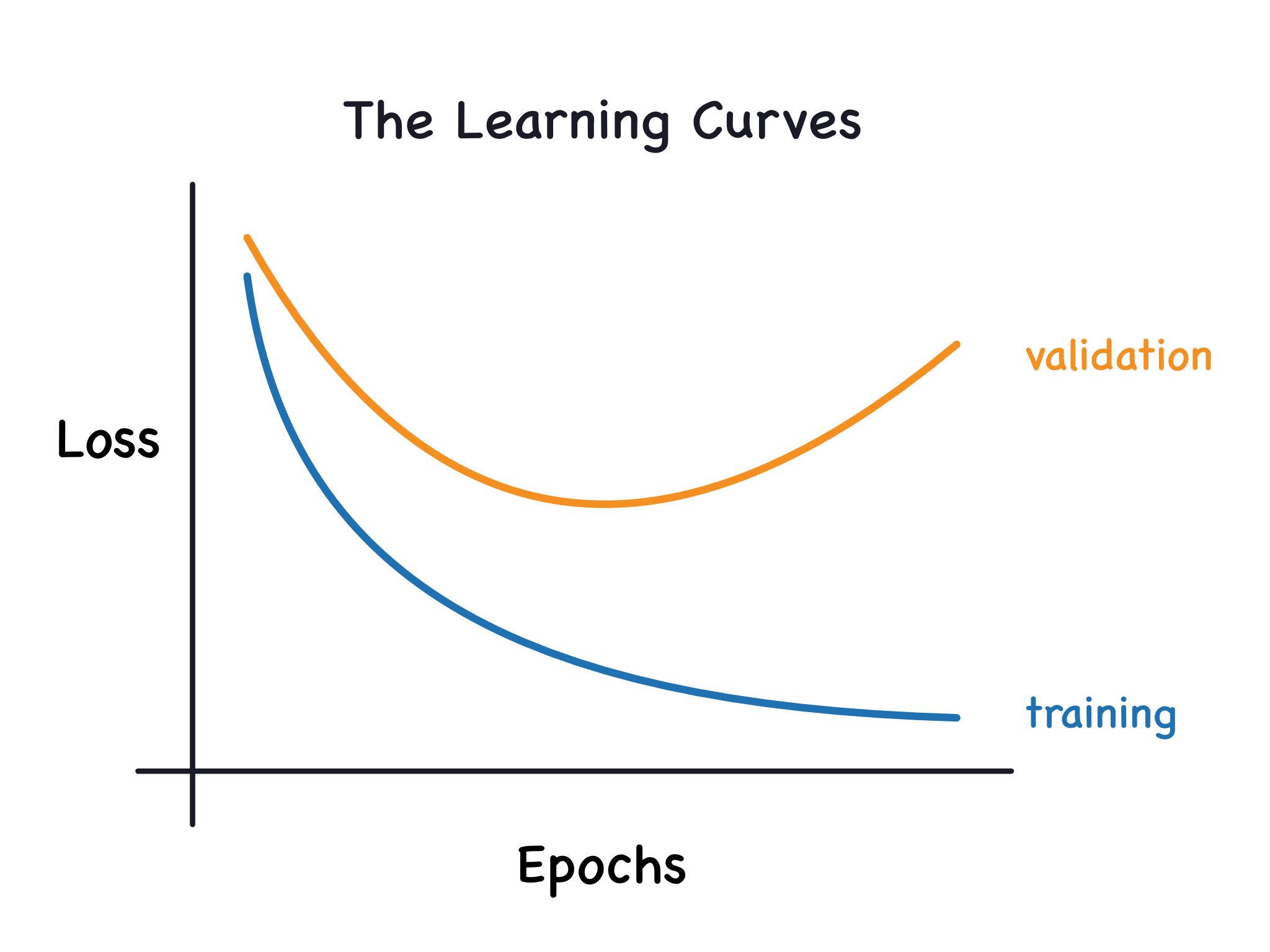
模型无论是学到数据里的有效特征还是噪声,训练损失都会下降。但验证损失只有在模型学到有效特征时才会降低(模型从训练集里学到的噪声,无法适配新数据)。
因此,当模型学习有效特征时,两条损失曲线会同步下降;一旦模型开始学习噪声,两条曲线之间就会出现差距,而差距大小能反映出模型习得噪声的多少。
理想状态下,我们希望模型只学习全部有效特征、完全不受噪声干扰,但这在实际中几乎无法实现。我们往往需要做出取舍:让模型学习更多有效特征的同时,难免也会学到更多噪声。只要这种取舍利大于弊,验证损失就会持续下降。但超过某个临界点后,弊端会盖过收益,验证损失便开始回升。
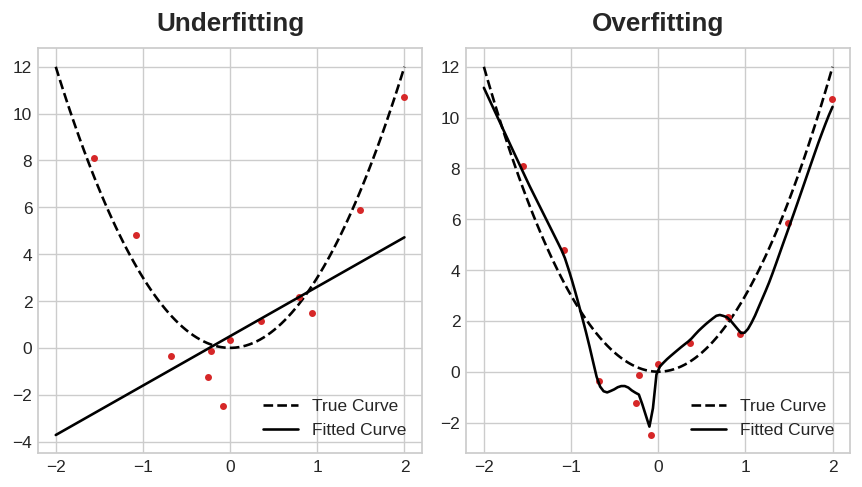
这种取舍关系,对应模型训练中常见的两类问题:有效特征学习不足或是噪声学习过多。
欠拟合指模型未能充分学习数据中的有效特征,导致损失值无法降到理想水平。 过拟合则是模型过度学习了数据里的噪声,同样会造成整体效果不佳。
训练深度学习模型的关键,就是在二者之间找到最佳平衡点。
接下来我们将介绍几种方法,帮助模型从训练数据中提取更多有效特征,同时减少对噪声的学习。
2.4.2 模型容量
模型容量是指模型能够学习的数据模式的范围与复杂程度。对于神经网络,其容量主要由神经元数量以及神经元的连接方式决定。如果网络出现欠拟合现象,就需要尝试提升模型容量。
提升神经网络容量有两种方式:加宽网络(在现有网络层中增加神经元)或加深网络(新增网络层)。加宽的网络更易学习线性关系,加深的网络则更擅长捕捉非线性关系。具体选用哪种方式,取决于对应的数据集。
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(1),
]) # 单隐藏层16个神经元的神经网络
wider = keras.Sequential([
layers.Dense(32, activation='relu'),
layers.Dense(1),
]) # 单隐藏层32个神经元的神经网络--宽度网络
deeper = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1),
]) # 多隐藏层16个神经元的神经网络--深度网络
2.4.3 早停法
当模型过度学习数据中的噪声时,训练过程里验证集损失会开始上升。为避免该问题,一旦发现验证集损失不再下降,便可直接终止训练。这种训练中断方式就叫做早停法。
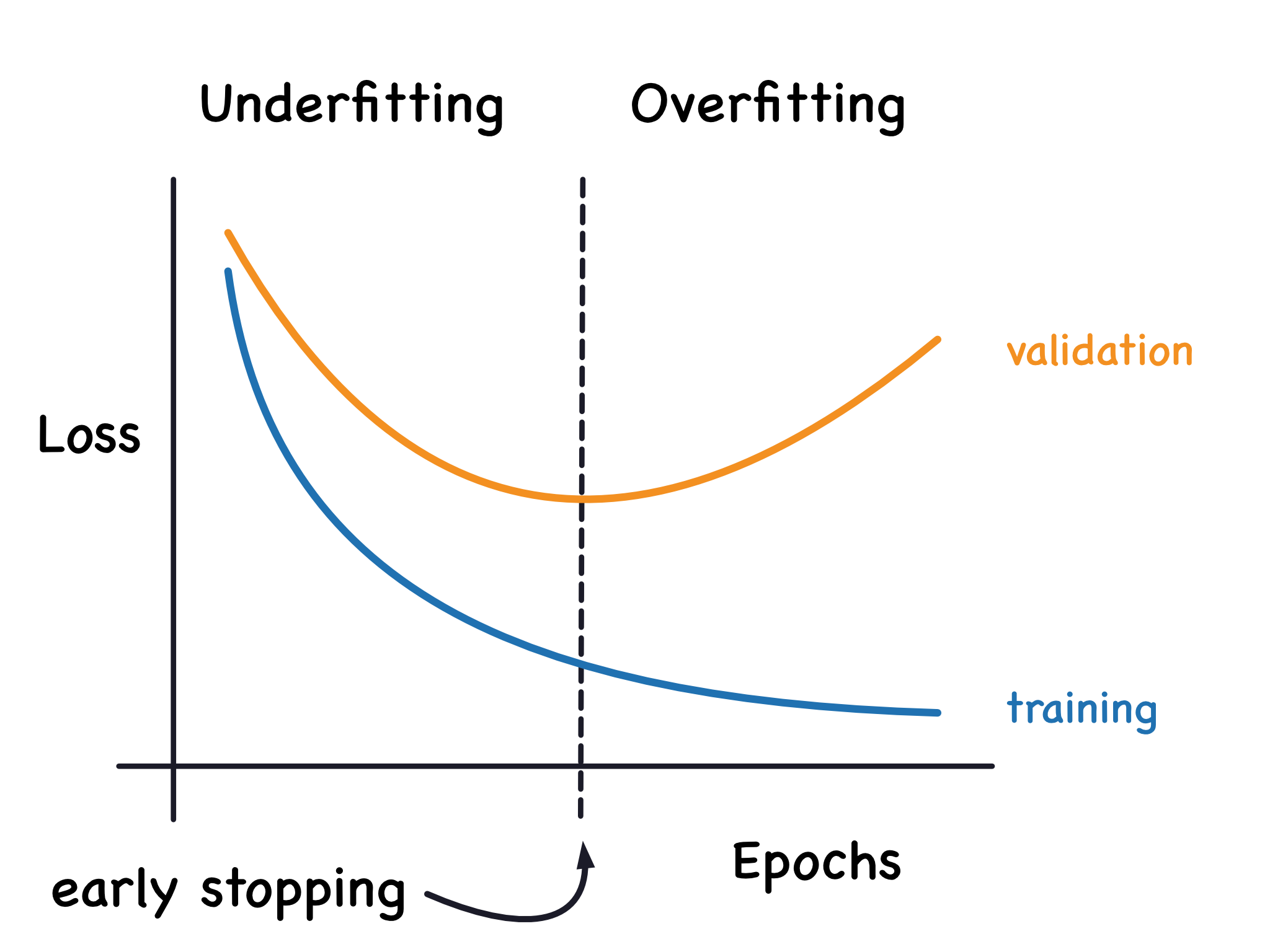
一旦检测到验证损失开始回升,我们就可以将模型权重恢复至损失值最低时的状态。这能避免模型继续学习数据噪声,进而防止过拟合。
采用早停法训练,也能有效规避因训练时长不足、模型尚未学到有效特征就提前终止的问题。因此,早停法既能避免训练过久引发的过拟合,也能防止训练时长不足导致的欠拟合。只需将训练轮数设置为一个较大数值(超出实际所需轮数),后续工作就交由早停法自动处理即可。
2.4.4 添加早停法
在 Keras 中,我们通过回调函数在训练过程中启用早停。回调函数指在网络训练期间按指定频次执行的函数。早停回调会在每一轮训练结束后运行。(Keras 内置了多种实用回调函数,同时也支持自定义回调)
# 导入 Keras 内置的早停回调函数
from tensorflow.keras.callbacks import EarlyStopping
# 创建早停实例,配置防止过拟合的规则
early_stopping = EarlyStopping(
min_delta=0.001, # 最小改善阈值:损失值下降至少 0.001 才算“有提升”
patience=20, # 耐心值:连续 20 轮没有达标提升,就停止训练
restore_best_weights=True, # 恢复最优权重:停止后,用验证集损失最低的那轮参数
)
2.4.5 示例:使用早停法训练模型
我们继续基于上一教程的模型进行优化。本次会提升该神经网络的模型容量,同时引入早停回调函数以防止过拟合。
以下仍是数据预处理部分。
import pandas as pd
from IPython.display import display
red_wine = pd.read_csv('../input/dl-course-data/red-wine.csv')
# Create training and validation splits
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
display(df_train.head(4))
# Scale to [0, 1]
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)
# Split features and target
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']

现在我们来提升网络的模型容量。我们会构建一个规模较大的网络,同时依靠回调函数,在验证集损失出现上升迹象时自动终止训练。
from tensorflow import keras
from tensorflow.keras import layers, callbacks
early_stopping = callbacks.EarlyStopping(
min_delta=0.001, # minimium amount of change to count as an improvement
patience=20, # how many epochs to wait before stopping
restore_best_weights=True,
)
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)
定义好回调函数后,将其作为参数传入fit方法(可传入多个回调函数,需放在列表中)。使用早停法时,建议把训练轮数设置得大一些,超出实际所需轮数即可。
# 开始训练模型
history = model.fit(
X_train, y_train, # 训练集
validation_data=(X_valid, y_valid),# 验证集
batch_size=256, # 每批次训练256个样本
epochs=500, # 最大训练500轮(早停会提前终止)
callbacks=[early_stopping], # 早停回调(多个回调就放列表里)
verbose=0, # 关闭训练过程的日志输出
)
# 把训练记录转成DataFrame
history_df = pd.DataFrame(history.history)
# 绘制 训练损失 & 验证损失 曲线
history_df.loc[:, ['loss', 'val_loss']].plot()
2.5 丢弃层与批次归一化
深度学习不只有全连接层,模型中还可以添加数十种不同类型的网络层(可以查阅 Keras 官方文档了解各类示例)。其中一部分层和全连接层类似,用于构建神经元之间的连接;另一部分则可完成数据预处理或各类变换操作。
本节课我们将学习两种特殊网络层。这类层本身不包含神经元,但能为模型增添实用功能,从多方面优化模型表现,也是当下主流网络架构中的常用组件。
2.5.1 丢弃层
第一种就是丢弃层,主要用于缓解过拟合问题。
上一节课我们讲到,过拟合的成因是网络学习到了训练数据中无意义的虚假特征。为了捕捉这类特征,网络往往会依赖特定的权重组合,相当于形成了一种 “权重联动”。这种组合局限性很强、稳定性差:只要其中一个权重发生变化,整套组合就会失效。
这正是丢弃层的设计思路。在每一轮训练中,它会随机让当前层的一部分输入单元暂时失效,以此打破上述的权重联动,大幅降低网络学习到虚假特征的概率。迫使模型去挖掘普适性更强的通用特征,对应的权重组合也会更加稳定可靠。
