AI Infra 硬件体系与编程模型:10. CUDA编程基础语法:三种基本函数
在上一篇文章中,我们深入了解了NVCC编译系统的工作原理,知道了CUDA代码会被分离为主机代码和设备代码分别编译。今天,我们将聚焦CUDA编程最核心的概念——核函数(Kernel Function)、设备函数 (Device Function) 和 主机函数 (Host Function),彻底搞懂__global__、__device__、__host__这三个神秘的关键字,以及每个CUDA开发者每天都在写的<<<x, y>>>语法到底是什么意思。
一、CUDA编程三类函数,GPU并行计算的入口
以下三类函数是CUDA编程的基石,它是运行在 CPU 或 GPU 上的并行函数。当我们在CPU代码中调用一个核函数时,它会在GPU上启动成千上万个线程同时执行,这就是CUDA能够实现超高性能的根本原因。
这三个概念主要出现在GPU编程(如CUDA或OpenCL)的上下文中,用于区分代码运行的位置。
1.1 核函数 (Kernel Function)
- 运行位置:设备端(GPU)。
- 作用:它是被主机调用的入口函数,当你在代码中调用核函数时,GPU会启动成千上万个线程并行执行这个函数。它不能直接返回数据给主机,通常通过指针参数传递结果。
- 关键词:
__global__(CUDA中)。
1.2 设备函数 (Device Function)
- 运行位置:设备端(GPU)。
- 作用:它只能在核函数内部被调用,不能从主机调用。通常用于封装GPU上重复执行的逻辑(如数学计算、数据转换),帮助简化核函数代码。
- 关键词:
__device__。
1.3 主机函数 (Host Function)
- 运行位置:主机端(CPU)。
- 作用:就是普通的C/C++函数。它负责准备数据、调用核函数、从GPU拷回结果。不能直接在主机函数里调用设备函数。
- 关键词:
__host__(有时可省略)。
一个生活化的比喻
把CPU(主机)想象成项目经理,GPU(设备)想象成1000个工人。
- 主机函数:项目经理做的事(分配任务、记录结果、开会)。
- 核函数:项目经理吹哨子喊的那句话:“所有人开始搬砖!” → 这句话一下达,1000个工人同时开工。
- 设备函数:工人内部的一个小工具(比如一个“砌墙”的动作)。它只在工人干活时被使用,项目经理不会直接操作这个工具。
快速对比表
| 特性 | 核函数 (Kernel) | 设备函数 (Device) | 主机函数 (Host) |
|---|---|---|---|
| 运行硬件 | GPU | GPU | CPU |
| 能否被CPU调用 | ✅ 可以 (是唯一入口) | ❌ 不可以 | ✅ 可以 |
| 能否被GPU调用 | ❌ 不可以 | ✅ 可以 | ❌ 不可以 |
| 典型用途 | 大规模并行任务入口 | 被核函数调用的子函数 | 主流程、逻辑控制 |
总结记忆:
- 主机函数 = CPU做的
- 核函数 = 让GPU开始工作的那一个入口
- 设备函数 = GPU内部调用的辅助小函数
二、三类函数修饰符:global、device、host
CUDA引入了三个特殊的函数修饰符,用来明确指定一个函数应该在哪里编译、在哪里调用、在哪里执行。这是CUDA对标准C++最核心的扩展之一。
2.1 global:核函数修饰符
__global__是我们最常用的修饰符,它用来定义核函数。
核心特性
- 编译位置:同时编译为主机端存根和设备端代码
- 调用者:只能从主机(CPU)调用(CUDA动态并行除外)
- 执行者:只能在设备(GPU)上执行
- 返回值:必须是
void - 执行方式:异步执行,主机调用后立即返回
代码示例
// 定义一个核函数:将两个向量相加
__global__ void vectorAdd(const float* a, const float* b, float* c, int n) {
// 计算当前线程的全局索引
int i = blockIdx.x * blockDim.x + threadIdx.x;
// 每个线程处理一个元素
if (i < n) {
c[i] = a[i] + b[i];
}
}
int main() {
// ... 省略内存分配和数据传输代码 ...
// 调用核函数:启动1个块,每个块256个线程
vectorAdd<<<1, 256>>>(d_a, d_b, d_c, n);
// 等待核函数执行完成
cudaDeviceSynchronize();
// ... 省略结果验证和内存释放代码 ...
