AI面试必杀技!13个核心概念,让你面试官眼前一亮!
兄弟们好,今天有料。
面试前五分钟,手机里翻笔记翻到怀疑人生——Agent是啥?ReAct和反思有啥区别?MCP到底怎么解释?概念一个比一个绕,背了忘忘了背。
别慌。这篇我把大厂常问的 13 个 AI Agent 核心概念,按"怎么理解最快"的方式重新捋了一遍。不是给你堆定义,是帮你把整条线串起来,下次面试官问到任何一个点,你都能顺着上下游讲出体系感。
面试前五分钟,你慌了吗
说实话,AI Agent 这个领域的概念密度太高了。像没整理过的工具箱,扳手螺丝刀锤子堆一起,用的时候摸半天。
光是一个"让 AI 自己干活"的命题,就牵扯出规划、记忆、工具、协议、工程方法一大串。很多人的问题不是不知道这些词,是不知道它们之间的关系。
打个比方:这些概念就像一栋楼的各个楼层。地基是大模型本身(预训练、微调),一楼是让模型能动手(Agent、ReAct、工具调用),二楼是让它更聪明(RAG、记忆、防幻觉),三楼是标准化能力(MCP、Skill),顶楼是工程保障(Harness、SDD、反思机制)。
搞清楚楼层关系,单个概念自然就记住了。
接下来我们一层层拆。
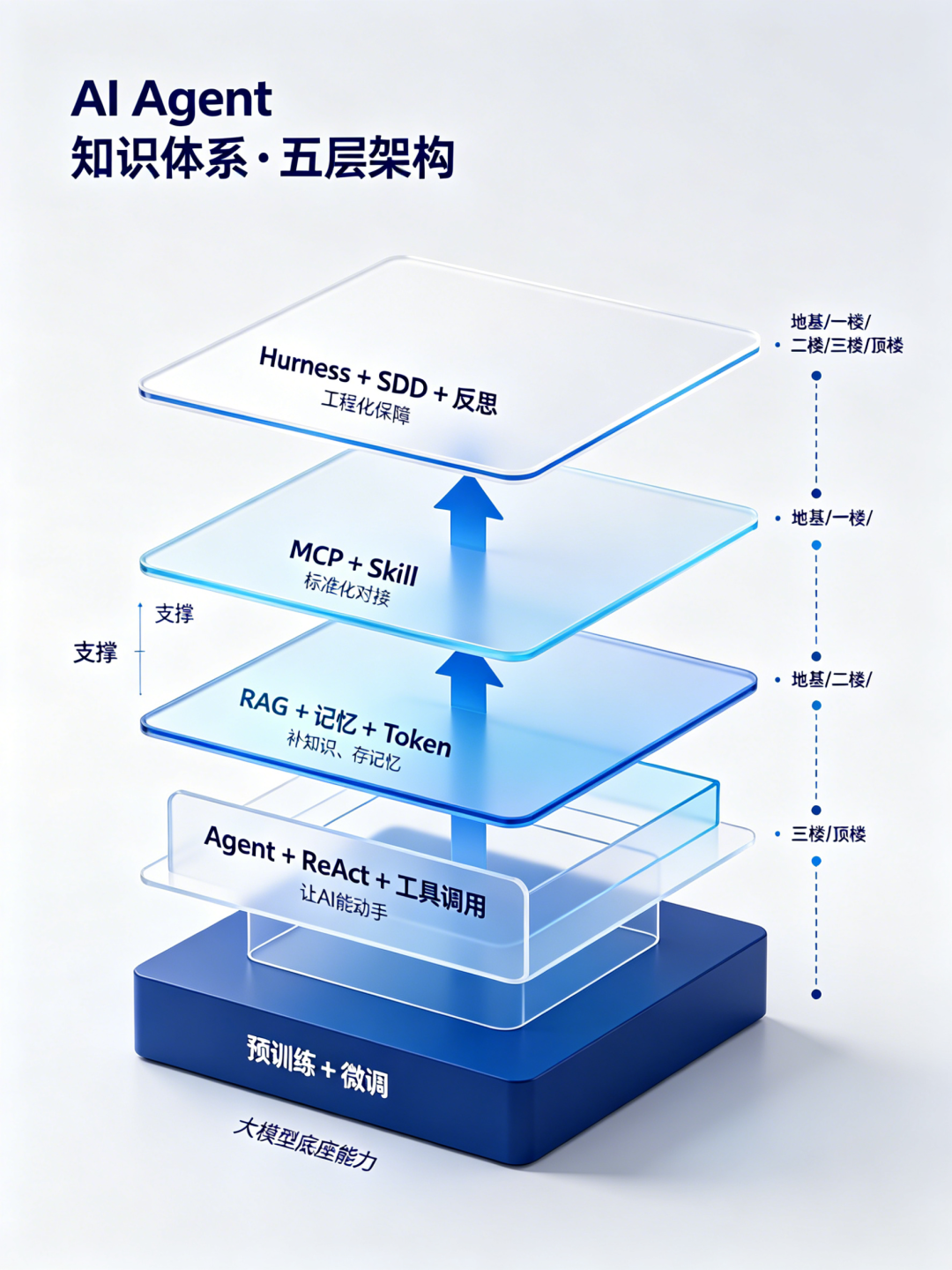
先从地基开始——大模型本身是怎么炼出来的。
底座先搞懂:预训练和微调到底干了啥
很多人面试被问"预训练和微调的区别",张嘴就是"预训练用大数据,微调用小数据"。没错,但太干了,面试官想听的是你理解这两步的目的差异。
预训练的本质是教语言。
