南京FIGO软件人工智能学习之路第五讲:大模型外挂 - RAG (检索增强生成)
作为一线程序员高强度使用各种AI大模型和工具近1年,我深刻感受到了AI大模型的强大和便捷,但是一直在应用层不知道底层原理,很多概念理解的似是而非,没有体系化的知识体系,所以开始了这个自学人工智能之路。
1.我会结合视频教程、文档、大模型等学习资源,将自己学习人工智能的过程做个整理和记录。
2.后续会结合实际使用的案例和项目(有实际工作中的项目,也有自己兴趣使然的作品),逐步讲解一些经验和教训,希望能给大家带来一些帮助。
3.其中的一些错误和共鸣点欢迎大家指正和交流。
第五讲:大模型外挂 - RAG (检索增强生成)
文章导读:如果你觉得大模型有时候像个“一本正经胡说八道”的骗子,或者总是不知道最新的新闻,那么 RAG (Retrieval-Augmented Generation) 就是拯救它的良药。如果说 Prompt 是大模型的“内功心法”,那么 RAG 就是给大模型装备了“外挂知识库”。本文将带你深入理解:
核心痛点:为什么大模型会有“幻觉”和“知识过时”?
技术原理:RAG 是如何让大模型从“闭卷考试”变成“开卷考试”的?
关键技术:向量数据库 (Vector DB) 和 Embedding 是什么鬼?
进阶应用:从简单的文档问答到复杂的企业级知识库。
📊 统计信息:全文约 9000 字 | 预计阅读时长 30 分钟
第一部分:为什么你需要 RAG?
即使是 GPT-4 这样强大的模型,也有两个致命的弱点:
-
**知识截止 (Knowledge Cutoff)**:
-
模型的知识来自于训练数据。如果训练数据截止到 2023 年,它就完全不知道 2024 年发生了什么。
-
形象比喻:就像一个博学多才的老教授,但他被关在深山老林里闭关修炼了两年,刚出关时,他完全不知道外面流行什么梗。
-
-
**幻觉 (Hallucination)**:
-
当模型不知道答案时,它倾向于通过概率预测“编造”一个看起来合理的答案。
-
形象比喻:就像一个爱面子的学霸,考试遇到不会的题,为了不留空白,硬是编了一套看似通顺的歪理。
-
1.1 传统的解决方案 vs RAG
面对这两个问题,我们通常有两种解决思路:
-
**微调 (Fine-tuning)**:
-
把新知识喂给模型,让它重新训练(或增量训练)。
-
缺点:贵!慢!而且知识更新太快,天天微调谁受得了?
-
比喻:为了让老教授知道昨天的新闻,把他的大脑做一次“手术”植入记忆。
-
-
**RAG (检索增强生成)**:
-
在问模型之前,先去外部知识库(数据库、文档、网页)里搜一搜,把搜到的相关信息作为“参考资料”喂给模型。
-
优点:便宜!快!数据实时更新,还能溯源。
-
比喻:给老教授配了一台能联网的电脑。遇到不懂的,先搜一下,再结合搜索结果回答你。
-
第二部分:RAG 的工作原理 - 从“闭卷”到“开卷”
RAG 的全称是 Retrieval-Augmented Generation,即 检索 + 增强 + 生成。
2.1 核心流程图解
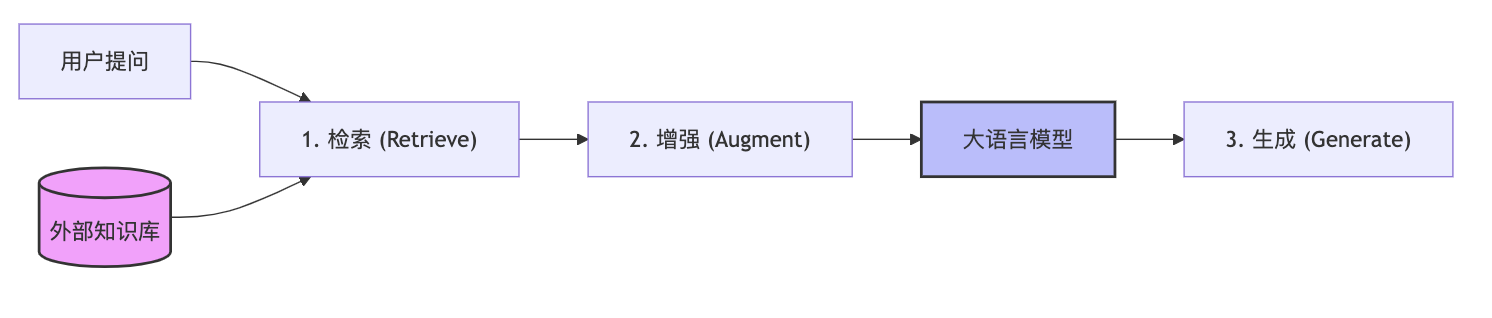
2.2 三步走战略
-
**检索 (Retrieve)**:
-
用户问:“飞哥最近在学什么?”
