MySQL慢查询优化全流程:pt-query-digest分析+EXPLAIN调优+生产环境上线规范
📌今日关键词:MySQL慢查询、EXPLAIN、pt-query-digest、索引优化、执行计划
大家好,我是数据库小学妹 👋
之前讲过慢查询的诊断方法,也拆过EXPLAIN执行计划,有同学说:“小学妹,工具我都学会了,但真遇到数据库变慢的时候,我还是不知道第一步干嘛。”
这个问题挺真实的。单独学工具和在生产环境里扛住压力排查,完全是两回事。数据库CPU突然飙到90%,开发在群里催"接口全超时了",你拿着一堆命令不知道先跑哪个——这种手忙脚乱的感觉,我经历过不止一次。
今天就从"发现数据库变慢"这个起点出发,走一遍完整的排查和优化流程。不讲单个工具怎么用,主要讲"碰到问题该怎么串起来"。
一、数据库变慢了,第一步看什么
收到告警或者开发反馈,别急着上工具。先判断慢在哪。
-- 看当前连接和查询状态
SHOW PROCESSLIST;
SHOW FULL PROCESSLIST;
重点看三个东西:
Threads_running高不高——正在跑SQL的连接多不多- 有没有执行了几十秒甚至几百秒的查询
- 有没有大量连接在
Sending data或Sorting result状态
SHOW STATUS LIKE 'Threads%';
Threads_connected 是总连接数(包含Sleep),Threads_running 是真正在干活的。如果 Threads_running 平时个位数突然飙到几十,肯定有SQL在作妖。
同时看一眼慢查询日志有没有东西:
# 看最近的慢查询
tail -50 /var/log/mysql/slow.log | grep -i "Query_time"
如果慢查询日志没开,先开上:
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1;
SET GLOBAL log_queries_not_using_indexes = 'ON';
这三个参数的含义:开启慢查询日志、超过1秒的SQL记下来、没走索引的也记下来。生产环境建议一直开着,long_query_time 设1秒或者0.5秒都行。
二、找到最该优化的SQL
慢查询日志打开后会收到一堆SQL,不可能挨个优化。得排个优先级。
mysqldumpslow 快速看概览
# 按总耗时排序,看最耗时的10条
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
# 按平均耗时排序
mysqldumpslow -s at -t 10 /var/log/mysql/slow.log
# 按执行次数排序
mysqldumpslow -s c -t 10 /var/log/mysql/slow.log
mysqldumpslow能快速看出哪类SQL最耗时,但信息比较粗糙。
pt-query-digest 深入分析
生产环境用 pt-query-digest,信息量大得多:
# 分析最近24小时的慢查询
pt-query-digest --since=24h /var/log/mysql/slow.log
看输出的时候,重点关注这几列:
Query_time max— 最长执行时间Rows_examined avg— 平均扫描行数Rows_sent avg— 平均返回行数
如果 Rows_examined 是50万,Rows_sent 只有100,扫描了50万行才返回100行——这就是典型需要加索引的场景。
pt-query-digest的输出会按SQL指纹(fingerprint)聚合,同一种SQL只会出现一次,但会告诉你执行了多少次、总耗时多少。先优化总耗时最高的那条。
performance_schema 看实时数据
如果不想翻日志,直接从内存里查:
SELECT
DIGEST_TEXT,
COUNT_STAR,
SUM_TIMER_WAIT / 1000000000000 AS sum_sec,
AVG_TIMER_WAIT / 1000000000000 AS avg_sec,
SUM_ROWS_EXAMINED,
SUM_ROWS_SENT
FROM performance_schema.events_statements_summary_by_digest
WHERE DIGEST_TEXT IS NOT NULL
