Transformer的⼯作流程
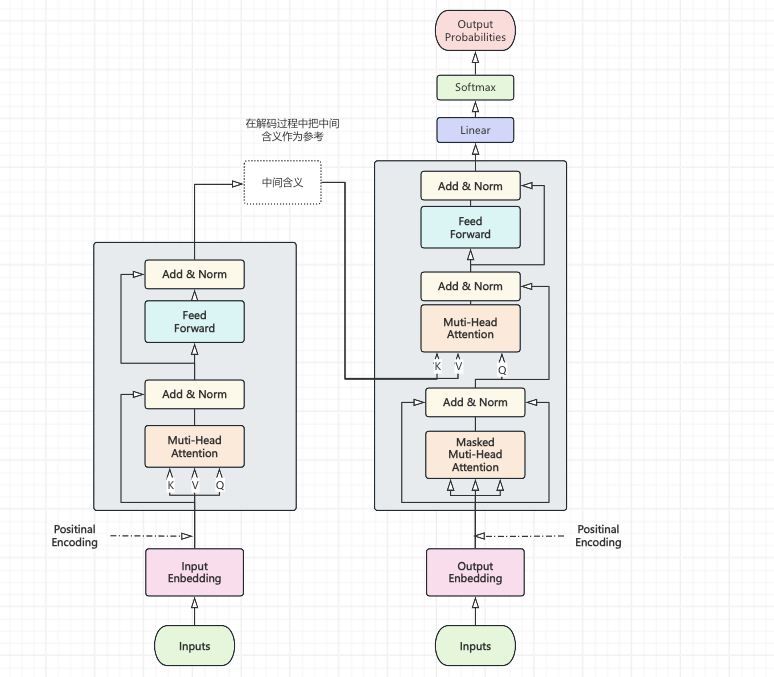
1、Input Embedding(输入嵌入)
Input Embedding(输入嵌入): 是整个模型的第一道工序。它的核心作用是将人类可读的、离散的文本符号(Token),转换为机器可计算的、连续的稠密向量表示。你可以把它理解为 “翻译官”,把“文字语言”翻译成“数学语言”,让后续的注意力机制和前馈网络能够处理
2、Output Embedding(输出嵌入)
Output Embedding(输出嵌入)指的是解码器输入端的词嵌入层。简单来说,它是将“已经生成的历史 token”转换为模型可理解的向量表示的模块。尽管名字里带有 "Output",但它实际上是解码器下一时刻预测的输入。
3、Positional Encoding(位置编码)
Positional Encoding(位置编码) 是 Transformer 架构中至关重要的一个组件。简单来说,它是为了给模型注入“顺序”或“位置”信息而人为添加的一个向量。
(Attention:注意力)
为什么需要Positional Encoding
- 要理解它的作用,首先要理解Transformer的核心缺陷:Transformer的Self-Attention的核心是“排列不变”的。这意味着,Self-Attention在计算时将输入序列视为一个集合(Set),而不是一个序列(Sequence)。如果如果打乱了句子的词序(例如把"I Love You" 变成"You Love I"),Self-Attention输出的特征表示在数学上是完全一样的(只是顺序变了)。
- 然而自然语言是高度依赖语序的(“狗咬人”和“人咬狗”意思完全不同),RNN/LSTM天生通过时间步传递信息,CNN通过卷积核的相对位置感知局部顺序,但Tansformer没有这种归纳配置,因此必须显示的告诉模型每个Token处于什么位置
它具体有什么作用
- 提供绝对位置信息:让模型知道当前token是句子中的第几个词
- 提供相对位置关系:好的位置编码设计能让模型通过运算(如点积)推导出两个Token之间的距离(相对位置),这对这对理解语法结构和语义依赖至关重要
- 保持注意力机制的有效性:将位置信息和词嵌入相加后,相同词在不同位置的Attention Score就会不同,从而使模型能够区分上下文
4、Multi-Head Attention(多头注意力机制)
Multi-Head Attention(多头注意力机制) 是 Transformer 架构的核心创新之一。简单来说,它是将标准的 Self-Attention 并行执行多次,每个“头”独立地学习不同的关注模式,最后将所有头的结果拼接融合。
1、为什么需要Multi-Head?单头不行吗?
理论上,单个足够大的 Attention 层也能拟合复杂函数。但在实践中,单头Attention 存在严重问题:单头 Attention 倾向于“平均化”多种不同的关注模式。
自然语言中,一个词与其他词的关系是多维度的。例如在句子 "The cat sat on the mat because it was tired" 中,"it" 同时涉及:
- 语法指代关系: "it" → "cat"(主语一致性)
- 语义因果关系: "tired" → "sat"(为什么坐?)