-
系统先去你的私有笔记库里搜索,找到了:“飞哥最近在写《人工智能之路》系列文章。”
-
-
**增强 (Augment)**:
-
系统把搜索到的信息和用户的问题拼在一起,变成一个新的 Prompt:
-
Prompt: 你是一个智能助手。请根据以下参考资料回答用户问题。 [参考资料]: 飞哥最近在写《人工智能之路》系列文章,已经更新到了第五讲。 [用户问题]: 飞哥最近在学什么?
-
-
**生成 (Generate)**:
-
大模型看到这个 Prompt,就不需要瞎编了,直接根据参考资料回答:“飞哥最近在系统地学习人工智能,并正在撰写《人工智能之路》系列文章。”
-
第三部分:核心技术 - 向量与向量数据库
你可能会问:系统是怎么从海量文档里精准找到“飞哥最近在写什么”这句话的? 靠关键词匹配吗?
❌ 关键词匹配 (Keyword Matching) 已经过时了。RAG 的核心武器是 **向量搜索 (Vector Search)**。
3.1 什么是 Embedding (嵌入)?
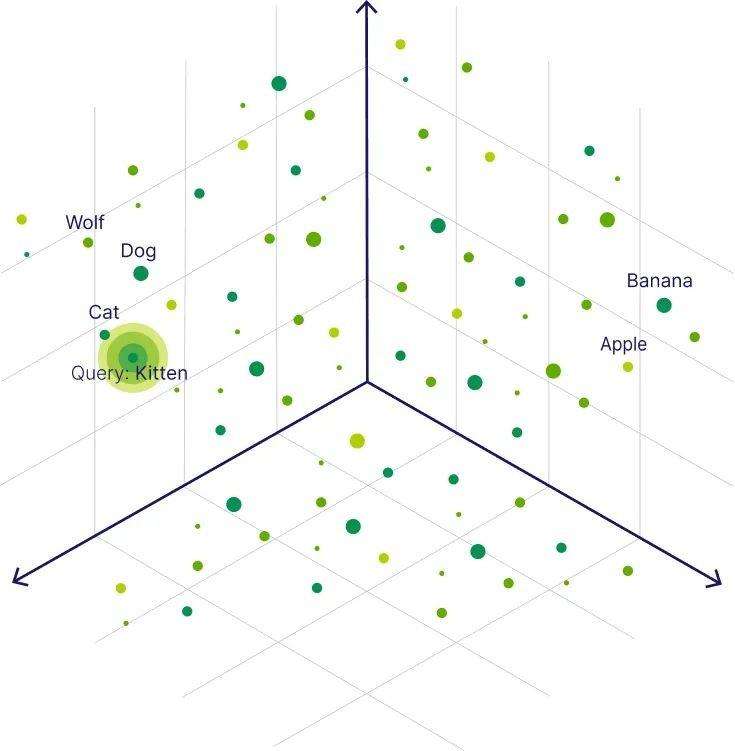
Embedding 是将 文字 转化为 数字向量 (Vector) 的过程。 但这不仅仅是编码,而是将语义压缩进数字里。
- 形象比喻:
-
假设我们在二维坐标系里描述水果。
-
“苹果”和“梨”在坐标系里离得很近(都是水果,圆的)。
-
“苹果”和“手机”离得很远。
-
但是!“苹果”和“乔布斯”在另一个维度上可能离得很近。
-
大模型通过 Embedding 模型,把一句话变成一个几百甚至几千维的向量(一串长长的数字列表)。意思相近的句子,在向量空间里的距离就越近。
3.2 向量数据库 (Vector DB)
传统的数据库(MySQL, Oracle)擅长存表格,不擅长算向量距离。如果你用 MySQL 存向量,查询时需要把库里几亿条数据一条条拿出来算距离,速度慢到怀疑人生。
于是,向量数据库 应运而生。它的核心能力就是:利用算法(如 HNSW, IVF)在海量数据中毫秒级找出距离最近的 N 个向量。
3.2.1 核心差异:关系型 vs 向量型
| 特性 | 关系型数据库 (MySQL/PostgreSQL) | 向量数据库 (Milvus/Pinecone) |
|---|---|---|
| 存储数据 | 结构化数据 (行/列) | 非结构化数据的向量表示 (Arrays) |
| 查询方式 | 精确匹配 (WHERE id=1) |
相似度匹配 (Top-K 近邻搜索) |
| 核心算法 | B+ Tree 索引 | ANN (近似最近邻) 索引 |
| 应用场景 | 订单、用户、库存管理 | 图片搜索、推荐系统、RAG 知识库 |
3.2.2 相似度计算:如何定义“近”?
