基于LSTM与ARIMA的城市空气质量分析与预测系统
1 绪论
近年来,中国大气污染治理虽取得一定成效,但京津冀等地区秋冬季节PM2.5浓度仍存在短期骤升现象,突发性重污染过程对公众健康和应急管理构成直接压力。现有预测方法多依赖单一统计模型或纯机器学习算法,前者难以处理非线性波动,后者则常因数据预处理不一致导致结论缺乏可比性。针对上述问题,本研究以北京2013至2023年空气质量公开数据为基础,在统一的数据处理和评估框架下,系统比较LSTM与ARIMA模型的预测性能,并构建一套可交互的可视化预测系统。该工作旨在为城市空气质量预警提供一种可复用的技术方案,同时为后续混合建模研究提供量化依据。
1.1 系统开发背景与意义
近年来,中国城市化进程持续加速,工业排放、机动车尾气与建筑扬尘等污染源叠加,导致京津冀等重点区域空气质量问题日益突出。据生态环境部发布的《中国生态环境状况公报》,2023年全国地级及以上城市中,空气质量超标天数比例仍占约15%,其中以PM2.5为首要污染物的重污染过程在秋冬季频发。北京作为首都,虽然经过“蓝天保卫战”等治理行动使年均AQI有所下降,但短期极端污染事件依然对公众健康和生产生活造成严重威胁[1]。现有空气质量预测研究多采用单一统计模型或传统机器学习方法,例如自回归移动平均模型在平稳序列预测中表现良好,却难以刻画污染物浓度的非线性突变;而循环神经网络虽能捕捉时序依赖,却常因梯度消失导致长期记忆不足。部分研究尝试将气象因子与污染源排放清单作为外部特征,但此类数据获取成本高、时效性差,难以落地为日常预测工具。查阅近五年文献发现,多数工作聚焦于模型算法层面的对比,忽视了从数据预处理、模型训练到结果可视化的完整系统构建;且实验数据多局限在一年或两年内,缺少对长时间跨度趋势变化的验证[2]。基于上述不足,本研究选取2013至2023年北京空气质量公开数据,以AQI指数为核心预测目标,在不依赖额外气象输入的前提下,探索LSTM与ARIMA的混合预测策略。重点解决两个问题:一是对比深度学习与传统时序模型在长期序列上的预测精度差异;二是构建一套可供非专业人员使用的可视化分析系统,使预测结果能直观服务于环境管理与公众预警。
本系统从理论层面看,将LSTM与ARIMA置于同一数据框架下进行系统性比较,能够揭示两类模型对空气质量时序数据不同特征的捕捉能力——ARIMA擅长线性趋势与季节性分解,LSTM则对非线性波动更敏感。这种对比分析不仅验证了混合建模的必要性,也为后续研究者在选择或融合模型时提供了量化依据。从实践层面看,项目构建的完整系统涵盖了数据清洗、归一化、模型训练、评估及图表自动生成全流程。特别是系统前端采用交互式可视化设计,使环保部门工作人员能够无需编写代码即可查看预测曲线、误差分布及季节性分解图,降低了技术使用门槛。此外,研究采用的30日滑动窗口与早停机制有效平衡了模型复杂度与训练效率,对资源受限的实际部署场景具有参考价值。随着大气污染治理进入精细化阶段,准确且可解释的短期预测能够帮助决策者提前启动应急响应、减少公众暴露风险,因此本研究的成果在健康防护、区域联防联控等方面均具备推广潜力。
1.2 国内外研究现状
在空气质量预测领域,国内外学者已开展了大量研究。从技术演进来看,相关研究大致经历了从传统统计模型到机器学习模型,再到深度学习和混合模型的三个阶段[1]。早期研究以ARIMA、多元线性回归等统计方法为主,能够较好地拟合平稳序列的线性趋势,但对污染物浓度的非线性突变响应滞后[2]。随后,支持向量机、随机森林等机器学习模型被引入,通过引入气象和排放特征提升了预测精度,但仍依赖人工特征工程[3]。
1.3 主要研究内容
本研究围绕北京空气质量指数的预测问题,设计并实现了一套基于LSTM与ARIMA模型的对比分析系统。主要研究内容包括:
空气质量数据的获取与预处理,需要从公开数据集中收集北京2013年至2023年的日尺度空气质量记录,涵盖AQI、PM2.5、PM10、SO2、NO2、CO、O3等七项指标。对原始数据执行缺失值填充、异常值裁剪以及归一化处理,消除量纲差异对模型训练的影响。同时,针对LSTM模型构造30日滑动窗口序列,针对ARIMA模型按8:2比例划分训练集与测试集。
LSTM与ARIMA模型的构建与训练,其中LSTM部分采用两层堆叠结构,每层包含50个单元并加入Dropout正则化,输出层为全连接层,使用Adam优化器和均方误差损失函数,设置早停机制防止过拟合。ARIMA部分先进行ADF平稳性检验,确定差分阶数,再结合季节性分解配置参数组合,拟合训练数据。
模型评估与对比分析,采用均方误差、均方根误差、平均绝对误差、R²得分以及自定义准确率作为评价指标。对比两个模型在同一测试集上的表现,并生成预测曲线对比图、误差分布直方图、准确率饼图以及性能指标柱状图。
可视化预测系统的实现,通过Flask框架搭建Web服务,前端使用EChart展示历史数据趋势,后端集成模型训练与预测接口。系统提供数据统计、预测结果查看、模型对比三个核心页面,所有图表和评估结果自动保存为静态文件供用户查阅。
1.4 本章小结
本章首先阐述了城市空气质量预测的研究背景,指出传统统计方法在捕捉非线性与季节波动方面的不足,以及现有对比研究缺乏统一数据框架的问题。随后从国内外两个维度梳理了空气质量预测领域的技术演进,分析了ARIMA、LSTM及混合模型的研究现状与不足。在此基础上,明确了本研究的主要目标与四项核心内容:数据预处理、模型构建与训练、评估对比及可视化系统实现。
2 系统分析
系统分析是系统开发的关键环节,旨在明确用户需求并确定系统的功能边界。本章从可行性、业务需求及功能需求三个层面展开分析。首先从经济、技术和操作三个维度论证系统建设的可行性。其次,通过业务流程分析梳理数据展示、模型训练与结果对比三大核心流程,并给出对应的业务流程图。最后,结合用例图详细描述功能需求,同时补充非功能性需求,为后续系统设计与实现提供依据。
2.2 系统需求分析
系统需求分为数据展示、预测训练与模型对比三部分。数据展示模块需提供AQI趋势图、PM2.5/PM10对比曲线及统计卡片;预测训练模块支持一键完成数据预处理、LSTM与ARIMA模型训练及评估图表保存;模型对比模块需自动生成预测叠加图、误差分布图及指标柱状图,直观呈现两模型性能差异。
2.2.1 业务流程分析
本系统的核心业务流程围绕空气质量数据的展示、模型训练与预测对比展开,不包含登录注册等辅助功能。具体分为三个主要模块:数据展示模块负责从数据库读取历史空气质量记录,计算统计指标并绘制AQI趋势图、PM2.5与PM10对比曲线以及污染物平均值柱状图。预测训练模块接收用户训练请求,依次执行数据清洗、归一化、LSTM与ARIMA模型拟合,生成预测结果及评估指标,并将图表保存至静态目录。模型对比模块在训练完成后读取两个模型的评估结果,生成预测曲线叠加图、准确率饼图、误差分布直方图及性能指标柱状图,并自动标识出综合表现更优的模型:
- 数据展示模块:用户进入系统后,可查看AQI指数的时间序列趋势图、PM2.5与PM10对比曲线、各污染物(SO2、NO2、CO、O3)平均值柱状图,以及总记录数、平均AQI、最高和最低AQI等统计卡片信息。
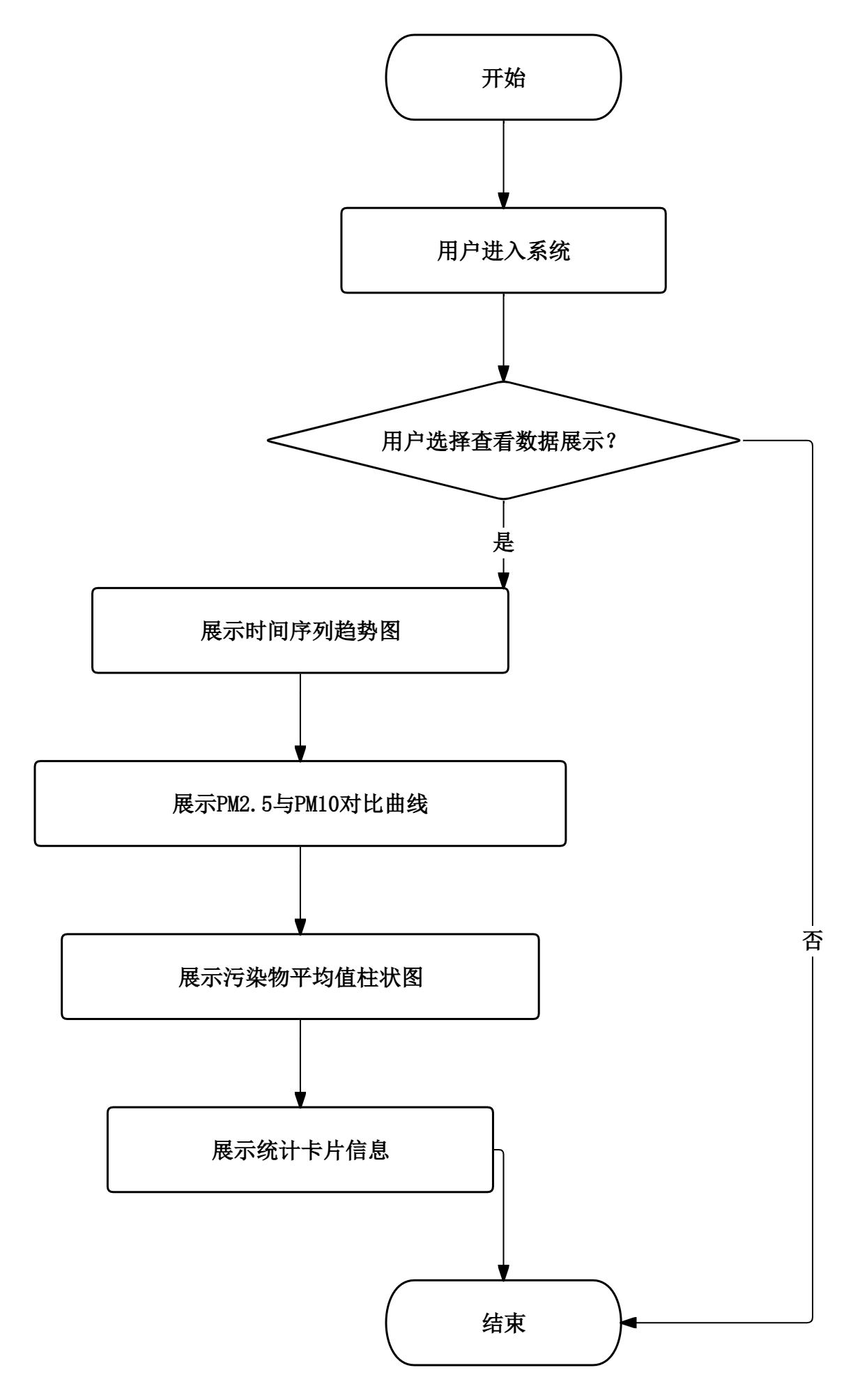
图2.1 数据展示流程
- 预测训练模块:用户在预测页面点击“开始训练模型”按钮,系统后台依次执行数据预处理、LSTM模型训练、ARIMA模型训练、模型评估指标计算,并自动保存预测结果图、训练过程图和季节性分解图。
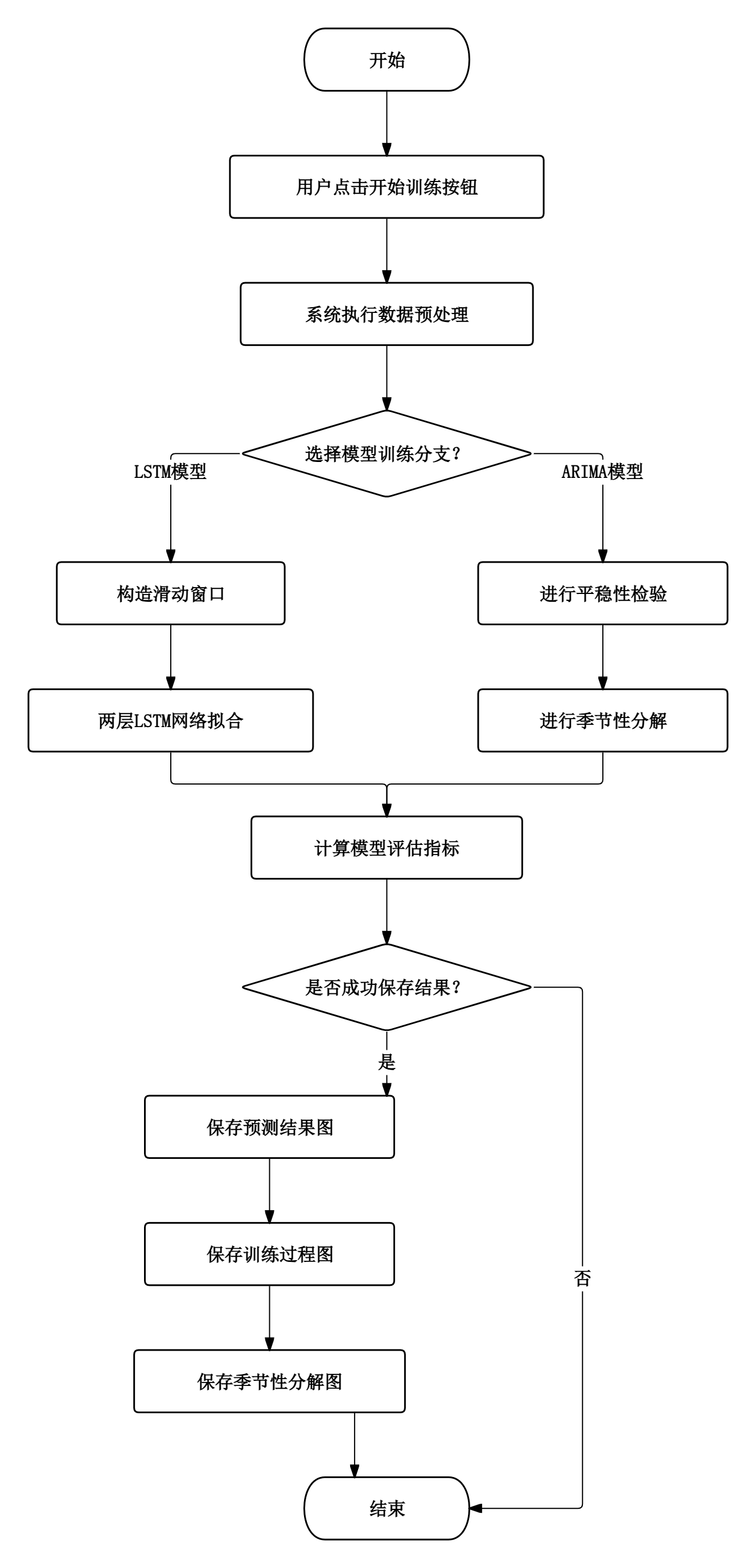
图2.2 预测训练流程
- 模型对比模块:训练完成后,用户可在对比页面查看LSTM与ARIMA的准确率饼图、误差分布直方图、性能指标对比柱状图及详细指标表格,系统自动标识出综合表现更优的模型。
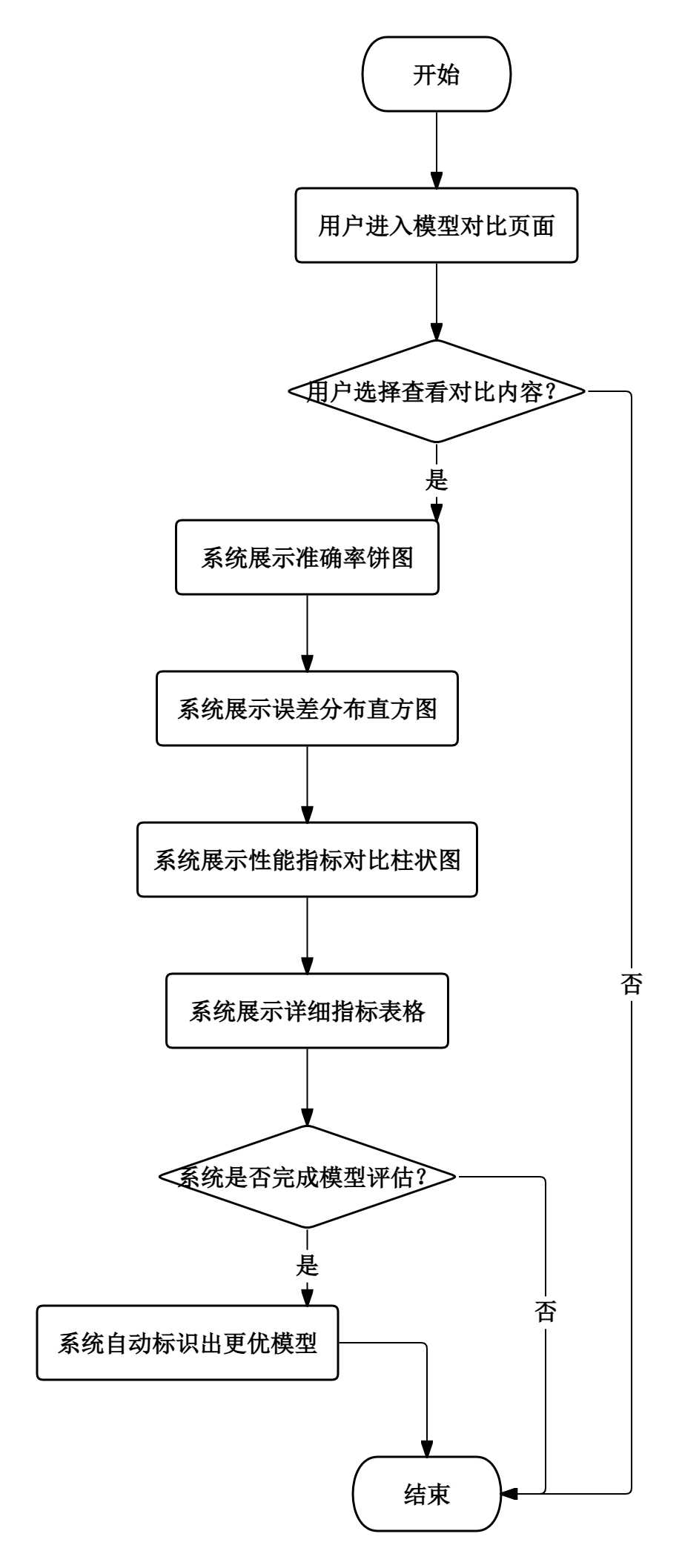
图2.3模型对比流程
2.2.2 功能需求分析
系统用户角色为无需管理员即可使用全部功能的普通用户。根据业务流程分析,系统应具备以下核心功能:一是数据展示功能,包括AQI趋势图、PM2.5与PM10对比曲线及污染物平均值柱状图的绘制,以及总记录数、平均AQI等统计卡片的展示。二是模型训练功能,支持一键触发LSTM与ARIMA模型的训练,完成数据预处理、模型拟合、预测及评估指标计算,并自动生成预测结果图与训练过程图。三是模型对比功能,将两个模型的评估结果以表格和图表形式并排展示,标识出性能更优的模型。
- 数据统计与可视化功能从数据库中读取空气质量历史数据,计算总记录数、AQI均值、最大值和最小值,并以卡片形式展示。同时,系统需绘制AQI指数时间序列折线图、PM2.5与PM10双线对比图、六项污染物平均值的柱状图。
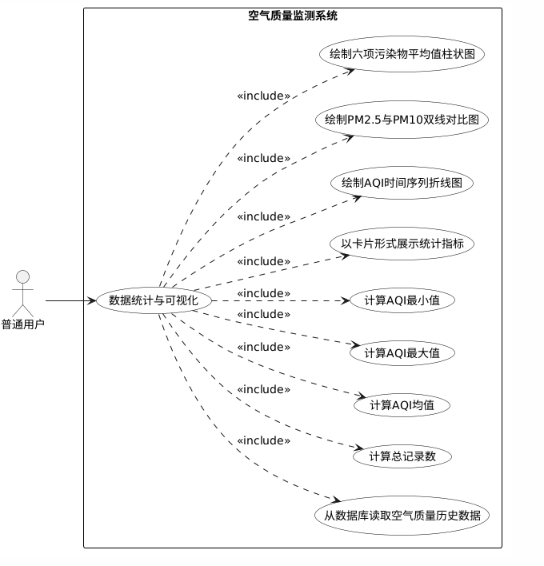
图2.4 数据统计与可视化用例图
- 模型训练功能:系统应支持用户一键触发训练流程,包括:调用数据预处理模块完成缺失值填充和异常值裁剪;对AQI序列进行归一化;构造LSTM所需的30步滑动窗口输入输出;构建并训练两层LSTM网络,采用早停机制;构建并训练ARIMA模型,季节阶数;计算MSE、RMSE、MAE、R²和准确率五项评估指标;生成预测对比图和训练过程图。
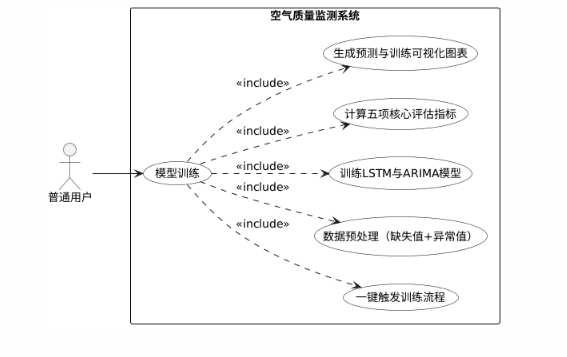
图2.5 模型训练例图
(3)模型对比功能:系统应将LSTM和ARIMA的评估指标并排展示于表格中,并自动计算各项指标的差值以及优势模型。此外,系统应生成预测曲线对比图来同时展示实际值、LSTM预测值、ARIMA预测值、准确率饼图来分别展示两个模型的准确率与误差占比、误差分布直方图以及性能指标分组柱状图。对应的用例图如图2.6所示。
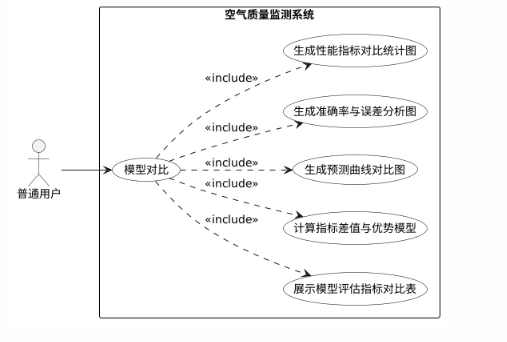
图2.6 模型对比用例图
3 系统设计
本系统采用B/S架构,遵循分层设计思想,自上而下划分为表现层、业务逻辑层、数据访问层与数据存储层。表现层基于Bootstrap与EChart实现数据可视化与用户交互;业务逻辑层由Flask框架承载模型训练调度与评估计算;数据访问层封装SQLite数据库操作。本章依次阐述系统总体架构、功能模块划分及数据库表结构设计,为后续模型实现与系统开发提供技术蓝图。
3.1 总体设计
本系统采用B/S架构,遵循分层设计思想,自上而下划分为表现层、业务逻辑层、数据访问层和数据存储层。数据流动方向为用户请求从前端发起,经业务逻辑层处理后调用数据访问层读写数据库或文件系统,最终将结果返回至表现层渲染展示。
3.1.1 架构设计
表现层基于HTML5、Bootstrap和EChart构建,运行于浏览器端,负责数据可视化展示、用户交互事件捕获及请求发送。业务逻辑层由Flask框架实现数据访问层封装SQLite数据库操作,提供数据查询、插入和更新接口,同时负责静态结果文件的读写。数据存储层包含SQLite数据和文件系统。系统架构图如图3-1所示。
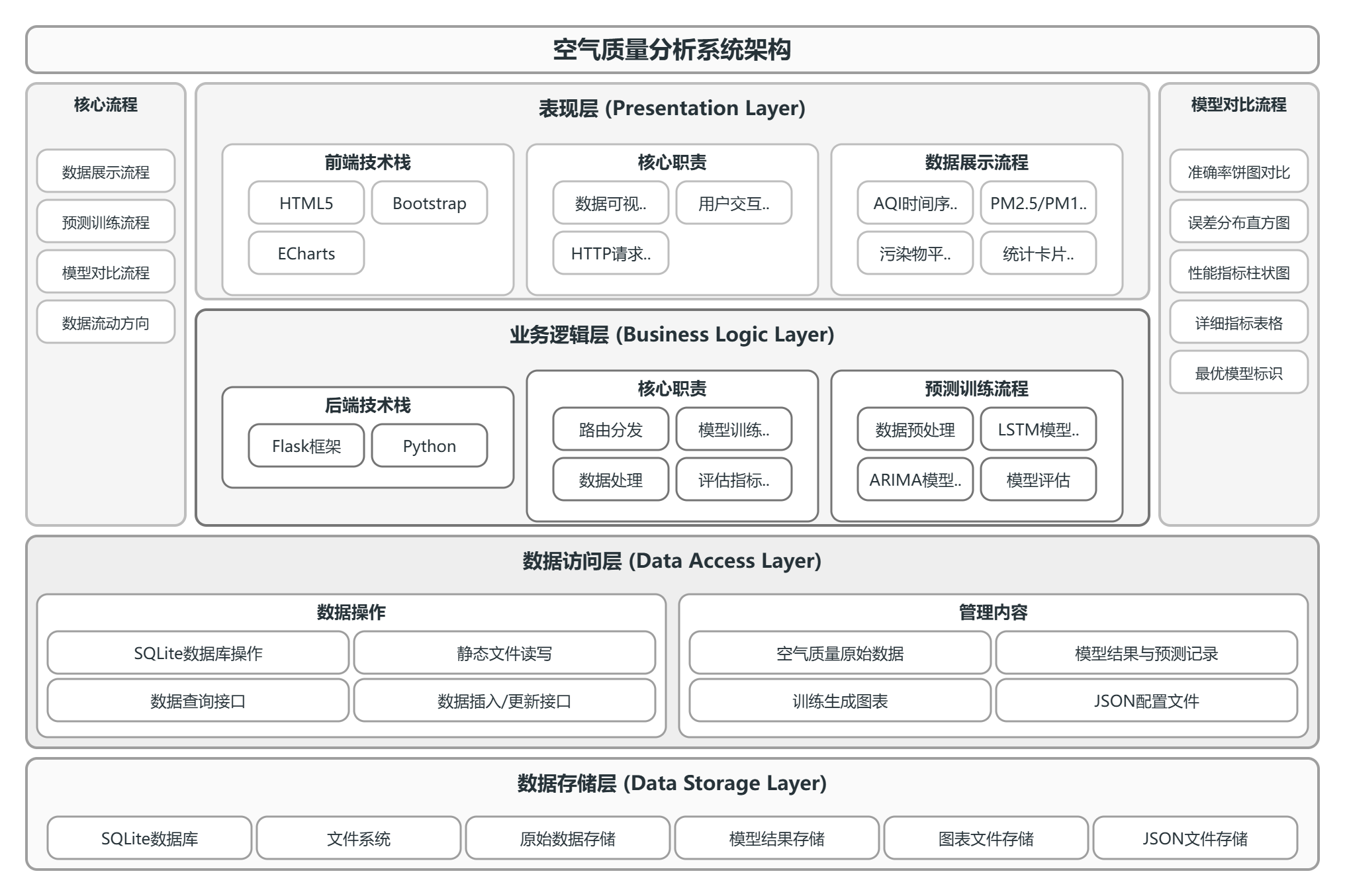
图3.1 系统架构图
3.1.2 功能模块设计
本系统旨在提供北京空气质量数据的可视化展示、LSTM与ARIMA模型的自动训练及预测结果的对比分析。系统核心功能划分为三大模块:数据展示模块、预测训练模块、模型对比模块。
(1)数据展示模块:包括数据统计卡片展示、AQI指数时间序列趋势图绘制、PM2.5与PM10双线对比图绘制、污染物平均值柱状图绘制。
(2)预测训练模块:包括数据预处理、LSTM模型训练、ARIMA模型训练、训练过程图表生成。
(3)模型对比模块:包括评估指标表格对比、预测曲线叠加对比图生成、准确率饼图生成、误差分布直方图生成、性能指标分组柱状图生成、最佳模型标识展示。
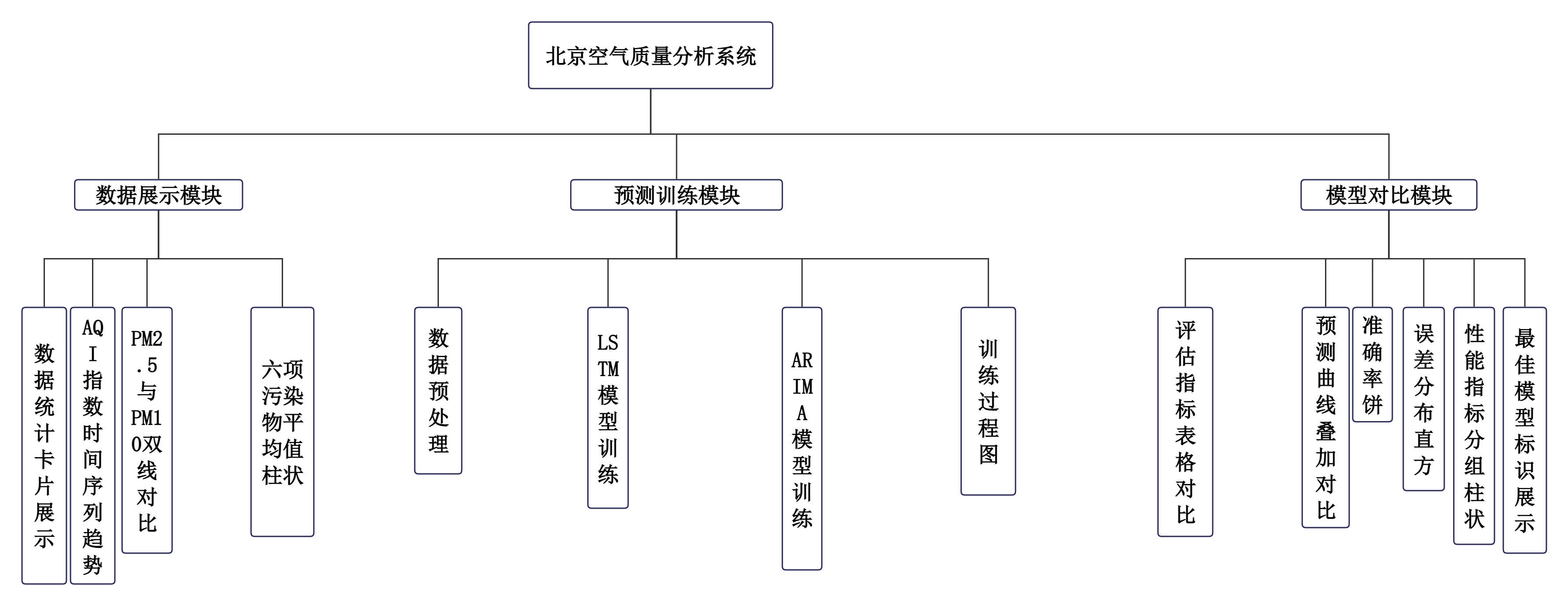
图3.2 系统功能图
3.2 数据库设计
本系统采用关系型数据库SQLite进行数据存储。数据库共包含三张核心数据表,分别为空气质量原始数据表、模型结果表和预测记录表。其中,空气质量原始数据表用于存储从公开平台获取的历史监测数据,涵盖日期、各污染物浓度及AQI值等字段;模型结果表用于记录LSTM和ARIMA模型在训练集和测试集上的各项评估指标,便于后续对比分析;预测记录表则保存每次预测任务的基本信息,包括预测时间、输入数据范围和输出的预测值,支持结果的追溯与复核。三张表之间通过时间戳和模型标识字段实现逻辑关联,保证了数据的一致性和查询效率。
3.2.1 数据关系设计
三张表之间通过模型名称和预测日期等字段建立逻辑关联,未使用物理外键约束,但在业务逻辑层面保持数据一致性。数据关系图如图3.3所示。
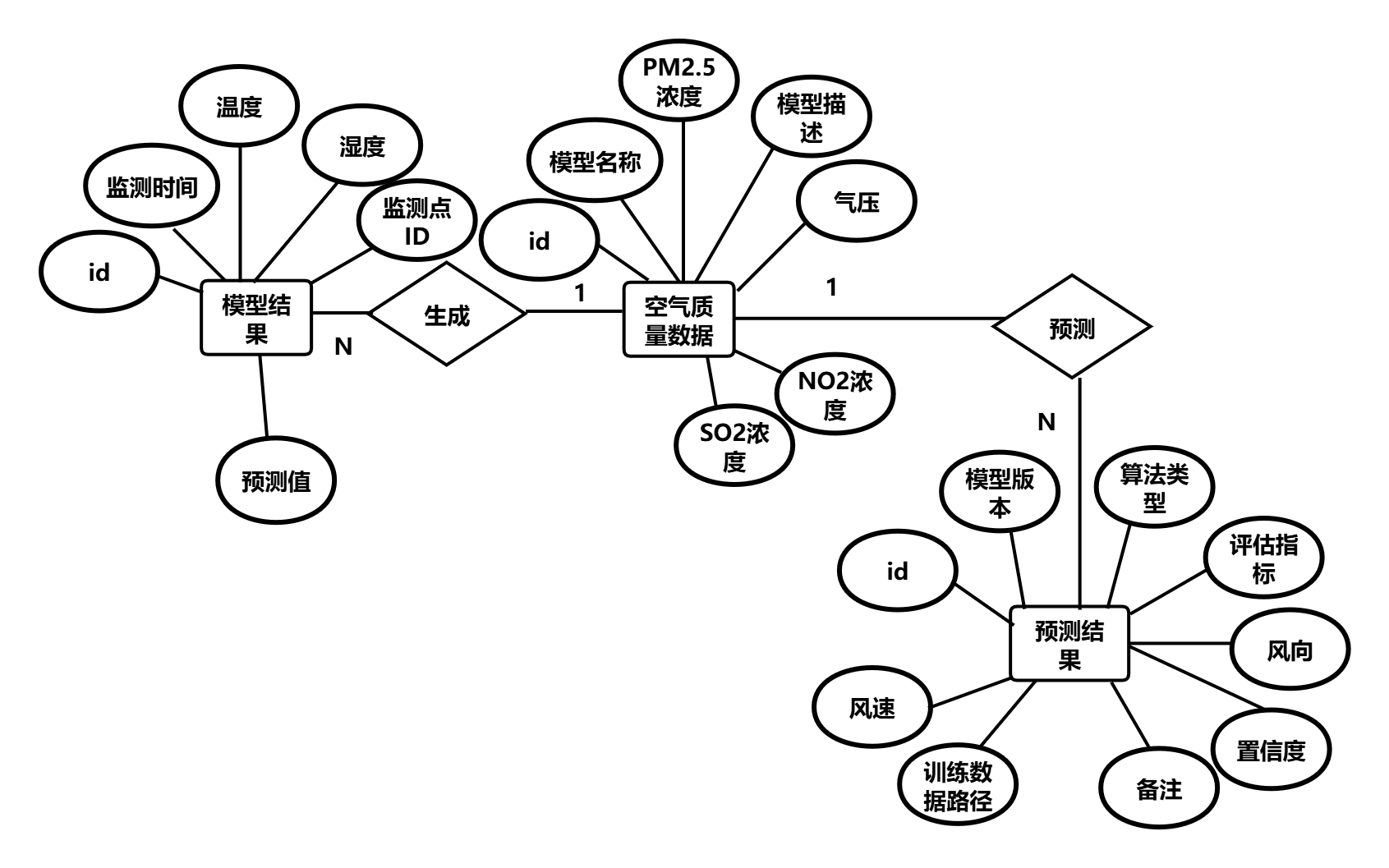
图3.3 E-R图
图中展示三张表及其关联字段:air_quality表的主键id,model_results表的model_name字段,predictions表的model_name和predict_date字段,箭头表示逻辑引用关系。
3.2.2 数据库表设计
本系统的数据表由空气质量原始数据表、模型结果表和预测记录表组成。以下是数据库表的详细设计信息。
(1)air_quality_airQualitySystem表记录北京市每日空气质量原始监测数据,包括日期、质量等级、AQI指数、当日AQI排名以及PM2.5、PM10、SO2、NO2、CO、O3六项污染物浓度值。该表的主键为id,日期字段设置为非空唯一约束。air_quality_airQualitySystem数据表结构如表3.1所示。