return 0;
}
重要说明
__global__函数不能有返回值,因为GPU上的成千上万个线程同时执行,无法返回一个统一的结果。如果需要返回数据,必须通过指针参数写入设备内存。- 核函数的执行是异步的,所以在主机上读取结果之前,必须调用
cudaDeviceSynchronize()等待所有线程执行完成。 - 传递给核函数的参数必须是POD(Plain Old Data)类型,或者是指向设备内存的指针。绝对不能传递指向主机内存的指针给核函数,否则会导致非法内存访问错误。
2.2 device:设备函数修饰符
__device__用来定义设备函数,也就是只能在GPU上调用和执行的函数。它就像GPU上的普通C++函数,用来封装核函数中重复使用的代码逻辑。
核心特性
- 编译位置:只编译为设备端代码
- 调用者:只能从**设备(GPU)**调用(可以是
__global__函数或其他__device__函数) - 执行者:只能在**设备(GPU)**上执行
- 返回值:可以有任意类型的返回值
- 执行方式:同步执行,和普通函数调用一样
代码示例
// 定义一个设备函数:计算两个数的平方和
__device__ float squareSum(float x, float y) {
return x * x + y * y;
}
// 在核函数中调用设备函数
__global__ void vectorNorm(const float* x, const float* y, float* result, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
result[i] = sqrt(squareSum(x[i], y[i]));
}
}
重要说明
__device__函数是GPU代码复用的主要方式,它可以被核函数或其他设备函数调用。- 设备函数支持递归调用(从计算能力2.0开始),但不推荐使用,因为GPU的栈空间非常有限。
- 设备函数默认是内联的,编译器会尽可能将其展开到调用者中,以减少函数调用开销。
2.3 host:主机函数修饰符
__host__用来定义主机函数,也就是只能在CPU上调用和执行的函数。它和标准C++函数完全一样,实际上,如果你不写任何修饰符,CUDA编译器会默认将函数视为__host__函数。
核心特性
- 编译位置:只编译为主机端代码
- 调用者:只能从主机(CPU)调用
- 执行者:只能在主机(CPU)上执行
- 返回值:可以有任意类型的返回值
- 执行方式:同步执行
代码示例
// 定义一个主机函数:初始化向量
__host__ void initVector(float* vec, int n) {
for (int i = 0; i < n; i++) {
vec[i] = static_cast<float>(rand()) / RAND_MAX;
}
}
int main() {
float* h_a = new float[1024];
initVector(h_a, 1024); // 在主机上调用主机函数
// ...
return 0;
}
2.4 组合修饰符:host device
这是一个非常有用的组合修饰符,它告诉NVCC编译器:同时为这个函数生成主机端和设备端两个版本的代码。这样,同一个函数就可以既在CPU上调用,也在GPU上调用,极大地减少了代码重复。
代码示例
// 定义一个同时可以在主机和设备上运行的函数
__host__ __device__ float clamp(float x, float min_val, float max_val) {
if (x < min_val) return min_val;
if (x > max_val) return max_val;
return x;
}
// 在主机上调用
int main() {
float x = 1.5f;
float y = clamp(x, 0.0f, 1.0f); // y = 1.0f
// ...
}
// 在设备上调用
__global__ void processImage(float* pixels, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
pixels[i] = clamp(pixels[i], 0.0f, 1.0f);
}
}
重要说明
- 使用
__host__ __device__修饰符时,函数中不能包含任何只能在主机或只能在设备上执行的代码。 - 编译器会自动生成两个版本的函数,一个给主机编译器,一个给设备编译器。
- 这是编写通用数学函数和工具函数的最佳方式,可以避免代码重复。
2.5 三类修饰符对比总结
为了方便记忆,我整理了一个对比表格:
| 修饰符 | 编译位置 | 调用者 | 执行者 | 返回值 | 执行方式 | 主要用途 |
|---|---|---|---|---|---|---|
__global__ |
主机+设备 | 主机 | 设备 | 必须是void | 异步 | 定义核函数,GPU并行入口 |
__device__ |
仅设备 | 设备 | 设备 | 任意 | 同步 | 封装GPU上的通用逻辑 |
__host__ |
仅主机 | 主机 | 主机 | 任意 | 同步 | 标准C++函数(默认) |
__host__ __device__ |
主机+设备 | 主机或设备 | 主机或设备 | 任意 | 同步 | 通用工具函数,减少代码重复 |
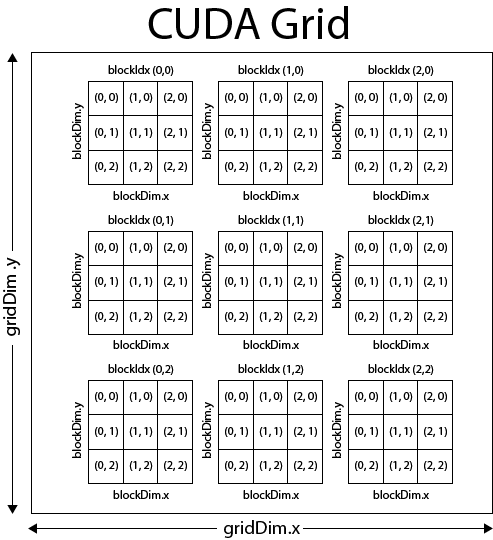
三、<<<gridDim, blockDim>>>语法:CUDA线程的组织方式
现在我们来讲解CUDA中最独特、也最容易让人困惑的语法:<<<gridDim, blockDim>>>。这不是什么魔法,它只是CUDA用来指定核函数启动时需要创建多少个线程,以及这些线程如何组织的语法。