想象一个小孩从零开始学说话——没人教语法,纯靠听。预训练干的就是这事:把海量文本喂给模型,让它学会"下一个字大概率是什么"。
训练方式是自监督学习,具体来说就是不断预测下一个 token。没有人工标注,不需要标准答案,纯靠统计规律。训练出来的东西叫基座模型,什么都会一点,但什么都不精。
跟小孩学完说话差不多。
微调的本质是教干活。
基座模型会说话了,但你让它帮你写代码、做客服、改文案,它可能东一句西一句。微调就是拿具体任务的数据,继续训练这个模型,让它学会"在这种场景下应该怎么回答"。
这步用的数据量小得多——几千到几万条标注数据就够。训练方式通常是监督学习,也就是有输入有标准输出,模型学着模仿。
一句话总结:预训练给能力,微调给方向。一个管"会不会说话",一个管"说话办不办事"。
面试时候把这个对比讲清楚,比背两段定义管用十倍。
让 AI 能动手的那套东西
学完说话、学完干活,下一步是什么?让它自己干活。
这就是 Agent 的核心命题。
Agent 不是一个工具,是一种工作方式。 它的特点是:能自己拆任务、自己决定下一步做什么、自己调用工具获取信息、自己判断结果对不对。
传统大模型像一个坐在那等你提问的答题机器。Agent 更像一个实习生——你说"帮我查一下上周的销售数据然后做个报表",它自己规划步骤,自己去查数据库,自己写 Excel,最后把结果交给你。
关键能力三件套:规划、记忆、工具调用。
但光有能力不够,还得有一套做事的方法论。这就是 ReAct。
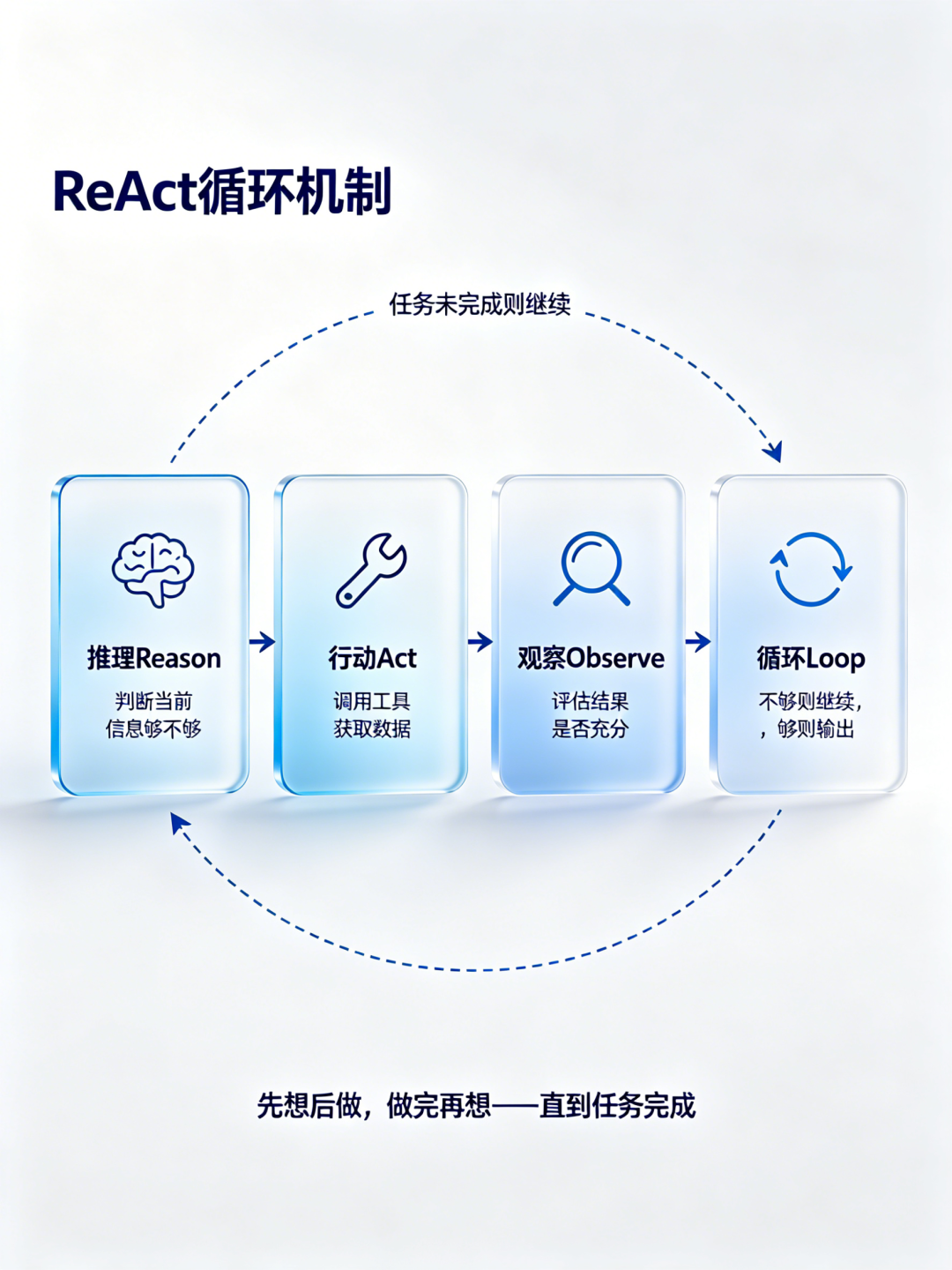