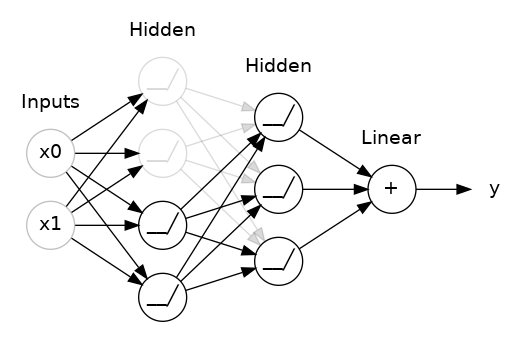
也可以将丢弃层理解为构建网络集成模型。最终预测结果不再由单一大型网络输出,而是由多个小型网络组成的 “组合模型” 共同决策。
这些子网络各自会出现不同的误差,但也能在多数场景下做出正确判断,因此整体组合的效果会优于任意单个网络。
2.5.2 添加丢弃层
在 Keras 中,参数rate用于设定输入单元的失效比例。只需将丢弃层放置在目标层的前一层,即可对其启用丢弃机制。
keras.Sequential([
# ...
layers.Dropout(rate=0.3), # apply 30% dropout to the next layer
layers.Dense(16),
# ...
])
2.5.3 批量归一化
接下来要介绍的特殊层是批量归一化(Batch Normalization,简称 BatchNorm),它能够改善训练速度慢、训练不稳定的问题。
对于神经网络而言,将所有数据统一到相同数值范围是通用的优化做法,比如使用 Scikit-learn 中的标准化器或归一化器。原因在于,随机梯度下降算法会根据数据产生的激活值大小来更新网络权重。如果不同特征生成的激活值量级差异过大,就会导致训练过程不稳定。
既然输入网络前对数据做归一化效果显著,那么在网络内部进行归一化想必也能进一步优化。批量归一化层就实现了这一功能:它会对每一批次的输入数据,先基于该批次自身的均值和标准差完成归一化,再通过两个可训练的缩放参数重新调整数据尺度。简单来说,批量归一化会对输入数据进行整体的尺度变换。
批量归一化主要用于辅助模型优化(有时也能提升预测效果)。添加该层后,模型通常能减少训练轮数,还可以解决训练陷入停滞等各类问题。如果训练过程遇到阻碍,不妨在模型中加入批量归一化层。
2.5.4 添加批量归一化层
批量归一化层几乎可以布置在网络的任意位置,一般将其放置在普通网络层之后即可。
layers.Dense(16, activation='relu'), layers.BatchNormalization(),
也可以置于网络层与其激活函数之间。
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),
如果将它作为网络的第一层,它还能充当自适应预处理模块,作用类似 Scikit-learn 中的标准化器(StandardScaler)。
2.6 二分类
此前我们学习了如何用神经网络解决回归问题,现在我们将把神经网络应用于另一类常见的机器学习任务:分类。此前学到的大部分知识依然适用,主要区别在于损失函数的选择,以及网络最终层的输出形式。
2.6.1 二分类
二分类是机器学习中十分常见的任务,即将样本划分至两个类别中的其一。比如预测客户是否会下单、判断信用卡交易是否存在欺诈行为、分析深空信号是否能证明新行星的存在,或是根据医学检测结果判断是否患病,这些都属于二分类问题。
原始数据中的类别往往以文本形式呈现,例如 “是 / 否”“狗 / 猫”。在训练前,我们需要为类别分配数值标签:一类标记为 0,另一类标记为 1。转为数值标签后,数据才能被神经网络读取使用。
2.6.2 准确率与交叉熵
准确率是评估分类模型效果的常用指标之一,指预测正确的样本数占总样本数的比例,计算公式为:准确率 = 正确预测数 ÷ 总预测数。模型预测完全准确时,准确率为 1.0。在各类别样本数量大致均衡的情况下,使用准确率作为评估指标是合理的选择。
但准确率(以及多数分类指标)无法用作损失函数。随机梯度下降(SGD)要求损失函数具备平滑变化的特性,而准确率基于计数比例计算,数值会出现跳变。因此我们需要选用替代方案作为损失函数,这就是交叉熵。
回顾一下:损失函数决定了网络的训练目标。回归任务的目标是缩小预测值与真实值之间的误差,我们通常选用平均绝对误差(MAE)来衡量该误差。
而分类任务需要衡量概率之间的差距,交叉熵恰好可以实现这一点。它可用来衡量两个概率分布之间的差异。
2.6.3 利用 Sigmoid 函数生成概率
交叉熵与准确率函数的输入都必须是概率值,也就是取值在 0 到 1 之间的数值。全连接层输出的是实数,想要将其转换为概率,就需要搭配一种新的激活函数 ——Sigmoid 激活函数。
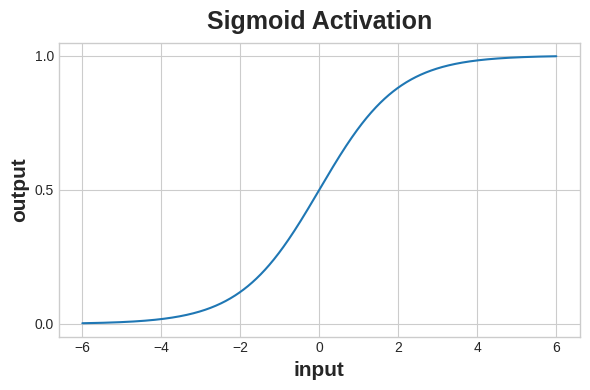
想要得到最终的分类结果,我们需要设定一个概率阈值。该阈值通常设为 0.5:数值小于 0.5,判定为标签 0 对应的类别;大于或等于 0.5,则判定为标签 1 对应的类别。Keras 在计算准确率时,默认就采用 0.5 作为阈值。
2.6.4 示例:二分类
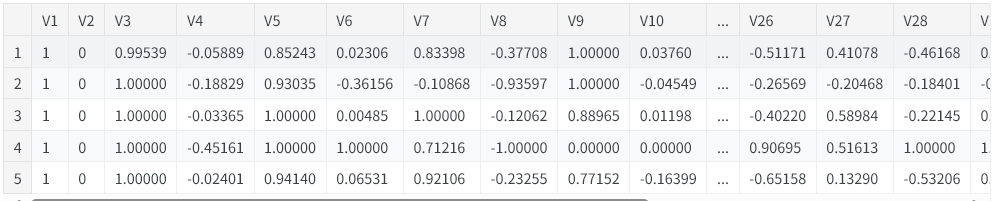
电离层数据集包含由探测地球大气电离层的雷达信号提取出的特征。该任务用于判断雷达信号是检测到了目标物体,还是仅对应空旷空域。
import pandas as pd
from IPython.display import display
ion = pd.read_csv('../input/dl-course-data/ion.csv', index_col=0)
display(ion.head())
df = ion.copy()
df['Class'] = df['Class'].map({'good': 0, 'bad': 1})
df_train = df.sample(frac=0.7, random_state=0)
df_valid = df.drop(df_train.index)
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)
df_train.dropna(axis=1, inplace=True) # drop the empty feature in column 2
df_valid.dropna(axis=1, inplace=True)
X_train = df_train.drop('Class', axis=1)
X_valid = df_valid.drop('Class', axis=1)
y_train = df_train['Class']
y_valid = df_valid['Class']
我们沿用回归任务的方式搭建模型,仅有一处区别:在输出层使用 sigmoid 激活函数,让模型输出类别概率。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(4, activation='relu', input_shape=[33]),
layers.Dense(4, activation='relu'),
layers.Dense(1, activation='sigmoid'),
])
调用模型的compile方法,设置交叉熵损失函数与准确率评估指标。二分类任务务必选用二元交叉熵(多分类任务的设置会略有不同)。Adam 优化器同样适用于分类任务,因此这里继续使用它。
model.compile(
optimizer='adam',
loss='binary_crossentropy', # 损失函数:二元交叉熵
metrics=['binary_accuracy'], # 评估指标:二分类准确率
)
该模型完成训练需要较多轮次,因此我们引入早停回调函数来简化训练过程。
early_stopping = keras.callbacks.EarlyStopping(
patience=10,
min_delta=0.001,
restore_best_weights=True,
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=1000,
callbacks=[early_stopping],
verbose=0, # hide the output because we have so many epochs
)
查看学习曲线,并查看验证集上损失值与准确率的最优结果。
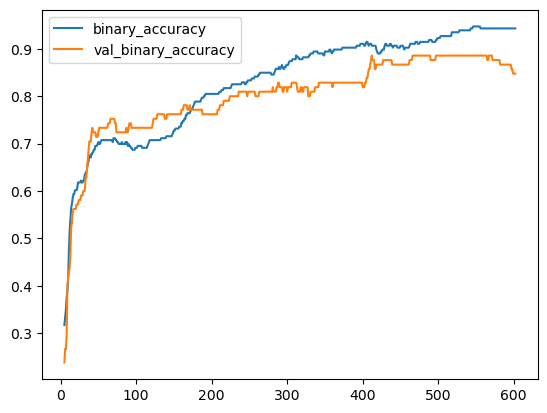
history_df = pd.DataFrame(history.history) # Start the plot at epoch 5 history_df.loc[5:, ['loss', 'val_loss']].plot() history_df.loc[5:, ['binary_accuracy', 'val_binary_accuracy']].plot()
3. 特征工程
3.1 什么是特征工程
3.1.1 特征工程的目标
特征工程的核心目的,就是让数据更适配当前所要解决的问题。
以体感温度相关指标(如酷热指数、风寒指数)为例。这类指标结合气温、湿度、风速等可直接采集的数据,计算出人体实际感受到的温度。体感温度本身就可以视作一种特征工程,它让原始观测数据和我们真正关注的目标 —— 人体对外界环境的实际体感,结合得更为紧密。
开展特征工程一般有以下目的:
- 提升模型的预测能力
- 减少计算资源与数据用量
- 增强结果的可解释性
3.1.2 特征工程的指导原则
一个特征想要发挥作用,它与目标变量之间必须存在模型能够学习到的关联。举例来说,线性模型仅能捕捉线性关系。因此在使用线性模型时,我们需要对特征做变换,让特征和目标变量呈现出线性关联。
这里的核心思路是:对特征做的变换,本质上也成为了模型的一部分。举个例子:假设你要根据正方形地块的边长来预测其价格。如果直接用边长训练线性模型,效果会很差,因为二者并非线性关系。
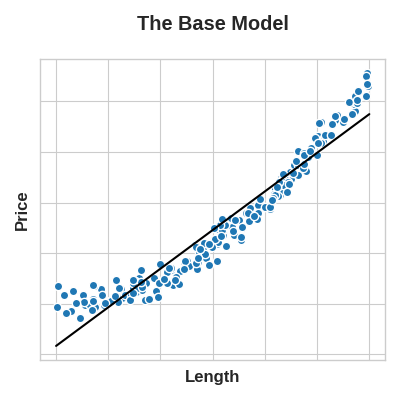
但如果我们对边长特征做平方运算得到面积,二者就形成了线性关系。将面积纳入特征集后,该线性模型便能拟合抛物线。换句话说,对特征做平方变换,相当于让线性模型具备了拟合二次特征的能力。
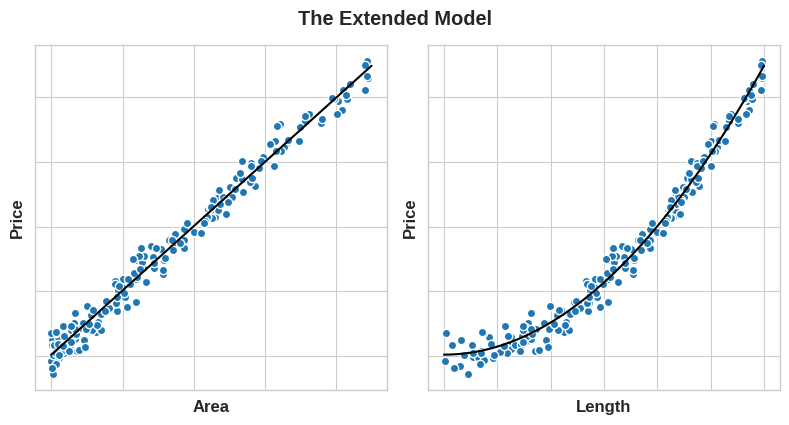
这也能看出,投入时间做特征工程往往能获得极高的回报。凡是模型无法自行挖掘的关联规律,你都可以通过特征变换来人为构建。在构建特征集时,要思考哪些信息能帮助模型达到最优效果。
3.1.3 示例:混凝土配方
下面通过案例说明上述思路:我们将为数据集构造若干衍生特征,以此提升随机森林模型的预测效果。
这份混凝土数据集收录了多种混凝土配方,以及对应成品的抗压强度(用于衡量混凝土的承重能力)。该任务的目标是根据配方预测混凝土的抗压强度。
