基于知识图谱的数据库课程智能问答系统的设计与实现(数据库课程;知识图谱;智能问答系统;Neo4j;Python、高质量)
随着高等教育信息化的快速发展,计算机专业课程的教学模式不断创新,数据库课程作为计算机类专业的核心基础课,其知识点体系庞大、逻辑关联性强、实践要求高的特点,给学生自主学习和教师教学答疑带来了诸多挑战。传统人工答疑模式存在响应滞后、答案碎片化、难以覆盖所有学生疑问等问题,学生容易产生知识断层,无法建立完整的数据库知识体系。知识图谱技术凭借强大的知识组织、语义关联和推理能力,为专业课程智能答疑提供了全新的技术解决方案,在此背景下,构建科学易用的数据库课程智能问答系统意义重大。
本基于知识图谱的数据库课程智能问答系统,运用Python语言、Neo4j数据库、Flask框架等关键技术。通过数据采集、知识抽取等流程构建数据库课程知识图谱,借助自然语言处理技术实现智能交互。系统涵盖用户管理、课程知识图谱检索、智能问答、知识点推荐、课程百科等功能模块,能为用户提供个性化的数据库课程知识解答。
经实验验证,该系统在准确率与响应速度上表现良好。有效帮助学生快速定位知识点、理清知识关联,提升自主学习效率,同时减轻教师重复性答疑负担,为教师掌握学生学习难点、优化教学策略提供数据支持。为数据库课程的智能化教学提供有力工具,在计算机专业课程教学改革领域具有广阔应用前景,对推动智能教育与专业课程深度融合有积极意义。
关 键 词:数据库课程;知识图谱;智能问答系统;Neo4j
ABSTRACT
With the rapid development of higher education informatization, the teaching mode of computer professional courses is constantly innovating. As a core basic course for computer majors, database course has the characteristics of huge knowledge system, strong logical correlation and high practical requirements, which brings many challenges to students' autonomous learning and teachers' teaching answering. The traditional manual answering mode has problems such as delayed response, fragmented answers and difficulty in covering all students' questions. Students are prone to knowledge gaps and cannot establish a complete database knowledge system. Knowledge graph technology, with its powerful capabilities in knowledge organization, semantic association and reasoning, provides a brand-new technical solution for intelligent answering of professional courses. Under these circumstances, the development of a scientifically robust and user-friendly intelligent Q&A system for database courses holds substantial significance.
This knowledge graph-based intelligent Q&A system for database courses utilizes key technologies including Python programming language, Neo4j database, and Flask framework. The system constructs knowledge graphs through data collection and knowledge extraction processes, enabling intelligent interaction via natural language processing techniques. It incorporates functional modules such as user management, course knowledge graph retrieval, intelligent Q&A, knowledge point recommendation, and course encyclopedia, providing personalized database course knowledge solutions for users.
Experimental validation has demonstrated that the system exhibits excellent performance in accuracy and response speed. It effectively helps students quickly locate knowledge points, clarify knowledge associations, and improve autonomous learning efficiency. Meanwhile, it reduces the burden of repetitive answering for teachers and provides data support for teachers to grasp students' learning difficulties and optimize teaching strategies. The system provides a powerful tool for the intelligent teaching of database courses, offering broad application prospects in the field of computer professional course teaching reform. It holds significant positive implications for promoting the deep integration of intelligent education and professional courses.