- 局部修饰关系: "on" → "mat"(空间位置)
单头 Attention 被迫在一个注意力分布中妥协、混合这些完全不同的关系,导致每种关系都学不精确。而多头机制让每个头专注于一种特定的关系类型
举例说明:想象你在审阅一篇复杂的学术论文:
- 单头 Attention 就像只有一位全能审稿人。他必须同时兼顾语法、逻辑、数据、创新性等所有维度。结果往往是他的注意力被“平均化”了,每个方面都看得不够深。
- Multi-Head Attention 就像组建了一个专家评审团。语言学专家专盯语法结构,逻辑学专家专盯论证链条,数据专家专盯图表引用,创新评估专家专盯核心贡献。每个人只负责自己擅长的维度(独立的子空间),最后把各自的评审意见汇总(Concat + Linear),得到一份全面且深刻的报告。
2、Multi-Head Attention 的核心作用
- 捕获多样化的依赖关系:不同头可以分别关注语法、语义、位置、共指等不同类型的关系
- 增强模型的鲁棒性:类似于集成学习,多个头的组合比单个头更稳定,不易过拟合到某种单一模式
- 提供可解释性窗口:可视化不同头的 Attention Map 可以发现模型学到的语言学结构(如主谓一致、从句嵌套等)
- 支持跨模态/跨层级交互:在 Encoder-Decoder Attention 中,不同头可以分别对齐源语言和目标语言的不同粒度单元
5、Masked Multi-Head Attention(带掩码的多头注意力)
Masked Multi-Head Attention(带掩码的多头注意力)是 Transformer 解码器中使用的核心注意力机制。简单来说,它就是加了一个“遮罩”的多头注意力,强制模型在生成第n个词时,只能看到前n−1 个词,绝对看不到未来的词。
Masked Multi-Head Attention有什么作用?
- 保证自回归生成的因果性:语言生成是从左到右逐个产出的。训练时必须模拟这一过程:预测第n个词时,模型不能“偷看”答案(第 n,n+1,n+2...个词)。Mask 确保了训练和推理时的信息可见性完全一致。
- 支持高效的并行训练:如果没有 Mask,要模拟自回归就需要逐时间步展开 RNN 式训练,无法并行。有了 Mask,可以一次性把整个序列喂进去,通过掩码矩阵在一次前向传播中同时计算所有位置的损失,训练效率提升数个数量级。这正是 Transformer 取代 RNN 的根本原因。
- 防止信息泄露:如果不加 Mask,模型会直接学会“复制下一个词”这个捷径,Loss 迅速降为 0 但模型毫无泛化能力。Mask 迫使模型真正学习语言规律而非记忆答案
总结:Masked Multi-Head Attention 就是带遮罩的多头注意力,它让 Transformer 既能像 RNN 一样遵守从左到右的生成顺序,又能像 CNN 一样高效并行训练。
6、Add & Norm
Add & Norm 是 Transformer 架构中每个子层(Self-Attention 和 Feed-Forward Network)之后都必须跟随的标准组件。它的全称是 Residual Addition + Layer Normalization。
Residual Addition:残差相加;Layer Normalization:层归一化
它的公式为Output=LayerNorm(X+Sublayer(X)),其中 𝑋 是该子层的输入,Sublayer(𝑋)是该子层(如 Attention 或 FFN)的输出。这个算式是深层 Transformer 能够成功训练的工程基石
Add(残差连接)有什么作用?
- 解决梯度消失问题: Transformer 通常有几十甚至上百层。如果没有残差连接,反向传播时梯度需要连续穿过每一层的非线性变换,极易造成指数级衰减或爆炸。Add提供了一条梯度高速公路,让梯度可以无损地跨层回传。
- 保留原始信息: 每一层只需要学习输入与输出之间的“差异”(即Δ=Sublayer(X)),而不需要从头重建完整表示。这大幅降低了每层的学习难度。
- 稳定训练动态: 即使某一层学到了错误的变换,残差连接保证了至少原始输入信息不会丢失,模型不会突然“崩溃”。
Add方式:将子层的输入X 直接“跳跃”连接到子层的输出上,进行逐元素相加
Norm(层归一化)
- 平滑优化地形(解决梯度爆炸问题) : 深度网络的损失曲面极其崎岖。将每层的输出拉回到一个稳定的数值范围,使 Loss Landscape 更平滑,允许使用更大的学习率。
- 解耦层间依赖: 每层的输入分布不再剧烈依赖于前一层参数的变化(缓解 Internal Covariate Shift),各层可以更独立地学习
- 正则化效果: LN 引入的噪声(来自 mini-batch 内的统计估计)具有一定的正则化作用,有助于泛化。
为什么必须 "Add" 和 "Norm" 组合使用?
