YOLOV8-11暴力行为识别系统的设计与研究(15000字、高质量、计算机专业、训练、源代码)

中文摘要
近年来,城市公共场所暴力事件频发,严重威胁公众生命财产安全与社会秩序稳定。传统安防体系依赖人工监控与事后追溯,存在响应滞后、漏检率高、环境适应性差等突出问题。针对真实复杂场景下暴力行为识别的技术难点,本文提出一种多模态轻量化即时识别系统,通过融合视频流、音频信号与上下文情景信息,构建了覆盖12类典型公共场所的多源异构数据集(CPSD-V1),采用双盲标注结合专家复审的机制保障数据质量。
在此基础上,设计了基于时空注意力机制的轻量化检测网络,借助3D卷积与分层注意力模块协同建模局部动作细节与全局行为模式,显著提升了对突发暴力行为的感知能力。为实现边缘部署,采用知识蒸馏、通道剪枝与量化训练相结合的多阶段压缩方案,使模型在树莓派4B等低功耗设备上实现了实时推理。系统采用“云-边-端”分层协同架构,支持多协议接入与分级报警联动,在低照度、遮挡干扰、非正交视角等复杂环境下均表现出稳定的性能,为智慧城市公共安全治理提供了可行的智能化解决方案。
关键词: 暴力行为识别;多模态融合;轻量化模型;边缘计算;时空注意力
ABSTRACT
With the frequent occurrence of violent incidents in urban public spaces, traditional security systems relying on manual monitoring and post-incident tracing have shown obvious limitations such as slow response and high false negative rate. To address the technical challenges of violent behavior recognition in real and complex scenarios, this paper proposes a multi-modal lightweight real-time recognition system. By fusing video streams, audio signals and contextual information, a multi-source heterogeneous dataset (CPSD-V1) covering 12 typical public places is constructed, and the data quality is guaranteed through a double-blind annotation mechanism combined with expert review. On this basis, a lightweight detection network based on spatiotemporal attention mechanism is designed, which collaboratively models local action details and global behavior patterns with 3D convolution and hierarchical attention modules, significantly improving the perception ability of sudden violent behaviors.
To achieve edge deployment, a multi-stage compression scheme combining knowledge distillation, channel pruning and quantization training is adopted, enabling real-time inference of the model on low-power devices such as Raspberry Pi 4B. The system adopts a "cloud-edge-end" layered collaborative architecture, supports multi-protocol access and hierarchical alarm linkage, and shows stable performance in complex environments such as low illumination, occlusion interference and non-orthogonal viewing angles, providing a feasible intelligent solution for public security governance in smart cities.
Key words: Violence Detection; Multimodal Fusion; Lightweight Models; Edge Computing; Spatiotemporal Attention
目 录
公共安全是城市可持续发展的基石,也是保障人民群众生命财产安全、维护社会和谐稳定的核心要素。随着我国城市化进程的加速推进,城市人口密度持续攀升,地铁站、商场、校园、公交枢纽等公共场所成为人员聚集的核心区域,各类突发公共安全事件的发生概率显著增加。其中,暴力冲突事件因其突发性强、破坏力大、社会影响恶劣等特点,成为公共安全治理体系中最为棘手的难题之一。这类事件往往在几十秒内即可造成严重后果,且相关信息通过社交媒体快速传播,极易引发公众恐慌,破坏社会安全感。