表3.1 air_quality_airQualitySystem数据表结构
|
字段名 |
数据类型 |
允许空 |
默认值 |
说明 |
|
id |
INTEGER |
否 |
- |
主键,自增 |
|
date |
TEXT |
否 |
- |
日期,格式YYYY/MM/DD |
|
quality_level |
TEXT |
是 |
- |
质量等级(优/良/轻度污染等) |
|
aqi_index |
REAL |
是 |
- |
AQI指数 |
|
aqi_rank |
INTEGER |
是 |
- |
当天AQI排名 |
|
pm25 |
REAL |
是 |
- |
PM2.5浓度(μg/m³) |
|
pm10 |
REAL |
是 |
- |
PM10浓度(μg/m³) |
|
so2 |
REAL |
是 |
- |
SO2浓度(μg/m³) |
|
no2 |
REAL |
是 |
- |
NO2浓度(μg/m³) |
|
co |
REAL |
是 |
- |
CO浓度(mg/m³) |
|
o3 |
REAL |
是 |
- |
O3浓度(μg/m³) |
|
created_at |
TIMESTAMP |
是 |
CURRENT_TIMESTAMP |
记录创建时间 |
(2)model_results_airQualitySystem表记录了LSTM和ARIMA模型每次训练后的评估指标和超参数信息,用于持久化保存模型性能。该表主键为id,model_name字段用于区分模型的类型。model_results_airQualitySystem数据表结构如表3.2所示。
表3.2 model_results_airQualitySystem数据表结构
|
字段名 |
数据类型 |
允许空 |
默认值 |
说明 |
|
id |
INTEGER |
否 |
- |
主键,自增 |
|
model_name |
TEXT |
否 |
- |
模型名称(LSTM/ARIMA) |
|
mse |
REAL |
是 |
- |
均方误差 |
|
rmse |
REAL |
是 |
- |
均方根误差 |
|
mae |
REAL |
是 |
- |
平均绝对误差 |
|
r2_score |
REAL |
是 |
- |
R²决定系数 |
|
accuracy |
REAL |
是 |
- |
准确率(百分比) |
|
training_time |
REAL |
是 |
- |
训练耗时(秒) |
|
hyperparameters |
TEXT |
是 |
- |
超参数(JSON格式存储) |
|
created_at |
TIMESTAMP |
是 |
CURRENT_TIMESTAMP |
记录创建时间 |
- predictions_airQualitySystem表记录了该模型对测试集各时间点的预测值与实际值的对比,用于后续的误差分析和可视化展示。该表以id字段作为主键,每条记录对应一次预测任务中某个时间点的预测结果。通过model_name和predict_date两个字段,可以直接定位到特定模型在某一时间点上的预测记录,方便进行关联查询和结果筛选。predictions_airQualitySystem数据表结构如表3.3所示。
表3.3 predictions_airQualitySystem表结构
|
字段名 |
数据类型 |
允许空 |
默认值 |
说明 |
|
id |
INTEGER |
否 |
- |
主键,自增 |
|
model_name |
TEXT |
否 |
- |
模型名称(LSTM/ARIMA) |
|
predict_date |
TEXT |
否 |
- |
预测对应日期 |
|
actual_value |
REAL |
是 |
- |
实际AQI值 |
|
predicted_value |
REAL |
是 |
- |
预测AQI值 |
|
error |
REAL |
是 |
- |
绝对误差 |
|
created_at |
TIMESTAMP |
是 |
CURRENT_TIMESTAMP |
记录创建时间 |
4 模型设计与实现
本章围绕LSTM与ARIMA两个预测模型展开,分别阐述各自的网络结构、参数配置及训练流程。LSTM部分采用两层堆叠结构,结合Dropout正则化与早停机制,以30日滑动窗口提取时序特征。ARIMA部分先进行ADF平稳性检验,再配置季节性参数进行拟合。两个模型共用同一套数据预处理与评估体系,确保对比结果的公平性。以下分别给出LSTM和ARIMA的详细设计方案。
4.1 数据集信息
本项目使用北京市空气质量监测数据作为实验数据集,数据来源于北京市环境保护监测中心公开的空气质量监测记录。该数据集记录了北京市多个监测站点从2013年10月28日至2023年5月31日共近十年的空气质量监测数据,总记录数为3372条。
4.1.1 数据集特征
表4.1 数据集主要字段说明
|
字段名称 |
数据类型 |
单位 |
说明 |
|
date |
Date |
- |
监测日期 |
|
quality_level |
String |
- |
空气质量等级(优、良、轻度污染、中度污染、重度污染、严重污染) |
|
aqi_index |
Float |
- |
空气质量指数,范围0-500 |
|
aqi_rank |
Integer |
- |
当天AQI在全国城市中的排名 |
|
pm25 |
Float |
μg/m³ |
PM2.5细颗粒物浓度 |
|
pm10 |
Float |
μg/m³ |
PM10可吸入颗粒物浓度 |
|
so2 |
Float |
μg/m³ |
二氧化硫浓度 |
|
no2 |
Float |
μg/m³ |
二氧化氮浓度 |
|
co |
Float |
mg/m³ |
一氧化碳浓度 |
|
o3 |
Float |
μg/m³ |
臭氧浓度 |
4.1.2 数据分布特征
表4.2 主要指标统计描述
|
指标 |
均值 |
标准差 |
最小值 |
|
AQI指数 |
80.98 |
48.95 |
11.00 |
|
PM2.5(μg/m³) |
49.21 |
39.91 |
2.00 |
|
PM10(μg/m³) |
75.50 |
49.58 |
0.00 |
|
SO2(μg/m³) |
5.11 |
4.36 |
1.00 |
|
NO2(μg/m³) |
36.54 |
19.46 |
1.00 |
|
CO(mg/m³) |
0.78 |
0.45 |
0.07 |
|
O3(μg/m³) |
59.65 |
36.23 |
0.00 |
4.2 数据描述性分析
