Codex 类工具继续升温后,开发者真正要关心的不是会不会写代码,而是能不能接进工作流
Codex 类工具继续升温后,开发者真正要关心的不是会不会写代码,而是能不能接进工作流
这两天 AI 编程工具的讨论又热了起来,但这次值得看的不是“谁又能多写几行代码”,而是一个更现实的问题:AI 助手正在从“代码补全工具”变成“开发流程的一部分”。
以前很多人用 AI 写代码,方式很简单:把报错贴进去,让它改;把需求说一遍,让它生成函数;让它解释一段看不懂的代码。
这当然有用,但也很容易停留在“临时救火”阶段。今天用一下,明天忘了;这个项目用一下,换个项目又重新开始。真正影响开发效率的,不是 AI 某一次回答有多惊艳,而是它能不能稳定进入你的日常开发流程。
尤其是 Codex 这类工具继续升温之后,开发者更应该换一个问题来问:不是“AI 会不会写代码”,而是“我能不能把 AI 放进一个可控、可复核、可复用的工作流里”。
这才是 CSDN 用户真正需要关心的点。
- 热点背后的变化:AI 编程助手不再只是补全代码
过去的 AI 编程工具更像“智能提示器”。你写一半,它补一半;你忘了 API,它帮你查;你遇到报错,它给你解释。
但现在的趋势明显变了:AI 正在从单点能力往流程能力走。它可能参与读需求、拆任务、生成初版代码、补测试、解释历史代码、检查边界条件、生成提交说明、辅助 code review、写接口文档、帮你定位影响范围等环节。
也就是说,AI 编程工具的价值,已经不只是“帮我写一个函数”,而是“帮我减少从需求到交付之间的重复劳动”。
如果 AI 只能在你卡住的时候临时帮一下,它是工具;如果 AI 能固定参与你的开发链路,它才可能变成工作流的一部分。
2. 普通开发者为什么要关心这个变化?
很多开发者第一次用 AI 写代码时,会经历两个阶段。
第一阶段:觉得很爽。“这段代码它居然秒写出来了。”“这个报错它居然看懂了。”
第二阶段:开始怀疑。“它写得对吗?”“这个边界条件是不是漏了?”“它改了这里,会不会影响别的模块?”“它生成的代码看着能跑,但我敢合并吗?”
问题就出在这里。
AI 生成代码不难,难的是让这段代码进入真实项目。真实项目里有历史包袱、有业务规则、有隐性约束、有老接口、有权限逻辑,还有一堆“不能动但没人写进文档”的坑。
所以,开发者关心 AI 编程工具,不应该只看它能不能生成代码,而要看它能不能被放进一个安全的流程里。输入是否明确、输出是否可检查、测试是否能覆盖、影响范围是否能判断、人工复核是否方便、生成内容是否能沉淀成团队经验,这些都比“生成得快不快”更重要。
3. 最容易被误解的一点:AI 写得快,不等于开发效率高
很多人对 AI 编程工具有一个误判:只要它生成代码快,就说明效率提升了。
这个判断太粗了。开发效率不是从“开始写代码”到“代码生成完成”这一小段时间决定的,而是从需求理解到上线稳定运行的完整链路决定的。
举个例子。一个后端开发者接到需求:“订单取消后,如果用户已使用优惠券,需要恢复优惠券状态;如果订单部分退款,不恢复;如果订单全额退款,根据业务标记判断是否恢复。”
你让 AI 生成一个处理函数,它可能很快给你一段代码:
def restore_coupon_after_order_cancel(order):
if order.status == "cancelled" and order.coupon_id:
coupon = get_coupon(order.coupon_id)
coupon.status = "available"
coupon.save()
return True
return False
看起来很清楚,但真实业务里可能马上出问题:
- 订单取消和订单退款是不是同一个事件?
- 部分退款是否触发优惠券恢复?
- 已过期优惠券是否允许恢复?
- 同一订单重复回调会不会重复恢复?
- 优惠券状态更新是否需要事务?
- 是否要写操作日志?
- 是否影响营销系统统计?
- 是否要兼容旧订单数据?
