DogsVsCats 项目复盘:从猫狗分类开始理解 PyTorch 训练闭环
DogsVsCats 项目复盘:从猫狗分类开始理解 PyTorch 训练闭环
项目地址:GitHub - DogsVsCats
数据集:Kaggle Dogs vs Cats
任务类型:图像二分类
主要模型:自定义 CNN、ResNet-18 迁移学习
主要结果:自定义 CNN 测试准确率约 86%,ResNet-18 测试准确率约 98%
1. 项目背景
DogsVsCats 是我系统学习深度学习之后完成的第一个图像分类项目。现在回头看,这个项目本身并不复杂,任务也很经典:输入一张猫或狗的图片,让模型判断它属于 cat 还是 dog。它当然不是我的核心方向项目,因为我后续更主要的目标是医学图像分割。但对我来说,它仍然是一个很重要的开始。
我做这个项目的目的,不是为了把猫狗分类做到多么极致,而是为了用一个足够简单的任务,把深度学习项目的基本流程真正跑通。也就是从数据处理、模型搭建、训练、验证、保存权重、测试,到日志记录、参数配置、README 整理,完整经历一次。
后来我做 U-Net、3D U-Net、nnU-Net 这些医学影像分割项目时才发现,虽然任务变复杂了,输入从自然图像变成 CT/MRI,输出从一个类别变成像素或体素级 mask,但很多底层流程其实一直在重复。而 DogsVsCats 就是我理解这些流程的起点。
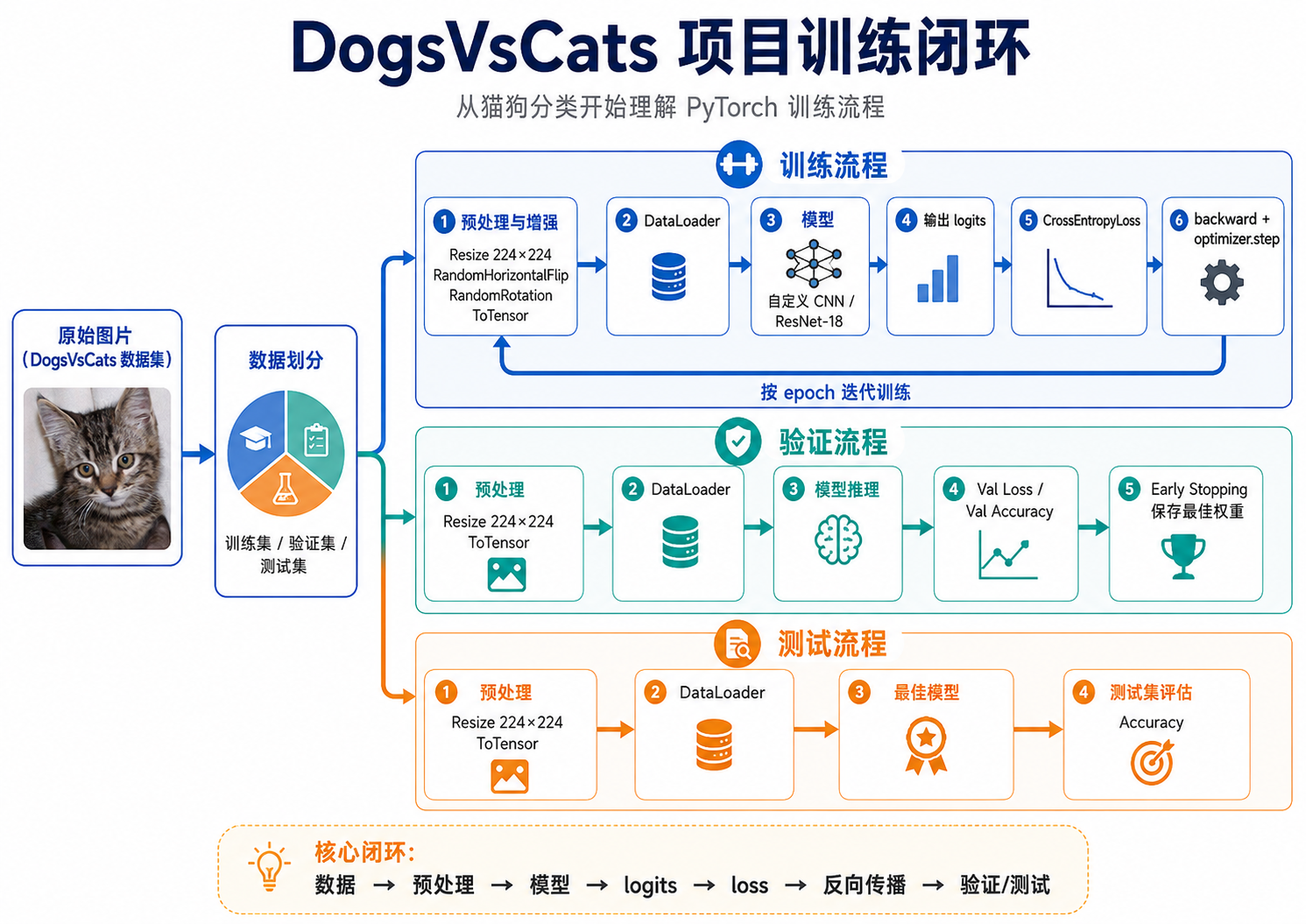
图 1:DogsVsCats 项目的 PyTorch 训练闭环
2. 任务理解
这个项目是一个图像二分类任务。输入是一张 RGB 图片,输出是 cat 或 dog 两个类别之一。和后面的医学影像分割不同,它不需要模型指出猫狗的位置,也不需要对每个像素分类,只需要判断整张图属于哪个类别。
这个任务简单,但它刚好适合用来理解深度学习视觉任务的基本闭环:图片怎么变成 tensor,模型怎么输出类别分数,loss 怎么衡量预测错误,反向传播怎么更新参数,最后怎么用测试集评估模型是否真的能泛化。
一开始我对这个任务的理解其实比较简单,就是“把图像丢进去,模型输出猫狗分类”。真正开始自己写代码、调试和训练之后,才会被一些很具体的问题卡住:为什么图片必须统一尺寸,为什么训练集和测试集不能混着用,为什么模型最后输出的是 logits 而不是直接给一个概率,为什么训练和验证还要切换不同模式。很多概念看书的时候觉得懂了,但只有自己把整个流程跑一遍,才会真正知道这些设计在代码里是怎么工作的。
3. 数据集与预处理
这个项目使用的是 Kaggle Dogs vs Cats 数据集。数据本身是猫狗图片,任务相对清晰,类别也比较均衡,所以 accuracy 可以比较直观地反映分类效果。

图 2:DogsVsCats 数据集中的部分样本
在预处理上,我把图片统一 resize 到 224×224。这个操作一开始看起来像是简单地把图片尺寸变统一,但后来复盘时我才真正理解它的必要性。原始图片大小不同,如果不统一尺寸,首先就没法在 PyTorch 里打包成一个 batch。一个 batch 通常是 [B, C, H, W] 这种规整的四维张量,同一批图片的高宽必须一致。
