R语言支持向量机算法----iris数据集
·
1、训练模型
# 安装加载包
if (!require("e1071")) install.packages("e1071")
library(e1071)
# 内置数据集 iris(鸢尾花,多分类,选两类做二分类演示)
data(iris)
# 筛选两类:setosa 和 versicolor,只保留前两个特征
svm_data <- iris[iris$Species != "virginica", -3:-4]
svm_data$Species <- factor(svm_data$Species) # 分类变量必须转为因子
# 划分训练集和测试集(7:3)
set.seed(123) # 固定随机种子,结果可复现
train_idx <- sample(1:nrow(svm_data), size = 0.7*nrow(svm_data))
train <- svm_data[train_idx, ]
test <- svm_data[-train_idx, ]
# 线性SVM建模,kernel = "linear"
svm_linear <- svm(Species ~ ., data = train, kernel = "linear", cost = 1)
# 查看模型信息
summary(svm_linear)Call:
svm(formula = Species ~ ., data = train, kernel = "linear", cost = 1)
Parameters:
SVM-Type: C-classification
SVM-Kernel: linear
cost: 1
Number of Support Vectors: 10
( 5 5 )
Number of Classes: 2
Levels:
setosa versicolor
# 预测测试集
pred_linear <- predict(svm_linear, test)
# 混淆矩阵 & 准确率
table(Pred = pred_linear, True = test$Species)
acc_linear <- mean(pred_linear == test$Species)
cat("线性SVM准确率:", acc_linear, "\n")
#可视化
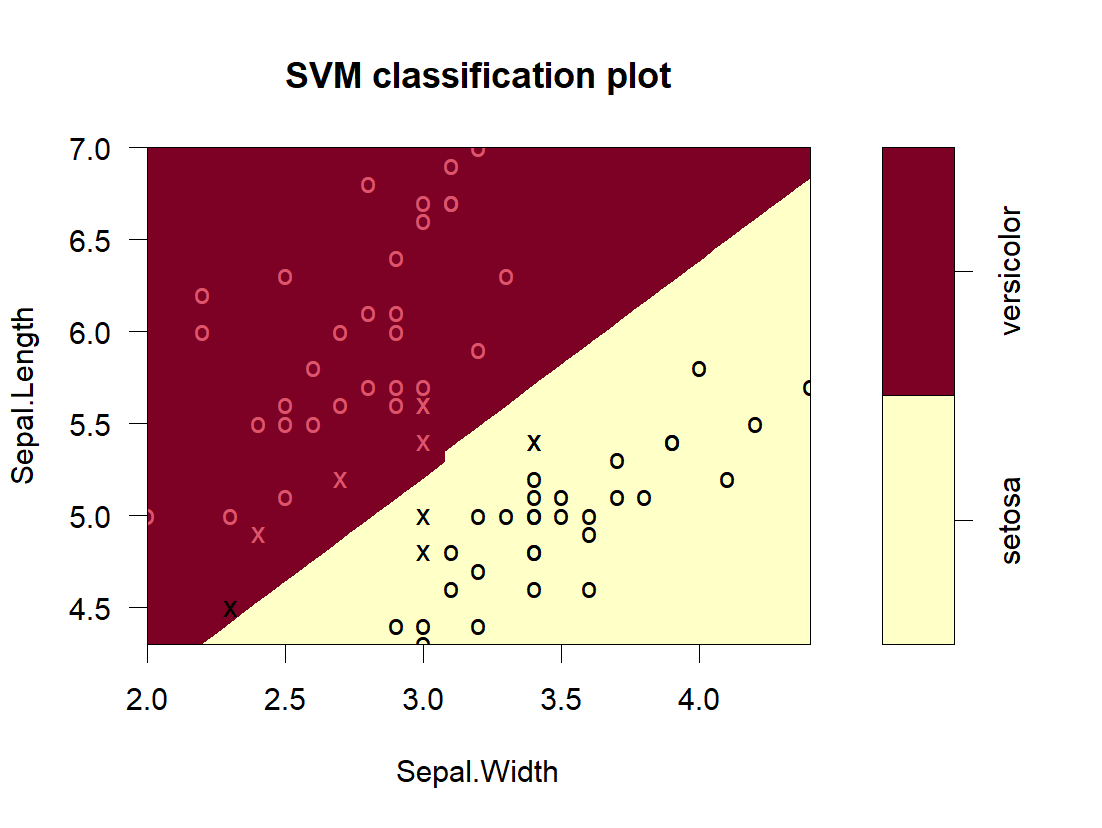
