2026年小白程序员必备:10个AI技能助你玩转大模型,收藏学习!
本文介绍了2026年上半年AI领域最值得学习的10项技能,包括Agent Skills、OpenClaw、Harness、Multi-Agent、Coding Plan、CLI回归、Desktop Agent、Physical AI、语音交互和Seedance 2.0。文章详细阐述了这些技能如何改变AI应用场景,以及它们如何帮助个人提升工作效率和创新能力。对于想要了解和学习大模型的程序员和小白来说,本文提供了宝贵的指导和实用的技巧。

昨天晚上做饭的时候,我用手机命令电脑里的 AI 干了三件事:打开一堆 PDF 发票整理成 Excel 报销单、一句话给电影《火遮眼》做一个带宣传视频+海报的网站,以及按我的风格给这篇稿子写个开头。
饭做完,活儿干完了。
这种事,一年前是科幻,今年是日常。
我说这个不是要煽情。我是想说,2026 上半年的 AI,已经不是“哪个模型分高”那回事了。模型这一头的卷,到 GPT-5.5、Claude 4.8、M3 这一档,边际收益肉眼可见地在递减。真正发生变化的地方,悄悄挪到了别处——挪到了你怎么把 AI 装进自己生活、装进自己工作流以及装进自己的电脑里。
这半年我一线测过的产品多到说不清,发布会看到一半就关掉的也多到数不清。这篇文章不是流水账,是我从一堆事里挑了 10 件,自己亲手用过、踩过坑、形成判断的,串成一条线。
10 个话题的顺序是:Agent Skills、OpenClaw、Harness、Multi-Agent(包括Agent OS、Sub-agent)、Coding Plan、CLI回归、Desktop Agent、Physical AI、语音交互、Seedance 2.0。
一万字,慢慢看。
一、Agent Skills:2026 年最值得学的技能
整个上半年,最被低估、又最影响一线工作流的事,是 Agent Skills。
它在半年里完成了从一家厂的功能,到行业标准的跨越。Anthropic 去年 10 月推出,12 月做成开放标准,到现在OpenAI、谷歌以及国内 AI 厂商全跟上。
那它到底是什么。一句话理解,Skills 是一个文件夹,里面必须有一份 SKILL.md,开头是 YAML 元数据 name 和 description,下面是 Markdown 写的执行说明,再带上可选的 scripts 子目录、references 子目录和 assets 资源文件。
skill-name/├── SKILL.md (必需)│ ├── YAML frontmatter (必需)│ │ ├── name: (必需)│ │ └── description: (必需)│ └── Markdown instructions (必需)└── Bundled Resources (可选) ├── scripts/ - 可执行代码 ├── references/ - 参考文档 └── assets/ - 资源文件
Agent Skills 最有意思的是 progressive disclosure 这个渐进式披露机制。三层结构。第一层是元数据,每个 Skill 大约 50 到 100 个 token,会话启动时全部 Skills 的 name 和 description 都进系统提示词,模型只是“知道有这些 Skill 存在”。第二层是指令,整份 SKILL.md 的正文,官方建议控制在 5000 token 以内、500 行以内,只在模型判断当前任务匹配某个 Skill 时才加载进上下文。第三层是资源,scripts 和 references 这些更深的文件,只在 SKILL.md 主动 reference 到它们时才进上下文。
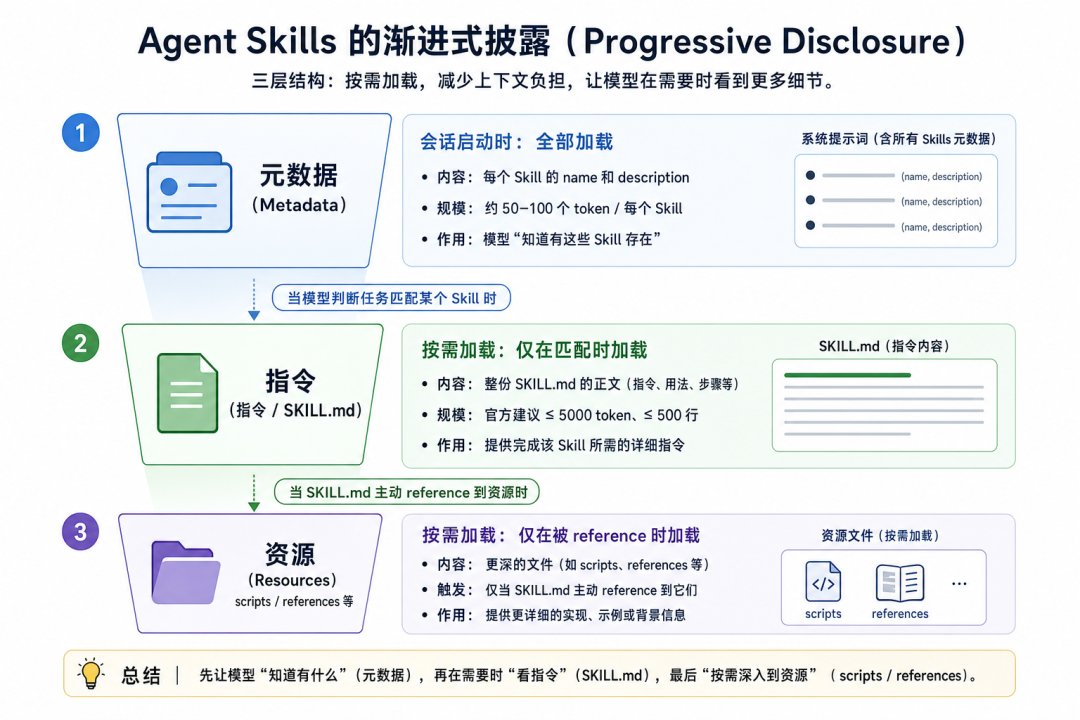
这套架构在解决一个非常实在的问题,上下文的稀缺性。早期 Agent 的痛点是塞东西,谁都想往 System Prompt 里塞更多专业知识,但塞越多模型越糊。Skills 把“有哪些能力”和“具体怎么干”在物理上拆开了,让模型只为正在做的事付 token。
Skills 解决的真正问题,不是 Prompt 长短,是个人知识的资产化。一个公司里最值钱的从来不是 SOP 文档,而是只有几个老员工才知道的“这个表必须按这个口径填”。过去这种东西要么靠人传人,要么写成员工手册然后没人看。Skills 第一次让“个人或团队的方法论”具备了被分发、被复用、被版本化管理的形态。
