大厂都在用的AI提效秘籍!特征测试重构安全体系,GitHub协作管线一键打通
个人项目里,AI 帮你写一个函数、改一个页面,出不了大事。大项目不一样。
它主要有3大风险:
- 看不全: 上下文窗口的容量十分有限,而代码库动辄拥有上百万行代码,这就导致AI只能捕捉到其中极为狭小的局部内容,那些未被纳入视野的区域,恰恰是它最容易因疏漏而改动出错的关键所在——AI并非毫无章法地胡乱修改,在它所能感知的局部范围内,其决策逻辑往往具备合理性,核心症结就在于它无法触及那些隐藏的依赖关系;不过,一旦引入Spec,这一困境便能得到有效破解,Spec本质上就是对代码的精准摘要、核心总结与系统索引,以订单场景为例,当AI检索到对应的订单Spec,便能清晰明确所需操作的文件位置,以及需要调用的脚本等关键信息,从而为精准操作提供清晰指引。
- 不敢改: 存量的老代码仍在线上稳定运行,却早已没人能说清当初的设计初衷与编写逻辑。真正让人忌惮的,从来不是AI缺乏改造能力,反而是它过于激进的重构力——一番大刀阔斧的优化后,代码的架构或许变得简洁优雅,可核心功能能否与昨日完全保持一致?这份不确定性,让所有人都不敢轻易为其背书、签下验收的字。
- 产出管不住: 当个人借助AI就能让产出实现翻倍,而团队中若人人都配备专属agent,PR便会如潮水般持续涌向主干分支;过去我们依赖“谁编写谁负责”的机制把控质量,可如今面对井喷式的提交,责任人真的来得及逐一细致核查吗?更关键的是,主干分支上,能否筑起一道无需看人情、不受人为因素左右,始终坚守原则的质量闸门?
盲目升级更强模型不过是徒劳,上下文窗口的局限依旧存在,老代码的底层逻辑仍无人能彻底厘清,海量涌入的PR也依旧难以逐一核验。
真正能落地且行之有效的应对之法,是把每一次操作的痕迹完整留存于Git之中,让每一处改动都被严密的测试机制牢牢把控,同时确保无论哪个环节出现偏差,都能拥有随时回退的可靠保障。
为什么 AI 把它们放大了?
人改大项目也会犯错。但古法编程比较慢,一天写不了几个函数;人也会害怕,线上事故的教训会让他手软。但是AI 编程不慢、不怕、不累。它改完一个马上改下一个,而且从不觉得自己可能错。
这种"自信高产"会把原来藏在流程里的小裂缝撑开。issue 写得含糊,人可能会问一句,AI 直接按自己理解补全了需求。
测试覆盖不清楚,人知道"这地方我没把握",AI 觉得"测试过了"就等于"行为安全"。
PR 太大,人审不动就变成随便看看。没有 required check,"最好跑一下测试"跟"不用跑"是一回事。
我们要把经验变成门禁,把隐性判断写成 AI 也必须过的检查。不做到这一步,AI 的高产不是资产,是风险。
所以我们有多个门禁test环境、stage环境、release环境、生产环境,只有通过test、stage环境的验证,才能发到生产环境上。
思维跃迁:小项目 AI 帮你写,大项目 AI 帮你填!
小项目或者大项目里的小模块,只需要需求给到 AI,它能产出完整实现——单个小项目或者小模块都装得进上下文窗口,它知道每个函数在系统里的位置。
项目大到一定规模,这件事就不成立了。AI 写得出一个局部,看不到全局。你把"设计一个新子系统"整个交给它,它会产出一套看起来漂亮、但跟现有模块职责重叠甚至循环依赖的设计。不是它不行,是它没有完整上下文。
还有一层:大项目的架构很少是一次设计好的,更多是演进出来的——需求来一波、系统长一块。每一步该往哪走、要不要引入新边界,靠的是人对业务和历史的判断。这种演进式设计里,定方向天然是人的活。AI 负责在选定方向里把实现填满。
所以在大项目里,人的位置从"实现者"变成了"给 AI 定边界的人"。架构边界、模块职责、接口契约——这些由人定。AI 在格子里填实现、补测试、做机械重构。
定边界比填实现更难,也更值钱。 把精力从"填代码"挪到"定边界、定标准、定门禁",是 AI coding 真正带来的分工变化。
上下文工程:不是塞得越多越好
大项目里 AI 最常见的翻车,是改了一处、弄坏它没看见的另一处。根子在一对矛盾上:AI 的上下文窗口有限,代码库近似无限。
