【3D 场景生成】NuiScene: Exploring Efficient Generation of Unbounded Outdoor Scenes

NuiScene:面向无边界户外场景的高效生成方法
源码链接:https://3dlg-hcvc.github.io/NuiScene/
数据集链接:https://3dlg-hcvc.github.io/NuiScene43-Dataset/
发表:ICCV-2025
图1. 本文所提模型可实现大规模户外场景几何结构的高效、无边界生成。场景纹理由SceneTex[6]完成。
摘要
本文针对广阔户外场景生成任务展开研究,生成对象涵盖城堡、高层建筑等多种户外场景。过往研究主要聚焦于室内场景生成,而户外场景生成存在诸多独有难题:场景高度差异极大,同时需要能够快速构建大规模地貌的生成方案。为解决上述问题,本文提出一种高效方法,将场景分块编码为统一向量集形式。相较于现有方法采用的空间结构化隐特征,该方案具备更优的压缩能力与运行性能。此外,本文训练了专用的显式外补绘制模型以实现无边界场景生成。相较于传统基于重采样的内补修复方案,该模型不仅提升了场景整体连贯性,还省去额外的扩散步骤,进一步加快生成速度。为支撑相关研究,本文构建了NuiScene43数据集,该数据集规模适中但场景质量优异,且完成预处理工作,可支持模型联合训练。实验结果表明,在多风格场景数据上完成训练后,本文模型能够在同一场景中融合不同环境元素(例如乡村民居与城市摩天大楼)。这一结果也验证了本文数据集构建方案可有效利用多类型异质场景开展联合训练。
1 引言
大规模户外场景生成在诸多领域具备重要应用价值,例如为开放世界游戏构建沉浸式虚拟世界、制作影视计算机图形(CGI)场景以及搭建虚拟现实仿真环境。传统方式打造这类巨型户外场景,需要投入大量人工与资源。得益于人工智能内容生成技术的快速发展,这一任务的落地门槛大幅降低,生成效率也得到显著提升。
以Stable Diffusion[38]为代表的扩散模型在图像生成领域取得成功,在此基础上,独立三维物体生成模型[24,48]也逐步走向成熟。这类模型的发展,很大程度上依托于Objaverse[10]等大规模三维数据集。然而,大规模场景生成技术仍存在明显短板,现有研究大多围绕室内场景展开[4,18,33,47]。部分研究虽采用语义驾驶数据集[26,27,31]或计算机辅助设计(CAD)模型[30],但这类数据存在几何质量不佳、场景样式单一、高度变化范围有限等问题。
与现有方法不同,本文聚焦于难度更高的户外场景生成任务,主要面临三大挑战:第一,实现高度多变的户外场景快速、高效生成;第二,将不同风格的地貌元素融合为连贯统一的完整场景;第三,构建适配该任务的数据集,支撑异质场景的联合训练与相关算法研究。
现有面向无边界室内场景生成的方法大多基于3D-Front[12]数据集,这类方法将场景划分为等大立方体,并学习三平面表示[47]、稠密特征网格[33]等空间结构化隐特征以完成数据压缩。但该思路难以适配摩天大楼等高度差异显著的户外建筑场景。如图3所示,若直接对这类特征表示进行缩放,会造成显存占用激增;而通过归一化缩放场景尺寸,又会导致场景细节丢失。
1.稠密网格是全局规则结构,不支持局部自适应分辨率。整个分块只能使用一套统一的网格密度,无法做到 “水平轴稀疏、竖直轴加密”,因此只能要求原始空间三轴跨度相近。
2.三平面的核心依赖均匀像素分布的双线性插值,尺度失衡会彻底破坏插值的一致性。它的设计初衷就是为三轴均衡的立方体空间服务,无法适配极端狭长的竖直空间。
3.3D 几何模型为了训练稳定,必须将坐标归一化到固定区间(如[−1,1]):
尺度均衡时:归一化是等比例缩放,不破坏三轴的相对精度;
尺度失衡时:归一化会非线性挤压长轴空间,直接抹杀长轴的精细几何信息。
这个训练层面的硬约束,进一步锁死了这类结构的适用范围。
为解决该问题,本文将场景分块压缩为向量集[52]。相较于三平面表示,向量集能够实现更高效的数据压缩,既提升训练效率,也能优化生成结果的质量。与此同时,本文针对扩散模型设计显式外补绘制策略,相比依赖重采样内补修复的现有方法[33,47],进一步缩短推理耗时。
除此之外,过往研究所使用的数据集风格较为单一,例如仅包含室内场景或城市道路场景。而本文旨在构建可融合多类场景的生成模型,如图2所示,模型能够将城堡、现代城市等不同场景元素融为一体。

图2. 本文模型在多场景数据上训练后所生成的场景,场景纹理由SceneTex[6]生成。如图所示,该模型能够融合数据集中不同场景的元素,例如城堡与摩天大楼。
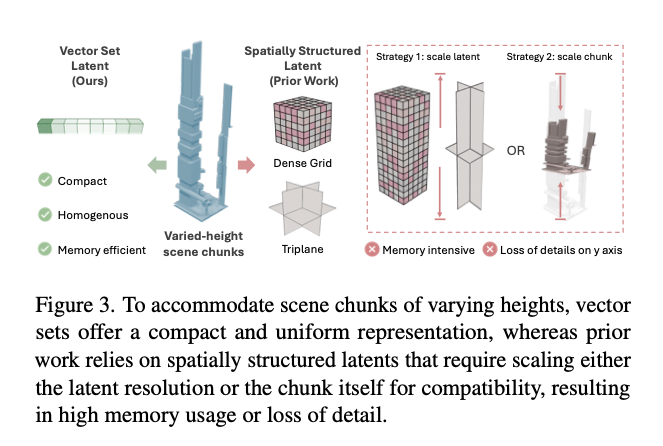
图3. 针对高度不一的场景分块,向量集可提供紧凑且统一的特征表示;而现有方法采用空间结构化隐特征时,为适配不同高度,要么缩放隐特征分辨率,要么缩放场景分块本身,前者会导致显存占用过高,后者则会造成纵轴(Y轴)细节丢失。
另一大现存难题是,目前缺乏可公开使用的高质量户外场景训练数据。3D-Front[12]常被用于无边界室内场景生成任务,但该数据集的场景高度缺乏多样性,也不包含家具以外的复杂几何结构。语义驾驶数据集[2,45]与城市重建数据集[13,14,37]的网格模型质量普遍偏低。Objaverse[10]虽包含大量可用于该任务的场景数据,但仍存在诸多问题:场景网格缺乏统一的全局尺度,地面几何形态差异极大(从极薄平面到厚实体结构均有分布),难以作为标准同质数据集训练生成模型。
针对以上问题,本文从Objaverse中筛选出一批场景数据,统一修正地面几何形态并设定全局尺度。基于处理后的数据集,本文所提方法可同时处理两类任务:一是适配高度分布多样化的场景;二是学习不同来源、不同风格的户外几何结构。实验证明,本文的数据集预处理流程能够支持异质场景在同一模型中完成联合训练。
综上,NuiScene方法的核心贡献可归纳为四点:
- 高效特征表示:提出使用向量集对尺寸各异的场景分块进行编码,得到统一形式的特征表示,兼顾训练效率与场景生成质量。
