使用llamafactory进行模型微调完整过程
一、构建领域内的数据集
准备工作:首先你要去申请一个API,我使用的是阿里云百炼,申请完成会给你一个API秘钥
然后推荐你去下载easy-dataset去构建你的数据集,网上很多下载教程
1、easy-dataset相关配置
首选创建项目,点击项目设置,然后去配置模型:
在模型编辑里面,输入你之前申请的API秘钥,记得去你API网站那里充钱,不然后面会一直报错,你选择的模型越好越烧钱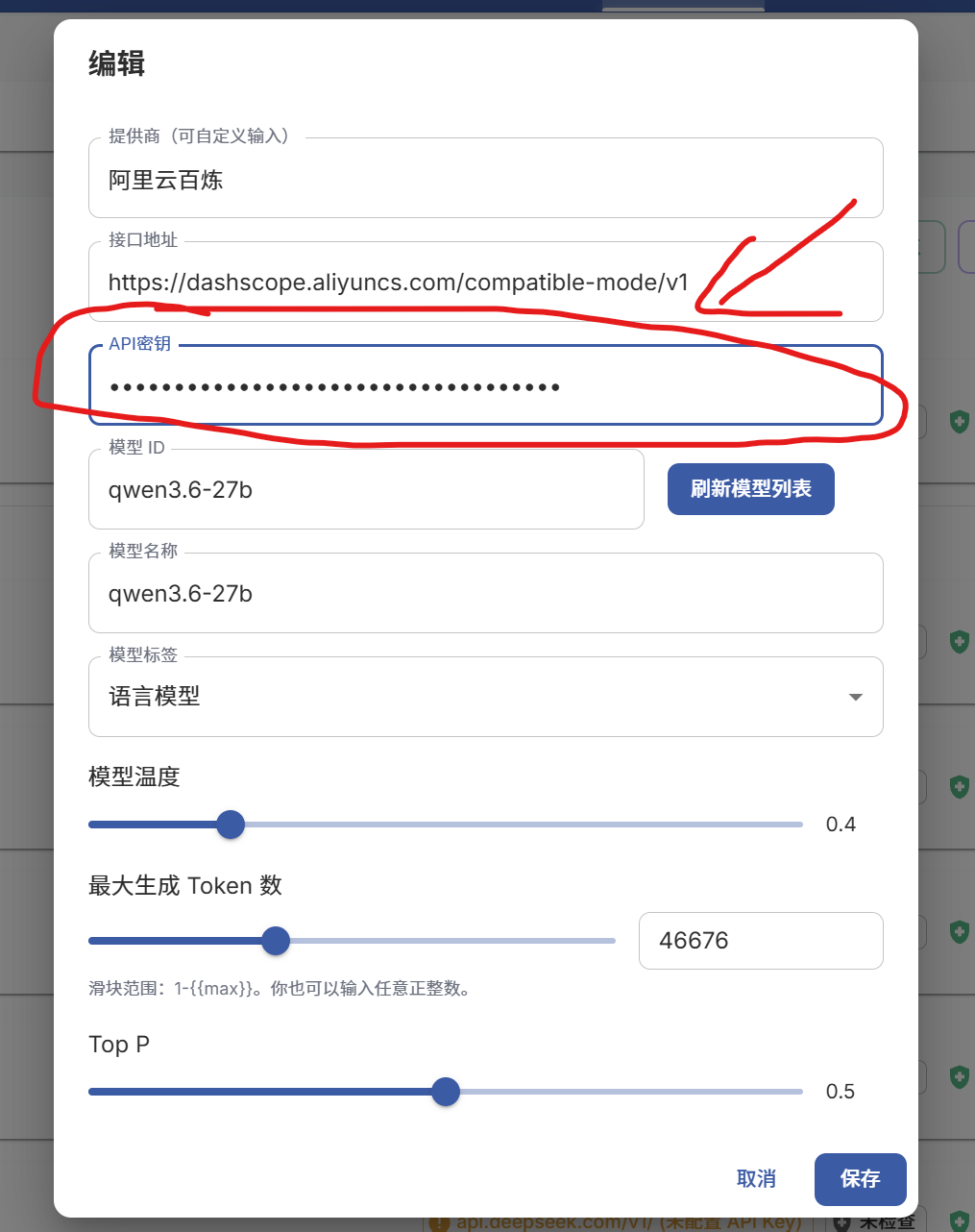
然后配置相关参数,最后点击保存,就可以在右上角使用你配置的模型了
2、提取文件
提取设备使用说明,公司内部 Wiki、,API 文档、硬件BOM表和通信协议文档,我是去https://www.dobot.cn/service/download-center,越疆机器人公司的官网资料下载了相关pdf。
3、配置MinerU
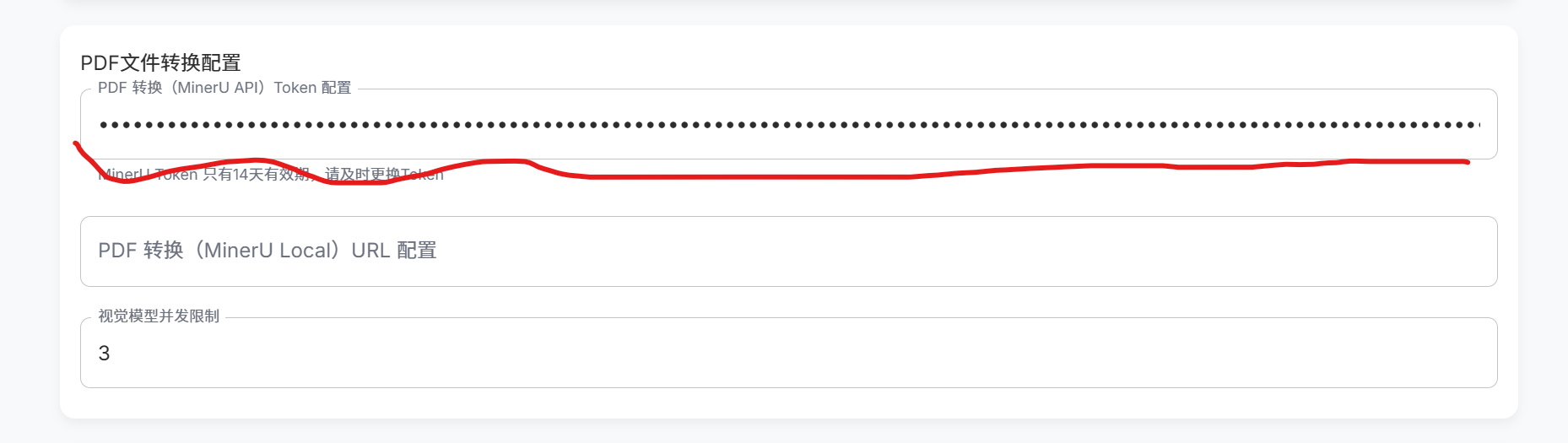
可以省略这步,如果你之后提前文件不使用MinerU的话
在项目配置的任务配置里面,下滑找到PDF文件转换的配置栏,然后输入你去MinerU官网申请的API,只有14天有效期,到期要重新申请
4、构建数据集
具体处理流程如下:
-
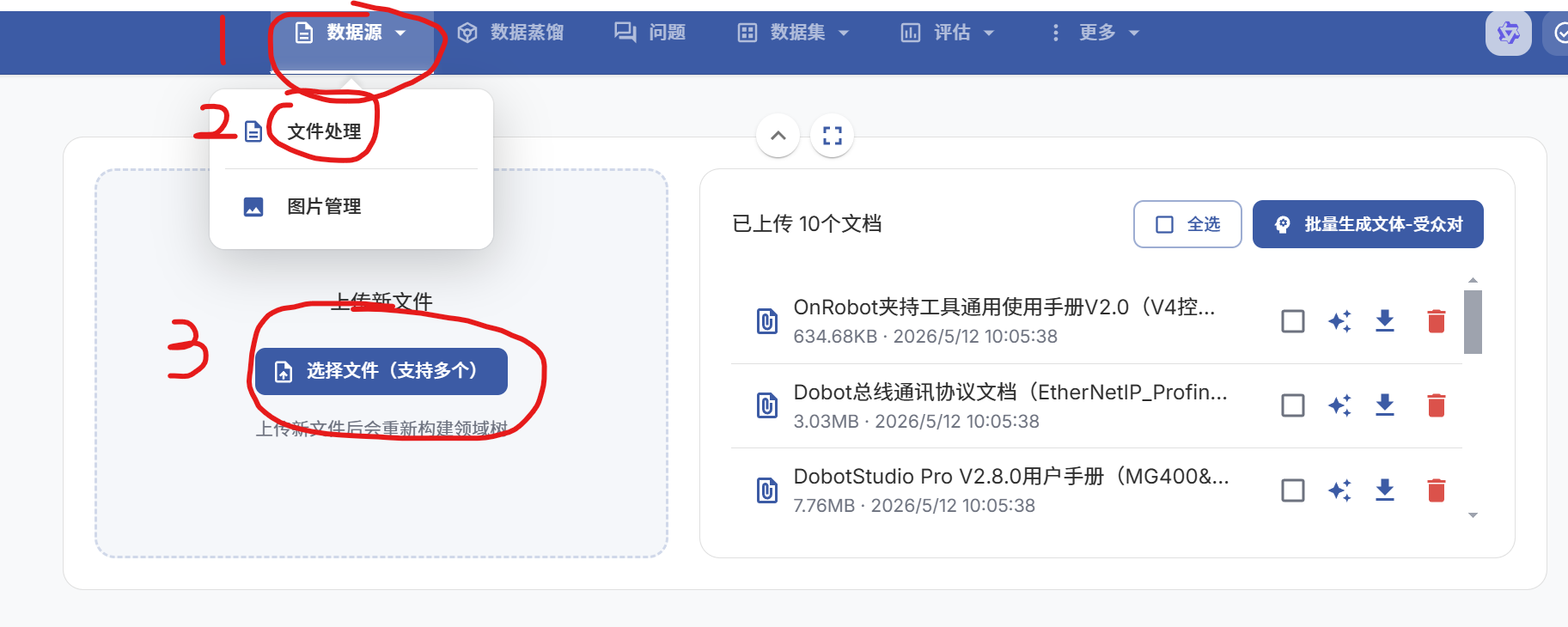
输⼊数据来源:推荐用MinerU方法来处理pdf文件,上传 PDF、Docx 等原始⽂档:
-
⽂本预处理:通过 OCR 识别⽂档内容,并切分为多个⽂本块;