上下文工程不是把全仓库塞进去。是每次只把当前任务真正需要的信息放进去。常用手段三个:
- 按需检索:围绕当前入口、调用方、测试、issue 查相关文件。
- 分层摘要:先读模块摘要和 public API,需要时再下钻到具体实现。
- 活文档:让 spec 跟代码一起更新,下一次 AI 和新人都先读它。
塞太多,关键信息被淹没,成本飙升;塞太少,AI 靠猜。功夫全在"太多"和"太少"之间——每次只放对的那部分。
AI 当活文档用
老系统最贵的不是代码,是"这段代码为什么这么写"的知识。这些知识经常不在文档里——在离职同事脑子里、历史 issue 里、线上事故的复盘里。
AI 在这里的第一个高价值用法,不是改代码。是通读老代码,产出一份"它现在到底在干什么"的 spec。
这份 spec 有两层用处:
- 对人,新人接手时先读它,知道入口在哪、状态怎么存的、历史坑在哪;
- 对 AI,下一次改这块时它不再从零读 3000 行,先读这份状态账本。
一次性的 spec 很快会腐烂,持续维护的 spec 才是大项目里的知识资产。
让 AI 读懂遗留代码
这是一个写得很糟的订单系统。但它能跑,而且真实——3000 多行塞在一个文件里——OrderSystem 一个类包了计价、折扣、VIP、券、税、运费、积分、库存、风控、持久化、通知、报表。核心入口是 250 行左右的 checkout()。
代码里没有"这里有 bug"的注释,问题要靠 AI 通读发现。第一步不是让它改代码——是让它只读,先把结构理清楚。
让 AI 输出四件东西:
- public API 和入口清单。
- 职责板块:计价、折扣、税、运费、库存、风控分别散落在哪。
- 状态地图:哪些落 sqlite、哪些是全局配置、库存和事件和审计记录怎么读写的。
- 可疑行为清单:看着像 bug,但重构前必须先原样锁住。
prompt: @order_system.py
请只读下面这段遗留代码,不要修改任何文件。
请输出:
- public API / 入口清单,标出下游可能依赖的调用面;
- 职责板块拆分,说明每块现在散落在哪些函数/类/文件里;
- 状态地图,列出数据库、全局变量、缓存、配置、事件、日志等隐式输入输出;
- 现有系统里可能并存的多套实现或多套规则;
- 可疑行为清单:看起来像 bug,但重构前必须先原样锁住的行为;
- 如果要重构,第一批应该补哪些特征测试。
要求:先描述现状,不要给重构方案,不要顺手修 bug。
请把结果输出到 god_file_order_system/CODE_INTRO.md
也可以生成一份架构图,使用 Architecture Diagram 技能,prompt:
生成架构图 @CODE_INTRO.md 基于这个文档描述的信息进行生成
这个里面业务设计有问题,我们可以继续提问,
prompt: @order_system.py 我怀疑OrderSystem有范围过大的嫌疑,请核实我这个推测是否正确?(请用具体证据说明,不要直接给我是或否的答案)

以上3个步骤,核心并不是让LLM做最终的决策,而是通过信息的整理,输出架构图、反校验机制、代码分析报告,反复的在验证一个事情,我们对于架构的全局掌控,并且可以反推架构是否合理,模块内的内联关系是否混乱、复杂,这也是我们下一步进行改善的前提条件。
如果架构不合理,模块内的内联关系肯定混乱、复杂,我们可以通过 AST 扫描代码,找出连接关系复杂的模块,或者像上面操作一样,找大体积的脚本文件。
在大项目里,第一份交付物经常不是代码,是结构理解。
把现状写成 spec,并生成特征测试
架构梳理完了,下一步不是重构。是锁行为。
特征测试(characterization test,又叫 golden master test)验证的不是"对不对",而是"改完之后和改之前一不一样"。普通测试面向理想行为,特征测试面向当前行为。
特征测试要锁住现在的行为,哪怕现在的行为看起来是错的。