- 外补绘制模型:摒弃传统依赖重采样的慢速外补绘制方案,训练专用扩散模型,基于已生成的完整场景分块做条件约束,实现显式外补绘制,大幅提升推理速度。
- 跨风格场景生成:实验证明,仅使用4组经过筛选的场景数据训练得到的NuiScene模型,即可融合中世纪建筑、现代城市等不同风格的场景元素,同时也验证了数据集预处理流程的有效性。
- NuiScene43数据集:该数据集包含43个中大型户外场景,全部完成地面几何修复与尺度统一。数据集可支撑异质场景联合训练,助力无边界场景生成算法的研发,能够适配场景高度多样化、场景风格多元化两大研究方向。
2 相关工作
基于文生图像先验的三维场景生成
近年来,借助文生图像(T2I)扩散模型[38]与单目深度估计方法[3,20,23]的先验知识,从文本或图像生成三维场景的技术路线受到广泛关注[8,11,41,51]。这类方法首先利用文生图像模型生成彩色图像,再通过深度预测模型提取几何信息,最后基于所得信息对三维几何结构进行特征蒸馏或优化。通过移动相机并合成新区域,该类方案可实现连续外补绘制与无边界场景生成。
文生图像模型具备强大的先验能力,能够支撑开放域场景生成,但深度预测过程会不断累积误差,进而造成几何畸变,同时难以保障场景的长距离一致性。
有界单样本三维场景生成
现有多项研究聚焦于基于单一样本生成三维场景[19,28,44,46],普遍采用由粗到细的渐进式策略,在不同尺度下提取图块统计特征。与SinGAN[39]思路类似,SinGRAV[44]、3INGAN[19]以及吴、郑二人提出的方法[46]均构建了生成对抗网络(GAN)金字塔结构:判别器针对小尺寸图块进行约束,以此保证局部内容的连贯性,同时允许全局布局多样化。
李等人[28]引入基于期望最大化(EM)的优化算法,完成多尺度下的图块匹配与融合。这类方法虽能生成布局、长宽比各不相同的场景,但仅支持有边界生成;若直接一次性生成大尺寸完整场景,会产生极高的显存开销。
无边界三维场景生成
主流的三维无边界场景生成框架思路如下:首先将完整场景切分为若干小型分块,利用自编码器将分块压缩为隐特征表示,随后基于场景分块的隐特征训练扩散模型。在生成阶段,将当前分块与已生成的相邻分块进行重叠,并结合RePaint[32]等基于重采样的内补修复算法,实现连续的外补绘制。
已有研究基于CarlaSC[45]、SemanticKITTI[2]等合成数据与真实世界语义驾驶数据集,探索户外无边界场景生成任务。这类数据集虽可支撑一定规模的场景生成,但场景几何质量普遍偏低。SemCity[27]沿用上述主流框架,并选用三平面作为隐特征表示;金字塔离散扩散模型(PDD)[31]直接在原始语义网格上构建金字塔型离散扩散模型,并搭配场景分块模块,依托重叠区域作为条件完成生成。
与PDD依托稠密网格、以重叠区域为条件的设计不同,本文方法以完整相邻分块作为条件,能够提供更丰富的上下文信息。受数据集本身限制,上述方法均存在几何质量不佳、场景高度变化不足的问题。
针对无边界室内场景生成任务,现有方法大多基于3D-Front[12]数据集开展训练,且默认将场景划分为立方体分块。BlockFusion[47]与SemCity思路一致,将场景分块压缩为三平面特征,同时额外使用一个变分自编码器(VAE)对三平面进一步降维,去除特征冗余,优化扩散模型的学习效果。LT3SD[33]则将基于临时有向距离场(TUDF)的场景分块编码为多级稠密特征网格隐特征树,自编码器与扩散模型均采用分层架构,实现分块由粗到细的生成。
这类特征表示在层高固定的室内场景中表现良好,但面对高度差异极大的户外环境时会出现明显缺陷,具体如图3所示。为解决该问题,本文采用向量集表示法:该方式可将不同尺寸的场景分块压缩为统一规格,不仅拥有更优异的压缩效果与综合性能,还结合专用外补绘制模型进一步提升生成速度。
其他户外无边界生成方法
还有部分研究采用不同技术路线实现户外无边界场景生成。CityDreamer[49]与InfiniCity[30]依托俯视视角完成无边界生成,但生成结果仅限城市场景,且几何分辨率较低。SceneDreamer[7]与Persistent Nature[5]是仅使用二维图像生成无边界三维场景的代表性工作,具备较大发展潜力;但由于缺少显式三维监督,最终生成的几何结构细节匮乏。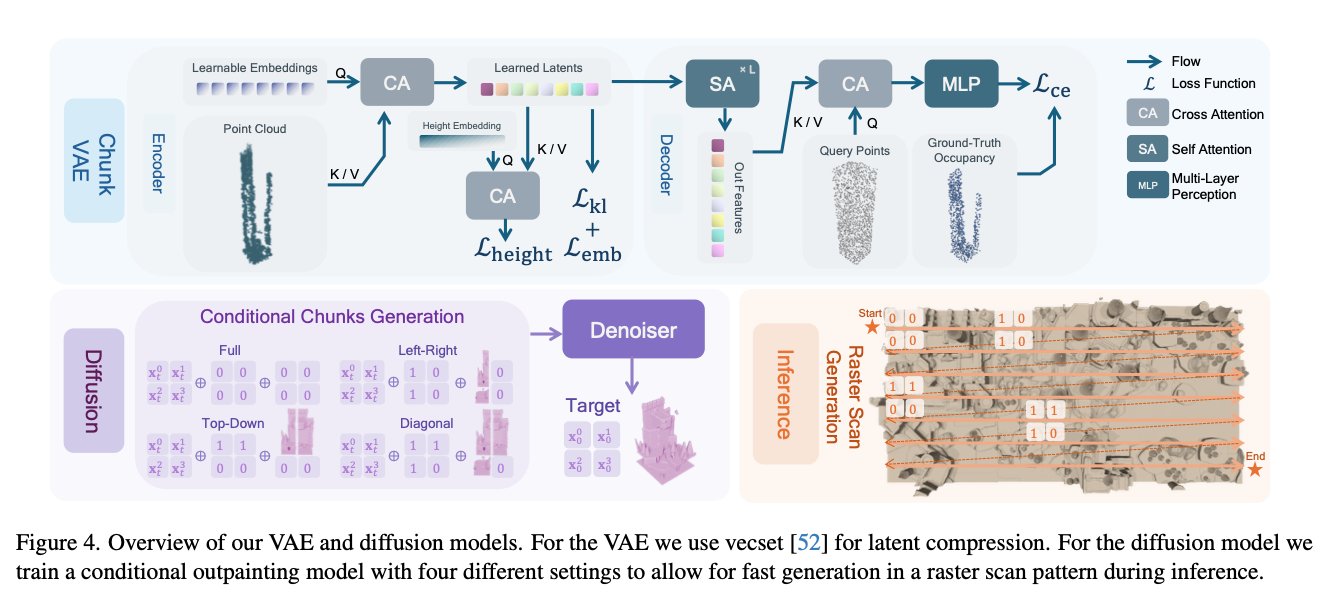
图4. 本文变分自编码器(VAE)与扩散模型整体架构。VAE部分采用向量集(vecset)[52]完成隐特征压缩;扩散模型为带条件约束的显式外补绘制模型,共设置四种约束模式,可在推理阶段以光栅扫描的方式快速生成场景。
3 方法
本文将大型户外场景拆解为若干局部场景分块。首先利用变分自编码器(VAE)将单个分块压缩为向量集形式的隐特征,再基于该隐特征训练扩散模型,实现以 2 × 2 2 \times 2 2×2 网格形式生成相邻场景分块。结合上述两个模型,即可完成连续、无边界的户外场景合成。本文的训练框架(见图4)沿用隐扩散模型(LDM)[38]的设计思路。
下文将在3.1节介绍数据集构建流程与训练分块的采样方式;为实现高效场景生成,本文对比了三平面隐特征与向量集隐特征两种方案,并在3.2节阐述变分自编码器主干网络,以及如何从隐特征解析得到占据信息;为提升推理速度,本文训练了专用显式外补绘制扩散模型,相关细节见3.3节;3.4节补充说明如何借助SceneTex[6]为场景添加纹理。
3.1 数据集
筛选与预处理
本研究首先借助DuoduoCLIP[25]的多视图嵌入特征对Objaverse[10]数据集做筛选,最终选出43个高质量场景。随后为所有场景标注相对尺度,建立统一的全局尺度标准。接着按照标注的相对尺度设定体素网格分辨率,将每个场景转换为占据网格,并结合移动立方体算法生成网格模型,用于后续点云采样。为保证不同场景的地面几何形态保持一致,本文在每个场景的地表下方设置固定厚度的体素层。更多细节可参考补充材料。

Q:占据网格和网格模型是什么?