3.1 CUDA的线程层次结构
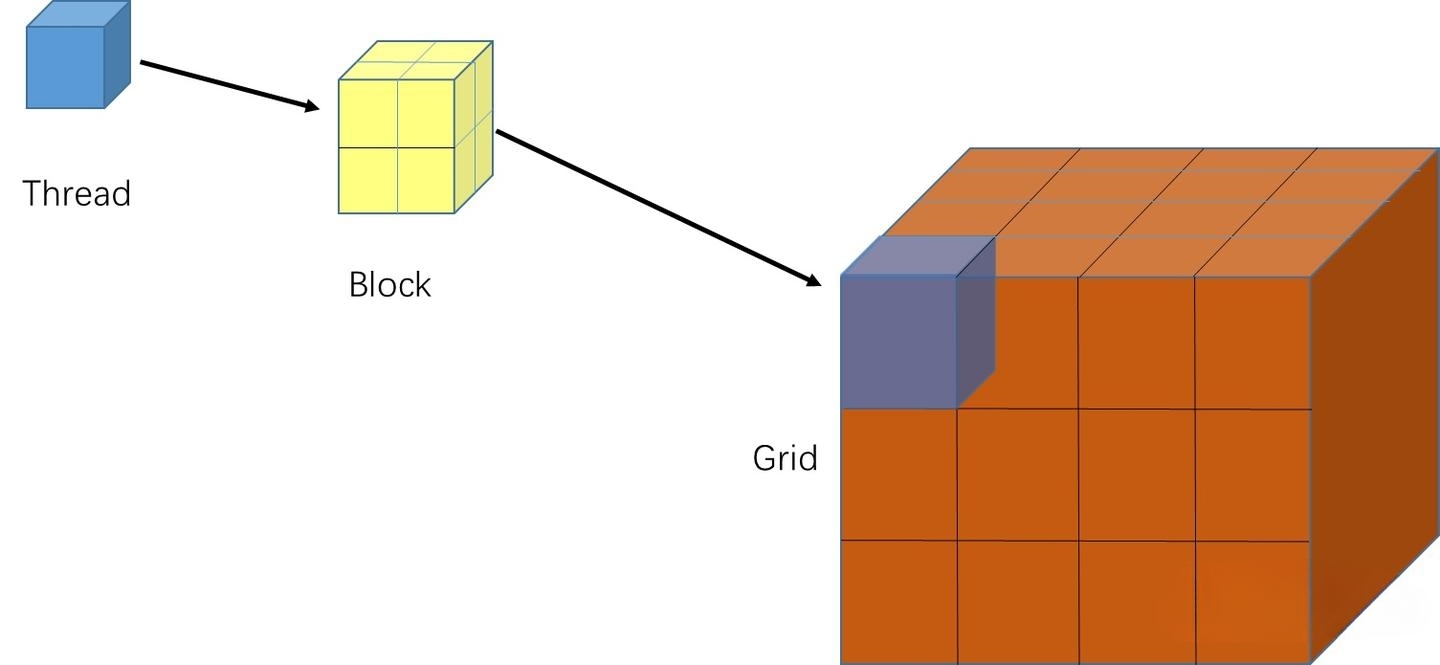
GPU的线程不是杂乱无章地组织的,而是按照三级层次结构来管理的:线程(Thread)→ 线程块(Block)→ 网格(Grid)。

- 线程(Thread):最小的执行单元,每个线程执行核函数的一份拷贝
- 线程块(Block):一组可以相互通信的线程,共享同一个线程块内的共享内存
- 网格(Grid):所有参与同一个核函数调用的线程块的集合
这种层次结构设计是为了匹配GPU的硬件架构:一个GPU包含多个流式多处理器(SM),每个SM可以同时运行多个线程块,每个线程块包含多个线程。
3.2 <<<>>>语法的完整形式
<<<>>>语法的完整形式其实有四个参数:
kernelName<<<gridDim, blockDim, sharedMemSize, stream>>>();
我们来逐一解释每个参数:
1. gridDim:网格维度
- 类型:
dim3(CUDA内置的三维整数类型,默认值为(1, 1, 1)) - 含义:指定网格中包含多少个线程块,以及这些线程块如何组织
- 示例:
dim3(10):1维网格,包含10个线程块dim3(10, 10):2维网格,包含10×10=100个线程块dim3(10, 10, 10):3维网格,包含10×10×10=1000个线程块
2. blockDim:线程块维度
- 类型:
dim3(默认值为(1, 1, 1)) - 含义:指定每个线程块中包含多少个线程,以及这些线程如何组织
- 示例:
dim3(256):1维线程块,每个块包含256个线程dim3(16, 16):2维线程块,每个块包含16×16=256个线程dim3(8, 8, 4):3维线程块,每个块包含8×8×4=256个线程
3. sharedMemSize:共享内存大小(可选)
- 类型:
size_t(默认值为0) - 含义:指定每个线程块可以使用的动态共享内存的大小,单位是字节
- 示例:
<<<grid, block, 1024>>>:每个线程块分配1KB的动态共享内存
4. stream:CUDA流(可选)
- 类型:
cudaStream_t(默认值为0,即默认流) - 含义:指定核函数在哪个CUDA流上执行,用于实现异步执行和计算与数据传输的重叠
补充: dim3 数据类型说明
dim3 是 CUDA 中一个非常重要的内置数据类型,它本质上是一个包含 3 个无符号整数的简单结构体,专门用于指定网格和线程块的维度。
dim3 的定义大致如下(简化版):
struct dim3 {
unsigned int x; // X 维度大小
unsigned int y; // Y 维度大小
unsigned int z; // Z 维度大小
// 构造函数
dim3(unsigned int vx = 1, unsigned int vy = 1, unsigned int vz = 1)
: x(vx), y(vy), z(vz) {}
dim3() : x(1), y(1), z(1) {}
};
关键特性:
- 包含 x、y、z 三个成员,默认值均为 1
- 所有成员是 unsigned int 类型(非负整数)
- 未指定的维度自动设为 1
主要用途
dim3 专门用于两个场景:
| 用途 | 对应内核启动参数 |
|---|---|
| 定义网格大小 | <<<gridDim, blockDim>>> 中的第一个参数 |
| 定义线程块大小 | <<<gridDim, blockDim>>> 中的第二个参数 |
一维配置(最简形式)
// 方式1:直接使用整数(自动转换为 dim3)
kernel<<<10, 256>>>();
// 等价于:grid(10,1,1), block(256,1,1)
// 方式2:显式使用 dim3(少见)
dim3 grid(10); // grid(10, 1, 1)
dim3 block(256); // block(256, 1, 1)
kernel<<<grid, block>>>();
二维配置(最常见)
dim3 threadsPerBlock(16, 16); // 16×16 = 256 线程/块
dim3 numBlocks(32, 32); // 32×32 = 1024 个块
kernel<<<numBlocks, threadsPerBlock>>>();
// 总共线程数 = 1024 × 256 = 262,144
三维配置(体积数据)
dim3 threadsPerBlock(8, 8, 8); // 8×8×8 = 512 线程/块
dim3 numBlocks(16, 16, 16); // 16×16×16 = 4096 个块
kernel<<<numBlocks, threadsPerBlock>>>();
// 总共线程数 = 4096 × 512 = 2,097,152
3.3 线程索引的计算
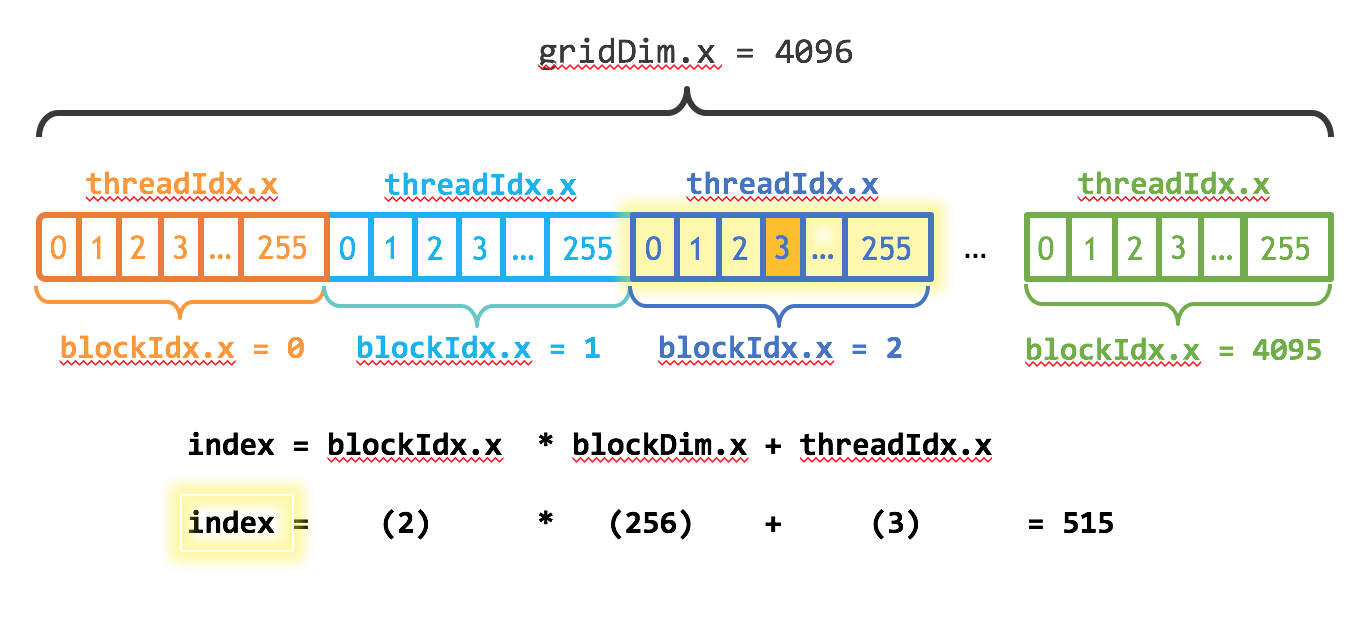
在核函数内部,我们可以通过四个内置变量来获取当前线程的位置信息:
threadIdx:线程在块内的索引(dim3类型)blockIdx:线程块在网格内的索引(dim3类型)blockDim:线程块的大小(dim3类型)gridDim:网格的大小(dim3类型)
1维线程索引计算(最常用)
__global__ void kernel(int n) {
// 计算当前线程的全局唯一索引
int i = blockIdx.x * blockDim.x + threadIdx.x;
// 确保索引不越界
if (i < n) {
// 处理第i个元素
}
}
// 调用方式:每个块256个线程,总共有n个元素