-
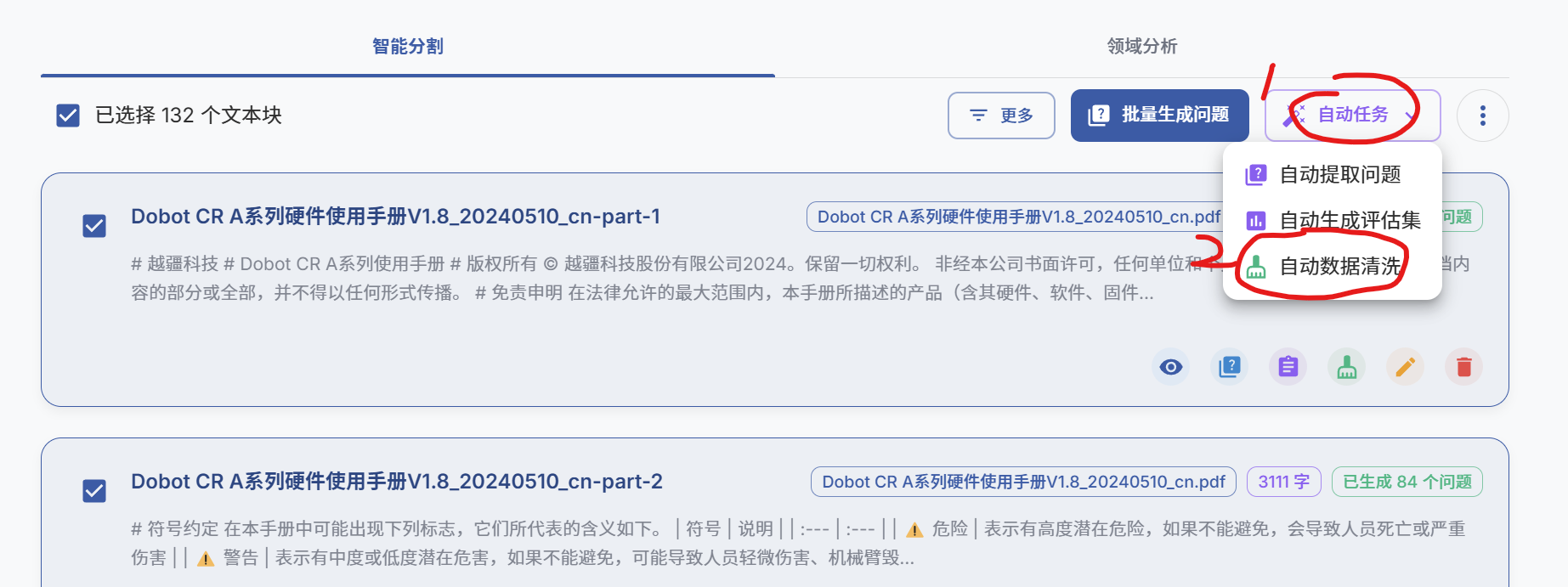
数据清洗:在生成问题前推荐进行数据清洗
-
⽣成问答对:调⽤⼤模型 API,基于⽂本块⾃动⽣成问答对,可以修改模型设置参数多生成几轮问答,并对每个问答对进⾏质量评分
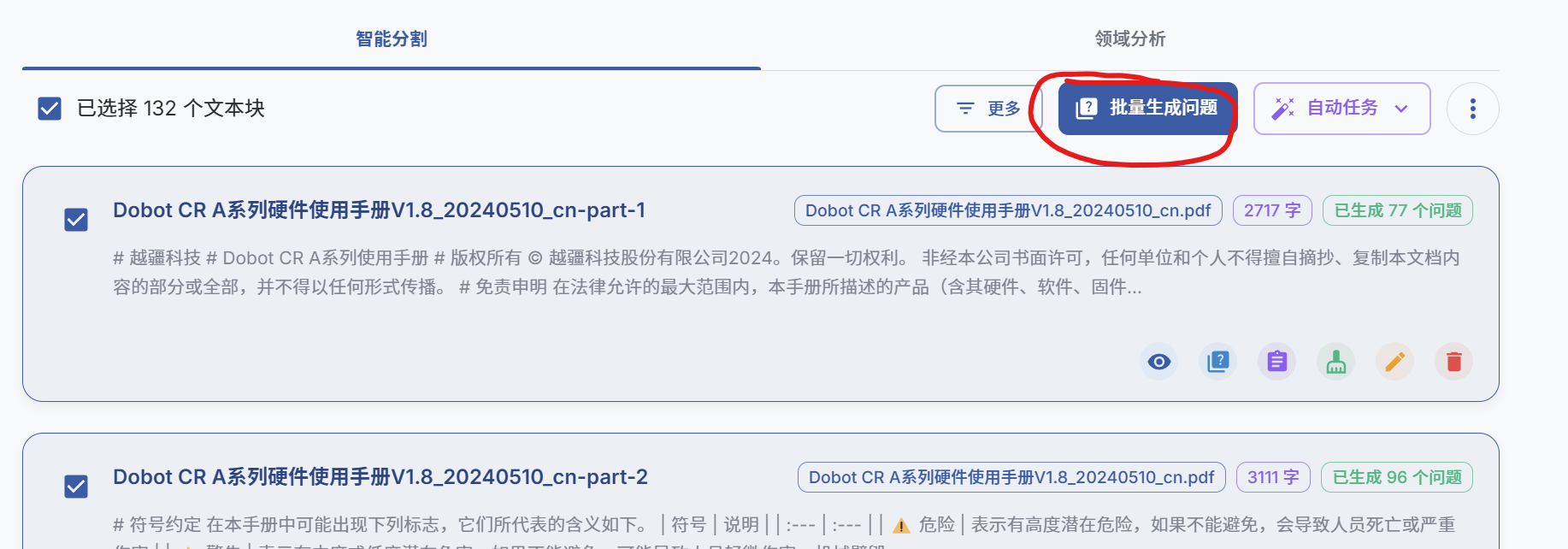
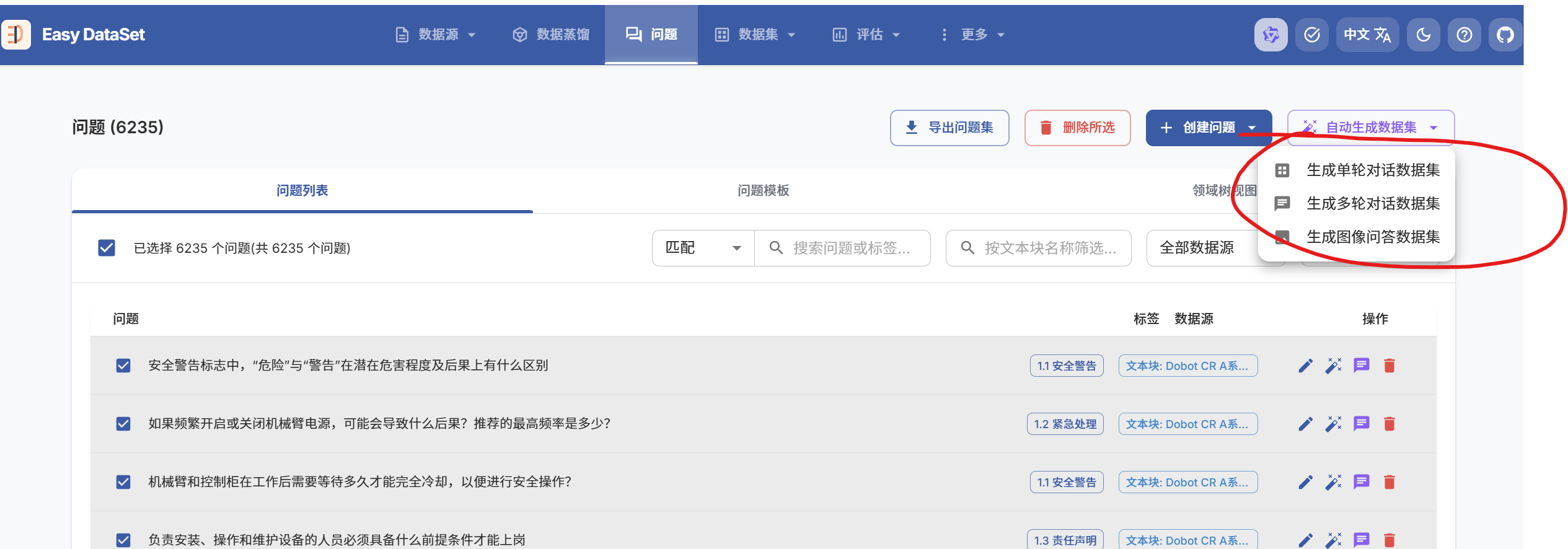
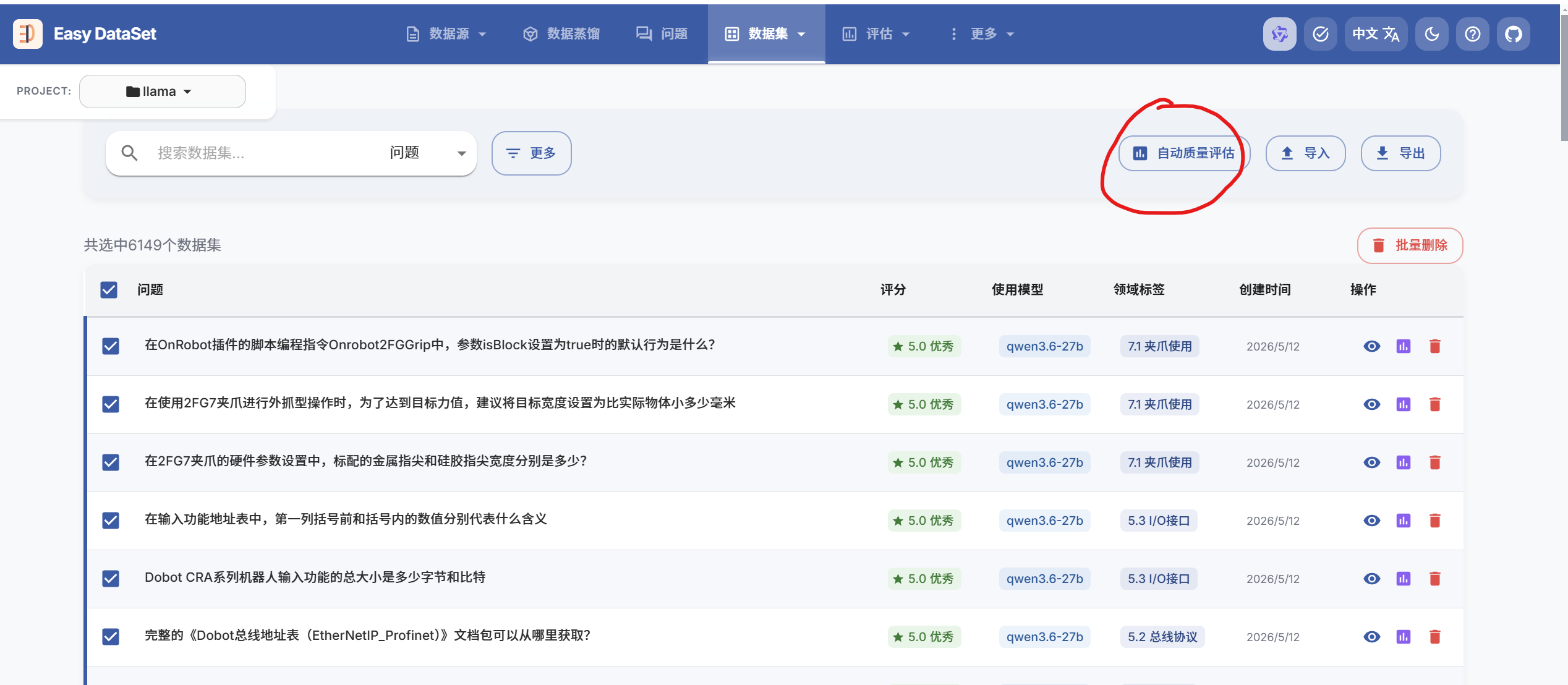
- 筛选与导出:筛选⾼分问答对,统⼀导出为单个 JSON ⽂件,作为训练框架的输⼊数据集。
二、LLaMA Factory安装部署
1.简介
LlamaFactory 是⽬前主流的开源低代码⼤模型微调框架,集成了业界最⼴泛使⽤的微调技术,⽀持通过 Web UI 零代码完成完整的微调流程。
2.下载
cd /进入你项目文件夹
git clone https://github.com/hiyouga/LLaMA-Factory.git #克隆官方llama-factory文件代码
cd LLaMA-Factory
安装依赖
# 创建python 环境
conda create -n llama python=3.11 -y
# 创建成功后切换到新的环境
conda activate llama
#要先进入LLaMA-Factory,或者直接在LLaMA-Factory文件下打开终端也可以