图5. 经过本文预处理流水线处理后的示例场景。对占据网格执行移动立方体算法,即可得到对应的网格模型。
分块采样
图5展示了经预处理后的示例场景,其对应占据网格的维度为 1059 × 478 × 1059 1059 \times 478 \times 1059 1059×478×1059。为适配模型训练,沿 x y xy xy平面与 z z z轴方向,将整体场景划分为尺寸为 ( 50 , h v o x , 50 ) (50, h_{vox}, 50) (50,hvox,50) 的小型分块,其中 y y y轴为高度轴。分块采样规则为 occ [ i − 25 : i + 25 , : , k − 25 : k + 25 ] \text{occ}[i-25: i+25,:, k-25: k+25] occ[i−25:i+25,:,k−25:k+25], i i i、 k k k 分别代表场景在 x x x轴、 z z z轴方向的采样坐标。单个分块的体素高度 h v o x ≤ 478 h_{vox} \le 478 hvox≤478,由该分块内位置最高的被占据体素决定。

训练阶段,在分块的占据网格内采样坐标点 r v o x = ( x v o x , y v o x , z v o x ) r_{vox}=(x_{vox}, y_{vox}, z_{vox}) rvox=(xvox,yvox,zvox),坐标满足 0 ≤ x v o x , z v o x ≤ 50 0 \le x_{vox}, z_{vox} \le 50 0≤xvox,zvox≤50 且 0 ≤ y v o x ≤ h v o x 0 \le y_{vox} \le h_{vox} 0≤yvox≤hvox,同时提取每个坐标对应的真实占据值 o ˉ \bar{o} oˉ。随后对采样坐标执行归一化操作:
r = 2 ⋅ ( r v o x / d ) − 1 r=2 \cdot (r_{vox} / d)-1 r=2⋅(rvox/d)−1
式中 d = ( d x , d y , d z ) d=(d_{x}, d_{y}, d_{z}) d=(dx,dy,dz) 为各坐标轴对应的归一化尺度。
分块的真实高度计算公式为:
h ~ = 2 ⋅ ( h v o x / 50 ) − 1 \tilde{h}=2 \cdot (h_{vox} / 50)-1 h~=2⋅(hvox/50)−1
分块对应的点云采用相同规则完成归一化,此时归一化尺度统一设为 d = ( 50 , 50 , 50 ) d=(50,50,50) d=(50,50,50)。
大场景切小分块:水平固定 50×50,高度自适应
切分方式:用数组索引 i/k定位,中心截取 50 长度
内部采样:只采有实体的区域,不浪费算力
所有坐标 / 高度 / 点云:全部归一化到 [-1,1],适配神经网络训练
点云高度统一用 50 做基准,保证全场景标准一致

3.2 场景分块变分自编码器
3.2.1 编码器
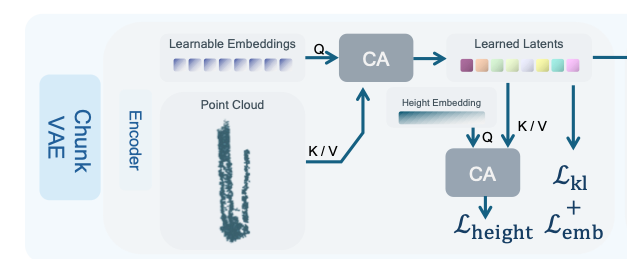
编码器 ε \varepsilon ε 负责将高度各不相同的场景分块集合 P P P,压缩为维度统一的向量集。对于任意分块 P i P_i Pi,首先从中均匀采样固定数量的点云 p ∈ R N p × 3 p \in \mathbb{R}^{N_p \times 3} p∈RNp×3,点云总数记为 N p N_p Np。本文参考3DShape2Vecset[52]的架构,使用交叉注意力(CA)层对点云特征进行聚合,依托一组可学习的固定特征大幅缩减特征令牌数量,得到紧凑的特征表示。
随后通过全连接(FC)层预测隐特征的均值与方差,并运用重参数化技巧[21]生成场景分块的嵌入特征,最终输出 z p = E ( p ) ∈ R V × c z^p=E(p) \in \mathbb{R}^{V \times c} zp=E(p)∈RV×c。其中 V V V 为向量数量, c c c 为特征通道数。
Q:重参数技巧的作用是什么?


实验发现,该基础结构容易出现变分自编码器典型的后验坍缩[42]问题。为此本文设计了一种新型正则化方案:从同一个场景分块 P i P_i Pi 中额外采样一组点云 q ∈ R N p × 3 q \in \mathbb{R}^{N_p \times 3} q∈RNp×3,约束两组点云对应的嵌入特征保持一致,对应的损失函数为:
L e m b = ( z p − z q ) 2 L_{emb}=(z^p-z^q)^2 Lemb=(zp−zq)2
该约束能够避免编码器忽略输入信息,确保同一场景分块采样得到的不同点云生成近似的嵌入特征,且额外计算开销极低,仅需多完成一次交叉注意力层与全连接层的前向传播。
Q:什么是后验坍缩?