int blockSize = 256;
int gridSize = (n + blockSize - 1) / blockSize; // 向上取整
kernel<<<gridSize, blockSize>>>(n);
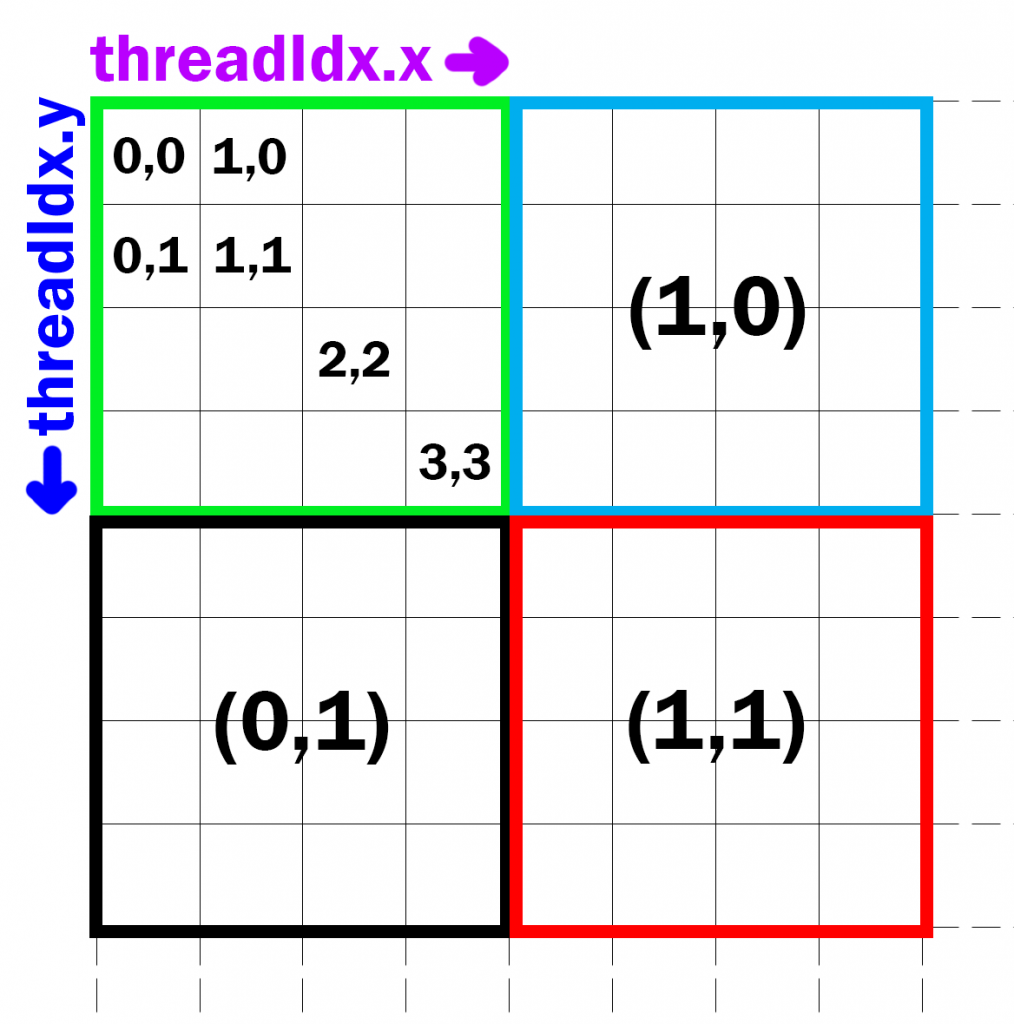
2维线程索引计算(常用于图像处理)
__global__ void imageKernel(float* pixels, int width, int height) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
int idx = y * width + x;
pixels[idx] = ...; // 处理像素(x, y)
}
}
// 调用方式:每个块16×16个线程
dim3 blockSize(16, 16);
dim3 gridSize((width + blockSize.x - 1) / blockSize.x,
(height + blockSize.y - 1) / blockSize.y);
imageKernel<<<gridSize, blockSize>>>(pixels, width, height);
3.4 线程块大小的最佳实践
线程块的大小对核函数的性能有非常大的影响,以下是一些经过验证的最佳实践:
- 总是使用32的倍数:GPU的基本执行单元是** warp( warp大小为32)**,所以线程块大小必须是32的倍数,否则会有部分warp没有被填满,造成资源浪费。
- 常用大小:256、512、1024是最常用的线程块大小。1024是从计算能力2.0开始每个线程块的最大线程数。
- 避免过小的块:小于64个线程的块通常效率不高,因为无法充分利用SM的资源。
- 根据寄存器使用调整:如果核函数使用了大量寄存器,可能需要减小线程块大小,以避免寄存器溢出到本地内存。
四、核函数的完整执行流程
现在我们把前面讲的内容串联起来,看看一个核函数从调用到执行完成的完整流程:
- 主机调用核函数:在CPU代码中,使用
<<<gridDim, blockDim>>>语法调用__global__函数。 - CUDA运行时处理:CUDA运行时库会验证参数,然后将核函数启动命令发送到GPU。
- GPU分配资源:GPU的调度器会将线程块分配到空闲的SM上。
- 线程块执行:每个SM将线程块划分为warp,以warp为单位执行指令。
- 主机继续执行:核函数启动后,主机代码会立即继续执行,不会等待核函数完成。
- 主机同步:当主机需要核函数的执行结果时,调用
cudaDeviceSynchronize()等待所有线程执行完成。
五、常见误区与最佳实践
5.1 常见误区
-
忘记同步:调用核函数后立即在主机上读取结果,导致得到未计算完成的数据。
// 错误示例 vectorAdd<<<grid, block>>>(d_a, d_b, d_c, n); // 没有调用cudaDeviceSynchronize() cudaMemcpy(h_c, d_c, n*sizeof(float), cudaMemcpyDeviceToHost); // 可能得到错误结果 // 正确示例 vectorAdd<<<grid, block>>>(d_a, d_b, d_c, n); cudaDeviceSynchronize(); // 等待核函数执行完成 cudaMemcpy(h_c, d_c, n*sizeof(float), cudaMemcpyDeviceToHost); -
传递主机指针给核函数:核函数只能访问设备内存,传递主机指针会导致非法内存访问错误。
// 错误示例 float h_a[1024], h_b[1024], h_c[1024]; vectorAdd<<<grid, block>>>(h_a, h_b, h_c, 1024); // 传递主机指针,程序崩溃 // 正确示例 float *d_a, *d_b, *d_c; cudaMalloc(&d_a, 1024*sizeof(float)); cudaMalloc(&d_b, 1024*sizeof(float)); cudaMalloc(&d_c, 1024*sizeof(float)); vectorAdd<<<grid, block>>>(d_a, d_b, d_c, 1024); -
线程索引越界:没有检查线程索引是否小于数据大小,导致访问越界内存。
// 错误示例 __global__ void vectorAdd(const float* a, const float* b, float* c, int n) { int i = blockIdx.x * blockDim.x + threadIdx.x; c[i] = a[i] + b[i]; // 当i >= n时,访问越界 } // 正确示例 __global__ void vectorAdd(const float* a, const float* b, float* c, int n) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < n) { // 检查索引是否有效 c[i] = a[i] + b[i]; } } -
核函数有返回值:
__global__函数必须返回void,不能有返回值。// 错误示例 __global__ int add(int a, int b) { return a + b; // 编译错误 } // 正确示例 __global__ void add(int a, int b, int* result) { *result = a + b; }
5.2 最佳实践
- 使用
