计算机毕业设计之基于朴素贝叶斯算法的电影推荐系统
摘要
本研究致力于构建一款基于朴素贝叶斯算法的电影推荐系统,利用Python编程语言、MySQL数据库以及Hadoop和Spark等大数据技术,实现高效的数据处理和分析。该平台的核心功能包括数据爬取、处理、分析和可视化。首先,利用Scrapy框架从豆瓣电影网站爬取了电影相关的数据,这些数据涵盖了电影的年份,地区,评论,评分和票房等多个维度,然后采用了pandas库对爬取的数据进行csv文件的保存,最后通过hadoop和spark大数据技术进行分布式存储和计算,使用Mysql进行数据的保存,通过Vue.js框架结合Echarts库构建了数据可视化界面。展示的可视化数据包括有热点评论词云,上映年份统计,国家/地区上榜电影数量统计,电影年份统计等。另外通过朴素贝叶斯机器学习算法建立模型,点击一部电影的时候会给出未来七年的评分预测,也会根据协同过滤算法完成相关的电影的推荐。总的来说,系统的开发不仅为用户提供了更加便捷、高效的电影数据查询和分析工具,也为电影行业的数字化发展提供了新的思路和方向。
根据以上的功能需求情况,整体的功能模块包括有前端程序,爬虫程序,大数据程序,机器学习程序,注册与登录后台程序和可视化数据展示后台程序。其中前端程序主要就是对应的vue页面项目,包括有注册与登录页面的构建,可视化数据展示页面等。爬虫程序主要是为了获取分析的数据源的。大数据程序使用spark进行创建,对原始的数据集进行分割和存储等操作。为了提升项目的层次性,系统针对注册与登录创建单独的一个项目,另外对大数据相关的数据处理创建一个项目。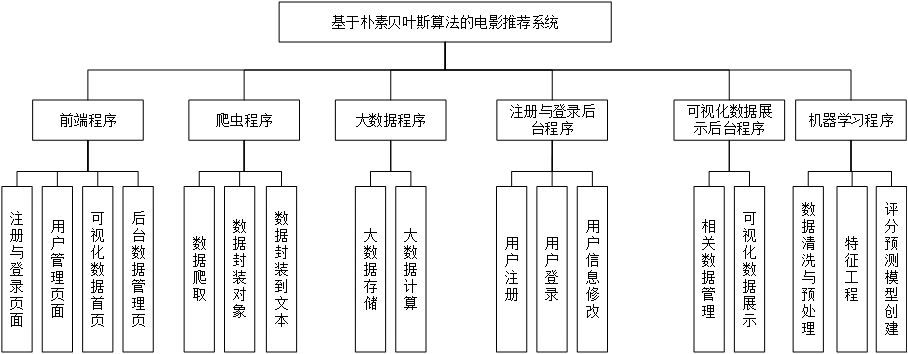
图5.3分割后的数据集图片
5.3 可视化首页功能实现
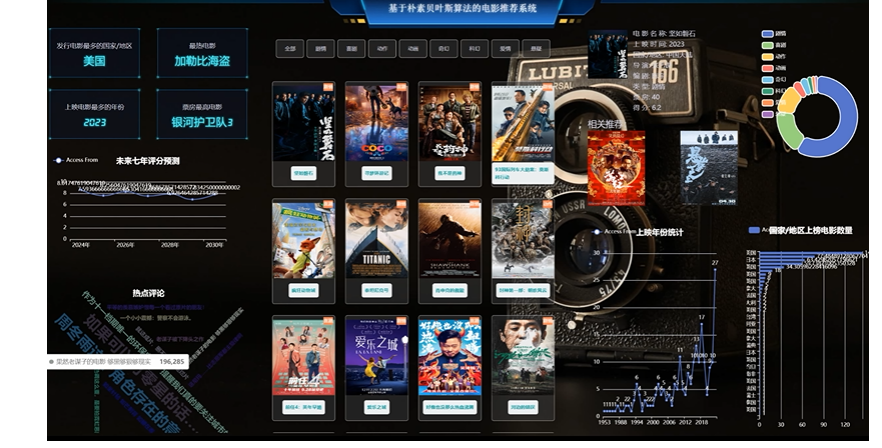
通过以上步骤完成了数据的爬取和存储,接下来就是系统可视化页面展示阶段了。系统前台页面通过vue框架结合element-ui等插件实现,采用了Django web框架,后台使用python进行代码的书写。在用户登录后进入系统首页,首页在展示数据之前肯定是需要先从数据库调取相应的数据,经过web服务器的解析,然后进行展示,首页主要展示爬取的可视化数据包括有热点评论词云,上映年份统计,国家/地区上榜电影数量统计,电影年份统计等。另外,其中七年评分预测是根据朴素贝叶斯算法建立的模型获取的,推荐的电影是通过协同过滤算法完成相关类似电影的推荐。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)