A:
- 后验坍缩 = VAE 的编码器躺平,不管输入什么,都输出标准正态分布,隐特征失去作用;
- 本质原因:解码器太强,模型发现 “不用编码器也能重建,总损失更小”;
- 本文向量集 VAE 更容易坍缩:解码器是注意力架构,能力极强,且隐空间维度更低;
- 本文解决方案:同一个输入采样两次,约束两次输出的嵌入一致,断了编码器躺平的后路。
详解:


除此之外,本文基于嵌入特征预测场景分块的高度,用于在推理阶段剔除无效的占据值预测区域。由于推理阶段的嵌入特征由扩散模型生成,无法获取分块真实高度,因此该预测模块是必要的。
具体实现方式为:可学习的学习高度嵌入特征 e h ∈ R 1 × c e_h \in \mathbb{R}^{1 \times c} eh∈R1×c,将其与隐特征执行交叉注意力运算,再通过全连接层得到预测高度 h ¨ = FC ( CA ( z p , e h ) ) \ddot{h}=\text{FC}(\text{CA}(z^p, e_h)) h¨=FC(CA(zp,eh))。高度损失函数定义为:
L h e i g h t = ( h ^ − h ~ ) 2 L_{height}=(\hat{h}-\tilde{h})^2 Lheight=(h^−h~)2
其中 h ^ \hat{h} h^ 为模型预测高度, h ~ \tilde{h} h~ 为分块真实高度。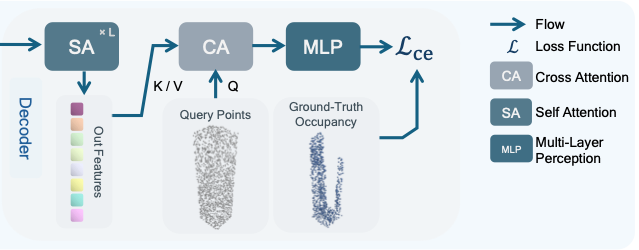
3.2.2 解码器
解码器将嵌入特征依次经过 L L L 层自注意力(SA)层处理,得到输出特征 f o u t = SA ( L ) ∘ ⋯ ∘ SA ( 1 ) ( z p ) f_{out} = \text{SA}^{(L)} \circ \dots \circ \text{SA}^{(1)}(z^p) fout=SA(L)∘⋯∘SA(1)(zp)。随后将输出特征输入三平面分支或向量集分支,解码得到空间占据信息。
三平面分支
对于三平面分支,先将 f o u t f_{out} fout 重塑为三平面结构,再参照LRM[16]的方式通过反卷积完成上采样,最终得到特征网格 T ∈ R 3 × h t r i × w t r i × c t r i T \in \mathbb{R}^{3 \times h_{tri} \times w_{tri} \times c_{tri}} T∈R3×htri×wtri×ctri。
Q: T ∈ R 3 × h t r i × w t r i × c t r i T \in \mathbb{R}^{3 \times h_{tri} \times w_{tri} \times c_{tri}} T∈R3×htri×wtri×ctri表示什么?
A:

按照3.1节规则对查询点 r t r i r_{tri} rtri 做归一化,此时归一化尺度设置为 d = ( 50 , 50 ⋅ S , 50 ) d=(50, 50 \cdot S, 50) d=(50,50⋅S,50),尺度因子 S S S 用于进一步压缩 y y y轴方向的坐标。为保证坐标取值落在 [ − 1 , 1 ] [-1, 1] [−1,1] 区间内、满足三平面采样要求,本文对坐标进行截断处理。本文定义三平面左边界与下边界为 − 1 -1 −1,右边界与上边界为 1 1 1。
通过双线性插值从三平面中提取特征并完成特征拼接,再经由全连接层预测查询点的占据值 o ^ r \hat{o}_r o^r。
三平面分支的本质是:把 3D 几何问题,拆解为三个 2D 图像问题来解决。
- 先把全局特征变成三个 2D 特征图;
- 把 3D 点投影到三个平面上,用插值取特征;
- 拼接特征后预测占据值。
它的所有优势(简单、易实现、速度快)和劣势(无法适配大高度差、Y 轴细节丢失),都源于这个核心设计。这也是为什么论文最终选择了向量集分支—— 它彻底打破了空间坐标的限制,完美适配户外场景高度多变的特点。

向量集分支
向量集分支中,查询点 r v e c r_{vec} rvec 的归一化尺度统一设为 d = ( 50 , 50 , 50 ) d=(50,50,50) d=(50,50,50)。依托交叉注意力机制完成占据值预测,计算方式如下:
o ^ r = FC ( CA ( f o u t , PE ( r v e c ) ) ) \hat{o}_r=\text{FC}(\text{CA}(f_{out}, \text{PE}(r_{vec}))) o^r=FC(CA(fout,PE(rvec)))
其中 PE \text{PE} PE 代表查询点的傅里叶位置编码。
向量集分支的本质是:把 “在固定网格上插值取特征”,变成了 “在全局特征字典里检索特征”。
- 坐标不需要压缩、不需要截断,三轴统一归一化;
- 用傅里叶位置编码把坐标变成高维特征;
- 用交叉注意力从全局向量集中检索该位置对应的特征;
- 全连接层输出占据概率。
这种设计彻底打破了空间结构化特征对尺度的限制,完美适配了户外场景高度多变的特点。
核心对比:
三平面分支的显存是空间结构化的平方级开销,其核心计算公式为:总显存 = 3 个正交平面 × 平面高度分辨率 × 平面宽度分辨率 × 单像素特征通道数 × 单元素字节数。显存大小完全由空间分辨率决定,任意一个空间维度(如高度)提升都会导致显存线性增长,若两个维度同时提升则会呈平方级暴涨;实际训练时还需叠加梯度、优化器状态的额外开销(约为参数显存的 3-4 倍),批量训练时再乘以批次大小,这是它无法工程化适配大高度户外场景的根本原因。
向量集分支的显存是全局非结构化的常数级开销,其核心计算公式为:总显存 = 全局向量数量 × 单向量特征通道数 × 单元素字节数。显存大小与场景的高度、宽度、分辨率完全无关,无论场景尺度多大,向量集的元素总数始终固定(如论文中 16×64=1024),实际训练的额外开销也成比例固定,不会随场景尺度增长,这是它在大尺度 3D 生成任务中具备压倒性显存优势的核心逻辑。
Q1: 为什么双线性插值只能处理 [-1,1] 区间内的坐标?