__host__ __device__编写通用函数:对于数学工具函数等通用逻辑,使用组合修饰符可以避免代码重复。 - 合理组织线程块大小:使用256或512作为默认的线程块大小,根据性能测试进行调整。
- 总是检查CUDA错误:在每个CUDA调用后检查错误,包括核函数调用。
- 避免在核函数中使用动态内存分配:
malloc和new在设备上非常慢,而且容易导致内存碎片。 - 保持核函数简洁:每个核函数只做一件事,复杂的逻辑拆分为多个核函数。
六、实战
6.1 向量加法
#include <stdio.h>
#include <cuda_runtime.h>
// 错误检查宏,便于调试
#define CUDA_CHECK(call) \
do { \
cudaError_t error = call; \
if (error != cudaSuccess) { \
printf("CUDA error at %s:%d - %s\n", __FILE__, __LINE__, \
cudaGetErrorString(error)); \
exit(1); \
} \
} while(0)
// 向量加法内核函数
// 每个线程负责计算一个元素:C[i] = A[i] + B[i]
__global__ void vectorAdd(const float* A, const float* B, float* C, int N)
{
// 计算当前线程对应的全局索引
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// 边界检查,防止越界(当 N 不是 blockSize 的整数倍时)
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
int main()
{
// ==================== 1. 设置问题规模 ====================
int N = 1000000; // 100 万个元素
size_t bytes = N * sizeof(float);
printf("Vector size: %d elements\n", N);
printf("Memory required: %.2f MB\n", bytes / (1024.0 * 1024.0));
// ==================== 2. 分配主机内存并初始化 ====================
float *h_A = (float*)malloc(bytes);
float *h_B = (float*)malloc(bytes);
float *h_C = (float*)malloc(bytes);
if (h_A == NULL || h_B == NULL || h_C == NULL) {
printf("Host memory allocation failed!\n");
return 1;
}
// 初始化主机数组 A 和 B
for (int i = 0; i < N; i++) {
h_A[i] = 1.0f; // A 全为 1
h_B[i] = 2.0f; // B 全为 2
}
// ==================== 3. 分配设备内存 ====================
float *d_A, *d_B, *d_C;
CUDA_CHECK(cudaMalloc(&d_A, bytes));
CUDA_CHECK(cudaMalloc(&d_B, bytes));
CUDA_CHECK(cudaMalloc(&d_C, bytes));
printf("Device memory allocated successfully\n");
// ==================== 4. 将数据从主机拷贝到设备 ====================
CUDA_CHECK(cudaMemcpy(d_A, h_A, bytes, cudaMemcpyHostToDevice));
CUDA_CHECK(cudaMemcpy(d_B, h_B, bytes, cudaMemcpyHostToDevice));
printf("Data copied to device\n");
// ==================== 5. 配置内核启动参数 ====================
int threadsPerBlock = 256; // 每个线程块的线程数(通常是 256 或 512)
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock; // 向上取整
printf("Launching kernel with %d blocks of %d threads each\n",
blocksPerGrid, threadsPerBlock);
printf("Total threads: %d\n", blocksPerGrid * threadsPerBlock);
// ==================== 6. 启动内核 ====================
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// 检查内核启动是否成功
CUDA_CHECK(cudaGetLastError());
// 等待 GPU 完成计算
CUDA_CHECK(cudaDeviceSynchronize());
printf("Kernel execution completed\n");
// ==================== 7. 将结果从设备拷贝回主机 ====================
CUDA_CHECK(cudaMemcpy(h_C, d_C, bytes, cudaMemcpyDeviceToHost));