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
df = pd.read_csv("../input/fe-course-data/concrete.csv")
df.head()
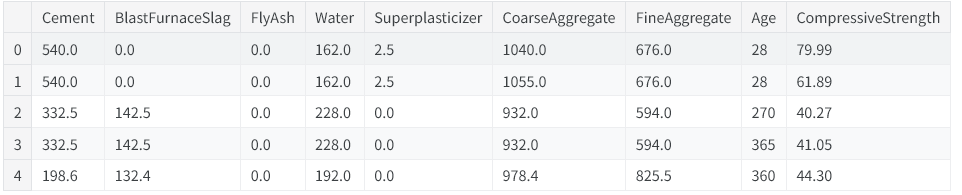
从这里可以看到各类混凝土所使用的不同原料。接下来我们会演示,基于这些原料数据构造新的衍生特征,能帮助模型挖掘出特征间的重要关联。
首先,我们使用原始数据集训练模型,得出基准结果,以此判断新构造的特征是否真正有效。
在开展特征工程前先建立基准,是十分规范的做法。基准分数可以帮你判断新特征是否有保留价值,或是应当舍弃并尝试其他方案。
X = df.copy()
y = X.pop("CompressiveStrength")
# Train and score baseline model
baseline = RandomForestRegressor(criterion="absolute_error", random_state=0)
baseline_score = cross_val_score(
baseline, X, y, cv=5, scoring="neg_mean_absolute_error"
) # 交叉验证
baseline_score = -1 * baseline_score.mean()
print(f"MAE Baseline Score: {baseline_score:.4}")
![]()
如果你平时在家做饭就会发现,食谱里食材的配比,往往比食材的绝对用量更能决定最终成品的效果。由此可以推断,上文中各类特征的比值,也能很好地预测混凝土的抗压强度。
下方代码会为数据集新增三个比值特征。
X = df.copy()
y = X.pop("CompressiveStrength")
# Create synthetic features
X["FCRatio"] = X["FineAggregate"] / X["CoarseAggregate"]
X["AggCmtRatio"] = (X["CoarseAggregate"] + X["FineAggregate"]) / X["Cement"]
X["WtrCmtRatio"] = X["Water"] / X["Cement"]
# Train and score model on dataset with additional ratio features
model = RandomForestRegressor(criterion="absolute_error", random_state=0)
score = cross_val_score(
model, X, y, cv=5, scoring="neg_mean_absolute_error"
)
score = -1 * score.mean()
print(f"MAE Score with Ratio Features: {score:.4}")

模型效果得到了提升,这说明新增的比值特征,为模型挖掘出了此前未能捕捉到的关键信息。
3.2 互信息
初次接触新数据集时,人们有时会感到无从下手。面对成百上千个毫无说明的特征,你甚至不知道该从哪里开始。
一个绝佳的起步方法是:借助特征效用指标对特征进行排序。该指标可衡量单个特征与目标变量之间的关联程度。之后你便可优先挑选一批价值最高的特征开展工作,也能确保时间投入更有意义。
我们将要使用的指标是互信息。它和相关系数类似,都用于衡量两个变量之间的关联。二者的区别在于:相关系数仅能识别线性关系,而互信息可以捕捉任意类型的关联。
互信息是通用性极强的指标,尤其适合在特征工程初期使用 —— 此时你往往还未确定最终要采用的模型。它具备以下优点:
- 用法简单、易于解读
- 计算效率高
- 理论基础扎实
- 不易产生过拟合
- 可识别各类变量关系
3.2.1 互信息及其衡量原理
互信息从不确定性的角度描述变量间的关联。两个变量的互信息,量化了已知其中一个变量的数值后,另一个变量的不确定性能够减少多少。简单来说:如果掌握了某个特征的值,我们对目标变量的预测把握能提升多少?
以埃姆斯房价数据集为例:下图展示了房屋外立面品质与成交价格之间的关系,图中每个点代表一套房屋。
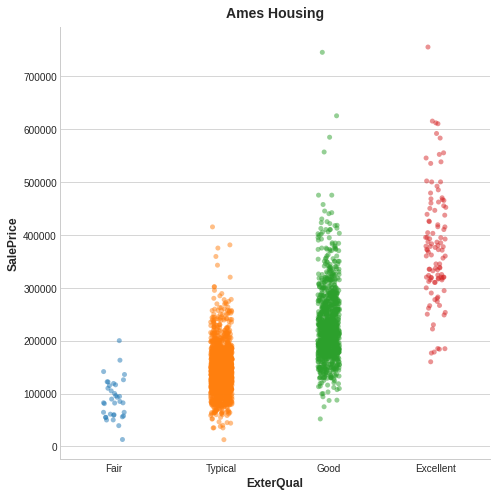
从图中可以看出,知晓外立面品质(ExterQual)的等级,就能让我们对对应的房屋售价(SalePrice)做出更准确的判断:外立面品质的每个等级,对应的房价基本都集中在固定区间内。外立面品质与房价之间的互信息,是综合该特征四个不同取值后,房价整体不确定性的平均下降幅度。举例来说,“一般(Fair)” 等级的样本数量少于 “普通(Typical)” 等级,因此它在互信息得分中所占权重也更低。
3.2.2 互信息得分解读
变量间互信息的最小值为 0.0。当互信息等于 0 时,说明两个变量相互独立,彼此无法提供任何有效信息。理论上,互信息没有上限,但实际应用中,数值超过 2.0 的情况十分少见(互信息属于对数度量,增长速度非常缓慢)。
下图可以帮你理解:不同大小的互信息,分别对应特征与目标变量之间关联的类型和强弱程度。
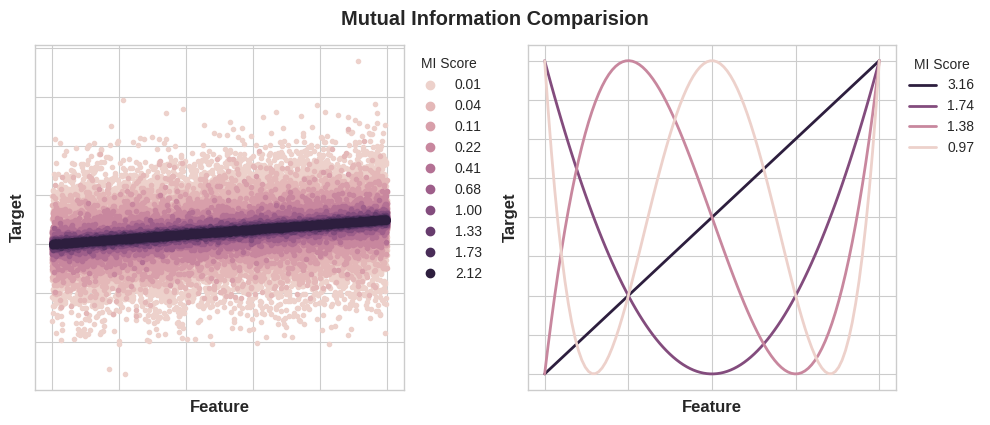
使用互信息时需注意以下几点:
-
互信息可用于评估单个特征对目标变量的预测潜力。
-
有些特征单独作用时价值有限,但与其他特征组合后能提供大量有效信息。互信息无法检测特征间的交互关系,它属于单变量评价指标。
-
特征的实际价值取决于所搭配的模型。只有当特征与目标变量的关联规律能够被模型学习时,该特征才真正有用。即便特征的互信息得分很高,模型也未必能利用其中的信息,这时往往需要先对特征做变换,凸显二者的内在关联。
3.2.3 示例:1985 年汽车数据集
该汽车数据集包含 193 款 1985 年车型。任务是根据品牌、车身类型、马力等 23 项车辆特征,预测汽车价格(目标变量)。本案例将利用互信息对特征进行排序,并结合数据可视化分析结果。
scikit-learn 中的互信息算法对离散特征和连续特征的处理方式不同,因此你需要明确区分二者。
经验判断规则:数据类型为浮点型(float)的特征均属于连续特征。对于类别型特征(数据类型为 object 或 category),经过标签编码后可当作离散特征处理。(标签编码相关内容可回顾我们的分类变量课程。)
X = df.copy()
y = X.pop("price")
# 类别型特征离散化处理---标签编码
for colname in X.select_dtypes("object"):
X[colname], _ = X[colname].factorize()
# 标记离散型特征
discrete_features = X.dtypes == int
Scikit-learn 的特征选择模块提供了两种互信息指标:mutual_info_regression 用于连续型目标变量,mutual_info_classif 用于分类型目标变量。本次任务的目标变量价格属于连续值。下方代码会计算各特征的互信息得分,并将结果整理成直观的数据表。
from sklearn.feature_selection import mutual_info_regression
def make_mi_scores(X, y, discrete_features):
mi_scores = mutual_info_regression(X, y, discrete_features=discrete_features)
mi_scores = pd.Series(mi_scores, name="MI Scores", index=X.columns)
mi_scores = mi_scores.sort_values(ascending=False)
return mi_scores
mi_scores = make_mi_scores(X, y, discrete_features)
mi_scores[::3] # show a few features with their MI scores
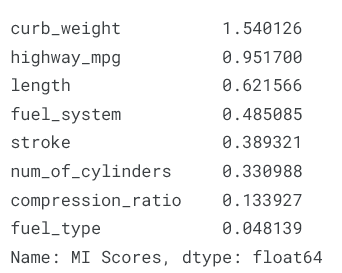
接下来绘制柱状图,方便进行对比。
def plot_mi_scores(scores):
scores = scores.sort_values(ascending=True)
width = np.arange(len(scores))
ticks = list(scores.index)
plt.barh(width, scores)
plt.yticks(width, ticks)
plt.title("Mutual Information Scores")
plt.figure(dpi=100, figsize=(8, 5))
plot_mi_scores(mi_scores)
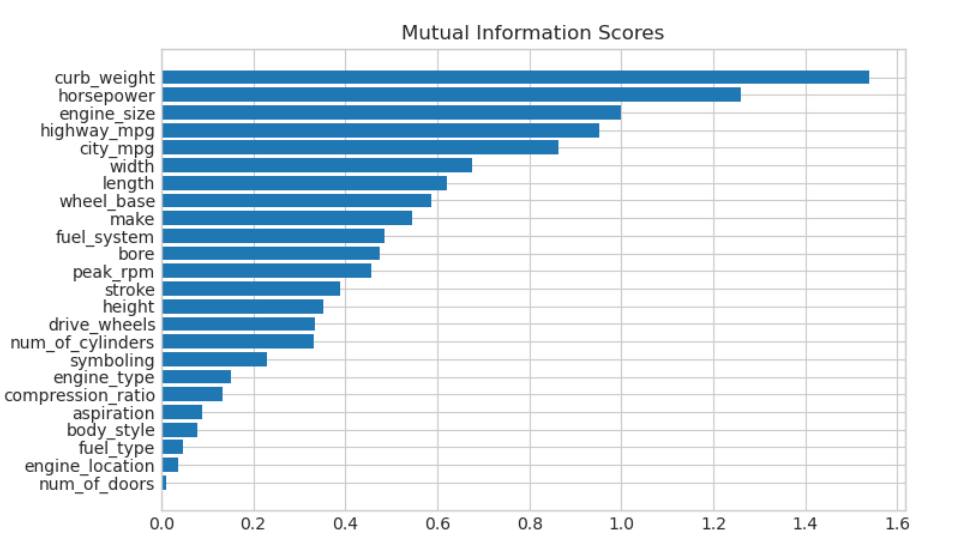
在完成特征效用排序后,数据可视化是很有效的后续分析手段。我们来仔细看看其中几项特征。
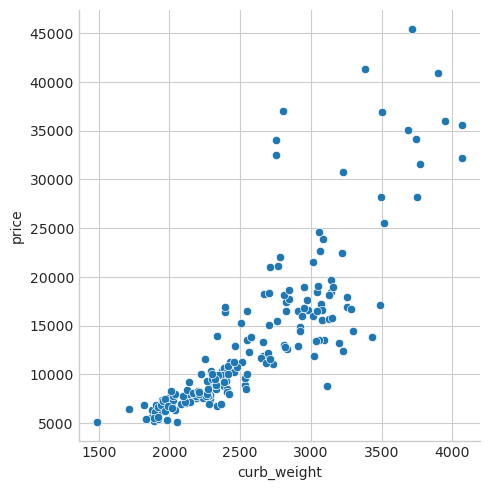
不出所料,得分较高的整备重量特征,与目标变量价格之间存在显著关联。
下面呈现price和curb_weight的图像:
sns.relplot(x="curb_weight", y="price", data=df);
sns.lmplot(x="horsepower", y="price", hue="fuel_type", data=df);
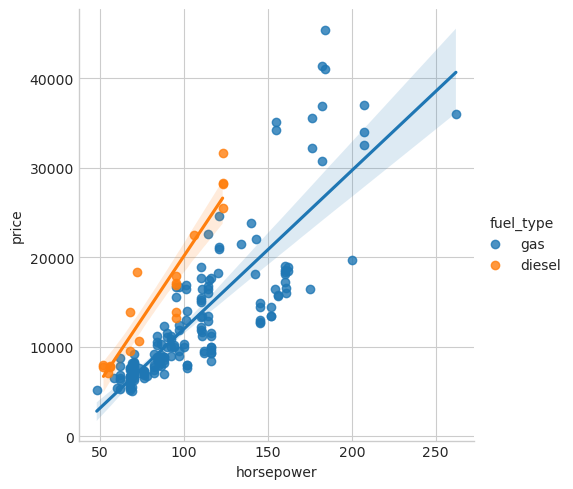
燃油类型这一特征的互信息得分偏低,但从图中可以明显看出,它在马力特征维度上将数据划分成了两组价格走势截然不同的群体。这说明燃油类型存在特征交互效应,实际上并非无关紧要。因此,切勿仅凭互信息得分就判定某个特征无用,还需要排查潜在的交互关系,而领域知识在这一过程中能起到很大的指导作用。
3.3 创建新特征
筛选出一批具备挖掘潜力的特征后,就可以着手对其进行优化改造了。本节课将介绍几种完全借助 Pandas就能实现的常用特征变换方法。如果你的 Pandas 基础有所生疏,可以先学习我们配套的 Pandas 专项课程。
本节会用到四份包含各类特征类型的数据集:美国交通事故数据集、1985 年汽车数据集、混凝土配方数据集以及客户生命周期价值数据集。
