掌握AI核心:LLM、Prompt、RAG、Agent、Workflow全解析,从智能到稳定实战指南!
本文深入剖析了AI领域的核心概念:LLM作为“大脑”、Prompt作为“指令接口”、RAG解决“知识不足”、Agent实现“自主行动”,以及Workflow保障“稳定运行”。通过“公司员工”比喻,清晰阐述各组件关系与作用,强调AI应用需从Demo走向生产,关注智能、稳定、可控、可追溯的闭环,助力技术人构建成熟的AI工程体系。
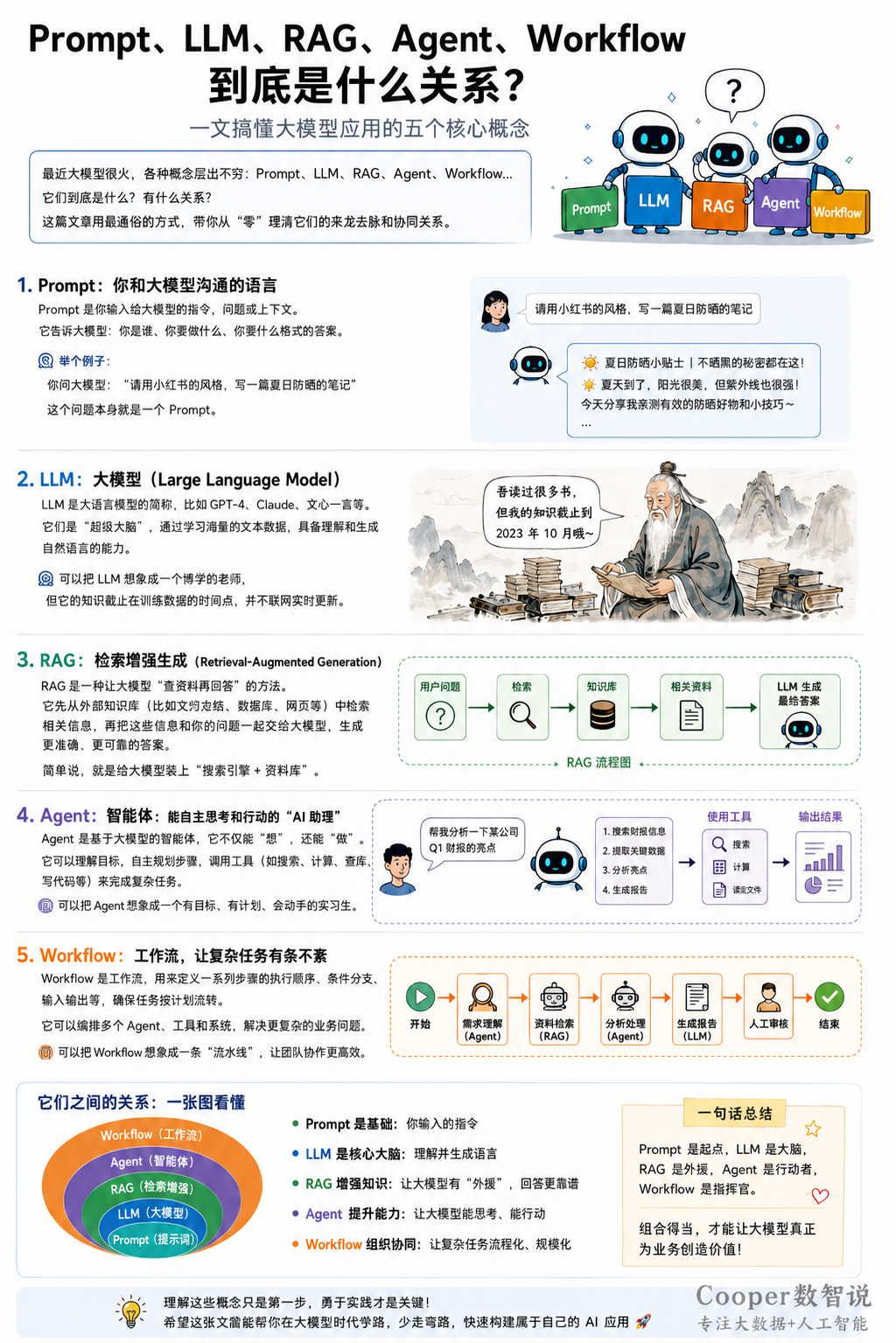
这两年,只要你关注 AI,一定绕不开几个词:Prompt、LLM、RAG、Agent、Workflow。
刚开始大家都在学 Prompt:
怎么问,AI 才能答得更好?