// ==================== 8. 验证结果 ====================
int correct = 1;
for (int i = 0; i < N; i++) {
float expected = h_A[i] + h_B[i]; // 3.0f
if (h_C[i] != expected) {
printf("Error at index %d: %f != %f\n", i, h_C[i], expected);
correct = 0;
break;
}
}
if (correct) {
printf("Result verification: PASSED (all %d elements correct)\n", N);
printf("Example: C[0] = %f + %f = %f\n", h_A[0], h_B[0], h_C[0]);
} else {
printf("Result verification: FAILED\n");
}
// ==================== 9. 清理资源 ====================
// 释放设备内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// 释放主机内存
free(h_A);
free(h_B);
free(h_C);
printf("Resources cleaned up\n");
return 0;
}
ubuntu@ubuntu:~/MyProject/MyCuda$ nvcc -o vectorAdd vectorAdd.cu
ubuntu@ubuntu:~/MyProject/MyCuda$ ./vectorAdd
Vector size: 100000000 elements
Memory required: 381.47 MB
Device memory allocated successfully
Data copied to device
Launching kernel with 390625 blocks of 256 threads each
Total threads: 100000000
Kernel execution completed
Result verification: PASSED (all 100000000 elements correct)
Example: C[0] = 1.000000 + 2.000000 = 3.000000
Resources cleaned up
6.2 矩阵加法
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
// 错误检查宏
#define CUDA_CHECK(call) \
do { \
cudaError_t error = call; \
if (error != cudaSuccess) { \
printf("CUDA error at %s:%d - %s\n", __FILE__, __LINE__, \
cudaGetErrorString(error)); \
exit(1); \
} \
} while(0)
// 矩阵结构体(行优先存储)
typedef struct {
int width; // 列数
int height; // 行数
float* elements;
} Matrix;
// 矩阵加法内核函数
// 每个线程负责计算一个元素:C[i][j] = A[i][j] + B[i][j]
__global__ void matrixAdd(const Matrix A, const Matrix B, Matrix C)
{
// 计算当前线程对应的全局行列索引
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
// 边界检查
if (row < C.height && col < C.width) {
// 行优先存储:index = row * width + col
int idx = row * C.width + col;
C.elements[idx] = A.elements[idx] + B.elements[idx];
}
}
// 初始化矩阵(随机值或固定值)
void initMatrix(Matrix* mat, int height, int width, float value)
{
mat->height = height;
mat->width = width;
size_t size = height * width * sizeof(float);
// 分配主机内存
mat->elements = (float*)malloc(size);
if (mat->elements == NULL) {
printf("Host memory allocation failed!\n");
exit(1);
}
// 初始化所有元素为指定值
for (int i = 0; i < height * width; i++) {
mat->elements[i] = value;
}
}
// 打印矩阵(仅适用于小矩阵)
void printMatrix(const Matrix mat, const char* name)
{
printf("%s (%d x %d):\n", name, mat.height, mat.width);
for (int i = 0; i < mat.height; i++) {
for (int j = 0; j < mat.width; j++) {