更进一步看,我自己写的 CNN 后面用了 Flatten + Linear。卷积和池化本身不一定特别怕图片尺寸变化,但一旦展平,向量长度就会和输入尺寸绑定。我的全连接层输入维度是按照 224×224 图像经过几次卷积池化后的特征图大小手动写死的。如果图片尺寸变了,展平后的向量长度就会变,后面的全连接层就接不上。所以 resize 不只是为了图片看起来一样大,而是为了让 batch 能组成、模型维度能对齐。224×224 也是 ResNet 等经典预训练模型常用的输入尺寸,后续做迁移学习也比较方便。
训练集里我还用了随机水平翻转和随机旋转。数据增强的本质不是简单“多造几张图片”,而是在标签不变的前提下,让模型看到同一类样本的更多合理变化。现实世界里的猫狗图片几乎是无限变化的,而训练集永远有限,里面还可能带有背景、光照、姿态这些伪特征。如果模型只看原始图片,可能会记住“这只狗在草地上”“这只猫在左边”这种偶然信息,而不是猫狗真正稳定的特征。随机翻转和轻微旋转就是告诉模型:狗翻过来还是狗,猫轻微歪一点还是猫。这样模型更容易学习对姿态和位置变化不敏感的特征。

图 3:数据增强后的样本变化
不过这个思想不能机械套用到医学影像里。自然图像里左右翻转通常不改变猫狗标签,但医学影像里的左右翻转、上下翻转、旋转可能会改变解剖语义。因此,数据增强必须结合具体任务来设计。
4. 数据划分:训练集、验证集和测试集
从模型能不能训练的角度看,其实只要训练集就够了。但从判断模型到底有没有泛化能力的角度看,必须有验证集和测试集。
训练集是模型真正拿来学习的,模型会根据训练集 loss 反向传播、更新参数。验证集虽然不参与参数更新,但它会影响训练过程中的决策,比如保存哪一轮权重、要不要 early stopping、要不要调整模型或参数。因此,验证集虽然没有直接参与反向传播,但它参与了模型选择。
测试集则应该像真正的观察组,只在最后使用,不介入训练和调参。这里最关键的区别是:验证集不参与参数更新,但参与模型选择;测试集既不参与参数更新,也不参与模型选择。只看训练集准确率是不可靠的,因为模型可能只是记住了训练样本,在训练集上分数很高,但遇到没见过的图片就不行。
这个认识对后续医学影像项目也很重要。尤其是医学影像数据通常比较少,如果测试集被反复查看和调参,就很容易高估模型的真实性能。
5. 模型结构:自定义 CNN 和 ResNet-18
这个项目里我做了两类模型:一个是自己写的简单 CNN,另一个是基于 ResNet-18 的迁移学习。
自定义 CNN 主要由卷积、ReLU、池化和全连接层组成。卷积层可以理解成一组可学习的特征探测器。不同卷积核会在图片上滑动,提取不同局部特征。浅层卷积可能学到边缘、直线、纹理、颜色变化这些低级特征,越往后可能组合出耳朵、鼻子、脸部轮廓这些更高级的视觉特征。这里很重要的一点是,卷积核不是人工固定好的滤镜,而是模型参数,和全连接层参数一样,会通过 loss、反向传播和优化器自动更新。
ReLU 的作用是引入非线性。如果网络里全是一层层线性函数,那么再多层叠起来本质上还是线性函数,表达能力很有限。ReLU 用很简单的方式引入非线性,让网络能够拟合更复杂的图像模式。池化则负责降低特征图尺寸、减少计算量,同时保留局部区域里比较强的响应,让模型对小范围的位置变化更鲁棒。简单来说,卷积负责找特征,ReLU 让网络有非线性表达能力,池化负责降尺寸、减计算、保留显著特征。
