【ch05】Pretraining-on-unlabeled-data
零、前言
本章主要讲了下如何评价llm生成文本的质量,如何进行预训练。
本章代码:ch05
一、Pretraining on unlabeled data
1.1 Evaluating generative text models
首先回顾下 GPT 生成文本的过程:
创建GPT模型:
import torch
from previous_chapters import GPTModel
GPT_CONFIG_124M = {
"vocab_size": 50257,
"context_length": 256,
"emb_dim": 768,
"n_heads": 12,
"n_layers": 12,
"drop_rate": 0.1,
"qkv_bias": False
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval()
建立text2id 和 id2text 的辅助函数:
import tiktoken
from previous_chapters import generate_text_simple
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0)
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0)
return tokenizer.decode(flat.tolist())
创建个文本样例,然后加载一下gpt2的tokenizer
start_context = "Every effort moves you"
tokenizer = tiktoken.get_encoding("gpt2")
生成文本:
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(start_context, tokenizer),
max_new_tokens=10,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
Output text:
Every effort moves you rentingetic wasnم refres RexMeCHicular stren
生成的文本过于随机,因为我们没有对模型进行预训练。
想要进行训练,我们得有loss function。
一个想法就是对我们的实际输出文本和预期文本之间计算cross entropy。
创建一个测试文本用于计算cross entropy:
inputs = torch.tensor([[16833, 3626, 6100], # ["every effort moves",
[40, 1107, 588]]) # "I really like"]
targets = torch.tensor([[3626, 6100, 345 ], # [" effort moves you",
[1107, 588, 11311]]) # " really like chocolate"]
with torch.no_grad():
logits = model(inputs)
probas = torch.softmax(logits, dim=-1)
probas.shape
torch.Size([2, 3, 50257])
获取预测结果(即概率最大的那个词):
token_ids = torch.argmax(probas, dim=-1, keepdim=True)
print("Token IDs:\n", token_ids)
Token IDs:
tensor([[[16657],
[ 339],
[42826]],
[[49906],
[29669],
[41751]]])
看一下生成内容:
print(f"Targets batch 1: {token_ids_to_text(targets[0], tokenizer)}")
print(f"Outputs batch 1:"
f" {token_ids_to_text(token_ids[0].flatten(), tokenizer)}")
Targets batch 1: effort moves you
Outputs batch 1: Armed heNetflix
输出和预期基本没啥关系,我们取出目标词的预测概率:
text_idx = 0
target_probas_1 = probas[text_idx, [0, 1, 2], targets[text_idx]]
print("Text 1:", target_probas_1)
text_idx = 1
target_probas_2 = probas[text_idx, [0, 1, 2], targets[text_idx]]
print("Text 2:", target_probas_2)
Text 1: tensor([7.4540e-05, 3.1061e-05, 1.1563e-05])
Text 2: tensor([1.0337e-05, 5.6776e-05, 4.7559e-06])
求 cross entropy:
log_probas = torch.log(torch.cat((target_probas_1, target_probas_2)))
log_probas
tensor([ -9.5042, -10.3796, -11.3677, -11.4798, -9.7764, -12.2561])
我们取均值作为最终的loss:
avg_log_probas = torch.mean(log_probas)
avg_log_probas
tensor(-10.7940)
但是我们往往是最小化loss,而这里计算的 log p 一定是负数,所以我们对结果取负:
neg_avg_log_probas = avg_log_probas * -1
neg_avg_log_probas
tensor(10.7940)
pytorch 为我们提供了cross_entropy的函数。
我们已经有了每个输入的预测分数logits,以及我们预期的文本预测targets
print("Logits shape:", logits.shape)
print("Targets shape:", targets.shape)
Logits shape: torch.Size([2, 3, 50257])
Targets shape: torch.Size([2, 3])
为了使用pytorch提供的cross entropy函数,我们需要把logits拉平成若干个token的vocab概率预测:
logits_flat = logits.flatten(0, 1)
targets_flat = targets.flatten()
print("Flattened logits:", logits_flat.shape)
print("Flattened targets:", targets_flat.shape)
Flattened logits: torch.Size([6, 50257])
Flattened targets: torch.Size([6])
然后直接调用api:
loss = torch.nn.functional.cross_entropy(logits_flat, targets_flat)
loss
tensor(10.7940)
和之前我们手写的输出一致。
大语言模型训练的时候会用均值交叉熵作为loss,但是展示时在大语言模型中更常用的指标是 Perplexity(困惑度)。
p e r p l e x i t y = t o r c h . e x p ( l o s s ) perplexity = torch.exp(loss) perplexity=torch.exp(loss)
perplexity 相比与均值交叉熵更加直观,它一定程度上反映了模型生成“一整句话”或“一篇文章”的表现。从公式的推导来看,Perplexity 直接对应着每个词预测概率的几何平均数的倒数:
p e r l e x i t y = e l o s s = ( 1 P ( x 1 , x 2 , … , x N ) ) 1 N perlexity = e^{loss} = \left ( \frac{1}{P(x_1, x_2, \dots, x_N)} \right )^{\frac{1}{N}} perlexity=eloss=(P(x1,x2,…,xN)1)N1
如果PPL=5,意味着模型平均给正确的下一个词分配了 1/5=20% 的概率。换句话说,模型成功的把从上万个词当中选出一个词作为正确结果的难度降低到了从5个词里面选出一个正确结果的难度。
所以,在在做模型“评价” 和 “展示”时,更习惯用的是 perplexity。
作者选择了第二章时用的那篇文章作为训练数据。
我们需要写一些辅助函数来计算training loss 和 validation loss。
加载一下训练数据:
file_path = "the-verdict.txt"
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
total_characters = len(text_data)
total_tokens = len(tokenizer.encode(text_data))
print("Characters:", total_characters)
print("Tokens:", total_tokens)
Characters: 20479
Tokens: 5145
划分训练集和验证集:
train_ratio = 0.90
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
from previous_chapters import create_dataloader_v1
torch.manual_seed(123)
train_loader = create_dataloader_v1(
train_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=True,
shuffle=True,
num_workers=0
)
val_loader = create_dataloader_v1(
val_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=True,
shuffle=True,
num_workers=0
)
print("Train loader:")
for x, y in train_loader:
print(x.shape, y.shape)
print("\nValidation loader:")
for x, y in val_loader:
print(x.shape, y.shape)
Train loader:
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
Validation loader:
torch.Size([2, 256]) torch.Size([2, 256])
然后写一个函数计算一个batch的loss:
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(
logits.flatten(0, 1), target_batch.flatten()
)
return loss
然后整合到计算整个loader的loss:
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0.
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(
input_batch, target_batch, model, device
)
total_loss += loss.item()
else:
break
return total_loss / num_batches
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device)
val_loss = calc_loss_loader(val_loader, model, device)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
Training loss: 10.98758347829183
Validation loss: 10.981106758117676
1.2 Training an LLM
pytorch 训练神经网络标准流程:
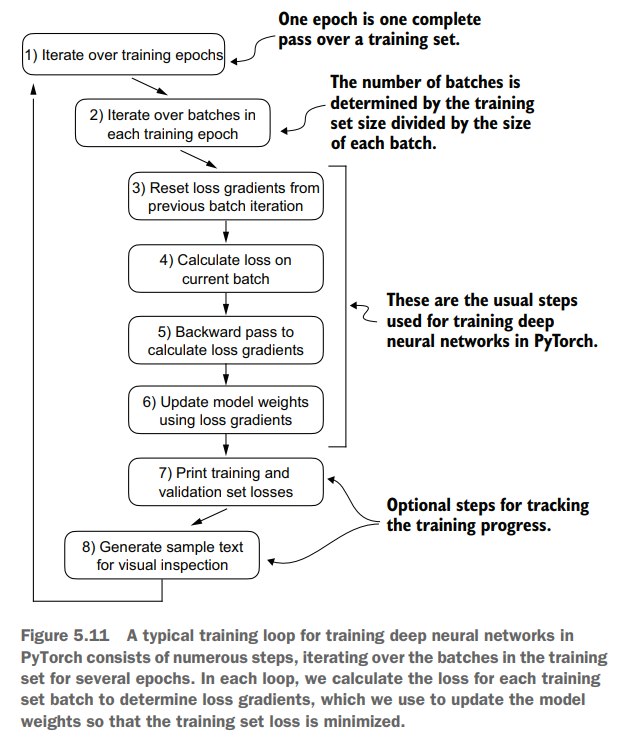
我们可以写一个标准的训练循环:
def train_model_simple(model, train_loader, val_loader,
optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
train_losses, val_losses, track_tokens_seen = [], [], []
tokens_seen, global_step = 0, -1
for epoch in range(num_epochs):
model.train()
for input_batch, target_batch in train_loader:
optimizer.zero_grad()
loss = calc_loss_batch(
input_batch, target_batch, model, device
)
loss.backward()
optimizer.step()
tokens_seen += input_batch.numel()
global_step += 1
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter
)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, "
f"Val loss {val_loss:.3f}"
)
generate_and_print_sample(
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen
主要到用到了两个辅助函数:
- evaluate_model 用于计算train loss 和 val loss
- generate_and_print_sample 用于进行一次文本预测,用来展示模型当前效果