-
**欧氏距离 (L2)**:两点之间的直线距离。越小越近。
-
余弦相似度 (Cosine):两个向量夹角的余弦值。主要看方向是否一致,不看长度。文本搜索最常用。
-
**内积 (IP)**:投影长度。用于推荐系统中算评分。
3.2.3 主流工具选型
-
Milvus:国产之光,开源,性能强,适合大规模数据。
-
Pinecone:SaaS 服务,开箱即用,不用自己维护服务器,但数据在海外。
-
Chroma:轻量级,Python 友好,适合本地开发和测试。
-
**Elasticsearch (ES)**:老牌搜索一哥,现在也支持向量搜索了,适合混合搜索场景。
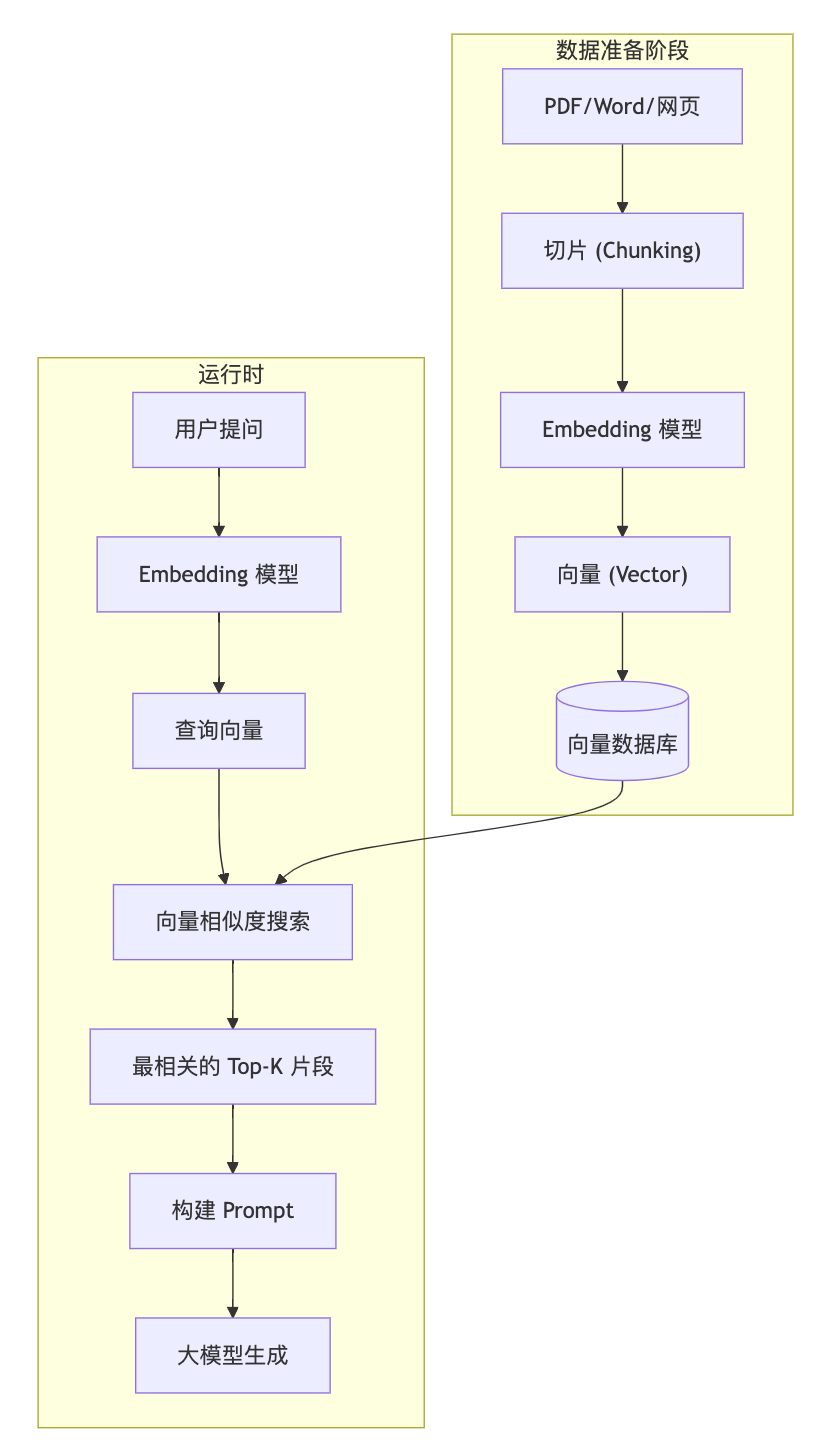
3.3 RAG 完整技术栈图解
第四部分:进阶 RAG - 让外挂更强
基础的 RAG 也就是“搜一段话给模型”,但在实际企业应用中,这还不够。
4.1 切片策略 (Chunking Strategy)
文档不能直接塞进数据库,需要切成小块。
-
切太小:语义不完整,容易断章取义。
-
切太大:包含太多无关信息,干扰模型,且浪费 Token。
-
技巧:按段落切、按语义切,或者**重叠切片 (Sliding Window)**(前一块和后一块有 10% 的重叠,保证上下文连贯)。
4.2 混合搜索 (Hybrid Search)
向量搜索虽然懂语义,但有时候对专有名词(如产品型号 "X-2000")的匹配不如关键词搜索精准。
-
解决方案:向量搜索 + 关键词搜索 同时进行,然后加权融合结果。
4.3 重排序 (Rerank)
向量数据库为了快,召回的 Top-K 结果可能只是“粗略相关”。
-
Rerank 模型:专门再请一个“精细审核员”模型,把召回回来的 50 条结果,仔仔细细读一遍,重新打分,选出最最相关的 5 条给大模型。
-
效果:虽然慢了一点点,但准确率大幅提升。
4.4 GraphRAG (知识图谱增强)
这是微软最近提出的新方向,也是 RAG 的进阶形态。要理解它,我们不仅要知道“它是什么”,更要深入了解“它为什么行”——即其背后的原理。
4.4.1 知识图谱的底层原理:三元组 (Triples)