3.3.1 挖掘新特征的技巧
-
理解现有特征:若有相关文档,务必查阅数据集说明。
-
深耕业务领域:积累行业知识。例如预测房价,就可以先了解房地产相关内容。维基百科可作为入门参考,专业书籍与期刊文献往往能提供更优质的信息。
-
参考过往案例:往届 Kaggle 竞赛的解题报告是绝佳学习资料。
-
善用数据可视化:可视化能够发现特征分布异常,或是可被简化的复杂关联。开展特征工程的过程中,一定要坚持做数据可视化分析。
3.3.2 数学变换
数值型特征之间的关联往往可以通过数学公式来体现,这也是你在开展领域调研时经常会遇到的内容。在 Pandas 中,你可以像对待普通数值一样,对数据列执行各类算术运算。
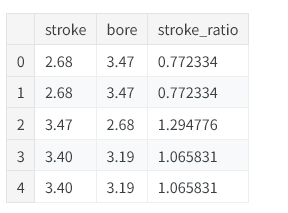
汽车数据集中包含诸多描述发动机的特征。结合行业知识,我们可以通过各类公式构造出有价值的新特征。举例来说,行程比能够衡量发动机在能效与性能之间的表现:
autos["stroke_ratio"] = autos.stroke / autos.bore autos[["stroke", "bore", "stroke_ratio"]].head()
特征组合的运算越复杂,模型就越难学习其中规律。以发动机排量(衡量动力大小的指标)计算公式为例:

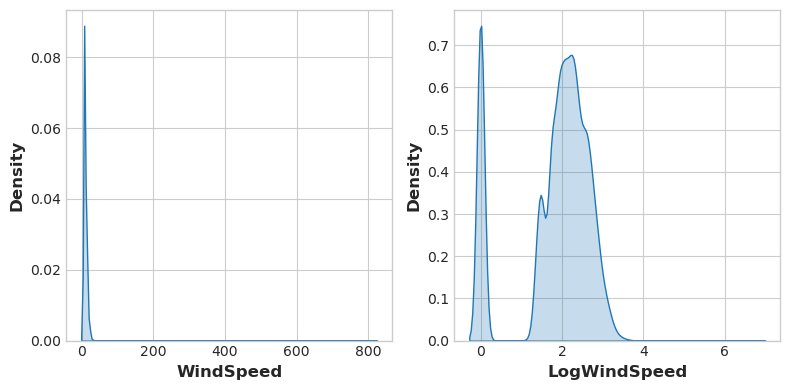
数据可视化能够为特征变换提供思路,常见做法是通过幂运算或对数运算调整特征分布形态。例如,美国交通事故数据里的风速特征分布存在严重偏态,此时使用对数变换就能有效将其转化为近似正态分布。
# If the feature has 0.0 values, use np.log1p (log(1+x)) instead of np.log accidents["LogWindSpeed"] = accidents.WindSpeed.apply(np.log1p) # Plot a comparison fig, axs = plt.subplots(1, 2, figsize=(8, 4)) sns.kdeplot(accidents.WindSpeed, shade=True, ax=axs[0]) sns.kdeplot(accidents.LogWindSpeed, shade=True, ax=axs[1]);
3.3.3 计数特征
用于描述事物有无的特征通常会成组出现,比如一组疾病风险因子。我们可以通过统计计数的方式对这类特征进行聚合处理。
这类特征一般为二值型(1 代表存在,0 代表不存在)或布尔型(真 / 假)。在 Python 中,布尔值可以像整数一样直接求和。
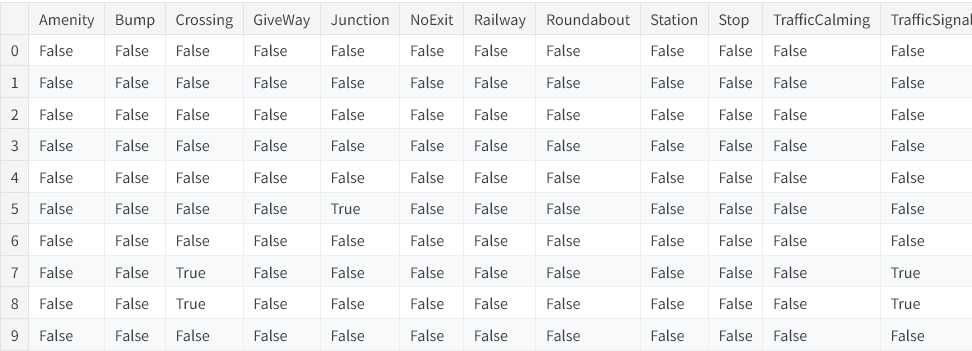
交通事故数据集中有多个特征,用于标记事故现场附近是否存在各类道路设施。我们可以借助求和方法,统计出周边道路设施的总数量。
roadway_features = ["Amenity", "Bump", "Crossing", "GiveWay",
"Junction", "NoExit", "Railway", "Roundabout", "Station", "Stop",
"TrafficCalming", "TrafficSignal"]
accidents["RoadwayFeatures"] = accidents[roadway_features].sum(axis=1)
accidents[roadway_features + ["RoadwayFeatures"]].head(10)
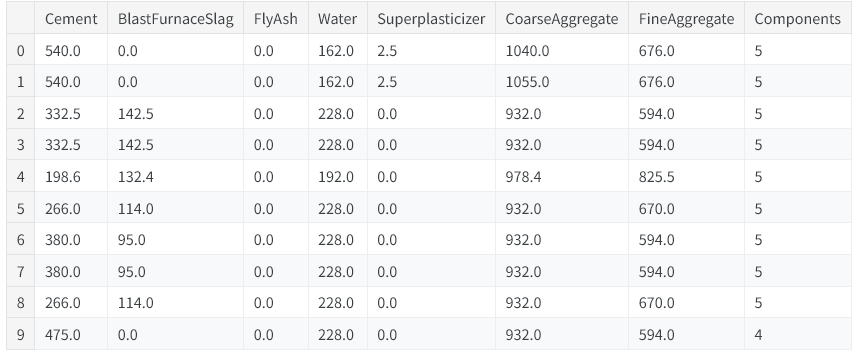
也可以借助数据框自带方法生成布尔值。混凝土数据集记录了各类配方的原料用量,不少配方会缺少一种或多种原料(对应原料数值为 0)。下面利用数据框内置的gt(大于)方法,统计每份配方中实际包含的原料种类数量。
components = [ "Cement", "BlastFurnaceSlag", "FlyAsh", "Water",
"Superplasticizer", "CoarseAggregate", "FineAggregate"]
concrete["Components"] = concrete[components].gt(0).sum(axis=1)
concrete[components + ["Components"]].head(10)
3.3.4 特征组合与特征拆分
特征组合指将多个原有特征整合生成新特征;特征拆分则是把单一复合特征拆解为多个独立新特征,二者都是特征工程的常用手段。
很多时候我们会遇到复杂字符串,将其拆分为简单片段往往能发挥更大作用。常见例子如下:
- 编号:
123-45-6789 - 电话号码:
(999) 555-0123 - 街道地址:
8241 Kaggle Ln., Goose City, NV - 网址:
http://www.kaggle.com - 产品编码:
0 36000 29145 2 - 日期时间:
Mon Sep 30 07:06:05 2013
这类特征通常具备特定结构,可以加以利用。例如美国电话号码中的区号(即(999)部分),能够反映通话归属地。结合业务调研分析,往往能挖掘出有效信息。
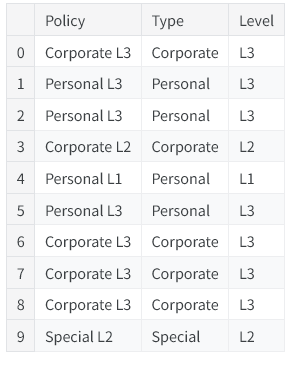
借助字符串访问器str,可以直接对数据列使用split等字符串方法。客户生命周期价值数据集记录了某保险公司的客户相关信息,我们可以从保单特征中,拆分出保单类型与保障等级。
# 创建两个新特征:Type(保单类型)和 Level(保障等级)
customer[["Type", "Level"]] = (
customer["Policy"] # 从原始 Policy 特征出发
.str # 启用 Pandas 字符串处理工具
.split(" ", expand=True) # 按空格拆分,自动扩展成多列
)
# 查看前10行,对比原始特征和拆分后的新特征
customer[["Policy", "Type", "Level"]].head(10)
如果判断多个简单特征组合后存在交互作用,也可以将它们合并为一个复合特征。
autos["make_and_style"] = autos["make"] + "_" + autos["body_style"] autos[["make", "body_style", "make_and_style"]].head()

3.3.5 分组变换
最后来讲分组变换,它会按照指定类别对多行数据进行聚合计算。借助分组变换,你可以生成这类特征:“个人所在州的平均收入”、“各题材电影在工作日上映的占比” 等。如果发现不同类别间存在交互关系,针对该类别做分组变换会是很有价值的分析方向。
分组变换通过聚合函数整合两类特征:一类是用于划分分组的分类特征,另一类是需要进行聚合运算的数值特征。以 “各州平均收入” 为例,选择所在州作为分组依据、均值作为聚合函数、收入作为被聚合特征。在 Pandas 中,可通过 groupby 和 transform 方法实现该计算。
均值函数是数据框的内置方法,因此我们可以将其以字符串形式传入 transform 方法。其他常用方法还有最大值、最小值、中位数、方差、标准差以及计数。下面演示如何统计数据集中各个州的出现频次:
customer["StateFreq"] = (
customer.groupby("State")
["State"]
.transform("count")
/ customer.State.count()
)
customer[["State", "StateFreq"]].head(10)
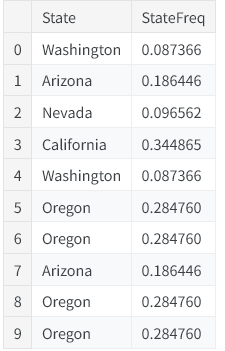
你可以借助这类变换,为分类特征生成频次编码。
如果数据集划分了训练集和验证集,为保证两者相互独立,建议仅使用训练集来构造分组特征,再将该特征关联到验证集上。具体做法是:先对训练集执行drop_duplicates去重得到唯一数据,再通过验证集的merge方法完成数据合并。
# Create splits
df_train = customer.sample(frac=0.5)
df_valid = customer.drop(df_train.index)
# Create the average claim amount by coverage type, on the training set
df_train["AverageClaim"] = df_train.groupby("Coverage")["ClaimAmount"].transform("mean")
# Merge the values into the validation set
df_valid = df_valid.merge(
df_train[["Coverage", "AverageClaim"]].drop_duplicates(),
on="Coverage",
how="left",
)
df_valid[["Coverage", "AverageClaim"]].head(10)
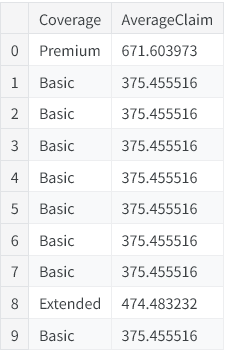
这是工业界标准做法:只用训练集做分组统计,再映射到验证集,避免数据泄露、保证数据集独立性。
特征构建建议:
构建特征时,需要结合模型自身的优缺点来设计,以下是相关参考原则:
-
线性模型擅长学习求和、求差这类简单关系,但无法捕捉更复杂的规律。
-
大多数模型难以自主学习比值关系,手动构造比值类特征,往往能轻松提升模型效果。
-
线性模型与神经网络在特征经过归一化后,表现通常更佳。其中神经网络尤其要求特征数值尽量接近 0。树模型(如随机森林、XGBoost)虽也可能从归一化中获益,但效果通常并不明显。
-
树模型几乎可以拟合各类特征组合,但如果某类特征组合对结果影响极大,尤其是在数据量不足的情况下,手动构建该组合特征仍能进一步优化模型。
-
计数值类特征对树模型帮助显著,因为这类模型本身不具备同时对大量特征做信息聚合的能力。
3.3.6 训练集与测试集的同步、映射处理
(1)需要映射测试集的情况
当你的特征依赖训练集的统计信息(均值、分组、最值、编码),不能直接对验证集用同样代码, 必须用训练集的规则去映射验证集。
(2)需要同步处理测试集的情况