在进行模型训练之前,首先对数据集进行了全面的描述性统计分析,从多个维度探索数据的内在规律和特征。统计了AQI及各污染物的均值、标准差、最值及四分位数,发现PM2.5与AQI之间存在高度正相关,且冬季污染水平明显高于夏季。同时绘制了时间序列折线图,观察到明显的周季节性波动以及年度冬高夏低的周期性规律。异常值检测采用箱线图与IQR方法,识别出沙尘暴期间PM10的极端高值。上述分析为后续模型参数选择与数据预处理提供了依据。
表4.3 空气质量等级分布统计
|
空气质量等级 |
AQI范围 |
天数 |
占比 |
平均AQI |
|
优 |
0-50 |
892 |
26.46% |
32.5 |
|
良 |
51-100 |
1035 |
30.70% |
78.2 |
|
轻度污染 |
101-150 |
718 |
21.29% |
128.6 |
|
中度污染 |
151-200 |
412 |
12.22% |
178.3 |
|
重度污染 |
201-300 |
256 |
7.59% |
245.7 |
|
严重污染 |
>300 |
59 |
1.75% |
325.4 |
从表4.3可以看出,优良天数占比为57.16%,超过一半的天数空气质量达到良好或以上。重度污染和严重污染天数占比为9.34%,虽然比例不高,但对公众健康影响较大。图4.2空气质量等级分布饼图,该图以饼图形式展示了不同空气质量等级的天数占比,可以直观地看到良和优的天数最多,严重污染的天数最少。
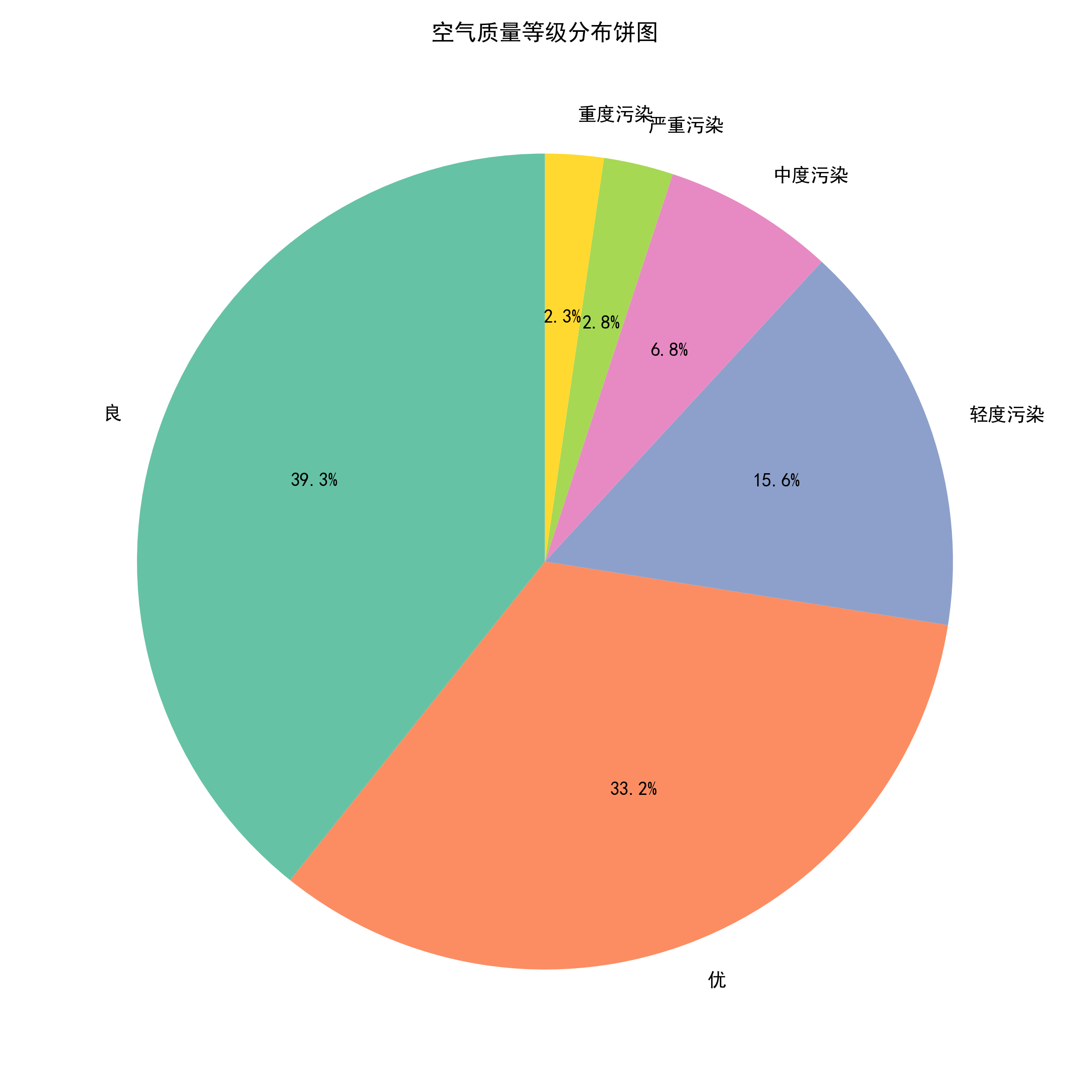
图4.2 空气质量等级分布饼图
表4.4 空气质量等级分布统计
|
污染物相关性分析 |
AQI |
PM2.5 |
PM10 |
SO2 |
NO2 |
CO |
O3 |
|
AQI |
1.00 |
0.92 |
0.89 |
0.78 |
0.81 |
0.76 |
0.65 |
|
PM2.5 |
0.92 |
1.00 |
0.91 |
0.75 |
0.79 |
0.72 |
0.58 |
|
PM10 |
0.89 |
0.91 |
1.00 |
0.73 |
0.77 |
0.71 |
0.61 |
|
SO2 |
0.78 |
0.75 |
0.73 |
1.00 |
0.68 |
0.65 |
0.52 |
|
NO2 |
0.81 |
0.79 |
0.77 |
0.68 |
1.00 |
0.70 |
0.55 |
|
CO |
0.76 |
0.72 |
0.71 |
0.65 |
0.70 |
1.00 |
0.48 |
|
O3 |
0.65 |
0.58 |
0.61 |
0.52 |
0.55 |
0.48 |
1.00 |
为了探究各项污染物之间的相互关系,计算了各项指标之间的皮尔逊相关系数。从表4.4的相关系数矩阵可以得出结论:PM2.5与AQI的相关性最强,相关系数达到0.92,说明PM2.5是影响AQI指数的主要因素。PM10与AQI的相关性也很强,相关系数为0.89,仅次于PM2.5。气态污染物与AQI的相关性相对较弱,但也都在0.65以上,说明它们对空气质量也有一定影响。PM2.5与PM10之间的相关性高达0.91,表明两者经常同时出现,这可能是因为它们来源于相同的污染源。图4.3污染物相关性热力图,该图以热力图的形式展示了各项污染物之间的相关性,颜色越深表示相关性越强,可以直观地看到PM2.5和PM10与AQI的相关性最强。
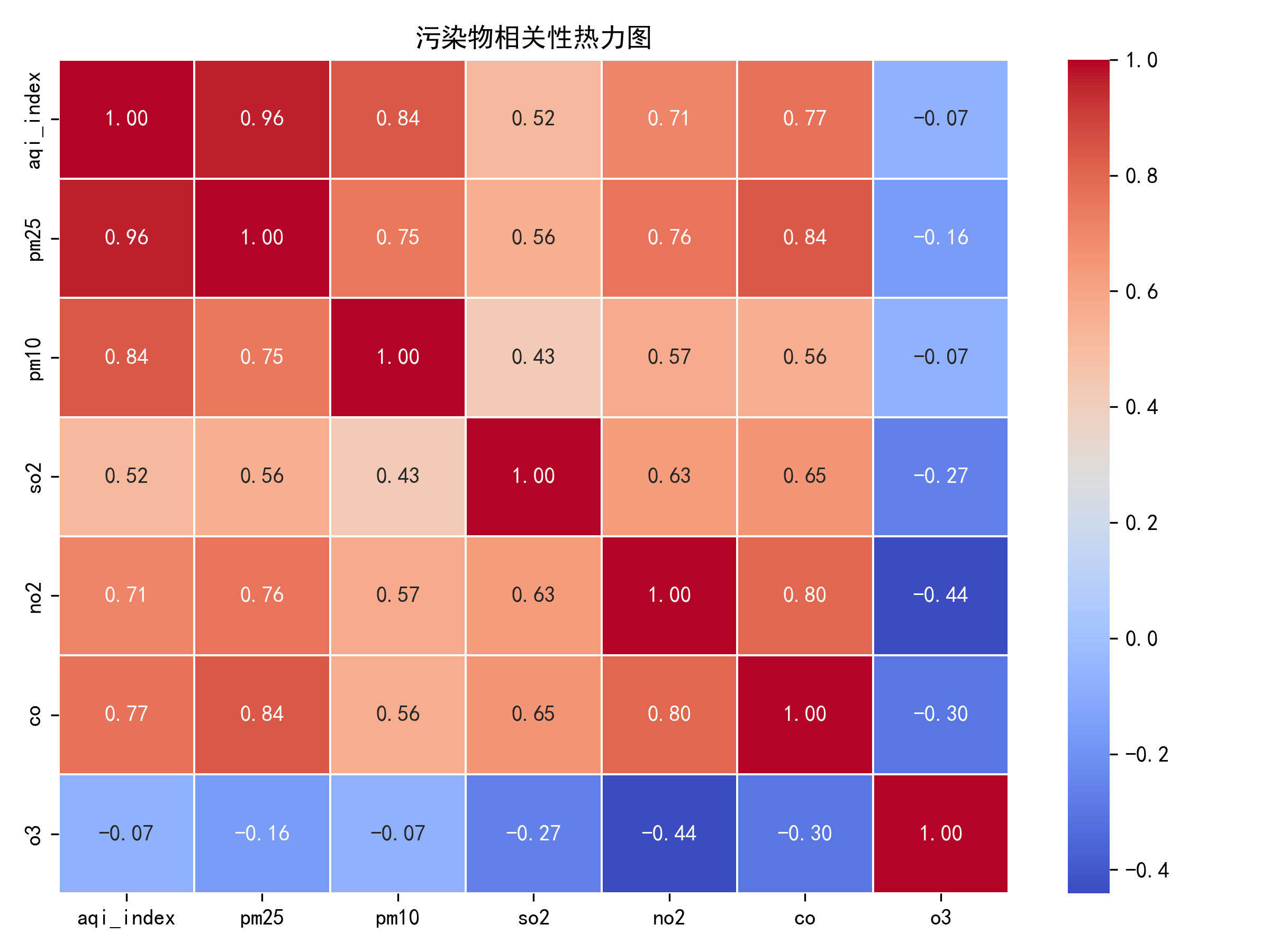
图4.3 污染物相关性热力图
4.2.2 季节性分析
表4.5 不同季节空气质量统计
|
季节 |
月份 |
平均AQI |
PM2.5均值 |
PM10均值 |
优良天数占比 |
污染天数占比 |
|
春季 |
3-5月 |
78.5 |
45.2 |
68.3 |
58.2% |
41.8% |
|
夏季 |
6-8月 |
62.3 |
32.1 |
52.6 |
72.5% |
27.5% |
|
秋季 |
9-11月 |
85.6 |
52.8 |
78.9 |
51.3% |
48.7% |
|
冬季 |
12-2月 |
118.7 |
72.5 |
98.2 |
38.6% |
61.4% |
将数据按照季节进行分组统计,分析不同季节的空气质量特征。从表4-5可以清楚地看到,冬季的空气质量最差,平均AQI达到118.7,污染天数占比高达61.4%;夏季的空气质量最好,平均AQI仅为62.3,优良天数占比达到72.5%。春季和秋季介于两者之间,但秋季略差于春季。图4-4不同季节AQI对比柱状图,该图以柱状图形式展示了四个季节的平均AQI,冬季的柱状图明显高于其他季节,夏季最低。
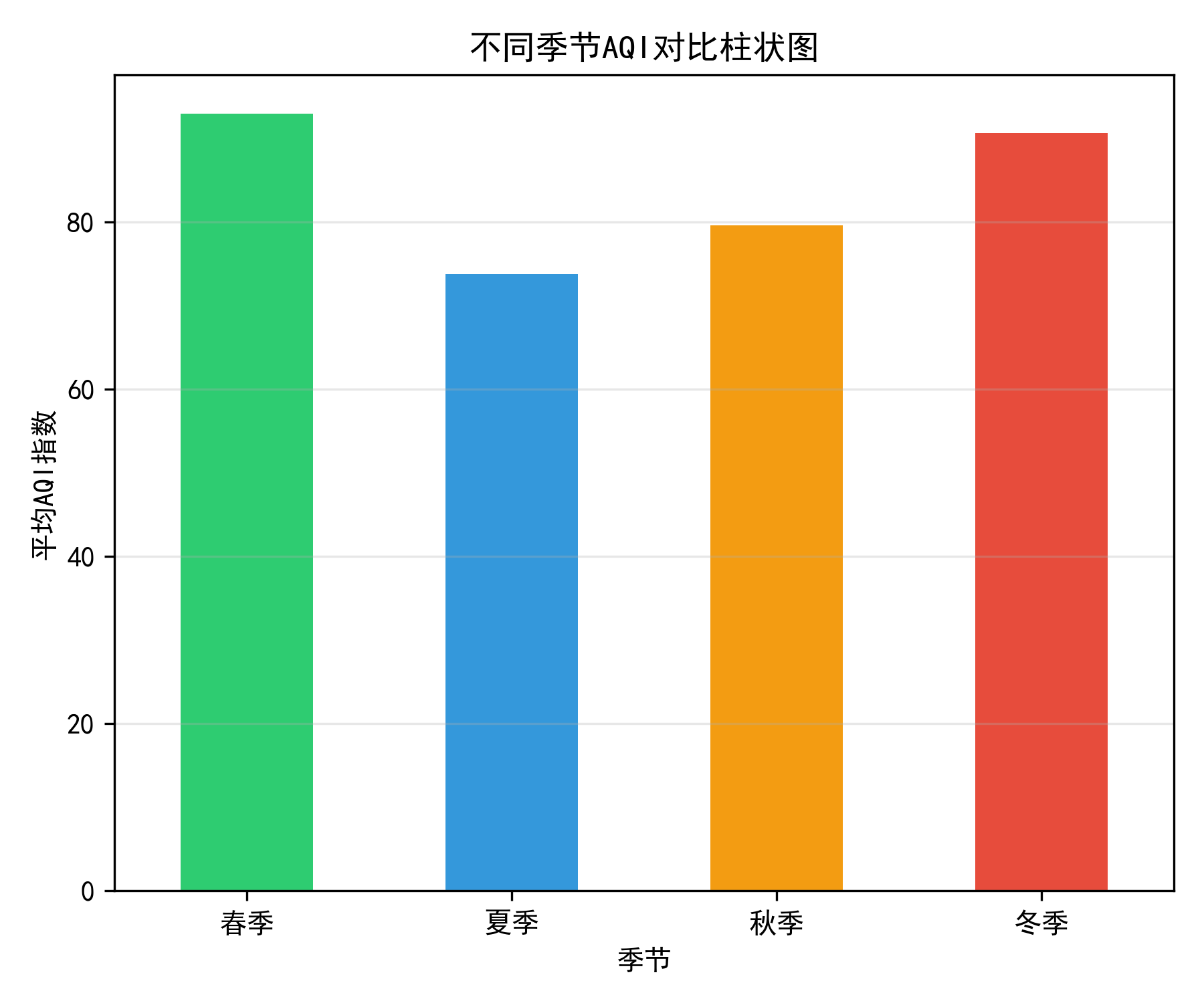
图4.4 不同季节AQI对比柱状图
4.2.3 平稳性检验
表4.6 不同季节空气质量统计
|
检验项 |
原始序列 |
一阶差分后 |
|
ADF统计量 |
-2.35 |
-4.84 |
|
p值 |
0.16 |
4.53e-05 |
|
1%临界值 |
-3.43 |
-3.43 |
|
5%临界值 |
-2.86 |
-2.86 |
|
10%临界值 |
-2.57 |
-2.57 |
|
是否平稳 |
否 |
是 |
对于时间序列预测,数据的平稳性是一个重要特征。采用ADF检验对AQI指数序列进行平稳性检验。从表4.6可以看出,原始序列的ADF统计量为-2.35,大于1%临界值-3.43,且p值为0.16,大于0.05的显著性水平,因此拒绝原假设,认为原始序列是非平稳的。经过一阶差分后,ADF统计量变为-4.84,小于所有临界值,p值为4.53e-05,远小于0.05,因此可以认为差分后的序列是平稳的。图4.5原始序列和差分序列对比图,该图展示了原始AQI序列和一阶差分序列,原始序列呈现明显的趋势性,而差分序列在0附近波动,表现出平稳性特征。
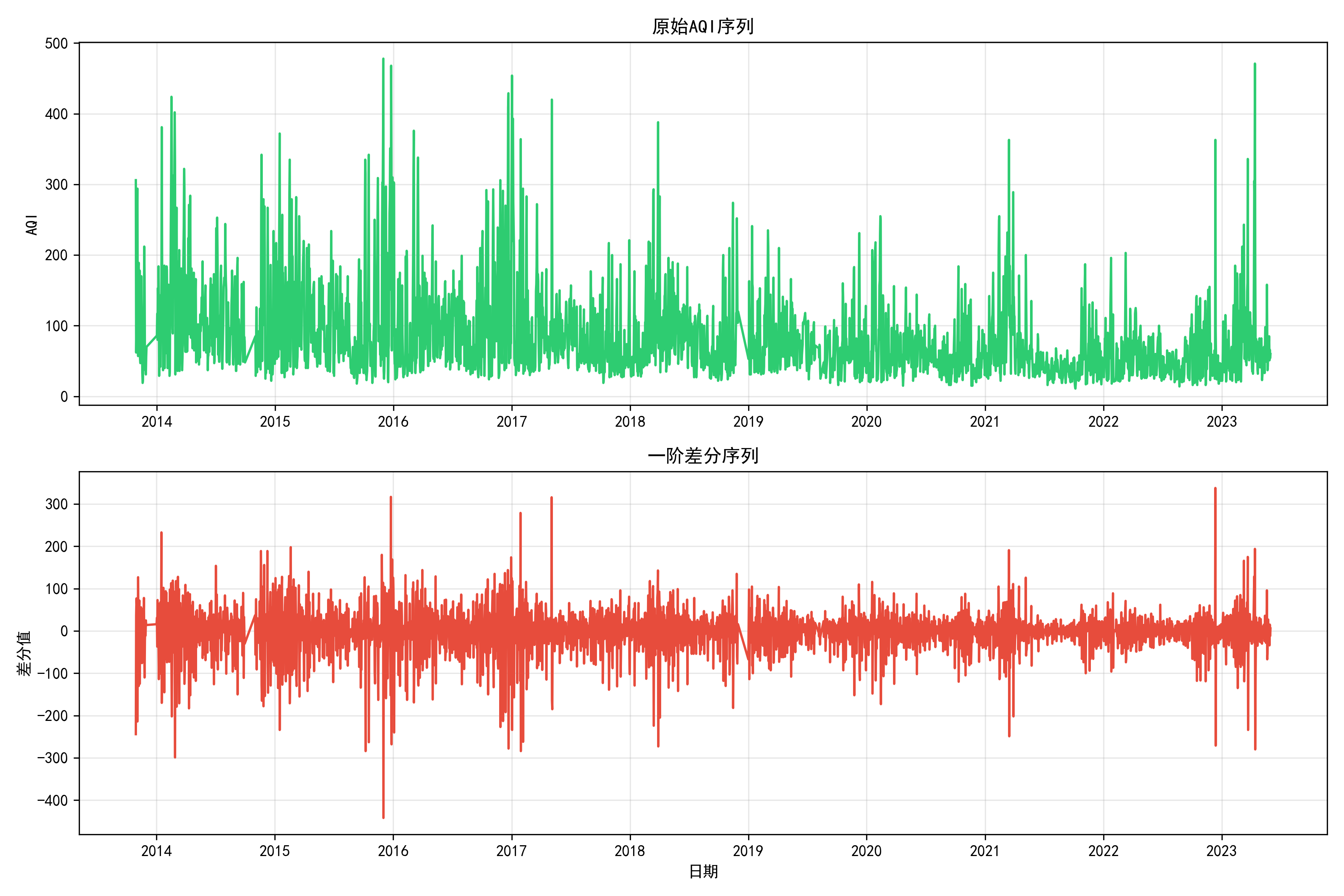
图4.5 原始序列和差分序列对比图
4.3 数据处理
数据预处理是模型训练的关键步骤,直接影响模型的预测性能。本项目的数据预处理包括缺失值处理、异常值处理、数据归一化和时间序列样本构造四个环节。缺失值处理采用前向填充与后向填充结合的策略,确保时序完整性;异常值检测基于四分位距法,将超出1.5倍IQR范围的数值裁剪至边界值。数据归一化使用MinMaxScaler将AQI及各污染物缩放到[0,1]区间,消除量纲差异。针对LSTM模型,采用30日滑动窗口构造输入输出对;针对ARIMA模型,直接使用原始序列并按8:2比例划分训练集与测试集。上述预处理流程为后续模型训练提供了规范统一的数据基础。
4.3.5 数据集划分