知识图谱的核心存储结构并非复杂的神经网络,而是最朴素的逻辑学结构:**SPO 三元组 (Subject-Predicate-Object)**。
-
**主体 (Subject)**:比如 "乔布斯"
-
**谓语 (Predicate)**:比如 "创立了"
-
**客体 (Object)**:比如 "苹果公司"
每一个知识点,都被拆解为这样的原子结构:("乔布斯", "创立了", "苹果公司")。成千上万个这样的三元组连接起来,就构成了图谱。
💡 思考:三元组是“双向链表”吗? 你的直觉非常敏锐!它们确实很像,但三元组是双向链表的 “超级进化版”:
双向链表:是线性的。节点 A 只能连节点 B(Next),B 连 C。关系只有一种(前后)。
三元组(图):是网状的。节点 A 可以通过“创立”连 B,通过“父亲”连 C,通过“居住在”连 D。
本质区别:链表是一条单行道,知识图谱是四通八达的立交桥网络。但如果你把图谱中的某一条路径单独拎出来(比如
乔布斯 -> 苹果 -> iPhone),它确实就是一个链表!
-
原理:这种结构让计算机能够进行确定性的逻辑推理。比如已知
A -> B和B -> C,计算机可以推导出A和C存在间接联系。
4.4.2 为什么向量搜索会失效?(向量的局限性)
向量搜索(Vector Search)虽然强大,但它有两个致命弱点,这正是 GraphRAG 要解决的:
-
无法处理复杂逻辑链:向量只看“语义相近”。比如“乔布斯的爸爸是谁?”,向量可能会搜到“乔布斯传记”,但不一定能直接定位到“Paul Jobs”这个名字,除非文本里这两句话紧挨着。
-
无法进行全局总结:向量数据库只能返回 Top-K 个切片。如果你问“这篇文章主要讲了哪几个方面的冲突?”,向量搜索只能给你返回几段具体的冲突描写,而无法给你一个宏观的概括。GraphRAG 可以通过社区检测 (Community Detection) 算法,先找出图谱中密集的节点群(比如“冲突”相关的所有节点),然后对这些群进行摘要。
4.4.3 GraphRAG 的工作流原理
GraphRAG 是如何把非结构化的文本变成图谱,再用起来的呢?