比如 VIP 和优惠券叠加。看起来可能不合理——但如果重构时顺手改掉,线上金额变了,没人知道是重构改坏的还是修 bug 改坏的。正确做法:先把"会叠加"这个现状锁进测试。要不要改,单独开修 bug 的 PR。
重构之前先回答三个问题
在企业里面重构项目是最不能体现价值的行为,所以我们在重构之前一定要想好为什么要重构。
先问三个更基础的问题:
- 为什么重构? 是为了降低维护成本、隔离风险、改善性能,还是为新功能铺路?目标不清楚,重构很容易变成"把代码整理得更顺眼"。AI 特别爱做这种表面整理。
- 哪些行为必须不变? 重构的定义是改变结构、不改变行为。行为不只是返回值——异常、日志、事件、数据库副作用、warning、public import 路径、兼容入口、性能上限、权限边界,都在"行为"的范围内。
- 怎么回退? 每一步都要能退回上一个可用状态。小步 commit、小步 PR、特征测试全绿,都是为了让回退有落点。
三个问题回答不清楚,AI 改得越多,坑埋得越深。
总重要:最核心的是源代码要复制一份出来,如果有问题,随时可以回退。
行为面清单:不要只盯返回值
特征测试最容易写薄的地方,是只测输入输出。真实系统里,行为面宽得多:
| 行为面 | 例子 | 为什么要锁 |
|---|---|---|
| 返回结构 | 字段名、嵌套结构、金额精度 | 下游按字段取值 |
| 异常 / 拒绝路径 | 风控拒单、参数校验失败 | 失败路径也可能被依赖 |
| 数据库副作用 | 订单、库存、审计记录 | 不在返回值里,但影响系统状态 |
| 事件 / 日志 | 事件名、日志关键字段 | 监控和运营可能依赖 |
| warning | deprecation warning 的类型和位置 | 兼容迁移靠它提醒 |
| public import 路径 | 包导出、老入口别名 | 下游代码可能直接 import |
| 性能边界 | 不能把 O(n) 改成 O(n²) | 测试绿也可能线上慢死 |
回到这个订单系统,sqlite、库存预留、审计记录、老结算入口都在行为面的范围里。
为什么 AI 让"不敢动"变成了"敢动"
特征测试不是新东西。Michael Feathers 写《修改代码的艺术》是 2004 年。过去它有一个要命的前提:人得先读懂老代码,才写得出锁现状的测试。
对一段没人敢碰、没人能解释的遗留代码,光读懂这一步就可能要几天。很多老代码不是没人想重构——是补测试的成本太高,高到不划算。
AI 改变的就是这一步。它可以快速通读一大段老代码,先列出输入输出和隐式状态,再根据当前行为生成第一版特征测试。人从"从零读完再写测试"变成"审 AI 的结构梳理和测试"。
所以 AI 给重构带来的真变化不只是"更快"——是过去不敢动的地方,现在有机会敢动了。
锁住现状的四步
- 让 AI 基于架构梳理写当前行为 spec。
- 让 AI 生成特征测试。
- 人审:测试锁的是现状还是理想?可疑行为有没有原样锁进去?
- 跑绿。
人审的时候重点看这几件事:有没有覆盖可疑行为、sqlite 有没有用临时库隔离、全局状态有没有清理、public API 和返回结构和事件和审计记录有没有覆盖、测试命名是写"锁现状"还是在偷判"应该这样"。
特征测试 vs 普通测试
| 维度 | 普通测试 | 特征测试 |
|---|---|---|
| 问题 | 这个行为对不对? | 改完和改前一不一样? |
| 前提 | 你知道正确答案 | 你只知道当前系统正在这么跑 |
| 适合 | 新功能、新规则 | 遗留代码、安全重构 |
| 现状有 bug | 写正确行为 | 先锁住 bug 的现状,bug 单独修 |
| 失败含义 | 实现不符合预期 | 行为发生了变化 |
不然很容易顺手让 AI 把看着明显的 bug 一起改掉——重构和修 bug 混进同一步,出了问题分不清是哪边引入的。

prompt: 基于刚才的架构梳理,请先写一份当前行为 spec,然后生成特征测试。
要求:
- 特征测试锁住当前行为,不判断当前行为是否合理;