cd D:\PythonProject\project_llama_factory\LLaMA-Factory #本地
cd /root/autodl-tmp/test1/project_llama_factory/LLaMA-Factory #我的远端服务器
#安装环境依赖(官网)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -e ".[torch,metrics]"
#或者
pip install -e ".[torch,metrics]" -i https://mirrors.aliyun.com/pypi/simple/
#卸载 因为我这个报错了
pip uninstall torch torchvision torchaudio -y
#再安装
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
#验证,输出结果是true
python -c "import torch; print(torch.cuda.is_available())"
启动llamafactory
#运行
# 第一行:设置环境变量
$env:USE_MODELSCOPE_HUB=1
# 第二行:启动 WebUI
llamafactory-cli webui
启动成功的界面

三、训练和微调
1. 配置
默认模型下载到c盘,需要改到D盘,不然占C盘空间,如果是租用远程服务器就无所谓啦。在刚才终端输入:
$env:HUGGINGFACE_HUB_CACHE="D:\model_cache"
$env:MODELSCOPE_CACHE="D:\model_cache"
把你数据集文件放进data文件夹,然后再dataset_info里面添加如下配置,你数据集和测试集的名字,以及为它们重新取个名字: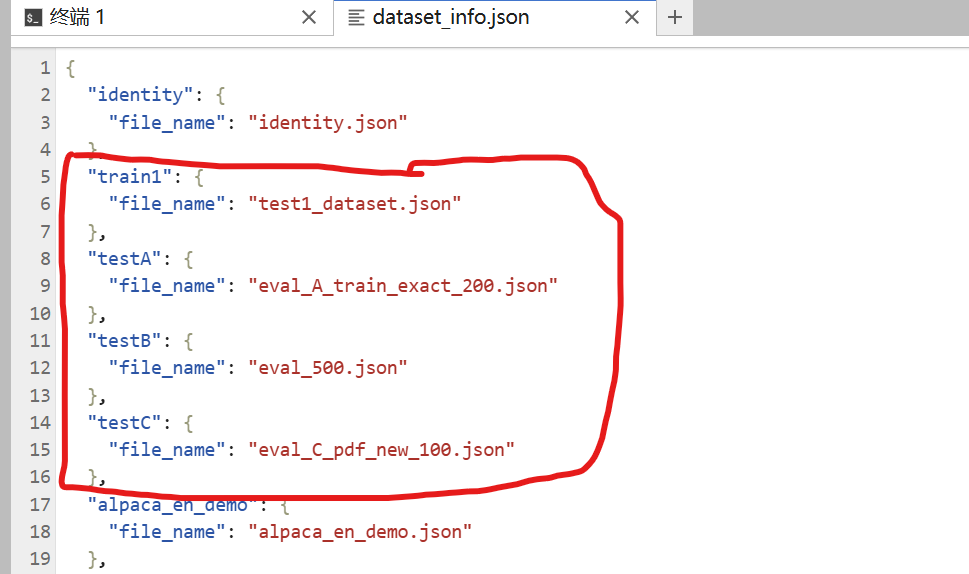
然后在运行出来的网页上选择你刚才添加的的数据集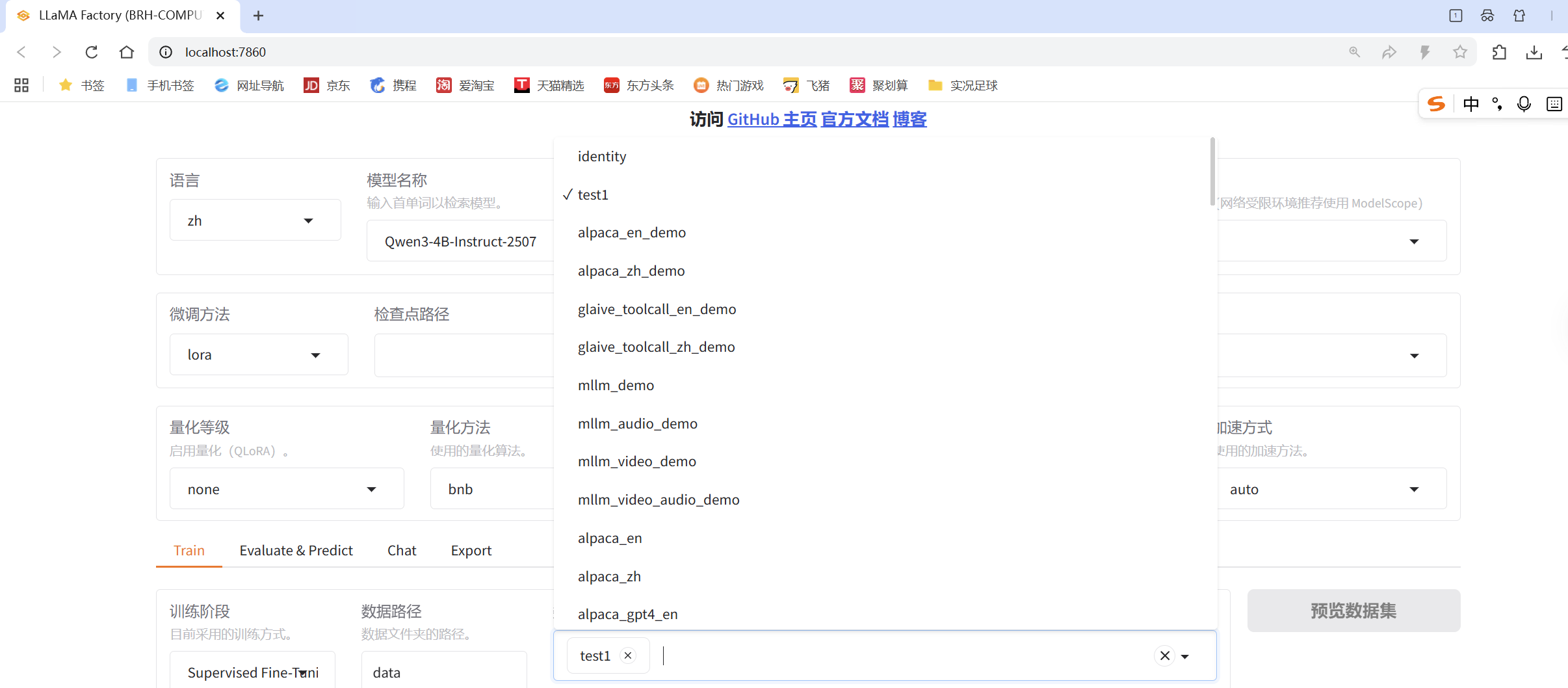
2.训练
在web界面调整好参数,然后在web界面的trian模块下点击train:
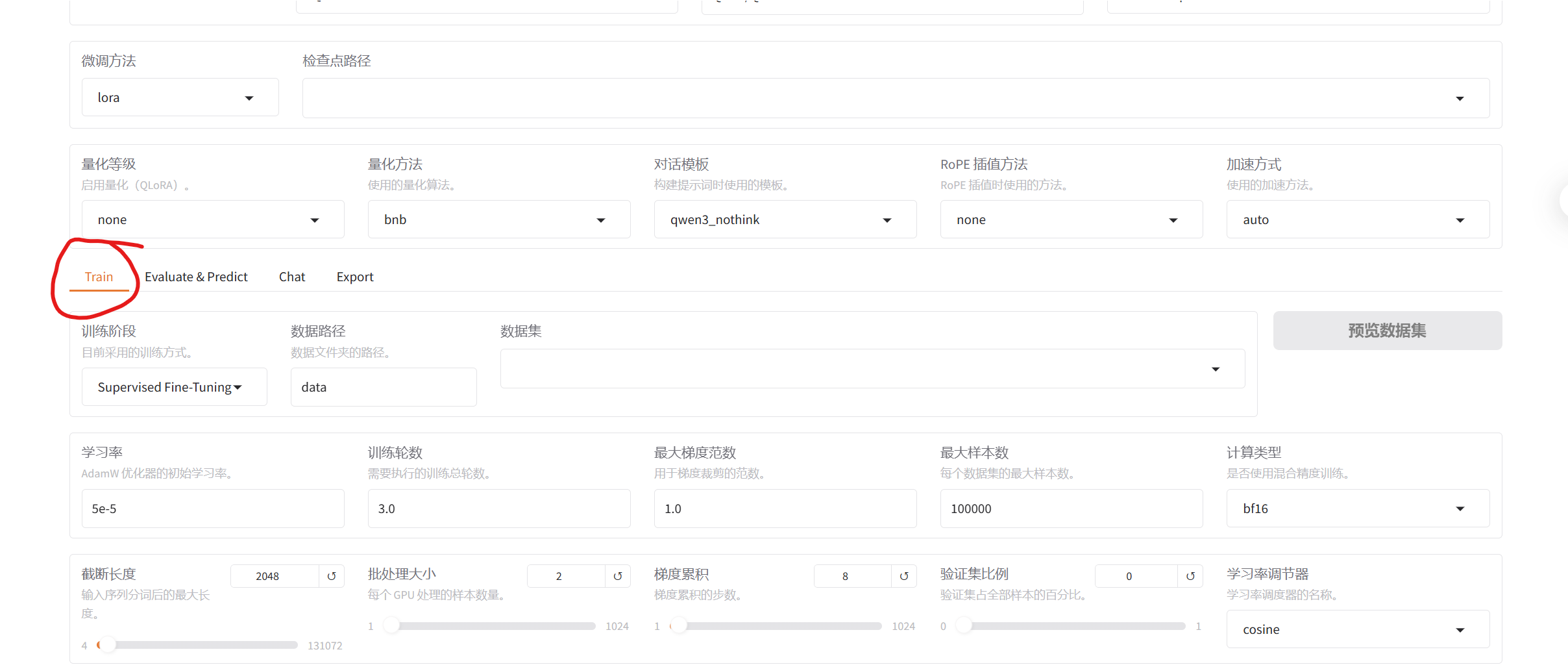
四、模型评估
1.Evaluate&Predict
对于 LLaMA Factory自带有Evaluate&Predict,官方文档中也提供了模型训练完成后的评估方式:可以通过 Predict 获得 BLEU 和 ROUGE 分数。 这说明 LLaMA Factory 自带的 Evaluate&Predict 并不是单纯“聊天测试”,而是可以用于批量评估模型输出与标准答案之间的差异。
操作方式:
记得选择检测路径(保存你之前训练出来的模型的地方),然后开始预测


它会让你安装如下一些库,ctrl+c终止当前webui界面程序:
pip install jieba nltk rouge_chinese -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install rouge_chinese -i https://pypi.tuna.tsinghua.edu.cn/simple