后来大家发现,只会写 Prompt 不够,因为大模型会胡说、知识不够新,于是 RAG 火了:
能不能让 AI 先查资料,再回答?
再后来,大家又觉得只问答还不够,希望 AI 能自动拆任务、调工具、写代码、查数据、发邮件,于是 Agent 火了:
能不能让 AI 像一个数字员工一样自己干活?
但真正落地到企业系统里,又会发现:完全让 Agent 自由发挥风险太大,还是要有明确流程、权限、审批、规则,于是 Workflow 又重新变得重要:
哪些步骤必须固定?哪些地方可以交给 AI 灵活处理?
所以很多人越学越乱:
Prompt、LLM、RAG、Agent、Workflow 到底是什么关系?它们是并列关系、包含关系,还是演进关系?
这篇文章用一套通俗但有深度的方式,把它们一次讲清楚。
一句话总览
可以先记住这个关系:
LLM 是大脑,Prompt 是指令,RAG 是外挂知识库,Agent 是会使用工具和规划任务的执行者,Workflow 是约束和编排整个执行过程的流程系统。
再换一个工程化的说法:
Prompt 负责表达意图,LLM 负责理解和生成,RAG 负责补充知识,Agent 负责决策和行动,Workflow 负责稳定交付。
它们不是谁取代谁,而是逐层组合。
一、LLM:整个 AI 应用的“发动机”
LLM,全称 Large Language Model,大语言模型。
比如 GPT、Claude、Gemini、通义千问、DeepSeek 等,本质上都是 LLM。
你可以把 LLM 理解成一个“通用语言智能引擎”。它擅长做几类事情:
- 理解自然语言
- 生成自然语言
- 总结、改写、翻译
- 代码生成
- 简单推理
- 多轮对话
- 根据上下文做判断
但要注意:LLM 不是一个完整应用,它只是一个能力核心。
就像发动机不是汽车。发动机很重要,但汽车还需要方向盘、刹车、轮胎、导航、车身结构和安全系统。
同理,LLM 很强,但它单独存在时有几个问题:
第一,它不知道你的私有数据。
比如你问它:“我们公司上个月哪个产品投诉最多?”如果你没有把内部数据给它,它不可能凭空知道。
第二,它的知识可能不是最新的。
大模型训练完成之后,它的参数知识就相对固定了。即使模型本身很聪明,也不代表它知道今天刚发生的事。
第三,它可能产生幻觉。
所谓幻觉,就是它看起来很自信,但内容可能不真实。
第四,它默认不能直接行动。
它可以告诉你“应该发一封邮件”,但如果没有工具调用能力,它不能真的帮你发出去。
所以,LLM 是核心,但不是全部。
二、Prompt:你和大模型沟通的“指令接口”
Prompt 就是你给大模型的输入指令。
很多人以为 Prompt 只是“提问技巧”,比如:
请你扮演一名资深架构师,帮我分析这个系统设计。
但在真正的 AI 应用里,Prompt 远不只是简单提问,它更像是一种“软编程”。
传统软件用代码控制机器:
if 条件 then 执行动作
AI 应用里,我们经常用 Prompt 控制模型的行为:
你是一个数据治理专家。
请基于以下元数据,判断字段命名是否规范。
输出必须包含:问题、原因、修改建议。
不要编造不存在的字段。
Prompt 的作用主要有四个:
- 设定角色
告诉模型它现在应该以什么身份回答。
例如:
你是一名有 10 年经验的大数据架构师。
- 提供任务
告诉模型要做什么。
例如:
请分析这段 Flink SQL 是否存在性能问题。
- 给出上下文
告诉模型依据什么资料回答。
例如:
以下是任务配置、运行日志和异常堆栈。
- 约束输出
告诉模型用什么格式、什么风格、什么边界输出。
例如:
请用 Markdown 表格输出,不要超过 800 字。
Prompt 很重要,但它也有边界。
如果你问的问题需要外部知识、私有数据、实时信息,仅靠 Prompt 是不够的。
这时就需要 RAG。
三、RAG:让大模型“先查资料,再回答”
RAG,全称 Retrieval-Augmented Generation,检索增强生成。
它解决的是一个非常现实的问题:
大模型本身不知道所有知识,尤其不知道你的企业内部知识。那能不能让它回答之前,先去知识库里查一遍?