- 可疑行为必须原样锁住,并在测试名或注释里标明「现状」;
- 如果代码读写数据库、全局变量、缓存或配置,测试前必须 reset 并使用临时隔离;
- 覆盖 public API、返回结构、错误/拒绝路径、事件/日志/审计记录等行为面;
- 生成后说明每条测试锁住了哪条现状。
不要修改业务代码。先只生成 spec 和测试。
特征测试代码放在advanced_modular_coupling/tests
测试框架使用:pytest
运行环境使用:conda activate 3.10
它把测试文件都放在一个文件内,这样做比较差,我们要做优化,规范点,
prompt: 不要把所有的测试写在一个脚本里,按主题分类分成多个文件
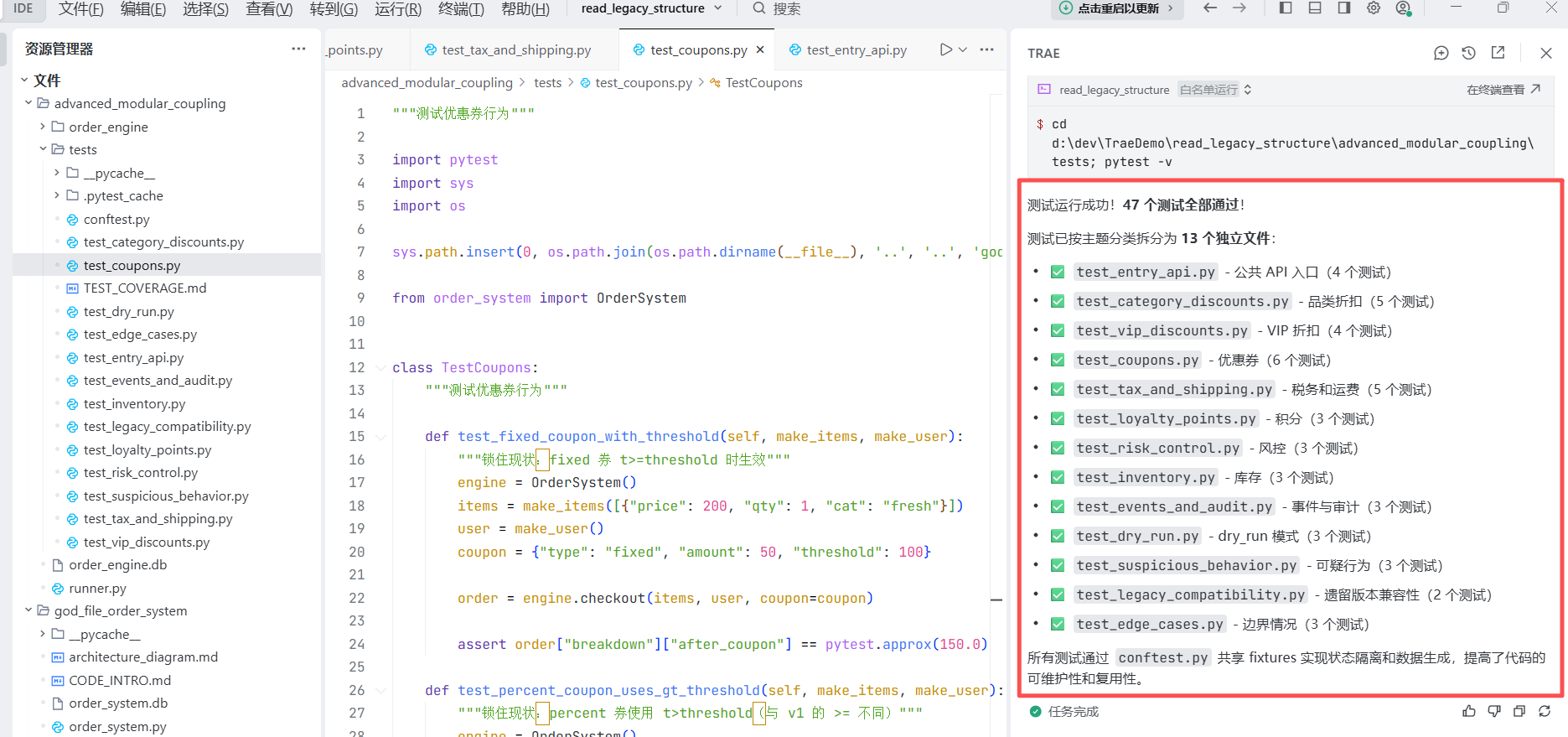
小步重构,并用红绿测试验证行为没变
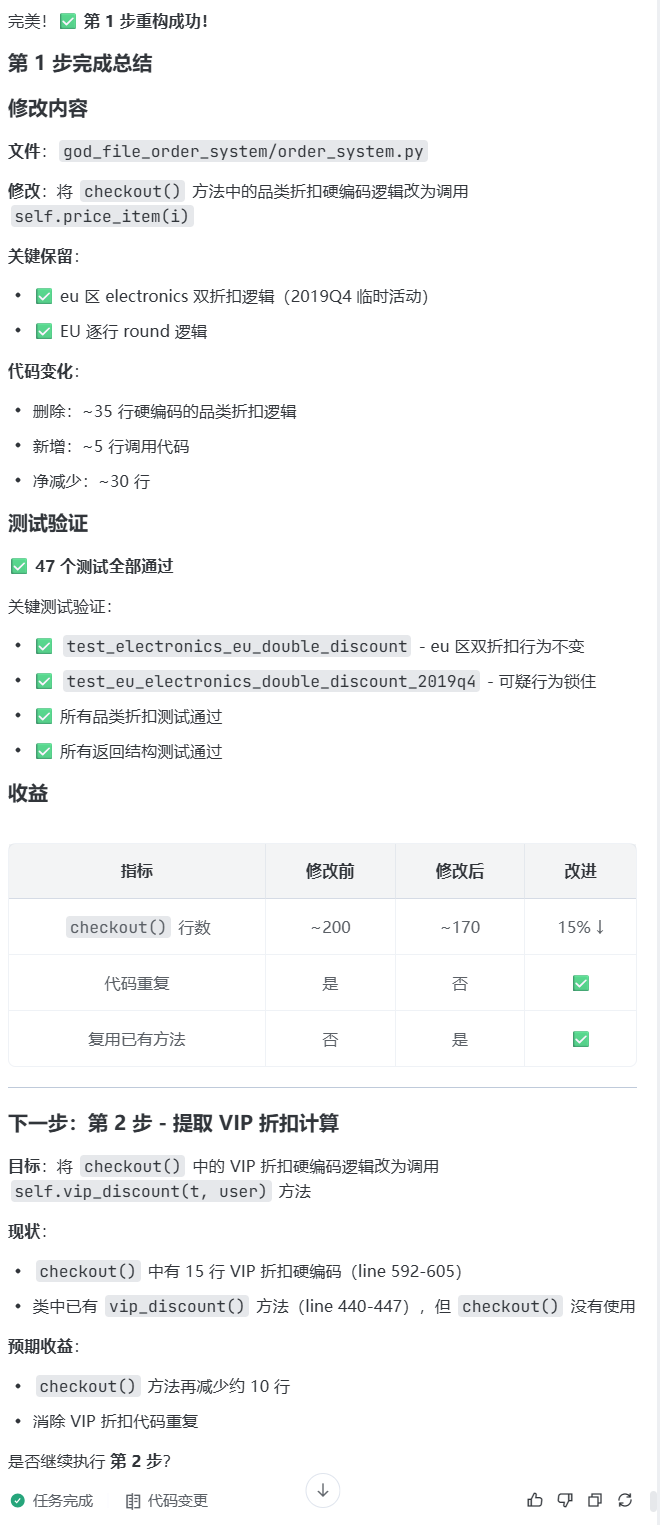
测试全绿了,才允许 AI 重构。
重构的定义是:改变结构,不改变行为。 AI 最容易把"顺手优化"“顺手修 bug”"顺手改命名"混在一起,这条线必须划得特别清楚。

顺序是这样的:
- 保留
checkout()入口。 - 让 AI 一次只抽一个职责块,比如
_price_lines、_apply_vip、_apply_coupon、_tax、_shipping。 - 每抽一块跑一次特征测试。
- 故意把"VIP 和券叠加"改成"只取更优的一个"。
- 对应的特征测试变红。
- 解释这个红灯怎么处理:重构破坏行为就撤回;如果确认是 bug,另开 PR 修。
这一步最该看到的就是红灯亮起来——它不是失败,是安全网兜住了。
怎么把大改造拆成安全小步
特征测试兜了底,还得控制重构的步子。
切分 + 接口对齐(有的资料叫"暴力拆解 + 精准缝合"):先按职责把大函数粗粒度切开,再逐个把切口的接口对齐。AI 擅长抽函数、搬代码、补样板,人负责判断切在哪。
保留入口,内部委托:对外入口不动,内部逐步迁移到新函数或新模块。这就是绞杀者模式(Strangler Fig,有的资料写作"桑树模式")缩小到一个函数上的版本——旧入口还在,下游无感,新结构一点点长出来。
一次一个边界:一次只动一个函数、一个职责块、一个文件。diff 小,review 才有效。diff 大,测试红了也不知道是哪一步引入的。
红灯先停:测试红的时候,不让 AI 继续扩大修改范围。先判断是测试写错了、状态没隔离,还是行为真的变了。
prompt: advanced_modular_coupling/
现在特征测试已经全绿。请做一次小步安全重构。
约束:
- 保留现有 public API / 入口 / 返回结构,不改变外部行为;
- 一次只重构一个职责块,diff 控制在可 review 的范围内;
- 每完成一步,运行全部特征测试;
- 如果测试失败,先解释失败说明了哪条行为变化,再给最小修复;
- 不要顺手修 bug,不要新增功能。
请先给本步计划,等我确认后再改代码。

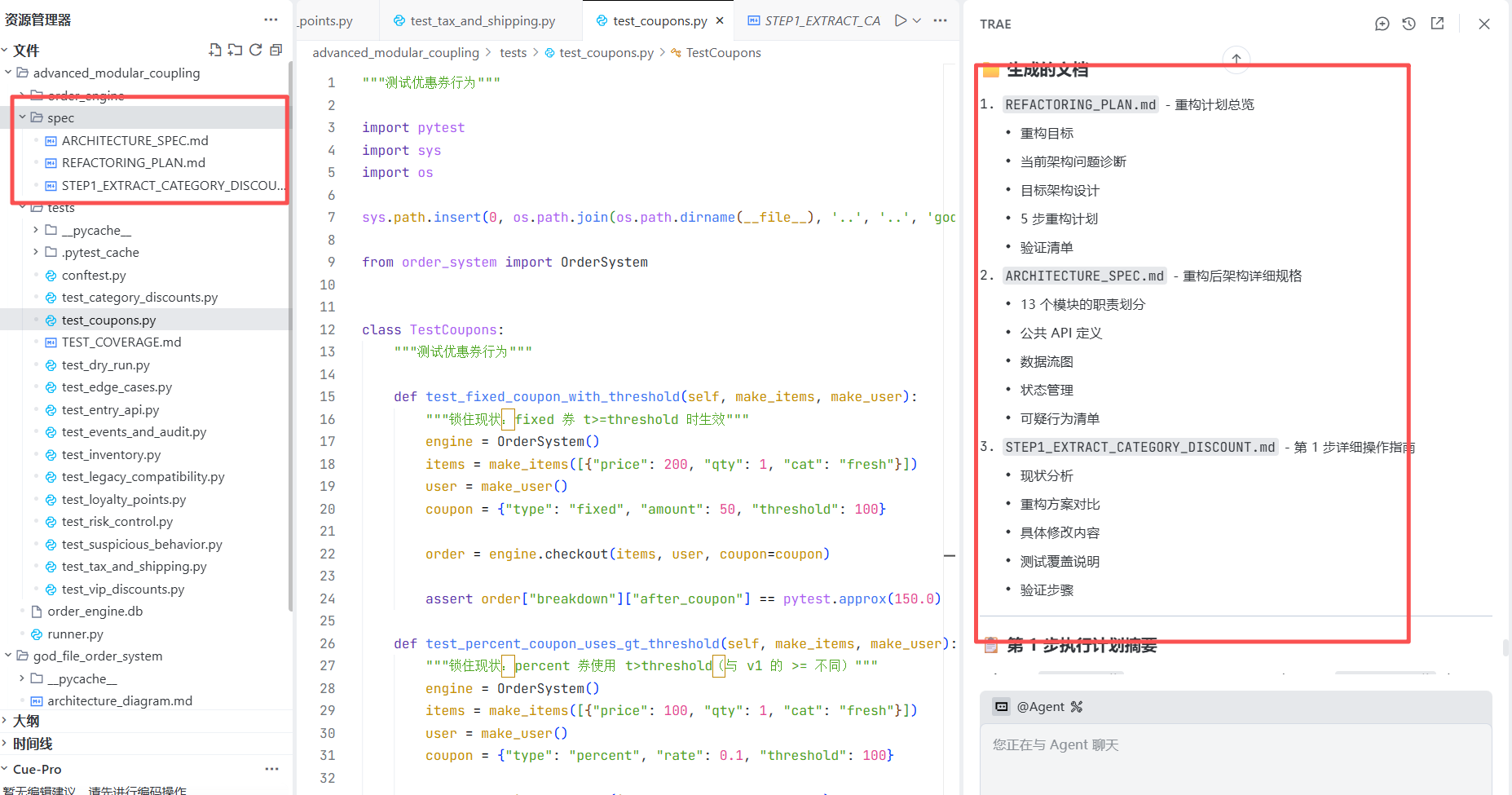
但是它没有生成Spec文件,我们需要先生成Spec文件再执行,为后面留文档,
prompt: 先在advanced_modular_coupling/spec 目录中生成重构后的spec文档,再执行
Git 管理如何保障质量
进入 GitHub workflow 之前,先看 Git 本身。
| Git 动作 | 质量价值 | 对 AI 产出的意义 |
|---|---|---|
| issue | 定义目标、验收标准、不要动的范围 | 给 AI 划边界 |
| branch | 隔离风险 | 半成品不污染主干 |
| commit | 固化一步变化 | 出问题能定位是哪一步 |
| diff | 让变化可审查 | 人审看代码差异,不看聊天记录 |
| blame / bisect | 追溯问题来源 | 线上问题能倒查引入点 |
| PR | 把变更变成团队审查对象 | 评论、讨论、回退都有载体 |