ResNet-18 的表现明显比自定义 CNN 更好。这个差距的核心不是简单一句“ResNet 更深”,而是 ResNet-18 带着 ImageNet 预训练得到的视觉能力来做猫狗分类。自定义 CNN 是从零开始学猫狗特征,所有卷积核都要靠这一个猫狗数据集一点点调出来;而 ResNet 已经在大规模自然图像数据上学过边缘、纹理、形状、动物轮廓、脸部结构这些通用特征。猫狗分类和 ImageNet 的图像分布又很接近,所以 ResNet 前面的特征提取层已经很好用了,只需要把最后的分类头改成 cat/dog 二分类,再训练最后一层,就能很快超过从零训练的 CNN。
我对这个对比的理解是:自定义 CNN 是从零学猫狗,ResNet 是带着已经学过的视觉经验来学猫狗。这也是迁移学习最直观的价值。
6. 训练机制:logits、loss 和反向传播
这个项目让我重新理解了分类模型最后输出的东西。模型最后输出的不是概率,而是 logits,也就是原始打分。比如猫狗二分类中,模型输出两个 logits,分别对应 cat 和 dog。单个 logit 的绝对数值不好直接解释,不同模型之间的 logits 也不能随便比较;真正有意义的是同一个模型、同一张图片下,不同类别 logit 的相对大小。哪个类别的 logit 更大,模型就更倾向于哪个类别。
二分类有两种常见写法。一种是输出一个 logit,用 sigmoid 变成“是不是狗”的概率,再用 BCEWithLogitsLoss;另一种是输出两个 logits,把 cat/dog 当作两个互斥类别,用 CrossEntropyLoss。这个项目用的是第二种。PyTorch 的 CrossEntropyLoss 内部已经包含类似 softmax 的处理,所以训练时不用手动加 softmax,直接把 logits 和整数标签传进去就行。它惩罚的是:模型没有把真实类别的得分提得足够高。
训练循环本质上就是一个反复改错的过程。先前向传播,把图片输入模型,得到 cat/dog 两个 logits;然后用损失函数把 logits 和真实标签进行比较,算出这次预测错得有多严重;接着 zero_grad() 清空上一轮残留的梯度,因为 PyTorch 默认梯度会累加;然后 loss.backward() 根据 loss 反向计算每个参数的梯度,包括卷积核和全连接层参数;最后 optimizer.step() 根据这些梯度真正更新参数。最简单的记法就是:forward 算输出,loss 算错误,zero_grad 清草稿纸,backward 算怎么改,step 真正去改。
这个训练闭环不只适用于猫狗分类,后面做 U-Net、3D U-Net、nnU-Net,本质上也还是这一套。
7. 训练模式、验证模式和 Early Stopping
训练和验证阶段还有一个容易混淆的点:model.train()、model.eval() 和 torch.no_grad()。
model.train() 和 model.eval() 不是在控制算不算梯度,而是在切换模型内部某些层的工作模式,比如 Dropout 和 BatchNorm。训练时用 model.train(),Dropout 会随机关掉一部分神经元,避免模型太依赖某些局部特征;验证和测试时用 model.eval(),Dropout 不再随机丢弃,而是让所有连接都参与推理。BatchNorm 也类似,训练时用当前 batch 的统计量,推理时用训练过程中积累的统计量。