2.评估方式
本项目建议最终采用以下指标:
| 指标 | 说明 |
|---|---|
| predict_bleu-4 | 衡量生成文本与参考答案在 4-gram(四个连续词)层面的匹配程度 |
| predict_rouge-1 | 衡量生成文本和参考文本在单词级的重叠率 |
| predict_rouge-2 | 衡量生成文本和参考文本在连续两个词层面的匹配 |
| predict_rouge-l | 衡量最长公共子序列(LCS)的比例 |
设计了三组测试:
| 测试集 | 内容 | 目的 |
|---|---|---|
| A. 原训练集抽样测试 | 从数据集中抽 200 条原问题 | 测模型是否学会训练数据 |
| B. 改写评估集测试 | 在数据集的基础上修改提问方式 | 测模型是否能处理同义问法 |
| C. 文档内新题测试 | 从同一批PDF中再抽 100 条没训练过的问题 | 补充证明模型对同领域文档有一定扩展能力 |
3.评估结果
测试A:原训练集抽样200条测试的结果


| 指 | 基座模型值 | 训练模型值 |
|---|---|---|
| predict_bleu-4 | 8.6 | 68.9 |
| predict_rouge-1 | 27.7 | 79.5 |
| predict_rouge-2 | 7.6 | 69.3 |
| predict_rouge-l | 16.5 | 73.5 |
测试B:改写评估集生成500条测试的结果
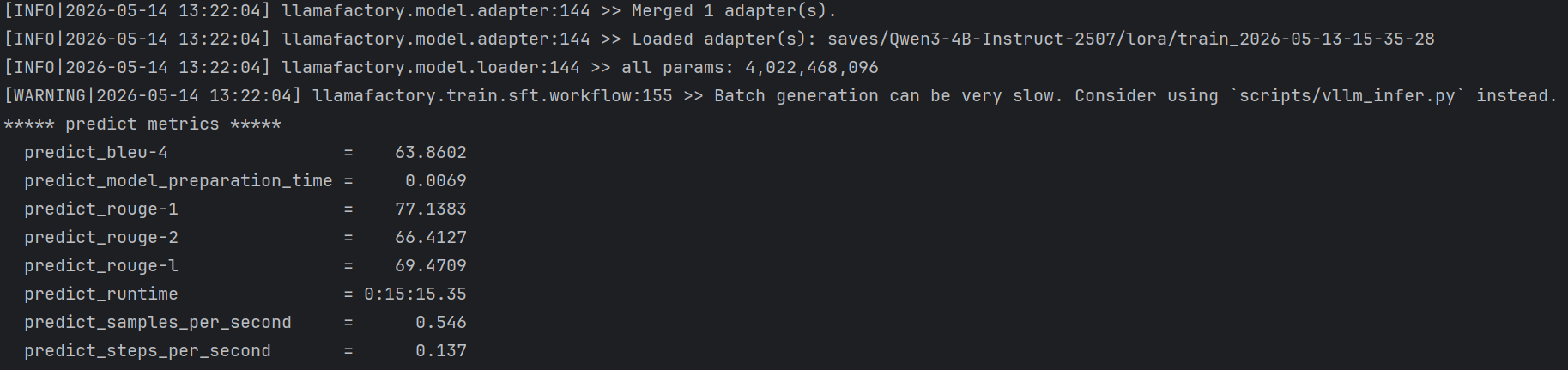