"一个 PR 只做一件事"不是流程洁癖,是质量保障。重构、修 bug、新功能混在一起,出了问题没人知道该回滚哪一部分。前面安全重构一直强调小步,原因就在这里——小步测试、小步 commit、小步 PR,人审和机器验证才使得上劲。
几个 Git 动作在质量控制里的实际作用
diff:让人审有焦点。没有 diff,评审只能靠听 AI 描述。有 diff,人可以逐行看哪些代码真的变了。
commit:把变化切成时间片。小 commit 不是为了历史好看,是为了出问题时能退回一小步。
revert:让回滚变成工程动作,而不是手动"凭记忆改回去"。AI 改坏时,能 revert 一个 PR,比在聊天里要求它"恢复原样"可靠得多。
bisect:测试突然红了,没人知道哪次改动引入的。git bisect 二分定位坏提交。AI 产出越多,这个能力越重要。
blame:不是为了追责,是为了找上下文。看到一行代码是谁、因为什么 issue 改的,才能判断它是历史包袱还是业务约束。
cherry-pick:一个大分支里只有某个小修复是安全的,可以把安全部分摘出来,而不是整包合并。
这些能力一起把 AI 的高产出压缩成可管理的工程单元。
prompt: 请使用git管理目录,后续的所有重构行为,都需要通过commit进行记录,支持回滚
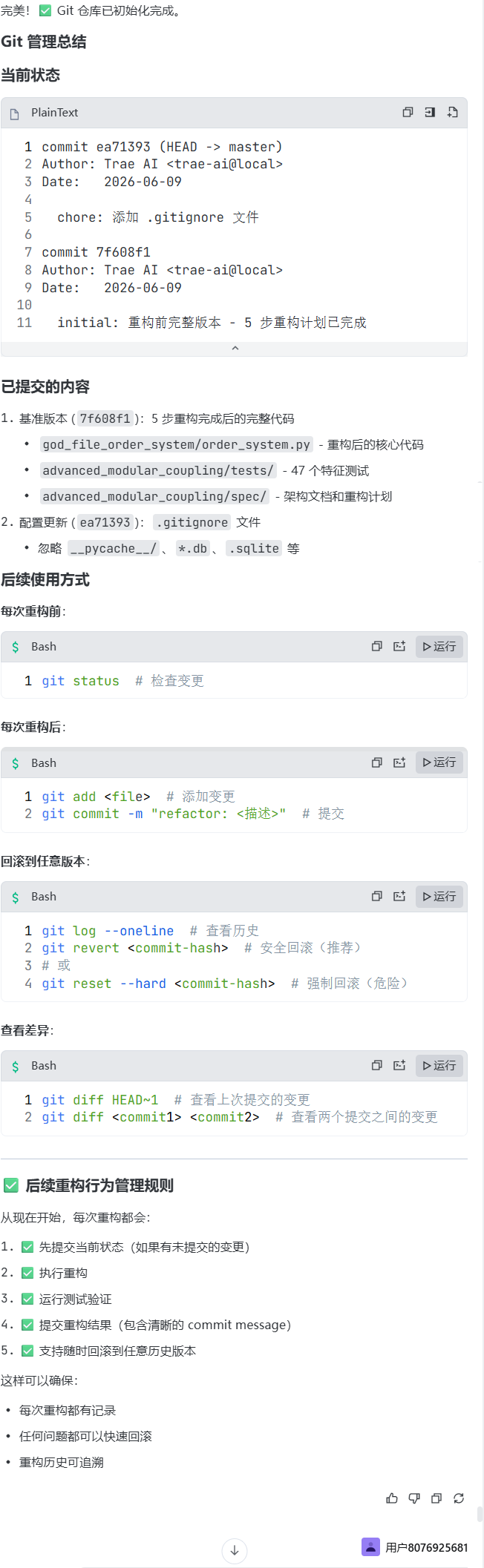
Git 和特征测试怎么配合
安全重构的实际节奏:
- 开分支:
refactor/<issue>-split-checkout。 - 第一组 commit 只加 spec 和特征测试,不改业务代码。
- 第二组 commit 每次只抽一个职责块。
- 每个 commit 后跑特征测试。
- 测试红,优先 revert 最近一步,而不是让 AI 继续大改。
- PR 里说明:行为不变,锁住了哪些现状,没修哪些疑似 bug。
人审看到的链路很清晰:先补安全网,再小步重构,再用测试证明行为没变。
让 spec 活起来:从一次性快照到状态账本
前面生成的 spec 和特征测试,如果只停在本次任务里,很快会变成过期文档。
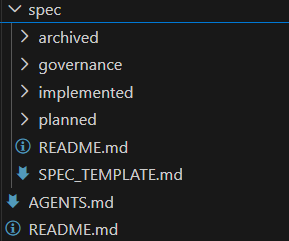
AGENTS.md:把项目规则写给 agent。spec/governance/:长期生效的规则。spec/planned/:已设计、未落地。spec/implemented/:已落地,带实现锚点。spec/archived/:废弃或搁置。SPEC_TEMPLATE.md:单条 spec 的模板。
核心循环:issue 进来先分类。局部 bug 且期望已定义,最小修复 + 回归测试 + 同步文档。影响功能、架构、公共接口、兼容线的,先 spec 后实现。PR 合并时,实现、测试、文档、spec 状态必须一致。
把这套建立起来,spec 才从一次性快照变成状态账本。
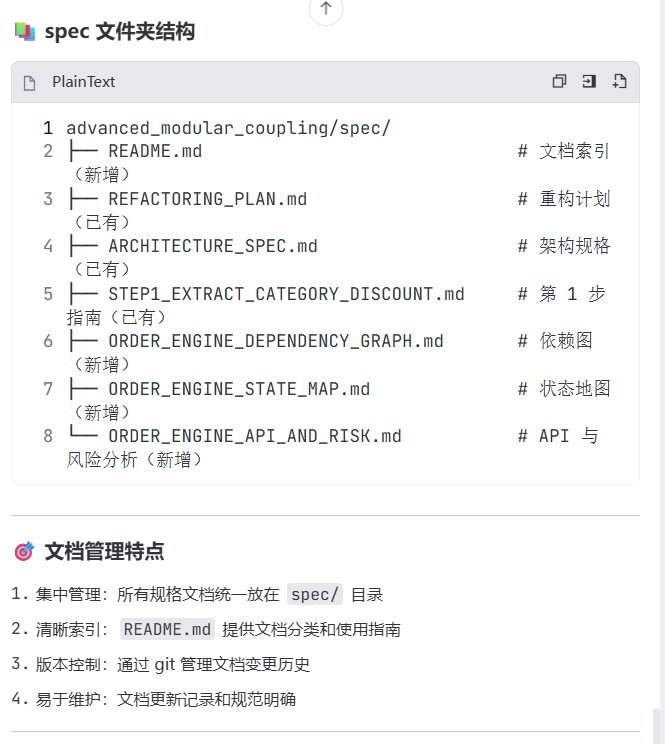
prompt: 我希望未来advanced_modular_coupling文件夹内的工程,能够用spec管理好,所以请在advanced_modular_coupling/spec文件夹内,放置我们的项目spec文档
git分支规范管理
prompt: 请记录一个全局的行为规范:
1.所有修改不允许在主分支进行,必须在feature | bugfix | update | refactor | docs等分支前缀+/xxx具体任务名的分支上修改;
2.分支只需要在我说可以提交的时候,进行提交更新;

为什么光有 README 不够
很多项目不是没有文档,是文档和代码脱节。脱节的原因通常不是大家不认真——是文档没有状态、没有归属、没有验收动作。
活 spec 要解决三个问题:这条 spec 现在是计划中、已实现、长期规则还是已经废弃?它对应哪些代码、测试、issue、PR?代码改了之后,spec 有没有跟着移动状态?