我自己用下来,最大的感受是效率神器。我给沃垠AI写了一堆 Skill,从选题收集、写作风格到标题生成,每加一个新 Skill,模型在没触发它的时候完全感受不到,触发后又能精准照做。这种“加它不亏,用它管用”的体验,是 Prompt 工程时代不可能有的。
时间走到 2026 年 6 月,再说“学会怎么问 AI”已经过时了。该学的是怎么教 AI,而 Skills 是这件事最干净的载体。
二、OpenClaw:全民 Agent 的第一次破圈
2026 年春节后,国内 AI 圈最热的一个名字是龙虾,学名 OpenClaw,开源协议,TypeScript 写的。这名字怎么来的,故事很简单。作者 Peter 想做一个叫 Molty 的“太空龙虾”AI 助理,做着做着把底层那一块抽出来开源,名字就成了 OpenClaw,“Open + 螯”。其GitHub Star数已达到37万,成为开源Top 1。

它解决了一个被忽视很久的问题。
过去做 Agent,主流路径就两条。比如 ChatGPT 的 Operator、Manus、Genspark 这些,你点开网页用,体验好但你的对话、文件、Memory 全在别人家服务器上跑。另一类是 Claude Code、Codex 这种 CLI,本地是本地,但本质上是一个写代码的终端工具,多通道、跨设备、永远在线这件事它不管。
OpenClaw 把这两条路接起来了。它本身不是模型,是一个本地起的 Gateway,给你接全套通讯渠道,然后挂任何你想用的LLM。微信、Telegram、WhatsApp、Slack、Discord,连 macOS / iOS 的语音唤醒和 Android 的连续语音都做了,背后都是同一个跑在你自己机器上的 Agent,同一份 Memory,同一份 Skill 库。
它真正引爆是春节那阵,几乎全民都在养龙虾。Kimi、GLM 和 MiniMax 相继推出了 Coding Plan,能在 OpenClaw 里直接挂国产模型。99元一个月你能跑一个永远在线的私人 Agent,搁一年前是不敢想的事。
但说实话它有它的“贵”。OpenClaw 是个心思特别细腻的管家,每一轮对话都拖家带口地把系统提示、长期记忆、技能元数据全塞进去。我刚装上那会儿,充了 50 块到云厂商,问到第三个问题余额就负了。OpenClaw 的 token 消耗大概是 Claude Code 的 3 到 5 倍。这不是 bug,是它的形态决定的。一个永远在线、跨多通道的 Agent,必须随时拎着完整上下文,否则人格、记忆、技能就接不上。
这玩意来得快,去得也快。现在,龙虾热潮已经大大降低,还留下来在玩的人绝对是龙虾的超级发烧友。它当然还有很多问题,比如新手门槛较高,安全性一直是个大问题,以及很烧token。但它把“自动化 Agent”从极客玩具拽到了大众能用的水平,这一步意义已经够大。
我个人的判断是,2026 下半年的核心战场不在通用 ChatBot,而在每个人都可以有自己的专属 Agent。OpenClaw 是第一个真正能跑通的开源样本。
三、Harness:给 LLM 牵一条缰绳
Harness Engineering,在 2026 年上半年讨论还挺火热的。当然这个火热主要集中在 AI 公司里,非 AI 从业者可能关注比较少。
中文翻译挺别扭,挽具、马具、缰绳,怎么翻都不传神。它指的是包在 LLM 外面一整层的工程化基础设施,包括指令 (Instructions)、约束 (Constraints)、反馈 (Feedback)、记忆 (Memory)、编排 (Orchestration)等。它的核心作用,是把一个原本不可预测的模型,变成一个稳定、可控、可用的“数字员工”。
为什么 Harness 突然在 2026 年变成共识。一个原因是大家发现,模型再强也撑不住上下文爆炸,真正决定成败的是它外面那层“缰绳”。同样一个模型,在 Cursor 里跑和在 Claude Code 里跑,体感差好几个段位,差就差在 Harness 的工程质量。
这个语境里跑出来的代表产品叫 Hermes Agent。开源,可自由接Claude、GPT、Kimi、GLM、MiniMax、Qwen和DeepSeek,3月开始成为 AI 极客的新宠儿,超过 OpenClaw。

它解决的问题,跟 OpenClaw 表面像,但骨子里不一样。OpenClaw 的核心叙事是“自动化 Agent”,跨通讯通道、本地永远在线。Hermes Agent 的核心叙事是“自我进化的Agent”。你今天教它一件事,下周它会自己评分、决定保留还是淘汰,质量不行的 Skill 它会自己合并或者删掉。