KEY WORDS: Database Course; Knowledge Graph; Intelligent Q&A System; Neo4j
目 录
目前,国内很多高校的数据库课程教学中,学生在自主学习过程中面临着知识点零散、关联不清的问题。数据库课程涵盖关系模型、SQL语言、事务处理、数据库设计、并发控制等多个核心模块,知识点之间存在紧密的逻辑依赖关系,例如不理解关系代数就难以掌握SQL查询语句,不了解事务的ACID特性就无法正确进行数据库并发控制。随着网络信息的快速发展,虽然相关学习资料逐渐增多,但由于信息来源复杂且碎片化,很多学生在查找时常常费时费力,难以获取准确和全面的知识,也无法建立系统的知识体系。为此,本项目旨在提供一个基于知识图谱的数据库课程问答平台,帮助学生快速了解数据库课程的基本概念、操作方法和应用场景。
在中国,计算机专业课程知识图谱的建设具有重要的现实意义。数据库技术作为计算机科学与技术领域的核心技术之一,广泛应用于各行各业的信息系统建设中。然而,传统的数据库教学模式往往以课堂讲授为主,答疑环节受时间和空间的限制,无法及时满足所有学生的学习需求。通过建立数据库课程知识图谱,可以将大量的课程知识进行整合和系统化,帮助学生、教师以及相关教育工作者更好地理解数据库课程的知识体系,提升学习和教学的效率。数据库课程知识图谱的意义还在于,它能够为未来的智能教学系统开发和教学模式创新提供宝贵的参考。
随着高等教育信息化的不断推进和人工智能技术的快速发展,智能教育已经成为教育领域的重要发展方向。通过建立数据库课程知识图谱,可以为高校计算机专业的智能教学提供基础数据支撑,促进优质教育资源的共享与创新。未来,数据库课程知识图谱不仅能够帮助提高学生的自主学习能力,还能推动高校教学模式的改革与创新,提升整体教学质量。
-
-
- 理论意义
-
该平台将通过整合来自教材、教学PPT、教学大纲、课后习题等多源信息,构建数据库课程知识图谱,提供一站式的查询服务。平台不仅能够解答有关数据库课程的基本问题,还将提供各种知识点的关联分析和学习路径推荐,帮助学生更好地掌握数据库课程的核心内容。通过本项目的实施,预计能有效解决学生在数据库学习中遇到的知识断层问题,提升学生的学习效率和学习效果。
-
- 国内外研究现状
知识图谱技术的起源可以追溯到20世纪90年代末,当时学术界主要关注如何将结构化和非结构化的数据进行关联与整合。随着互联网的普及和信息量的爆炸性增长,传统的关系型数据库难以处理复杂的语义关系,因此,研究者们开始探索能够表示多种复杂关系和信息的知识表示方法。最初,知识图谱多应用于自然语言处理和信息检索领域,重点是如何将文本中的实体和关系抽取出来并进行表示,构建出一个覆盖各类知识的图谱。
进入21世纪后,随着大数据和人工智能技术的发展,知识图谱的应用得到了广泛的扩展。特别是随着深度学习和图神经网络等技术的兴起,知识图谱不仅能够处理结构化数据,还能在自然语言处理、语义搜索、推荐系统等领域发挥重要作用。谷歌在2012年推出的“知识图谱”是这一技术应用的标志性事件。谷歌知识图谱通过将全球各类信息进行节点化表示,使得搜索引擎能够更智能地理解用户的意图,提供更加精准的搜索结果。这一技术的成功使得知识图谱迅速成为人工智能领域的重要组成部分。