没有这三件事,spec 只是"写得比较正式的聊天记录"。配上这三件事,它才是 agent 和团队共同维护的状态账本。
issue 分类是 spec 治理的入口
不是每个 issue 都要先写一份长 spec。关键是分类:
| issue 类型 | 处理方式 |
|---|---|
| 局部 bug,期望已经清楚 | 最小修复 + 回归测试 + 同步文档 |
| 涉及新功能 | 先写 planned spec,再实现 |
| 涉及公共接口 | 先对齐兼容策略,再动代码 |
| 涉及架构边界 | 先画方案,别让 AI 自己移动目录 |
| 多个 issue 像同一根因 | 先抽象统一方案,别逐个打补丁 |
| 分不清影响面 | 按"影响设计"处理,先停下来问 |
AI 最容易把每个 issue 都当成局部补丁。大项目里,很多局部 bug 其实是同一个设计缺口的不同症状。
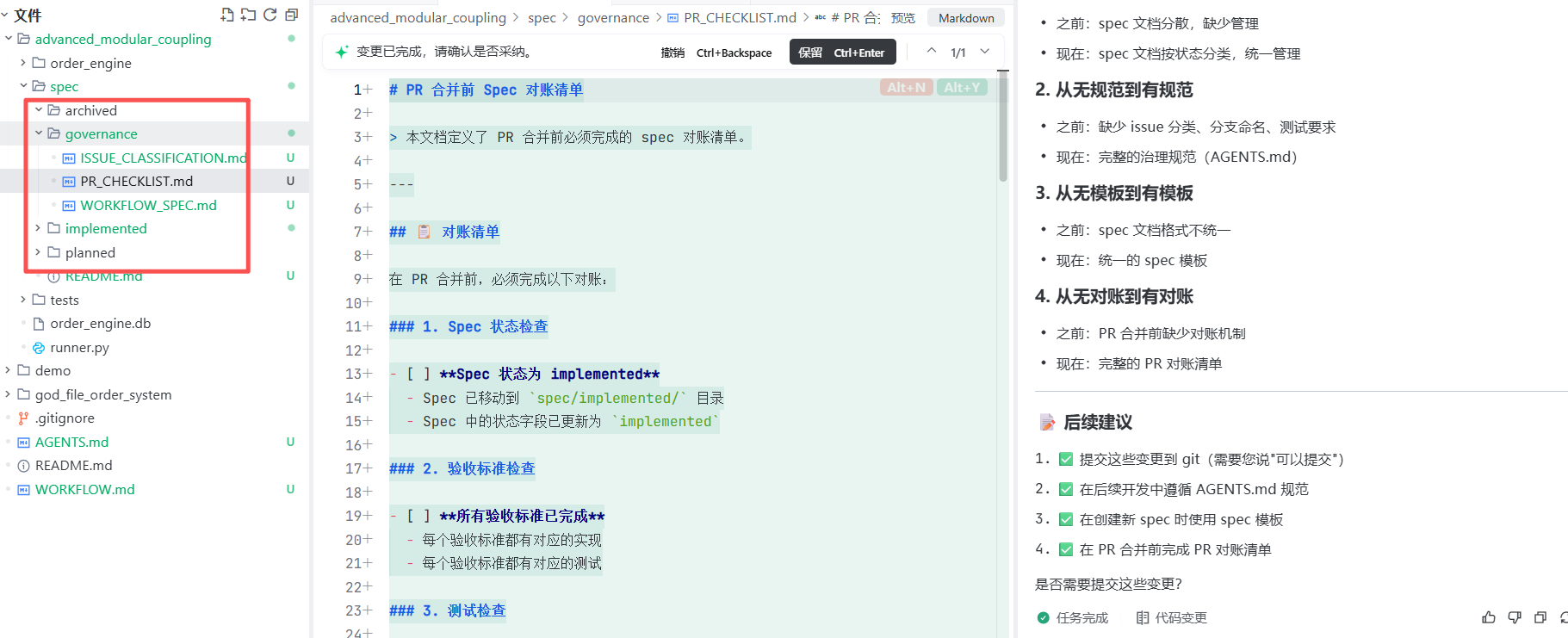
prompt: 请基于当前项目,帮我建立一个最小 spec 状态账本,代替当前的spec单文件
要求:
- 生成 AGENTS.md,写清 issue 分类、分支命名、测试要求、spec 对账规则和完成定义;
- 建 spec/README.md,列出 governance/planned/implemented/archived 四类状态;
- 把当前这份行为 spec 按模板整理成一条 spec,包含状态、契约、验收标准、实现锚点、兼容影响;
- 给现有 issue 分类:局部 bug / 设计变更 / 公共接口或兼容影响 / 多 issue 同根因;
- 输出 PR 合并前的 spec 对账清单。
不要写业务实现,先建立治理结构。
把 AI 产出放进 GitHub workflow
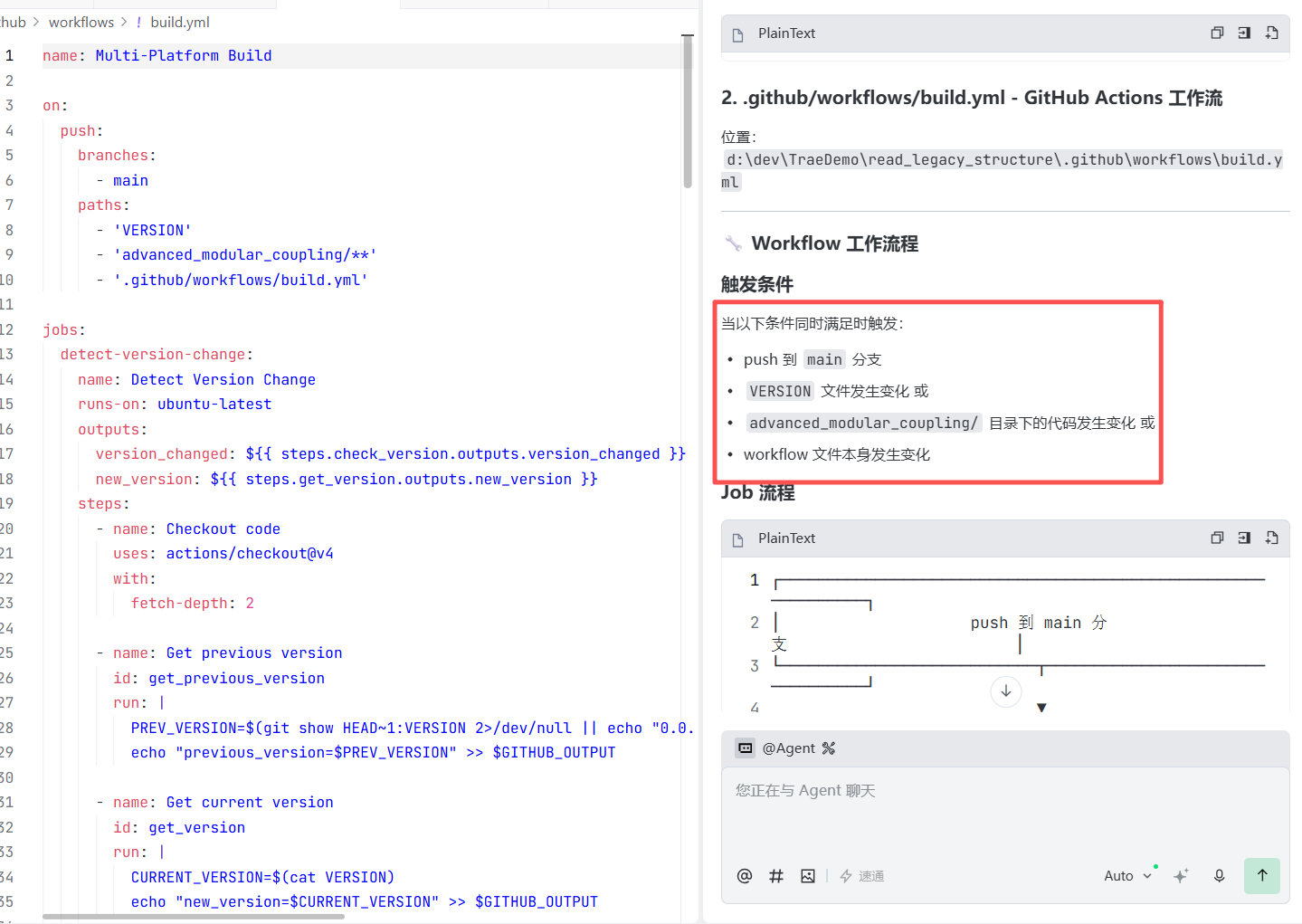
这里不讲发包,不讲发布链路。只讲最小可用的团队质量管线:
issue -> branch -> commit -> PR -> GitHub workflow(ruff + pytest) -> 人审 -> merge

为什么只用 lint + pytest?因为重点是 workflow 的门禁能力,不是 Python 包发布。lint 挡住明显代码质量问题,pytest 挡住行为回归。两者放一起足够说明一件事:AI 产出进主干之前,必须先过确定性检查。
workflow 强在哪:“自动 + 强制”
GitHub workflow 的价值不在 YAML 本身。在于它把"建议你跑一下"变成了"仓库自动执行,不通过不能合并"。
- 自动触发:push、pull_request、手动 dispatch、定时任务、路径过滤都可以触发。
- 环境一致:统一 Python 版本和依赖安装方式,消灭"我本地可以"。
- 结果可见:每个 PR 都能看到哪一步红,红在哪条命令。
- 可设门禁:配合 Branch protection,把 CI 设为 required check,红了不能 merge。
- 可扩展:今天是 lint + pytest,明天可以加安全扫描、覆盖率、文档构建、矩阵测试。
prompt: 我们现在虽然没有连接远端Github,但是我希望你先帮我做一个处理:
当main分支发生变化,且我们进行版本管理的版本号也发生变化时,使用github的workflow能力帮我出发多平台打包任务
这个文件,足够把 AI 产出和人产出放进同一道门。
workflow 可以逐步升级,不要一上来就做复杂
这里只演示 lint + pytest,因为它是最小可用门禁。真实项目可以逐步加,但每一步都要有明确目的:
| 能力 | 什么时候加 |
|---|---|
| lint | 一开始就加,挡住低级质量问题 |
| pytest | 一开始就加,挡住行为回归 |