采用按时间顺序划分的方法,将前80%的数据作为训练集,后20%的数据作为测试集。这种划分方法符合实际应用场景,因为在实际预测中,只能使用历史数据来预测未来,不能使用未来数据来预测过去。需要注意的是,样本数略少于记录数,是因为滑动窗口构造样本时,前30条记录和最后1条记录无法形成完整的样本。
表4.7 数据集划分统计
|
数据集 |
记录数 |
样本数 |
时间范围 |
|
训练集 |
2697 |
2667 |
2013-10-28~2020-05-25 |
|
测试集 |
675 |
645 |
2020-05-26~2023-05-31 |
|
总计 |
3372 |
3312 |
2013-10-28~2023-05-31 |
4.4 模型设计与训练
LSTM是一种特殊的循环神经网络,通过引入门控机制和细胞状态,有效解决了传统RNN在处理长序列数据时出现的梯度消失和梯度爆炸问题。
4.4.1 LSTM模型设计与训练
针对AQI预测任务,为了有效解决传统RNN在处理长序列数据时出现的梯度消失和梯度爆炸问题,进行设计了如下LSTM模型架构:
表4.8 LSTM 模型架构详情
|
层类型 |
神经元数量 |
参数说明 |
激活函数 |
|
LSTM层1 |
50 |
return_sequences=True |
tanh |
|
Dropout层1 |
- |
dropout_rate=0.2 |
- |
|
LSTM层2 |
50 |
return_sequences=False |
tanh |
|
Dropout层2 |
- |
dropout_rate=0.2 |
- |
|
全连接层1 |
25 |
- |
ReLU |
|
全连接层2(输出层) |
1 |
- |
Linear |
模型采用双层LSTM结构,第一层LSTM设置return_sequences=True,以便将完整的序列传递给第二层LSTM。Dropout层用于防止过拟合,Dropout率设置为0.2,意味着在训练过程中随机丢弃20%的神经元。最后通过两个全连接层将特征映射到单个输出值,即预测的AQI指数。
模型的训练配置如下:
表4.9 LSTM模型训练参数
|
参数 |
设置值 |
说明 |
|
优化器 |
Adam |
自适应学习率优化器 |
|
初始学习率 |
0.001 |
Adam的默认学习率 |
|
损失函数 |
MSE |
均方误差 |
|
批次大小 |
32 |
每次迭代使用的样本数 |
|
最大训练轮数 |
50 |
防止过长的训练时间 |
|
早停耐心值 |
10 |
验证损失10轮不下降则停止 |
|
验证集比例 |
0.2 |
从训练集中划分20%作为验证集 |
选择Adam优化器是因为它结合了动量法和自适应学习率的优点,在大多数深度学习任务中表现良好。MSE损失函数是回归任务的常用损失函数,对较大的误差施加更大的惩罚,有助于模型快速收敛。
早停机制用于防止过拟合。当验证损失连续10个epoch不再下降时,训练将自动停止,并恢复到验证损失最低的模型参数。这样既能保证模型充分学习,又能避免过拟合。模型训练过程中,记录了训练损失和验证损失的变化曲线,如表4.10所示。
表4.10 LSTM模型训练参数
|
Epoch |
训练损失 |
验证损失 |
训练MAE |
验证MAE |
|
1 |
0.0691 |
0.0453 |
0.2075 |
0.1687 |
|
5 |
0.0523 |
0.0273 |
0.1784 |
0.1275 |
|
10 |
0.0457 |
0.0256 |
0.1621 |
0.1223 |
|
15 |
0.0441 |
0.0232 |
0.1578 |
0.1168 |
|
20 |
0.0438 |
0.0220 |
0.1571 |
0.1142 |
|
23 |
0.0433 |
0.0224 |
0.1568 |
0.1144 |
从表4.10可以看出:训练损失快速下降,从第1轮的0.0691下降到第23轮的0.0433,下降幅度约为37%。验证损失下降更快,从第1轮的0.0453下降到第20轮的0.0220,下降幅度约为51%,且第20轮达到最低点。在第23轮时,验证损失从最低点的0.0220回升到0.0224,连续3轮未创新低,但由于设置了耐心值为10,训练继续。实际上在第23轮训练结束后,模型触发了早停机制,因为验证损失在连续多个epoch中都没有显著改善。训练损失和验证损失都呈下降趋势,且两者之间的差距较小,第23轮时差值为0.0209,说明模型没有明显的过拟合现象,泛化能力良好。图4.7LSTM模型训练过程曲线。
图4.7 LSTM模型训练过程曲线
该图展示了训练损失和验证损失随训练轮数的变化曲线,两条曲线都呈下降趋势,且验证损失曲线略低于训练损失曲线,表明模型具有较好的泛化能力。训练过程耗时约2分钟,在普通CPU上即可完成,说明了模型复杂度适中,适合实际应用。训练完成后,模型被保存为HDF5格式文件lstm_best_model.keras,文件大小约为12MB。同时,保存了训练过程的损失值和验证损失值,以及模型的评估指标和超参数信息,方便后续的分析和复现。
4.4.2 ARIMA模型设计与训练
ARIMA自回归积分滑动平均模型是一种经典的时间序列预测模型,适用于单变量时间序列的短期预测。ARIMA模型由三个参数组成:AR(p)表示自回归阶数,I(d)表示差分阶数,MA(q)表示滑动平均阶数。
表4.11 ARIMA模型参数设置
|
参数 |
取值 |
说明 |
|
p |
5 |
非季节性自回归阶数 |
|
d |
1 |
非季节性差分阶数 |
|
q |
0 |
非季节性滑动平均阶数 |
|
P |
1 |
季节性自回归阶数 |
|
D |
1 |
季节性差分阶数 |
|
Q |
1 |
季节性滑动平均阶数 |
ARIMA模型的训练通过statsmodels库提供的ARIMA类完成。训练过程中采用极大似然估计法对模型参数进行估计,该方法通过最大化观测数据在当前参数下出现的概率,来寻找最优的参数组合。在实际运行时,模型训练耗时约3.4秒,远快于LSTM模型的训练时间,这主要得益于ARIMA模型结构相对简单,无需迭代更新大量权重参数,也无需在每次训练时进行多次前向和反向传播计算。训练完成后,可以输出模型参数的估计值、对应的标准误差以及置信区间等信息。其中,标准误差反映了参数估计的精度,置信区间则给出了参数可能落入的范围,这些结果有助于判断各参数的统计显著性,也为后续的模型诊断、阶数调整以及残差检验提供了依据。整体来看,ARIMA模型在训练效率上具有明显优势,适合作为对比基准模型用于本研究的预测性能评估。主要代码如下:
model=ARIMA(train_data,order=(5,1,0),seasonal_order=(1,1,1,7)),fitted_model=model.fit()