当前,知识图谱技术正朝着更加智能化、开放化的方向发展。随着跨领域知识的融合和知识自动化构建技术的进步,知识图谱的应用场景不断拓宽。例如,在教育领域的发展,知识图谱不仅用于知识的组织和展示,还能够通过智能推理和数据分析提供个性化学习推荐和教学决策支持。未来,随着更多领域的融合,知识图谱将成为人工智能系统中不可或缺的基础设施,推动各行各业的数字化转型与智能化升级,知识图谱架构图如图1.1所示。

图1.1 知识图谱架构图
论文分析了当前智能问答系统在教育领域应用的重要性和可行性,提出通过使用知识图谱作为知识库,设计并构建数据库课程智能问答系统。该系统旨在通过智能化的方式帮助用户获取数据库课程相关的专业信息,提升学习和教学效率。论文的主要工作如下:
构建本体,通过整理数据库课程相关的教材、教学PPT、教学大纲等专业资料,识别出实体和关系,构建详细的数据库课程本体,确保知识的全面性和准确性。
使用网络爬虫技术收集互联网上关于数据库课程的相关教程、学习资料、习题解析和专家意见,并对爬取的内容进行解析,从中提取有用的文本信息,经过数据清洗和预处理,去除噪声和无关数据。
基于构建的本体对处理后的文本数据进行去重和整理,构建数据库课程知识的三元组数据集,利用Neo4j图数据库对数据进行高效存储,确保知识图谱的可扩展性和查询效率。
构建问答模板,根据常见的数据库课程问题,设计问答流程和规则,搭建数据库课程智能问答系统,能够快速响应并提供准确的概念解释、操作方法、习题解答和学习建议等相关内容。
通过以上步骤,最终实现了一个数据库课程智能问答系统,为学生、教师以及数据库学习者提供一个便捷的工具,帮助他们更好地理解和掌握数据库课程的知识内容。
Python是一种高级编程语言,由Guido van Rossum于1991年首次发布。它具有简洁易读的语法和强大的功能,深受开发者喜爱。Python支持多种编程范式,包括面向对象、命令式和函数式编程,具有极高的灵活性。由于其简洁的语法和丰富的标准库,Python被广泛应用于Web开发、数据分析、人工智能、自动化脚本等多个领域。Python的代码结构清晰,易于学习和使用,特别适合初学者入门。
Python的强大生态系统是其另一个突出优势。通过PyPI(Python包索引),用户可以方便地访问大量的第三方库,进一步扩展Python的功能。例如,NumPy、Pandas、Matplotlib等库在数据科学领域有着广泛应用,而TensorFlow、PyTorch等库在人工智能和深度学习方面也占有重要地位。此外,Python还具备跨平台能力,能够在不同的操作系统上运行。这使得Python成为了开发者、数据科学家和研究人员的首选工具之一。
-
-
- Python爬虫框架
-