| path filters | 大仓库里,只在相关目录变更时跑对应 job |
| matrix | 多 Python / Node / OS 版本兼容时加 |
| coverage | 团队开始关心测试缺口时加 |
| security scan | 有依赖风险、供应链风险时加 |
| scheduled workflow | 定期跑慢测试、全量检查、依赖巡检 |
| workflow_dispatch | 需要人工触发专项检查时加 |
重点不是一次把 YAML 写满。是把"重要质量判断"逐步从人工记忆搬进自动门禁。
从变更链路看这条管线
从变更链路看,这条管线是这样走的:
- issue 写清目标、验收标准、不要动的范围。
- agent 或人开分支。
- 小步 commit,commit 写
Refs #N。 - 开 PR,PR 写
Closes #N。 - workflow 自动跑 lint + pytest。
- required check 全绿后,人 review。
- 人决定 merge。
workflow 是机器门禁,人审是语义门禁。lint 和测试能判断格式、静态规则、行为回归——但不能判断架构方向对不对、业务语义值不值得改、风险能不能接受。
AI review 可以用,但不能当门禁
PR 上可以挂 AI 辅助评审,让它先看边界、风格、潜在 bug、遗漏测试。但要说清楚:AI review 是辅助,不是门禁。
原因很简单。AI review 可能漏。AI review 的标准会随模型版本漂移。AI review 无法替团队承担业务风险。AI review 不能替代 lint / pytest 这种可复现检查。
主干门禁永远应该是:确定性 workflow + required review。AI review 可以提高评审效率,但不能决定能不能合并。
prompt: 请按这个 GitHub issue 工作:
- 先复述 issue 的目标、验收标准和不要动的范围;
- 给出最小实现计划;
- 创建一个只解决本 issue 的小步修改;
- 提交信息包含 Refs #<issue号>,PR 正文包含 Closes #<issue号>;
- 运行 workflow 的本地等价命令:ruff check src tests && pytest -q;
- 如果失败,只根据失败信息做最小修复;
- PR 描述里列出:改动范围、验证命令、未改动范围、风险。
不要自动合并,不要扩大 scope。

收束:生成—验证—修正质量飞轮
回头看,前面每一步其实是同一条飞轮在转:
AI 生成
-> spec / 特征测试 / lint / pytest / PR 模板验证
-> 失败信息结构化回喂给 AI
-> AI 修正
-> 人做最终裁决

每一步的对应关系:读懂遗留结构是给 AI 正确上下文。特征测试验证行为变没变。小步重构控制 diff 和回退面。Git 让变更可追溯、可审查、可回退。活 spec 让知识持续对账。GitHub workflow 把验证变成团队门禁。
飞轮里有一个常被误解的环节:让 AI 给自己的产出补边界用例,再用这些用例反过来测自己。这不是机器学习里的对抗样本攻击——这是"生成对照、边界用例自测"。两回事。而且最好让出题的 AI 和被测的产出分开,否则它对着自己的理解出题,测不出理解本身的错。
大项目里 AI 的可信度,不来自它说"我完成了"。来自你把它放进了 spec、测试、Git、workflow、PR、人审 gate 组成的系统里。
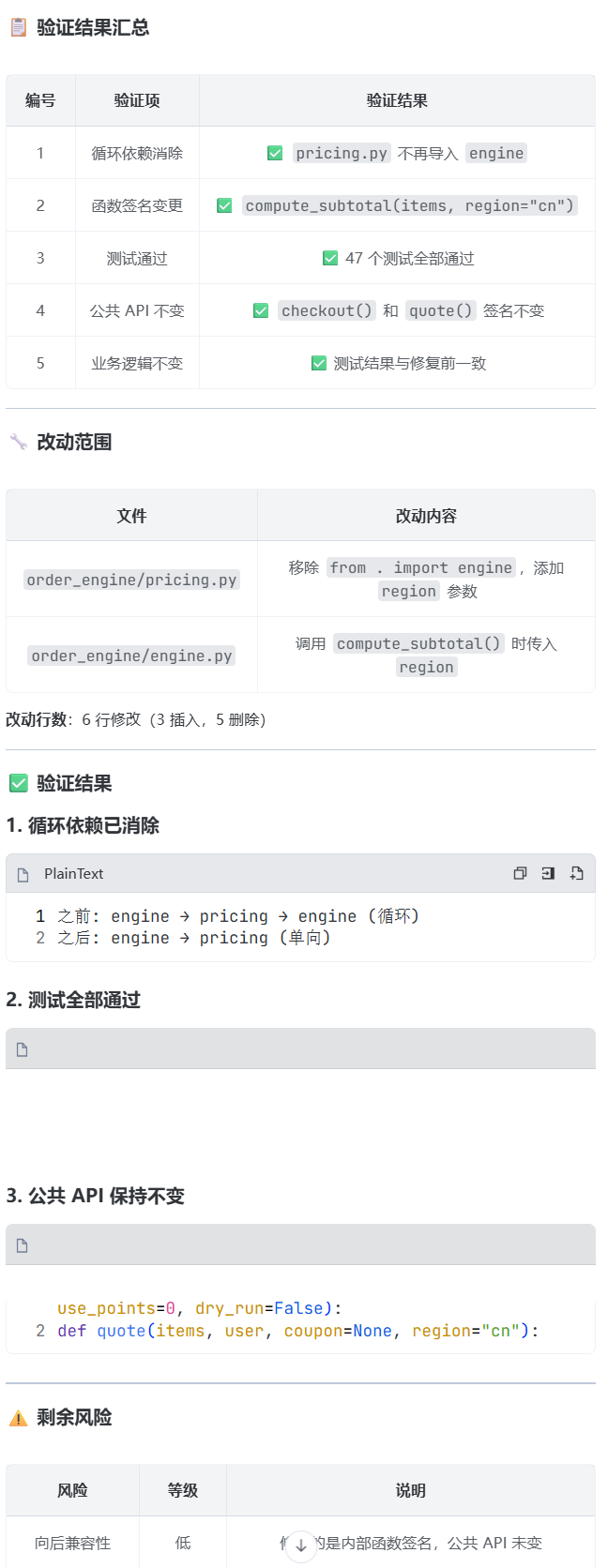
prompt: 请按生成-验证-修正流程执行本任务:
- 先列出本任务的验证标准;
- 做最小实现;
- 运行验证命令,并贴出关键结果;
- 如果失败,请按「失败项 / 输入 / 期望 / 实际 / 最小修复」格式分析;
- 修复后重新运行验证;