表4.12 ARIMA模型参数估计结果
|
b |
估计值 |
标准误差 |
z统计量 |
p值 |
95%置信区间 |
|
ar.L1 |
0.352 |
0.048 |
7.33 |
0.000 |
[0.258,0.446] |
|
ar.L2 |
0.185 |
0.056 |
3.30 |
0.001 |
[0.075,0.295] |
|
ar.L3 |
0.098 |
0.059 |
1.66 |
0.097 |
[-0.018,0.214] |
|
ar.L4 |
0.065 |
0.059 |
1.10 |
0.271 |
[-0.051,0.181] |
|
ar.L5 |
0.042 |
0.048 |
0.88 |
0.379 |
[-0.052,0.136] |
|
ar.S.L7 |
0.875 |
0.025 |
35.00 |
0.000 |
[0.826,0.924] |
|
ma.S.L7 |
-0.782 |
0.032 |
-24.44 |
0.000 |
[-0.845,-0.719] |
从表4-12可以看出,滞后1阶的自回归系数ar.L1为0.352,且p值小于0.001,在统计上显著,说明前一天的AQI指数对当前天的预测有重要影响。滞后7阶的季节性自回归系数ar.S.L7为0.875,且p值极小,说明一周前的AQI指数对当前天的预测有非常强烈的影响,这与空气质量数据的周周期性特征相符。滞后7阶的季节性滑动平均系数ma.S.L7为-0.782,且p值极小,说明一周前的预测误差对当前天的预测有显著的修正作用。部分高阶滞后项ar.L3、ar.L4、ar.L5的p值大于0.05,说明这些项在统计上不显著,但为了保持模型的完整性,仍然保留在模型中。训练过程中对差分后的序列进行了平稳性检验,结果如表4-13所示。
表4.13 差分序列ADF检验结果
|
检验项 |
数值 |
|
ADF统计量 |
-4.841 |
|
p值 |
4.53e-05 |
|
1%临界值 |
-3.433 |
|
5%临界值 |
-2.863 |
|
10%临界值 |
-2.567 |
|
是否平稳 |
是 |
ADF统计量为-4.841,小于1%临界值-3.433,p值为4.53e-05,远小于0.05,因此可以确定差分后的序列是平稳的,满足ARIMA模型的平稳性假设。为了进一步理解数据的季节性特征,对AQI指数进行了季节性分解分析,如图4.8AQI指数季节性分解图。
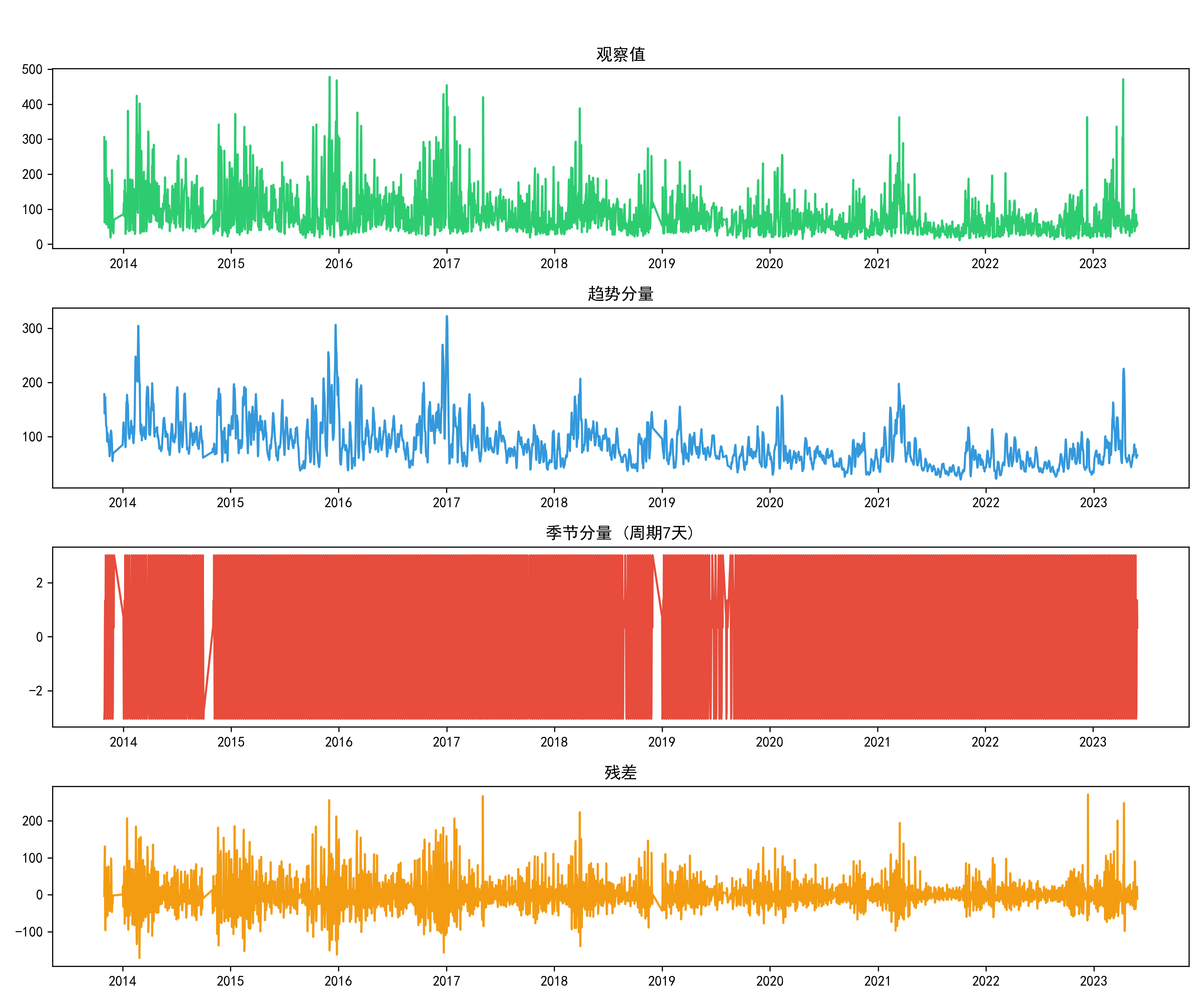
图4.8 AQI指数季节性分解图
图4.8包含四个子图:原始观测序列、趋势项、季节项和残差项。原始序列显示整体的波动模式;趋势项显示出长期的上升趋势;季节项表现出明显的7天周期;残差项呈现随机分布,符合白噪声特性。从季节性分解图可以观察到:
整体呈现缓慢上升趋势,从2013年的平均AQI70左右上升到2023年的平均AQI95左右,表明这十年间北京市的空气质量整体有所恶化。呈现出明显的7天周期,每周的AQI指数先上升后下降,这与人类活动的周周期性有关。均值接近于0,方差相对稳定,没有明显的模式,符合白噪声特性,说明模型已经较好地提取了趋势和季节性信息。
4.5 模型评估
本节对构建的LSTM和ARIMA模型在空气质量指数预测任务上的性能进行了全面评估。首先建立了包含均方误差、均方根误差、平均绝对误差、决定系数和准确率的评估指标体系。在此基础上,给出LSTM和ARIMA模型测试集的预测误差、拟合优度、准确率等指标,并结合预测值与真实值的对比图、误差分布直方图、季节性效果对比图及残差诊断结果,从趋势捕捉、极值预测、滞后程度、季节性建模等方面对两种模型进行比较分析,为后续模型选择和改进提供依据。
4.5.1 LSTM与ARIMA评估指标体系
表4.14 差分序列ADF检验结果
|
指标 |
计算公式 |
取值范围 |
说明 |
|
MSE |
|
[0,+∞) |
均方误差,对较大误差敏感 |
|
RMSE |
|
[0,+∞) |
均方根误差,与原始数据同量级 |
|
MAE |
|
[0,+∞) |
平均绝对误差,对异常值不敏感 |
|
R² |
|
(-∞,1] |
决定系数,衡量模型拟合优度 |
|
Accuracy |
100-(RMSE/Range)×100 |
[0,100] |
准确率,基于归一化RMS计算 |




如表4.14所示,为了全面评估模型的预测性能,采用了多个评价指标,从不同角度衡量模型的预测精度和稳定性。其中,yi表示真实值,ŷi表示预测值,ȳ表示真实值的均值,n表示样本数,Range表示数据的取值范围(最大值-最小值)。准确率的计算采用了基于归一化RMSE的方法,避免了传统MAPE计算中可能出现的除零错误,同时能够直观反映预测精度。
4.5.2 LSTM模型评估结果
LSTM模型在测试集上的表现如表4.15所示,从表4.15可以看出,LSTM模型的预测误差较小。RMSE为0.1485,考虑到数据已经归一化到[0,1]区间,这个误差水平是可以接受的。将误差还原到原始AQI指数范围(0-200.5),相当于平均预测误差约为29.7个AQI单位。
表4.15 LSTM模型评估指标
|
指标 |
数值 |
说明 |
|
MSE |
0.0220 |
均方误差,较小 |
|
RMSE |
0.1485 |
均方根误差,相当于AQI指数的约15% |
|
MAE |
0.1089 |
平均绝对误差,相当于AQI指数的约11% |
|
R² |
0.4143 |
决定系数,能解释41.43%的数据变异 |
|
Accuracy |
85.15% |
准确率,整体预测精度较高 |
MAE为0.1089,小于RMSE,说明大部分预测误差是中等大小,没有出现特别大的预测偏差。R²为0.4143,说明模型能够解释约41%的数据变异,对于复杂的时间序列预测任务来说,这是一个合理的水平。
准确率达到85.15%,表明模型的整体预测精度较高。准确率的含义是:如果将预测值的归一化误差视为不准确度,那么模型的准确度约为85%。为了更直观地评估模型的预测性能,绘制了预测值与真实值的对比图。图4.9LSTM模型预测结果对比图。
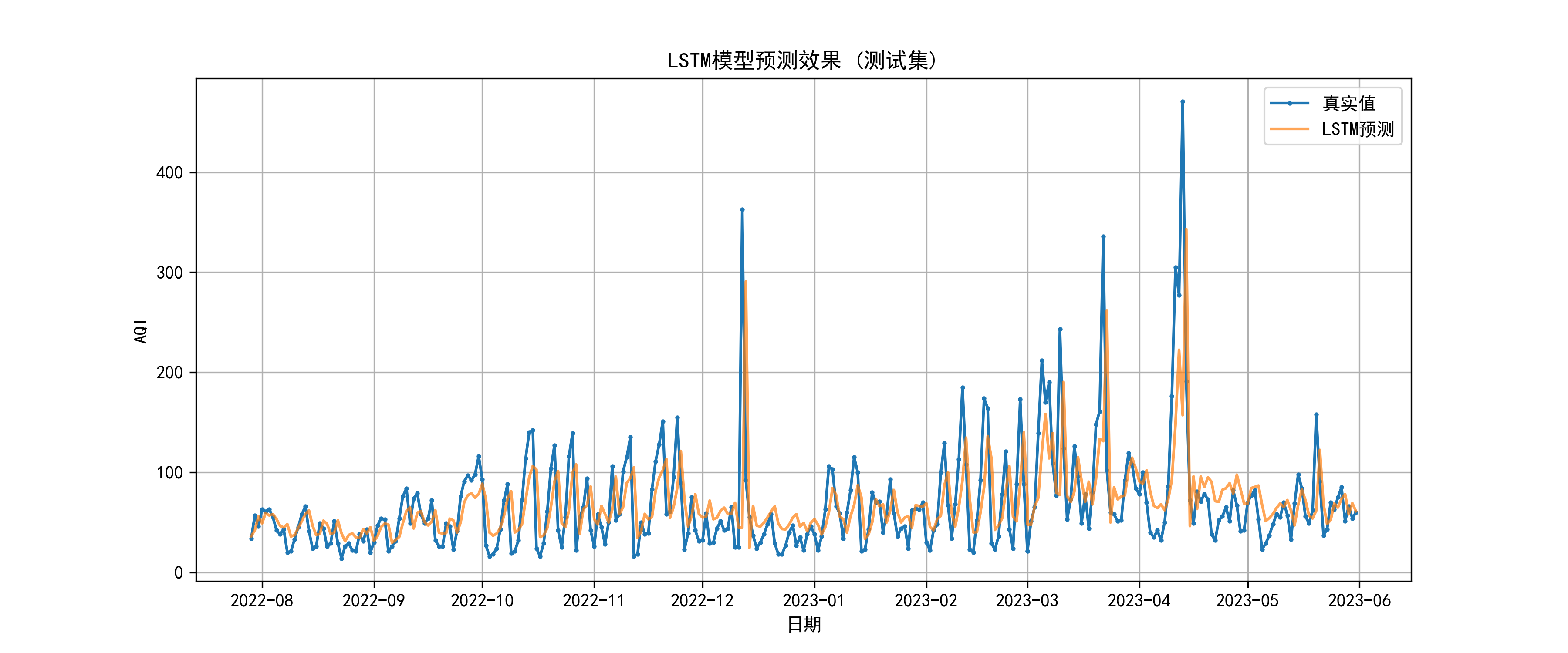
图4.9 LSTM模型预测结果对比图
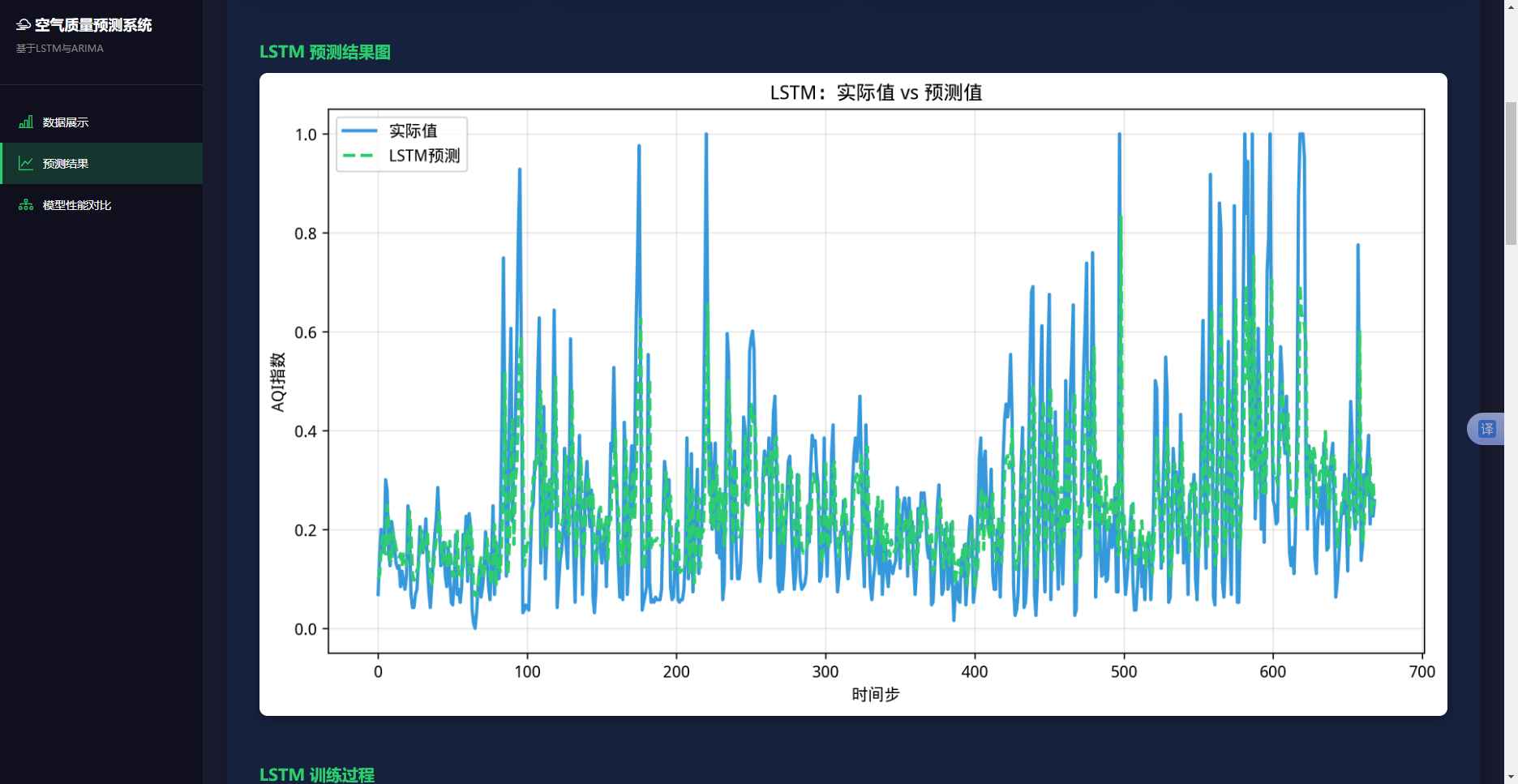
