Redis - Pika 如何基于 SSD 实现大容量 Redis
文章目录
引言
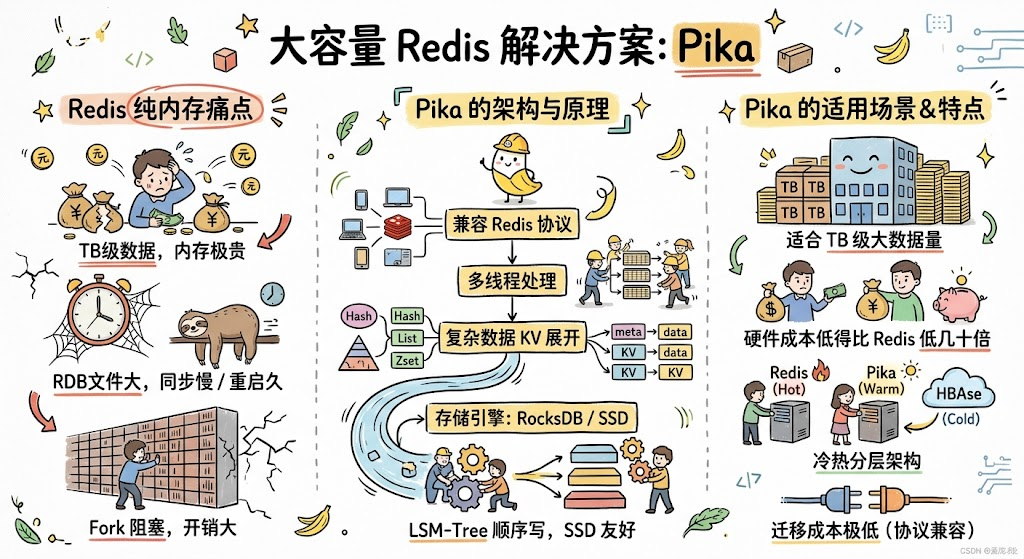
Redis 把数据全放内存里,速度很快但内存贵。当业务数据量到 TB 级,单纯靠加内存的成本会陡然上升。这时候有一个很自然的想法:能不能让 Redis 兼容的服务跑在 SSD 上,拿一点延迟换取大得多的容量?360 团队开源的 Pika 就是这个思路的代表。
大容量 Redis 的痛点
随着数据量增加,纯内存方案会暴露出几个问题:
内存成本高
主流云服务商的 100GB 内存机器价格远高于同等容量的 SSD。如果业务数据量到 TB 级,内存方案的硬件成本可能是 SSD 方案的几十倍。
主从同步压力大
Redis 实例越大,全量同步时生成的 RDB 越大,网络传输越久。万一从库长时间断连,重新接入时大概率触发全量同步,瞬间打满主库 IO。
故障恢复慢
实例越大,重启后从 AOF 或 RDB 恢复数据的时间越长。一个 50GB 的实例,恢复可能要十几分钟,期间业务完全不可用。
fork 开销大
无论是 BGSAVE 还是 AOF 重写,都依赖 fork。实例越大,页表越大,fork 阻塞越严重。
Pika 的整体架构
Pika 兼容 Redis 协议,应用层无需改动就能切换。它的核心是把数据从内存搬到了 SSD,底层用 RocksDB 做存储引擎。
整体由几个模块组成:
网络层(兼容 Redis 协议)
↓
线程模型(多线程处理)
↓
数据结构层(String/Hash/List/Set/Zset 等)
↓
存储引擎(RocksDB / 改进版本)
↓
SSD
每个模块都为大容量场景做了针对性优化。
RocksDB 作为存储引擎
RocksDB 是 Facebook 基于 LevelDB 改造的 KV 存储引擎,使用 LSM-Tree(Log-Structured Merge Tree)结构。它的特点正好契合 SSD:
- 顺序写为主:LSM-Tree 把所有写入先记到内存表(MemTable),然后按层级合并下沉到磁盘。SSD 顺序写性能极佳。
- 批量持久化:MemTable 满了才落盘,减少小 IO。
- 数据有序:每层 SSTable 内部有序,方便范围查询。
LSM-Tree 的代价是读放大和空间放大。读一个 key 可能需要查多层 SSTable;后台 compaction 会复制数据,导致空间占用比实际数据大。但对于大容量场景来说,这些代价是可以接受的。
数据结构的存储设计
Redis 的复杂数据类型(Hash、List、Set、Zset)都需要在 KV 存储上重新设计。Pika 采用了一种通用方案:把上层的复杂类型展开成多个底层 KV 对。
Hash 的存储
原始:HSET user:1 name Alice age 30
底层:
meta_user:1 → {size: 2, version: 1}
data_user:1_name → Alice
data_user:1_age → 30
一个 meta key 记录元信息(元素数、版本号),多个 data key 存实际字段。
List、Set、Zset 类似处理
每种类型都有自己的展开规则,Zset 还需要额外的 score 索引。
这种设计的代价是:单个高层操作可能要触发多个底层 KV 操作。但好处是把所有数据类型统一到 RocksDB 之上,简化了存储引擎的实现。