这就是 AI 编程的典型风险:它能快速给出“像代码的代码”,但不一定理解你项目里的真实约束。真正的效率提升,来自“少返工、少误改、少漏测、少线上事故”。
4. 一个更合理的 AI 编程工作流
如果要把 Codex 类工具接进日常开发,我更建议把流程拆成 5 步,而不是直接让 AI 写完整代码。
第一步:让 AI 帮你复述需求
不要一上来就说“帮我写代码”。先让它复述需求,拆出业务条件和边界。
你现在是一个后端开发助手。
请先不要写代码。
请根据下面需求,帮我拆解:
1. 业务目标是什么;
2. 涉及哪些状态;
3. 可能有哪些边界条件;
4. 哪些地方需要我向产品或后端负责人确认;
5. 哪些逻辑不能直接假设。
需求:
订单取消后,需要根据优惠券使用情况恢复优惠券状态。
如果订单部分退款,不恢复优惠券。
如果订单全额退款,需要根据订单上的 coupon_restore_flag 判断是否恢复。
这一步的价值不是生成代码,而是避免“需求还没想清楚,代码已经写完了”。
第二步:让 AI 生成伪代码,不要马上生成正式代码
请根据上面的业务条件,先生成伪代码,不要写具体语言实现。
要求:
1. 明确每个判断分支;
2. 标注需要事务控制的位置;
3. 标注需要幂等校验的位置;
4. 标注需要日志记录的位置;
5. 不要假设数据库结构。
可能得到这样的伪代码:
function handle_coupon_restore(order_event):
validate event type
if event already processed:
return success
load order by order_id
if order has no coupon:
record log
return success
if event type is partial_refund:
record log: no restore
return success
if event type is full_refund:
if coupon_restore_flag is not true:
record log: flag disabled
return success
if event type is cancelled:
continue restore logic
begin transaction:
lock coupon record
if coupon already available:
record idempotent log
commit
return success
if coupon expired:
record log
commit
return success
update coupon status to available
write operation log
mark event processed
commit
return success
伪代码比直接生成 Python、Java 或 Go 代码更有价值,因为它暴露的是业务逻辑,而不是语法细节。
第三步:再让 AI 生成具体代码,但必须限定边界
请基于刚才确认过的伪代码,生成 Python 版本实现。
限制条件:
1. 不要编造数据库字段;
2. 未知字段用 TODO 注释标记;
3. 每个关键分支必须写注释;
4. 必须包含幂等处理;
5. 必须包含异常日志;
6. 不要引入我没有说明的第三方库。
代码示例:
def handle_coupon_restore(order_event, order_repo, coupon_repo, event_repo, logger):
event_id = order_event.get("event_id")
order_id = order_event.get("order_id")
event_type = order_event.get("event_type")
if event_repo.exists(event_id):
logger.info("event already processed", extra={"event_id": event_id})
