从脚本拼装到平台化:多系统告警归集+分级+自动派单+工单闭环的完整方案——我们为什么放弃了自建告警管道
2024年初,我们搭建了第一版告警归集方案:Zabbix Webhook → Python Flask服务 → Alertmanager → 企业微信机器人。核心代码不到300行,加上docker-compose跑三个容器,一个下午就搭完了。
那个下午确实很爽——Zabbix、Syslog、SNMP Trap三套告警终于收到一个企业微信群里了。但18个月后回头看,我们在这套方案上投入的维护时间,远超当初搭建的时间。
这篇文章不是要说"开源拼装不好"——它在30台设备、3个告警源、2人团队时跑得非常稳。我想写清楚的是:当规模涨上去之后,哪些东西该自己写、哪些东西该用平台,以及我们做这个判断的完整过程。
一、自建方案跑了一年半,我们遇到了什么
先交代环境。我们团队MSP模式下维护着多个客户的IT环境,其中最大的一个客户规模是:
- 200+设备(服务器+网络设备+IoT网关)
- 7个告警源:Zabbix、Prometheus/Alertmanager、交换机Syslog、机房环控SNMP Trap、阿里云云监控、安全设备API、定制业务探针
- 6人运维值班团队(3班轮转+1人机动)
- 日均告警量:约220条原始告警 → 经收敛后约25条需要人为关注
这套自建方案跑了18个月,处理了超过4万条告警。它没有"挂掉"——Flask服务一直稳定运行、Alertmanager从未丢过告警。问题是维护成本在悄悄涨。
问题一:每次加告警源都要动代码
最初只有Zabbix一个告警源时,Flask脚本的 normalize_alert() 函数只处理一种格式。后来每加一个告警源(Syslog、SNMP Trap、云监控回调……),就要加一个 elif source == "xxx" 分支。
第4个告警源时还好,第7个时就不好玩了——不同来源的字段命名不一致(有的叫host、有的叫hostname、有的叫device),映射逻辑散落在5个分支中,改了这处怕影响那处。
# 这还只是"告警源→统一格式"部分
# 实际还有:分级映射、收敛规则、派单路由、通知模板...
def normalize_alert(source, raw_data):
if source == "zabbix":
alert["host"] = raw_data.get("host", "")
alert["severity"] = map_zabbix_sev(raw_data.get("trigger_severity"))
elif source == "prometheus":
alert["host"] = raw_data.get("labels", {}).get("instance", "")
alert["severity"] = raw_data.get("labels", {}).get("severity", "P3")
elif source == "syslog":
alert["host"] = raw_data.get("hostname", "") # 注意:这里叫hostname!
alert["severity"] = map_syslog_sev(raw_data.get("severity"))
elif source == "snmptrap":
alert["host"] = raw_data.get("agent_addr", "")
alert["severity"] = "P2"
elif source == "aliyun_cloudmonitor":