6月3日,Hermes Agent推出了桌面版,macOS、Windows、Linux都能用,前后端共享同一份配置、技能和记忆。你在CLI起的会话,能直接接到桌面端。
我自己的判断是,Harness 在 2026 下半年会越来越重要。模型层的卷已经开始边际递减,Harness 这一层才刚开始。
四、Multi-Agent:Agent 开始组队干活
2026 年上半年,Agent 圈最显著的变化是单 Agent 开始过时了。
不是 AI 不够强,是任务变复杂了。一个企业级代码迁移、一份跨多平台的市场调研、一次大型 bug 跨服务排查,单一上下文窗口塞不下,单一思路也跑不完。多 Agent 协作在这半年里从论文走到了产品,名词也跟着分裂出来一堆,Sub-agent、Agent Team、Multi-Agent、Agent OS,听起来近,差别大。
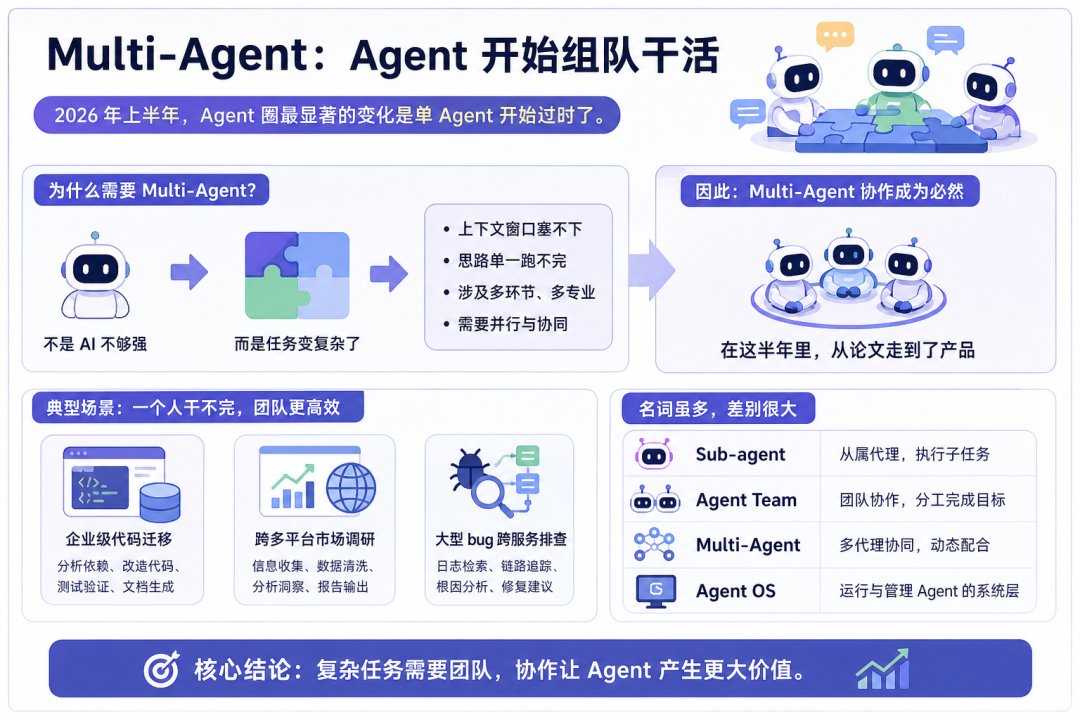
先把这几个词分清楚。
Sub-agent。一次性、隔离、向上汇报。主 Agent 派一个或一组子 Agent 出去干活,子 Agent 有自己的上下文窗口,干完只把结果汇总回来,期间互不通讯。这是最轻量的多智能体形态,本质是上下文隔离 + 并行加速。Claude Code 文档里把这一类描述得很直白,fire-and-forget worker。VS Code 1.109 在 2026 年 2 月把 Sub-agent 做成了 IDE 一等公民,直接支持多个子 Agent 并发跑、可视化看进度。
Agent Team。多个Sub-Agent + 一个 Team Lead,长跑、共享任务列表、有 mailbox 互相通讯。区别在于队员之间能直接对话、能争论、能在发现问题时彼此预警。代价是 token 成本起飞。
Dynamic Workflows。Anthropic 5 月 28 日跟 Opus 4.8 一起发的东西,中文名叫“动态工作流”。它不是让你手动派子 Agent,而是让 Claude 自己写一份 orchestration 脚本,动态决定要拉几十甚至上百个子 Agent,并行跑、独立验证、再交叉收敛。官方给的演示场景是大型代码库迁移和企业级 bug 跨服务排查,本来要几周的活儿压到几天。
Agent OS。这是野路子最多的一个词,没有过官方定义。开发者社区里折腾出来的形态是:一个 CEO Agent 做规划,一个 COO Agent 做路由,再有一个研究员做长程任务,一个个人助理采集屏幕和麦克风做上下文。说白了就是用多个开源 Agent 拼一个个人级的 AI 操作系统。
Multi-Agent。这是最大的伞概念,上面所有的形态都属于它。Cursor v3 内置最多 8 个并发 Agent,Google Antigravity 2.0 上线了 Agent Teams,GitHub Copilot 也跟进了 multi-agent workspace,amux 这种工具不可知的 orchestrator 用 tmux + SQLite 任务板 + git worktree 把多个不同厂的 Agent 编在一起跑。
为什么 2026 年上半年“多智能体架构”这件事突然集中爆发。我自己的判断有三条线索。
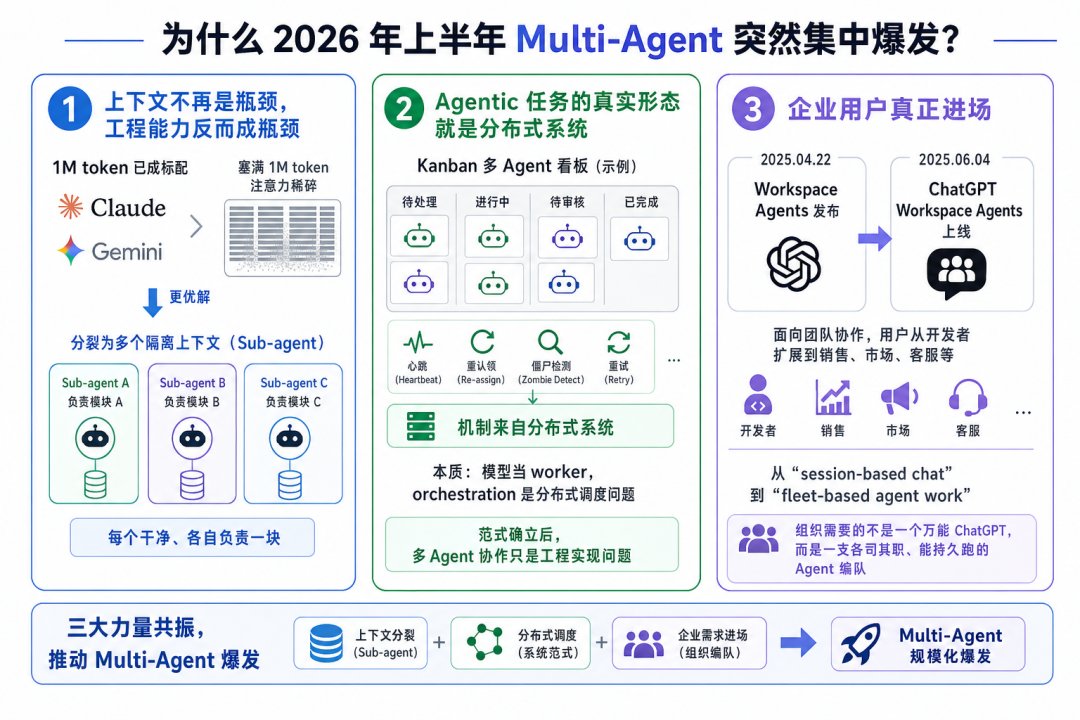
第一条,模型上下文窗口不再是瓶颈,工程能力反倒成了瓶颈。1M token 已经是 Claude、Gemini 的标配,但你真把 1M 都塞满,模型注意力切得稀碎。与其往一个上下文里硬塞,不如分裂成多个隔离上下文跑,每个干净、各自负责一块。这是 Sub-agent 流行的根本原因。
第二条,Agentic 任务的真实形态就是分布式系统。Hermes Agent v0.13 那个 Kanban 多 Agent 看板我之前讲过,心跳、重认领、僵尸检测、retry,这些机制全是从分布式系统直接搬来的。Agent Team 也好、Dynamic Workflows 也罢,本质都是把模型当 worker,把 orchestration 当成一个分布式调度问题。这个范式一旦确立,多 Agent 协作就只是工程实现问题了。