torch.no_grad() 才是关闭梯度计算、节省显存和计算量的东西。所以验证和测试时通常两个都要写:model.eval() 负责切换推理模式,torch.no_grad() 负责不记录梯度。
在训练策略上,我后面加入了 Early Stopping。一开始我只是随便设几百轮,反正保存最佳权重。但后来发现,这样可能会浪费大量时间和电费。模型可能很早就达到一个比较好的验证效果,后面几百轮都没有新提升。即使后面从 85% 慢慢蹭到 86%,也未必划算,因为这个 1% 可能只是模型对验证集某些细节的偶然适应,带着过拟合风险。
Early Stopping 不是为了偷懒,而是在模型不再有效提升时及时停下来。它通常看验证集 loss,因为训练集 loss 只能说明模型越来越适应训练数据,不能说明泛化能力。验证集 loss 更能反映模型在未见数据上的拟合情况。当然在这个猫狗任务里,看验证集 accuracy 也可以,但 loss 通常更连续、更敏感。核心是:训练不是越久越好,要在效果、泛化和算力成本之间找平衡。
8. 实验结果与评价指标
| 模型 | 训练方式 | 测试准确率 |
|---|---|---|
| 自定义 CNN | 从零训练 | 86.1% |
| ResNet-18 | ImageNet 预训练 + 训练分类头 | 98.2% |
这个结果最重要的意义不是证明“猫狗分类做得很好”,而是让我直观看到了从零训练和迁移学习之间的差距。
Accuracy 在这个任务里是比较合适的指标,因为 cat 和 dog 类别比较平衡,错误代价也差不多。Accuracy 看的是最终答案对不对,loss 看的是模型给真实类别的概率够不够高。也就是说,我们既希望模型答得准,也希望它对真实类别有足够高的置信度。
不过 Accuracy 也有明显局限。它很怕类别不平衡。如果猫狗分类里有 9990 张猫、10 张狗,模型一直猜猫也能拿接近满分,但它根本没学会识别狗。所以不是“任务简单就能看 Accuracy”,而是“类别平衡、错误代价相近时,Accuracy 才比较可靠”。
到了医学影像里,这个问题会更明显。医学分类任务常常存在类别不平衡和漏诊风险,只看 Accuracy 可能掩盖模型对少数异常样本的失败。因此还需要关注 sensitivity、specificity、precision、recall、F1、AUC 等指标。如果是分割任务,还要看 Dice、IoU、HD95 这类空间重叠和边界指标。
9. 项目不足与下一步
这个项目最大的问题不是“不够高级”,而是它本来就不是科研型项目。它更像一个 PyTorch / CNN / 迁移学习入门项目,价值在于走通完整闭环,而不是把猫狗分类做成一个复杂科研课题。
如果从工程角度看,它还有一些可以优化的地方。比如数据划分可以做分层抽样,保证 train、val、test 中 cat 和 dog 的比例更稳定;可以加入断点续训,不过这个小模型其实不是刚需;代码工程化也还有提升空间,比如训练逻辑、配置管理、实验记录可以更加统一。不过这些问题在后面的项目里已经逐步改进了。
如果从实验设计角度看,它确实缺少系统对比。现在主要是自定义 CNN 和 ResNet-18 的对比,更多是一次模型和代码尝试,不是完整的消融实验。如果只补几个小实验,我觉得最有价值的不是继续卷猫狗分类准确率,而是围绕关键理解点做实验:比如有无数据增强对泛化的影响,ResNet 是否使用 ImageNet Normalize 的差异,以及 ResNet 只训练最后 fc 层和解冻部分层微调的区别。这些实验能连接到后面更重要的泛化、输入分布和迁移学习问题。