RAG 的基本流程是:
- 用户提出问题
- 系统把问题转成向量或关键词
- 去知识库、文档库、数据库中检索相关内容
- 把检索到的内容塞进 Prompt
- LLM 基于这些资料生成答案
所以 RAG 并不是一个模型,而是一种架构模式。
它的核心思想是:
不把所有知识都塞进模型参数里,而是在回答时动态检索相关知识。
这就像一个人考试。
纯 LLM 像是闭卷考试,只能靠记忆。
RAG 像是开卷考试,可以先查资料,再组织答案。
RAG 适合什么场景?
RAG 非常适合以下场景:
- 企业知识库问答
- 政策制度查询
- 产品手册问答
- 合同、简历、报告解析
- 数据指标口径解释
- 代码库文档问答
- 运维手册问答
比如在大数据平台中,用户问:
ads_user_retention_7d 这个指标是怎么计算的?
系统可以先从指标平台、数据字典、血缘系统、SQL 脚本里检索相关内容,再让 LLM 汇总解释。
这样答案会比单纯问大模型靠谱得多。
但 RAG 也不是万能的
很多人误以为“上了 RAG 就解决幻觉问题”。这其实过于乐观。
RAG 的效果取决于很多环节:
- 文档是否完整
- 切片是否合理
- 向量检索是否准确
- 召回内容是否相关
- 排序是否有效
- Prompt 是否约束模型只基于资料回答
- 答案是否带引用来源
如果检索阶段就找错资料,大模型再强也可能答错。
所以 RAG 的关键不是“接一个向量库”,而是检索质量 + 上下文组织 + 答案约束。
四、Agent:从“会回答”到“会做事”
如果说 RAG 让大模型能够“查资料”,那么 Agent 则希望让大模型能够“做事情”。
Agent 通常包含几个能力:
- 目标理解
- 任务拆解
- 计划制定
- 工具调用
- 结果观察
- 过程反思
- 多轮执行
比如你对一个 Agent 说:
帮我分析昨天 Flink 作业失败的原因,并给出修复建议。
一个普通 LLM 可能只能根据你提供的日志进行分析。
但一个 Agent 可能会这样工作:
- 读取作业列表
- 找到失败任务
- 拉取 YARN 日志
- 查询 Flink checkpoint 状态
- 查看 HDFS 写入路径
- 分析异常堆栈
- 判断是数据倾斜、资源不足、权限问题还是依赖冲突
- 生成修复方案
- 必要时提交工单或创建修复脚本
这就从“问答系统”变成了“任务执行系统”。
Agent 的本质是什么?