- **提取 (Extraction)**:利用 LLM 强大的理解能力,从文档中自动抽取实体和关系。
-
Prompt:"请阅读以下文本,提取所有人物、公司及其关系,输出为 JSON 格式。"
-
-
**构建 (Construction)**:将抽取的三元组存入 **图数据库 (Graph DB)**,如 Neo4j、NebulaGraph。
- **检索 (Retrieval)**:
-
混合检索:同时进行关键词搜索、向量搜索和图谱遍历。
-
**多跳推理 (Multi-hop Reasoning)**:从起点节点出发,沿着边跳跃寻找答案。比如问“比尔盖茨的竞争对手创立了什么公司?”,系统路径:
比尔盖茨 --(竞争对手)--> 乔布斯 --(创立)--> 苹果公司。
-
4.4.4 图解 GraphRAG
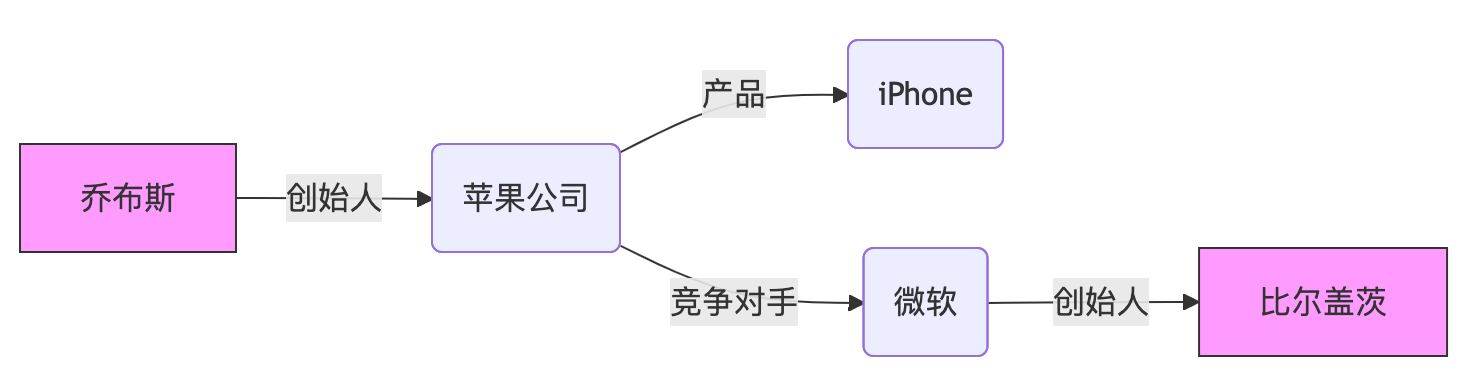
普通 RAG 很难把“乔布斯”和“比尔盖茨”联系起来,但 GraphRAG 可以顺着箭头找到他们的关系。
第五部分:实战场景 - 企业级知识库
光说不练假把式。RAG 在企业里最典型的应用就是 企业知识库 / 智能客服。
5.1 场景描述
你是某公司的技术负责人,公司有几万份 PDF 的产品手册、维修指南、内部流程。新员工入职总是问重复的问题,老员工不仅要干活还要当客服,苦不堪言。
5.2 解决方案
搭建一套私有化的 RAG 系统:
-
数据层:把几万份 PDF 全部 OCR 识别,切片,Embedding 入库。
- 应用层:
-
员工在钉钉/飞书里提问:“打印机卡纸怎么修?”
-
RAG 后台去搜维修指南的第 32 页。
-
大模型回答:“根据维修手册第 32 页,卡纸通常是因为滚轮老化。请尝试以下步骤:1. 打开侧盖... 2. 清理滚轮...” 并附上原文链接。
-
- 价值:
-
解放生产力:老员工不用回答弱智问题了。
-
知识资产化:沉睡在硬盘里的 PDF 变成了随时可调用的智慧。
-
安全可控:数据不出内网,大模型只负责语言组织,不负责存储机密。
-
第六部分:总结
RAG 是连接大模型与现实世界的桥梁。
-
如果 Prompt 是你教大模型怎么说话(心法);
-
那么 RAG 就是你给大模型喂什么书(外挂)。
在未来的 AI 应用架构中,LLM + RAG 将是标配。大模型负责逻辑推理和语言生成,RAG 负责提供精准、实时、私有的知识。掌握了 RAG,你就拥有了定制“行业专家”的能力。
下一讲,我们将探讨 AI Agent(智能体),看看当大模型不仅有脑子(LLM)、有知识(RAG),还有了手和脚(Tools)之后,会进化成什么样的新物种。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)