Python爬虫框架是为了简化网络数据抓取和解析过程而设计的工具集合。常见的Python爬虫框架包括Scrapy、BeautifulSoup和Selenium。Scrapy是一个功能强大的异步爬虫框架,适合构建大规模、高效的爬虫项目。它支持多线程、请求调度、数据持久化等功能,能够快速抓取并处理大量网页数据。BeautifulSoup是一个轻量级的库,主要用于解析HTML和XML文件,操作简单,常用于小型爬虫或需要对网页内容进行精细处理的场景。Selenium则模拟浏览器操作,适合抓取动态加载的网页内容,广泛应用于需要处理JavaScript渲染的页面。
除了这些框架外,Python还有一些辅助工具可以帮助构建高效的爬虫。比如,requests库用于发送HTTP请求和获取网页内容,lxml库能够高效解析XML和HTML文档,支持XPath和CSS选择器查询。此外,针对大规模爬虫,Python也提供了队列、线程池等工具,帮助优化任务调度和资源管理。整体而言,Python爬虫框架不仅降低了开发的难度,还提高了爬虫的效率和稳定性,成为数据抓取和分析中不可或缺的工具。
-
- Neo4j数据库
- Neo4j图数据库简介
- Neo4j数据库
Neo4j的核心特点是图数据结构的高效存储与查询性能,特别是在处理复杂的关联数据时,能够提供非常快速的响应。Neo4j提供了强大的查询语言Cypher,使得用户可以通过简单的语法来执行图数据的操作,如节点、边的创建、删除以及复杂的图算法查询。Neo4j还支持ACID事务,确保数据一致性和可靠性,适合构建需要高并发读写的图应用程序。由于其强大的社区支持和丰富的生态系统,Neo4j已成为企业和开发者首选的图数据库之一。
Neo4j有着强大的图形数据模型,高效的查询性能,易于扩展和集成,可视化界面等优点,如图2.1所示,简单利用Neo4j图数据库构建出关系,简单易懂,所以本项目选择使用Neo4j图数据库。
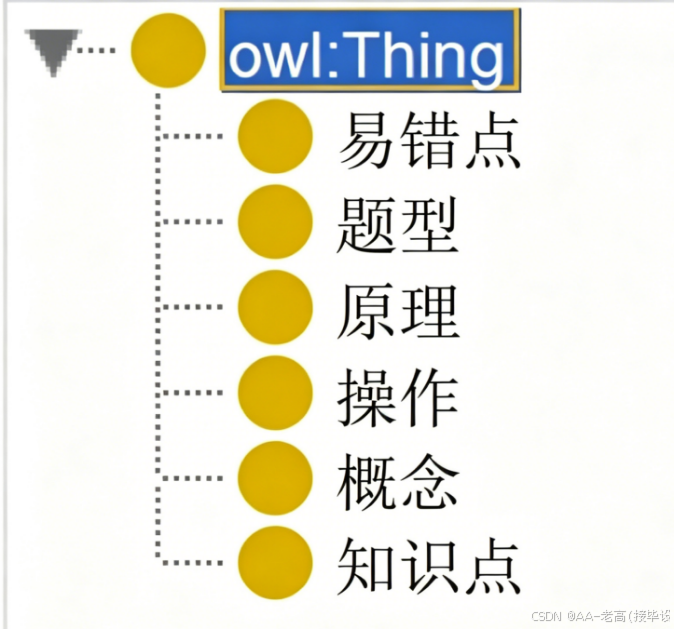
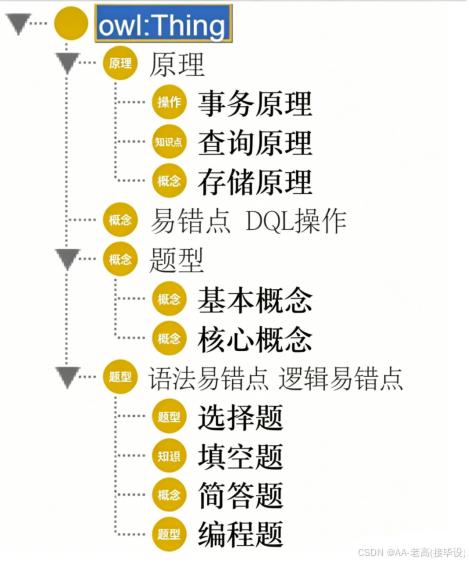

如图4.2(a)所示,在数据库课程智能问答系统中,将课程知识划分为多个相关领域。课程信息可以分为知识点、概念、操作、原理、题型和易错点等。其中概念细化为基本概念和核心概念;操作则可以进一步划分为DDL操作、DML操作、DQL操作等;原理包括事务原理、查询原理、存储原理等;题型包括选择题、填空题、简答题、编程题等;易错点则涵盖语法易错点和逻辑易错点等方面。通过将这些信息细分为不同的类目,系统能够更加精准地匹配用户问题并提供具体建议。数据库课程智能问答系统课程知识领域划分如表4.1所示。
表4.1 数据库课程智能问答系统疾病知识领域划分
|
一级领域 |
二级领域 |
详细内容 |
|
课程信息 |
知识点 |
各类数据库课程的核心知识点 |
|
概念 |
基本概念、核心概念 |
|
|
操作 |
DDL操作、DML操作、DQL操作等 |
|
|
原理 |
事务原理、查询原理、存储原理等 |
|
|
题型 |
选择题、填空题、简答题、编程题 |
|
|
易错点 |
语法易错点、逻辑易错点 |