第三条,企业用户真正进场。OpenAI 4 月 22 日发的 Workspace Agents、6 月 4 日上线的 ChatGPT Workspace Agents,全是冲着团队协作来的,目标用户从开发者扩到了销售、市场、客服。这是从“session-based chat”到“fleet-based agent work”的范式迁移。组织里需要的从来不是一个万能 ChatGPT,而是一支各司其职、能持久跑的 Agent 编队。
我自己体验下来最大的体会:Sub-Agent 真好用,token 翻倍但任务质量明显跳一档,特别是在长程研究和编程这类场景。Agent Team 就一言难尽了,多个 Agent 互相通讯听起来美,实际跑起来经常出现“两个队员都觉得对方应该先动”的死锁。动态工作流真有效果,但成本是真高。
回头看会觉得很有意思,2024 年我们说 Agent 是工具调用,2025 年说 Agent 是工作流,2026 年终于说到了“Agent 团队”这个层级。一个跑得好的 Agent 团队,不再像一个工具,更像一个真正的部门。
五、Coding Plan:AI 市场化路上的经典事件
2026 年上半年,影响开发者最大的一次价格革命,是 Coding Plan。
这事的来龙去脉得从一年前讲起。Cursor、Claude Code这些 AI 编程工具,2024 年上线时几乎统一按 token 计费。一个稍微复杂点的编程任务,跑一次 Opus 几十美元起步,OpenClaw 这种 24 小时在线的 Agent 一天烧出几百块也不稀奇。我自己装 OpenClaw 那会儿,充 50 块API进去,问到第三个问题余额就负了。这是非常真实的体验,不是段子。
按 token 付费,费用真的离谱。每一次按回车前,你脑子里都得过一遍这个 prompt 大概要烧多少钱。开发者最讨厌的事就是这种持续认知税,写代码本来就累,再叠一层成本焦虑,体验直接劝退。
转折点是 GLM 推出的 GLM Coding Plan。
定价结构很直接。20 元一个月起,从 Lite 到 Max 200 元封顶。相比 Anthropic 自家 20 美元的 Pro 和 100 美元的 Max,定价差出一个数量级。给的不是次数限制,是 5 小时滚动配额加上 7 天周配额。20 元这一档基本能撑住一个全职程序员每天的 AI 编程量。
更关键的是兼容生态。改一行环境变量就能切过去,国产模型直接挂在 Claude Code 的壳子里跑。MiniMax、Kimi、阿里云百炼、火山方舟、阶跃星辰等紧跟其后对标。大家一联手,整个行业的定价范式被改变了。
为什么 Coding Plan 这个形态能成。我自己的理解有三条。
第一条,模型边际成本下来了。GLM-5.1 在主流编程基准上能做到 Opus 4.6 大约九成的水平,国内推理成本本身就低,再加上 GLM 自有云、自家模型、自营售卖,一手货卖给开发者。MiniMax、Kimi同理。这种垂直整合让“低价吃饱”在商业上跑得通。
第二条,开发者不需要“最强模型”,需要“够用且不贵”。我自己天天用 Claude Code 的体感最直接,写日常的脚本、做网站、跑 Skill,GLM-5.1 在 Claude Code 壳子里基本无感,跟原生 Sonnet 体验差不多。
第三条,订阅制本身降低了认知税。每月固定支出,按惯性跑,大脑不再对“这次该不该问”做经济计算。这件事的工程意义被严重低估。开发者愿意问得更多、试得更猛、错得更频繁,这正是 AI 编程能力涨上来的土壤。
2026 下半年,我认为 Coding Plan 还会继续下沉,月费 20 美元这一档会逐步成为开发者标配。
Coding 的成本焦虑是过去两年最大的一道墙,Coding Plan 把这道墙拆掉了。这事的功劳簿上,GLM 得记一笔。
六、CLI:AI 时代的统一接口
2026 年回头看,CLI 这个东西在 AI 圈里地位的逆转挺戏剧的。
往前两年还在说“AI 让普通人不用学命令行了”。Copilot 写代码、Cursor 拉聊天框、ChatGPT 用网页对话,所有产品都在做更轻、更视觉、更小白的入口。
但到了 2025 年下半年,风向掉头。Anthropic 推出 Claude Code,OpenAI 拿出 Codex CLI,Google 发布 Gemini CLI,几个月内三大厂同步发布一个跑在终端
最直接的原因是 Coding Agent 的最佳工作面就是文件系统和命令行。你让一个 Agent 帮你做迁移,它得能切目录、能 git、能跑测试。这些动作在图形界面里全是绕路,在终端里就是原生。CLI本身就是历史上最稳定、最强大的“工具调用协议”,过去四十年程序员积累下来的所有工具都能直接用上。