A1:
先纠正一个最关键的误解
双线性插值本身可以处理任何数值的坐标,它只是一个数学计算方法。 真正限制坐标必须在[-1,1]的,不是双线性插值,而是三平面的本质——它是一张有固定大小的“特征图片”。
第一步:先搞懂双线性插值到底在干什么(用你手机里的照片举例) 想象你手机里有一张照片,尺寸是 64×64像素(和论文里三平面的分辨率一模一样)。
- 这张照片是一个二维数组,每个格子就是一个像素;
- 像素的索引是整数,范围是
[0, 63](因为从0开始数,64个像素的索引就是0到63);- 比如左上角的像素索引是
(0, 0),右下角的是(63, 63)。双线性插值的作用 当你想知道“照片里某个非整数坐标的颜色”时,比如
(10.3, 20.7),它会找到这个点周围最近的4个像素((10,20)、(10,21)、(11,20)、(11,21)),然后根据距离远近加权平均,算出这个点的颜色。但有一个绝对的前提
你问的坐标,必须在照片的范围内。
- 如果你问
(100, 200)这个点的颜色——照片只有64×64大,根本没有这个位置的像素,双线性插值无中生有不出来;- 如果你问
(-5, 10)这个点的颜色——照片没有负数索引的像素,同样算不出来。
第二步:把照片的逻辑,1:1套用到三平面上 三平面的每个平面(XY、YZ、XZ),本质上就是一张64×64像素的“特征照片”,和你手机里的照片没有任何区别:
- 普通照片的像素存的是“颜色值(RGB)”;
- 三平面的像素存的是“特征向量(40维)”。
其他所有逻辑完全一样:
- 三平面的像素索引也是整数,范围
[0, 63];- 双线性插值只能在存在的像素之间计算;
- 只要坐标超出
[0, 63]的范围,就没有对应的像素,插值直接失败。
第三步:为什么要把坐标映射到[-1,1],而不是直接用[0,63]? 这是深度学习领域的通用标准化约定**,目的是“解耦坐标和特征图分辨率”。**
不管你用的是64×64、128×128还是256×256的三平面,所有物理坐标都先统一映射到[-1,1],再用一个通用公式转换成像素索引:
像素索引 = 归一化坐标 + 1 2 × ( 分辨率 − 1 ) \text{像素索引} = \frac{\text{归一化坐标} + 1}{2} \times (\text{分辨率} - 1) 像素索引=2归一化坐标+1×(分辨率−1)我们代入论文的参数算一遍(最关键的一步) 论文里三平面分辨率是64,所以
分辨率-1=63:
如果归一化坐标
r = -1:
像素索引 = − 1 + 1 2 × 63 = 0 \text{像素索引} = \frac{-1 + 1}{2} \times 63 = 0 像素索引=2−1+1×63=0
刚好对应三平面的第一个像素。如果归一化坐标
r = 1:
像素索引 = 1 + 1 2 × 63 = 63 \text{像素索引} = \frac{1 + 1}{2} \times 63 = 63 像素索引=21+1×63=63
刚好对应三平面的最后一个像素。如果归一化坐标
r = 1.1(超出了[-1,1]):
像素索引 = 1.1 + 1 2 × 63 = 66.15 \text{像素索引} = \frac{1.1 + 1}{2} \times 63 = 66.15 像素索引=21.1+1×63=66.15
三平面只有0到63的像素,没有66号像素,双线性插值直接报错,或者返回无效值。
第四步:回到论文的户外场景,看三平面的死局 论文里的摩天大楼高度是478个体素,X/Z轴是50个体素。 如果我们用向量集的归一化方式(三轴都用50做尺度),Y轴的归一化坐标是: r y = 2 × 478 50 − 1 = 18.12 r_y = 2 \times \frac{478}{50} - 1 = 18.12 ry=2×50478−1=18.12
把这个值代入像素索引公式: Y轴像素索引 = 18.12 + 1 2 × 63 = 602.28 \text{Y轴像素索引} = \frac{18.12 + 1}{2} \times 63 = 602.28 Y轴像素索引=218.12+1×63=602.28
三平面只有0到63的像素,602号像素根本不存在。
三平面只有两个选择,全是死路
选择1:提高三平面Y轴的分辨率到602
三平面的显存开销是平方级增长:
原来的显存开销: 3 × 64 × 64 × 40 = 491520 3 \times 64 \times 64 \times 40 = 491520 3×64×64×40=491520
现在的显存开销: 3 × 64 × 602 × 40 ≈ 4623360 3 \times 64 \times 602 \times 40 \approx 4623360 3×64×602×40≈4623360
显存直接翻了9.4倍,普通GPU根本装不下,工程上完全不可行。选择2:压缩Y轴坐标,让它落在[-1,1]
把Y轴的归一化尺度改成 50 × 9.56 = 478 50 \times 9.56 = 478 50×9.56=478,这样478体素的Y坐标归一化后刚好是1。
但这样一来,Y轴的1个归一化单位对应478个体素,而X/Z轴的1个归一化单位只对应50个体素——Y轴的细节被压缩了9.56倍,楼层、窗户等精细结构全部模糊。这就是引言里说的“三平面无法适配高度差异显著的户外场景”的根本原因。
最后对比向量集,就彻底懂了 向量集没有任何“特征图片”,它只有16个全局向量。 它不需要把坐标映射到任何像素索引上,自然也就没有“坐标范围”的限制。
- 不管Y轴坐标是1、10还是100,傅里叶位置编码都能把它转换成高维特征;
- 交叉注意力会拿着这个位置特征,去16个全局向量里检索对应的信息;
- 整个过程没有任何“索引越界”的问题,也不需要压缩任何维度。
一句话终极总结
双线性插值是“在一张固定大小的纸上找颜色”,坐标超出纸的范围就找不到了; 而向量集是“在一本字典里查信息”,不管你问的是第几页的内容,只要字典里有,就能查得到。
Q2:为什么傅里叶位置编码得到的是 2×L 维的特征向量,2 是什么含义?
A2:




损失函数
本文采用二元交叉熵损失 L c e = BCE ( o ^ r , o ~ r ) L_{ce}=\text{BCE}(\hat{o}_r, \tilde{o}_r) Lce=BCE(o^r,o~r) 监督占据值预测, o ~ r \tilde{o}_r o~r 为真实占据值;同时引入KL散度损失 L k l L_{kl} Lkl 约束嵌入特征的分布,相关细节可参考Zhang等人的工作[52]。
模型总损失函数为:
L = λ k l L k l + λ e m b L e m b + λ c e L c e + λ h e i g h t L h e i g h t L=\lambda_{kl} L_{kl}+\lambda_{emb} L_{emb}+\lambda_{ce} L_{ce}+\lambda_{height} L_{height} L=λklLkl+λembLemb+λceLce+λheightLheight
式中 λ \lambda λ 为各项损失对应的权重系数。
与三平面表示不同,向量集表示允许查询点坐标超出 [ − 1 , 1 ] [-1, 1] [−1,1] 范围。这是因为交叉注意力与位置编码可直接处理任意取值的坐标,无需将坐标限制在固定区间内。
推理阶段解码
推理阶段无法获取分块的真实高度 h ~ \tilde{h} h~,因此使用模型预测高度 h ^ \hat{h} h^ 剔除无效计算区域,具体流程如下:
- 模型首先预测出当前分块的高度 h ^ \hat{h} h^;
- 在尺寸为 ( 50 , 50 ⋅ ( h ^ + 1 ) / 2 , 50 ) (50, 50 \cdot (\hat{h}+1)/2, 50) (50,50⋅(h^+1)/2,50) 的空间范围内生成全部查询坐标 r v o x r_{vox} rvox;
- 按照公式 r = 2 ⋅ ( r v o x / d ) − 1 r=2 \cdot (r_{vox} / d)-1 r=2⋅(rvox/d)−1 对坐标做归一化;
- 利用归一化坐标查询隐特征,得到所有位置的占据预测结果;
- 对占据体素场执行移动立方体算法,重构出场景分块的网格模型。
Q:尺寸为 ( 50 , 50 ⋅ ( h ^ + 1 ) / 2 , 50 ) (50, 50 \cdot (\hat{h}+1)/2, 50) (50,50⋅(h^+1)/2,50) 的空间范围是什如何计算的?

3.3 扩散模型
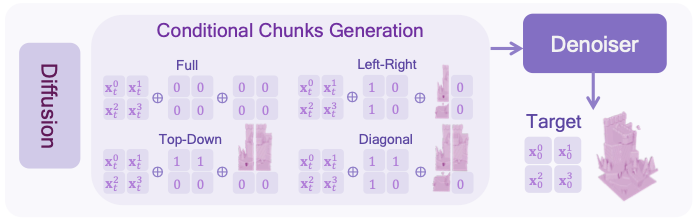
现有方法[27,33,47]大多依靠RePaint[32]实现外补绘制,该方案需要执行额外的扩散迭代步骤,运行效率较低。为此本文设计了更高效的实现方案:所提外补绘制扩散模型可一次性生成 2 × 2 2 \times 2 2×2 网格内的4个场景分块,并依托多种约束模式,以已生成分块为条件完成上下文约束,支持按照光栅扫描顺序实现连续场景生成,四种约束模式见图4。
本文采用DDPM[15]构建扩散概率模型。训练阶段,从场景中采样一组呈 2 × 2 2 \times 2 2×2 网格排布的相邻分块隐特征 { z 0 , z 1 , z 2 , z 3 } \{z^0, z^1, z^2, z^3\} {z0,z1,z2,z3},该组特征由变分自编码器编码得到,分块排布顺序见图4。
Q1:VAE 编码器永远只输入 1 个分块的点云,输出该分块的 16×64 维向量集隐特征,也就是编码器每次只处理 50h50 这个区域的 3d 块?