在设计基于知识图谱的数据库课程智能问答系统时,可以通过定义类与个体之间的关系,建立知识点、概念、操作等相关信息的层次结构。可以定义如下几种关系:数据库核心知识点属于基础知识点或进阶知识点,操作可以包括DDL操作、DML操作等,知识点易错点可以分为语法易错点、逻辑易错点等不同类型。此外,数据库应用场景属于实践类中的行业应用,通过这种结构,系统能够有效地关联不同类型的知识点与相应的操作及原理,基于知识图谱的类与个体关系定义如表4.2所示。
表4.2 基于知识图谱的类与个体关系定义
|
类别 |
具体关系 |
示例 |
|
知识点分类关系 |
数据库核心知识点属于基础知识点或进阶知识点 |
SQL查询属于基础知识点 |
|
操作方法关系 |
操作包括DDL操作、DML操作等 |
CREATE TABLE属于DDL操作 |
|
易错点关系 |
知识点易错点分为语法易错点、逻辑易错点 |
WHERE子句错误属于语法易错点 |
|
应用类别关系 |
数据库应用场景属于行业应用 |
电商数据库设计属于行业应用 |
-
- 数据获取
本设计采用Python+requests+BeautifulSoup的技术框架作为数据抓取的核心工具,利用该框架从多个与数据库课程相关的权威教学网站进行数据抓取,例如中国大学MOOC、学堂在线、W3Cschool数据库教程、菜鸟教程数据库专区等。通过这些数据源,系统能够不断更新和完善数据库课程知识点、操作方法、习题解析等领域的知识图谱。
通过对多个数据库教学和学习相关网站进行爬取,收集了大量的HTML数据。随后,使用第三方库BeautifulSoup对HTML数据进行解析,从关键的tag标签中抽取构建知识图谱所需的信息,包括常见数据库知识点数据、操作方法、原理讲解、习题答案等。数据经过初步解析后,以JSON字符串的形式保存,方便后续进行存储、管理和查询。这样构建的知识图谱能够为数据库课程智能问答系统提供精确、及时的学习咨询服务。
-
- 数据处理
在数据库课程智能问答系统中,数据处理是保障系统高效运行、精准回答用户问题的关键环节。系统的数据处理主要基于课程知识的领域划分与知识图谱中类与个体关系的定义展开。
-
-
- 数据分类与结构化
-
依据表4.1所示的课程知识领域划分,对原始课程数据进行系统分类。将课程信息拆解为知识点、概念、操作等一级领域,并进一步细化二级领域与详细内容,如将操作分为DDL操作、DML操作、DQL操作,使数据具备清晰的层次结构。通过这种分类方式,无序的原始数据被转化为结构化数据,便于后续存储与调用,为系统精准匹配用户问题奠定数据基础。
为了使基于知识图谱的数据库课程智能问答系统能够更好地理解用户的提问,系统需要设置大量的关键词以识别用户的意图。例如,用户询问某个数据库知识点的概念时,可能会有不同的问法,如:“请问什么是事务?”或“事务的定义是什么?”因此,针对数据库课程的概念这一主题,可以设置关键词为“什么是”,“定义”,“概念”等。类似地,对于其他查询意图,例如知识点的操作方法、前置知识、易错点等,也可以根据用户提问的方式设置相关的关键词。
针对不同的知识点查询,系统需要通过这些关键词来精准识别用户的意图。例如,当用户询问知识点的操作方法时,可能会问:“如何创建表?”或“写一个查询语句的方法是什么?”这时,系统通过识别“如何”,“创建”,“写”等关键词,能够判断用户是在寻求操作相关的回答。表4.3中列出了部分常见的查询问题和对应的意图分类,通过这些关键词的设置,能够有效地提高智能问答系统对多样化问题的理解和响应能力,从而更好地为用户提供精准的答案。
