RPA 闯入设计部
AI 自动核查电商稿件文字,把百万级损失拦在印刷前
导语
在电商行业,一张详情页、一个包装袋上的错别字或错误参数,就可能让一批货变成废品,甚至引发客诉和召回。美术设计团队是创意发动机,却也背负着“一字之差,全盘报废”的巨大风险。RPA(机器人流程自动化)与 AI 的联手,正在成为这一环节的“终极校对员”。
本文将通过一个我在某集团下属电商公司落地的项目,详解如何用 RPA 自动提取设计稿中的文字,结合本地产品知识库,一键发送给大模型进行核验,生成可视化纠错报告。在人工二次确认后,错误率从千分三降至接近零,每张稿件的核对时间从 30 分钟压缩到 3 分钟。
|
一、RPA 在美术/设计部门的用武之地 很多人认为 RPA 只适合财务、人力等白领流程,但实际上,设计部门的“非创意”环节正是自动化的天然土壤: 应用场景 |
具体描述 |
价值 |
|
1. 稿件文字核验 |
自动提取设计稿(PSD/AI/图片)中的文字,与产品规格书对照,标记错别字、单位错误、成分误写。 |
拦截印刷风险,避免批次报废。 |
|
2. 批量套版与切图 |
根据命名规则和模板,RPA 驱动 Photoshop 脚本自动生成不同尺寸的主图、详情页切片。 |
释放设计师双手,日均节省 2 小时。 |
|
3. 多平台合规检测 |
自动扫描图片,检查是否包含“第一”“最”等违禁词,以及平台要求的特殊标识。 |
有效规避下架和罚款风险。 |
|
4. 设计资产归档 |
自动将定稿文件按项目、版本、日期上传到共享云盘并更新协作表格。 |
保证版本不混乱,新人也能秒找文件。 |
其中,“稿件文字核验” 在货值高的行业(如美妆、3C、食品)是刚需中的刚需,因为包装或详情页上的一处印刷错误,轻则改版重印,重则产品全量召回。
二、实战案例:零失误的设计稿文字智能核查系统
2.1 血淋淋的业务痛点
我服务的品牌主营护肤品,每天有 20-40 款新详情页、海报、包装稿待审。
人工校对瓶颈
一名设计助理专职逐字比对成分表、净含量、批号等信息,日均可核对 20 张,加班常态。
损失惨重
去年某次圣诞节,包装上“Nicotinamide”误写为“Nicotinemide”,导致 20 万支包材报废,加上返工和平台处罚,直接损失超 80 万。
信息源分散
正确的产品信息散落在 ERP、产品规格书、药监局备案截图等多个地方,人工查找极易漏项。
2.2 解决方案架构
我们建立了一套闭环系统:“RPA 流程调度 + 本地标准化知识库 + 大模型语义核验”。
RPA 监听与提取
监控共享文件夹,一旦有新的设计稿(.png/.jpg/.pdf)上传,立即触发 OCR 提取全部文本。
产品 ID 匹配与知识库查询
根据文件名中的产品编码,从本地 MySQL 知识库中精准拉取对应的“标准信息卡片”(品名、成分、功效、注意事项等)。
AI 多维度核验
将 OCR 文本和知识库信息组织成结构化提示词,发送给大模型(我们用的是通义千问 API),要求其逐条比对,指出错别字、信息矛盾、格式错误,并输出JSON格式的核验报告。
报告生成与推送
RPA 将 JSON 解析为一份中文 Markdown 报告(带高亮标记),存档并发送给指定设计师复核。
为何如此设计?