ReAct 的全称是 Reason + Act,推理加行动。听起来很学术,翻译成人话就是:先想后做,做完再想。
具体流程是这样的:模型接到任务,先推理"我现在知道什么、还缺什么",如果信息不够就调工具去拿,拿到结果后再推理"拿到的东西够不够解决问题",不够就继续调。周而复始,直到任务完成。
跟人干活一模一样——想清楚了再动手,动完手看看结果,不行再调整。
不过 ReAct 只管"做"的循环。做完以后怎么知道自己做得对不对?这就需要自我反思机制。
反思本质上是"先出答案,再检查,然后修改"。两种路径:
第一种是自我反馈——模型自己审查自己的输出。适合检查文案一致性、有没有违反约束、格式对不对这类能靠逻辑判断的事。
第二种是外部反馈——把结果放进真实环境验证。代码跑一下看报不报错,JSON 过一下 schema 验证,SQL 查询看返回结果对不对。
反思不是锦上添花,是质量兜底。 省了这步,输出质量全靠运气。
补知识、存记忆、防胡说
Agent 能干活了,但有三个实际问题得解决:
第一,它知识有限——模型训练时没见过你公司的内部文档。 第二,它记性差——聊着聊着就忘了前面说了啥。 第三,它爱编——模型会把自己没见过的东西编出一个"看起来对"的答案。
分别对应三个解法:RAG、记忆系统、Token 理解。
RAG 就是让模型开卷考试。
全称 Retrieval-Augmented Generation,检索增强生成。跟你查字典一个道理——不确定的词先翻一下再答题。模型回答问题之前,先去知识库里搜一轮相关资料,把搜到的内容塞进上下文,然后基于这些"参考答案"来回复。