表4.3 查询关键词
|
用户问题 |
意图 |
关键词 |
|
1. 知识点概念 |
概念 |
什么是,定义,概念 |
|
2. 已知概念查询知识点 |
知识点名称 |
概念,知识点 |
|
3. 知识点原理 |
原理 |
原理,机制,工作过程 |
|
4. 知识点的前置知识 |
前置知识 |
前置知识,先学什么,基础 |
|
5. 知识点包含的内容 |
包含内容 |
包含,包括,有哪些 |
|
6. 知识点的操作方法 |
操作方法 |
如何,怎么,操作,实现 |
|
7. 某操作属于什么知识点 |
知识点名称 |
操作,属于,对应 |
|
8. 操作的语法格式 |
语法格式 |
语法,格式,写法 |
|
9. 知识点的常见题型 |
题型 |
题型,考什么,怎么考 |
|
10. 某题型对应哪些知识点 |
知识点名称 |
题型,对应,考查 |
|
11. 知识点的易错点 |
易错点 |
易错点,容易错,注意事项 |
|
12. 某错误属于哪个知识点 |
知识点名称 |
错误,问题,属于 |
|
13. 知识点的应用场景 |
应用场景 |
应用,用途,使用场景 |
|
14. 知识点的学习方法 |
学习方法 |
怎么学,学习方法,技巧 |
|
15. 知识点的重要性 |
重要性 |
重要吗,为什么学,作用 |
|
16. 习题解答 |
习题解答 |
解答,答案,怎么做 |
|
17. 知识点的区别 |
区别 |
区别,不同,对比 |
|
18. 知识点的联系 |
联系 |
联系,关系,关联 |
-
- 实体识别
下方数据,利用标注工具标注出其中的关键信息。标注后,在每段文本后加入标注的实体内容,并记录每个实体的位置。例如:
Plaintext
"_id": {
"$oid": "5bb578b6831b973a137e3ee6"
},
"name": "事务",
"desc": "事务(Transaction)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。事务具有原子性、一致性、隔离性和持久性四个特性,简称ACID特性。事务是数据库并发控制的基本单位,能够保证数据库的一致性和可靠性。",
"category": [
"数据库基础",
"核心概念",
"事务处理"
],
"prevent": "1、避免长事务占用数据库资源。\n2、合理设置事务隔离级别。",
"cause": "事务的产生是为了解决数据库并发操作带来的数据不一致问题,如脏读、不可重复读、幻读等。",
"symptom": [
"原子性",
"一致性",
"隔离性",
"持久性"
],
"yibao_status": "否",
"get_prob": "必考",
"get_way": "理论+实践",
"acompany": [
"并发控制",
"锁机制"
],
"cure_department": [
"数据库系统",
