【论文阅读】EmbodiedScan: A Holistic Multi-Modal 3D Perception Suite Towards Embodied AI
快速了解部分
基础信息:
- 题目: EmbodiedScan: A Holistic Multi-Modal 3D Perception Suite Towards Embodied AI
- 时间: 2024.06
- 机构: Shanghai AI Laboratory, Shanghai Jiao Tong University, The University of Hong Kong, etc.
- 3个英文关键词: Embodied AI, 3D Perception, Multi-Modal Dataset
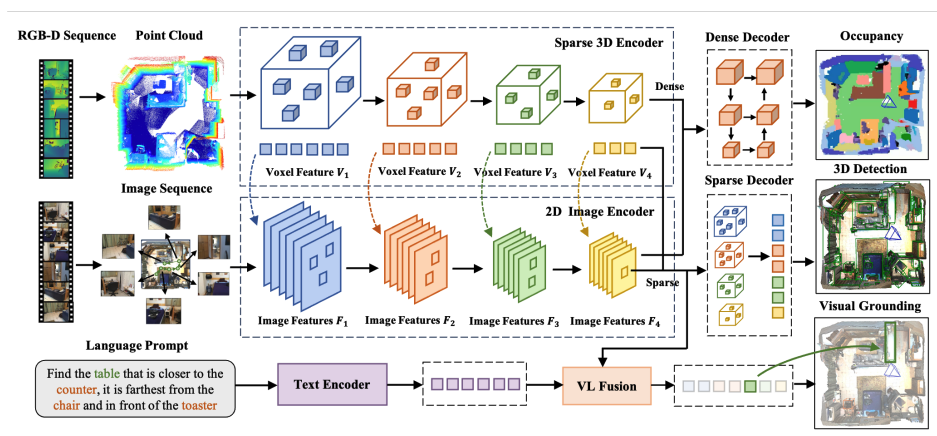
1句话通俗总结本文干了什么事情
本文发布了一个名为 EmbodiedScan 的超大规模室内3D场景数据集,并基于此提出了一个名为 Embodied Perceptron 的基准模型,旨在解决具身智能体在第一人称视角下对3D环境进行全方位感知和理解的问题。
研究痛点:现有研究不足 / 要解决的具体问题
- 视角偏差:传统3D感知研究多基于“上帝视角”(全局扫描),而具身智能体看到的是Ego-centric,两者存在巨大鸿沟。
- 数据匮乏:现有的第一人称RGB-D数据集太小,或者缺乏全面的3D标注(如 Oriented Box、Occupancy),无法支持复杂的语言 grounding 任务。
- 割裂:几何(深度)和语义(图像)信息处理割裂,且缺乏将语言与3D场景结合的基准测试。
核心方法:关键技术、模型或研究设计(简要)
- 数据集构建:利用 SAM 辅助标注,从 ScanNet 等数据源中提取了 5k+ 扫描数据,包含 1M+ 第一人称图像、760+ 类别的 3D Oriented Box 和密集的语义 Occupancy 标注。
- 模型设计:提出了 Embodied Perceptron,核心是一个能处理任意数量输入视图的多模态编码器,通过“同构多级融合”将图像、点云和语言特征对齐。
深入了解部分
作者想要表达什么
作者想表达:未来的具身智能不能只看局部图片或依赖完美的全局扫描,必须建立在“第一人称连续探索”的基础上。通过发布这个包含几何、视觉、语言多模态的大数据集,作者试图定义一个新的标准,即 Holistic 3D Perception(全方位3D感知),强调不仅要识别物体,还要理解空间占用和语言指令。
相比前人创新在哪里
- 视角转换:不同于以往数据集(如 KITTI, nuScenes 侧重驾驶,ScanNet 侧重全局静态),本文专注于动态的、移动的“第一人称视角”。
- 标注密度与维度:规模比以往大 10 倍以上,且同时提供了稀疏的物体检测框(Oriented 3D Box)和密集的空间占用(Semantic Occupancy)以及语言描述。
- 任务设置:提出了 Continuous 3D Perception(连续感知)任务,模拟机器人边走边看的场景,而非一次性输入全景。
解决方法/算法的通俗解释
想象给机器人装上眼睛(RGB相机)和激光雷达(Depth)。
- 看多张图:机器人在房间里走动,拍了很多张照片。模型不只看一张,而是能把前后好几十张照片的信息融合起来,拼成一个局部的 3D 地图。
- 特征融合:模型设计了一种机制,让 2D 图片的纹理信息和 3D 点云的几何信息在多个层级上互相“对话”,而不是简单地拼在一起。
- 理解语言:如果给一句“把左边的红色杯子拿起来”,模型能利用融合后的特征,在 3D 空间里精准定位那个杯子。