实现也很简单:
def evaluate_model(model, train_loader, val_loader, device, eval_iter):
model.eval()
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)
model.train()
return train_loss, val_loss
def generate_and_print_sample(model, tokenizer, device, start_context):
model.eval()
context_size = model.pos_emb.weight.shape[0]
encoded = text_to_token_ids(start_context, tokenizer).to(device)
with torch.no_grad():
token_ids = generate_text_simple(
model=model, idx=encoded,
max_new_tokens=50, context_size=context_size
)
decoded_text = token_ids_to_text(token_ids, tokenizer)
print(decoded_text.replace("\n", " "))
model.train()
稍微训几个epoch试试水:
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.to(device)
optimizer = torch.optim.AdamW(
model.parameters(),
lr=0.0004, weight_decay=0.1
)
num_epochs = 10
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context="Every effort moves you", tokenizer=tokenizer
)
Ep 1 (Step 000000): Train loss 9.781, Val loss 9.933
Ep 1 (Step 000005): Train loss 8.111, Val loss 8.339
Every effort moves you,,,,,,,,,,,,.
Ep 2 (Step 000010): Train loss 6.661, Val loss 7.048
Ep 2 (Step 000015): Train loss 5.961, Val loss 6.616
Every effort moves you, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and,, and, and,
Ep 3 (Step 000020): Train loss 5.726, Val loss 6.600
Ep 3 (Step 000025): Train loss 5.201, Val loss 6.348
Every effort moves you, and I had been.
Ep 4 (Step 000030): Train loss 4.417, Val loss 6.278
Ep 4 (Step 000035): Train loss 4.069, Val loss 6.226
Every effort moves you know the "I he had the donkey and I had the and I had the donkey and down the room, I had
Ep 5 (Step 000040): Train loss 3.732, Val loss 6.160
Every effort moves you know it was not that the picture--I had the fact by the last I had been--his, and in the "Oh, and he said, and down the room, and in
Ep 6 (Step 000045): Train loss 2.850, Val loss 6.179
Ep 6 (Step 000050): Train loss 2.427, Val loss 6.141
Every effort moves you know," was one of the picture. The--I had a little of a little: "Yes, and in fact, and in the picture was, and I had been at my elbow and as his pictures, and down the room, I had
Ep 7 (Step 000055): Train loss 2.104, Val loss 6.134
Ep 7 (Step 000060): Train loss 1.882, Val loss 6.233
Every effort moves you know," was one of the picture for nothing--I told Mrs. "I was no--as! The women had been, in the moment--as Jack himself, as once one had been the donkey, and were, and in his
Ep 8 (Step 000065): Train loss 1.320, Val loss 6.238
Ep 8 (Step 000070): Train loss 0.985, Val loss 6.242
Every effort moves you know," was one of the axioms he had been the tips of a self-confident moustache, I felt to see a smile behind his close grayish beard--as if he had the donkey. "strongest," as his
Ep 9 (Step 000075): Train loss 0.717, Val loss 6.293
Ep 9 (Step 000080): Train loss 0.541, Val loss 6.393
Every effort moves you?" "Yes--quite insensible to the irony. She wanted him vindicated--and by me!" He laughed again, and threw back the window-curtains, I had the donkey. "There were days when I
Ep 10 (Step 000085): Train loss 0.391, Val loss 6.452