- 只有 Add 没有 Norm
- 残差不断累加, activations 的方差会随层数增长而膨胀,最终数值失控
- 不同层的输出尺度不一致,Attention 的 softmax 对尺度敏感,导致训练不稳定
- 只有 Norm 没有 Add
- 归一化虽然稳定了分布,但切断了跨层的梯度直通路径,深层仍然难以训练
- 每层都在重新归一化,原始输入信息被反复扭曲,丧失了残差学习的优势
总结:Add & Norm 不是可选的优化技巧,而是 Transformer 能堆叠到数百层的必要条件。 Add 解决了“深度带来的梯度问题”,Norm 解决了“深度带来的数值问题”,二者缺一不可。
7、Feed-Forward Network(前馈神经网络,简称 FFN)
Feed-Forward Network(前馈神经网络,简称 FFN)是紧跟在每一个 Attention 层之后的独立子层。如果说 Attention 负责“理解词与词之间的关系”,那么 FFN 就负责“深度思考和知识存储”
- Feed-Forward 有什么作用?
- 引入非线性表达能力:Attention 机制本质上是加权求和(softmax + 矩阵乘法),无论堆叠多少层,如果没有非线性激活,整体仍然是线性变换。FFN 中的激活函数𝜎是 Transformer 中最主要的非线性来源,使模型能够拟合复杂的语言模式。
- 充当“知识库”:大量研究表明,FFN 的权重矩阵实际上存储了模型的事实知识和语义记忆:
- 对 FFN 特定神经元进行消融实验,会导致模型丢失特定的事实知识(如国家首都、语法规则)。
- 通过修改 FFN 权重可以直接编辑模型的行为或注入新知识。
- Attention 更像是“检索引擎”(决定看哪里),而 FFN 才是“数据库”(存储了什么)。
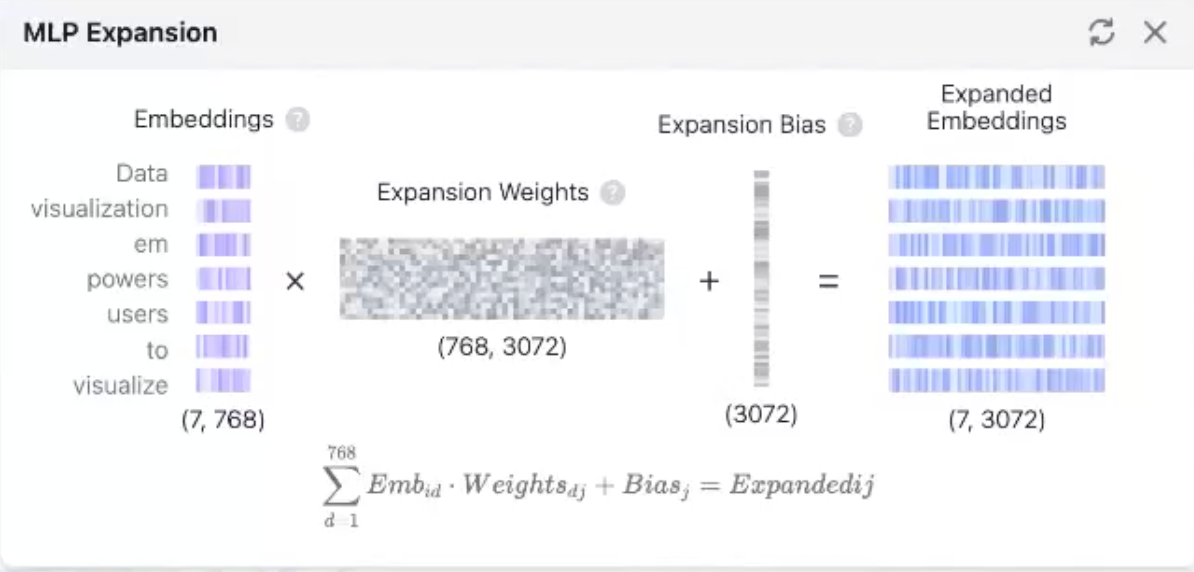
- 特征空间的扩展与压缩:FFN 先将维度扩大 4 倍再压回来,这种“瓶颈-扩展”结构的作用是:
- 扩展阶段: 将紧凑的语义表示投射到高维空间,在高维空间中原本纠缠在一起的特征变得线性可分,便于非线性操作。
- 压缩阶段: 将处理后的丰富特征重新整合回原始维度,供下一层使用。
- 这类似于人脑的“联想思考”过程:接收到一个概念后,在大脑中展开丰富的关联信息进行处理,然后再提炼出结论传递给下一步推理
- 提供计算容量:在标准 Transformer 中,FFN 的参数量约占整个模型的 2/3。它是模型容量的主要载体,决定了模型能记住多少知识、能做多复杂的推理
总结:Attention 负责“看到什么”(动态路由),FFN 负责“知道什么”(静态知识与非线性变换)。 二者交替堆叠,构成了 Transformer “检索-思考-检索-思考”的深度推理循环。
举例:
7*768 升维到 7*(768*4)3072 再降维到 7*768
8、Linear(线性层)
Linear(线性层):是全连接层(Fully Connected Layer / Dense Layer),其本质就是一个不带激活函数的矩阵乘法加偏置操作。它是神经网络中最基础、最核心的构建块。如果说 Attention 和 FFN 是 Transformer 的“器官”,那么 Linear 就是构成这些器官的“细胞”。
Linear 有什么作用?