只要你的特征变换不依赖数据本身的统计值,就必须完全一样的处理。比如:数学变换、字符串拆分 / 组合、固定规则的计数、时间 / 日期提取。
3.4 k-均值的聚类
前面内容大多描述特征与目标向量的关联性分析。
本节与下一节将介绍无监督学习算法。这类算法不需要目标变量,核心作用是挖掘数据内在特性,并以特定方式呈现特征的结构。在面向预测任务的特征工程中,无监督算法可以理解为一种特征挖掘手段。
聚类,简单来说,就是根据数据样本之间的相似度,将其划分成不同组别。正所谓 “物以类聚”,聚类算法正是遵循这一原理。
将聚类应用于特征工程时,我们可以划分出代表不同细分市场的客户群体,或是气候特征相近的地理区域。把聚类标签作为新特征加入模型,能够帮助机器学习模型梳理复杂的空间关联与邻近关系。
3.4.1 聚类标签作为特征
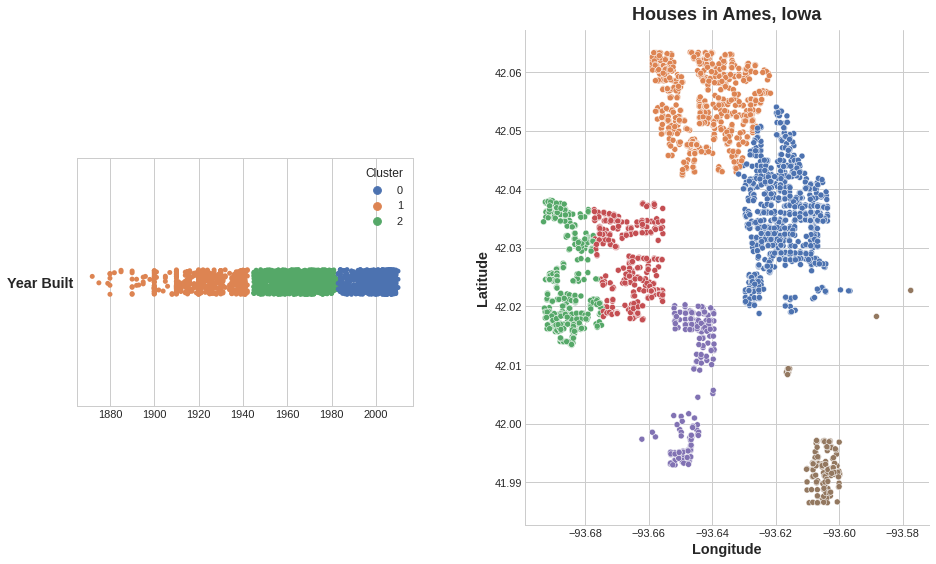
将聚类应用于单个连续数值特征时,效果等同于传统的分箱或离散化变换。作用于多个特征时,则相当于多维分箱(也常被称作矢量量化)。
如图,左侧:对单个特征进行聚类;右侧:基于两个特征进行聚类。
将聚类标签作为新列添加到数据框后,效果大致如下:
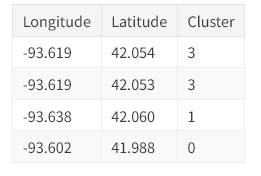
需要注意,聚类标签属于分类特征。常规聚类算法会将其转换为标签编码(也就是一系列整数);根据所用模型的不同,采用独热编码或许会更加合适。
添加聚类标签的核心思路,是把特征间复杂的关联关系拆分为多个简单模块。如此一来,模型只需逐个学习这些简单模块,而非一次性拟合整体的复杂规律,这是一种分而治之的策略。
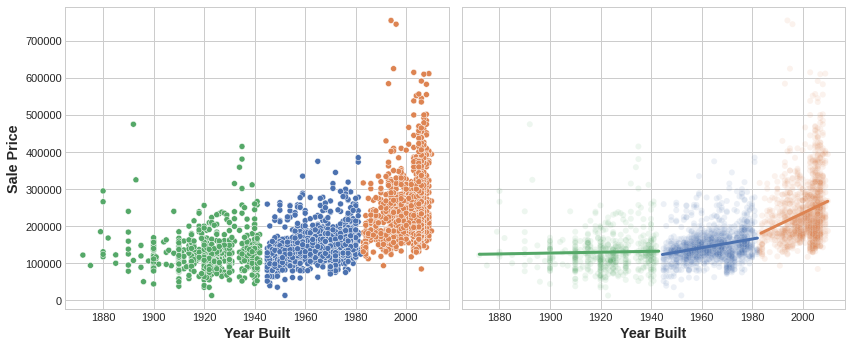
该图展示了聚类如何优化简单线性模型。房屋建成年份与售价之间存在曲线关系,这类复杂关系超出了线性模型的拟合能力,会导致欠拟合。而将数据按类别拆分后,各分组内的关系近似呈线性,模型便能轻松完成学习。
3.4.2 K均值聚类
聚类算法种类繁多,它们的主要区别在于相似度 / 邻近度的计算方式,以及适用的特征类型。本文选用的 K-Means(K 均值) 算法逻辑直观,在特征工程场景中也易于使用。当然,根据实际业务场景,也可以选择其他更合适的聚类算法。
K-Means 采用普通直线距离(即欧氏距离)衡量样本相似度。该算法会在特征空间中设置若干个中心点,也就是质心,以此划分聚类簇。数据集中的每个样本,都会被划分到距离自身最近的质心所属的簇中。算法名称里的 k 代表质心(即聚类簇)的数量,该数值需要由人为设定。
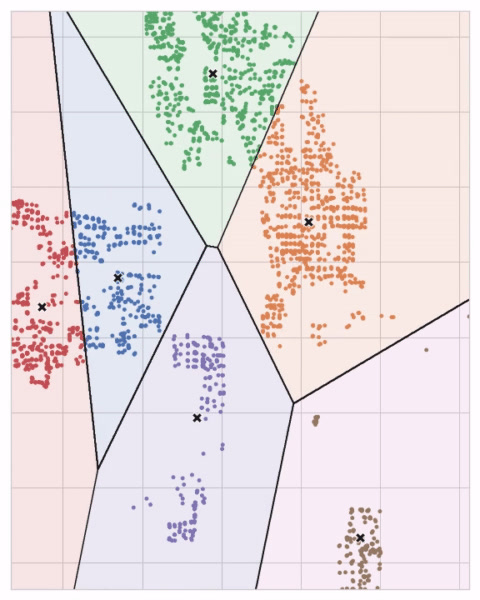
你可以把每个质心想象成向外辐射圆圈的中心点。当不同质心的辐射范围相交时,就会形成分界线,最终构成沃罗诺伊图。这张划分图决定了未来新数据会被归入哪一个聚类簇,本质上也是 K-Means 从训练数据中学到的核心规则。
上文艾姆斯数据集的聚类结果就来自 K-Means 算法,下图标注出了对应的沃罗诺伊分割区域与质心位置。
我们来回顾一下 K-Means 算法的聚类原理,以及它在特征工程中的实际意义。下面重点讲解 Scikit-learn 实现版本中的三个核心参数:n_clusters(质心数量)、max_iter(单轮次最大迭代次数) 和 n_init(重复轮数)。
该算法的流程分为简单的两大步骤。首先,算法会随机初始化指定数量(由 n_clusters 设定)的质心,之后不断循环执行以下两项操作:
-
将所有样本划分到距离最近的聚类质心所属簇中;
-
重新调整每个质心的位置,使质心到其簇内所有样本的总距离最小。
算法会持续迭代这两个步骤,直到质心位置不再变化,或是达到设定的最大迭代次数(max_iter)。
质心的初始随机位置,有时会导致最终聚类效果不佳。为此,算法会重复运行指定轮次(由 n_init 设定),最终返回样本与对应质心总距离最小的最优聚类结果。
如果聚类数量较多,可适当调大max_iter;若数据集结构复杂,则建议增加n_init的取值。日常使用中,通常只需自行设置n_clusters(即 k 值)。特征的最优聚类划分方式,取决于所用模型与预测目标,因此该参数需像其他超参数一样进行调优(例如采用交叉验证)。
3.4.3 示例:加州房价数据集
纬度和经度属于空间特征,非常适合使用 K-Means 聚类。本示例将结合这两项特征与收入中位数做聚类,以此划分加州不同区域的经济圈层。
加载并展示数据:
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.cluster import KMeans
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True)
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=14,
titlepad=10,
)
df = pd.read_csv("../input/fe-course-data/housing.csv")
X = df.loc[:, ["MedInc", "Latitude", "Longitude"]]
X.head()
由于 K 均值聚类对特征量纲十分敏感,若数据存在极值,建议先做缩放或归一化处理。本例中各特征的数值范围大致相近,因此无需额外处理。
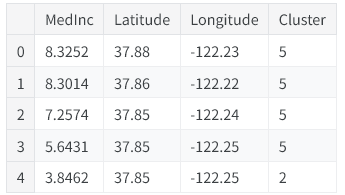
# 创建聚类特征
kmeans = KMeans(n_clusters=6) # 初始化K-Means模型,设定分成6个簇
X["Cluster"] = kmeans.fit_predict(X) # 训练模型并给每条数据分配聚类标签
X["Cluster"] = X["Cluster"].astype("category") # 把聚类标签转为分类类型(非常重要)
X.head() # 查看前5行数据
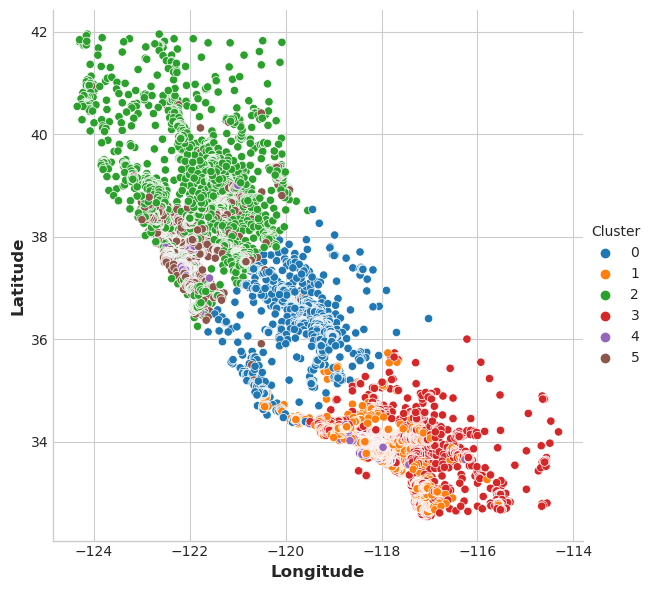
接下来我们通过几张图表看看聚类效果如何。首先是散点图,展示各类别的地理分布。可以看出,算法已将沿海高收入区域划分成了独立组别。
sns.relplot(
x="Longitude", y="Latitude", hue="Cluster", data=X, height=6,
);
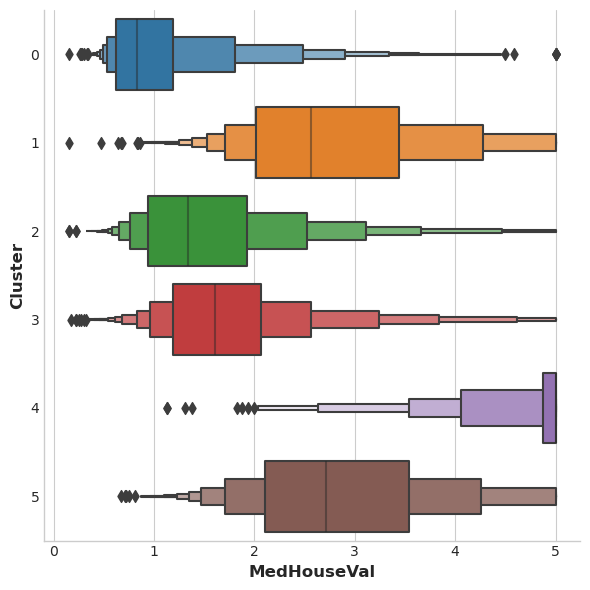
该数据集的目标变量为房屋价值中位数(MedHouseVal)。下方箱线图展示了每个聚类簇中目标值的分布情况。如果聚类结果具备参考价值,不同簇的房屋价值分布理应存在明显差异,而当前结果也确实印证了这一点。
X["MedHouseVal"] = df["MedHouseVal"] sns.catplot(x="MedHouseVal", y="Cluster", data=X, kind="boxen", height=6);
3.5 主成分分析
上一节我们学习了第一种基于模型的特征工程方法:聚类。本节课将介绍另一种方法:主成分分析(PCA)。聚类是依据样本间的相似度对数据集进行划分,而主成分分析可以理解为对数据中的变异信息进行拆分。它不仅有助于挖掘数据中潜藏的重要关联,还能构建出信息量更丰富的新特征。
3.5.1 主成分分析
鲍鱼数据集记录了数千只塔斯马尼亚鲍鱼的各项形体测量数据(鲍鱼是一种外形类似蛤蜊、牡蛎的海洋生物)。本节先选取两个特征展开讲解:外壳的高度与直径。
可以这样理解:数据中存在多条变异轴,用来描述鲍鱼个体之间的主要差异。从图像上看,这些轴是沿着数据固有分布方向延伸的垂线,原始数据有多少个特征,就对应多少条变异轴。
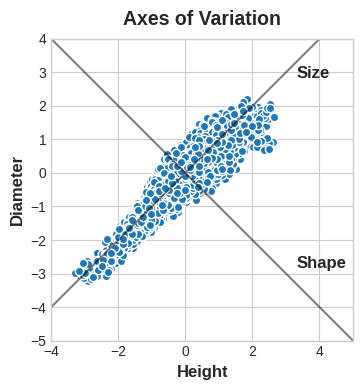
我们通常可以为这些变异轴赋予实际含义。较长的轴可称作尺寸主成分:左下方代表高度、直径均偏小的个体,右上方则对应高度、直径都偏大的个体。较短的轴可称作形态主成分:高度小、直径大对应偏扁平的外形,高度大、直径小则对应偏圆润的外形。
不难发现,我们不必再用原始的高度和直径来描述鲍鱼,改用尺寸和形态同样可行。这正是主成分分析(PCA)的核心思想:舍弃原有特征,转而用数据的变异轴来表征数据,这些变异轴就成为了全新特征。
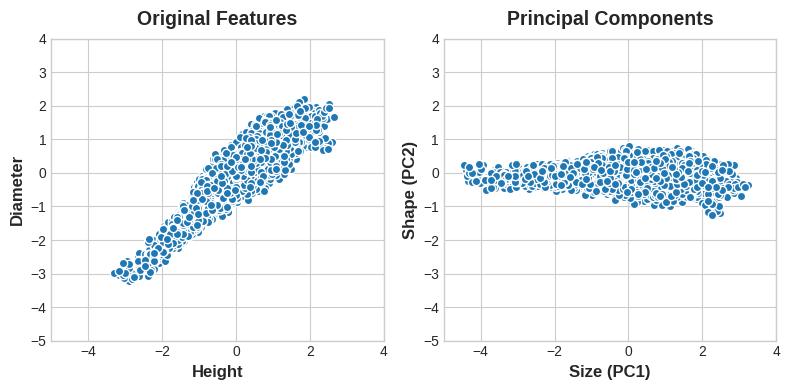
PCA 构建的新特征,本质上是原始特征的线性组合(加权求和)。

这些新特征被称为数据的主成分,而其中的权重则叫作载荷。主成分的数量与原始数据集的特征数量保持一致:倘若我们使用十个特征而非两个,最终就会得到十个主成分。
每个主成分的载荷可通过正负符号与数值大小,体现出该成分所表征的数据变异特征。
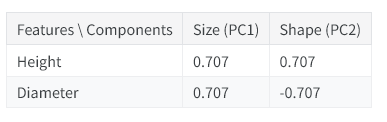
这份载荷表表明:在尺寸主成分中,高度与直径呈同向变化(符号一致);而在形态主成分中,二者呈反向变化(符号相反)。两个主成分里,各项载荷的数值大小均相等,说明两个原始特征的贡献度相同。
PCA 还能量化每个主成分所承载的数据变异量。从图中能直观看出,数据在尺寸维度上的变异程度远高于形态维度。PCA 会通过方差解释率,精准量化每个主成分对应的变异占比。
如图为两主成分的方差解释率和累积方差(将各主成分的方差解释率依次累加,得到的总和即为累积方差。它表示选取前若干个主成分后,能够保留的原始数据信息量比例)。
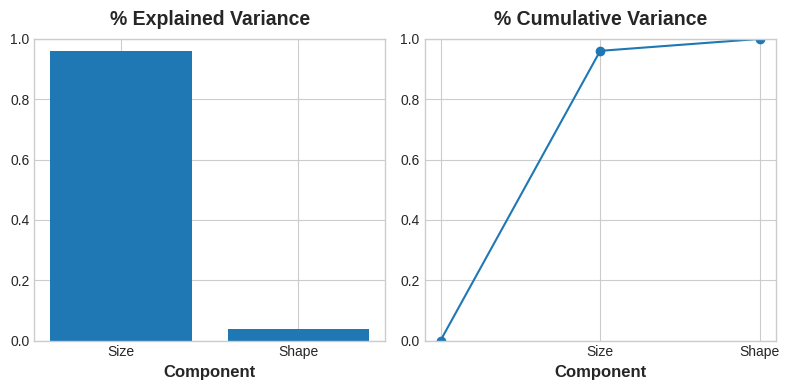
尺寸主成分捕捉了高度与直径之间的大部分变异。不过需要牢记的是,某个主成分的方差解释量,并不等同于它作为预测变量的优劣程度 —— 这完全取决于你要预测的目标是什么。
3.5.2 主成分分析在特征工程中的应用
在特征工程中,主成分分析(PCA)主要有两种使用方式。
第一种是将其作为数据分析工具。由于主成分能够反映数据的变异规律,你可以计算各主成分的互信息得分,判断哪类数据变化对预测目标最具参考价值。这能为特征构造提供思路:例如,若 “尺寸” 维度影响显著,可构造高度与直径的乘积特征;若 “形态” 维度更为关键,则可尝试构建高度与直径的比值特征。你也可以对得分较高的单个或多个主成分做聚类分析。
第二种方式是直接将主成分作为新特征使用。主成分能够直观呈现数据的变异结构,所含有效信息通常多于原始特征,常见应用场景如下:
-
降维:当特征存在严重冗余(即多重共线性)时,PCA 会将冗余信息归集到一个或多个方差近似为零的主成分中。这类成分几乎不包含有效信息,可直接剔除。
-