alert["host"] = raw_data.get("instanceName", "") # 又不一样
alert["severity"] = raw_data.get("severity", "P3")
# ... 第6、7个告警源继续加elif
问题二:值班表变更需要改配置→Git commit→reload
最初2人值班时,派单规则硬编码在脚本里——“张工管网络、李工管服务器”。后来团队扩到6人、三班轮转,每次换班/调休都要改派单配置。
我们优化了一版:派单规则抽到YAML里,改完走Git → 发reload信号给Flask服务。看起来挺"DevOps"的,但实际体验是:凌晨3点值班人临时请假,另一个人替班——你要爬起来改YAML、push、reload,或者接受这个告警发给了错误的人。
# dispatch_rules.yaml —— 每次值班变更都要改
# 一个月大概要改4-6次(调班、请假、新人入职)
oncall_schedule:
weekdays_day:
network: ["zhangsan"]
server: ["lisi"]
security: ["wangwu"]
weekdays_night:
network: ["zhaoliu"] # 这周赵六请假→临时切给张三→改YAML
server: ["lisi"]
weekend:
all: ["zhouqi"] # 周末全员兜底
问题三:脚本维护在吃时间
贴一组真实数据。我们在6个月里统计了这套自建方案的时间投入:
| 维护类型 | 频次 | 单次耗时 | 月度耗时 |
|---|---|---|---|
| 新增告警源 | 约1次/月 | 4小时(改代码+测试+部署) | 4h |
| 值班表变更 | 约4次/月 | 0.5小时(改YAML+推送) | 2h |
| 分级/收敛规则调整 | 约2次/月 | 1.5小时 | 3h |
| 三方依赖升级(安全补丁) | 约1次/月 | 2小时 | 2h |
| 突发故障排查(Flask挂了、告警漏发) | 约1次/月 | 1小时 | 1h |
| 月度合计 | 12小时 |
一个月12小时。一年144小时——相当于一个运维工程师整整三周半的工作时间,花在了维护告警管道本身,而不是处理告警。
这些时间在企业内部IT可能不算什么,但在MSP模式下——每个客户都有一套独立的告警环境,维护成本是线性放大的。
问题四:告警到工单永远是"断的"
这套方案最核心的功能缺失是:告警来了,但工单还是手建的。
我们试过在Flask脚本里加一段代码——P1告警触发时调ITSM系统API创建工单。但两个系统之间的数据映射(告警→工单模板、设备→配置项、值班人→处理人)每次都依赖手工维护,而且告警恢复后工单不会自动更新状态。
告警处理和工单管理在两条平行的轨道上跑,值班人要在告警群和工单系统之间来回切。
问题五:没有SLA时钟
告警发到群里了、工单也建了——但谁来保证它在15分钟/2小时内被处理?
自建方案里我们只能做到"发了通知",至于有没有人看、看了有没有处理、超时了要不要升级——完全没有机制。后来发现每个月大概有15-20%的P2告警超过了2小时响应时限,等发现时已经是第二天看报表了。
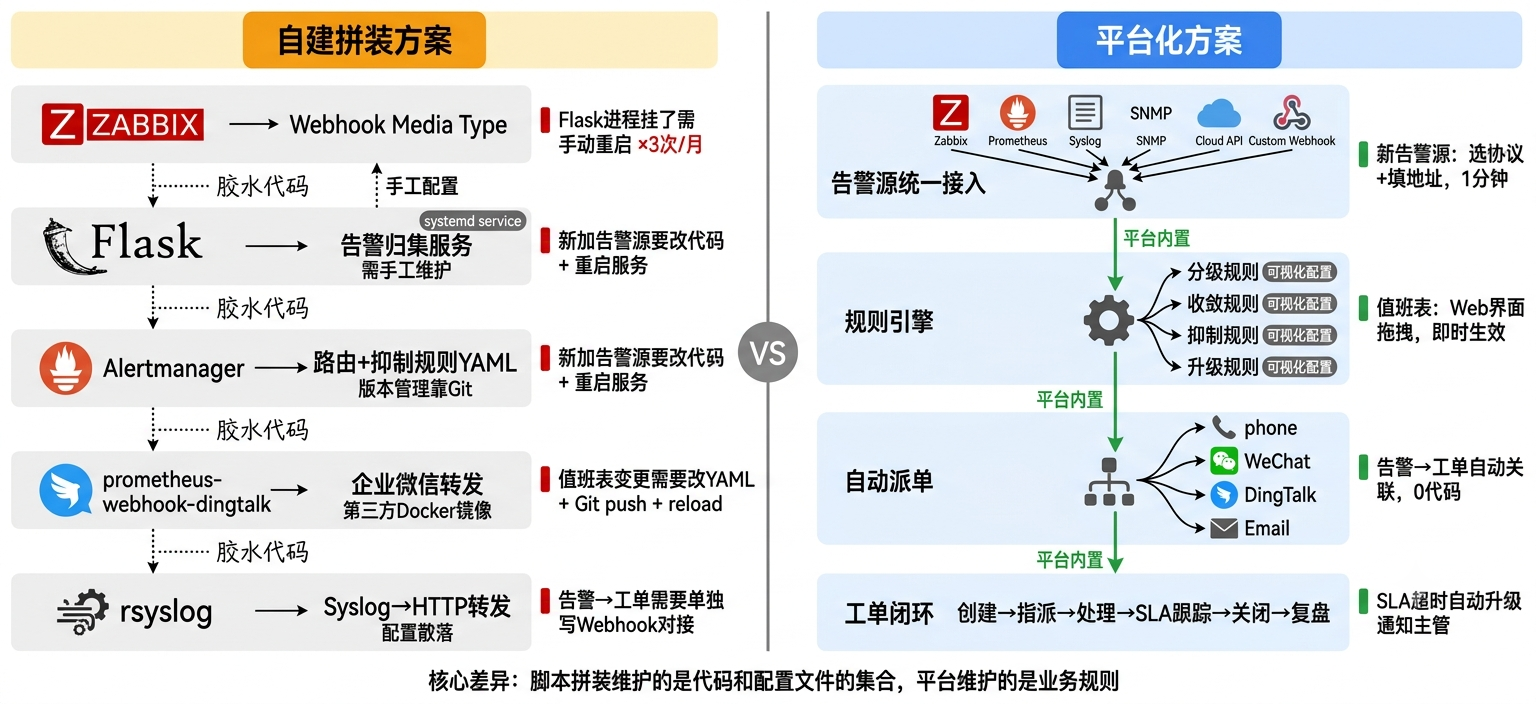
二、做迁移决策:我们评估了什么
上面5个问题累加起来,团队达成了一个共识:告警归集这条链路,脚本拼装的拐点在100台设备/5个告警源/4人值班。超过这个规模,继续往脚本上加功能的ROI会越来越低。
但我们不想"为了用平台而用平台"。评估时列了三个硬标准:
标准一:告警源接入必须是配置而不是代码。 加一个告警源不能改Python脚本再重启服务。选协议(Webhook/Syslog/SNMP/API)、填地址、填字段映射——这应该是3分钟做完的事。
标准二:派单和工单必须是一条线。 告警触发→分级→通知到人→自动创建工单→SLA超时升级→处理完关闭,整条链路不能有手工步骤。值班人收到告警时,工单已经有了。
标准三:SLA时钟必须内置。 不是"通知了就算",而是"没在规定时间内响应就自动升级"。P1要15分钟内响应、P2要2小时内响应——超时了通知主管、再超时通知经理。
这三个标准筛下来,市面上能满足的方案其实不多。我们最后选了冠服云EMS的ITOM模块——不是因为它是"最好的",而是在我们评估的几个方案里,它是唯一一个在一条产品链路里把告警归集、分级、派单、工单、SLA串起来的。其他方案要么只管告警、工单要靠API对接,要么工单很强但告警归集很弱。
这个决策做了大概两周。比较重要的一个考量是:我们不只是自己用,客户环境也要用。对于客户来说,一个统一入口比"运维给我们开了一堆GitHub仓库的权限"更容易接受。
三、迁移实战:从Flask脚本到平台化的完整配置过程
迁移策略是并行跑两周——旧的Flask方案继续跑,新的平台方案同步接入告警源,确认数据一致后再切通知渠道。
3.1 第一步:告警源迁移(最长的一步)
7个告警源的迁移不是同时做的。按"最容易切→最难切"的顺序:
第1-2天:Zabbix 告警源(最简单的)
Zabbix的Webhook配置改一下URL就行。在EMS平台上创建告警源,选"Zabbix Webhook"协议,系统自动生成一个接收URL。去Zabbix的 Media Type 把原来的 http://flask-server:5000/alert/zabbix 替换成这个URL。
不需要停机、不需要重启Zabbix Server、不需要改任何规则。告警继续触发,只是推送目标从Flask变成了EMS的告警接收端点。
# Zabbix前端操作路径
# Administration → Media Types → 找到原来指向Flask的Webhook Media Type
# 修改URL: http://flask-server:5000/alert/zabbix
# → https://ems-api.guanfucloud.com/v1/alert/source/zabbix-inbound
# 保存 → 点Test按钮验证
第3-4天:Prometheus Alertmanager
Alertmanager改一下 alertmanager.yml 里的webhook URL就行,和Zabbix类似。
第5-7天:Syslog + SNMP Trap + 云监控 + API
这几个需要做字段映射——不同来源的告警格式差异大。核心工作是定义一套消息解析规则,把异构格式统一为标准告警结构。下面以Syslog为例,给出一套可复用的解析模板配置:
{
"source_type": "syslog",
"source_name": "网络设备Syslog",
"message_samples": [
"<134>Jun 10 08:15:23 Core-SW-01 %%10IFNET/5/LINK_UPDOWN: Line protocol on interface GigabitEthernet0/0/1 changed to DOWN.",
"<131>Jun 10 08:20:11 Access-SW-12 %%10SSH/5/SSH_LOGIN: SSH user admin logged in from 10.100.1.50."