更深一层,CLI 是被严肃对待的“人机协作界面”。GUI 优化的是首次使用的好懂,CLI 优化的是高频使用的快和稳。
除了 Coding Agent 喜欢 CLI 外,其他很多产品也都在 CLI 化。比如,飞书可以 CLI 链接各个 Agent 里。甚至很多产品开发出两版,一版是 GUI 给人类用,一版是 CLI 给 AI 用。这是今年特别有意思的一个事情。
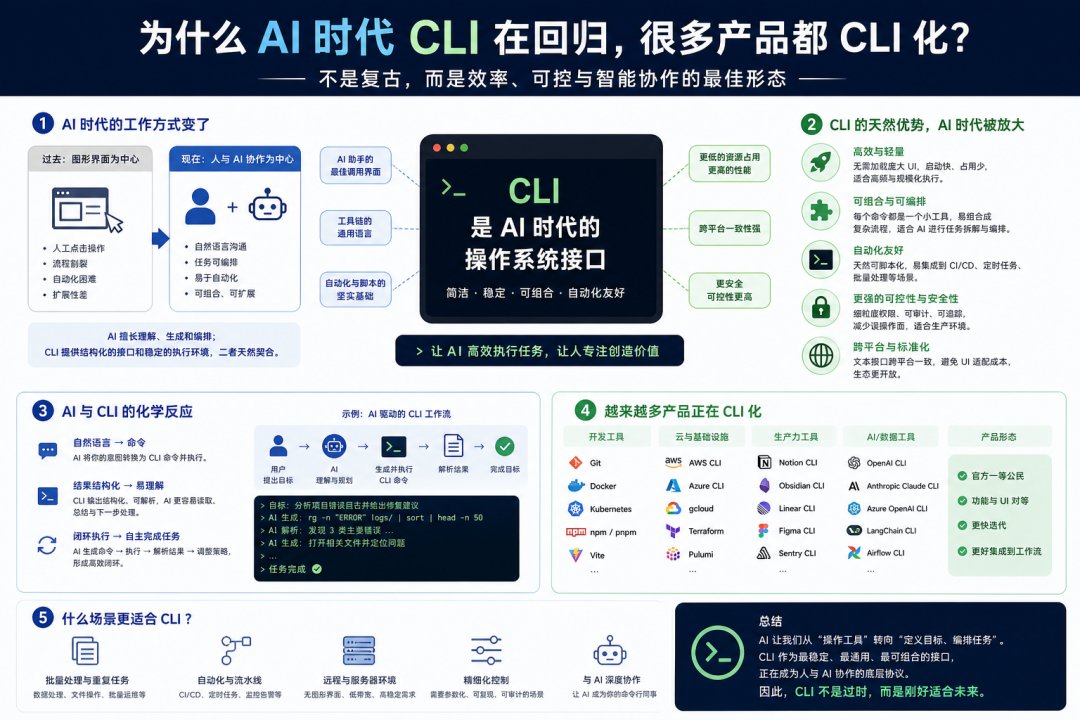
但 CLI 也不是完美的。它对新手仍然不友好,CLAUDE.md / AGENTS.md 该写什么、Plan Mode 怎么用、Sub-Agent 派多少个、Skills 怎么挂,这些都需要学习成本。它对持续会话也仍然挑战大,长程任务跑到一半窗口断了、tmux 挂了,恢复体验跟 GUI 差着一个段位。这也是为什么 Hermes Desktop 这种“命令行内核 + 桌面壳子”的形态会出现。
下一波的产品演化,我猜会出现在“命令行内核 + 多形态壳子”这一层。终端、桌面、Web 全打通,记忆和技能跨表面共享。
七、Desktop Agent:AI 真正走进你的电脑
2026 年上半年最具体的一次范式变化,是 Desktop Agent 这个形态终于跑通了。
我说的“具体”是真的具体。AI 不再是浏览器里的一个 Chat 网页,而是一个本地跑着的程序,能读你磁盘上的文件、调你电脑里的应用、敲你桌面上的键。这件事被预言了两三年,今年上半年多家 AI 公司都给出了答案。
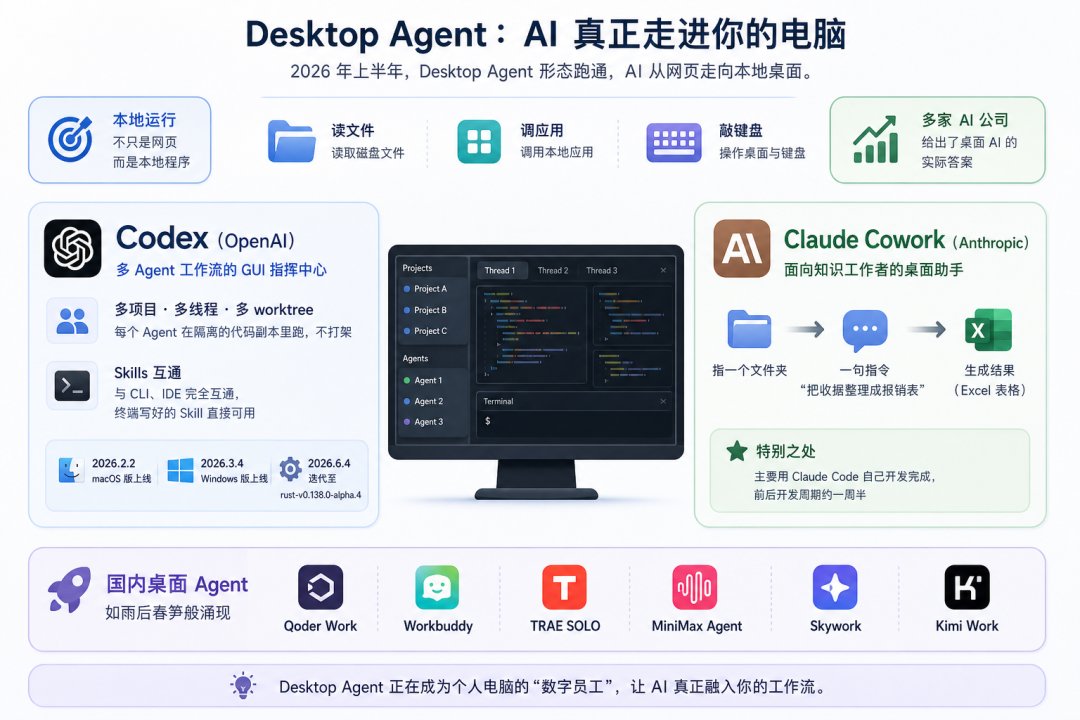
Codex(OpenAI)。2026年2月2日 macOS 版上线,3月4日 Windows 跟上,6月4日已经迭代到 rust-v0.138.0-alpha.4。它定位很明确,不是来替代 Codex CLI 的,是给多 Agent 工作流做一个 GUI 指挥中心。一个窗口里同时挂多个项目、多个线程、多个 worktree,每个 Agent 在隔离的代码副本里跑,不打架。Skills 跟 CLI、IDE 完全互通,你在终端里写好的 Skill 在 Codex 里直接能用。
Claude Cowork(Anthropic)。瞄的不是开发者,是知识工作者。你给它指一个文件夹、说一句“把收据整理成报销表”,它去读、去归类、去出 Excel。有一个细节我特别喜欢:Cowork 主要是用 Claude Code 自己写出来的,前后开发周期大概一周半。这本身就挺戏剧的,一个 Coding Agent 给自己写出来一个面向非程序员的 Desktop Agent。
同时国内,Qoder Work、Workbuddy、TRAE SOLO、MiniMax Agent、Skywork、Kimi Work等桌面端产品也如雨后春笋般冒了出来。
为什么是 2026 上半年。
第一个原因是模型层准备好了。Computer Use 这件事 2024 年 Anthropic 第一次放出来的时候跑得通,但稳定性一塌糊涂。一年后 Claude 4.x 系列、GPT-5 系列在视觉理解、UI 元素定位、连续操作上达到了“敢上线”的水平。Online-Mind2Web 这种浏览器自动化基准测出来的成绩从去年的“勉强”变成了“能用”。
第二个原因是 Skills 标准化了。Desktop Agent 跟 Coding Agent 的最大区别是它要面对的工具种类多到爆炸。每一个应用都是一种隐性 SOP,没法写死在模型里。Skills 给了一个把隐性知识沉淀下来的载体。Anthropic 12 月 18 日把 Agent Skills 做成开放标准之后,Desktop Agent 这件事的拼图就齐了。
第三个原因是企业进场。Workspace Agents 那一节我讲过,OpenAI 4 月 22 日的产品定位就是替代传统 GPT 的“组织级 AI 同事”。Claude Cowork 也是冲着这个去的,它的 Enterprise 部署文档里专门讲 SSO、MDM、MSIX 安装包,这些都是给 IT 部门看的语言。Desktop Agent 不只是给个人用的智能助理,是企业 IT 资产的一部分。
那它解决了什么。
我自己用下来最直接的体感是消除了复制粘贴这件事。过去用 Chatbot 做研究,最大的工作量不是问问题,是把网页内容复制到对话框、把 AI 输出复制到本地文档、把表格内容反复倒腾。Desktop Agent 直接把这一层抹掉了,文件就是它的输入输出,应用就是它的工具,整个工作流闭环。
