CQRS架构模式与传统CRUD相比的优势特点
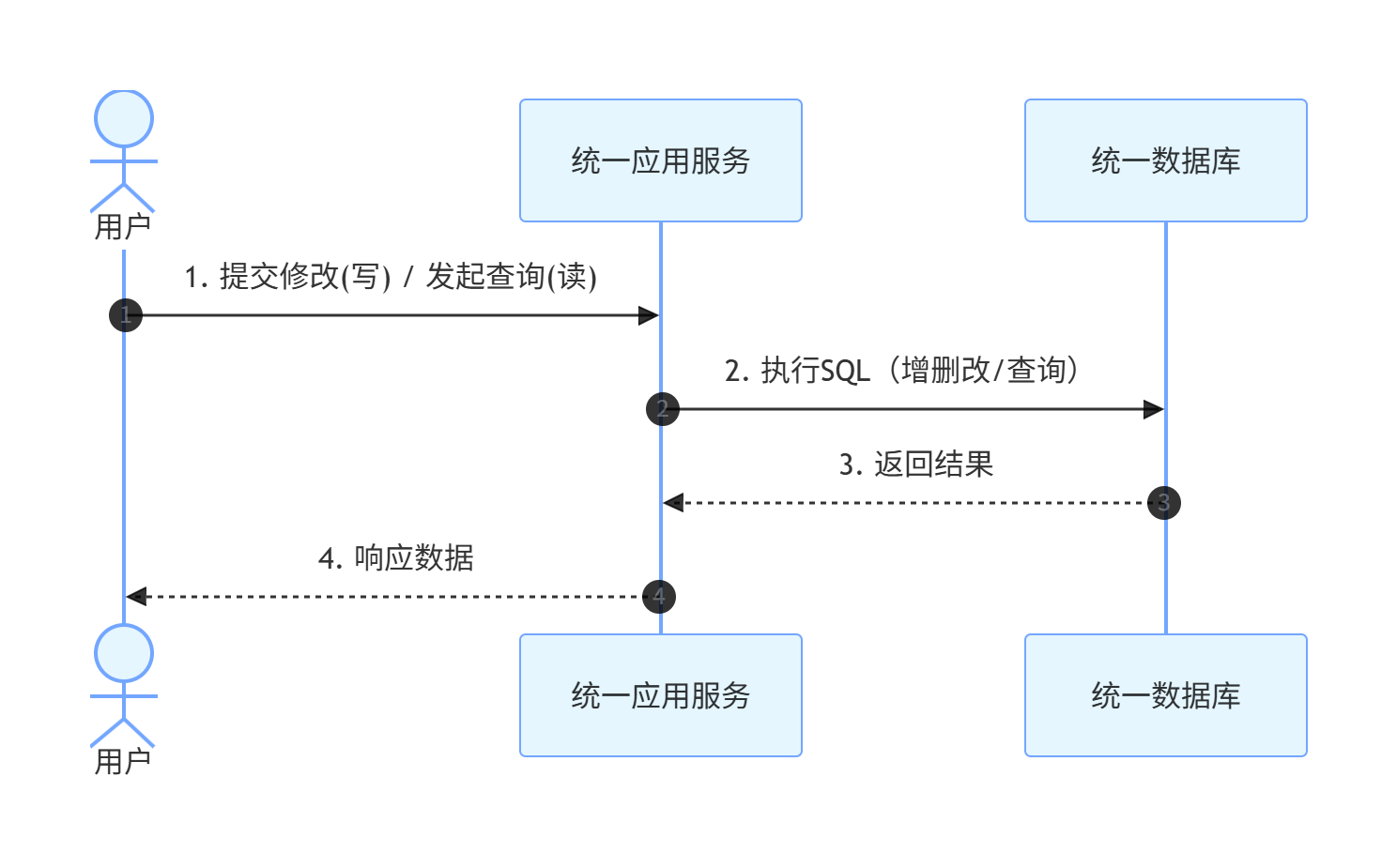
一、传统CRUD
- 传统开发习惯一套代码、一个数据库搞定增删改查(CRUD),读写操作混在一起。
- 传统 CRUD 模式下,不管是新增、修改数据,还是查询列表、检索内容,都共用同一张表、同一个服务、同一组接口。业务简单时完全够用,但一旦数据量变多、查询请求暴涨,数据库压力会全部堆在一起:
- 写操作要锁表保证事务,读操作又频繁扫描全表,互相影响,查询越跑越慢,系统很容易遇到性能瓶颈。
1.1CRUD流程图
二、CQRS命令查询职责分离
引言 CQRS 里的读流程到底是怎么工作的?