"事务管理"
],
"cure_way": [
"BEGIN TRANSACTION",
"COMMIT",
"ROLLBACK"
],
"cure_lasttime": "约2课时",
"cured_prob": "约80%",
"cost_money": "无",
"check": [
"事务隔离级别测试",
"并发操作模拟"
],
"recommand_drug": [],
"drug_detail": []
通过init函数完成了实体识别模型的构建,然后重构torch.nn.Module的forward方法,将构建好的模型各部分进行组装,构成了完整的前向网络传输流程。其代码如图5.6所示。

图5.6 命名实体识别模型
-
- 构建知识图谱
(1)将数据从json文件中取出
首先,需要读取json文件。Python的json库提供了方便的解析工具,示例代码如下:
import json
读取json文件
with open('data.json', 'r', encoding='utf-8') as file:
Plaintext
data = json.load(file)
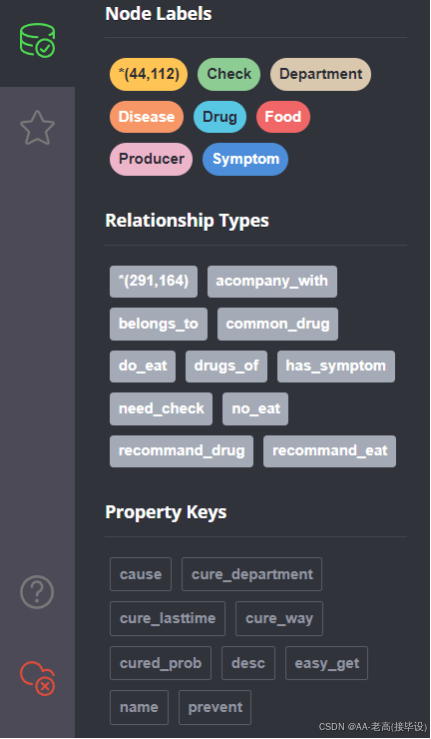
上述代码打开名为data.json的文件,将其内容解析为Python的字典或列表结构,存储在data变量中。若json文件结构复杂,可能还需要进一步遍历数据,筛选出与7个实体类型和11个关系类型相关的数据。
(2)创建node,循环将全部数据创建实体节点
以Python结合Neo4j的官方驱动Neo4j库为例,在连接到Neo4j数据库后,通过循环遍历提取的数据,根据不同的实体类型创建节点。假设7个实体类型分别为KnowledgePoint(知识点)、Concept(概念)、Operation(操作)、Principle(原理)、QuestionType(题型)、ErrorPoint(易错点)、KnowledgeCategory(知识类别),代码示例如下:
from Neo4j import GraphDatabase
连接到Neo4j数据库
uri = "bolt://localhost:7687"
user = "Neo4j"
password = "your_password"
driver = GraphDatabase.driver(uri, auth=(user, password))
def create_nodes(data):
Plaintext
with driver.session() as session:
for item in data:
if item['type'] == 'KnowledgePoint':
session.run("CREATE (k:KnowledgePoint {name: $name})", name=item['name'])
elif item['type'] == 'Concept':
session.run("CREATE (c:Concept {name: $name})", name=item['name'])