plot(svm_linear, data = train, Sepal.Length ~ Sepal.Width)True Pred setosa versicolor setosa 15 0 versicolor 0 15 线性SVM准确率: 1
2、高斯核(RBF)非线性 SVM(最常用)
RBF 核有两个关键超参数:
cost(C):惩罚系数,越大越不允许错分,易过拟合gamma:核函数参数,越大决策边界越复杂,易过拟合
# RBF核SVM
svm_rbf <- svm(Species ~ ., data = train, kernel = "radial",
cost = 1, gamma = 0.1)
# 模型摘要
summary(svm_rbf)
# 预测
pred_rbf <- predict(svm_rbf, test)
# 混淆矩阵
table(Pred = pred_rbf, True = test$Species)
acc_rbf <- mean(pred_rbf == test$Species)
cat("RBF核SVM准确率:", acc_rbf, "\n")3、调参
# 网格搜索超参数
set.seed(123)
svm_tune <- tune.svm(Species ~ ., data = train, kernel = "radial",
cost = c(0.1, 1, 10, 100),
gamma = c(0.01, 0.1, 1, 10))
# 最优参数
svm_tune$best.parameters
# gamma cost
#14 0.1 100
# 最优模型
best_svm <- svm_tune$best.model
# 测试集评估
pred_best <- predict(best_svm, test)
acc_best <- mean(pred_best == test$Species)
cat("调参后最优SVM准确率:", acc_best, "\n")
# 绘制分类边界图
plot(best_svm, data = train, Sepal.Length ~ Sepal.Width)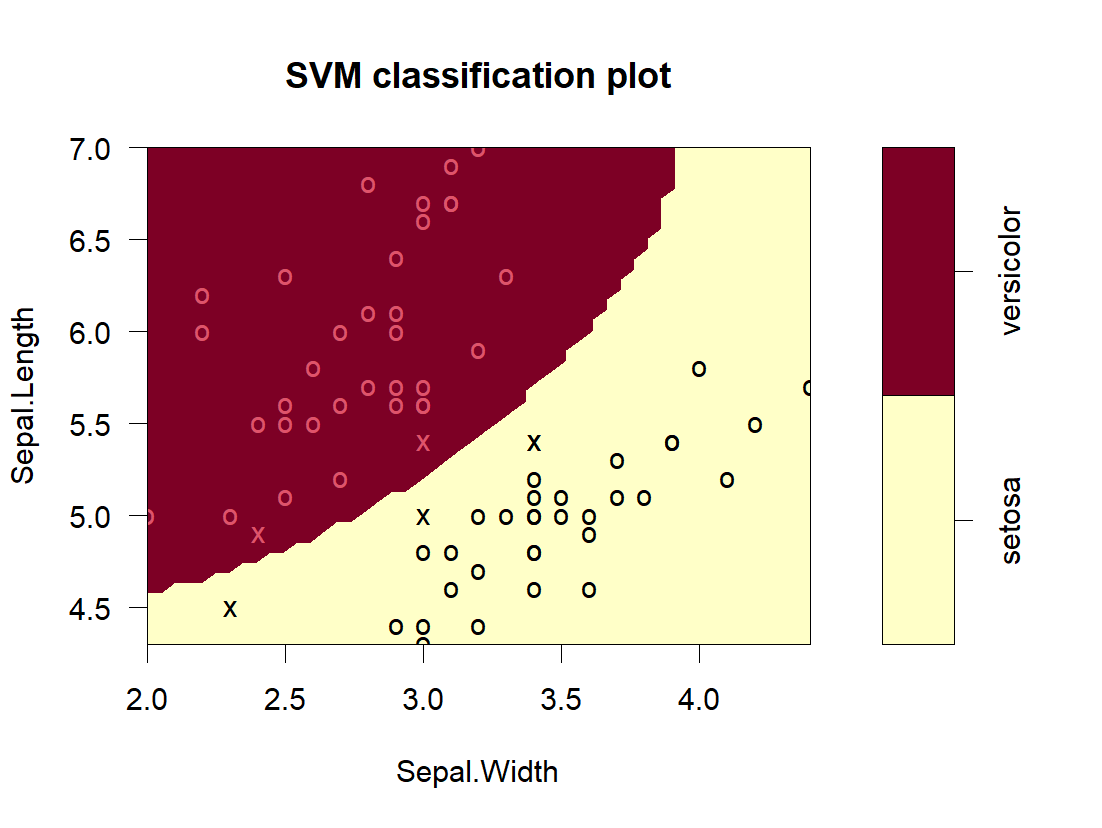
关键参数说明:
kernel:核函数,linear/radial/polynomial/sigmoid
cost:惩罚系数 C,控制对错分样本的惩罚力度
gamma:RBF 核宽度,控制邻域样本影响范围
scale = TRUE:默认自动标准化特征,SVM 对量纲敏感,必须标准化

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)