],
"parsing_template": {
"device_name": {
"extract_from": "message_body",
"regex": "\\S+\\s+\\d+\\s+\\d+:\\d+:\\d+\\s+(\\S+)\\s+%%",
"capture_group": 1
},
"alert_type": {
"extract_from": "message_body",
"regex": "%%[^:]+/(\\d+)/(\\S+)",
"capture_group": 2
},
"interface_name": {
"extract_from": "message_body",
"regex": "interface (\\S+) changed",
"capture_group": 1,
"optional": true
},
"severity_mapping": {
"field": "syslog_severity",
"rules": [
{"match": "Emergency|Alert|Critical", "map_to": "P1"},
{"match": "Error", "map_to": "P2"},
{"match": "Warning", "map_to": "P2"},
{"match": "Notification|Informational|Debug", "map_to": "P3"}
]
},
"severity_keyword_override": [
{"keywords": ["DOWN", "FAILED", "CRITICAL"], "override_to": "P1"},
{"keywords": ["UP", "RECOVERED", "RESTORED"], "override_to": "P3"}
]
},
"dedup_key": "{device_name}_{alert_type}",
"time_window_seconds": 300
}
这套模板的核心思路:不硬编码每种设备的消息格式,而是用正则+捕获组做字段提取,再按关键字做级别覆盖。新增一个告警源时,改的是这个JSON模板,不是Python代码。
3.2 第二步:分级和收敛规则
告警源接入后,所有告警先进"未分级"池。我们在EMS平台上配了两类规则:
分级规则(在平台上通过Web界面配置,底层对应的规则定义结构如下):
# alert_classification_rules.yaml
# 分级规则:所有接入告警先在"未分级"池,逐条匹配规则确定P级
rules:
- id: "rule-001"
name: "设备不可达"
priority: 10 # 数字越小越先匹配
condition:
operator: OR
expressions:
- field: "alert_type"
operator: "in"
values: ["Host Down", "Unreachable", "NodeDown", "PING_FAILURE"]
action:
set_severity: "P1"
notify_groups: ["network-team", "oncall-primary"]
notify_channels: ["phone", "wechat"]
auto_create_ticket: true
ticket_priority: "urgent"
- id: "rule-002"
name: "服务中断"
priority: 20
condition:
operator: OR
expressions:
- field: "alert_type"
operator: "contains_any"
values: ["服务停止", "进程退出", "端口DOWN", "Service Down"]
- field: "alert_summary"
operator: "regex"
pattern: "(stopped|terminated|killed|exited)"
action:
set_severity: "P1"
notify_groups: ["service-owner"]
notify_channels: ["phone", "wechat"]
auto_create_ticket: true
- id: "rule-003"
name: "资源预警"
priority: 30
condition:
operator: AND
expressions:
- field: "alert_summary"