# 其他实体类型的创建逻辑类似,依次补充
#...
调用函数创建节点
create_nodes(data)
driver.close()
上述代码通过判断数据中的实体类型,执行相应的Cypher语句在Neo4j中创建节点,并为节点设置名称属性。
(3)创建关系,循环将全部数据创建关系
同样基于Neo4j驱动,根据11个关系类型,遍历数据创建节点间的关系。假设存在关系类型如CONTAINS(包含)、PREREQUISITE(前置知识)、CORRESPONDS_TO(对应题型)等,示例代码如下:
def create_relationships(data):
Plaintext
with driver.session() as session:
for relationship in data:
if relationship['type'] == 'CONTAINS':
session.run("MATCH (k:KnowledgePoint {name: $kp_name}), (c:Concept {name: $concept_name}) "
"CREATE (k)-[:CONTAINS]->(c)",
kp_name=relationship['from'], concept_name=relationship['to'])
elif relationship['type'] == 'PREREQUISITE':
session.run("MATCH (k1:KnowledgePoint {name: $kp1_name}), (k2:KnowledgePoint {name: $kp2_name}) "
"CREATE (k1)-[:PREREQUISITE]->(k2)",
kp1_name=relationship['from'], kp2_name=relationship['to'])
# 其他关系类型的创建逻辑类似,依次补充
#...
调用函数创建关系
create_relationships(data)
driver.close()
该代码根据关系数据中的起始节点名称、结束节点名称以及关系类型,使用MATCH语句找到对应的节点,再通过CREATE语句创建关系。
(4)导入图数据库Neo4j 中
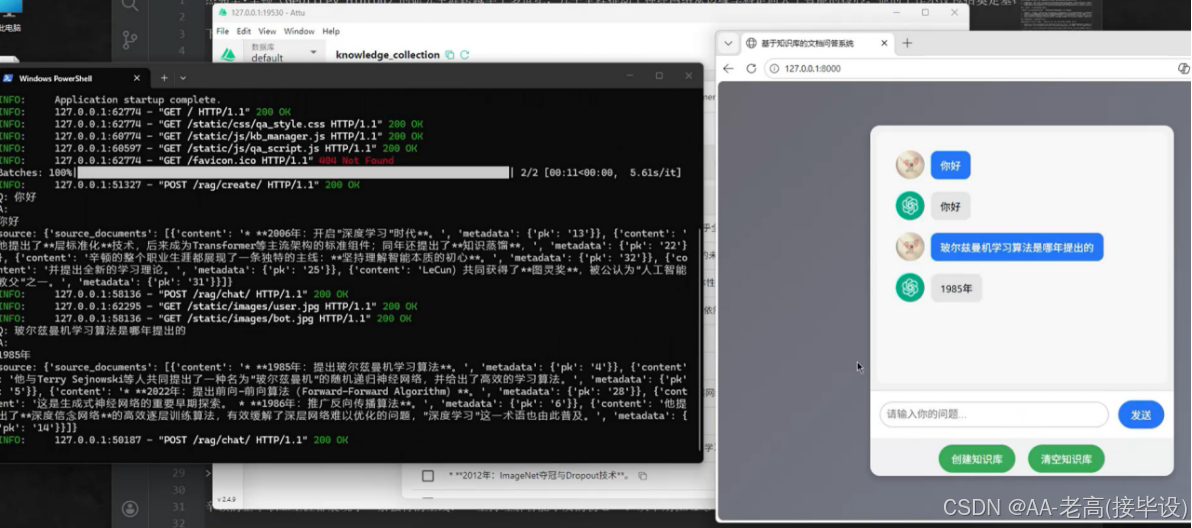
上述步骤(2)和(3)在执行过程中,已经通过Neo4j驱动将数据以节点和关系的形式导入到Neo4j数据库。只要确保数据库服务正常运行,代码中连接信息准确,数据就能成功存储在Neo4j中。后续可以通过Neo4j的桌面客户端或浏览器访问界面,使用Cypher查询语句验证数据是否正确导入,例如使用MATCH (n) RETURN n语句查看所有节点和关系 。
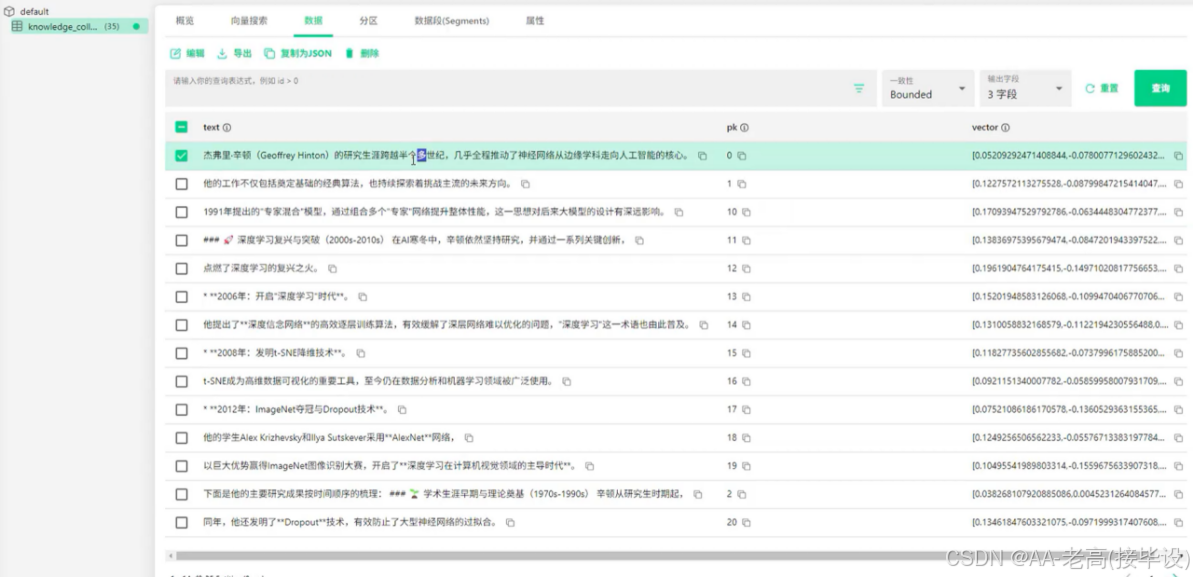
形成一个实体数量庞大的知识图谱,数据类型如图5.7所示,该图谱可以提供全面、准

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)