如果每次都把完整的知识库塞给 AI,Token 消耗巨大且容易产生幻觉。使用 “本地知识库精准检索” 作为前置,每次只需传输候选产品的几条标准信息,成本降低 90% 以上,准确率明显提升。
2.3 详细实现步骤
第一步:RPA 监控文件夹 + OCR 提取文字
利用 watchdog 监听设计稿上传目录,触发 OCR 处理。选择 PaddleOCR 是因为其离线可用、对中文印刷体识别率高。
import time
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang='ch') # 初始化一次
class DesignFileHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith(('.png', '.jpg', '.pdf')):
print(f"检测到新文件:{event.src_path}")
process_file(event.src_path)
def extract_text(image_path):
result = ocr.ocr(image_path, cls=True)
# 将所有识别出的文本按行拼接
full_text = "\n".join([line[1][0] for line in result[0]])
return full_text
# 启动监听
observer = Observer()
observer.schedule(DesignFileHandler(), path="./waiting_designs", recursive=False)
observer.start()第二步:提取产品编码,精准查询知识库
我们要求设计师在命名文件时遵循规范:产品编码_用途_版本.png,RPA 便可截取编码。
import re
import pymysql
def get_product_info(product_code):
conn = pymysql.connect(host='10.0.0.5', user='rpa', password='***', db='product_center')
# 从标准化产品表中提取必核对字段
sql = f"""SELECT 产品名, 成分, 净含量, 功效, 使用方法, 保质期, 备案号
FROM product_knowledge_base WHERE 编码='{product_code}'"""
df = pd.read_sql(sql, conn)
conn.close()
if not df.empty:
return df.iloc[0].to_dict()
else:
return None
def parse_code_from_filename(filename):
match = re.match(r"([A-Z0-9]+)_", filename)
return match.group(1) if match else None第三步:构建提示词,调用大模型做终极核验
这是核心大脑。我们把 OCR 文本和知识库标准信息拼成对比表,让模型扮演“严苛的包装审核员”。
def suite_AI(data_dic, products_info_list, supplier_name, unit_conversion_excel_path):
"""
审核套装稿件(由多个单产品稿件组合而成)
Args:
data_dic: 基准字典,包含所有产品的标准信息(产品名、使用方法、警告语、单位换算等)
products_info_list: list of str,每个元素为一个从SVG稿件中提取的产品文本信息
注意:SVG稿件文本可能包含与产品信息无关的工艺标注、尺寸等噪音内容
supplier_name: 供应商名称
unit_conversion_excel_path: 净含量换算规范 xlsx 文件路径
Returns:
str: 所有产品的审核结果汇总
"""
# 获取API Key
api_key = xbot.asset.get_asset('txt', 'APIKey', 0)
client = OpenAI(
api_key=api_key[0],
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# ========== 读取单位换算表 ==========
try:
df_grams = pd.read_excel(unit_conversion_excel_path, sheet_name=0, header=1, usecols="A:B")
df_ml = pd.read_excel(unit_conversion_excel_path, sheet_name=0, header=1, usecols="D:E")
# 重命名列
df_grams.columns = ["克 (g)", "盎司 (oz)"]
df_ml.columns = ["毫升 (mL)", "美式液量盎司 (fl oz)"]
# 去除空行
df_grams = df_grams.dropna(how='all').dropna(subset=["克 (g)"])
df_ml = df_ml.dropna(how='all').dropna(subset=["毫升 (mL)"])
# 构建换算表文字说明
conversion_text = "【净含量单位换算对照表(必须严格匹配)】\n"
conversion_text += "1. 克重换算(g ↔ oz):\n"
for _, row in df_grams.iterrows():
g = str(row["克 (g)"]).strip()
oz = str(row["盎司 (oz)"]).strip()
conversion_text += f" {g} g ↔ {oz} oz\n"
conversion_text += "\n2. 液量换算(mL ↔ fl oz):\n"