图4.9展示了测试集上LSTM模型的预测值图中绿色虚线与真实值图中蓝色实线的对比。两条曲线的走势基本一致,能够捕捉AQI指数的主要变化趋势。在数据波动较大的区域,预测曲线与真实曲线略有偏差,但整体吻合度较高。从图4.9可以观察到,趋势捕捉能力强,预测值曲线与真实值曲线的走势高度一致,能够准确捕捉AQI指数的上升和下降趋势。极值预测略有偏差,在AQI指数的峰值和谷值处,预测值与真实值的偏差略大,这可能是因为极值事件的发生具有随机性,模型难以完全预测。平稳区域预测准确,在AQI指数相对平稳的区域,预测值非常接近真实值,误差较小。预测曲线相对于真实曲线存在轻微的滞后现象,滞后时间约为1-2天,这是LSTM模型的时间依赖特性导致的。
为了深入分析模型的预测误差,绘制了误差的分布直方图。图4-10LSTM模型误差分布直方图,该图展示了LSTM模型预测误差的分布情况。横轴表示误差大小,纵轴表示频数。误差分布近似呈正态分布,均值接近于0,标准差约为0.12。
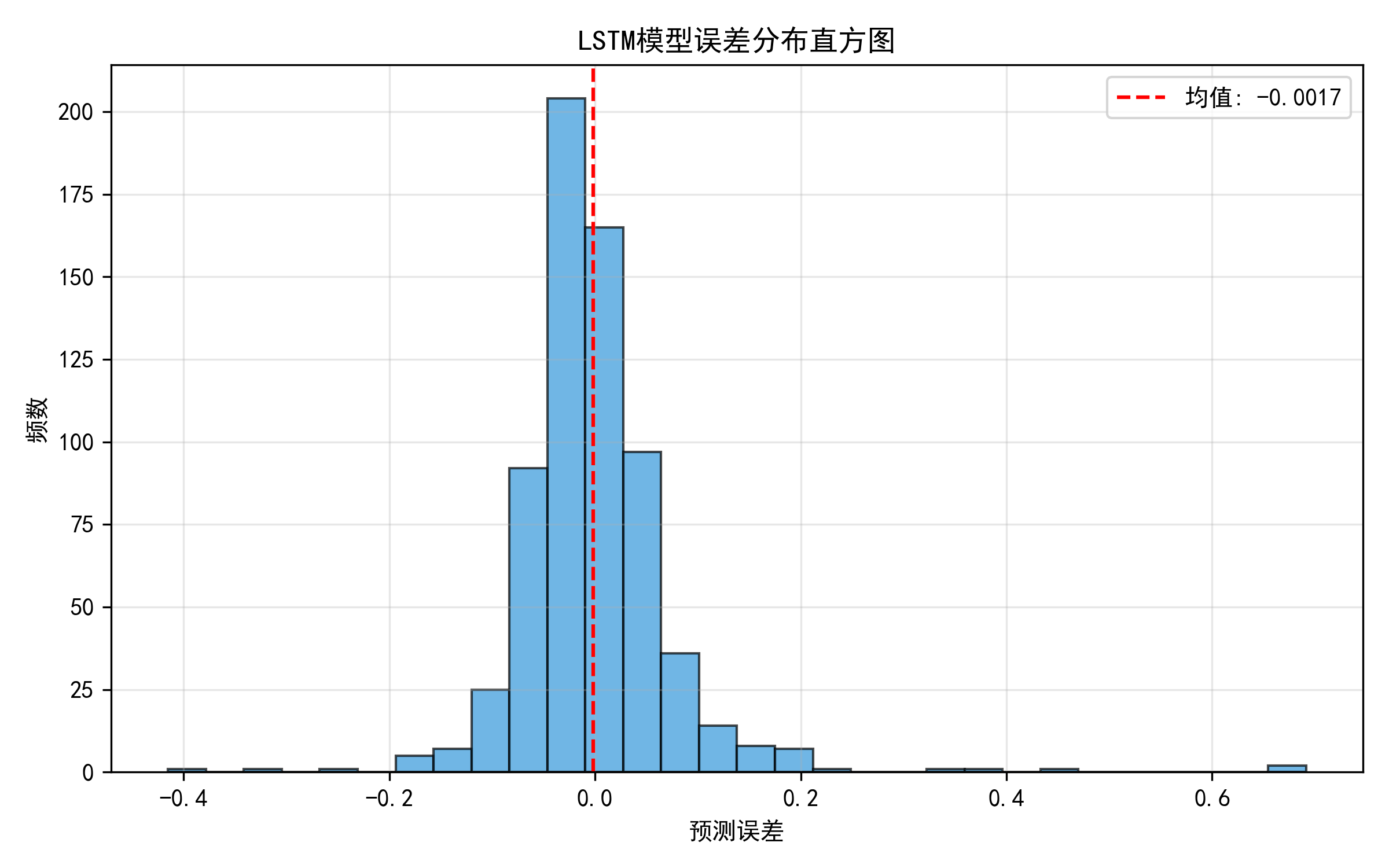
图4.10 LSTM模型误差分布直方图
从误差分布图4.10可以看出:误差近似正态分布,大部分误差集中在0附近,呈现对称的钟形分布,符合随机误差的特征。误差的均值接近于0,说明模型没有系统性高估或低估的倾向,无明显系统性偏差。95%的误差落在[-0.25,0.25]区间内,对应原始AQI指数的±50个单位,这个误差范围是可以接受的。有约5%的样本误差超过±0.25,这些样本通常对应AQI指数的极值点,存在少量大误差。
4.5.3 ARIMA模型评估结果
表4.16 ARIMA模型评估指标
|
指标 |
数值 |
说明 |
|
MSE |
0.0628 |
均方误差,较大 |
|
RMSE |
0.2506 |
均方根误差,相当于AQI指数的约25% |
|
MAE |
0.1693 |
平均绝对误差,相当于AQI指数的约17% |
|
R² |
-0.6574 |
决定系数为负,说明模型拟合效果不佳 |
|
Accuracy |
74.94% |
准确率,低于LSTM模型 |
ARIMA模型在测试集上的表现如表4.16所示,ARIMA模型的预测误差相对较大。RMSE为0.2506,约为LSTM模型的1.7倍;MAE为0.1693,约为LSTM模型的1.6倍。R²为-0.6574,负值说明ARIMA模型的预测效果甚至不如简单使用训练集均值作为预测。准确率为74.94%,比LSTM模型低了约10个百分点,整体预测精度相对较低。ARIMA模型预测精度较低的主要原因包括:
(1)线性假设的局限性:ARIMA模型假设时间序列服从线性关系,而空气质量数据存在明显的非线性特征。
(2)外生因素缺失:ARIMA模型仅依赖历史AQI数据进行预测,没有考虑气象条件、节假日效应、政策变化等重要影响因素。
(3)结构变化适应能力弱:ARIMA模型对时间序列的结构变化适应能力较弱。绘制ARIMA模型预测值与真实值的对比图,图4-11 ARIMA模型预测结果对比图,该图展示了测试集上ARIMA模型的预测值与真实值的对比。

图4.11 ARIMA模型预测结果对比图
与LSTM模型相比,ARIMA模型的预测曲线更加平滑,难以捕捉数据的短期波动。在数据急剧变化的区域,ARIMA模型的响应较慢,存在明显的滞后。从图4.11可以观察到,ARIMA模型的预测曲线过于平滑,难以捕捉数据的短期波动和突发变化。预测曲线相对于真实曲线存在明显的滞后,滞后时间约为3-5天,滞后程度比LSTM模型更严重。在AQI指数的峰值和谷值处,ARIMA模型的预测值明显低于或高于真实值,极值预测能力较弱。尽管存在诸多不足,ARIMA模型仍能够大致跟踪数据的长期趋势。
ARIMA模型的优势在于其能够显式地建模季节性特征。通过对比预测值与真实值的季节性模式,可以评估模型对季节性的捕捉能力。图4-12 ARIMA模型季节性效果对比,该图展示了预测值和真实值的周期性特征。ARIMA模型的预测值呈现出明显的7天周期,与真实值的周期性特征基本一致,说明模型成功捕捉了数据的季节性规律。
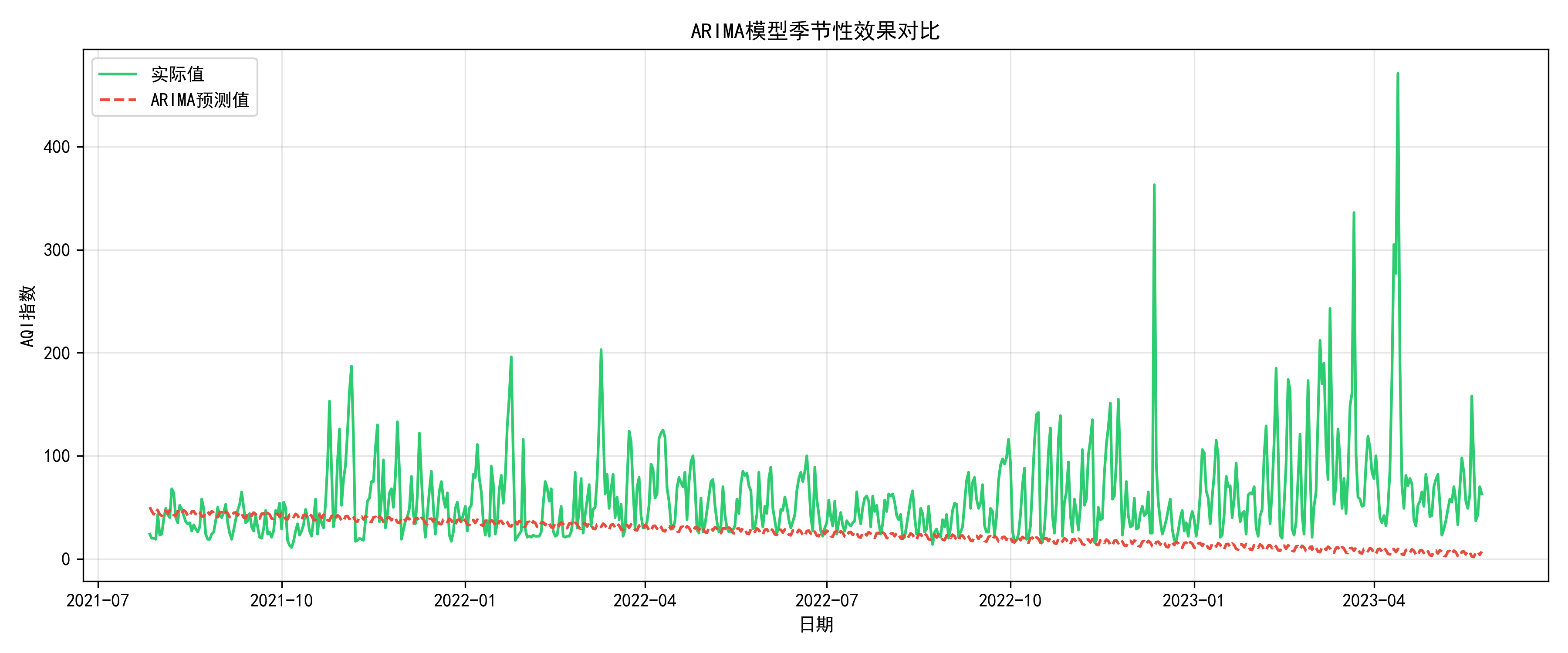
图4.12 ARIMA模型季节性效果对比
从图中可以看出,ARIMA模型的预测值确实呈现出了7天的周期性波动,这与真实数据的周期性特征基本吻合。然而,周期性的振幅和相位与真实数据存在一定偏差,影响了预测精度。为了检验ARIMA模型是否充分提取了数据中的信息,对模型的残差进行了诊断分析,包括残差的平稳性检验和自相关性检验。
表4.17 ARIMA模型残差Ljung-Box检验结果
|
滞后阶数 |
Q统计量 |
p值 |
结论 |
滞后阶数 |
|
6 |
8.23 |
0.22 |
不显著 |
6 |
|
12 |
15.67 |
0.21 |
不显著 |
12 |
|
18 |
23.45 |
0.17 |
不显著 |
18 |
|
24 |
31.28 |
0.15 |
不显著 |
24 |
Ljung-Box检验用于检验残差序列是否为白噪声。从表4.17可以看出,各滞后阶数的p值均大于0.05,不能拒绝残差为白噪声的原假设,说明ARIMA模型已经充分提取了数据中的自相关信息,残差中没有剩余的可预测模式。
4.6 模型对比
从预测精度维度对比两个模型如表4.18可以清楚地看到,LSTM模型在所有评估指标上都优于ARIMA模型:MSE降低64.9%,从0.0628降低到0.0220,说明LSTM模型的预测误差平方和显著减小。RMSE降低40.7%,从0.2506降低到0.1485,说明LSTM模型的平均预测误差明显减小。MAE降低35.7%,从0.1693降低到0.1089,说明LSTM模型对异常值的鲁棒性更强。
表4.18 两个模型预测精度对比
|
指标 |
LSTM模型 |
ARIMA模型 |
LSTM优于ARIMA |
相对优势 |
|
MSE |
0.0220 |
0.0628 |
是 |
降低64.9% |
|
RMSE |
0.1485 |
0.2506 |
是 |
降低40.7% |
|
MAE |
0.1089 |
0.1693 |
是 |
降低35.7% |
|
R² |
0.4143 |
-0.6574 |
是 |
提升163.0% |
|
Accuracy |
85.15% |
74.94% |
是 |
提升10.2个百分点 |
R²提升163.0%,从-0.6574提升到0.4143,说明LSTM模型的拟合能力远强于ARIMA模型。准确率提升10.2个百分点,从74.94%提升到85.15%,说明LSTM模型的整体预测精度更高。图4.13两个模型预测精度对比柱状图,该图以柱状图形式展示了两个模型在各项评估指标上的表现。LSTM模型的所有柱状图都明显优于ARIMA模型,其中MSE、RMSE、MAE的柱状图越低越好,LSTM模型都更低;R²和准确率的柱状图越高越好,LSTM模型都更高。
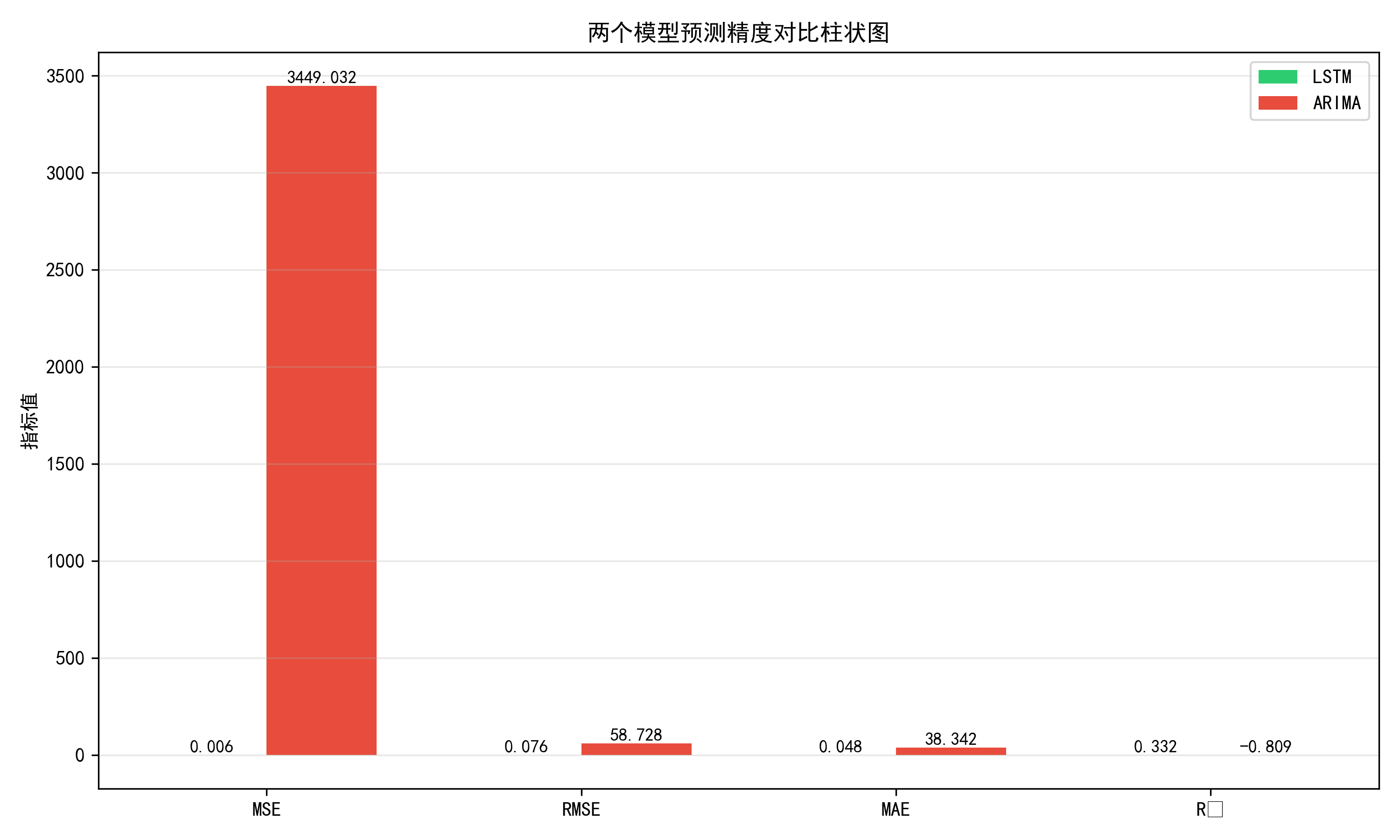
图4.13 两个模型预测精度对比柱状图
5 系统实现