Agent 的本质不是一个新模型,而是一种使用 LLM 的方式。
它通常由 LLM 加上一组外部能力组成:
Agent = LLM + Prompt + Tools + Memory + Planning + Execution Loop
其中:
- LLM 负责理解、推理和生成
- Prompt 负责定义角色、目标和边界
- Tools 负责连接外部系统
- Memory 负责保存上下文和历史经验
- Planning 负责拆解任务
- Execution Loop 负责循环执行、观察结果、调整下一步
所以 Agent 比 RAG 更进一步。
RAG 主要解决“知道什么”。
Agent 主要解决“怎么做”。
五、Workflow:让 AI 从“聪明”变成“稳定”
Workflow 是工作流,也就是一组明确的流程编排。
比如:
接收需求 → 解析需求 → 查询数据 → 生成报告 → 人工审核 → 发送邮件
在传统系统里,Workflow 很常见:OA 审批流、数据开发流程、订单处理流程、风控流程,本质上都是 Workflow。
到了 AI 时代,Workflow 没有过时,反而更重要了。
因为 Agent 虽然灵活,但也有风险:
- 可能走偏
- 可能多做
- 可能漏做
- 可能调用错误工具
- 可能输出不可控
- 可能不符合企业权限和审计要求
所以在企业级 AI 应用里,不能完全依赖一个自由发挥的 Agent。
更现实的方式是:
用 Workflow 控制主流程,用 Agent 处理其中需要智能判断的节点。
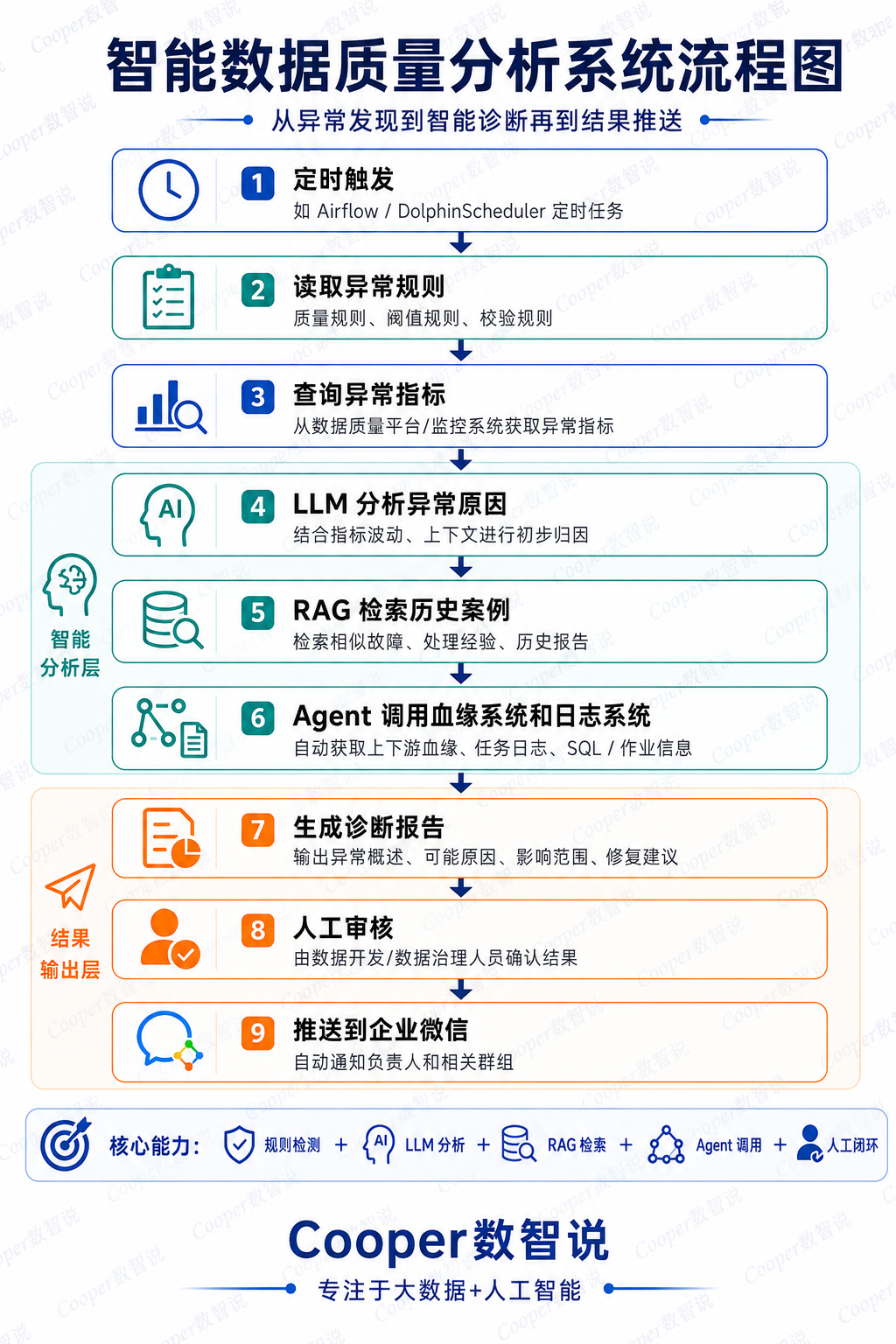
这里面既有固定流程,也有智能节点。
固定流程保证稳定性。
智能节点提升分析能力。
这才是更接近企业落地的 AI 应用架构。
六、它们之间到底是什么关系?
可以用一张分层图理解:
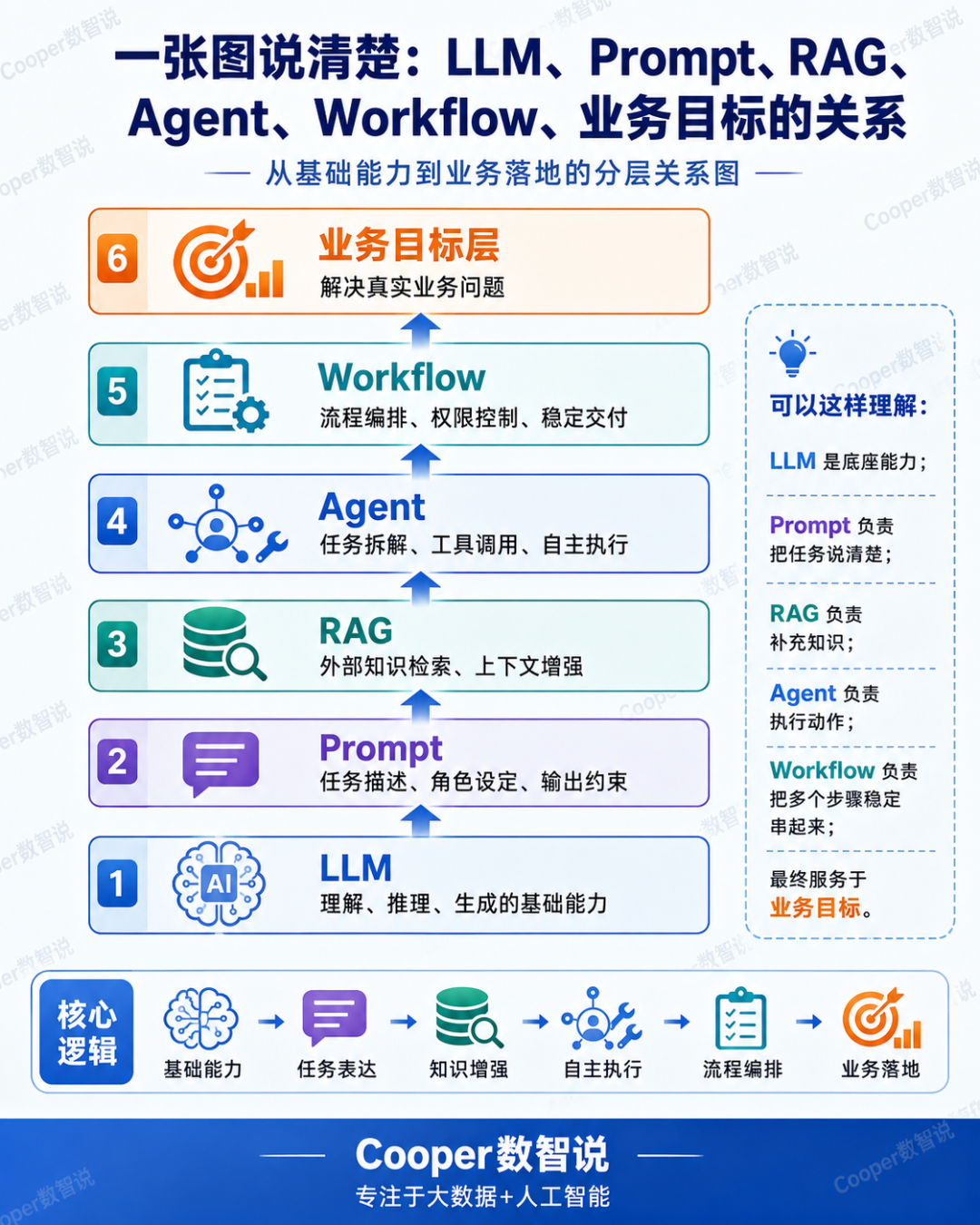
也可以从能力演进角度理解:
LLM:能理解和生成
Prompt:让它按你的要求生成
RAG:让它基于外部资料生成
Agent:让它会规划和调用工具
Workflow:让它在可控流程中稳定执行
更直白一点:
| 概念 | 解决的问题 | 像什么 | 典型作用 |
| LLM | 有没有智能能力 | 大脑 | 理解、推理、生成 |
| Prompt | 怎么指挥大脑 | 指令 | 设定角色、任务、格式 |