第二个体感是任务能力被拉长放大了。Web 端 chat 是一来一回的会话,超过五分钟你就会下意识觉得它卡了。Desktop Agent 是常驻进程,可以挂十几分钟、几十分钟跑一个长程任务,你该干别的就干别的,它跑完会自己回来通知你。这种异步感才是 Agent 真正的形态。
Desktop Agent 这件事最大的意义是,AI 第一次真正入住到你的电脑里。它不在云端、不在浏览器、不在 chat 窗口里,它就在你本地这台机器的进程列表里,是一个写在 macOS 活动监视器或者 Windows 任务管理器里的名字。这个名字可能是它真正成为“AI 同事”的那道门槛。
八、Physical AI:AI 终于开始有身体了
如果说前面七个话题都还在说 AI 在数字世界里的演化,那 Physical AI 是 2026 上半年最大的“破壁”事件。
AI 终于开始有身体了。而且不是 demo 视频里的那种身体,是真正在工厂里上下班、在大学里做研究、在汽车产线上拧螺丝的那种身体。

先说硬件这一头。截至 2026 年中,全球大约有 7000 到 8000 台商用人形机器人在跑。中国这边,AGIBOT 3 月底交付到第 1 万台,宇树 6 月通过科创板上市委员会的审核,估值约 62 亿美元。海外这边,Tesla Optimus 量产了,目标 2 万到 3 万美元一台。Figure 03 已经在宝马工厂上线,Atlas 卖给现代汽车。
光看数字就能感觉到拐点。一年前所有人形机器人加起来还在几百台量级,今年集体跨过千台、万台。
但硬件不是核心叙事,软件才是。Physical AI 这个词的真正含义,是软件第一次能驱动一台机器在真实物理世界里“理解 + 行动”。
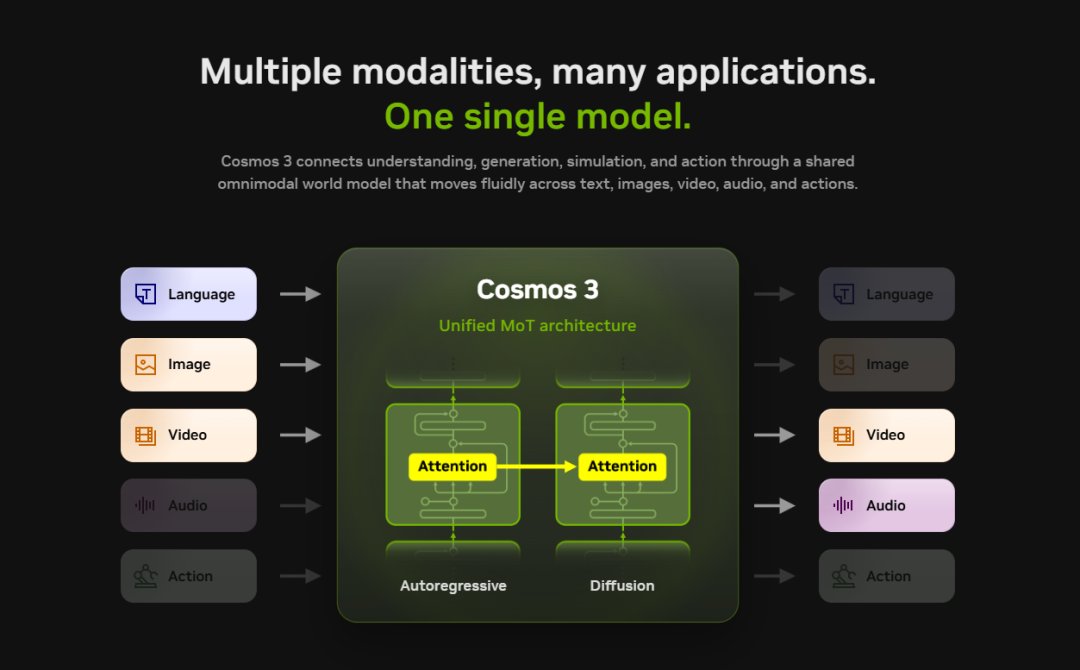
NVIDIA 是这一波最关键的推手。它发的 Cosmos 3 是一个“世界基础模型”,把“看懂世界 + 预测未来 + 生成动作”打包到一个模型里。配套的 GR00T 是人形机器人专用栈,同一份模型权重能在不同品牌的人形机器人上做适配。
这件事的意义在于,过去每家机器人公司都得自己从零训练模型,现在有了一个共享底座。NVIDIA 出大脑,机器人出身体,学术界出场景。这个合作姿态非常明确。
那 Physical AI 解决了什么。
我自己的判断是它解决了“AI 进入实体经济”这件事的最后一道接口。Knowledge work 这一头 AI 已经卷得很深,但全球 GDP 里超过一半其实是搬运、装配、巡检、护理这些手活儿。过去 AI 跟这一半经济基本绝缘,现在 Physical AI 把这道墙拆开了。
但它还没真正成为可用的 C 端产品。
C 端目前最近的是 1X Neo,宣布售价 2 万美元,目标 2026 年底交付。其他几家全是 B 端服务,Figure 03 在宝马工厂里跑、Optimus 在 Tesla 自家工厂里跑、Atlas 给现代汽车跑。
这事的真实瓶颈不是钱,是可靠性。一个能稳定跑 8 小时不死机的家用人形,对软件和硬件的考验比工业场景大一个数量级。家里地形复杂、孩子和宠物到处跑、光线复杂、任务边界模糊。Cosmos 3 这种世界模型在工业场景已经能用,在家庭场景仍然差着一截。
我个人对 Physical AI 是乐观的,但不是短期乐观,是长期乐观。2026 年是从几百台到几万台的跨越,2027 年要看能不能从工业场景跨到商业服务场景,比如餐厅、仓储、酒店。真正的 C 端拐点我猜要等到 2028 之后。
但就算节奏比硅谷宣传的慢,方向是对的。AI 不再只是屏幕里的一段对话,开始成为站在你面前会回头看你一眼的一个东西。这件事比所有 chatbot 加起来都更接近“AI 改变世界”那句话本来的意思。
九、语音交互:成为所有AI产品的标配
2026 年上半年最容易被忽略的一件事,是几乎所有的 AI 产品都默默装上了语音入口。
它可能不像其他话题那么高大上,但它真真实实改变了普通用户跟 AI 打交道的方式。一个最直观的判断标准:你想想去年这时候你怎么用豆包,再想想现在你怎么用,你会发现“打字”这个动作的占比在快速下降,“口喷交流”在快速上升。
它解决了什么。
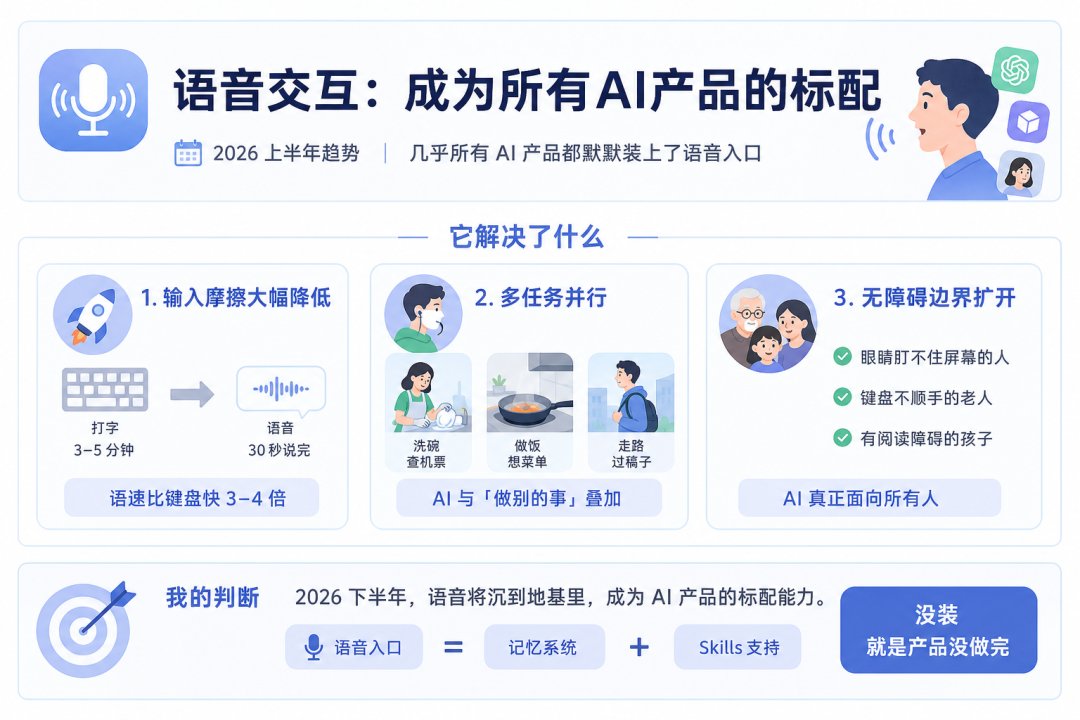
第一件,输入摩擦的彻底降低。我自己最直接的体感是写长 prompt 的时间成本被砍了一刀。过去布置一个稍微复杂点的任务,得在键盘上敲三五分钟,现在嘴巴一秒钟一句话,30 秒说完一个需求。语速比键盘快三到四倍。