- 最后输出:改动范围、验证结果、剩余风险、需要人裁决的问题。
不要跳过验证,不要把未验证内容说成已完成。
AI 比人更需要制度
对人来说,制度是外部约束。对 AI 来说,制度几乎是可信度的全部来源。
一个靠谱工程师身上有很多隐性刹车:线上事故的压力、代码审美、对历史坑的敬畏、觉得不对劲时会停下来问。AI 没有这些。它不会因为 PR 有 bug 被追责,也不会因为连续犯错自动长记性。
所以对 AI,规则不能只写在聊天里。必须写进 issue 模板、PR 模板、AGENTS.md、spec 状态账本、lint 和 pytest、Branch protection、required review。
这不是流程主义。这是让 AI 能被团队安全使用的基本条件。
人退到哪里
人的位置变了:
- 人定边界。
- 人定验证标准。
- 人审 AI 生成的 spec 和测试。
- 人裁决机器判断不了的业务语义。
- 人按 merge 键。
AI 做大量体力活:读代码、列现状、补测试、抽函数、修 lint、按失败日志改。人的价值变成定义标准和最终裁决。
这套飞轮怎么从某几个人的习惯变成整个团队的共同纪律——从"超级个体"到"超级团队"——下一篇专门讲。
总结
用 AI 重构遗留代码(Legacy)的核心思维:
使用AI Idea的Plan模式,形成markdown文件。
核心思路是:先理解、再锁定、后替换;
跟换人一样,先有交接文档、再逐步学会东西,再一点点交接给新人做事,最后替代完成。
分四步走:
- AI 读旧代码写文档: 把 1500 行的老代码丢给 AI,翻译成业务流程图和规则说明,先搞清楚原来在干什么,再设计新架构。
- 补行为快照测试: 让 AI 给老代码写黑盒测试,记录当前输入输出。重构时只要测试通过,就说明业务逻辑没被改坏。
- 渐进替换: 不一次性推翻重写,而是围绕旧模块逐步搭建新服务(如 src/order/),先写接口契约和测试,再迁移实现,新老系统并行运行。
- 逐函数小步重构: 选中一个函数,让 AI 在保持外部行为不变的前提下,优化可读性、加类型注解。改一点测一点,风险最小。
建议顺序:文档化 → 补测试 → 搭新模块 → 逐函数迁移。这样既有 AI 辅助,又不会把系统改崩。
考察面试者三方面能力:
- 工程化重构思维(渐进替换而非推倒重来)
- AI 工具落地能力(用 AI 辅助文档、测试、代码生成而非盲目重写)
- 风险控制意识(先锁定行为再迁移,保证业务连续性)。
优先保障兼容,然后再去做重构
大项目里 AI 的价值不在写得更快。在三件过去很难、现在有机会做的事:
- 驾驭一个人读不完的代码库:靠架构梳理、上下文工程、活文档。
- 敢动一段没人敢碰的老代码:靠特征测试先锁住现状。
- 让 AI 产出进入团队秩序:靠 Git 的可追溯性和 GitHub workflow 的确定性门禁。
从头到尾用的不是某个工具,是同一条纪律:
先理解,再锁住;先小步,再验证;先入 Git,再进主干;先过 workflow,再由人裁决。
常见翻车处理
AI 架构梳理漏了关键入口:不要继续生成测试,先追问 public API、调用方、import 面。
特征测试不稳定:先查数据库、全局状态、时间、随机数、缓存。测试不稳定,不许重构。
AI 把疑似 bug 顺手修了:撤回,先锁现状。如果要修,另开 issue 和 PR。
重构 diff 太大:要求拆小,按单个职责块重新来。大 diff 让 review 失效。
workflow 红但 AI 解释说没问题:以 workflow 为准。让它根据日志做最小修复,不要扩大 scope。
PR 里混了重构、bug、新功能:拆 PR。混合 PR 是大项目质量事故的温床。
spec 写完没人维护:把 spec 状态迁移放进 PR checklist,不更新 spec 就不算完成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)