printf("%8.2f ", mat.elements[i * mat.width + j]);
}
printf("\n");
}
printf("\n");
}
// 验证矩阵加法结果
int verifyResult(const Matrix hostC, const Matrix hostA, const Matrix hostB)
{
for (int i = 0; i < hostC.height * hostC.width; i++) {
float expected = hostA.elements[i] + hostB.elements[i];
if (hostC.elements[i] != expected) {
printf("Verification failed at index %d: %f + %f = %f, got %f\n",
i, hostA.elements[i], hostB.elements[i],
expected, hostC.elements[i]);
return 0;
}
}
return 1;
}
int main()
{
// ==================== 1. 设置矩阵维度 ====================
int height = 1024; // 矩阵行数
int width = 1024; // 矩阵列数
size_t bytes = height * width * sizeof(float);
printf("Matrix dimensions: %d x %d\n", height, width);
printf("Total elements: %d\n", height * width);
printf("Memory per matrix: %.2f MB\n", bytes / (1024.0 * 1024.0));
// ==================== 2. 分配并初始化主机矩阵 ====================
Matrix h_A, h_B, h_C;
initMatrix(&h_A, height, width, 1.0f); // A 全为 1
initMatrix(&h_B, height, width, 2.0f); // B 全为 2
initMatrix(&h_C, height, width, 0.0f); // C 初始化为 0
printf("Host matrices initialized\n");
// 可选:打印小矩阵用于调试
// if (height <= 8 && width <= 8) {
// printMatrix(h_A, "Matrix A");
// printMatrix(h_B, "Matrix B");
// }
// ==================== 3. 分配设备内存 ====================
Matrix d_A, d_B, d_C;
d_A.width = width; d_A.height = height;
d_B.width = width; d_B.height = height;
d_C.width = width; d_C.height = height;
CUDA_CHECK(cudaMalloc(&d_A.elements, bytes));
CUDA_CHECK(cudaMalloc(&d_B.elements, bytes));
CUDA_CHECK(cudaMalloc(&d_C.elements, bytes));
printf("Device memory allocated\n");
// ==================== 4. 拷贝数据到设备 ====================
CUDA_CHECK(cudaMemcpy(d_A.elements, h_A.elements, bytes, cudaMemcpyHostToDevice));
CUDA_CHECK(cudaMemcpy(d_B.elements, h_B.elements, bytes, cudaMemcpyHostToDevice));
printf("Data copied to device\n");
// ==================== 5. 配置内核启动参数 ====================
// 通常使用 16x16 或 32x32 的线程块
int blockSize = 16;
dim3 threadsPerBlock(blockSize, blockSize);
dim3 numBlocks((width + blockSize - 1) / blockSize,
(height + blockSize - 1) / blockSize);
printf("Launching kernel with %d x %d = %d blocks, each %d x %d = %d threads\n",
numBlocks.x, numBlocks.y, numBlocks.x * numBlocks.y,
threadsPerBlock.x, threadsPerBlock.y, threadsPerBlock.x * threadsPerBlock.y);
// ==================== 6. 启动内核 ====================
// 记录开始时间
cudaEvent_t start, stop;
CUDA_CHECK(cudaEventCreate(&start));
CUDA_CHECK(cudaEventCreate(&stop));
CUDA_CHECK(cudaEventRecord(start, 0));
// 执行矩阵加法内核