Every effort moves you know," was one of the axioms he laid down across the Sevres and silver of an exquisitely appointed luncheon-table, when, on a later day, I had again run over from Monte Carlo; and Mrs. Gis
可以看出这个loss下降的非常快,效果也从最早的输出一堆 ‘,’,到后来生成一堆语法正确的句子。
我们可以写个绘图函数展示一下:
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
def plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):
fig, ax1 = plt.subplots(figsize=(5, 3))
ax1.plot(epochs_seen, train_losses, label="Training loss")
ax1.plot(
epochs_seen, val_losses, linestyle="-.", label="Validation loss"
)
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.legend(loc="upper right")
ax1.xaxis.set_major_locator(MaxNLocator(integer=True))
# Creates a second x-axis that shares the same y-axis
ax2 = ax1.twiny()
# invisible plot for aligning ticks
ax2.plot(tokens_seen, train_losses, alpha=0)
ax2.set_xlabel("Tokens seen")
fig.tight_layout()
plt.show()
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
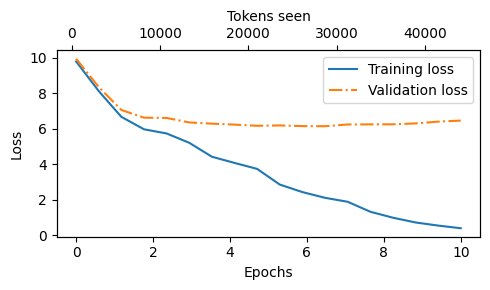
值得注意的是,val loss 很快就不怎么变了,这是因为模型只记住了 training data,过拟合了。
这个很容易理解,毕竟我们的训练数据太小了。通常对于llm来说,要在很大的数据上训练很久。
不过对于学习llm而言,我们后面直接加载OpenAI 公开的GPT-2权重即可。
1.3 Decoding strategies to control randomness
我们前面的文本预测都是每次取 torch.argmax,即预测概率最大的那个。但是局部最优不一定得到全局最优。
我们进行一次预测:
model.to('cpu')
model.eval()
tokenizer = tiktoken.get_encoding('gpt2')
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids("Every effort moves you", tokenizer),
max_new_tokens=25,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
Output text:
Every effort moves you know," was one of the axioms he laid down across the Sevres and silver of an exquisitely appointed lun
我们可以是
- Every effort moves you know
- Every effort moves you forward
- …
所以作者介绍了一些提高 inference 创造性、随机性的trick。
1.3.1 Temperature scaling
通过一个例子解释 temperature sampling:
创建一个词表:
vocab = {
"closer": 0,
"every": 1,
"effort": 2,
"forward": 3,
"inches": 4,
"moves": 5,
"pizza": 6,
"toward": 7,
"you": 8,
}
inverse_vocab = {v: k for k, v in vocab.items()}
赋一个logits:
next_token_logits = torch.tensor(
[4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79]
)
我们进行softmax,然后按照 argmax预测:
probas = torch.softmax(next_token_logits, dim=0)
next_token_id = torch.argmax(probas).item()
print(inverse_vocab[next_token_id])
'forward'
不出意外我们得到了 ‘forward’
但如果我们按照概率来抽:
torch.manual_seed(123)
next_token_id = torch.multinomial(probas, num_samples=1).item()
inverse_vocab[next_token_id]
'forward'
仍然得到了’forward’,这不奇怪,因为’forward’的概率最大,我们随便抽一下抽到 ‘forward’ 并不奇怪。
但如果我们抽的次数多起来:
def print_sampled_tokens(probas):
torch.manual_seed(123)
sample = [torch.multinomial(probas, num_samples=1).item() for i in range(1_000)]
sampled_ids = torch.bincount(torch.tensor(sample))
for i, freq in enumerate(sampled_ids):
print(f"{freq} x {inverse_vocab[i]}")
print_sampled_tokens(probas)
73 x closer
0 x every
0 x effort
582 x forward
2 x inches
0 x moves
0 x pizza
343 x toward
我们发现其它单词也或多或少地会被抽到。
而 temperature sampling 就是在基于概率抽样的基础上更进一步,在softmax之前,对logits 除一个大于0的常数temperature:
def softmax_with_temperature(logits, temperature):
scaled_logits = logits / temperature
return torch.softmax(scaled_logits, dim=0)
temperatures = [1, 0.1, 5]
scaled_probas = [softmax_with_temperature(next_token_logits, T) for T in temperatures]
x = torch.arange(len(vocab))
bar_width = 0.15
fig, ax = plt.subplots(figsize=(5, 3))