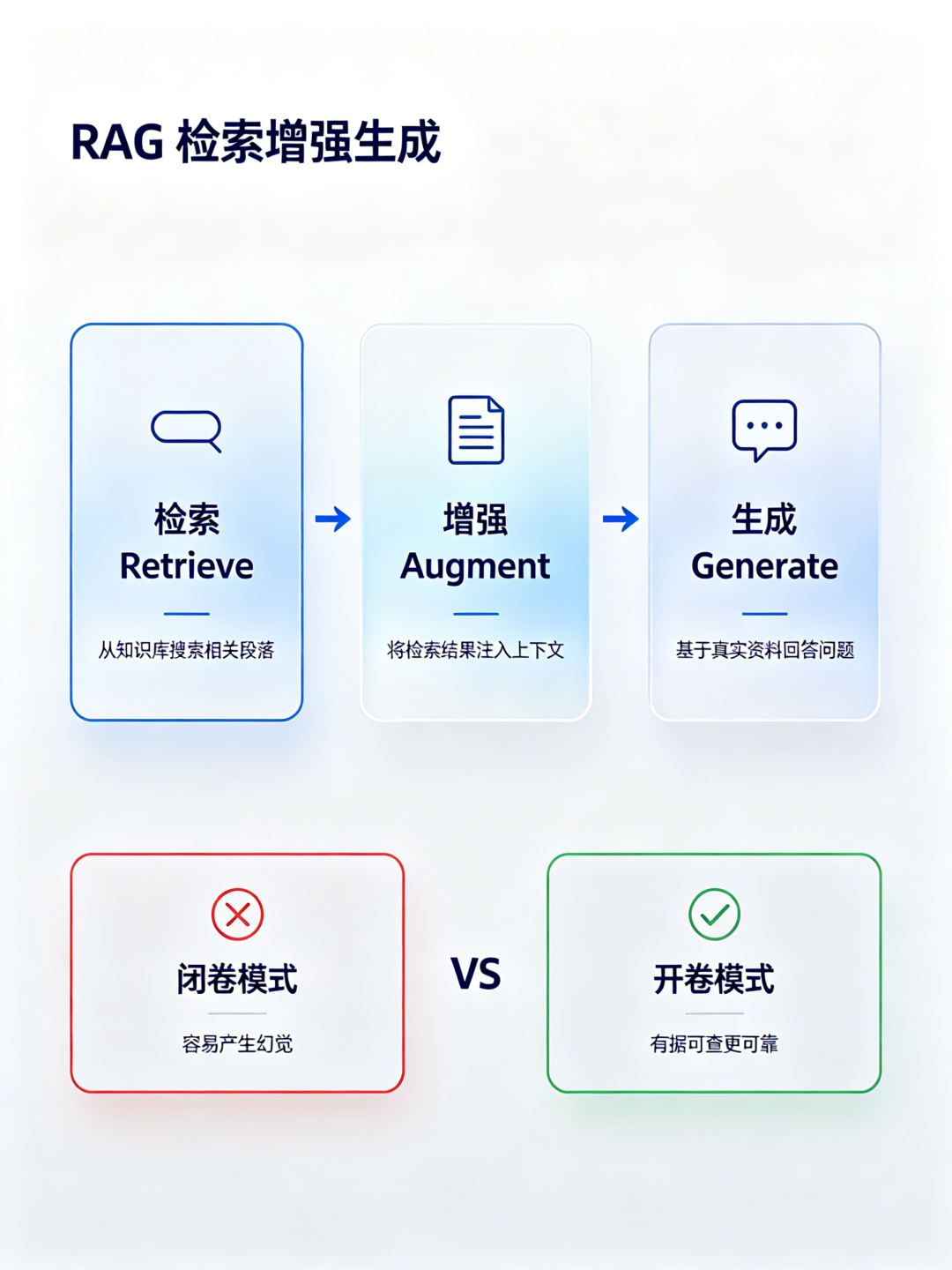
就像你考试可以带小抄——模型本身可能不知道公司上个月的运营数据,但只要把相关文档检索出来给它,它就能基于真实信息回答,而不是瞎编。
关于幻觉这件事要多说两句。
幻觉就是模型一本正经地胡说八道。 它不是不会回答,是会给你一个格式完美、逻辑通顺、但内容是编的答案。所以永远不要把大模型的输出当成事实来用,特别是涉及数字、日期、人名这些具体信息的时候。
RAG 能缓解幻觉,但不能完全消除。这是模型的底层特性,面试时要诚实讲。
再说记忆系统。
Agent 的记忆分两层,跟人的记忆是一回事:
短期记忆管当前对话——你跟它聊的这一轮。但上下文窗口有限,聊多了前面的内容会被挤掉。处理方式通常是截断旧消息或者做摘要压缩,保持 prompt 长度不爆。
长期记忆管跨会话——上次聊过什么、用户偏好是啥、历史决策记录。做法是把关键信息存成向量,下次需要的时候用语义检索召回,再塞回上下文里。
最后补一个底层概念:Token。
模型不认字,只认数字。Token 就是模型处理文本的最小单位。分词器把你输入的文字切成一个个小块(token),每块对应一个数字 ID,模型全程用这些 ID 来计算。
为什么面试要问这个?因为它直接影响成本和性能——输入越长 token 越多,价格越贵,速度越慢。理解 token 机制,才能理解为什么 prompt 要精简、为什么上下文窗口有上限。
接口标准和能力封装
到这里,模型能力有了、做事方法有了、知识补充和记忆也有了。下一个问题是:怎么让这些能力跟外部世界对接?