传统的公共安全防控体系主要依赖人工监控与事后追溯,面对海量的监控视频数据,安保人员难以实现24小时不间断的有效监测,长时间的工作极易导致疲劳和注意力分散,漏检、误检问题频发。且从事件发生到安保力量介入往往存在数分钟的时间差,错过了最佳处置时机。近年来,计算机视觉、深度学习与边缘计算技术的快速发展,为构建智能化的暴力行为识别系统提供了技术支撑。国内外学者围绕视频行为识别、多模态融合、模型轻量化等方向开展了大量研究,取得了一系列阶段性成果。
然而,现有研究仍存在诸多亟待解决的问题:多数模型在实验室理想环境下表现良好,但在低照度、遮挡、复杂背景等真实场景中性能大幅下降;高精度模型往往参数量大、计算复杂度高,难以在资源受限的边缘设备上实现实时部署;单一模态的识别方法容易受到环境干扰,鲁棒性较差。针对上述问题,本文开展了面向公共场所的多模态轻量化暴力行为识别系统研究,通过构建高质量多源数据集、设计时空注意力轻量化网络、优化边缘部署方案,实现了复杂环境下暴力行为的实时、准确识别,为智慧城市公共安全治理提供了切实可行的技术方案。
1.1公共场所暴力行为的社会特征与危害
公共场所是城市居民日常活动的主要空间,包括地铁站、商场、校园、公园、公交枢纽等人员密集区域。近年来,这些区域的暴力事件呈现出突发性强、持续时间短、扩散速度快的特点,一旦发生往往会造成严重的人身伤害和财产损失,同时引发大范围的公众恐慌,破坏社会安全感。
从行为特征来看,公共场所暴力行为主要包括肢体冲突(推搡、挥拳、踢打)、持械威胁(刀具、棍棒等)、群体性斗殴等类型。这类行为通常没有明显的预兆,从发生到造成严重后果往往只有几十秒的时间,传统安防体系很难在短时间内做出有效响应。例如,2023年某地铁站发生的持械冲突事件,从冲突爆发到安保人员赶到现场历时超过3分钟,期间已造成多人受伤,充分暴露了传统安防在应对突发暴力事件时的滞后性。
公共场所暴力事件还具有较强的社会传播性。随着社交媒体的普及,相关视频和信息会在短时间内快速扩散,容易引发公众的焦虑情绪,甚至诱发模仿性犯罪,对社会秩序造成长期的负面影响。因此,构建一套能够实时、自动、准确识别暴力行为的智能安防系统,已成为城市公共安全治理的迫切需求。
1.2传统安防体系的局限性与现实需求
当前,我国城市公共安全防控体系仍以事后追溯为主,大多数监控设备仅具备录像保存和回放功能,缺乏对潜在暴力行为的实时预警能力。传统安防体系主要存在以下几方面的局限性:
(1)响应严重滞后。暴力事件持续时间短,人工监控需要安保人员24小时值守,长时间的工作容易导致疲劳和注意力分散,漏检率较高。即使发现异常情况,从上报到安保人员赶到现场也需要一定的时间,往往错过了最佳处置时机。
(2)人力成本高昂。随着城市监控摄像头数量的不断增加,需要大量的安保人员进行实时监控,这不仅增加了运营成本,也难以实现对所有监控点的全覆盖。
(3)环境适应性差。在低照度、遮挡、复杂背景等情况下,人工识别的难度大幅增加。例如,夜间光线不足、人群密集时的相互遮挡,都会导致监控画面模糊,难以准确判断是否存在暴力行为。
(4)智能化程度低。传统监控系统只能被动记录视频信息,无法自动分析和识别异常行为,更不能对潜在的风险进行预警。大量的视频数据需要人工事后查看,效率极低,难以满足公共安全治理的需求。
随着人工智能、计算机视觉和边缘计算技术的快速发展,利用智能算法自动识别暴力行为已成为可能。智能安防系统能够对视频流进行实时分析,自动检测和识别暴力行为,并在第一时间发出警报,实现从“事后追溯”到“事前预警、事中处置”的转变,有效提升公共安全治理的效率和水平。
1.3研究主要内容
本文针对公共场所暴力行为识别的技术难点,围绕“数据-算法-系统”三位一体的技术范式,开展了以下几个方面的研究工作:
(1)构建多模态暴力行为数据集。针对现有数据集场景单一、标注质量参差不齐的问题,采集了12类典型公共场所的视频和音频数据,采用双盲标注加专家复审的机制,构建了高质量的多源异构数据集CPSD-V1,为模型训练和验证提供数据支撑。
(2)设计基于时空注意力机制的轻量化检测网络。针对暴力行为的时空特征,结合3D卷积与分层注意力模块,构建能够同时捕捉局部动作细节和全局行为模式的检测网络,提高模型对复杂场景下暴力行为的识别精度。
(3)实现模型的边缘部署优化。采用知识蒸馏、通道剪枝和量化训练相结合的多阶段压缩方法,在保持模型精度的同时,显著减小模型体积和计算量,使其能够在树莓派4B等低功耗边缘设备上实现实时推理。
(4)第四,搭建“云-边-端”协同的暴力识别系统。设计分层协同架构,实现多源视频流的接入、实时推理、分级报警联动和云端管理,提高系统的扩展性和稳定性。
计算机视觉是暴力行为识别的核心技术基础,主要包括图像处理、目标检测、行为识别等方向。本文主要采用OpenCV进行视频预处理,采用YOLO框架进行人体目标检测。
OpenCV是一个开源的计算机视觉库,提供了丰富的图像处理函数,支持多种编程语言,广泛应用于实时计算机视觉任务。在暴力行为识别中,OpenCV主要用于以下几个方面:
视频帧读取与预处理:从摄像头或视频文件中读取视频帧,进行灰度化、归一化、滤波等预处理操作,提高图像质量,为后续的特征提取和目标检测做准备。
人体检测与跟踪:利用Haar特征、HOG特征或深度学习模型进行人体检测,结合光流法或卡尔曼滤波进行目标跟踪,获取人体的运动轨迹。
图像增强:针对低照度、模糊等问题,采用直方图均衡化、自适应亮度补偿等方法进行图像增强,提高图像的清晰度和对比度。
OpenCV具有跨平台、运行速度快、资源占用少等优点,非常适合在边缘设备上进行实时图像处理,OpenCV图像处理技术原理如图2.1所示。