多线程模型
Redis 是单线程的(命令处理这块),Pika 引入了多线程:
- 网络 IO 线程:处理客户端连接和数据读写。
- 工作线程:执行命令。
- 后台线程:处理 RocksDB 的 compaction、key 过期等。
多线程能更好地利用现代多核 CPU,但也要处理并发控制的问题。Pika 通过分片锁、无锁数据结构等手段降低并发开销。
主从同步的优化
Pika 的主从同步不再用 RDB+命令的方式,而是直接基于 RocksDB 的二进制日志:
- 全量同步:从库直接拷贝主库的 SSTable 文件,类似数据库的物理备份。
- 增量同步:基于 binlog 序号,主库把增量 binlog 发给从库。
物理拷贝比生成 RDB 快得多,全量同步速度大幅提升。
Pika 的性能特点
和 Redis 比,Pika 的性能特征大致是这样:
| 维度 | Redis | Pika |
|---|---|---|
| 容量 | 受限于内存 | 受限于磁盘 |
| 单机数据量 | 几十 GB | TB 级 |
| 平均延迟 | 微秒级 | 亚毫秒级 |
| QPS(小 value) | 10W+ | 5W~10W |
| 启动恢复 | 慢(大实例) | 快(直接打开数据库) |
| 内存开销 | 100% | ~10% |
延迟是 Pika 的主要短板,但对于大多数业务来说,从 100μs 到 500μs 的差距并不致命。
适合用 Pika 的场景
Pika 不是 Redis 的替代品,而是补充。它适合:
- 数据量大且延迟容忍:用户画像、推荐特征、历史归档等。
- 冷热分层:热数据放 Redis,温冷数据放 Pika。
- 存储型场景:把 Redis 当数据库用的场景,Pika 更稳妥。
- 从 Redis 迁移:因为协议兼容,迁移成本低。
不适合:
- 极致延迟要求:金融行情、实时风控等。
- 小数据量:折腾 Pika 不如直接用 Redis。
- 高频小写入:LSM-Tree 的写放大在频繁小写入下会暴露。
Tendis 等同类方案
业界类似思路的开源方案还有:
- Tendis(腾讯):基于 RocksDB,强一致主备同步。
- KeeWiDB(腾讯):分层存储,自动冷热分离。
- Kvrocks(美图):兼容 Redis Cluster,基于 RocksDB。
它们的共同点都是用 LSM-Tree 引擎换大容量。差异主要在数据结构设计、副本协议、运维体验上。
实践建议
- 先评估业务的延迟敏感度,如果业务能接受亚毫秒级延迟,Pika 是省钱的选择。
- 冷热分层架构:热数据 Redis,温数据 Pika,冷数据 HBase/对象存储。
- 关注 RocksDB 调优:write_buffer_size、max_background_compactions 这些参数对性能影响很大。
- 监控空间放大:Compaction 不及时会导致磁盘占用远超实际数据。
- 测试主从同步:大数据量下的同步行为和 Redis 差别不小,上线前充分演练。
Pika 的存在意义在于:当业务的数据规模远超内存预算时,提供一条折中路径,既保留了 Redis 的接口和生态,又拓展了容量上限。理解它的设计取舍,有助于在架构选型时做出更合理的决策。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)