两个关键概念:MCP 和 Skill。
MCP 是 AI 世界的 TypeC 接口。 一根线通吃所有设备。
全称 Model Context Protocol,模型上下文协议。它定义了一套标准化的对接方式,让 AI 应用能连接各种外部数据源和工具——本地文件、数据库、搜索引擎、工作流系统,全走统一协议。
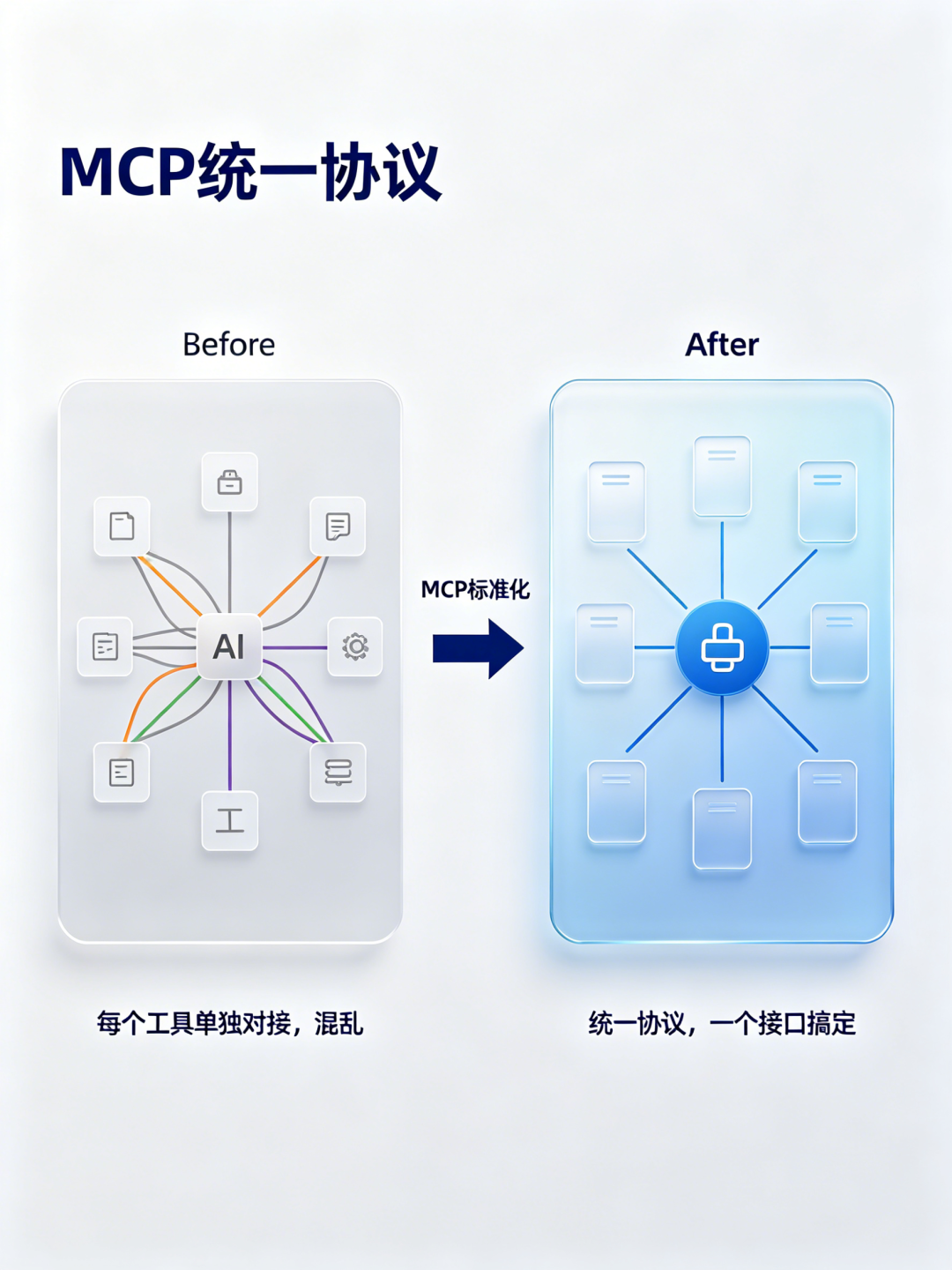
没有 MCP 之前,每接一个新工具就要写一套对接代码,跟手机充电线一样混乱——安卓一根、苹果一根、老诺基亚又一根。有了 MCP,所有工具方按同一个协议提供服务,AI 应用方按同一个协议去调用。一个协议搞定所有连接。
面试时讲 MCP,关键词是"标准化"和"解耦"。
Skill 是给模型装的技能包。
本质上是结构化的本地文件夹,里面打包了某个领域需要的一切:流程文档、知识材料、模板示例、脚本工具。模型遇到相关场景时自动或按需加载,相当于临时给它装上一个领域的专业知识和操作手册。
跟游戏里装备技能一回事——基础属性不变,但装备不同技能包就能应对不同副本。
工程化怎么落地
概念都懂了,最后一个问题:在真实项目里,Agent 怎么才能可靠地跑起来?