return {"success": True, "reason": "idempotent"}
order = order_repo.get_by_id(order_id)
if not order:
logger.warning("order not found", extra={"order_id": order_id})
return {"success": False, "reason": "order_not_found"}
coupon_id = getattr(order, "coupon_id", None)
if not coupon_id:
event_repo.mark_processed(event_id)
return {"success": True, "reason": "no_coupon"}
if event_type == "partial_refund":
event_repo.mark_processed(event_id)
return {"success": True, "reason": "partial_refund_no_restore"}
if event_type == "full_refund":
restore_flag = getattr(order, "coupon_restore_flag", None)
if restore_flag is not True:
event_repo.mark_processed(event_id)
return {"success": True, "reason": "restore_flag_disabled"}
if event_type not in ["cancelled", "full_refund"]:
event_repo.mark_processed(event_id)
return {"success": True, "reason": "event_not_supported"}
try:
with coupon_repo.transaction():
coupon = coupon_repo.get_for_update(coupon_id)
if not coupon:
logger.warning("coupon not found", extra={"coupon_id": coupon_id})
event_repo.mark_processed(event_id)
return {"success": False, "reason": "coupon_not_found"}
if coupon.status == "available":
event_repo.mark_processed(event_id)
return {"success": True, "reason": "coupon_already_available"}
if coupon.is_expired():
event_repo.mark_processed(event_id)
return {"success": True, "reason": "coupon_expired"}
coupon.status = "available"
coupon_repo.save(coupon)
event_repo.mark_processed(event_id)
return {"success": True, "reason": "coupon_restored"}
except Exception as exc:
logger.exception("restore coupon failed")
return {"success": False, "reason": "restore_failed", "error": str(exc)}
这段代码不是让你直接复制上线,而是说明一个原则:AI 生成代码时,你要把“不能做什么”也写清楚。
5. 用测试用例约束 AI,而不是只靠感觉判断