ORDER BY sum_sec DESC
LIMIT 10;
这个视图按SQL指纹汇总了从MySQL启动以来的执行统计,不需要开慢查询日志就能看到。
三、EXPLAIN 看执行计划
找到了要优化的SQL,下一步搞清楚它为什么慢。在SQL前面加 EXPLAIN:
EXPLAIN SELECT * FROM orders
WHERE user_id = 1000 AND status = 'completed'
ORDER BY created_at DESC
LIMIT 20;
输出里有12个字段,新手容易看懵。其实只需要盯住三个:
type 字段——怎么看有没有走索引
从好到差排列:
| type值 | 含义 | 好不好 |
|---|---|---|
| const | 主键或唯一索引精确匹配 | 最好 |
| eq_ref | JOIN时主键/唯一索引匹配 | 很好 |
| ref | 普通索引匹配 | 好 |
| range | 索引范围查询 | 还行 |
| index | 全索引扫描 | 一般 |
| ALL | 全表扫描 | 很差 |
看到 ALL 就得警惕了——全表扫描,在大表上就是性能杀手。
Extra 字段——隐藏的关键信息
| Extra值 | 含义 | 需不需要优化 |
|---|---|---|
| Using index | 覆盖索引,不回表 | 不用,这是好事 |
| Using index condition | 索引下推 | 一般不用 |
| Using filesort | 额外排序 | 需要优化 |
| Using temporary | 用了临时表 | 需要优化 |
| Using where | 回表后过滤 | 看情况 |
Using filesort 和 Using temporary 同时出现的话,这条SQL基本逃不掉要优化。
rows 字段——扫描了多少行
rows 是MySQL估算的扫描行数。扫描500万行返回20行,一看就知道有问题。
我之前踩过一个坑:EXPLAIN显示走了索引(type=ref),但rows还是几十万。原因是索引区分度太低——一个 status 字段只有5个值,索引建在上面跟没建差不多。后来改成复合索引才解决。
四、六个高频慢查询场景
知道了怎么分析,接下来看六个在生产环境里最常见的慢查询,每个给一个改写方案。
场景一:SELECT * 拖慢性能
-- 问题写法
SELECT * FROM orders WHERE user_id = 1000;
-- 优化:只查需要的字段
SELECT id, order_no, status, amount, created_at
FROM orders WHERE user_id = 1000;
SELECT * 的问题不只是多传了数据。在InnoDB里,如果查询的字段都在索引里(覆盖索引),MySQL可以直接从索引返回数据,不用回表。SELECT * 会逼着MySQL去聚簇索引里捞所有字段,白白多了一次IO。
场景二:深分页
-- 问题写法:跳过100万行取20行
SELECT * FROM orders
WHERE status = 'completed'
ORDER BY id DESC
LIMIT 1000000, 20;
MySQL会扫描100万+20行,扔掉前100万行,只返回20行。offset越大越慢。
三种改法:
-- 方法一:游标分页(推荐,前提是知道上一页最后一条的id)
SELECT * FROM orders
WHERE status = 'completed' AND id < 1000020
ORDER BY id DESC
LIMIT 20;
-- 方法二:延迟关联
SELECT o.* FROM orders o
INNER JOIN (
SELECT id FROM orders
WHERE status = 'completed'
ORDER BY id DESC
LIMIT 1000000, 20
) t ON o.id = t.id;
-- 方法三:覆盖索引+子查询(介于两者之间)
游标分页性能最好,但前端得配合改成"加载更多"模式。如果产品非要"跳到第5000页",用延迟关联。
场景三:COUNT(*) 慢
-- 问题写法
SELECT COUNT(*) FROM orders WHERE status = 'pending';