A1:编码器永远只处理单个 50×h×50 的 3D 分块,输入一个分块的点云,输出一个 16×64 的向量集特征,没有任何例外。
Q2:在整个处理过程中,有多个编码器在同时进行,然后在 diffusion 阶段,再一起进行 2*2 区域生成?
A2:没有多个编码器同时运行。训练扩散模型的时候,VAE 已经完全训练好了、固定不动了。我们会提前把整个数据集所有分块的 16×64 特征都编码好,存在硬盘里,训练扩散时直接读这些预存的特征,根本不会再跑编码器。
Q3:那么解码器的输入是一个分块还是前面扩散模型输出的多个分块的结果?
A3:解码器也永远只输入单个分块的 16×64 特征,输出一个分块的 3D 几何。扩散模型输出的 2×2 特征,会被拆成 4 个独立的分块,每个分块单独过解码器,最后在几何空间拼接成大场景。
每一轮训练中,首先随机选取时间步 t ∈ [ 1 , T ] t \in [1, T] t∈[1,T],并采样高斯噪声 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I),将噪声叠加到嵌入特征组上,得到含噪隐特征 X t = { x t 0 , x t 1 , x t 2 , x t 3 } ∈ R 4 × V × c X_t=\{x_t^0, x_t^1, x_t^2, x_t^3\} \in \mathbb{R}^{4 \times V \times c} Xt={xt0,xt1,xt2,xt3}∈R4×V×c。其中 x t i ∈ R V × c x_t^i \in \mathbb{R}^{V \times c} xti∈RV×c 代表第 i i i 个分块在时间步 t t t 下的含噪隐特征。
扩散模型将含噪隐特征 x t x_t xt 作为输入,同时接收二值掩码与对应条件嵌入特征。掩码用于标记已生成的分块,条件嵌入特征则为外补绘制提供上下文信息。本文共设计四种约束配置,每种配置对应专属掩码 M M M 与条件嵌入特征 Z c o n d Z_{cond} Zcond,如图4所示。
掩码定义为 M = { m 0 , m 1 , m 2 , m 3 } ∈ R 4 × V × 1 M=\{m^0, m^1, m^2, m^3\} \in \mathbb{R}^{4 \times V \times 1} M={m0,m1,m2,m3}∈R4×V×1,掩码取值分为四类组合: { 0 , 0 , 0 , 0 } \{0, 0, 0, 0\} {0,0,0,0}、 { 1 , 0 , 1 , 0 } \{1, 0, 1, 0\} {1,0,1,0}、 { 1 , 1 , 0 , 0 } \{1, 1, 0, 0\} {1,1,0,0}、 { 1 , 1 , 1 , 0 } \{1, 1, 1, 0\} {1,1,1,0},其中 0 , 1 ∈ R V × 1 0, 1 \in \mathbb{R}^{V \times 1} 0,1∈RV×1。
结合上述四类掩码组合,条件嵌入特征 Z c o n d Z_{cond} Zcond 依次构建为: { 0 , 0 , 0 , 0 } \{0, 0, 0, 0\} {0,0,0,0}、 { z 0 , 0 , z 2 , 0 } \{z^0, 0, z^2, 0\} {z0,0,z2,0}、 { z 0 , z 1 , 0 , 0 } \{z^0, z^1, 0, 0\} {z0,z1,0,0}、 { z 0 , z 1 , z 2 , 0 } \{z^0, z^1, z^2, 0\} {z0,z1,z2,0},式中 0 ∈ R V × c 0 \in \mathbb{R}^{V \times c} 0∈RV×c。
将掩码 M M M、条件嵌入特征 Z c o n d Z_{cond} Zcond 与位置编码 PE \text{PE} PE 进行拼接,得到扩散模型的最终条件输入:
C = M ⊕ Z c o n d ⊕ PE C=M \oplus Z_{cond} \oplus \text{PE} C=M⊕Zcond⊕PE
本文选用Craftsman[29]提出的类UNet Transformer作为去噪网络 ϵ θ \epsilon_\theta ϵθ。模型的训练目标为对含噪隐特征做去噪处理,损失函数如下:
E X , C , ϵ ∼ N ( 0 , I ) , t [ ∥ ϵ − ϵ θ ( ( X t ⊕ C ) , t ) ∥ 2 2 ] \mathbb{E}_{X, C, \epsilon \sim \mathcal{N}(0, I), t}\big[\|\epsilon-\epsilon_\theta\left(\left(X_t \oplus C\right), t\right)\|_2^2\big] EX,C,ϵ∼N(0,I),t[∥ϵ−ϵθ((Xt⊕C),t)∥22]
扩散模型训练过程中,会随机选用四种约束配置中的一种,并加载对应的掩码与条件嵌入特征。关于光栅扫描式生成的更多细节可参考补充材料。

完整流程时间线(从数据到最终生成)
阶段一:单独训练VAE(和扩散没有任何关系)
目标:造一个“3D分块→16×64向量”的压缩器和解压器
- 从大场景中随机采样单个50×h×50的分块
- 从这个分块的表面采样4096个点云
- 点云输入编码器 → 输出16×64的向量集特征
- 特征输入解码器 → 重建出这个分块的3D占据网格
- 用重建损失+KL损失+嵌入一致性损失训练VAE
- 训练完成后,VAE的编码器和解码器就固定不动了,永远不再修改
阶段二:单独训练扩散模型(和3D几何没有任何关系)
目标:学会“用已知的16×64向量,生成相邻的16×64向量”
- 预编码所有分块:用刚才训练好的固定编码器,把数据集中所有可能的分块都编码成16×64的向量,全部存在硬盘上(这就是论文里说的620万个可采样分块的来源)
- 采样2×2训练样本:从硬盘上预存的向量里,随机采样4个有25个体素重叠的相邻分块的向量,按空间顺序拼成一个2×2的特征网格(形状:[2,2,16,64])
- 加噪训练:对这个2×2特征网格加噪声,然后让扩散去噪器预测噪声