第二件,多任务并行成本被砍了。以前用 AI 必须坐到电脑前停下手里的活儿,现在洗碗时候可以让 OpenClaw 帮你查机票、做饭时候让 ChatGPT 帮你想晚饭菜单、走路时候让 Claude 帮你过一遍今天要发的稿子。AI 第一次能跟“做别的事”叠加在一起。
第三件,无障碍的边界扩开了。眼睛盯不住屏幕的人、键盘不顺手的老人、有阅读障碍的孩子,这些人过去基本被 AI 的文字界面挡在外面。语音入口铺开之后,AI 真正面向所有人。
我的判断是,2026 下半年语音不会再是任何一家厂的差异化卖点,它会沉到地基里,跟记忆系统、skills支持一样,是 AI 产品的标配能力,没装就是产品没做完。
十、Seedance 2.0:中国模型第一次站在了世界中央
最后,我想用一个中国模型来作为收尾。
2 月,字节发布 Seedance 2.0。3 月,Seedance 2.0 进入 CapCut,先在巴西、印尼、马来西亚、墨西哥、菲律宾、泰国、越南这些海外市场上线。5 月,DeepLearning 用了一个挺有意思的标题,《字节把 Seedance 2.0 装进 CapCut,OpenAI 撤了》。Sora 那边那时候在收缩消费级业务,字节这边正把视频生成铺成 CapCut 数亿用户的默认能力。这是一个很具象的对比。

那 Seedance 2.0 到底是什么。
它的本质是一个统一的多模态生成框架。输入支持文字、图片、声音、视频,可以一次塞最多 9 张图、3 段视频、3 段音频做参考。输出是带原生音轨的视频,可以同步生成对白、环境音、音乐。视频时长 5 到 15 秒,分辨率 720p。
那 Seedance 2.0 解决了什么。
最直接的,它把 AI 视频从“试一下出几条分镜”推到了“能进生产管线”。15 秒 720p 配音乐配口型一次出,对短视频创作者、电商商品视频、社媒广告、教育课件这些日常场景简直就是大杀器。
更深一层,它改变了视频内容的供给结构。过去拍一条 60 秒的产品视频要演员、场地、剪辑、配音四项成本,现在 Seedance 2.0 + CapCut 一个人对着电脑两小时搞定。这件事对中小品牌、自媒体、跨境电商是真正的解放。
但 Seedance 2.0 不是没短板。分辨率天花板还在 720p 和 1080p 区间,跟 Veo 3.1 4K 比差着一档。连续叙事仍然是靠拼,转场处偶尔露馅。物理真实度仍有差距,流体、布料这些场景,Seedance 2.0 的“看着像”和 Sora 2 的“算出来的真实”是两个概念。另外,肖像权和版权风险大。
两年前我们说“中国 AI 视频是慢一拍的追赶者”,今年这话已经不能说了。Seedance 2.0、Kling 3.0、可灵、即梦这一拨一起把 AI 视频革命的舞台搬到了东半球。这一轮 AI 视频革命,最热闹的地方,已经不在硅谷。
写在最后
10 个话题写完,回头看其实只有一条主线。
2026 年上半年的 AI,不再是“模型多大、跑分多高、demo 多炸”的故事。它是把模型层卷出来的能力,往下沉、往外扩、往身边带的故事。
Skills 把方法论沉淀为资产,OpenClaw 和 Harness 把 Agent 框架变成了开源基础设施,harness 把 Agent 工程提升到了被严肃讨论的层级,Multi-Agent 把单兵 AI 升级成了团队 AI,Coding Plan 把成本焦虑拆掉,CLI 给了 AI 统一的接口,Desktop Agent 把 AI 装到本地,Physical AI 给 AI 装上身体,语音交互给 AI 装上耳朵和嘴,Seedance 2.0 让中国模型在视频赛道第一次坐上主桌。
每一件事单看都是技术演化,串起来看是 AI 第一次大规模开始成为日常。这种“成为”不是一次发布会能完成的,是无数个小齿轮咬合到位之后的自然结果。
下半年我会继续一线跑,继续测,继续记。
如果让我对 2026 下半年押一个判断,那就是“AI 的 iPhone 时刻并未过去,但应用商店时刻才刚刚开始”。AI 会越来越像水电煤,融在你做的每件事里,融到你都意识不到。
最后
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。
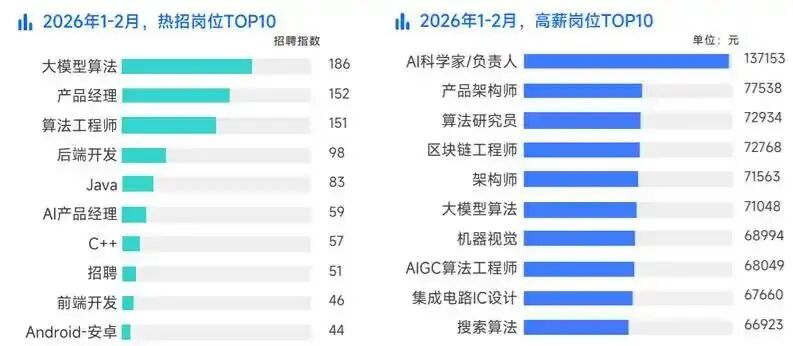
现在的市场,已经用数据给程序员指明了方向:学AI大模型,就是冲刺高薪的最优解!