| 指标 | 基座模型值 | 训练模型值 |
|---|---|---|
| predict_bleu-4 | 10.5 | 63.9 |
| predict_rouge-1 | 28.6 | 77.1 |
| predict_rouge-2 | 8.1 | 66.4 |
| predict_rouge-l | 18.1 | 69.5 |
测试C:从同一批 PDF 中再抽 100 条没训练过的问题测试的结果
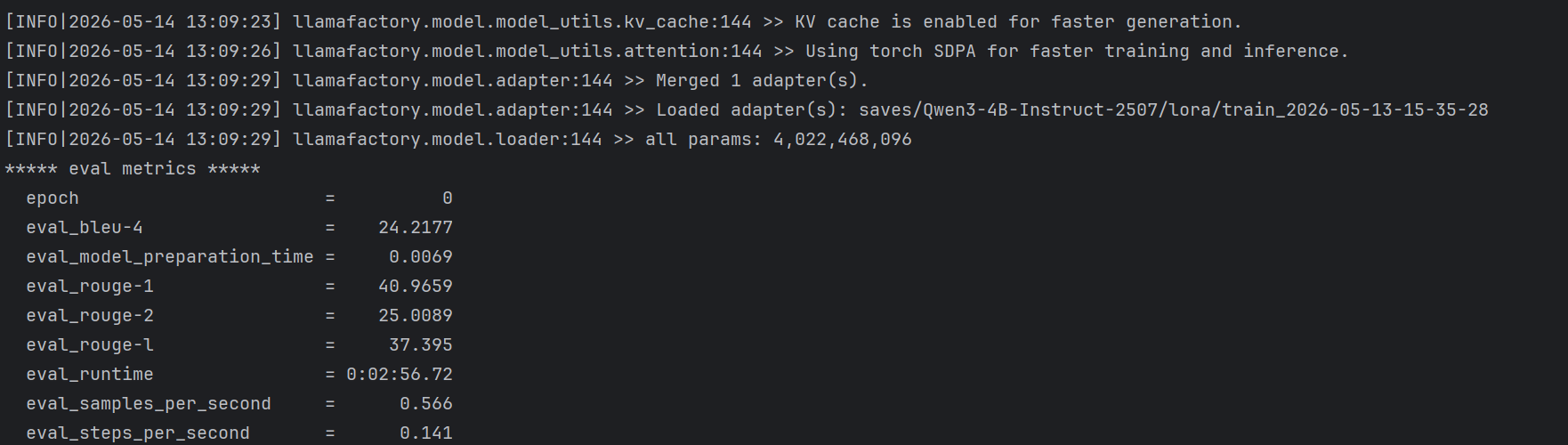
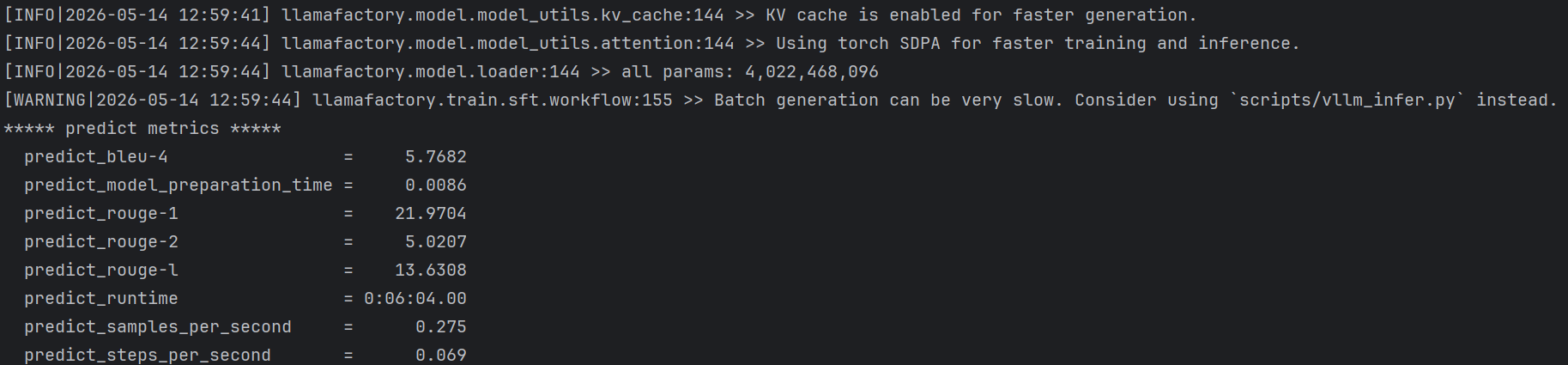
| 指标 | 基座模型值 | 训练模型值 |
|---|---|---|
| predict_bleu-4 | 5.7 | 24.2 |
| predict_rouge-1 | 22.0 | 41.0 |
| predict_rouge-2 | 5.0 | 25.0 |
| predict_rouge-l | 13.6 | 37.4 |
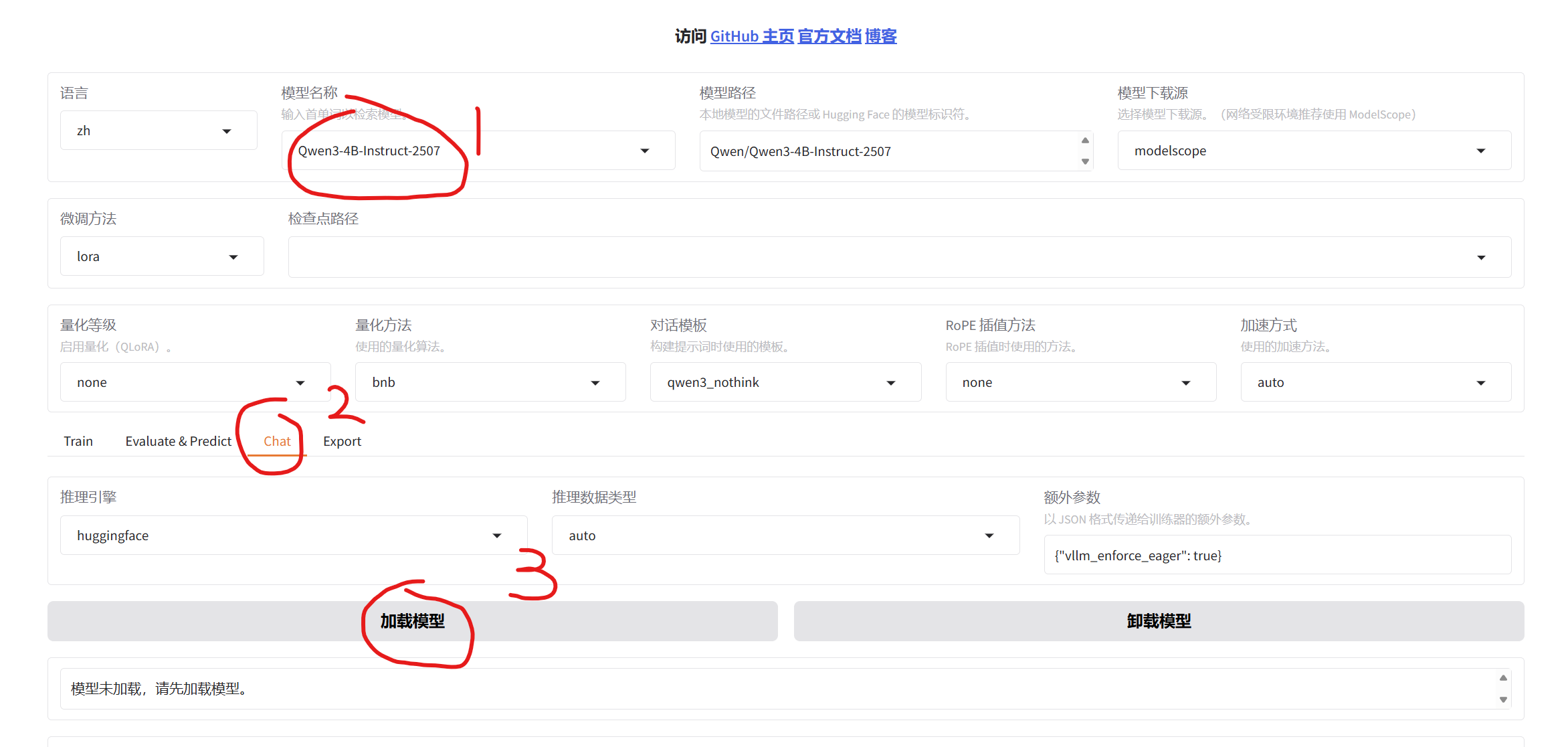
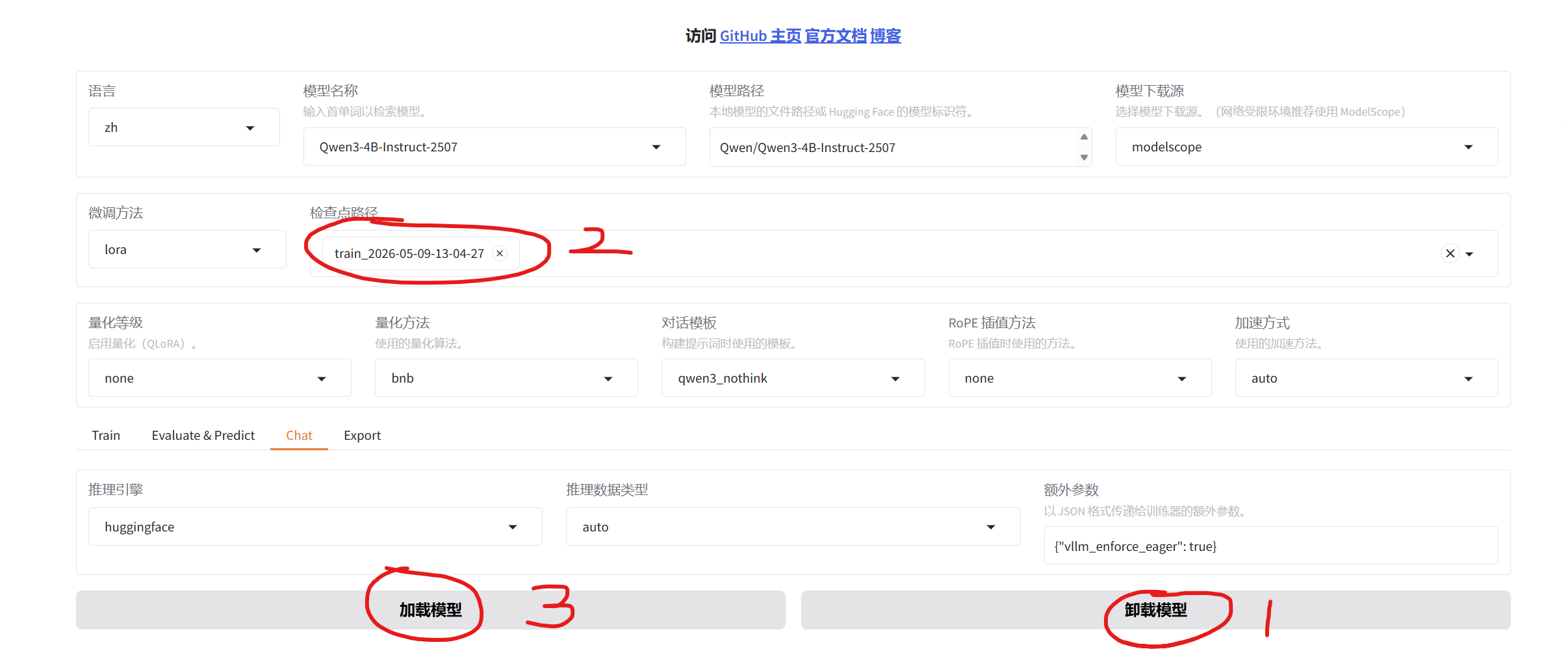
五、模型对话
1.基座模型加载
2.微调模型加载
3.对比
问题1:
Dobot CRA系列机器人输入功能的总大小是多少字节和比特

基座模型的回答:基座无法确定具体字节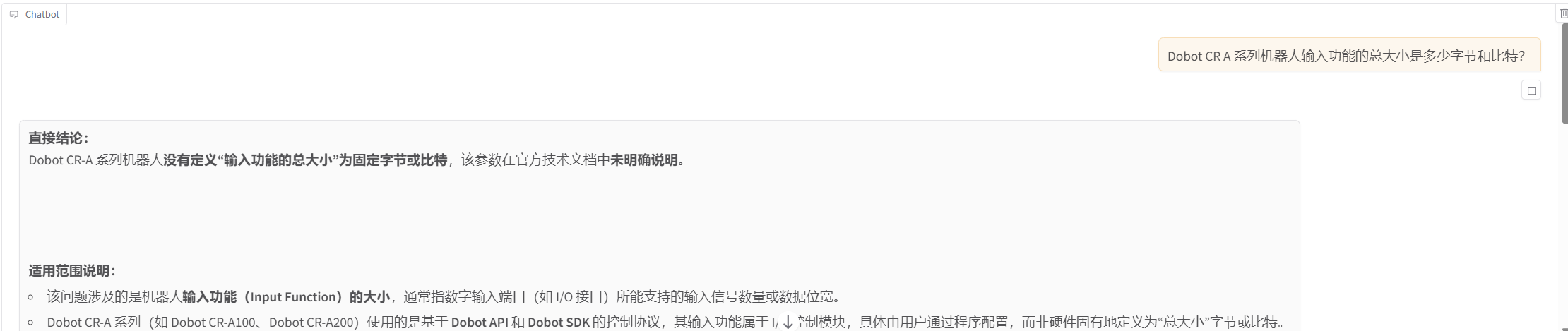