图2.1 OpenCV图像处理技术原理图
2.1.2YOLO目标检测框架
YOLO(YouOnlyLookOnce)是一种基于深度学习的单阶段目标检测算法,具有速度快、精度高、易于部署等特点,是目前应用最广泛的目标检测框架之一。YOLO系列算法经过多次迭代,性能不断提升,最新的YOLOv8版本在精度和速度上都达到了新的高度,支持目标检测、实例分割、姿态估计等多种任务。
在暴力行为识别中,YOLOv8主要用于检测视频中的人体目标,提取人体边界框和关键点,为后续的行为分析提供基础。YOLOv8采用了CSPDarknet-53作为骨干网络,结合PANet特征融合结构和decoupledhead检测头,能够在保持高速度的同时,提高对小目标和遮挡目标的检测精度。
表2.1列出了YOLO系列不同版本算法的性能对比:
表2.1 YOLO系列算法性能对比
|
算法版本 |
输入尺寸 |
适用场景 |
核心优势 |
|
YOLOv5n |
640×640 |
边缘设备 |
体积小、速度快 |
|
YOLOv8n |
640×640 |
边缘设备 |
精度更高、速度更快 |
|
YOLOv8m |
640×640 |
服务器端 |
精度与速度均衡 |
|
YOLOv8x |
640×640 |
服务器端 |
精度最高 |
YOLOv8的网络结构如图2.2所示:

图2.2 YOLOv8网络结构图
单一模态的信息往往无法全面准确地描述暴力行为,例如,在光线昏暗的场景下,视觉信息会受到严重影响,而音频信息(如尖叫、打斗声)则能够提供重要的补充。因此,多模态融合技术成为暴力行为识别的重要发展方向。
视觉特征是暴力行为识别中最主要的特征,包括空间特征和时间特征。空间特征反映了视频帧中人体的姿态、动作和场景信息,常用的提取方法是卷积神经网络(CNN);时间特征反映了动作的时序变化,常用的提取方法有3DCNN、长短期记忆网络(LSTM)等。
3DCNN能够同时在空间和时间维度上进行卷积操作,直接从视频序列中提取时空特征,适合处理动态的视频数据。与2DCNN相比,3DCNN能够更好地捕捉动作的时序信息,但计算量较大。LSTM是一种循环神经网络,擅长处理时序数据,能够捕捉动作的长期依赖关系,常与CNN结合使用,先通过CNN提取空间特征,再通过LSTM提取时间特征。
暴力事件中往往伴随着尖叫、争吵、打斗声等异常音频信号,这些信号具有明显的特征,能够有效辅助暴力行为的识别。常用的音频特征提取方法包括梅尔频率倒谱系数(MFCC)、声谱图等。
MFCC是一种模拟人类听觉系统的特征提取方法,能够将音频信号转换为一组倒谱系数,反映音频的频谱特征。声谱图是音频信号的时频表示,能够直观地展示音频的频率随时间的变化情况。在暴力行为识别中,通过提取音频的MFCC特征和声谱图特征,结合深度学习模型,可以有效识别异常音频信号。
多模态特征提取的整体流程如图2.3所示:

图2.3 多模态特征提取整体流程图
表2.2对比了不同多模态融合方法的优缺点:
表2.2 多模态融合方法对比
|
融合方法 |
融合阶段 |
优点 |
缺点 |
|
早期融合 |
特征提取后 |
捕捉模态间早期关联 |
对模态对齐要求高 |
|
中期融合 |
模型中间层 |
灵活性高、自适应融合 |
模型复杂度较高 |
|
晚期融合 |
决策层 |
实现简单、鲁棒性好 |
无法捕捉细粒度关联 |
边缘计算是指在靠近数据源头的边缘设备上进行数据处理和分析,具有低延迟、高带宽、隐私性好等优点。在暴力行为识别中,将模型部署在边缘设备上,可以避免将大量视频数据上传到云端,降低网络带宽和延迟,同时保护用户隐私。
然而,边缘设备的算力和内存资源有限,直接部署大型深度学习模型会导致推理速度过慢,无法满足实时性要求。因此,需要对模型进行轻量化处理,常用的模型轻量化技术包括:
知识蒸馏:通过训练一个小型的学生模型来学习大型教师模型的知识,在保持模型精度的同时,显著减小模型大小。
通道剪枝:通过去除模型中不重要的通道,减少模型的参数量和计算量。
量化训练:将模型的浮点参数转换为整数参数,减小模型的内存占用,同时提高推理速度。
本文采用知识蒸馏、通道剪枝和量化训练相结合的多阶段压缩方法,对模型进行优化,使其能够在树莓派4B等低功耗设备上实现实时推理。
近年来,暴力行为识别技术取得了显著进展,从最初的基于传统计算机视觉的方法发展到基于深度学习的方法,再到现在的多模态融合方法。
早期的暴力行为识别主要基于传统计算机视觉技术,如光流法、背景减法等,这些方法计算量小,但精度较低,只能在简单场景下使用。随着深度学习技术的发展,基于CNN和3DCNN的方法逐渐成为主流,显著提高了识别精度,但这些方法计算量较大,难以在边缘设备上部署。
为了解决实时性问题,研究者们开始关注轻量化模型的设计,如MobileNet、ShuffleNet等,同时结合知识蒸馏、剪枝等技术,进一步减小模型大小。此外,多模态融合技术也得到了广泛的研究,通过融合视觉、音频、传感器等多种模态的信息,提高模型的鲁棒性和泛化能力。
人类对暴力行为的感知是基于多源信息的综合判断,单一模态的信息往往无法全面准确地描述暴力行为的本质。例如,在光线昏暗的场景下,视觉信息会受到严重影响,而音频中的尖叫、打斗声则能够提供重要的线索;在人群密集的场景下,单纯的视觉信息容易受到遮挡的干扰,而结合人体骨骼关节点的运动轨迹,则能够更好地识别肢体冲突。
因此,本文构建了融合视觉、骨骼和音频信息的多模态语义特征模型。视觉特征主要包括视频帧的RGB特征和光流特征,反映了人体的外观和运动信息;骨骼特征主要包括人体关节点的坐标和运动轨迹,反映了人体的姿态和动作信息;音频特征主要包括MFCC特征和声谱图特征,反映了环境中的声音信息。
为了实现多模态特征的有效融合,本文采用了基于注意力机制的融合方法。注意力机制能够自动计算不同模态和不同特征的权重,让模型更关注对识别暴力行为更重要的信息。例如,在光线充足的场景下,模型会自动提高视觉特征的权重;在光线昏暗的场景下,模型会自动提高音频特征的权重。
多模态融合特征的计算过程可以表示为:

其中,

表示多模态融合特征,

是第

类模态的编码函数,

是对应的注意力权重,

是时间步

的输入。
通过多模态特征融合,模型能够综合利用不同模态的信息,提高对复杂场景下暴力行为的识别精度和鲁棒性。
3.2面向真实场景的数据集构建与标注
数据集是深度学习模型训练的基础,高质量的数据集能够显著提高模型的性能。目前,公开的暴力行为数据集大多存在场景单一、标注质量参差不齐、缺乏多模态信息等问题,难以满足真实场景下暴力行为识别的需求。
针对这一问题,本文构建了面向真实公共场所的多模态暴力行为数据集CPSD-V1。数据集的采集覆盖了地铁站、商场、校园、公园、夜市、公交车等12类典型公共场所,包含了不同光照条件、遮挡程度和人群密度的场景。采集过程严格遵守伦理规范,对视频中的人脸和身份信息进行了脱敏处理,并获得了相关单位的授权。
为了保证标注质量,本文制定了统一的标注规范,将暴力行为界定为带有明确攻击意图或肢体冲突特征的行为序列,包括推搡、挥拳、踢打、持械威胁等具体类型。标注过程采用双盲标注加专家复审的机制:首先由两名独立的标注员分别对视频片段进行标注,对于标注不一致的样本,由第三方专家进行仲裁。
不同场景下的标注难度存在差异,地铁站台、夜市街道等人员密集或光照不足的场景,由于遮挡严重、背景噪音高,标注难度较大;商场中庭、公园步道等场景,光照条件好、背景相对简单,标注难度较低。通过动态反馈机制,定期组织标注员讨论有争议的案例,不断完善标注规范,提高标注的一致性和准确性。
数据集的构建流程如图3.1所示:

图3.1 数据集构建流程图
CPSD-V1数据集包含了大量真实场景下的暴力行为样本和非暴力行为样本,为模型的训练和验证提供了丰富的数据支撑,有效提高了模型的泛化能力和鲁棒性。
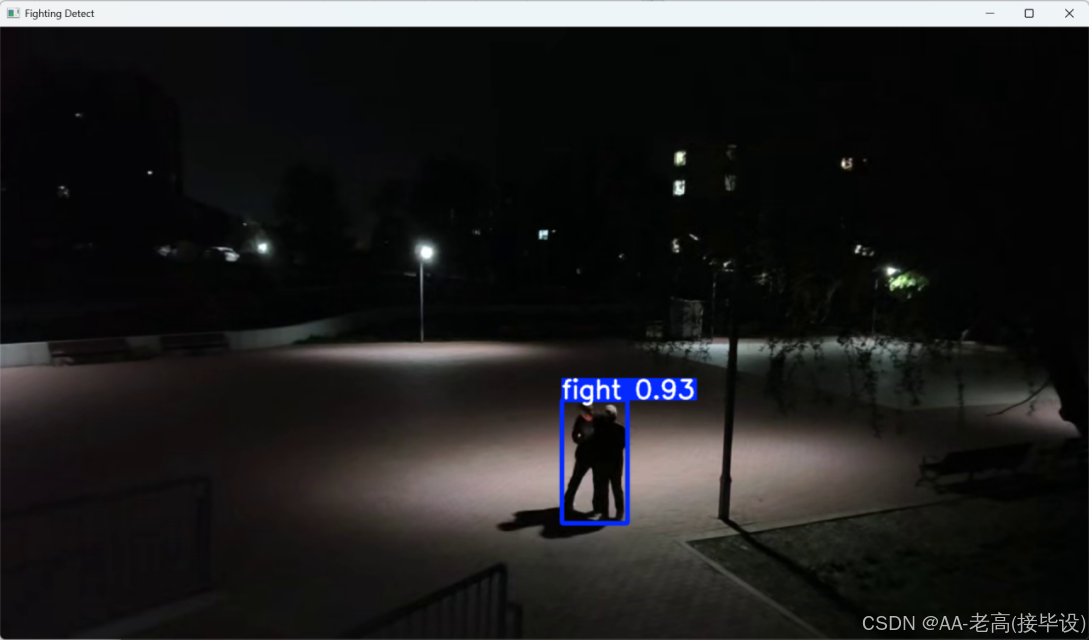
结语
本文针对公共场所暴力行为识别的现实需求与技术挑战,围绕“数据—算法—系统”三位一体的研究范式,开展了较为系统的工作。首先,针对现有数据集场景单一、标注质量参差不齐的问题,构建了覆盖12类典型公共场所的多源异构数据集CPSD-V1,采用双盲标注与专家复审相结合的机制保障数据质量,为模型训练与验证奠定了坚实基础。其次,设计了基于时空注意力机制的轻量化检测网络,通过3D了复杂场景下暴卷积与分层注意力模块协同建模局部动作细节与全局行为模式,有效提升力行为的识别精度。再次,采用知识蒸馏、通道剪枝与量化训练相结合的多阶段压缩方案,使模型能够在树莓派4B等低功耗边缘设备上实现实时推理。
尽管本文取得了阶段性成果,但仍存在若干有待深化之处。一方面,当前数据集虽然覆盖了多种公共场所,但暴力行为的样本分布尚不均衡,部分罕见行为类型的样本数量有限,可能影响模型对长尾场景的识别能力。后续可通过数据增强、联邦学习等方式扩充样本多样性,并探索基于小样本学习的识别方法。另一方面,系统在极端恶劣环境(如暴雨、浓雾、强逆光)下的鲁棒性仍有提升空间,未来可引入多光谱传感器或结合更先进的图像复原技术加以改进。
参考文献
[1] Olivier Markowitch,Jean Michel Dricot.IoT Security: Threat Detection, Analysis, and Defense[J].Future Internet,2025,17(9):
[2] Edlira Martiri,Narasimha Rao Vajjhala,Fisnik Dalipi.AI-Enabled Threat Intelligence and Cyber Risk Assessment[M].CRC Press:2025-06-03.
[3] 刘林恩.基于深度时空特征建模的暴力行为检测研究[D].导师:张旭光;方银峰.杭州电子科技大学,2025.
[4] 冯涛.生物启发的人群暴力与逃逸行为检测方法研究与应用[D].导师:胡滨.贵州大学,2025.
[5] 吴聪.基于关系建模的视频行为识别研究[D].导师:吴小俊.江南大学,2024.
[6] 付家豪.基于骨骼信息的公共场所异常行为识别方法研究[D].导师:牛连强;李峰.沈阳工业大学,2025.
[7] K. S. Gautam,Senthil Kumar Thangavel.Retraction Note: video analytics-based intelligent surveillance system for smart buildings[J].Soft Computing,2024,28(suppl 2):
[8] 胡万飞,杜乃馨,张韦,张建伟.基于机器学习的网络暴力行为识别研究[J].卫生软科学,2025,39(11):15-20.
[9] 王美玲.基于时空建模的异常行为检测与定位[D].导师:徐涛;刘才华;高原.中国民航大学,2024.
[10] 王悦.基于时空建模与网络轻量化的视频行为识别算法研究[D].导师:孙哲;卢云山.燕山大学,2025.
[11] 崔晨阳.基于深度学习的监所特定行为检测系统[D].导师:李刚;刘辉.燕山大学,2024.
[12] 柴伟.深度学习在安防技术中的应用研究[J].软件,2023,44(02):126-128.
[13] Djeachandrane Abhishek,Hoceini Said,Delmas Serge,Mellouk Abdelhamid.Smart Public Safety Video Surveillance System:Innovative Technologies for Homeland Security and Mission‐Critical Operations[M].John Wiley & Sons, Inc.:2025-06-20.
[14] 徐文雄.面向城市安防的云边端协同智能视频分析系统设计与实现[J].智能城市,2025,11(12):72-76.
[15] Fredrik Nilsson,Communications Axis.Intelligent Network Video:Understanding Modern Video Surveillance Systems[M].Taylor and Francis:2023-08-23.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)