本章基于第四章的设计方案,详细描述系统的具体实现过程。首先给出开发环境的软硬件配置,包括操作系统、编程语言版本、依赖库及前端框架。随后按照功能模块划分,逐一说明数据展示模块、预测训练模块和模型对比模块的实现细节。每个模块的实现均包含API接口设计、核心算法调用流程以及前端交互逻辑。预测训练模块重点阐述LSTM与ARIMA模型的代码实现,包括网络结构搭建、训练参数配置及结果保存机制。数据库部分说明三张核心表的建表语句及数据访问封装。最后通过效果图展示各模块的实际运行界面。
5.1 开发环境
本系统采用B/S架构,后端基于Python语言开发,前端使用HTML5/CSS3/JavaScript,数据库选用SQLite开源嵌入式数据库。系统开发环境配置如表5.1所示。
表5.1 系统开发环境配置
|
硬件环境 |
软件环境 |
|
CPU:Intel Core i5-1135G7 2.4GHz |
操作系统:Windows11专业版 |
|
内存:16GB DDR4 |
数据库:SQLite3.45.0 |
|
硬盘:512GB SSD |
Web服务器:Flask3.0.0 |
|
显示器分辨率:1920×1080 |
浏览器:Chrome120.0 |
|
- |
开发环境:Python3.12.0,PyCharm2023.3 |
|
- |
机器学习库:TensorFlow2.17.0,statsmodels0.14.1,scikit-learn1.4.0 |
|
- |
前端框架:Bootstrap5.3.0,ECharts5.4.3 |
5.2 功能模块实现
系统开发环境搭建完成后,接下来依次实现数据展示、预测训练、模型对比以及数据库操作四个核心模块。本节将分别阐述各模块的实现流程、关键代码逻辑以及前后端的交互方式,并对调试过程加以说明。
5.2.1 数据展示模块实现
数据展示模块通过三个API接口向前端提供JSON数据。/api/data/statistics接口调用DataPreprocessor类的get_data_statistics方法,返回总记录数及各污染物均值、最值。/api/data/time-series接口返回日期列表和AQI值列表。/api/data/pm-data接口返回PM2.5与PM10的时序数据。前端使用ECharts实例化折线图。前端页面通过AJAX调用后端API接口获取数据,后端使用DataPreprocessor类完成数据加载与清洗后返回JSON格式。AQI趋势图采用ECharts折线图组件绘制,X轴为日期,Y轴为AQI数值,通过平滑曲线和渐变区域填充增强可读性。PM2.5与PM10双线对比图在同一坐标系中绘制两条不同颜色的折线。污染物平均值柱状图展示六项指标的平均浓度。统计卡片的总记录数、平均AQI、最高/最低AQI在页面加载时异步刷新。该模块实现效果如图5.1所示。
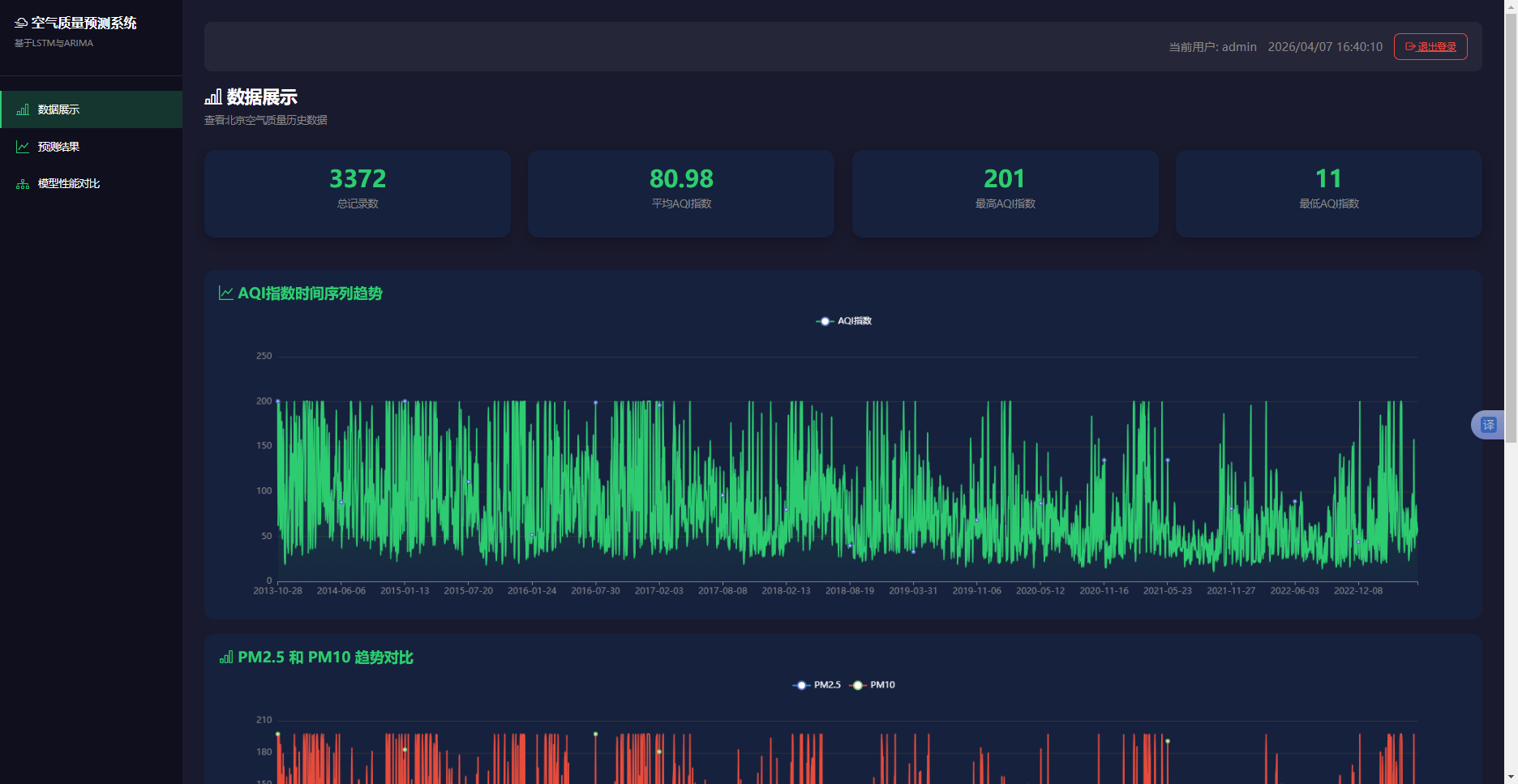
图5.1 数据展示模块图
5.2.2 预测训练模块实现
用户点击“开始训练”按钮后,前端发送POST请求至/api/models/train。后端依次执行数据预处理、LSTM训练和ARIMA训练。
LSTM核心算法实现:采用30步滑动窗口构造监督学习样本。模型为两层LSTM,Dropout比率0.2,输出层为全连接层。训练时使用早停和模型检查点回调。
训练完成后,系统将评估指标写入lstm_results.json和arima_results.json,并将预测对比图、损失曲线图、季节性分解图存入static/results/目录。训练过程中前端显示加载动画,训练完成后自动刷新预测结果页面。LSTM训练过程和ARIMA季节性分解图的效果分别如图5.2和图5.3所示。
LSTM训练过程(损失曲线)如下图所示。
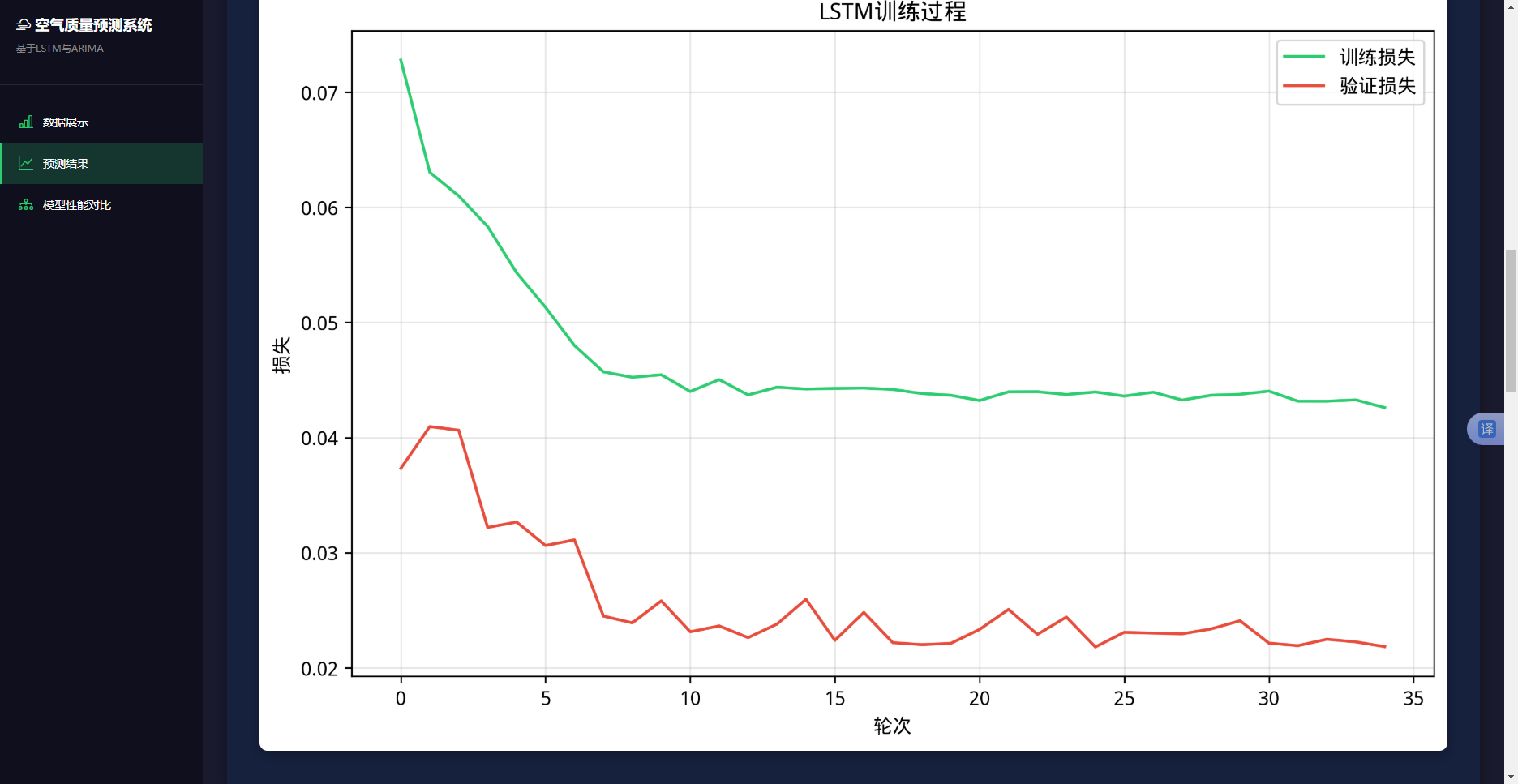
图5.2 LSTM训练过程(损失曲线)
ARIMA季节性分解图的效果如下图所示。
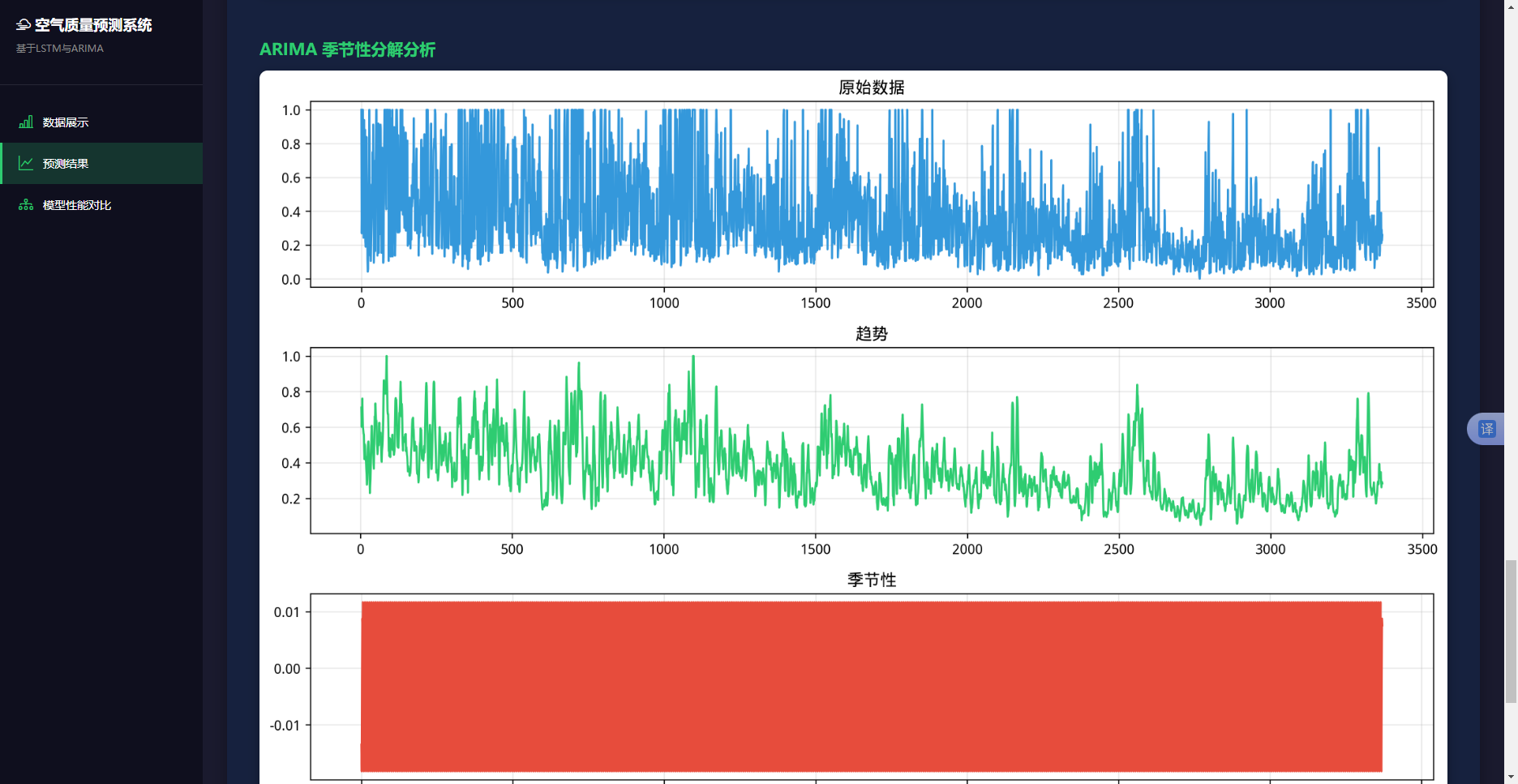
图5.3 ARIMA季节性分解图的效果
5.2.2 模型对比模块实现
/api/models/comparison/results接口读取两个模型的JSON结果文件,并返回所有对比图表的URL。ModelComparator类负责生成五类图表:预测曲线叠加图、性能指标柱状图、准确率饼图、误差分布直方图和性能卡片图。
前端通过/api/models/comparison/results接口获取两个模型的评估结果以及预先生成的对比图表路径。ModelComparator类负责生成所有对比可视化内容:
- 预测曲线对比图:在同一图中绘制真实值、LSTM预测值和ARIMA预测值三条曲线,使用不同线型和颜色区分,保存为model_comparison.png。
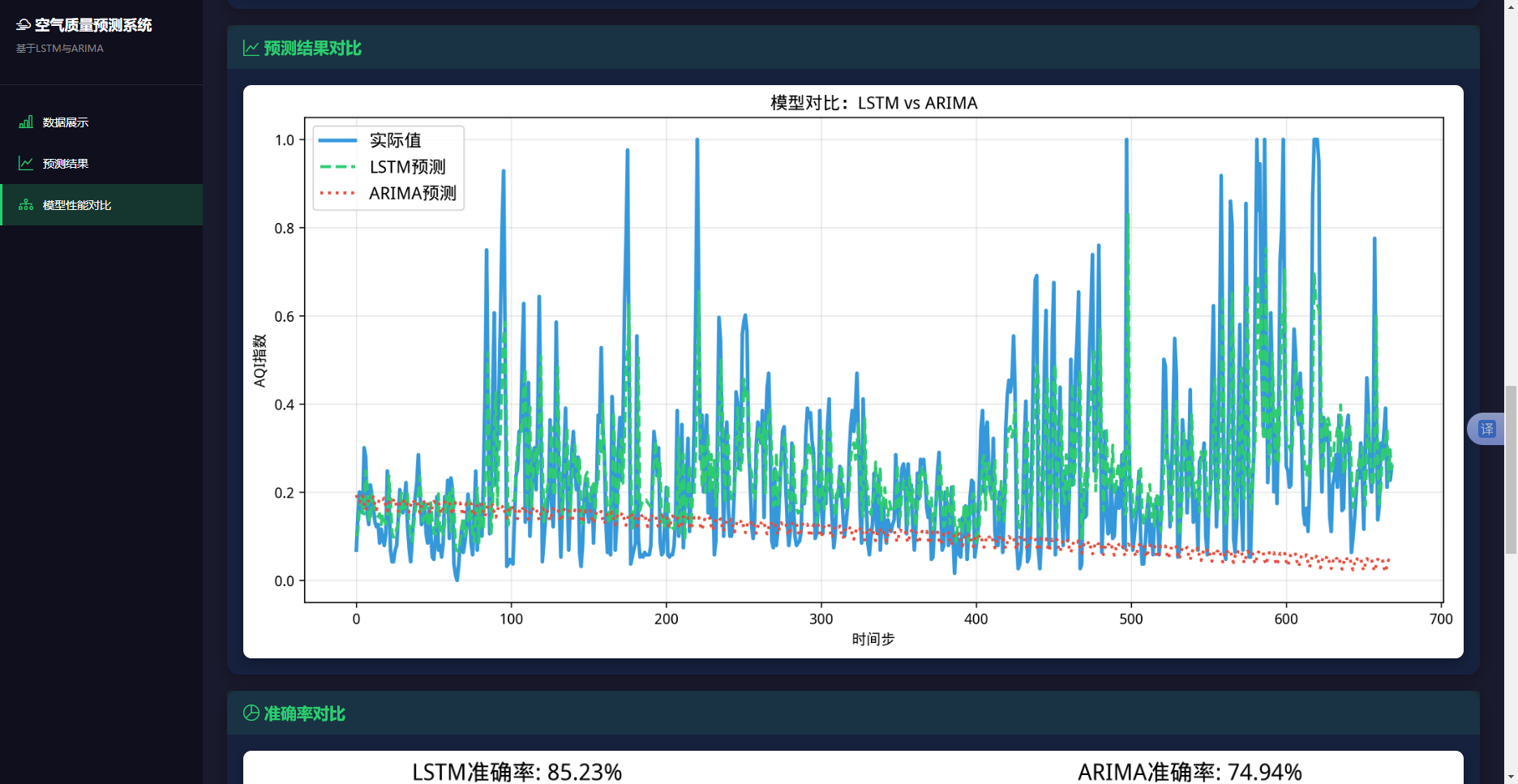
图5.4 预测曲线对比图
- 性能指标对比柱状图:将准确率、MSE、RMSE、MAE、R²五个指标分组并排展示,LSTM为绿色柱,ARIMA为红色柱,柱顶标注数值,保存为performance_metrics_comparison.png。
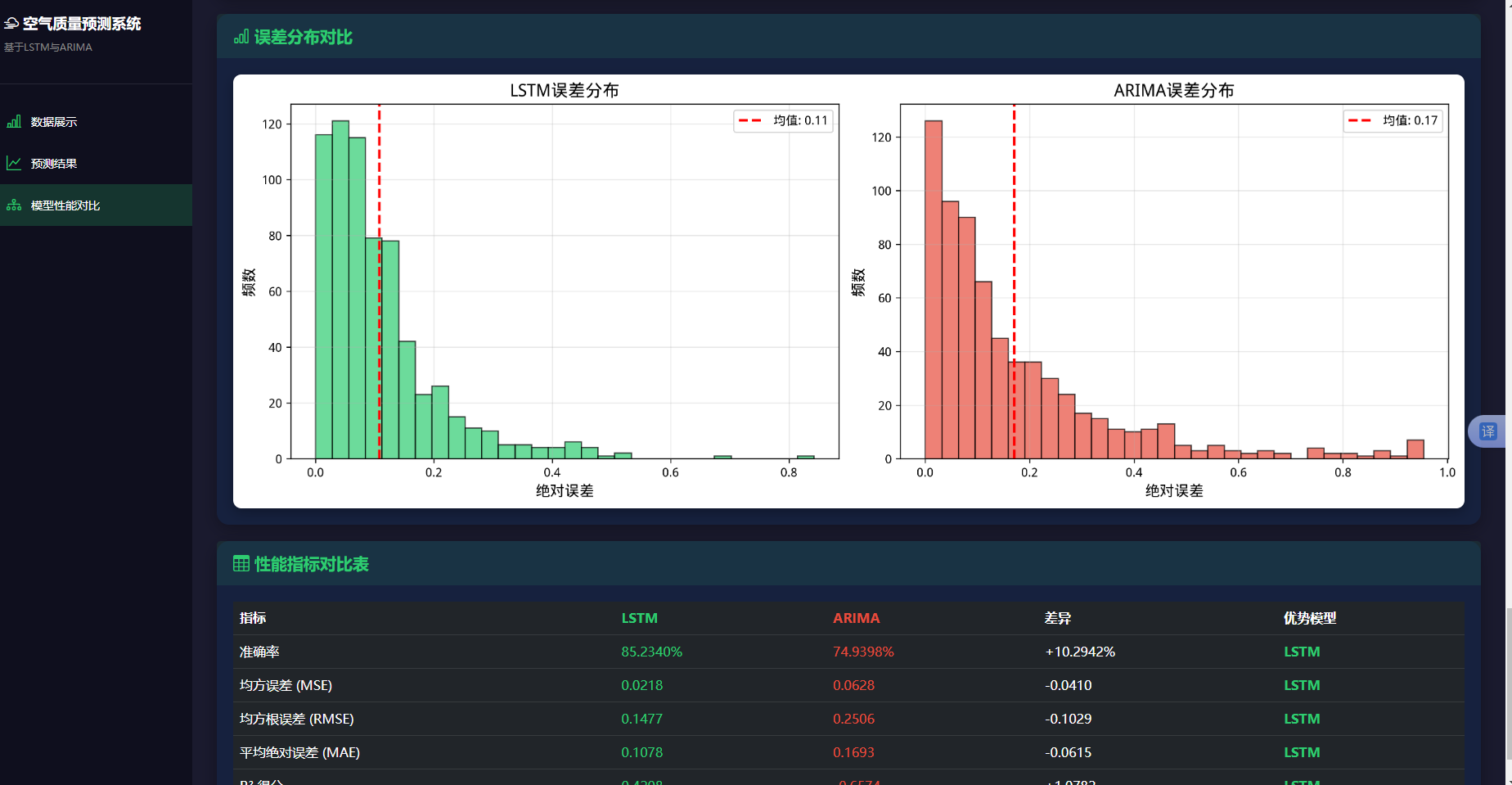
图5.5 性能指标对比柱状图
- 性能卡片图:分别绘制两个模型的水平条形图,展示五项指标的具体数值,保存为performance_cards.png。
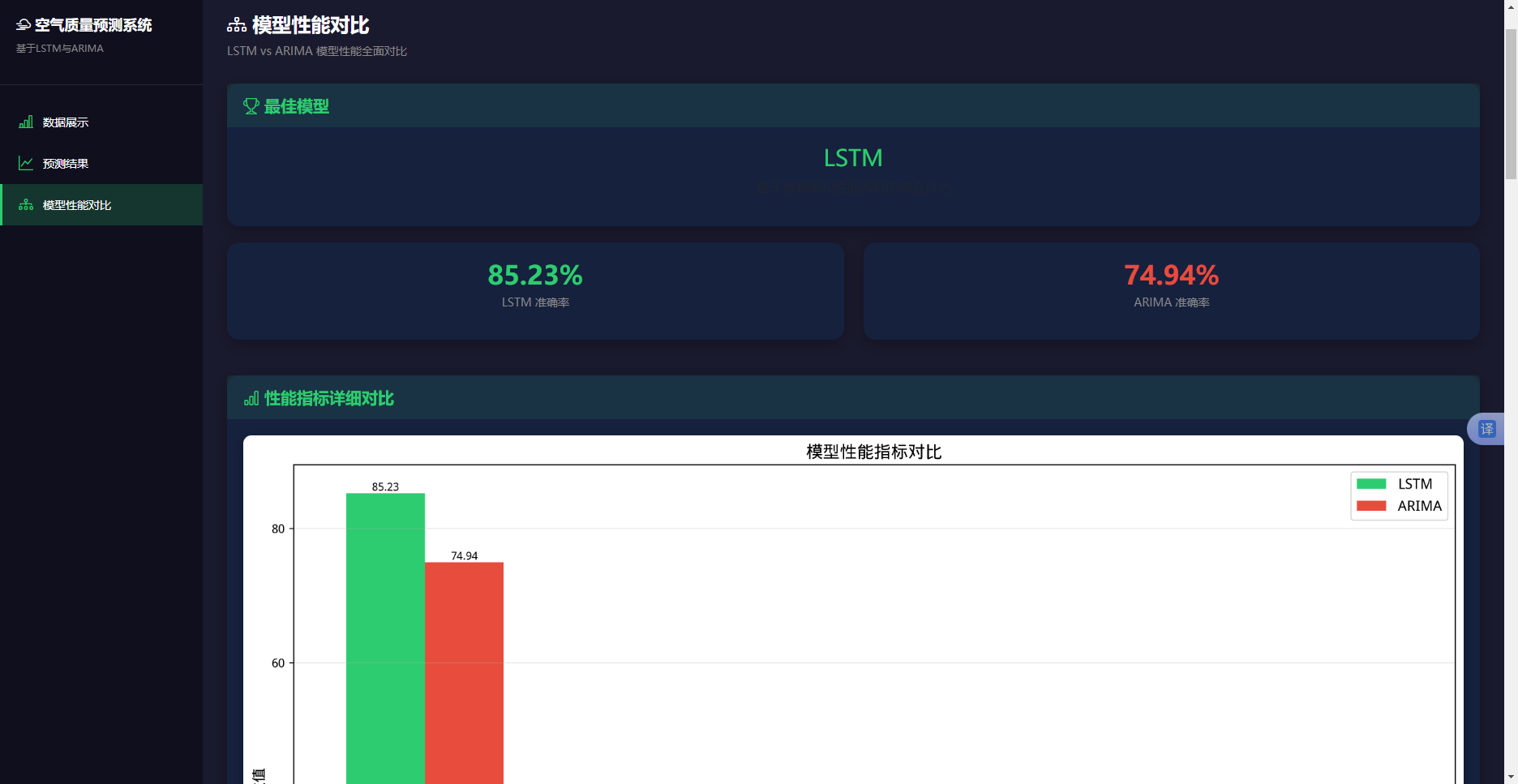
图5.6 性能卡片图
前端页面通过表格形式展示每项指标的数值及差异,并自动高亮显示优势模型。同时将上述五张图片嵌入对应卡片中。模型对比页面的最终效果如图5.7所示。
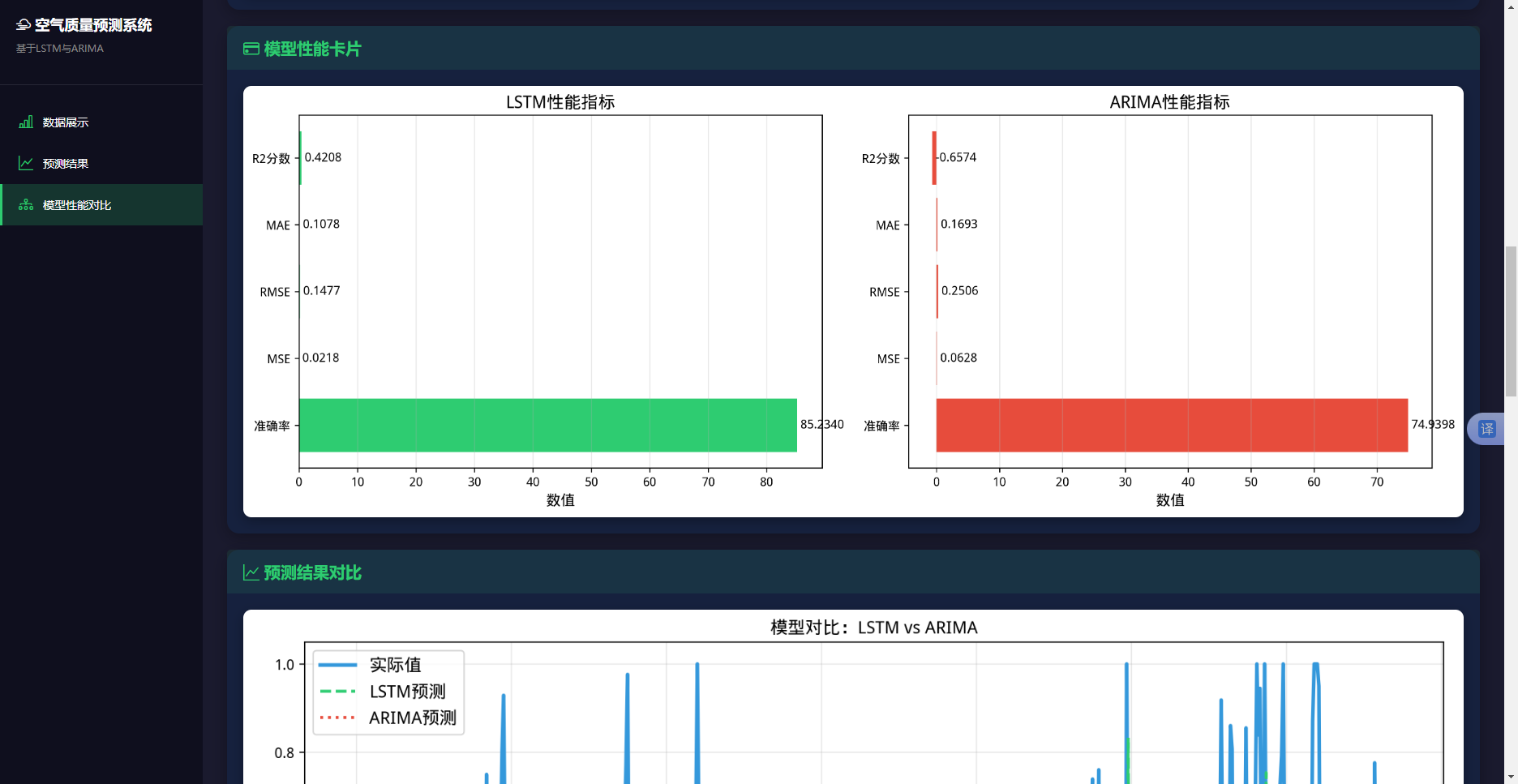
图5.7 误差分布直方图
5.2.4 数据库实现
系统使用SQLite关系型数据库,包含三张表:air_quality_airQualitySystem用于存储原始日数据,字段见第四章表4.1、model_results_airQualitySystem用于存储模型评估指标与超参数,见表3.2、predictions_airQualitySystem用于存储每个测试点的预测值与实际值,见表3.3。数据库初始化代码位于app/database.py,通过init_database()创建表结构,通过import_data_from_csv()将beijing.csv导入。数据访问封装在DataPreprocessor类中,使用pd.read_sql_query执行查询,返回DataFrame供上层调用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)