- 多模式条件训练:随机用四种掩码(全0、左右、上下、对角线)遮住部分分块,让模型学会根据已知分块生成未知分块
- 训练完成后,扩散模型也固定不动了
阶段三:推理生成(无边界大场景)
目标:用训练好的两个模型,生成任意大小的3D场景
- 扩散模型先生成一个初始的2×2特征网格
- 用滑动窗口的方式,每次保留3个已知分块作为条件,生成下一个相邻的分块
- 重复这个过程,生成任意大小的N×N特征网格
- 把N×N特征网格拆成N²个独立的16×64向量
- 每个向量单独输入固定的VAE解码器,得到N²个3D分块
- 把所有3D分块按空间位置拼接起来,去掉重叠区域,得到最终的无边界大场景
3.4 场景纹理映射
本文可选用SceneTex[6]为生成的场景添加纹理。针对户外大场景,本文对相机参数进行优化调整,相比SceneTex默认的球面相机,能够实现更全面的场景覆盖。
具体操作:在Blender软件中手动设置相机运动轨迹与移动速度并添加关键帧;根据场景形态与尺度差异,最终生成1200至1800个关键帧,用于SceneTex的训练。将整体场景归一化至 [ − 1 , 1 ] 3 [-1,1]^3 [−1,1]3 空间范围,相机视场角设置为 40 ∘ 40^\circ 40∘,近裁剪距离设为 0.01 m 0.01\ \text{m} 0.01 m。更多细节见补充材料。
4 实验
4.1 数据集
单场景实验采用图5中的预处理场景开展训练。实验不再单独采样小型分块,而是选取尺寸为 ( 100 , h v o x , 100 ) (100, h_{vox}, 100) (100,hvox,100) 的四分块进行采样,该四分块由 2 × 2 2 \times 2 2×2 排布、尺寸为 ( 50 , h v o x , 50 ) (50, h_{vox}, 50) (50,hvox,50) 的小型分块构成。采样规则为 occ [ i − 50 : i + 50 , : , k − 50 : k + 50 ] \text{occ}[i-50: i+50,:, k-50: k+50] occ[i−50:i+50,:,k−50:k+50],沿场景的 x x x 轴与 z z z 轴完成采样。实验总计采样10万个四分块,其中9.5万个作为训练集,5000个作为验证集。这些四分块彼此存在重叠,但因采样坐标不同,内容并不重复。
单场景生成是 3D 领域一个专门的研究方向,它的任务定义非常明确:
只用一个完整的 3D 场景的全部数据来训练模型,然后生成与该场景风格、结构完全一致的无限扩展内容。
这个任务的挑战在于:模型不能从其他任何场景中借用特征,必须完全从这一个场景里学习到所有的几何规律、建筑风格和空间关系,然后合理地外推生成从未见过的部分。很多之前的方法在这个任务上会严重过拟合,只能机械复刻训练数据里的结构,无法生成新的合理内容。
单场景续连实验的本质是 “场景语法学习”:模型不是记住了图 5 里的每一块石头,而是学会了 “城堡应该怎么建”—— 比如塔楼应该放在城墙的转角处、护城河应该围绕城堡、屋顶应该是尖顶的等等。学会了这些语法规则后,模型就可以无限生成符合这些规则的全新城堡结构。
本实验将单次输入的四分块数量定义为批次大小。在变分自编码器训练阶段,每个四分块会被拆分为4个小型分块,最终得到38万个训练样本与2万个验证样本。针对扩散模型训练,先使用变分自编码器对四分块对应的点云完成编码,再将得到的隐特征送入扩散模型。
多场景实验在原有单一场景的基础上额外增加3个场景参与训练,最终从全部场景中累计采样30万个四分块。
4.2 评价指标
重建任务:参照Zhang等人[52]的评估方案,在验证集上对比真实分块与重建分块,采用倒角距离(CD)、F分数与交并比(IoU)作为重建评价指标。计算倒角距离与F分数时,为每个分块采样5万个点,阈值设定为 2 / 50 2/50 2/50(即小型分块的体素边长)。计算交并比时,总共采样2万个占据值,其中1万个取自被占据区域与未被占据区域,另外1万个取自模型近表面区域。
生成任务:采用**弗雷歇点云网络距离(FPD)与核点云网络距离(KPD)**评估扩散模型的生成质量,评估流程同样遵循Zhang等人[52]的方案。本文使用Point-E[34]中的PointNet++模型,并按照Yan等人[50]的实验规则执行。具体流程为:从扩散模型中采样1万个四分块,提取每个四分块的表面点云(单块包含2048个点),再与原始场景中采样的1万个四分块进行对比,计算对应指标。
4.3 模型与对比基线
本文选用在过往研究中被广泛应用的三平面表示作为基线模型[27,47]。本工作未直接采用BlockFusion的三平面架构,原因是该架构需要为数据集中所有分块拟合三平面特征,基于3D-Front数据集完成该流程需要数千小时的GPU算力。因此本文选用基于LRM[16]架构的变分自编码器主干网络(详见3.2节)。
本文排除了稠密网格类方法[31,33]:稠密网格的显存占用会随分辨率呈三次方增长,而三平面仅为二次方增长;在本任务中,部分场景分块的高度可达其 x 、 z x、z x、z 轴维度的8.5倍,会进一步加剧稠密网格的显存消耗。与此同时,LT3SD[33]要求自编码器与扩散模型均执行多尺度训练,会显著增加整体训练耗时。
变分自编码器配置
- 三平面基线模型:设置隐特征数量 V = 3 × 4 2 V=3 \times 4^2 V=3×42,调整归一化尺度因子 S S S 与反卷积层数(反卷积层数决定模型输出分辨率),相关配置见表1。
- 向量集模型:设置向量数量 V = 16 V=16 V=16,该配置在保留几何保真度的同时,能够支撑扩散模型高效训练。
两类特征表示统一设置特征通道数 c = 64 c=64 c=64,单分块采样点云数量 N p = 4096 N_p=4096 Np=4096;三平面分支的输出通道数 c t r i = 40 c_{tri}=40 ctri=40。解码器共包含 L = 24 L=24 L=24 层自注意力层。所有变分自编码器模型均训练160轮,每次迭代会为每个分块采样4096个查询点,用于占据值的监督学习。
扩散模型配置