for _, row in df_ml.iterrows():
ml = str(row["毫升 (mL)"]).strip()
floz = str(row["美式液量盎司 (fl oz)"]).strip()
conversion_text += f" {ml} mL ↔ {floz} fl oz\n"
conversion_text += (
"\n换算规则:\n"
"- 如果稿件中出现公制和英制数值对(例如 '8.5 fl oz (220 mL)'),"
"则必须完全匹配上表中的对应关系。\n"
"- 例如:8.5 fl oz 在表中对应的是 250 mL(根据表格数据),若稿件出现 220 mL,则判定为未通过。\n"
"- 如果表格中某一行有多个候选值(如 '28.3 或 29'),则稿件中可使用其中任意一个,仍视为匹配。\n"
"- 不在表格中出现的组合一律视为换算错误,不通过。\n"
)
except Exception as e:
conversion_text = f"(读取单位换算表失败:{e},将使用默认换算规则)"
# ========== 构建系统消息 ==========
system_content = f"""你是一个产品信息审核专家。你需要根据基准字典中的标准数据,审核从SVG稿件中提取的产品文本信息。
**基准字典(标准数据)**:
{data_dic}
**重要说明**:你要审核的文本是从SVG印刷稿件中提取的,可能包含:
- 工艺标注(如"光油"、"哑膜"、"烫金"等印刷术语)
- 尺寸标注(如"43X105"、"65X65"等数字)
- 材料说明(如"PET(透明)"、"纸标(铜版)"等)
- 产品信息(产品名、使用方法、警告语、净含量等)
- 公司信息(制造商、地址、联系方式等)
请忽略这些印刷工艺相关的内容,**只关注与产品信息相关的文本**进行审核。
**通用要求**:所有产品信息(包括产品名、使用方法、警告语、香味名称、致辞内容、其他术语、邮件地址等)都必须同时包含英文和法文版本。若缺失任何一种语言版本,则视为不通过。
**注意**:以下法规特定字符在出现时,不要求同时存在英文和法文版本,可单独出现:FR、POT、FLACON。
**审核流程(关键:多实例识别)**:
- 稿件中可能包含多个产品的信息,也可能包含**同一种产品但不同香味/颜色/规格的多个实例**。
- 请仔细阅读文本,根据**产品名的出现位置**、**伴随的净含量**、**香味名称**、**包装规格**等信息来区分不同的产品实例。
- **重要**:即使产品名完全相同(例如两处都出现“SHIMMERING BUBBLE BATH”),如果它们分别关联了不同的香味(如一处是LAVENDER,另一处是VANILLA)或不同的净含量,则必须视为**两个独立的产品实例**,各自独立审核。不得因为文本有重复而将其合并为一个产品。
- 同一产品实例的正标和背标信息可能分散在稿件中,但通常会共享相同的产品名、香味和净含量等核心标识。请根据这些标识将分散的文本聚合到同一个实例下。
- 对于识别出的每个产品实例,按以下规则匹配基准字典:
1. 从该实例的文本中提取英文产品名(可能以多种形式出现,如“SHOWER GEL”、“BODY SCRUB”、“SHIMMERING BUBBLE BATH”等)。
2. 在字典的“个护产品”和“美妆产品”的“products”下查找匹配的条目。
3. **匹配规则**:将提取到的英文产品名与字典中各条目“产品名”字段的“英”值进行忽略大小写的**完全匹配**。一个“英”值可能包含斜杠“/”分隔的多个候选名称,稿件中的名称匹配其中任意一个即视为匹配成功。
4. 找到匹配条目后,该产品实例的所有后续比对都将使用此条目的数据。
5. 如果未找到匹配条目,输出“错误:未找到与英文产品名 [提取的英文产品名] 匹配的字典条目”,并跳过该实例的后续检查。
- 供应商名称为:{supplier_name}
**检查点列表(针对每个识别出的产品实例,序号从1开始)**:
1. **产品名比对**:
- 从该实例的稿件文本中提取英文产品名和法文产品名。**必须同时存在两种语言版本。**
- 分别与字典匹配条目中“产品名”字段的对应语言候选名称(忽略大小写)完全一致。
- 如果缺失任一语言,或语言不匹配,均视为不通过。
- 注意:产品名可能以多种形式出现(如单行、多行、有斜杠分隔、与香味名称粘连等),只要能提取出完整的产品名即可。大小写差异不影响本检查点的通过/不通过判断,统一由检查点12评估。
2. **使用方法比对**:
- 提取该实例的英文和法文使用方法(通常以“Directions:”和“Instructions:”或类似标识引导)。
- 分别与字典中对应语言的使用方法进行完全一致比对(包括所有单词、标点、空格)。
- 必须同时存在且除大小写外的内容完全一致,否则不通过。大小写差异不影响本检查点,由检查点12单独评估。
3. **警告语比对(特殊警告语优先)**:
- 首先查找字典中该产品条目下的“特殊警告语”字段。若不为空,则必须以此为基准。
- 若无特殊警告语,则使用该产品所属大类的“通用警告语”字段。
- 提取稿件中的英文和法文警告语(通常以“WARNING:”和“AVERTISSEMENT:”引导),与基准进行完全一致比对。
- 必须同时存在且除大小写外的内容完全一致,否则不通过。大小写差异不影响本检查点,由检查点12单独评估。
4. **中文警告语检查**:
- 稿件中可以没有中文警告语,若没有则直接通过。
- 若出现中文警告语,则必须与字典中对应产品的中文内容完全一致。
5. **产品名单复数形式检查**:
- 检查稿件中产品名前方是否出现数字或复数描述,根据字典“复数品名”表判断单复数形式是否正确。
6. **其他术语格式检查**:
- 检查稿件中出现的其他术语(净重、成分、分销商、制造商、“中国制造”、无动物测试等)是否与字典“其他术语”表中的单词、标点、空格及语序一致,比对时忽略大小写。
- 每个术语必须同时包含英文和法文版本,且格式完全一致。
- **净含量表述特殊规则**:
* 判断是单产品单数量还是多产品多数量。
* 仅单产品单数量时,使用不带“EACH”的格式。
* 多产品或多数量的情形必须使用带“EACH”的格式。
* 同时检查单位换算(见检查点9)。
7. **香味名称检查**:
- 若该产品实例的文本中包含香味描述(如“LAVENDER/LAVANDE”),则必须同时包含英文和法文香味名称。**缺失任何一种语言版本均视为不通过。**
- 提取到的英文和法文香味名称,分别与字典“香味”表中对应语言的名称进行忽略大小写的完全一致比对。大小写差异由检查点12统一评估。
8. **致辞内容检查**:
- 若稿件中包含感谢信、毛巾水洗标等内容,必须同时包含英文和法文版本。
- 与字典“英法双语”表中的内容完全一致。
9. **单位换算检查(使用固定换算表)**:
- 若稿件中同时出现公制(g/mL)和英制(oz/fl oz)数值,必须严格按照下方的换算对照表进行检查。
- 对于每一处英制-公制数值对,必须能找到表中完全一致或候选值匹配的对应关系。
- 如果出现表格中未列出的组合,或者数值对与表格不符,均判定为不通过。
- 注意:表中可能出现多个可选值,稿件中使用任意一个即可通过。
{conversion_text}
10. **公司名称检查**:
- 必须包含制造商信息,格式为“MANUFACTURED FOR”和“FABRIQUÉ POUR”双语同时出现。
- 检查是否包含完整的制造商名称和地址。
- 检查是否出现了分销商表述,按规则不应出现。
- 缺失或单语言版本均不通过。
11. **供应商名称检查**:
- 检查稿件中是否出现供应商信息。
- 若出现则必须与给定的供应商名称完全一致。
- 若未出现,则输出提示信息。
12. **文本大小写一致性检查**:
- 稿件中同一产品实例内的所有英文和法文文本必须保持统一的大小写格式:要么全部使用大写字母,要么全部使用首字母大写。
- 若同一实例内出现大小写格式混用,则判定为不通过。
- 注意:若稿件中同一实例文本整体为全大写,属于允许的统一格式,本检查点应判定为通过。
**输出格式要求**:
- 对稿件中识别出的每个产品实例,输出“=== 产品 X: [英文产品名] (香型/变体标识,如有) ===”(X为序号)。
- 然后按顺序输出每个检查点的结果。
- 每个检查点格式:“检查点X:通过” 或 “检查点X:未通过 - 预期值:... 实际值:...”。
- 如果某个产品因找不到匹配条目而跳过,直接输出错误信息。
- 在最后增加一个“=== 审核总结 ===”,列出稿件中发现的所有文本问题。
- 所有输出为纯文本,不得使用表格或Markdown格式。
- 每个产品结果之间用空行分隔。
请按照以上规则仔细审核稿件中的每个产品实例。注意区分印刷工艺文本和产品信息文本,并**确保同产品名但不同香味/规格的实例均被独立审核**。
"""
# 构建用户消息:将多个产品文本信息拼接
user_parts = []
for idx, pro_data in enumerate(products_info_list, 1):
user_parts.append(f"=== SVG稿件文本 {idx} ===\n{pro_data}")
user_content = "\n\n".join(user_parts)
# 添加提示,帮助AI理解稿件结构
user_content += "\n\n【重要提示】以上文本是从SVG印刷稿件中提取的,包含多个产品的正标和背标信息。请忽略印刷工艺相关内容(如光油、哑膜、尺寸数字等),只审核与产品信息相关的文本。产品信息通常以产品名、使用方法(Directions)、警告语(WARNING)等形式出现。"
try:
completion = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "system", "content": system_content},
{"role": "user", "content": user_content}
],
temperature=0.3,
timeout=360, # 5分钟超时
stream=True # 启用流式响应
)
# 收集流式响应片段
response_chunks = []
for chunk in completion:
if chunk.choices[0].delta.content:
response_chunks.append(chunk.choices[0].delta.content)
result = "".join(response_chunks)
return result
except Exception as e:
return f"调用AI审核套装稿件时出错:{str(e)}"第四步:生成核验报告并通知人工复核
解析返回的 JSON,并生成Word报告,同时保存归档,并发送企业微信或钉钉飞书通知。
import json
import os
import requests
from docx import Document
from docx.shared import Pt, RGBColor, Inches
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
def generate_report(json_str, file_name, product_name):
"""
生成 Word 核验报告。
:param json_str: JSON 字符串:
{
"is_pass": false,
"errors": [
{
"error_type": "Title Error",
"error_content": "Niacinamide",
"correct_content": "Nicotinamide",
"risk_level": "High"
}
],
"suggestion": "Please verify product filing information and replace the incorrect term."