operator: "regex"
pattern: "(CPU|内存|磁盘|Memory|Disk).*(>\\s*\\d+%|超过)"
- field: "severity_raw"
operator: "in"
values: ["Average", "Warning", "High"]
action:
set_severity: "P2"
notify_groups: ["infra-team"]
notify_channels: ["wechat"]
work_hours_only: true # 工作时间外降为P3
off_hours_severity: "P3"
- id: "rule-004"
name: "恢复通知"
priority: 99 # 最低优先级,最后匹配
condition:
field: "alert_status"
operator: "equals"
value: "resolved"
action:
close_related_tickets: true
append_timeline: "告警已自动恢复"
notify_channels: ["wechat"]
这套规则引擎的关键设计:priority 控制匹配顺序(像防火墙规则)、work_hours_only 避免半夜P2发一堆非紧急通知、恢复通知的 close_related_tickets 让工单和告警状态自动同步。
收敛规则(同样通过Web界面配置,底层规则定义):
# alert_convergence_rules.yaml
rules:
- id: "conv-001"
name: "设备级收敛——根因抑制"
type: "root_cause_suppression"
trigger:
alert_type: "设备不可达"
severity: "P1"
suppress:
target: "same_device_all_alerts" # 抑制该设备所有其他告警
exclude_self: true
effect: "1台交换机DOWN → 只发1条P1,自动抑制20条端口+10条下游告警"
- id: "conv-002"
name: "同源重复收敛"
type: "deduplication"
conditions:
- field: "device_name" # 同一设备
operator: "equals"
- field: "alert_type" # 同一告警类型
operator: "equals"
time_window_seconds: 300 # 5分钟窗口
action: "suppress" # 抑制后续重复,仅记录计数
max_count_before_notify: 10 # 累积超10次发一条聚合通知
- id: "conv-003"
name: "端口抖动收敛"
type: "flap_detection"
trigger:
alert_type_pattern: "端口.*(Up|Down)"
flap_window_seconds: 600 # 10分钟内
flap_threshold: 3 # 切换≥3次
action: "merge_to_single" # 合并为1条"端口抖动"告警
merged_alert_summary: "端口 {{interface}} 10分钟内抖动{{count}}次"
这三条收敛规则的效果:日均220条原始告警 → 收敛后约25条需要关注。收敛率约89%,和之前Flask脚本的效果一致,但不需要维护去重逻辑代码。
3.3 第三步:值班排班和自动派单
这是迁移后体验差异最大的环节。
之前改值班表要走"改YAML→Git commit→reload Flask服务"流程。在EMS平台上,值班表是一个可视化的Web日历——拖拽班次、勾选人员、设置交接时间,改完即时生效。底层对应的排班和派单配置结构如下:
# oncall_schedule_and_dispatch.yaml
schedule:
shifts:
- name: "白班"
hours: "08:00-20:00"
min_staff: 2
teams: ["network", "system", "security"]
- name: "夜班"
hours: "20:00-08:00"
min_staff: 1
backup_staff: 1 # 1人备份,主值不响应时升级
- name: "周末"
days: ["Saturday", "Sunday"]
min_staff: 1