大表上如果 status 没索引,全表扫描几百万行。
-- 加索引
ALTER TABLE orders ADD INDEX idx_status (status);
-- 对精度要求不高时,直接查元数据
SELECT TABLE_ROWS FROM information_schema.TABLES
WHERE TABLE_SCHEMA = 'your_db' AND TABLE_NAME = 'orders';
如果业务允许几秒的延迟,用汇总表定时刷新也行。
场景四:JOIN 太多表
四张表以上的JOIN,执行计划就开始不可控了。关键是确保JOIN字段有索引,小表驱动大表。
-- 确保连接字段有索引
ALTER TABLE order_items ADD INDEX idx_order_id (order_id);
ALTER TABLE orders ADD INDEX idx_user_id (user_id);
如果JOIN性能实在扛不住,考虑拆成多次查询在应用层组装。MySQL优化器不总是选最优的JOIN顺序。
场景五:OR 条件导致索引失效
-- 问题写法
SELECT * FROM users
WHERE name = '张三' OR email = 'zhangsan@test.com' OR phone = '13800138000';
OR条件可能让MySQL放弃索引直接全表扫描。改写成UNION:
SELECT * FROM users WHERE name = '张三'
UNION
SELECT * FROM users WHERE email = 'zhangsan@test.com'
UNION
SELECT * FROM users WHERE phone = '13800138000';
每个分支都走各自的索引,效率高得多。前提是三个字段都有独立索引。
场景六:IN 里面套子查询
-- 问题写法
SELECT * FROM orders
WHERE user_id IN (SELECT id FROM users WHERE created_at > '2026-01-01');
老版本MySQL处理IN子查询效率很差,外层每取一行都要跑一次子查询。改成JOIN:
SELECT o.* FROM orders o
INNER JOIN users u ON o.user_id = u.id
WHERE u.created_at > '2026-01-01';
8.0对IN子查询做了半连接优化,很多时候会自动转换。但写成JOIN更保险,行为更可控。
五、配置参数:改几个关键的就够
SQL优化完了,还有提升空间的话,可以调配置参数。但别一上来就改几十个参数,先改影响最大的几个。
innodb_buffer_pool_size
这是InnoDB最重要的参数,控制数据和索引在内存里缓存多少。设太小,频繁读磁盘;设太大,内存不够用。
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
经验值:物理内存的60%80%。16G内存的机器,设10G12G。
innodb_flush_log_at_trx_commit
控制redo log的刷盘策略:
| 值 | 行为 | 安全性 | 性能 |
|---|---|---|---|
| 1 | 每次commit刷盘 | 最安全 | 最慢 |
| 2 | 每秒刷盘,commit只写OS缓存 | 丢1秒数据 | 快 |
| 0 | 由master thread控制 | 可能丢更多 | 最快 |
非金融场景设2就够了。金融场景必须是1。
tmp_table_size 和 max_heap_table_size
SQL执行过程中用到的内存临时表大小。设太小会落磁盘(Created_tmp_disk_tables飙升),设太大怕内存不够。
SHOW STATUS LIKE 'Created_tmp%';
如果 Created_tmp_disk_tables 很高,适当调大这两个参数,一般256M起步。
sort_buffer_size 和 join_buffer_size
排序和JOIN操作的缓冲区。这两个是每个连接独立分配的,别设太大(1000个连接×4M=4G内存就没了)。
一般4M够用。如果EXPLAIN里频繁出现 Using filesort,可以临时调大试试。
六、生产环境操作规范
优化方案找到了,怎么安全地上线?