for i, T in enumerate(temperatures):
rects = ax.bar(x + i * bar_width, scaled_probas[i],
bar_width, label=f'Temperature = {T}')
ax.set_ylabel('Probability')
ax.set_xticks(x)
ax.set_xticklabels(vocab.keys(), rotation=90)
ax.legend()
plt.tight_layout()
plt.show()
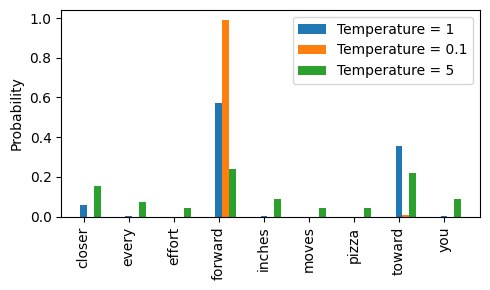
- 不难发现当除的 temperature 越小,抽样分布越极端
- 因为指数函数增长很快,此时越大的logit越容易占主导
- 当除的 temperature 越大,抽样分布越均匀
- 理解方式类似
1.3.2 Top-k sampling
其实就是束搜索(beam search)。
每次选取当前所有可能分支中概率最高的k个。
def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
if top_k is not None:
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(
logits < min_val,
torch.tensor(float('-inf')).to(logits.device),
logits
)
if temperature > 0.0:
logits = logits / temperature
probs = torch.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
else:
idx_next = torch.argmax(probs, dim=-1, keepdim=True)
if idx_next == eos_id:
break
idx = torch.cat((idx, idx_next), dim=1)
return idx
torch.manual_seed(123)
token_ids = generate(
model=model,
idx=text_to_token_ids("Every effort moves you", tokenizer),
max_new_tokens=15,
context_size=GPT_CONFIG_124M["context_length"],
top_k=25,
temperature=1.4
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
Output text:
Every effort moves you stand to work on surprise, a one of us had gone with random-
1.4 Loading and saving model weights in PyTorch
pytorch 保存模型权重非常的简洁明了:
torch.save(model.state_dict(), "model.pth")
这样就在当前目录下,保存模型的 state_dict 为 model.pth文件。
我们通过 state_dict 保存模型权重后,可以直接加载权重到新模型中:
model = GPTModel(GPT_CONFIG_124M)
model.load_state_dict(torch.load("model.pth", map_location=device))
model.eval()
我们用eval来暂停模型的一些训练策略(如dropout等),但在inference后,我们如果想接着训练的话,更建议的是把optimizer的权重也保存了:
torch.save({
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
},
"model_and_optimizer.pth"
)
然后我们可以通过torch.load加载:
checkpoint = torch.load("model_and_optimizer.pth", map_location=device)
model = GPTModel(GPT_CONFIG_124M)
model.load_state_dict(checkpoint["model_state_dict"])
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-4, weight_decay=0.1)
model.train()
1.5 Loading pretrained weights from OpenAI
先运行这段代码从github仓库获取下载权重的脚本。
import urllib.request
url = (
"https://raw.githubusercontent.com/rasbt/"
"LLMs-from-scratch/main/ch05/"
"01_main-chapter-code/gpt_download.py"
)
filename = url.split('/')[-1]
urllib.request.urlretrieve(url, filename)
然后调用脚本下载权重:
from gpt_download import download_and_load_gpt2
settings, params = download_and_load_gpt2(
model_size="124M", models_dir="gpt2"
)
settings 类似于 GPT_CONFIG_124M,里面是一些参数配置
params 则包含了gpt2的权重 tensor
二者都是字典
print("Settings:", settings)
print("Parameter dictionary keys:", params.keys())
Settings: {'n_vocab': 50257, 'n_ctx': 1024, 'n_embd': 768, 'n_head': 12, 'n_layer': 12}
Parameter dictionary keys: dict_keys(['blocks', 'b', 'g', 'wpe', 'wte'])
我们先定义模型:
# Define model configurations in a dictionary for compactness
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
# Copy the base configuration and update with specific model settings
model_name = "gpt2-small (124M)" # Example model name
NEW_CONFIG = GPT_CONFIG_124M.copy()
NEW_CONFIG.update(model_configs[model_name])
NEW_CONFIG.update({"context_length": 1024, "qkv_bias": True})
gpt = GPTModel(NEW_CONFIG)