p1_escalation: "manager" # P1直接升级到值班经理
rotation:
type: "weekly" # 每周一轮换
handover_time: "周一 09:00"
members:
network: ["zhangsan", "zhaoliu", "zhouqi"]
system: ["lisi", "qianba"]
security: ["wangwu"]
dispatch_rules:
- match:
alert_category: "network"
assign_to: "network.oncall" # 动态取当前值班人
channels: ["wechat"]
- match:
alert_category: "server"
assign_to: "system.oncall"
channels: ["wechat"]
- match:
severity: "P1"
override_channels: ["phone", "wechat"]
auto_create_ticket: true
ticket_template: "urgent_incident"
escalation:
timeout_minutes: 15
escalate_to: ["network.manager", "system.manager"]
escalate_channels: ["phone"]
- match:
severity: "P2"
channels: ["wechat"]
auto_create_ticket: true
ticket_template: "standard_incident"
escalation:
timeout_minutes: 120
escalate_to: ["network.manager"]
escalate_channels: ["wechat"]
对比之前的方案:自建阶段每次调班要改YAML+Git push+reload,一个月约4-6次、每次30分钟。迁移后值班人直接在Web日历拖拽调整,变更即时生效、零操作成本。
3.4 第四步:工单闭环
这是以前自建方案最薄弱的一环,现在变成了最顺的一环。核心在于告警→工单的字段映射和SLA时钟是平台内置的,不需要写胶水代码对接两个系统:
{
"alert_to_ticket_mapping": {
"trigger": "severity in [P1, P2]",
"field_mapping": {
"ticket_title": "{alert_severity} | {alert_type} | {device_name}",
"ticket_priority": {
"P1": "urgent",
"P2": "normal"
},
"assigned_to": "{dispatch_rule.oncall_user}",
"ci_id": "{device_name} -> CMDB lookup by hostname",
"ci_category": "{device_name} -> CMDB lookup by category",
"alert_source": "{alert.source_type}",
"alert_id": "{alert.id}"
},
"sla_config": {
"P1": {
"response_time_minutes": 15,
"resolution_time_minutes": 240,
"escalation_levels": [
{"timeout_minutes": 15, "escalate_to": "manager"},
{"timeout_minutes": 30, "escalate_to": "director"}
]
},
"P2": {
"response_time_minutes": 120,
"resolution_time_minutes": 1440,
"escalation_levels": [
{"timeout_minutes": 120, "escalate_to": "manager"}
]
}
},
"lifecycle": {
"on_alert_firing": "CREATE_TICKET",
"on_alert_acknowledged": "UPDATE_TICKET_STATUS -> in_progress",
"on_alert_resolved": "APPEND_TIMELINE + UPDATE_TICKET_STATUS -> pending_close",