解决方法的具体做法
- 数据处理:收集 ScanNet, 3RScan, Matterport3D 的原始数据,利用 SAM 生成 Mask,人工修正生成 Oriented 3D Box,并计算体素级的 Occupancy。
- 编码器:
- 使用 ResNet 提取 2D 图像特征。
- 使用 MinkowskiNet 提取 3D 点云特征。
- 使用 BERT 提取文本特征。
- 通过 Perspective Projection(透视投影)将 2D 特征反向投影到 3D 空间进行融合(Isomorphic Multi-Level Fusion)。
- 解码器:
- 稀疏解码器预测 3D Box(带旋转角度)。
- 密集解码器预测 Occupancy(空间占用语义)。
- 引入 Transformer 进行视觉-语言(VL)融合以支持 grounding。
基于前人的哪些方法
- SAM:用于辅助生成高质量的 2D Mask,从而推导 3D 标注。
- FCAF3D:稀疏检测解码器的设计参考了 FCAF3D,但改进了旋转框的回归方式。
- MinkowskiNet:用于处理 3D 点云的骨干网络。
- BERT:用于处理自然语言文本。
实验
exp1: Continuous 3D Object Detection (连续3D物体检测)
<设置>: 输入连续的多帧 RGB-D 图像,评估模型在不同视图数量下的表现。
<数据>: EmbodiedScan 数据集 (3930训练/703验证/552测试 scans)。
<评估方式>: mAP (IoU 0.25 和 0.5)。
<结论>: RGB-D 融合效果最好;视图越多(50帧 vs 10帧),性能提升越明显;证明了连续感知的有效性。
exp2: Continuous Semantic Occupancy Prediction (连续语义占用预测)
<设置>: 预测传感器前方空间的语义占用情况(什么物体在哪个体素里)。
<数据>: 同上。
<评估方式>: mIoU。
<结论>: 深度信息对预测空区域和墙面很重要,但 RGB 信息对区分门、窗、柜子等纹理相似的物体至关重要。
exp3: Multi-View 3D Visual Grounding (多视角3D视觉定位)
<设置>: 输入多张图片和一句自然语言,找出对应的物体。
<数据>: EmbodiedScan 的语言子集。
<评估方式>: AP。
<结论>: 提出的模型优于之前的 SOTA (如 ScanRefer),证明了其多模态编码器的有效性。
提到的同类工作
<2023>同类数据集,但侧重单目3D检测且非第一人称连续视角
<2017>基础数据源,但缺乏第一人称序列和丰富语言标注
<3RScan><2019>基础数据源,侧重物体重定位而非场景理解
<2021>合成数据集,缺乏真实感
<2020>语言 grounding 基准,但规模小且基于静态场景
和本文相关性最高的3个文献
<ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes><2017>EmbodiedScan 的主要数据来源之一,本文将其重构为第一人称序列
<2023>本文利用 SAM 进行辅助标注的核心工具
<FCAF3D: Fully Convolutional Anchor-Free 6D Object Detection><2022>本文检测解码器的主要基线模型
我的
- 一个数据集+一个3D perception Model,具身领域,专注ego视角的3D数据标注感知。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)