- 特征空间的投影与变换:这是 Linear 最根本的作用。它将输入从一个语义空间旋转、缩放、平移到另一个语义空间:
- 升维:将紧凑表示展开到高维空间,使紧凑的特征变得线性可分,为非线性处理做准备。
- 降维:将高维处理结果压缩回原始维度,提取关键信息并丢弃冗余。
- 同维变换:在同一维度内重新组合特征,改变信息的表达方式而不改变容量。
- 作为所有复杂模块的基础组件:Transformer 中几乎每个核心模块都由 Linear 构成,Transformer 的参数几乎全部存储在 Linear 层的权重矩阵W中。
- 跨位置的信息混合(间接):Linear 本身是逐位置独立操作的(对序列中每个 token 用相同的W ),不做跨位置交互。但它与 Attention 交替堆叠后,形成了完整的处理循环:
- Attention:跨位置混合信息("看哪里")
- Linear:对混合后的信息进行逐点变换("怎么处理")
二者缺一不可。只有 Attention 没有 Linear,模型无法做非线性特征提取;只有 Linear 没有 Attention,模型退化为逐位置的 MLP,完全丧失上下文理解能力
- 知识存储的载体:FFN 是“知识库”,而 FFN 的主体就是两个 Linear 层。研究证实事实知识编码在 FFN 的W1和W2权重中
- 语言模式、语法规则分布在 Attention 的 Q/K/V 投影矩阵中
- 对特定 Linear 权重进行手术式修改,可以精准编辑模型行为
总结:Linear 是深度学习中的“万能齿轮”——它本身只做最简单的线性投影,但通过不同的组合方式,构成了注意力机制的记忆检索、前馈网络的知识存储、以及整个大模型的智能基座。
9、Softmax(Soft Maximum,软最大值)
Softmax(Soft Maximum,软最大值)是深度学习中最重要的归一化激活函数。 简单来说,它的作用是:将一组任意实数转换为一个概率分布,使得所有输出值都在(0,1) 之间,且总和严格等于 1。在 Transformer 中,它是 Attention 机制的“灵魂”——没有 Softmax,注意力分数就只是无意义的数值,无法变成可解释的“权重”
Softmax 有什么作用?
- 将注意力分数转化为概率权重:在 Self-Attention 中计算出的原始分数可以是任意实数(正、负、无穷大)。Softmax 将其归一化为概率分布
- 每个 query 对所有 key 的注意力权重之和 = 1
- 权重可以直接解释为“关注度比例”
- 使加权求和成为有意义的组合,输出不会因权重尺度而爆炸或消失
- 多分类任务的输出层:在语言模型的最终输出头(LM Head)中,Linear 层产出词表大小的 logits(如 32000 维),Softmax 将其转为下一个 token 的概率分布:
- 训练时:与真实标签计算交叉熵损失
- 推理时:取 argmax 得到预测词,或按概率采样生成文本
- 提供可微的“选择”机制:在很多需要“从多个选项中选一个”的场景中,硬选择不可导。Softmax 提供了连续的近似
- Mixture of Experts (MoE):路由器用 Softmax 决定各专家的激活权重
- Pointer Networks:用 Softmax 指向输入序列中的某个位置
- Differentiable Sorting / Ranking:用 Softmax 近似排序操作
总结:Softmax 是连接“原始数值”与“概率语义”的桥梁——它把 Attention 的相似度分数变成了可解释的关注度权重,把模型的 logits 变成了可采样的语言概率
注意力模块是要知道词(token)和句子中其它词的关系来理解在句子中的含义
前馈神经网络是要知道所有词组成的句子是什么含义

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)