}
:param file_name: 稿件名称
:param product_name: 产品名称
:return: 保存的报告文件路径
"""
data = json.loads(json_str)
# 兼容中英文键名
def get_key(obj, *keys):
for k in keys:
if k in obj:
return obj[k]
return None
is_pass = get_key(data, 'is_pass', 'is_pass')
errors_raw = get_key(data, 'errors', 'errors') or []
suggestion = get_key(data, 'suggestion', 'suggestion') or "No suggestion provided."
# 将错误列表转换为统一英文结构
errors = []
for err in errors_raw:
errors.append({
'error_type': get_key(err, 'error_type', '错误类型') or 'Unknown',
'error_content': get_key(err, 'error_content', '错误内容') or '',
'correct_content': get_key(err, 'correct_content', '正确内容') or '',
'risk_level': get_key(err, 'risk_level', '风险等级') or 'Medium'
})
# 创建 Word 文档
doc = Document()
# 标题
title = doc.add_heading(f"Text Verification Report - {product_name}", level=1)
title.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 稿件名称
doc.add_heading(f"Document: {file_name}", level=2)
# 核验结果
result_para = doc.add_paragraph("Verification Result: ")
if is_pass:
run = result_para.add_run("PASS")
run.font.color.rgb = RGBColor(0, 128, 0) # Green
else:
run = result_para.add_run("FAILED (Errors Found)")
run.font.color.rgb = RGBColor(255, 0, 0) # Red
# 错误列表
if errors:
doc.add_heading("Error Details", level=2)
for idx, err in enumerate(errors, 1):
p = doc.add_paragraph(style='List Number')