加索引:大表别直接ALTER
-- 小表直接加
ALTER TABLE small_table ADD INDEX idx_name (name);
-- 大表用pt-online-schema-change
pt-online-schema-change \
--alter "ADD INDEX idx_user_status (user_id, status)" \
--user=root --password=xxx \
D=mydb,t=orders \
--execute --print
-- 或者用gh-ost
gh-ost \
--host=localhost --port=3306 \
--database=mydb --table=orders \
--alter="ADD INDEX idx_user_status (user_id, status)" \
--execute
大表直接 ALTER TABLE 在MySQL 5.6之前会锁表,5.6+虽然支持Online DDL,但大表加索引还是会占不少IO。用pt-osc或gh-ost更安全,线上流量基本无感知。
上线前必须做的事
# 1. 备份表结构
mysqldump -u root -p --no-data mydb orders > orders_schema.sql
# 2. 在测试环境跑EXPLAIN,确认执行计划变好了
EXPLAIN SELECT ...;
# 3. 选低峰期执行
# 凌晨2-5点是大多数业务的低峰
# 4. 改完验证
SHOW INDEX FROM orders;
EXPLAIN SELECT ...; -- 再跑一次确认
危险操作红线
几条血的教训:
- DELETE和UPDATE必须带WHERE,而且先用SELECT确认影响范围
- 生产环境禁止无LIMIT的全表查询
- DDL操作前备份,改配置前备份my.cnf
innodb_buffer_pool_size不是动态参数(8.0之前),改了要重启
# 改配置前先备份
cp /etc/mysql/my.cnf /etc/mysql/my.cnf.bak.$(date +%Y%m%d%H%M%S)
# 检查配置语法
mysqld --validate-config
# 重启后看error log确认没问题
tail -f /var/log/mysql/error.log
七、排查流程速查
数据库变慢了,按这个顺序走:
SHOW PROCESSLIST— 看有没有卡住的查询SHOW STATUS LIKE 'Threads%'— 看活跃线程数- 慢查询日志 +
pt-query-digest— 找到最耗时的SQL EXPLAIN— 分析执行计划- 加索引 / 改写SQL — 优化
- 测试环境验证 — 确认执行计划变好
- 低峰期上线 — 改完再跑一遍EXPLAIN
- 观察 — 看CPU、IO、慢查询数有没有降下来
中间如果发现CPU打满、IO打满、连接打满,参考之前的笔记。
八、避坑清单
| 序号 | 坑点 | 后果 | 正确做法 |
|---|---|---|---|
| 1 | 不开慢查询日志 | 慢SQL来了都不知道 | 生产环境一直开着,long_query_time设1秒 |
| 2 | 只看mysqldumpslow不用pt-query-digest | 信息太粗糙,分不清轻重缓急 | 用pt-query-digest按指纹聚合,优先优化总耗时最高的 |
| 3 | EXPLAIN只看type不看Extra | 以为走了索引就没问题,其实有filesort | type和Extra都要看 |
| 4 | SELECT * 写习惯了 | 多传数据、无法覆盖索引、浪费IO | 只查需要的字段 |
| 5 | 大表直接ALTER TABLE加索引 | 锁表或IO飙升影响业务 | 用pt-online-schema-change或gh-ost |
| 6 | 上线前不跑EXPLAIN验证 | 加了索引但优化器没用上 | 测试环境先跑EXPLAIN确认 |
| 7 | 索引加在区分度低的字段上 | 加了跟没加差不多 | 看基数(Cardinality),低于10%的字段不适合单独建索引 |
| 8 | 一次改几十个参数 | 出问题不知道是哪个改坏了 | 一次改一两个,观察后再改下一个 |
| 9 | 深分页用大offset硬扛 | 越到后面越慢 | 游标分页或延迟关联 |
| 10 | 改完配置不看error log | 配置错误导致MySQL起不来 | 重启后立即tail error.log |
总结
慢查询优化不是某个工具的使用问题,是一套流程:
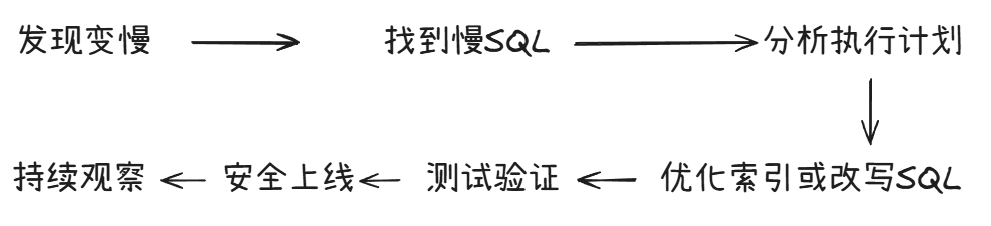
工具只是手段。mysqldumpslow和pt-query-digest帮你找到目标,EXPLAIN帮你理解为什么慢,索引和SQL改写是具体动作。把这串流程跑熟了,数据库性能问题就不会慌。
记住一个原则:先理解再动手。不看EXPLAIN就加索引,跟不看地图就出门一样,方向错了越努力越远。
我是数据库小学妹,咱们下篇见 👋

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)