| RAG | 知识不够怎么办 | 资料库 | 检索企业知识、减少胡说 |
| Agent | 能不能自己做事 | 助理/员工 | 拆任务、调工具、执行 |
| Workflow | 怎么稳定上线 | 流程制度 | 编排、审核、权限、监控 |
七、用一个“公司员工”的比喻讲清楚
假设你开了一家公司,想招一个智能助理。
LLM 就像这个人的大脑。他会理解语言、写文章、分析问题。
Prompt 就像你给他的工作指令。你告诉他今天要做什么、以什么标准做、结果怎么交付。
RAG 就像公司的资料库。员工不能只靠脑子记,遇到制度、合同、产品文档,应该先查资料再回答。
Agent 就像一个有执行能力的助理。他不只是回答你,还能自己去查系统、拉数据、调用工具、生成报告。
Workflow 就像公司的流程制度。再聪明的员工,也不能想怎么干就怎么干。报销要审批,发公告要审核,改生产系统要走发布流程。
所以,一个成熟的 AI 应用不是“找一个最强模型就完事”,而是要回答:
- 这个模型怎么被指挥?
- 它依据哪些知识?
- 它能调用哪些工具?
- 哪些步骤可以自主?
- 哪些步骤必须审批?
- 出错后怎么追溯?
- 权限如何控制?