gpt.eval();
值得注意的是,原始的gpt-2-124M的context_length=1024,而我们之前写的是256,所以需要更新一下
为了防止加载权重的时候加载错误,我们可以加一个长度检查函数:
def assign(left, right):
if left.shape != right.shape:
raise ValueError(f"Shape mismatch. Left: {left.shape}, Right: {right.shape}")
return torch.nn.Parameter(torch.tensor(right))
然后就是一一匹配加载:
import numpy as np
def load_weights_into_gpt(gpt, params):
gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params['wpe'])
gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params['wte'])
for b in range(len(params["blocks"])):
q_w, k_w, v_w = np.split(
(params["blocks"][b]["attn"]["c_attn"])["w"], 3, axis=-1)
gpt.trf_blocks[b].att.W_q.weight = assign(
gpt.trf_blocks[b].att.W_q.weight, q_w.T)
gpt.trf_blocks[b].att.W_k.weight = assign(
gpt.trf_blocks[b].att.W_k.weight, k_w.T)
gpt.trf_blocks[b].att.W_v.weight = assign(
gpt.trf_blocks[b].att.W_v.weight, v_w.T)
q_b, k_b, v_b = np.split(
(params["blocks"][b]["attn"]["c_attn"])["b"], 3, axis=-1)
gpt.trf_blocks[b].att.W_q.bias = assign(
gpt.trf_blocks[b].att.W_q.bias, q_b)
gpt.trf_blocks[b].att.W_k.bias = assign(
gpt.trf_blocks[b].att.W_k.bias, k_b)
gpt.trf_blocks[b].att.W_v.bias = assign(
gpt.trf_blocks[b].att.W_v.bias, v_b)
gpt.trf_blocks[b].att.out_proj.weight = assign(
gpt.trf_blocks[b].att.out_proj.weight,
params["blocks"][b]["attn"]["c_proj"]["w"].T)
gpt.trf_blocks[b].att.out_proj.bias = assign(
gpt.trf_blocks[b].att.out_proj.bias,
params["blocks"][b]["attn"]["c_proj"]["b"])
gpt.trf_blocks[b].ff.layers[0].weight = assign(
gpt.trf_blocks[b].ff.layers[0].weight,
params["blocks"][b]["mlp"]["c_fc"]["w"].T)
gpt.trf_blocks[b].ff.layers[0].bias = assign(
gpt.trf_blocks[b].ff.layers[0].bias,
params["blocks"][b]["mlp"]["c_fc"]["b"])
gpt.trf_blocks[b].ff.layers[2].weight = assign(
gpt.trf_blocks[b].ff.layers[2].weight,
params["blocks"][b]["mlp"]["c_proj"]["w"].T)
gpt.trf_blocks[b].ff.layers[2].bias = assign(
gpt.trf_blocks[b].ff.layers[2].bias,
params["blocks"][b]["mlp"]["c_proj"]["b"])
gpt.trf_blocks[b].norm1.scale = assign(
gpt.trf_blocks[b].norm1.scale,
params["blocks"][b]["ln_1"]["g"])
gpt.trf_blocks[b].norm1.shift = assign(
gpt.trf_blocks[b].norm1.shift,
params["blocks"][b]["ln_1"]["b"])
gpt.trf_blocks[b].norm2.scale = assign(
gpt.trf_blocks[b].norm2.scale,
params["blocks"][b]["ln_2"]["g"])
gpt.trf_blocks[b].norm2.shift = assign(
gpt.trf_blocks[b].norm2.shift,
params["blocks"][b]["ln_2"]["b"])
gpt.final_norm.scale = assign(gpt.final_norm.scale, params["g"])
gpt.final_norm.shift = assign(gpt.final_norm.shift, params["b"])
gpt.out_head.weight = assign(gpt.out_head.weight, params["wte"])
load_weights_into_gpt(gpt, params)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
gpt.to(device);
load_weights_into_gpt(gpt, params)
gpt.to(device)
随便跑个预测:
torch.manual_seed(123)
token_ids = generate(
model=gpt,
idx=text_to_token_ids("Every effort moves you", tokenizer).to(device),
max_new_tokens=25,
context_size=NEW_CONFIG["context_length"],
top_k=50,
temperature=1.5
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
Output text:
Every effort moves you toward finding an ideal new way to practice something!
What makes us want to be on top of that?
输出句子的语法都很正常,说明加载没什么问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)