很多人在刚接触 CQRS(Command Query Responsibility Segregation)时,最容易疑惑的就是:
“写读流程到底怎么走的?”
“为什么不直接查 MySQL?”
“Redis / ES 的数据又是哪里来的?”
本篇博客用一张 CQRS 流程图清晰展示给大家:
- CQRS 的写流程
- CQRS 的读流程
- 为什么需要读写分离
- Redis / ES 在 CQRS 中的作用
- 数据同步机制
- 最终一致性
2.1 核心概念
传统架构中,我们对同一个数据库进行读写(增删改查)。但实际业务中,读和写的压力往往是不对等的(例如电商系统,浏览商品的次数远大于下单次数)。
CQRS 核心思想是将“写操作(Command)”与“读操作(Query)”彻底分离。写库负责高并发的数据写入和业务逻辑校验;读库(如结合 ES 或 Redis)负责高性能的数据查询。
-
优点:读写分离、各自优化、性能极高。
-
缺点:写库的数据需要同步到读库,存在短暂的最终一致性延迟。
2.2核心调用顺序图

一句话总结:
写进 MySQL
查走 Redis / ES
2.3写流程说明
1.用户发起数据变更请求(创建 / 更新 / 删除)
2.命令服务执行业务逻辑,写入数据库
3.数据库写入成功,返回结果
4.命令服务返回成功给用户(写操作完成)
5.通过Binlog捕获数据库变更数据
- binlog:MySQLServer 服务层日志,所有引擎通用
- 作用:用于主从复制、数据备份与误操作恢复
- 记录内容:记录逻辑 SQL 语句,记录执行的操作逻辑
- 写入时机:事务完全提交成功后才写入
- 写入方式:追加写入,不断生成新日志文件,不覆盖旧日志
- 使用场景:主库同步从库、数据定时备份、找回误删数据
6.将变更数据发布到消息队列,并同步到读存储(ES/Redis)
其中Elasticsearch(简称 ES)不是传统意义上的关系型数据库,但它可以被看作是一种特殊的 “文档型 / 搜索型数据库”,擅长全文检索、分词、模糊匹配、多维度过滤
| 原则 | 说明 |
|---|---|
| Redis 存热点,ES 存全量 | Redis 命中率决定查询延迟,ES 保证功能完整性 |
| 缓存是计算结果的缓存,不是数据库的缓存 | 存的是读模型视图,不是原始表数据 |
| 删除缓存而非更新缓存 | 更新缓存易引发并发脏数据,删除+懒加载更安全 |
| ES 面向查询设计,不要追求范式 | 大胆冗余,一个索引解决一类查询场景 |
| 同步链路要有监控和兜底 | 延迟告警、对账任务、手动重建能力必备 |
2.4 读流程说明
1.用户发起数据查询请求(搜索 / 列表 / 详情)
2.查询服务(Query Service)接收请求
- Query Service 只负责查询
- 不负责新增、修改、删除操作
- 读服务与写服务完全分离
3.查询服务从读存储查询数据(Redis / ES)
Redis:适合高频缓存数据
ES(Elasticsearch):适合全文搜索与复杂检索
| 组件 | 主要用途 |
|---|---|
| Redis | 用户信息、排行榜、热点缓存 |
| ES | 商品搜索、文章搜索、全文检索 |
4.读存储返回查询结果给 Query Service
5.Query Service 对结果进行封装处理
- 数据聚合
- 字段转换
- 权限过滤
- 分页处理
6.Query Service 返回结果给前端用户完成整个读流程
三、最关键的问题:Redis / ES 的数据哪里来的?
这是 CQRS 最核心的地方。
因为:
用户写数据
↓
MySQL
但:
用户查数据
↓
Redis / ES
所以:
必须:
把 MySQL 数据同步到 Redis / ES
四、CQRS 的数据同步机制
最常见方案:
Binlog + MQ
流程:
MySQL
↓
监听 Binlog
↓
发送 MQ 消息
↓
消费者更新 Redis / ES
五、Binlog与MQ
举例说明Binlog:
MySQL 的操作日志
例如:
UPDATE user
SET name = '李四'
WHERE id = 1;
MySQL 会记录:
谁被修改了
改了什么
然后:
同步程序监听这些变化。
MQ的简单示例
- 例子:商品修改 → 同步 ES
- 场景:你修改了商品名称、价格,不能直接阻塞用户去更新 ES,所以用 MQ 异步做。
- 流程
生产者:更新 MySQL 商品 → 发一条消息到 MQ
MQ:存着消息,不着急处理
消费者:后台慢慢取出消息 → 更新 ES
用户不用等 ES 更新完,立刻返回成功!