matrixAdd<<<numBlocks, threadsPerBlock>>>(d_A, d_B, d_C);
// 检查内核启动错误
CUDA_CHECK(cudaGetLastError());
// 等待 GPU 完成
CUDA_CHECK(cudaDeviceSynchronize());
// 记录结束时间
CUDA_CHECK(cudaEventRecord(stop, 0));
CUDA_CHECK(cudaEventSynchronize(stop));
float milliseconds = 0;
CUDA_CHECK(cudaEventElapsedTime(&milliseconds, start, stop));
printf("Kernel execution time: %.3f ms\n", milliseconds);
// 计算带宽(GB/s)
float gbTransferred = 3.0f * bytes / (1024.0f * 1024.0f * 1024.0f); // A,B,C 三个矩阵
float bandwidth = gbTransferred / (milliseconds / 1000.0f);
printf("Effective bandwidth: %.2f GB/s\n", bandwidth);
// ==================== 7. 拷贝结果回主机 ====================
CUDA_CHECK(cudaMemcpy(h_C.elements, d_C.elements, bytes, cudaMemcpyDeviceToHost));
printf("Result copied back to host\n");
// ==================== 8. 验证结果 ====================
if (verifyResult(h_C, h_A, h_B)) {
printf("Result verification: PASSED ✓\n");
// 打印示例结果
printf("Sample results (top-left corner):\n");
for (int i = 0; i < 5 && i < height; i++) {
for (int j = 0; j < 5 && j < width; j++) {
int idx = i * width + j;
printf("C[%d][%d] = %.1f + %.1f = %.1f\n",
i, j, h_A.elements[idx], h_B.elements[idx], h_C.elements[idx]);
}
if (width > 5) printf("...\n");
break;
}
} else {
printf("Result verification: FAILED ✗\n");
}
// ==================== 9. 清理资源 ====================
// 释放设备内存
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
// 释放主机内存
free(h_A.elements);
free(h_B.elements);
free(h_C.elements);
// 销毁 CUDA 事件
cudaEventDestroy(start);
cudaEventDestroy(stop);
printf("Resources cleaned up\n");
return 0;
}
结果
ubuntu@ubuntu:~/MyProject/MyCuda$ nvcc -o matrixAdd matrixAdd.cu
ubuntu@ubuntu:~/MyProject/MyCuda$ ./matrixAdd
Matrix dimensions: 1024 x 1024
Total elements: 1048576
Memory per matrix: 4.00 MB
Host matrices initialized
Device memory allocated
Data copied to device
Launching kernel with 64 x 64 = 4096 blocks, each 16 x 16 = 256 threads
Kernel execution time: 5.404 ms
Effective bandwidth: 2.17 GB/s
Result copied back to host
Result verification: PASSED ✓
Sample results (top-left corner):
C[0][0] = 1.0 + 2.0 = 3.0
C[0][1] = 1.0 + 2.0 = 3.0
C[0][2] = 1.0 + 2.0 = 3.0
C[0][3] = 1.0 + 2.0 = 3.0
C[0][4] = 1.0 + 2.0 = 3.0
...
Resources cleaned up
七、总结
核函数是CUDA编程的核心,理解核函数的工作原理是掌握CUDA的第一步。本文详细讲解了:
- 核函数的本质:GPU上的并行函数,采用SIMT执行模型
- 三类函数修饰符的区别和使用场景:
__global__、__device__、__host__ <<<>>>语法的完整含义和CUDA的线程层次结构- 线程索引的计算方法和线程块大小的最佳实践
- 常见误区和避坑指南
掌握了这些知识,你已经可以编写基本的CUDA程序了。在下一篇文章中,我们将深入讲解CUDA的内存模型,这是优化CUDA程序性能的关键。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)