异常检测:原始特征中难以发现的异常波动,往往会体现在低方差主成分中。这类成分在异常值、离群点检测任务中价值很高。
-
降噪:一组传感器采集的数据通常会夹杂共性背景噪声。PCA 有时能将有效信号整合到少数特征中,同时分离出噪声,从而提升信噪比。
-
解相关:部分机器学习算法难以处理高度相关的特征。PCA 可将存在相关性的原始特征转换为互不相关的主成分,降低算法的运算难度。
总的来说,PCA 可以帮你直观掌握数据的相关结构,你也可以结合实际场景拓展更多用法。
3.5.3 PCA 使用最佳时机
应用 PCA 时需注意以下几点:
-
PCA 仅适用于数值型特征,比如连续型数值、计数数据。
-
PCA 对特征量纲十分敏感。除非有特殊合理的缘由,否则在执行 PCA 前,建议先对数据做标准化处理。
-
建议剔除或限制离群值,这类数据会对分析结果造成较大干扰。
3.5.4 示例 ——1985 年汽车数据集
本示例将再次使用汽车数据集并开展主成分分析(PCA),借助该分析工具挖掘新特征。下方代码单元用于加载数据,并定义方差绘图与互信息得分计算两个函数。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from IPython.display import display
from sklearn.feature_selection import mutual_info_regression
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True)
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=14,
titlepad=10,
)
def plot_variance(pca, width=8, dpi=100):
# Create figure
fig, axs = plt.subplots(1, 2)
n = pca.n_components_
grid = np.arange(1, n + 1)
# Explained variance
evr = pca.explained_variance_ratio_
axs[0].bar(grid, evr)
axs[0].set(
xlabel="Component", title="% Explained Variance", ylim=(0.0, 1.0)
)
# Cumulative Variance
cv = np.cumsum(evr)
axs[1].plot(np.r_[0, grid], np.r_[0, cv], "o-")
axs[1].set(
xlabel="Component", title="% Cumulative Variance", ylim=(0.0, 1.0)
)
# Set up figure
fig.set(figwidth=8, dpi=100)
return axs
def make_mi_scores(X, y, discrete_features):
mi_scores = mutual_info_regression(X, y, discrete_features=discrete_features)
mi_scores = pd.Series(mi_scores, name="MI Scores", index=X.columns)
mi_scores = mi_scores.sort_values(ascending=False)
return mi_scores
df = pd.read_csv("../input/fe-course-data/autos.csv")
我们选取了四项涵盖不同属性的特征,它们与目标变量价格的互信息得分均较高。由于这些特征的量纲并不统一,接下来我们会对数据进行标准化处理。
features = ["highway_mpg", "engine_size", "horsepower", "curb_weight"]
X = df.copy()
y = X.pop('price')
X = X.loc[:, features]
# Standardize
X_scaled = (X - X.mean(axis=0)) / X.std(axis=0)
现在我们可以使用 scikit-learn 的 PCA 模型进行拟合,并生成主成分。下方展示了转换后数据集的前几行内容。
from sklearn.decomposition import PCA
# 创建主成分
pca = PCA() # 初始化PCA模型,保留所有主成分(不主动降维)
X_pca = pca.fit_transform(X_scaled) # 拟合数据 + 生成主成分,一步完成
# 给主成分起名字:PC1, PC2, PC3, PC4...
component_names = [f"PC{i+1}" for i in range(X_pca.shape[1])]
# 把 numpy 数组转成 pandas 表格,方便查看
X_pca = pd.DataFrame(X_pca, columns=component_names)
# 展示前几行
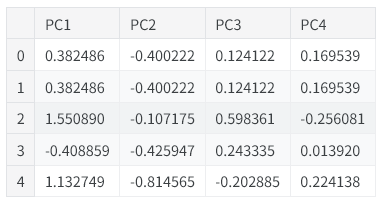
X_pca.head()
PCA 转换后得到的主成分特征矩阵,每一行代表一条样本,每一列代表一个主成分。
模型拟合完成后,PCA 实例的components_属性中存储了各主成分的载荷。
loadings = pd.DataFrame(
pca.components_.T, # 转置:(主成分数 × 原始特征数) → (原始特征数 × 主成分数)
columns=component_names, # 列:PC1、PC2、PC3、PC4...
index=X.columns # 行:原始特征名(如:重量、马力、排量…)
)
loadings
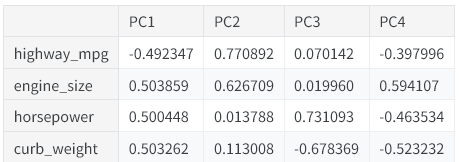
第一主成分(PC1)体现了一种对比:大尺寸、高动力但油耗高的车型,与更小、更经济且油耗表现好的车型之间的差异。
查看第一主成分(PC1)的方差解释率和累积方差。
plot_variance(pca);
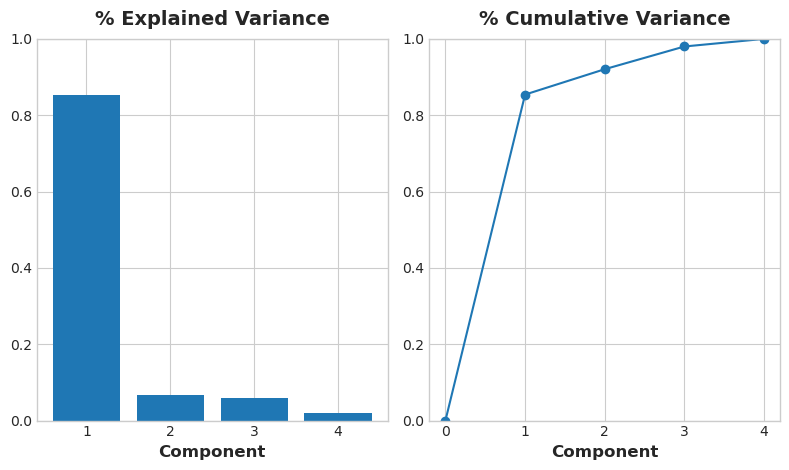
图表显示,我们选取的四个特征的变异主要分布在这条 “豪华 / 经济型” 轴上。
我们再来看看各主成分的互信息得分(MI scores)。
mi_scores = make_mi_scores(X_pca, y, discrete_features=False) mi_scores
不出所料,PC1 具有很高的信息量,尽管其余主成分的方差较小,但它们与价格仍存在显著关联。深入分析这些成分,或许能挖掘出 “豪华 / 经济型” 主轴线未能捕捉到的潜在关系。
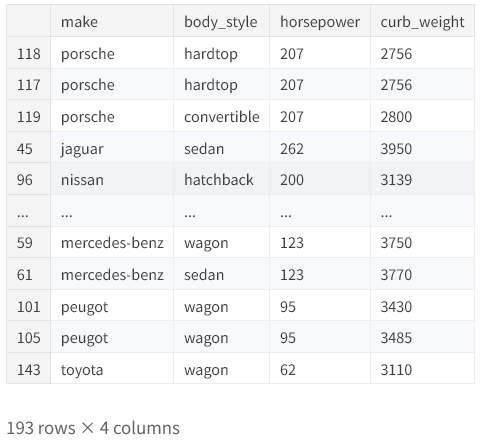
第三主成分体现出马力与整备质量之间的对比 —— 这似乎代表了跑车与旅行车之间的差异。
查看一下第三主成分的数据表:
idx = X_pca["PC3"].sort_values(ascending=False).index cols = ["make", "body_style", "horsepower", "curb_weight"] df.loc[idx, cols]
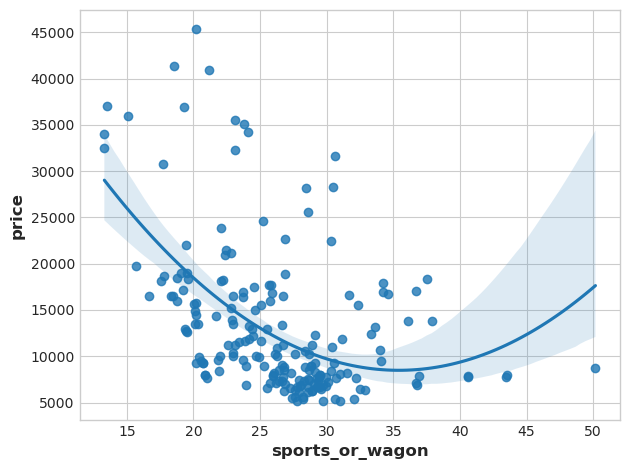
马力与整备质量均为数值型数据,现在创建一个新的比值特征:
df["sports_or_wagon"] = X.curb_weight / X.horsepower sns.regplot(x="sports_or_wagon", y='price', data=df, order=2);
3.6 目标编码
本节此前讲解的方法大多适用于数值型特征。本节课要介绍的目标编码,则专门针对类别型特征。它和独热编码、标签编码一样,都是将类别转换为数值的方式,区别在于目标编码会结合目标变量完成编码工作,因此它属于有监督特征工程方法。
3.6.1 目标编码
目标编码是一类编码方式,它会用从目标变量计算得出的数值,替换特征中的各类别取值。
其中一种简单且实用的实现方式,是采用第三课讲到的分组聚合运算(例如求均值)。以汽车数据集为例,该方法会计算出每个汽车品牌对应的平均售价。
autos["make_encoded"] = autos.groupby("make")["price"].transform("mean")
autos[["make", "price", "make_encoded"]].head(10)
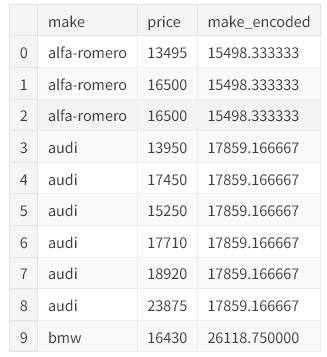
这种目标编码有时也被称为均值编码。当应用于二分类目标变量时,它还被称作二值计数编码。
3.6.2 平滑处理
然而,这类编码方式存在两个问题。首先是未知类别问题。目标编码存在过拟合的特殊风险,这意味着必须在独立的「编码集」上进行训练。当你将编码结果应用到后续数据集时,Pandas 会为编码集中未出现过的类别填充缺失值,而这些缺失值需要你通过某种方式进行填补。
其次是稀有类别问题。当某个类别在数据集中仅出现少数几次时,基于该分组计算的统计量大概率不够准确。在汽车数据集中,水星(Mercury)品牌仅出现一次,我们计算的价格「均值」就只是这一辆车的价格,这很难代表未来可能遇到的同品牌车型。对稀有类别进行目标编码会大幅增加过拟合的风险。
解决这些问题的方法是加入平滑处理。其核心思想是将类别内均值与全局均值进行融合。稀有类别会赋予类别均值更小的权重,而缺失的类别则直接使用全局均值。
伪代码如下:
![]()
其中权重是根据类别出现频率计算得出的数值,取值范围在 0 到 1 之间。
确定权重有一种简便方法:计算m 估计值。
![]()
公式中,n 代表该类别在数据中的总出现次数。参数 m 为平滑系数,m 取值越大,全局均值所占权重就越高。
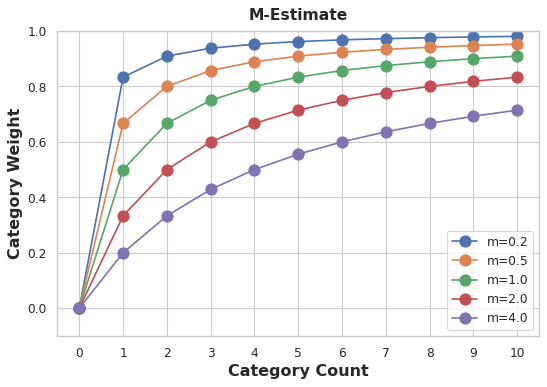
在这份汽车数据集中,共有三辆雪佛兰车型。若设置平滑系数 \(m=2.0\),那么雪佛兰这个类别的编码值,将由60% 的雪佛兰车型均价与40% 的数据集全局均价组合而成。
![]()
在设定平滑系数 m 时,需要考量各类别数据的噪声程度。同一品牌下车辆的价格波动是否很大?是否需要大量样本才能得到可靠的估计值?如果答案是肯定的,建议将 m 设大一些;若各品牌的均价相对稳定,那么选用较小的 m 即可。