另外,使用 ImageNet 预训练 ResNet 时,输入预处理最好加入对应的 ImageNet Normalize。这个项目当时更关注流程跑通,没有专门对 Normalize 做实验,后续如果要让迁移学习流程更规范,可以补上这一点。
这里我也意识到一点:不是所有能优化的地方都值得优化。这个项目的价值在于完成入门闭环,而不是把猫狗分类榨干。
10. 我真正理解了什么
复盘这个项目之后,我觉得它真正带给我的不是“我会做猫狗分类了”,而是几个更基础的理解。
- 我理解了 Resize 不只是图片缩放,而是 batch 组织和模型维度对齐的需要。
- 我理解了数据增强不是简单扩充数量,而是在有限数据里制造合理变化,让模型学习更稳定的不变特征。
- 我理解了验证集虽然不参与反向传播,但会参与模型选择,因此最终还需要独立测试集。
- 我理解了 logits、softmax、CrossEntropyLoss 之间的关系,也知道训练时 loss 通常直接吃 logits。
- 我理解了
model.eval()和torch.no_grad()的区别。 - 我理解了 Early Stopping 不是偷懒,而是训练策略的一部分。
- 我也理解了迁移学习不是简单换一个更大的模型,而是复用大规模数据上学到的特征表示。
这些东西都不复杂,但它们构成了我后面继续学习医学影像项目的基础。
11. 和后续医学影像项目的关系
DogsVsCats 不是医学影像项目,但它是我进入医学影像深度学习之前的一个训练入口。后面的医学影像分割任务会复杂很多:输入可能是 2D/3D 的 CT 或 MRI,输出不再是一个类别,而是每个像素或体素的类别;loss 可能从 CrossEntropy 变成 Dice、CE 或二者组合;指标也会从 Accuracy 变成 Dice、IoU、HD95 等。
但从项目流程看,很多东西是一样的:数据预处理、Dataset/DataLoader、模型前向传播、loss、反向传播、验证、保存权重、测试评估、日志记录、配置管理。这些在 DogsVsCats 里第一次被完整串起来,后来只是换成更复杂的数据、更复杂的模型和更严格的评价方式。
所以我不会把这个项目当成核心求职项目来讲,但我会把它看作后续项目的工程起点。它让我第一次从一个简单任务中建立起深度学习项目的完整训练闭环。
12. 总结
这是我系统学习深度学习后完成的第一个完整 PyTorch 图像分类项目。项目中我实现了自定义 CNN,并使用 ResNet-18 做迁移学习,对比了从零训练模型和预训练模型的效果。虽然任务本身比较基础,但我通过这个项目走通了数据预处理、DataLoader、模型构建、loss、optimizer、训练验证、early stopping、日志记录、命令行参数配置、README 和测试集评估的完整流程。后续我做医学影像分割项目时,很多工程习惯和训练流程都是从这个项目延续过去的。
所以,这个项目不是我的核心项目,但它搭建了我后续深度学习项目的工程骨架。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)