万字干货|多模态AI产品设计与落地难点详解(图文/音视频全覆盖)
💥 前言:文本AI已内卷,多模态才是产品核心竞争力
在大模型落地常态化的当下,传统纯文本RAG知识库、对话机器人产品已经趋于同质化,无论是项目落地还是求职面试,都很难形成核心差异化优势。
当下企业AI迭代的核心方向,已经从单模态文本交互,全面转向图文、音频、视频一体化的多模态交互。市面上主流AI产品、企业私有化AI项目、智能剪辑、视觉问答场景,均基于多模态大模型搭建。
但在实际落地过程中,绝大多数产品团队都会遇到各类共性问题:图片解析失真、图表识别错误、视频解析超时、音画信息错位、多模态融合精度低、算力成本失控等。
究其根本:多数产品经理仍沿用纯文本AI设计思维做多模态项目,忽略了图像、音视频的专属技术约束与产品设计规范。
本文将系统性拆解多模态AI产品完整落地体系,涵盖核心原理、业务场景、标准化设计要点、高频落地难点、技术对齐代码、最优解决方案,适合AI产品、算法产品、大模型落地从业者学习复用。
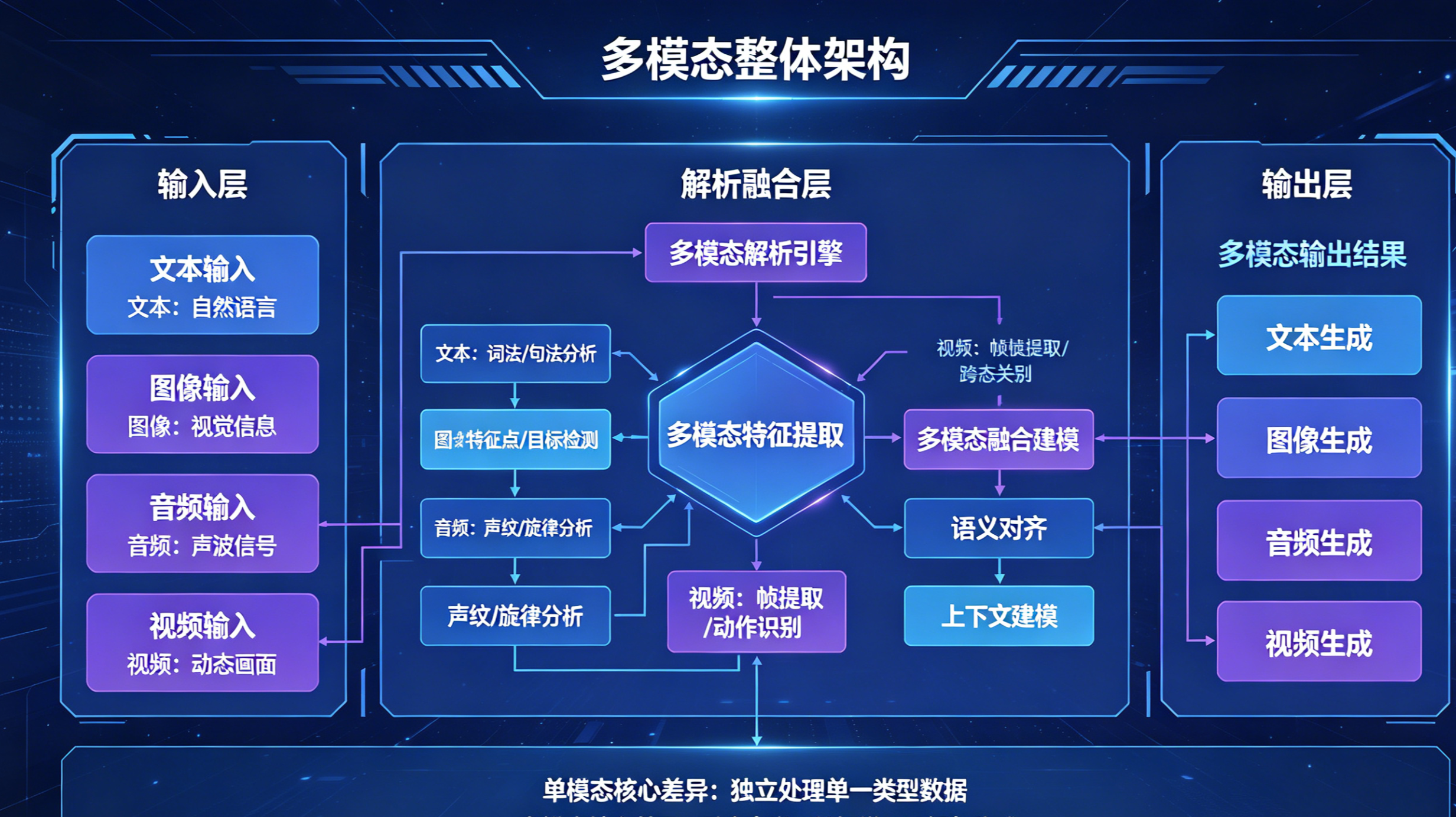
一、多模态AI核心概念:单模态与多模态的本质区别
在落地项目前,首先要厘清核心概念,这是所有产品设计的基础。
1.1 单模态AI
仅支持文本单一媒介的输入输出,典型场景为传统知识库问答、文本对话、文档总结,优势是轻量化、低成本、响应快,缺点是无法处理可视化、流媒体内容,场景局限性极大。
1.2 多模态AI
融合文本、图像、音频、视频多种媒介信息,模拟人类视觉、听觉、文字理解的综合感知能力,可实现跨媒介理解与生成,是当前大模型商业化落地的核心形态。
核心价值:突破纯文本场景限制,适配企业真实复杂业务场景,大幅提升AI产品实用性与商业化价值。

二、多模态AI四大核心业务场景(产品全覆盖)
目前企业落地的多模态项目,全部围绕以下四大场景展开,也是求职面试、项目复盘的核心考点:
2.1 图文模态场景
图片问答、OCR文字识别、表格/图表智能解析、图文对照问答、AI绘图、海报生成、截图内容解读。
2.2 音频模态场景
实时语音转写、智能降噪、语音意图识别、多轮语音对话、声纹校验、音频内容总结。
2.3 视频模态场景
短视频智能理解、视频画面打标签、自动字幕生成、视频内容总结、智能剪辑、违规画面检测、课程视频答疑。
2.4 跨模态生成场景
文生图、图生文、文生视频、视频自动解说、图文内容互转,是C端AI产品的核心创新场景。
三、多模态AI产品标准化设计要点
多模态产品设计区别于传统文本AI,不能简单复用对话、知识库逻辑,需针对流媒体特性制定专属产品规范,以下为落地必备核心要点。
3.1 统一输入资源规范,前置风险拦截
图像、音视频资源格式杂乱、大小不一、分辨率参差不齐,是导致解析失败、效果差的首要原因。产品侧必须设计前置校验与自适应压缩机制,统一限制文件格式、文件大小、视频时长、分辨率阈值,提前拦截违规、超大资源,降低后端与模型解析压力。
3.2 分模态解析,结果融合输出
视频、图文混合场景不能将资源直接投喂模型。例如完整视频包含画面帧、音频流、字幕文本三类信息,产品需设计模态拆分、并行解析、后期融合的链路,避免单一信息维度缺失导致答案不准。
3.3 保留时序与空间位置核心信息
文本AI可按需截断、清洗内容,但多模态场景严禁随意处理。图片表格的空间位置、视频的时间线、语音的时序逻辑,是模型精准理解内容的关键,产品设计中需完整保留核心维度信息。
3.4 差异化输出约束设计
不同模态需匹配专属输出规则:图文问答需标注图片溯源位置、视频解答需关联对应时间戳、语音输出需适配语速与断句逻辑,避免输出内容与原始资源错位。
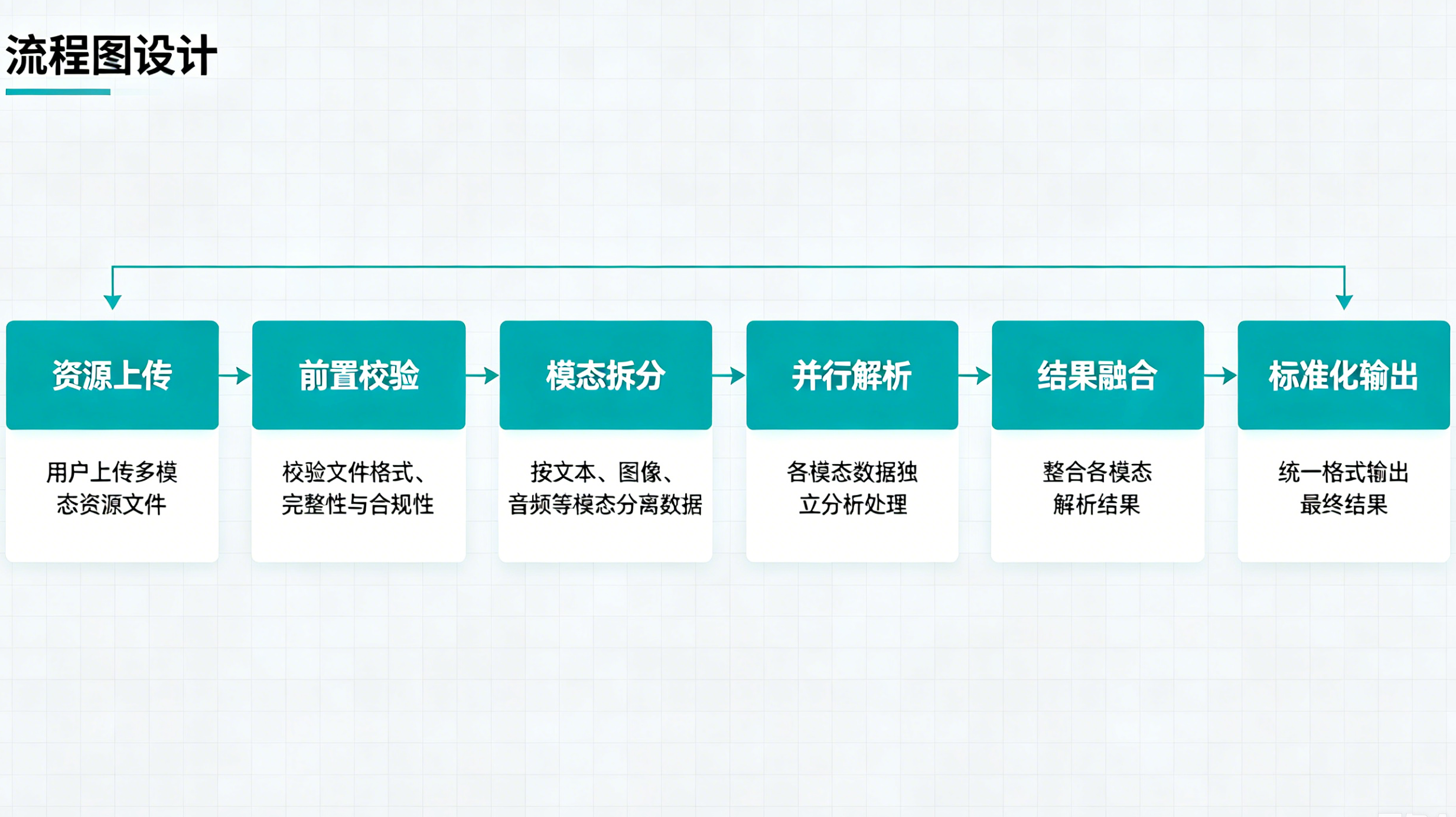
四、多模态项目高频落地难点与问题根源
结合大量私有化项目与线上产品落地经验,总结出行业通用的高频难点,也是产品迭代优化的核心方向:
-
模态信息错位:视频画面、音频、字幕信息割裂,AI回答与实际画面内容不匹配,出现答非所问。
-
流媒体资源超时:高清图片、长视频资源量大,解析链路复杂,极易出现接口超时、解析失败问题。
-
关键细节丢失:为降低成本过度压缩图片、抽帧,导致表格小字、图标细节模糊,识别准确率大幅下降。
-
模态权重失衡:模型偏重文本语义,忽略图像、画面核心信息,图文问答、视频解读效果极差。
-
算力成本失控:多模态模型调用、视频抽帧、图像向量入库算力消耗远高于文本模型,大规模落地后成本飙升。
五、产品侧技术对齐极简代码(可直接落地)
作为AI产品,无需深耕开发,但需掌握核心校验与分发逻辑,可用于PRD规则定义、需求评审、问题排查、技术对齐。以下为多模态项目通用极简可运行代码,覆盖资源校验、模态分发核心场景。
# 多模态AI产品 资源校验与模态分发核心逻辑
# 适配图文、音视频场景,可直接用于产品规则配置
def multimodal_check(file_type: str, file_size: int, duration: int = 0):
"""多模态资源合规前置校验"""
# 图片资源约束
if file_type in ["jpg","png","jpeg"]:
if file_size > 5 * 1024 * 1024:
return False, "图片超出5M限制,需压缩后上传"
# 视频资源约束
elif file_type == "mp4":
if duration > 300:
return False, "视频时长超出5分钟限制,请裁剪后重试"
return True, "资源校验通过"
def modal_model_route(file_type: str) -> str:
"""根据资源类型匹配对应解析模型"""
if file_type in ["jpg","png","jpeg"]:
return "图像解析多模态模型"
elif file_type == "mp4":
return "视频帧+音频融合解析模型"
else:
return "文本大模型"
if __name__ == "__main__":
print(modal_model_route("mp4"))
产品落地价值:可直接写入产品需求文档,定义前端拦截规则、后端资源校验逻辑、模型分发策略,实现与研发团队的高效对齐,减少需求返工与线上问题。
六、多模态产品最优落地解决方案
针对以上难点,总结出一套可直接复用的标准化落地方案:
-
前置风控拦截:在用户侧完成格式、大小、时长校验,提前拦截异常资源,从源头降低解析失败率。
-
分模态并行解析:拆解视频、图文混合资源,分维度解析后做信息融合,提升答案准确率。
-
智能自适应压缩:基于场景自适应压缩资源,平衡解析精度与算力成本,避免细节丢失。
-
时序与位置溯源:为视频、图文解析结果绑定时间戳、空间位置信息,实现答案可溯源、可校验。
-
动态权重调优:针对图文、视频场景调高视觉模态权重,避免文本信息主导导致的效果偏差。
七、总结
在AI行业高度内卷的2026年,纯文本AI产品能力已经无法支撑高薪岗位与复杂项目落地。多模态产品设计与落地能力,已经成为AI产品经理的核心差异化竞争力。
想要做好多模态项目,核心是跳出传统文本思维,尊重图像、音视频的技术特性,通过标准化的输入规范、分模态解析逻辑、精细化的参数配置,解决准确率低、超时、成本高、信息错位等核心问题。
配套学习资料
为方便大家快速落地项目、备战面试,我整理了多模态AI产品全套实战资料,包含多模态标准化PRD模板、图文/音视频参数配置规范、落地避坑手册、面试高频问题汇总,适配日常项目迭代与求职提升。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)