p.add_run(f"{err['error_type']}: ").bold = True
p.add_run(f"{err['error_content']} → Should be {err['correct_content']}")
p.add_run(f" [{err['risk_level']} Risk]").italic = True
else:
doc.add_paragraph("No errors found.")
# 处理建议
doc.add_heading("Action Suggestion", level=2)
doc.add_paragraph(suggestion)
# 保存 Word 文件
os.makedirs("./reports", exist_ok=True)
report_path = f"./reports/{file_name}_report.docx"
doc.save(report_path)
print(f"Report saved to {report_path}")
return report_path
RPA统合所有模块执行
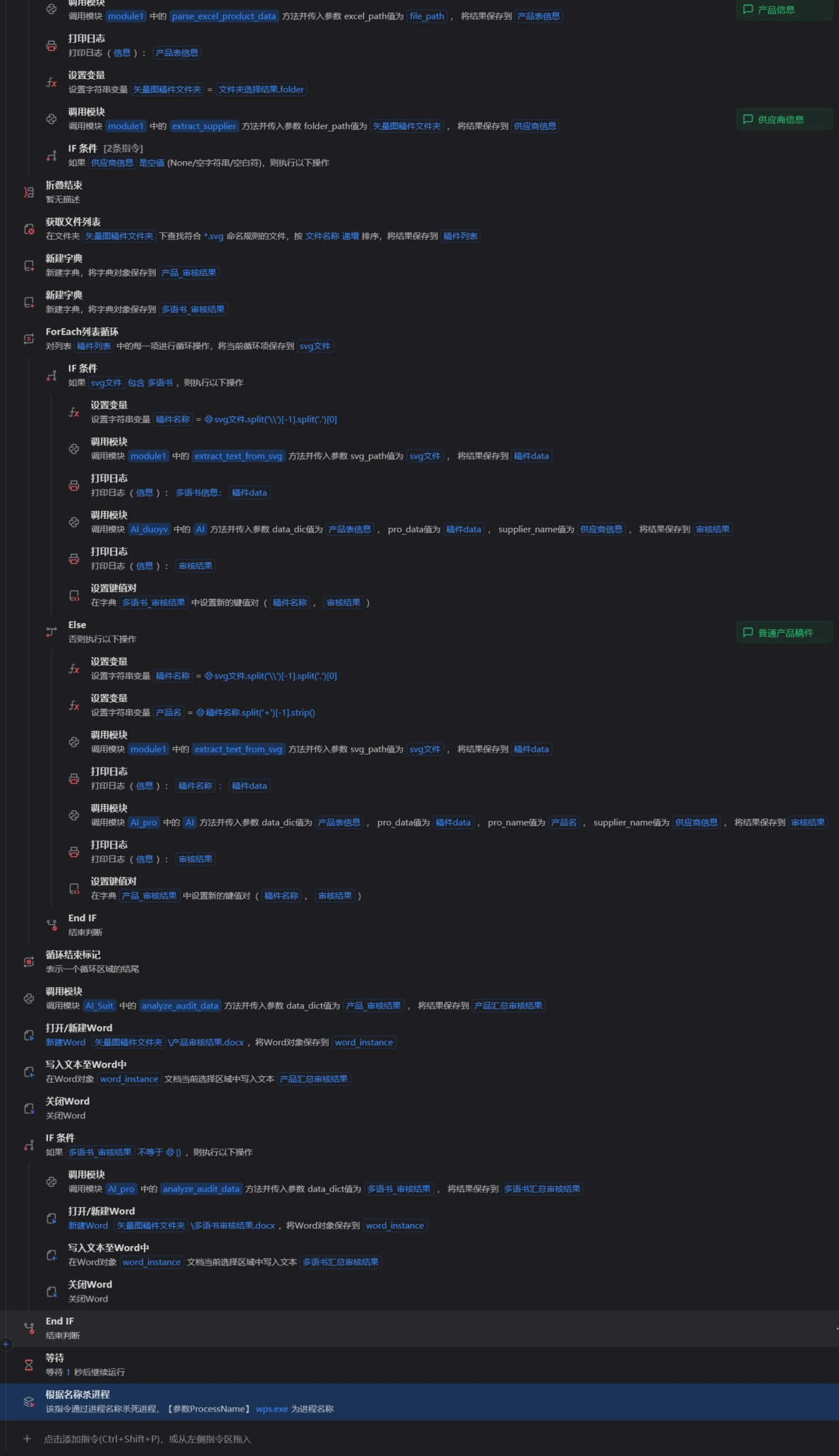
2.4 项目成果与直观变化
系统上线三个月,我们得到了这些硬指标:
错误拦截率 100%:
8 个微小但致命的错误(如“30ml”误为“30g”)被 AI 在一分钟内揪出,避免了至少两次批次包装重印,节省约 35 万元。
效率飞跃:
单张稿件核对平均耗时从 30 分钟 → 5 分钟(含人工最终确认),设计助理每天可多支援 2-3 个新项目。
知识库得以沉淀:
在整理标准产品信息的过程中,公司意外统一了原本混乱的成分表述,间接提升了其他系统的数据质量。
三、实施中的避坑指南
OCR 要“因地制宜”:
设计师常使用艺术字、竖排文字、极细字体,通用 OCR 容易翻车。建议对高频设计模板训练专属微调模型,或在 AI 审核 Prompt 中注明“OCR 可能将‘0’识别为‘O’”,让大模型具备容错判断能力。
AI 也会“信口开河”:
务必设置 temperature=0.1,并且限定输出格式为 JSON。同时,人工复核步骤绝对不能省,AI 目前适合做“全覆盖扫描”,最终决策权必须给人。
知识库是灵魂:
垃圾进垃圾出。必须由产品经理、法规专员共同维护知识库的“唯一真值”。我们内部规定,任何包材信息变更必须先更新知识库,再提交设计需求。
做好版本与回滚:
每份设计稿的 OCR 文本、AI 报告都要按版本存档。一旦发现误判,可以回溯是哪一环节出了问题。
四、结语
在这个案例中,RPA 扮演了串联一切的“流程主管”,本地知识库保证了核验的“事实锚点”,而大模型则提供了人类难以企及的“逐字粒度”与“多任务并行”能力。
设计团队的自尊心,不应该消耗在终日的文字校对里;他们的创意,才是品牌溢价的核心。 让 RPA 扛起纠错的责任,让设计师回归创造。
如果你对这个方案的具体代码实现或组件选型有更多疑问,欢迎在评论区与我探讨。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)