这些问题,才是 AI 应用从 Demo 走向生产系统的关键。
八、常见误区
误区一:Prompt 写得好,就能解决一切
Prompt 很重要,但它不能凭空创造真实数据。
如果问题需要企业内部知识、实时数据、业务规则,就必须接入外部知识和工具。
误区二:RAG 等于向量数据库
RAG 不是买一个向量库就完成了。
向量库只是组件,真正难的是文档治理、切片策略、召回排序、权限过滤、答案引用和评估体系。
误区三:Agent 越自主越好
企业系统里,自主不等于可靠。
对于高风险任务,Agent 应该被限制在明确权限和流程中执行。
比如删除数据、修改生产配置、发送正式通知,都应该有人审或有规则约束。
误区四:Workflow 太传统,不适合 AI
恰恰相反,Workflow 是 AI 生产化的重要基础。
没有 Workflow,AI 应用很容易停留在聊天机器人阶段。
有了 Workflow,AI 才能嵌入真实业务流程。
九、从大数据工程师视角看这套体系
如果你是大数据工程师,可以把这几个概念映射到熟悉的大数据体系里。
LLM 类似计算引擎,比如 Spark、Flink。
Prompt 类似作业配置和 SQL,决定你让计算引擎干什么。
RAG 类似外部数据源和维表关联,模型回答时需要查外部数据。
Agent 类似带调度、决策、执行能力的智能任务系统。
Workflow 类似 Airflow、DolphinScheduler、Azkaban、DataPipeline,负责编排任务依赖、重试、告警和治理。
所以 AI 应用工程化并不是完全陌生的东西。
它和大数据系统有很多相通之处:
- 都要处理数据输入
- 都要考虑任务编排
- 都要接入外部系统
- 都要做权限控制
- 都要做监控告警
- 都要做质量评估
- 都要从 Demo 走向生产稳定性
不同的是,大数据系统的核心是“数据计算”,AI 应用的核心是“语言理解 + 推理生成 + 工具执行”。
十、一个完整 AI 应用通常长什么样?
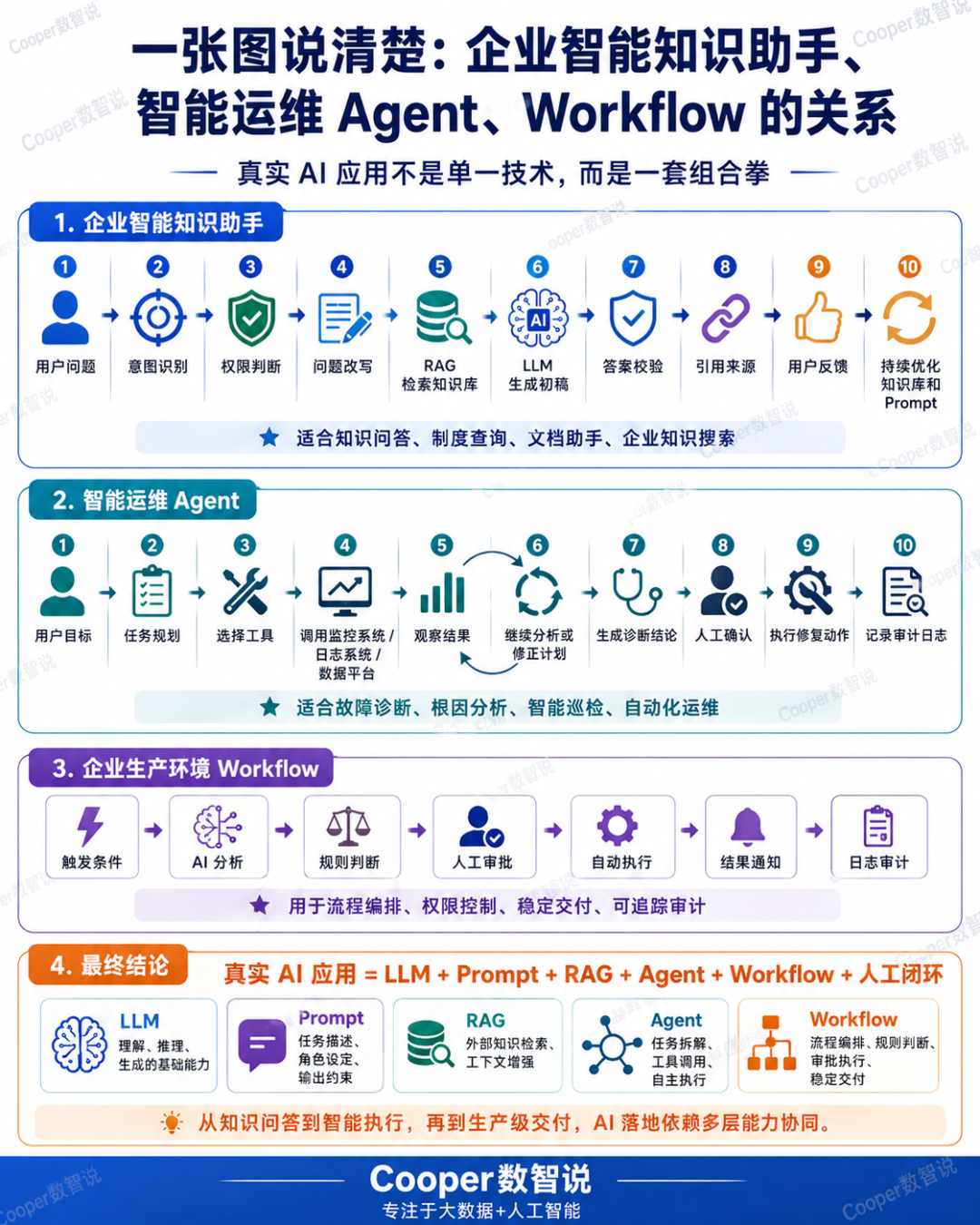
十一、怎么判断一个场景该用什么?
可以用下面这套判断方法。
只需要文字生成:用 LLM + Prompt
例如:
- 写周报
- 改简历
- 写文章
- 生成 SQL 模板
- 总结会议纪要
需要基于企业资料回答:用 RAG
例如:
- 公司制度问答
- 数据指标解释
- 产品文档问答
- 合同条款查询
- 运维知识库问答