"on_ticket_closed": "RECORD_SLA_METRICS"
}
}
}
值班人在企业微信收到的通知也不再是纯文本,而是带结构化字段的卡片:
🔴 **P1 紧急工单 #2026-0610-0042**
> 设备:Core-SW-01(核心交换机)
> 告警:设备不可达
> 来源:Zabbix
> 触发:2026-06-10 14:32:15
>
> ⏱ **SLA倒计时:响应剩余 12分钟 | 解决剩余 3小时52分**
>
> 📋 关联配置项:NET-CORE-001 | 所属站点:总部机房
> 📖 历史工单:近30天同类故障 0次
>
> 处理人:@张三(网络组值班)
> 📞 联系电话:13800000001
工单关闭后,系统自动记录完整时间线——告警触发时间、值班响应时间、处理完成时间、SLA是否达标、处理记录。这些数据直接支撑月度运维报告的SLA章节,不需要手工统计。
四、迁移前后对比
跑了两个月后拉了一组数据,跟自建方案最后6个月的平均值做了对比:
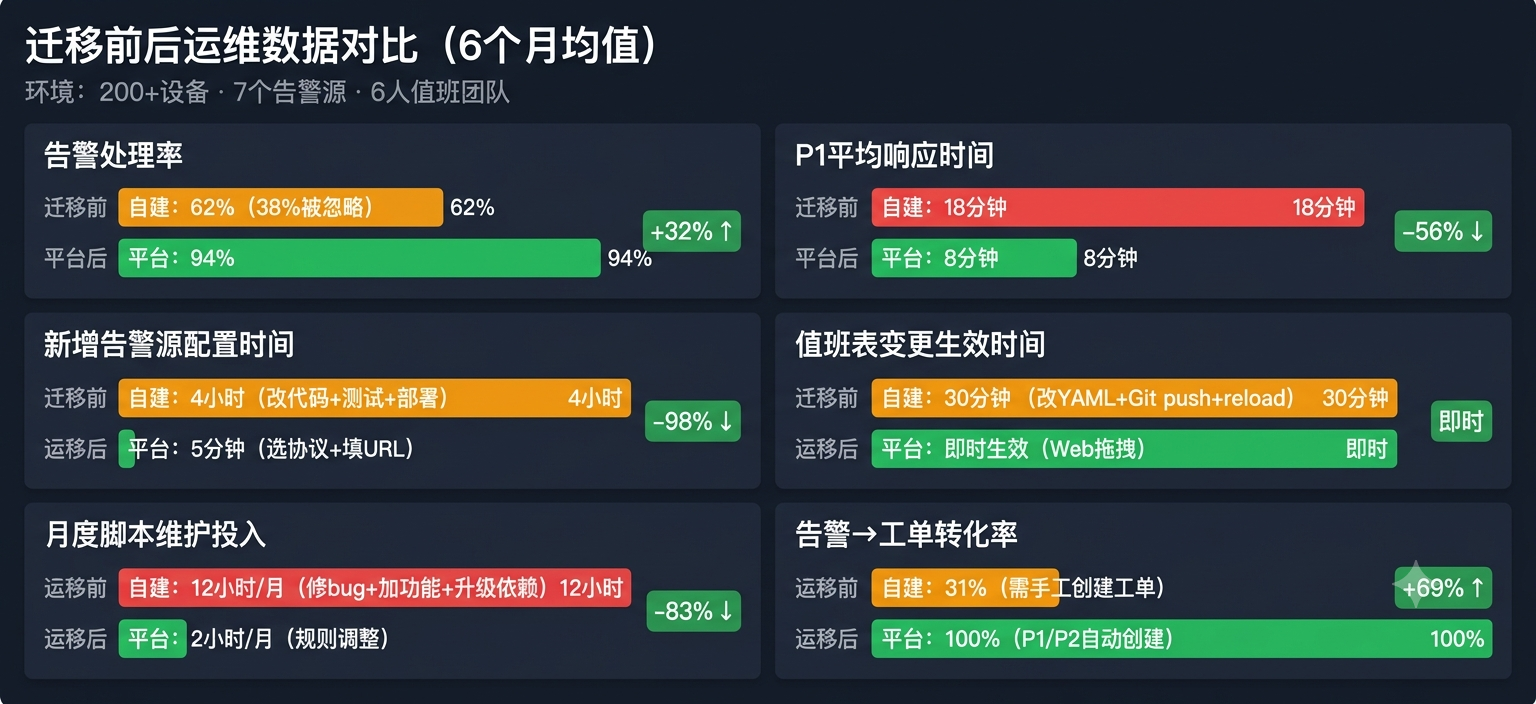
告警处理率从62%跳到94%是最超出预期的。原因不是"平台比脚本聪明",而是工单+SLA这层闭环把人逼到了行动上——你不处理,超时自动升级到主管。自建方案里告警发到群里就结束了,看不看完全靠自觉。
五、怎么判断你该不该迁移
不是每个团队都要从自建脚本迁到平台。给一个简单的判断框架:
| 你的情况 | 建议 |
|---|---|
| 设备<50台、告警源≤3个、值班≤2人 | 继续用脚本。 Flask+Webhook足够,维护成本极低 |
| 设备50-150台、告警源4-6个、值班3-4人 | 评估阶段。 开始留意维护时间占比,看拐点什么时候来 |
| 设备>150台、告警源≥7个、值班≥5人轮转 | 该迁了。 脚本维护成本已超过平台成本 |
| 有合规要求(等保/审计需要工单轨迹) | 优先迁。 自建方案的审计轨迹太弱 |
| 多客户环境(MSP模式) | 尽早迁。 脚本方案不擅长多租户隔离 |
核心判断标准就一个:你团队花在"维护告警管道"上的时间,是不是已经超过了"处理告警"的时间。 如果答案是"是",那就该换了。
六、迁移过程的6条经验
第一,并行跑两周再切。 旧管道和新管道同时接收告警,对比两周——确认新管道没漏告警、分级规则一致、通知渠道通畅。同时跑的时候可以调规则,不影响实际值班。
第二,告警源一个一个迁。 不要7个告警源同一天切。从最简单的(Zabbix Webhook,只改一个URL)开始,每迁一个验证一天再迁下一个。
第三,分级规则先复制再优化。 迁移时先把旧方案的P1/P2/P3分级规则1:1复制过来,确保告警行为不变。跑稳之后再优化规则(比如把某些P2降成P3、把漏掉的P3升成P2)。
第四,通知模板要重新设计。 平台的通知格式和脚本不一样,不要硬套。利用平台的结构化字段(设备名、告警来源、工单号、SLA倒计时),让企业微信通知比以前的纯文本更有信息量。
第五,SLA先松后紧。 刚迁移后的前两周,把SLA阈值设宽松(P1: 30分钟/ P2: 4小时),给团队适应期。两周后再收紧到目标值(P1: 15分钟/ P2: 2小时)。
第六,旧脚本不要立刻删。 再留一个月,以防有边缘场景没被新平台覆盖。确认新平台稳定后再下线。
七、总结
回看这一年半,从Flask脚本到平台化迁移,最大的感受是:好的开源工具解决了"能不能做"的问题,但规模上去之后,"好不好维护"变成了主要矛盾。
告警归集这条链路,核心价值不在"能把告警收到一个地方"——这个Flask脚本100行代码就能做到。核心价值在"收到之后怎么分、怎么派、怎么跟、怎么闭环"。这部分才是真正影响值班效率的东西。
我们现在的思路是:底层监控继续用Zabbix和Prometheus——这两件事它们做到最好;告警进来之后的分级、派单、工单、SLA、知识库关联——这些交给平台。不是"替代",是"分层"。
冠服云EMS的ITOM模块在这套架构里就是告警治理层——它不替代Zabbix做监控,也不替代企业微信做通知,它做的是把"告警从消息变成工单"这件事。这件事自建也可以做,但维护成本会随着规模涨,而平台方案在这方面有天然优势。
本文基于的真实环境:200+设备、7个告警源、6人值班团队、18个月自建方案运行数据。迁移前后对比数据为实际生产环境统计。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 37
37 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)