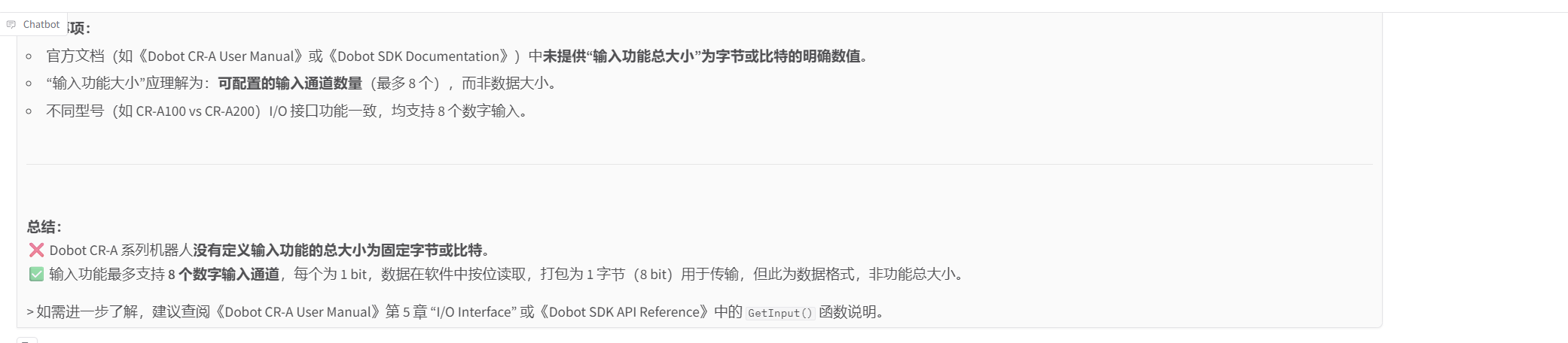
微调模型的回答:训练的模型准确回答出472字节,相当于3776比特,与数据集答案相符

问题2:
Dobot CR A 系列机器人输入/输出数据的字节存储模式是什么

基座模型的回答:基座模型错误回答“大端存储”,但是实际文档中的答案是小端存储

微调模型的回答:训练的模型准确回答出“小端存储”,与数据集答案相符

六、最终结论
在模型训练完成后,本文分别从Evaluate & Predict批量评估和人工对话对比两个角度,对基座模型和微调模型进行了对比测试。评估阶段共设计了三类测试集:A类为原训练集抽样测试,用于验证模型是否掌握训练数据中的固定知识;B类为改写评估集测试,用于验证模型面对同一知识点不同问法时的回答稳定性;C类为PDF文档内新题测试,从同一批PDF中再抽100条没训练过的问题 补充证明模型对同领域文档有一定扩展能力。
从量化评估结果来看,微调模型在三组测试集中均明显优于基座模型。在A类原训练集抽样测试中,基座模型的 predict_bleu-4仅为8.6,而微调模型提升至68.9;predict_rouge-l也由基座模型的16.5提升至73.5。这说明微调模型已经较好地学习到了训练数据中的领域知识和技术支持回答格式。
在B类改写评估集测试中,基座模型的predict_bleu-4为10.5,微调模型达到63.9;基座模型的predict_rouge-l为18.1,微调模型达到69.5。这表明微调模型不仅能够回答原始训练问题,还能在问题表述发生变化时,仍然较稳定地输出接近标准答案的内容。