需要调用工具完成任务:用 Agent
例如:
- 自动查日志
- 自动分析作业失败
- 自动生成数据报告
- 自动执行代码检查
- 自动创建工单
需要稳定、可控、可审计地落地:用 Workflow
例如:
- 智能审批
- 智能客服工单流转
- 数据质量异常处理
- 自动化运维修复
- 企业级 AI 办公流程
真正复杂的场景,一般是组合使用:
Workflow + Agent + RAG + Prompt + LLM
十二、未来趋势:不是 Agent 取代 Workflow,而是 Agentic Workflow
未来比较有价值的方向,不是单纯 Agent,也不是传统 Workflow,而是二者结合:
Agentic Workflow:带有智能决策能力的工作流。
它的特点是:
- 主流程可控
- 局部节点智能化
- 工具调用有权限
- 关键动作可审批
- 过程可观测
- 结果可评估
- 出错可回滚
比如在数据开发场景中:
传统 Workflow 只能按固定 DAG 执行任务。
Agentic Workflow 可以在任务失败后自动判断原因:
- 是上游数据延迟?
- 是字段变更?
- 是资源不足?
- 是 SQL 写法问题?
- 是 HDFS 权限问题?
然后给出不同处理策略。
这对于大数据工程师来说,是非常值得关注的方向。
因为未来很多数据平台、数据治理、数据开发、数据运维系统,都会逐步加入 AI Agent 能力。
结尾:AI 应用的关键不是“会聊天”,而是“能闭环”
Prompt、LLM、RAG、Agent、Workflow 的关系,可以总结成一句话:
LLM 提供智能,Prompt 驱动智能,RAG 补充知识,Agent 扩展行动,Workflow 保证闭环。
如果只是 LLM + Prompt,你得到的是一个会聊天的助手。
如果加上 RAG,你得到的是一个会查资料的助手。
如果加上 Agent,你得到的是一个会做事的助手。
如果再加上 Workflow,你才有机会得到一个能在企业里稳定运行的 AI 系统。
AI 应用真正的价值,不在于模型回答得多漂亮,而在于它能不能进入真实业务流程,解决真实问题,并且做到可靠、可控、可追溯。
这也是技术人接下来最值得投入的方向:
不是只学一个大模型名词,而是理解 AI 应用的完整工程体系。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献184条内容
已为社区贡献184条内容

所有评论(0)