MQ(消息队列)流程图: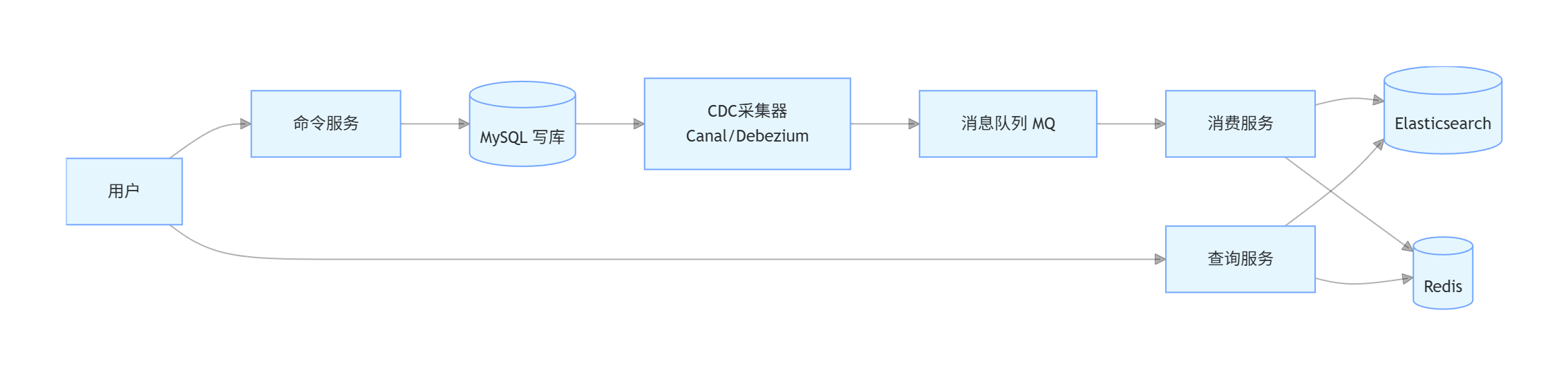
常见MQ消息队列:
- Kafka
- RabbitMQ
- RocketMQ
六、缓存过期怎么办?
这是 CQRS 里最经典的问题。
因为:
MySQL 更新了
Redis 可能还是旧数据
缓存过期后的标准流程:
用户查询
↓
Redis 没数据(miss)
↓
查询 MySQL
↓
把数据重新写回 Redis
↓
返回用户
这个过程叫:
缓存回填(Cache Rebuild)
而 CQRS 的核心目标:
允许短暂不一致
换取高性能
为什么不用缓存永久不过期?
1.Redis 内存很贵
- 不可能永远缓存所有数据
2.数据会变脏
- 例如:商品价格变化,缓存一直不失效:用户会看到旧数据。
设置TTL 自动过期(兜底机制)
Redis:
EXPIRE user:1 300
5 分钟后自动失效。
即使同步失败或系统异常
缓存最终也会自动恢复
双删策略
流程:
先删缓存
↓
更新数据库
↓
延迟再删一次缓存
作用:
防止:
旧数据重新写回缓存
CQRS 里的真正目标
CQRS + Redis 的核心:
不是:
完全不查 MySQL
而是:
让 MySQL 只负责少量真实查询
绝大多数请求:Redis / ES 解决
总结注意!!!
CQRS并不适用于所有场景,只适用于某些特定的场景。大部分系统都使用传统的 CRUD 模式,人们对它的认知度也更高。CQRS 模式对人们来说跨度太大,所以说除非它成效显著,不然很少有人愿意去尝试。虽然存在 CQRS 的成功案例,但目前为止,CQRS 大多数情况下的运行不尽人意,人们认为使用 CQRS 会让软件系统出现问题
目前来说,CQRS 在两个方面的应用很好。首先,CQRS 可以轻松处理复杂场景。然而我想强调一下,这种情况是非常少的。通常情况下,命令和查询重叠较多,共用一个模型更简单些。如果 CQRS 和场景不匹配就会增加系统的复杂性,因此降低生产效率、增加风险。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)