3.6.3 目标编码的适用场景
目标编码尤其适用于以下情况:
-
高基数特征 类别数量繁多的特征很难处理:独热编码会产生海量新特征,而标签编码等其他方式又往往并不适用。目标编码则依托类别与目标变量的关联关系,直接为各类别生成数值。
-
基于业务经验的特征 结合过往经验,你可能判断某一类别特征具备实际价值,但它在常规特征指标中得分偏低。借助目标编码,能够挖掘出该特征真正的信息价值。
3.6.4 示例 — MovieLens1M 数据集
MovieLens1M 数据集包含 MovieLens 网站用户提交的一百万条电影评分,同时附带描述用户与影片的各类特征。下方代码单元已完成全部环境与数据初始化工作。
# 导入常用数据分析与可视化库
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# 忽略警告信息
import warnings
# 设置matplotlib绘图风格为 seaborn 白色网格
plt.style.use("seaborn-whitegrid")
# 自动调整布局,防止标题、坐标轴被截断
plt.rc("figure", autolayout=True)
# 设置坐标轴、标题的字体大小、粗细(统一图表样式)
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=14,
titlepad=10,
)
# 关闭所有警告提示
warnings.filterwarnings('ignore')
# 读取 MovieLens 100万条评分数据
df = pd.read_csv("../input/fe-course-data/movielens1m.csv")
# 将数据类型转为 uint8(无符号8位整型),大幅减少内存占用
df = df.astype(np.uint8, errors='ignore')
# 输出:数据集中唯一邮政编码的数量
print("Number of Unique Zipcodes: {}".format(df["Zipcode"].nunique()))
![]()
该邮编特征拥有三千余个类别,非常适合采用目标编码。而这份数据集超百万行的体量,也让我们可以划分出部分数据专门用于训练编码器。
首先我们先划分出25%的数据,用来训练目标编码器。
X = df.copy()
y = X.pop('Rating')
X_encode = X.sample(frac=0.25)
y_encode = y[X_encode.index]
X_pretrain = X.drop(X_encode.index)
y_train = y[X_pretrain.index]
scikit-learn 扩展库中的category_encoders模块实现了 m 估计编码器,接下来我们将使用它对邮编特征进行编码。
# 导入 m-估计 编码器(带平滑的目标编码器) from category_encoders import MEstimateEncoder # 创建编码器实例 # cols:指定要编码的列 # m=5.0:平滑系数,越大越依赖全局均值,越小越依赖类别自身均值 encoder = MEstimateEncoder(cols=["Zipcode"], m=5.0) # 在专门用来训练编码器的数据集上拟合(学习编码规则) encoder.fit(X_encode, y_encode) # 用训练好的编码器转换特征,把类别型邮编替换成编码后的数值 X_train = encoder.transform(X_pretrain)
我们将编码后的值与目标变量进行对比,以此判断该编码方式的信息有效性。
plt.figure(dpi=90)
ax = sns.distplot(y, kde=False, norm_hist=True)
ax = sns.kdeplot(X_train.Zipcode, color='r', ax=ax)
ax.set_xlabel("Rating")
ax.legend(labels=['Zipcode', 'Rating']);
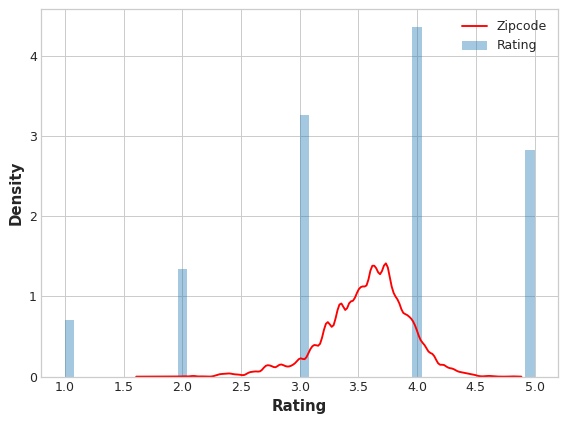
编码后的邮编特征分布与实际评分的分布大致吻合。这说明不同邮编区域的用户评分存在明显差异,本次目标编码成功提取到了有效信息。
4. 中级机器学习
4.1 分类变量
分类变量的取值数量是有限的。
举个例子,有一项调查询问吃早餐的频率,设置了四个选项:“从不吃”“很少吃”“多数日子吃” 和 “每天都吃”。这类数据就属于分类数据,因为所有答案都归属于固定的类别集合。
如果调查统计人们所使用的汽车品牌,答案会分为本田、丰田、福特等不同类别,这同样属于分类数据。
在 Python 中使用大多数机器学习模型时,若未提前对这类变量做预处理,直接输入模型会触发报错。本文将对比三种常用的分类数据预处理方案:(1)直接剔除分类变量;(2)序数编码;(3)独热编码。
4.1.1 直接剔除分类变量
处理分类变量最简单的方式,就是将其从数据集中直接删除。这种方法仅适用于该字段不具备有效信息的场景。
代码如下:
drop_X_train = X_train.select_dtypes(exclude=['object']) drop_X_valid = X_valid.select_dtypes(exclude=['object'])
4.1.2 序数编码
序数编码会为每一个不同的类别值分配一个唯一的整数。
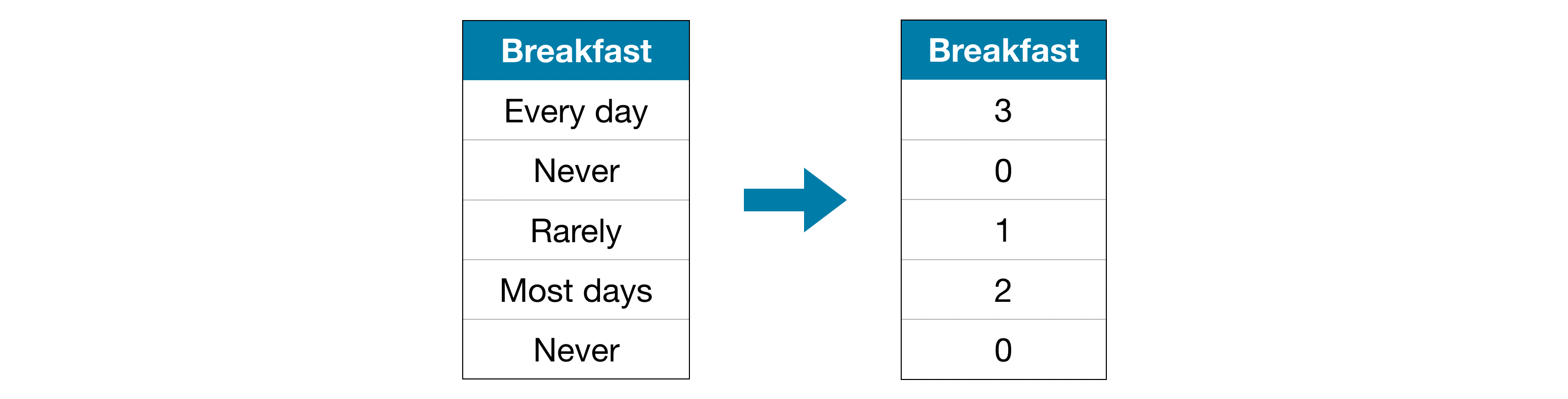
该编码方式默认类别存在顺序关系:从不吃 (0) < 很少吃 (1) < 多数日子吃 (2) < 每天都吃 (3)。
在这个例子中,这样的设定是合理的,因为各类别之间有着明确的等级次序。并非所有分类变量都具备清晰的取值顺序,我们将有顺序的分类变量称为序数变量。对于树模型(如决策树、随机森林),使用序数编码处理序数变量通常能取得不错的效果。
序数编码的代码如下:
# 从 sklearn 库导入 序数编码器 from sklearn.preprocessing import OrdinalEncoder # 复制数据,避免修改原始的训练集和验证集 label_X_train = X_train.copy() label_X_valid = X_valid.copy() # 创建序数编码器实例 ordinal_encoder = OrdinalEncoder() # 在训练集上学习编码规则,并同时转换训练集 label_X_train[object_cols] = ordinal_encoder.fit_transform(X_train[object_cols]) # 只用学习好的规则转换验证集 label_X_valid[object_cols] = ordinal_encoder.transform(X_valid[object_cols])
4.1.3 独热编码
独热编码会生成新的列,用于标识原始数据中每个可能取值是否存在。下面我们结合示例来理解这一编码方式。
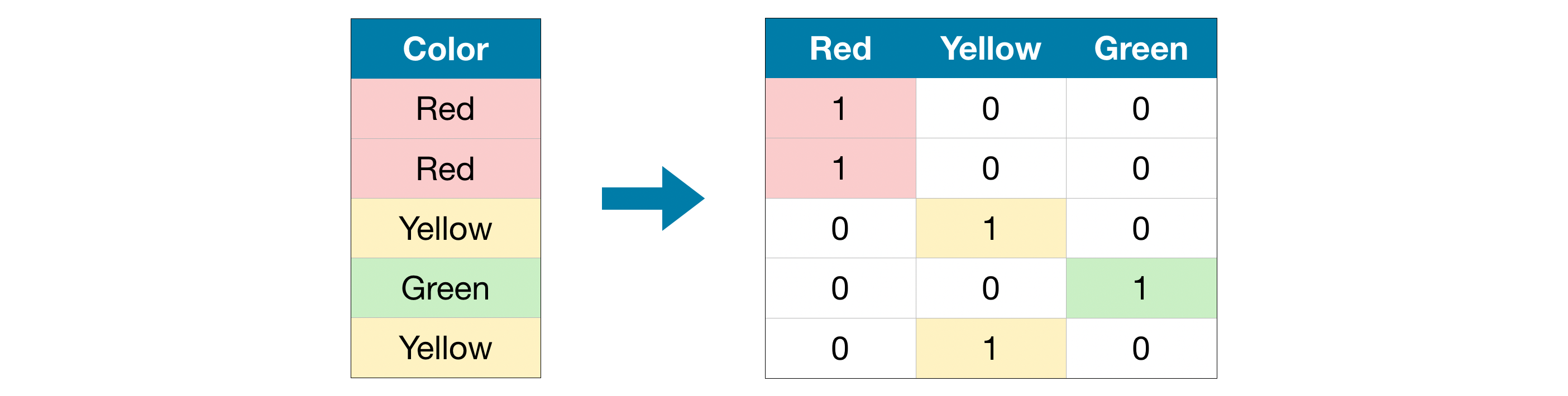
原始数据集中,颜色是一个分类变量,包含红色、黄色、绿色三个类别。对应的独热编码会为每一个类别单独生成一列,数据行数则与原数据集保持一致。若原始值为红色,就在 “红色” 列填 1;若原始值为黄色,就在 “黄色” 列填 1,其余以此类推。
与序数编码不同,独热编码不假设类别之间存在顺序关系。因此,当分类数据没有明确次序时(比如红色和黄色不存在高低、大小之分),该编码方式效果尤佳。这类本身无内在排序的分类变量,我们称之为名义变量。
如果分类变量的取值种类过多,独热编码通常表现不佳,一般不建议用于类别数超过 15 的特征。
独热编码的代码如下:
# 从 sklearn 导入独热编码器 from sklearn.preprocessing import OneHotEncoder # 初始化独热编码器 # handle_unknown='ignore':遇到未知类别时不报错,填0 # sparse=False:输出为普通数组,而非稀疏矩阵 OH_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False) # 对训练集的分类列进行拟合 + 转换,并转成DataFrame OH_cols_train = pd.DataFrame(OH_encoder.fit_transform(X_train[object_cols])) # 对验证集只做转换,使用训练集学到的规则 OH_cols_valid = pd.DataFrame(OH_encoder.transform(X_valid[object_cols])) # 独热编码会丢失索引,这里把原索引恢复回去 OH_cols_train.index = X_train.index OH_cols_valid.index = X_valid.index # 删掉原来的文本分类列(用独热编码列替换它们) num_X_train = X_train.drop(object_cols, axis=1) num_X_valid = X_valid.drop(object_cols, axis=1) # 把数值列和独热编码列拼接在一起 OH_X_train = pd.concat([num_X_train, OH_cols_train], axis=1) OH_X_valid = pd.concat([num_X_valid, OH_cols_valid], axis=1) # 确保所有列名都是字符串类型(避免报错) OH_X_train.columns = OH_X_train.columns.astype(str) OH_X_valid.columns = OH_X_valid.columns.astype(str)
4.2 管道
管道(Pipeline) 是一种简化数据预处理与建模代码、提升代码规范性的工具。简单来说,管道会将数据预处理和模型训练的流程整合为一体,调用时可当作单个步骤使用。
不少数据科学家在搭建模型时不会使用管道,而是零散编写代码,但管道具备诸多突出优势:
-
代码更简洁:若分步处理数据,代码容易杂乱。使用管道后,无需手动在每个环节管理训练集与验证集数据。
-
减少出错概率:能有效避免误用处理步骤、遗漏预处理操作等问题。
-
便于工程落地:将原型模型改造为可大规模部署的正式模型往往难度不小,管道可以为此提供助力。