这是面试中区分"背概念"和"真做过"的分水岭。
三个工程方法得知道。
Harness 工程——给 AI 搭工作台。
直译是"驾驭工程"。核心思路是:不能把 Agent 像野马一样放出去,得给它围好栅栏。

具体包括:上下文怎么管理、工具怎么调用、执行环境怎么隔离、权限怎么控制、输出怎么验证、日志怎么记录、代码谁来 review、反馈怎么形成回路。
八个维度,缺一个都可能在生产环境翻车。跟连锁餐厅开店一样——菜单、食材、后厨、卫生、培训、巡检、客诉、复盘,漏一环就砸招牌。面试里能把这八点列出来并且每个举一两个实践细节,基本就过了这道题。
SDD——先写规格,再写代码。
全称 Spec-Driven Development,规格驱动开发。思路很直接:让 AI 写代码之前,先把需求、范围、行为约束、设计决策、任务拆分全写成文档。AI 按文档来开发,不自己猜。
不给规格让 AI 写代码,跟不给需求文档让实习生干活一样——他倒是能写出东西来,但大概率不是你想要的。
这步省了,后面返工时间翻三倍。
真要选工程方法优先级,我会把 SDD 排第一。因为它从源头减少歧义,后面所有环节的质量上限都被它决定。
最后是反思机制在工程中的落地——就是前面讲的自我反思,但在工程层面要设计成流程的一部分,而不是"有时候模型自己会检查"。
好的 Agent 系统,每次输出后都会走一轮校验:代码跑测试、文案查约束、数据核对来源。这不是可选步骤,是流水线里的必经质检站。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

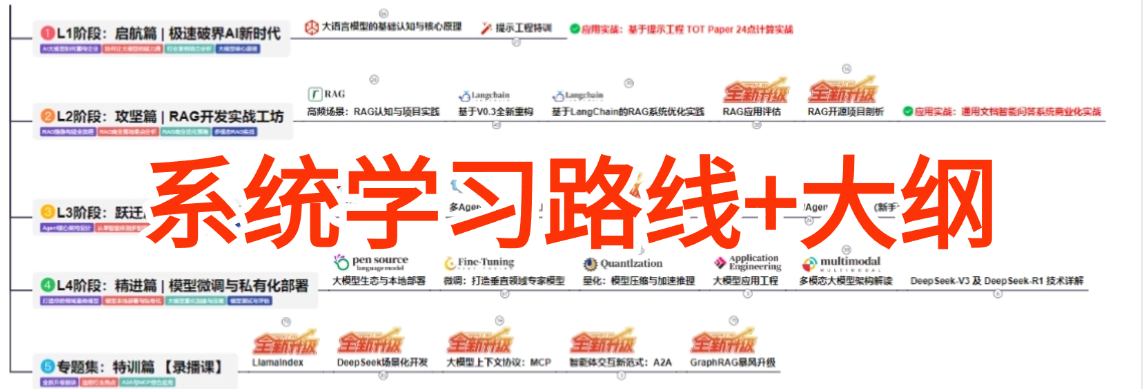
② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献173条内容
已为社区贡献173条内容

所有评论(0)