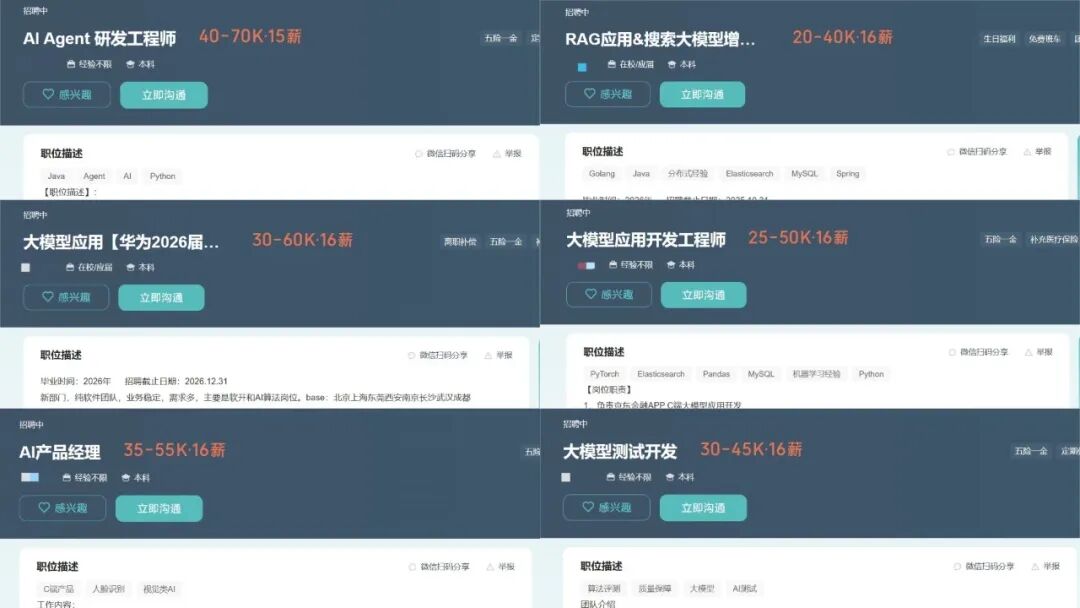
看着身边越来越多的同行转型大模型、拿到高薪offer,很多人心里都动了心,但真正的难题来了:零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?
别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序员和小白!
👇👇扫码免费领取全部内容👇👇

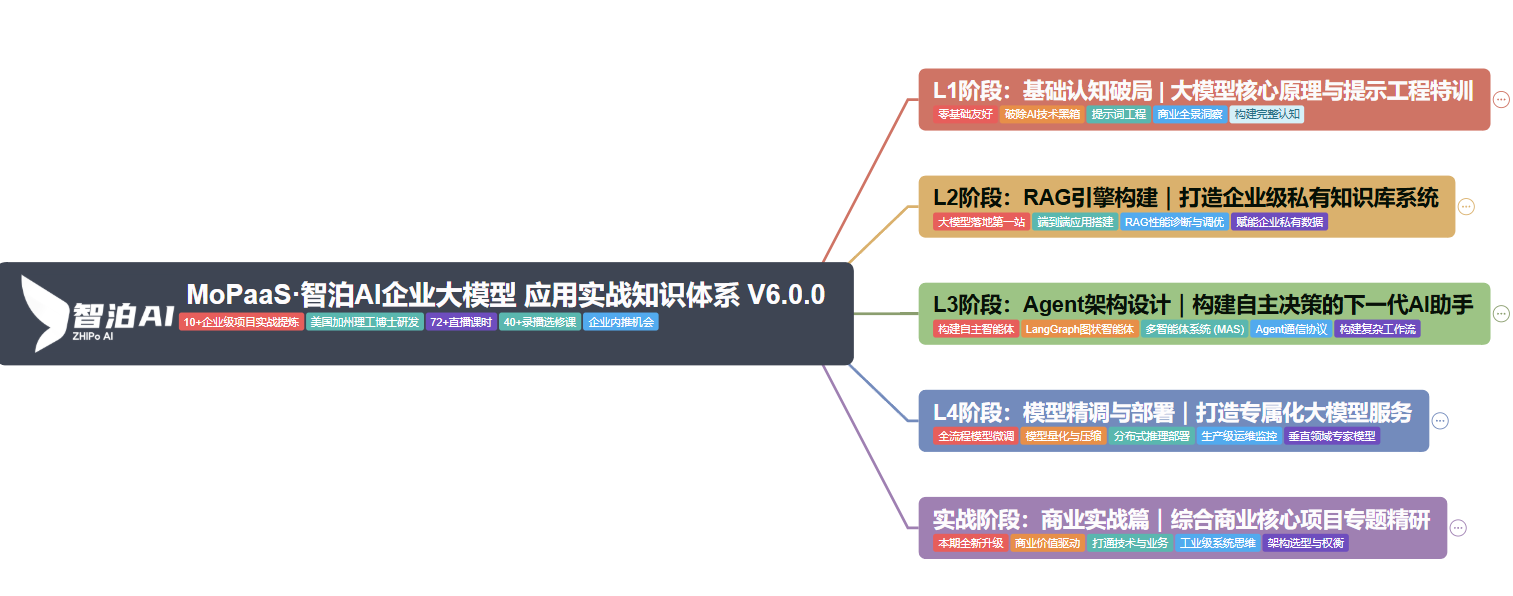
1、大模型系统化学习路线
2、大模型学习书籍&文档

3、AI大模型最新行业报告

4、大模型项目实战&配套源码

5、大模型大厂面试真题

四阶段精细化学习规划(附时间节点,可直接照做)
结合上述资源,给大家整理了一份可直接落地的四阶段学习规划,总时长约2个月,小白可循序渐进,程序员可根据自身基础调整节奏,高效掌握大模型核心能力,快速实现从“入门”到“能落地、能面试”的跨越。
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
👇👇扫码免费领取全部内容👇👇
6、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献308条内容
已为社区贡献308条内容

所有评论(0)