-
丰富模型验证方式:下一篇教程会结合交叉验证举例说明这一点。
4.2.1 定义预处理流程
使用 ColumnTransformer 类来组合不同的数据预处理操作。
下方代码实现了两项功能:
- 对数值型数据进行缺失值填充;
- 先对分类数据填充缺失值,再执行独热编码。
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
# 数值型数据预处理
numerical_transformer = SimpleImputer(strategy='constant') # 填充0
# 分类数据预处理
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# 整合数值型与分类型数据的预处理流程
preprocessor = ColumnTransformer(
transformers=[
('num', numerical_transformer, numerical_cols),
('cat', categorical_transformer, categorical_cols)
])
4.2.2 定义模型
使用常用的 RandomForestRegressor 类来构建随机森林回归模型。
from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor(n_estimators=100, random_state=0)
4.2.3 创建并评估管道
最后,我们使用 Pipeline 类搭建管道,将数据预处理与模型训练环节整合在一起。有几点重要内容需要注意:
使用管道时,仅需一行代码就能完成训练数据预处理和模型拟合。反之,若不使用管道,就要分开执行缺失值填充、独热编码、模型训练等操作。当数据同时包含数值变量和分类变量时,代码会变得格外繁杂。
调用预测方法时,直接传入未经处理的验证集特征 X_valid 即可,管道会在生成预测结果前自动完成预处理。而如果不使用管道,就必须手动先对验证集做预处理,再进行预测。
# 导入平均绝对误差评估指标
from sklearn.metrics import mean_absolute_error
# 搭建管道:整合预处理与模型
my_pipeline = Pipeline(steps=[('preprocessor', preprocessor), # 第一步:数据预处理
('model', model) # 第二步:模型
])
# 对训练集执行预处理 + 训练模型
my_pipeline.fit(X_train, y_train)
# 自动完成验证集预处理并生成预测结果
preds = my_pipeline.predict(X_valid)
# 计算模型误差并评估
score = mean_absolute_error(y_valid, preds)
print('MAE:', score)
4.3 交叉验证
机器学习是一个反复迭代的过程。
在实践中,你需要选择预测特征、模型类型以及模型参数等。此前,我们一直采用留出法验证集,以数据结果为依据来完成上述选择、评判模型优劣。
但这种方法存在一定缺陷。举个例子:假设数据集共有 5000 行数据,通常会抽取 20%(即 1000 行)作为验证集。此时模型得分会受到随机因素影响 —— 模型可能在这 1000 条数据上表现良好,换另外 1000 条数据,预测效果却不尽如人意。
极端情况下,若验证集仅有 1 条数据,对比不同模型时,谁的预测结果更准确基本全靠运气。
一般来说,验证集数据量越大,模型评估结果中的随机误差(也称 “噪声”)就越少,评估结果也越可靠。但弊端在于:扩大验证集就意味着减少训练集数据,而训练数据不足,最终训练出的模型效果也会变差。
4.3.1 什么是交叉验证
交叉验证会将数据集划分为多个不同子集,在各个子集上分别执行建模流程,从而得到多组模型评估结果。
举例来说,我们可以把整体数据均分为 5 份,每份占总数据的 20%,这种划分方式称为将数据分成5 折。
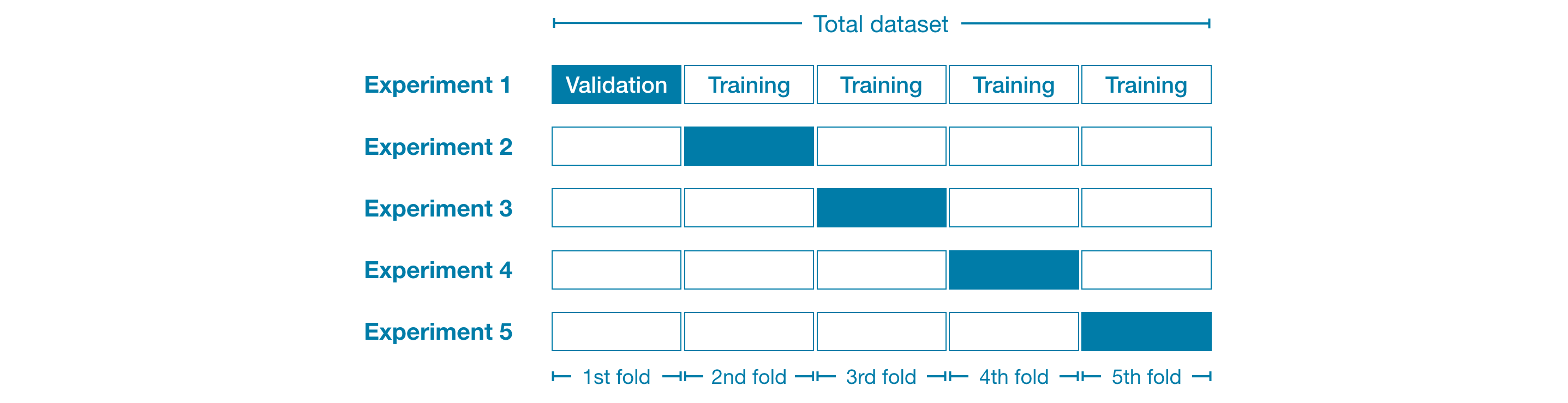
让每一折数据都轮流充当一次验证集,整个过程中,全部数据都会先后作为验证样本参与评估。最终得到的模型评价结果,综合了数据集中所有样本的表现。
4.3.2 何时使用交叉验证
交叉验证能更精准地评估模型效果(泛化能力),当你需要频繁调整模型方案时,这一优势尤为重要。但由于要针对每一折分别训练模型,它的运行耗时会更长。
结合以上利弊,两种方式的适用场景区分如下:
-
数据集较小时:额外的计算开销影响不大,建议使用交叉验证。
-
数据集较大时:单用一份验证集就足够。代码运行速度更快,且数据量充足,无需反复划分样本做验证。
数据集大小并没有明确的划分标准。如果你的模型单次训练耗时在数分钟以内,那么改用交叉验证会是不错的选择。
4.3.3 示例
我们沿用上一教程的数据集,将特征数据载入变量X,标签数据载入变量y。
随后构建管道:先通过缺失值填充器处理空缺数据,再使用随机森林模型完成预测。
不借助管道也能实现交叉验证,但操作难度会大幅增加。使用管道则能让代码变得简洁易懂。
# 导入 pandas 库,用于数据读取与处理
import pandas as pd
# 读取数据集
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# 挑选用作特征的列
cols_to_use = ['Rooms', 'Distance', 'Landsize', 'BuildingArea', 'YearBuilt']
X = data[cols_to_use]
# 选取预测目标(房价)
y = data.Price
# 导入随机森林回归、管道、缺失值填充工具
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
# 搭建管道:先填充缺失值,再训练随机森林模型
my_pipeline = Pipeline(steps=[
('preprocessor', SimpleImputer()), # 预处理:缺失值填充
('model', RandomForestRegressor(n_estimators=50, random_state=0)) # 模型:50棵树的随机森林
])
# 导入交叉验证工具
from sklearn.model_selection import cross_val_score
# 5折交叉验证
# sklearn 默认返回负MAE,因此乘以 -1 转为正常MAE
scores = -1 * cross_val_score(my_pipeline, X, y,
cv=5, # cv=5 代表 5折交叉验证
scoring='neg_mean_absolute_error') # 评估指标:负平均绝对误差
# 打印每一折对应的 MAE
print("MAE scores:\n", scores)
4.4 XGBoost 梯度提升算法
随机森林通过综合多棵决策树的预测结果,性能远优于单棵决策树。
随机森林属于集成学习方法。顾名思义,集成学习会融合多个模型的预测结果(随机森林便是整合了多棵决策树)。
接下来我们学习另一种集成算法:梯度提升。
4.4.1 梯度提升
梯度提升会不断循环迭代,逐步将新模型加入集成框架中。
首先,先用一个基础模型初始化集成体系,这个初始模型的预测效果往往比较粗糙。即便它的预测偏差很大,后续新增的模型也会逐步修正这些误差。
随后开始循环迭代,步骤如下:
-
利用当前已有的集成模型,对数据集中的每一条样本做出预测。最终预测结果为集成内所有模型的输出之和。
-
根据预测结果计算损失函数(例如均方误差)。
-
基于损失函数训练一个新模型,并将其纳入集成体系。训练目标是调整新模型的参数,让整体损失进一步降低。 补充说明:梯度提升中的梯度,指的是我们会借助梯度下降算法,依据损失函数求解新模型的参数。
-
将训练好的新模型加入集成框架。
之后不断重复上述整套流程。
梯度提升算法模型的代码:
from xgboost import XGBRegressor my_model = XGBRegressor() my_model.fit(X_train, y_train)
4.4.2 参数调优
XGBoost 中有部分参数会显著影响模型精度与训练速度,首先你需要了解以下核心参数:
n_estimators
该参数用于指定执行上述建模迭代流程的次数,其数值等同于集成模型中决策树的总数量。
-
取值过小会引发欠拟合,导致模型在训练集和测试集上的预测效果都较差。
-
取值过大会引发过拟合,模型在训练集上预测表现优异,但在我们真正关注的测试集上效果不佳。
该参数常用取值范围为 100 至 1000,具体数值很大程度上取决于学习率。
4.5 数据泄漏
当训练数据中包含了与预测目标相关的信息,但模型正式投入预测时却无法获取这类数据,就会发生数据泄露。其后果是:模型在训练集(甚至验证集)上表现优异,但实际上线使用时效果大幅下滑。
简单来说,数据泄露会让模型看似精度很高,可一旦用于实际业务预测,准确率就会急剧下降。
数据泄露主要分为两类:目标泄露和训练集与测试集数据污染。
4.5.1 目标泄露
当特征数据在实际预测场景中无法获取时,便会引发目标泄露。判断是否存在目标泄露,关键要结合数据的产生时间与先后顺序,而非只看该特征能否提升预测效果。
4.5.2 训练集 - 测试集数据污染
另一种数据泄露问题,源于未能严格区分训练数据与验证数据。
要知道,设置验证集的目的,是评估模型在从未接触过的数据上的表现。如果验证数据影响了数据预处理逻辑,就会悄悄破坏验证流程,这种情况就被称为训练集 - 测试集数据污染。
举个例子:假如你在执行数据集划分(train_test_split)之前,就完成了预处理操作(比如拟合缺失值填充器)。最终结果往往是:模型在验证集上得分很高,让你误以为效果理想,但实际部署后预测表现却很差。
究其原因,预处理阶段混入了验证集或测试集的信息,模型自然在这批数据上表现良好,却无法泛化到全新数据。当特征工程流程变得更加复杂时,这类问题会更加隐蔽,危害也更大。
如果采用简单的划分方式拆分训练集与验证集,所有拟合操作(包括各类预处理)都必须排除验证数据。使用 Scikit-learn 管道可以轻松规避该问题。而在开展交叉验证时,务必将预处理步骤写入管道内部,这一点尤为关键。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)