在C类PDF文档内新题测试中,微调模型同样优于基座模型。基座模型的predict_bleu-4为5.7,微调模型达到24.2;基座模型的 predict_rouge-l为13.6,微调模型达到37.4。虽然C类测试集由于问题相对更接近文档内补充问题,整体分数低于A、B两类测试,但微调模型仍然表现出明显优势,说明本次微调对同领域文档问答能力具有一定增强效果。
除了批量评估结果外,在人工对话测试中也可以直观看出微调模型与基座模型的差异。例如,在问题 “Dobot CR A 系列机器人输入功能的总大小是多少字节和比特?” 中,基座模型无法给出明确参数,而微调模型能够准确回答472字节,相当于3776比特。在问题 “Dobot CR A 系列机器人输入/输出数据的字节存储模式是什么?” 中,基座模型错误回答为大端存储,而微调模型能够正确回答小端模式存储。这说明微调模型已经学习到了 Dobot 总线通讯文档中的关键技术细节。
综合来看,基座模型在面对越疆Dobot机器人固定领域问题时,容易出现回答不确定、关键参数缺失或技术细节错误等情况;而经过领域数据微调后的模型,在BLEU、ROUGE等自动评估指标上均显著高于基座模型,在人工对话中也能更准确地回答参数、协议、地址、数据格式和操作说明类问题。因此,本次基于越疆官方技术文档构建的数据集和微调流程是有效的,能够明显增强模型在越疆Dobot机器人特定领域文档问答任务中的表现。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)