AI 写完代码后,很多人只看一眼,觉得“差不多”,然后就手动改。这其实很危险。更好的方式是:让 AI 先列测试用例,再补测试代码。
请根据当前优惠券恢复逻辑,列出测试用例表。
要求:
1. 覆盖正常路径;
2. 覆盖异常路径;
3. 覆盖边界条件;
4. 覆盖重复回调;
5. 用表格输出:用例名称、输入条件、预期结果、风险点。
| 用例名称 | 输入条件 | 预期结果 | 风险点 |
|---|---|---|---|
| 订单取消且使用优惠券 | event_type=cancelled,coupon_id 存在 | 优惠券恢复为 available | 是否需要事务 |
| 部分退款 | event_type=partial_refund | 不恢复优惠券 | 避免误恢复 |
| 全额退款且允许恢复 | event_type=full_refund,coupon_restore_flag=true | 恢复优惠券 | 字段缺失兼容 |
| 全额退款但不允许恢复 | coupon_restore_flag=false | 不恢复 | 业务规则误判 |
| 老订单字段缺失 | coupon_restore_flag=None | 不直接恢复,按规则处理 | 兼容旧数据 |
| 重复回调 | event_id 已处理 | 直接返回成功 | 幂等问题 |
| 优惠券已过期 | coupon.is_expired=true | 不恢复 | 过期券误恢复 |
| 优惠券已恢复 | coupon.status=available | 不重复更新 | 状态污染 |
| 优惠券不存在 | coupon_id 无对应记录 | 返回失败或记录日志 | 数据异常处理 |
因为 AI 编程最容易出现的问题,不是“写不出代码”,而是“测试覆盖不够”。
6. 判断一个 AI 编程助手能否长期使用,看这 5 个标准
任务覆盖率
它能覆盖你每天多少真实任务?不是“理论上能做什么”,而是你每天实际会不会用到。
上下文能力
开发不是单文件游戏。一个真实问题往往涉及 controller、service、repository、database schema、cache、mq、config、log、test、deployment。
输出可控性
AI 输出不是越多越好。可用的 AI 编程助手,应该允许你控制输出形式:只输出思路、只输出伪代码、只输出差异修改、只输出测试用例、不改动指定文件、不引入第三方库。
人工复核成本
判断 AI 是否提升效率,不要只看生成速度,要看复核成本。
真实效率提升 = 原本完成任务时间 -(AI 生成时间 + 人工复核时间 + 返工时间)
团队协作适配度
个人用 AI 和团队用 AI 是两件事。团队里要考虑 Prompt 是否能复用、代码风格是否一致、生成代码是否符合规范、是否能留下审查记录、是否能接入 CI、是否符合安全要求。
7. 结论:AI 编程工具不是越强越好,而是越可控越有价值
Codex 类工具继续升温,说明 AI 编程已经不再是小众尝鲜。但开发者真正要关心的,不是谁生成代码最快。
真正值得长期使用的 AI 编程助手,至少要满足三个条件:
第一,它能进入你的真实任务,而不是只能玩 demo。
第二,它生成的结果可复核、可测试、可追踪。
第三,它能减少返工,而不是制造更多隐藏风险。
如果你只是偶尔查语法、解释报错,免费工具或轻量用法可能就够了。如果你每天都要处理固定开发任务,尤其是测试、重构、文档、bug 定位、接口逻辑这类重复度较高的工作,才值得认真搭建一套 AI 辅助开发流程。
最后补一句偏实用的:如果你已经确定自己确实会长期用 ChatGPT Plus 或 Codex 类能力参与开发,再去考虑账号、周期、套餐和异常处理这些问题;像 gpt985 这类入口,更适合放在开通前做信息核对参考,而不是在还没想清楚使用场景时就先处理 ChatGPT Plus。先确认工作流,再确认工具和账号,这个顺序别反了。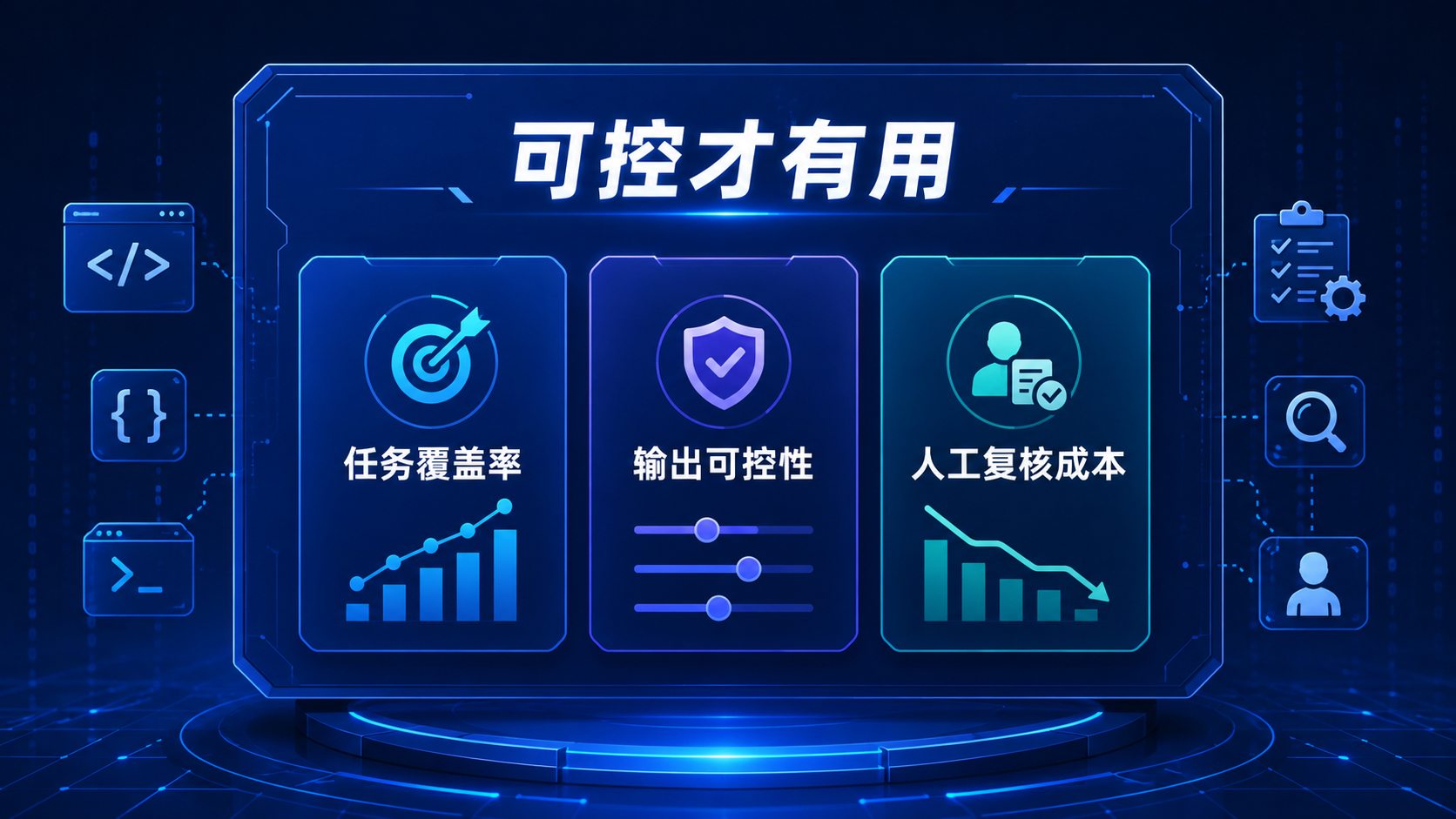

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)