所有扩散模型均采用25层类UNet Transformer[29]作为去噪主干网络。三平面扩散模型基于变分自编码器输出的隐特征训练,三平面输出分辨率设为 h t r i = w t r i = 64 h_{tri}=w_{tri}=64 htri=wtri=64,尺度因子 S = 6 S=6 S=6。所有扩散模型统一训练320轮,批次大小设置为192。由于扩散模型会一次性生成 2 × 2 2 \times 2 2×2 网格内的4个分块,Transformer的输入令牌长度为 4 × V 4 \times V 4×V。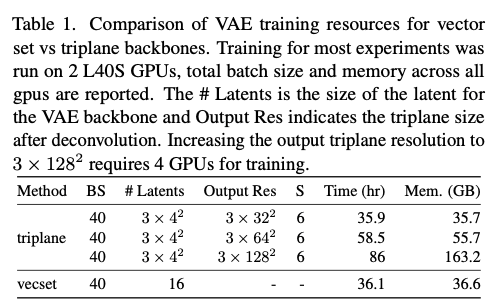
表1 向量集与三平面主干网络的变分自编码器训练资源对比。大部分实验基于2块L40S显卡运行,表中批次大小与显存为所有显卡的合计数值。隐特征数量代表变分自编码器主干的隐特征规模,输出分辨率为反卷积处理后的三平面尺寸。将三平面输出分辨率提升至 3 × 128 2 3 \times 128^2 3×1282 时,需要使用4块显卡完成训练。
4.4 单一场景实验
单场景实验主要用于对比向量集表示与三平面这类空间结构化隐特征的性能。4.4.1节展示变分自编码器的重建结果,4.4.2节对比扩散模型的综合表现。实验证明,向量集具备更优异的压缩能力,训练效率与生成效果均全面优于三平面。
4.4.1 变分自编码器重建
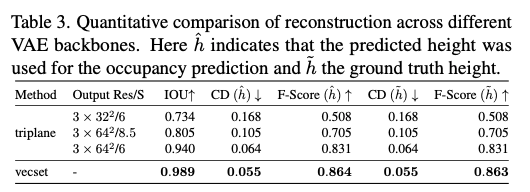
表3 不同变分自编码器主干网络的重建结果定量对比。 h ^ \hat{h} h^ 代表采用模型预测高度计算占据值, h ~ \tilde{h} h~ 代表采用真实高度计算占据值。
表3为各类模型的重建量化结果,可以看出向量集模型的重建效果优于所有三平面配置。实验分别使用**预测高度 h ^ \hat{h} h^与真实高度 h ~ \tilde{h} h~**重构网格并计算倒角距离、F分数,两组结果数值高度接近,这也验证了本文高度预测模块具备较高的精度。
对于三平面模型而言,其性能受限于变分自编码器的输出分辨率:当输出分辨率从 3 × 32 2 3 \times 32^2 3×322 提升至 3 × 64 2 3 \times 64^2 3×642 时,模型重建效果逐步提升。但针对高层建筑场景,若建筑高度超出尺度因子 S = 6 S=6 S=6 的适配范围,三平面采样阶段的坐标截断操作会导致高层建筑结构无法完整重建。若将尺度因子 S S S 调整至8.5(匹配数据集内最高分块的高度), y y y 轴方向会被过度压缩,造成精度大幅下降,模型整体性能明显退化。
虽然可通过反卷积将分辨率进一步提升至 128 2 128^2 1282,但该配置需要4块L40S显卡才能完成训练(见表1)。反观向量集模型,其隐特征数量仅为16,压缩效率更高;同时训练耗时、显存占用与最低分辨率的三平面模型基本持平,充分证明向量集在场景分块表征任务中兼具高效性与高性能。更多实验结果见补充材料。
4.4.2 扩散模型
生成质量
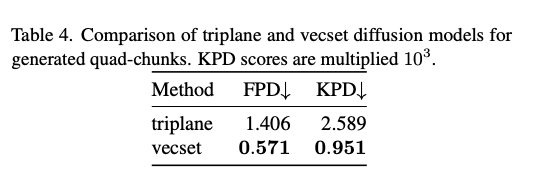
表4 三平面与向量集扩散模型针对四分块生成结果的指标对比。KPD指标的数值均乘以 10 3 10^3 103。
表4展示了FPD与KPD两项指标的对比结果,向量集扩散模型的性能明显优于三平面基线模型。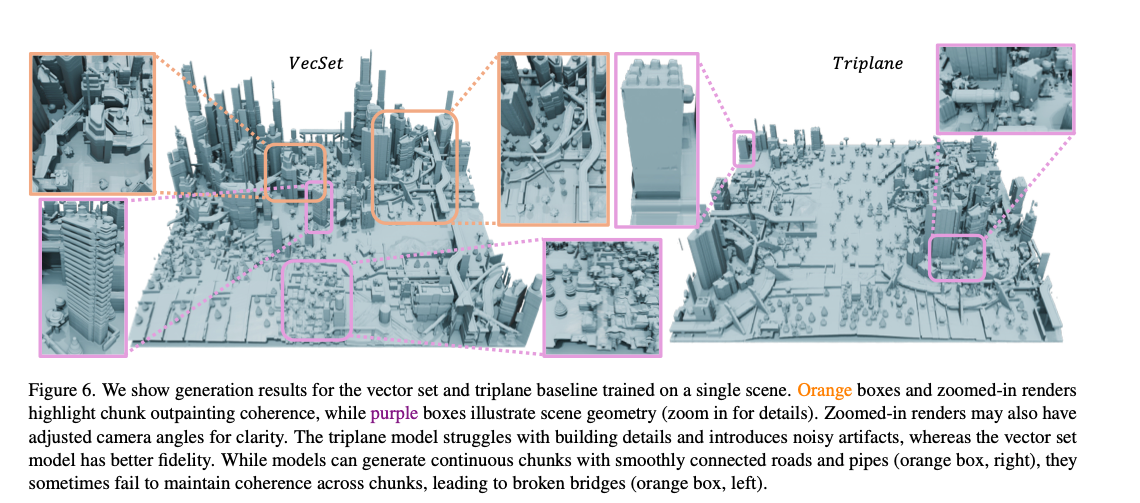
图6 基于单一场景训练的向量集与三平面模型生成结果对比。橙色框及局部放大视图用于展示分块外补绘制的连贯性,紫色框用于展示场景整体几何结构(放大可查看细节)。为便于观察,放大视图调整了相机角度。可以看到,三平面模型难以还原建筑细节,还会产生噪声伪影;向量集模型的几何保真度更高。两类模型均能生成道路、管道等衔接自然的连续分块(右侧橙色框),但偶尔会出现分块衔接失效的问题,例如桥梁断裂、结构不连续(左侧橙色框)。
图6为规模 21 × 21 21 \times 21 21×21 的场景可视化结果。三平面模型无法还原精细的建筑细节,还易产生噪声伪影,这也是其FPD、KPD指标偏高的核心原因,问题根源在于 y y y 轴方向查询点的压缩处理。结合表2可知,向量集模型的训练速度约为三平面模型的2.5倍,显存占用仅为后者的一半。这是因为向量集对应的令牌总数更少,令牌数量仅为三平面模型的三分之一。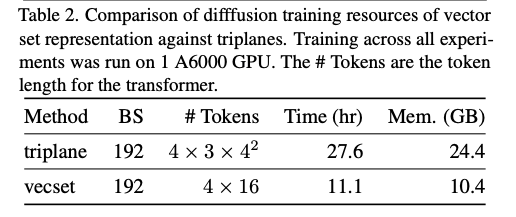
表2 向量集表示与三平面表示的扩散模型训练资源对比。所有实验基于1块A6000显卡运行。令牌数量为Transformer的输入令牌长度。
外补绘制效果
本文将所提方法与RePaint[32]开展对比,该方法是过往多项无边界场景生成研究[27,33,47]中主流的外补绘制方案。实验中保持场景生成顺序、分块重叠规则与本文方法完全一致。RePaint会将掩码与条件嵌入特征置零,依靠迭代重采样机制引入已有分块的上下文约束。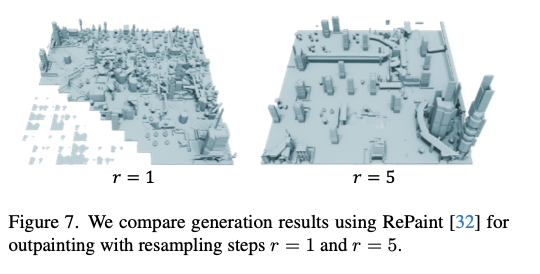
图7 对比RePaint外补绘制在重采样步数 r = 1 r=1 r=1 与 r = 5 r=5 r=5 时的生成效果。
当重采样步数 r = 1 r=1 r=1 时,分块之间的衔接性极差,甚至出现场景结构崩塌,推测原因是模型以扩散生成的含噪分块作为约束条件;当重采样步数提升至 r = 5 r=5 r=5 时,场景连贯性有所改善,但生成内容的多样性下降,同时依旧存在结构崩塌问题(详见补充材料)。
除此之外,RePaint的推理速度远低于本文的显式外补绘制方案(见表5),其推理耗时会随重采样步数增加而线性上升,而本文方法无需额外的重采样步骤。本文设计的外补绘制框架支持并行计算,也可迁移至[33,47]等现有方法中,进一步提升整体生成速度。
表5 推理耗时对比。基于RTX 2080 Ti显卡重复5次实验并取平均值,分别统计采用5次重采样的RePaint方案、三平面显式外补绘制模型、向量集显式外补绘制模型生成 21 × 21 21 \times 21 21×21 规模场景的耗时,统计维度分为嵌入特征生成耗时、占据值解码耗时两类。
本文的外补绘制方案仍存在一定缺陷,部分分块的衔接区域依旧会出现错位、噪声伪影等问题。如图6右侧橙色框所示,向量集扩散模型能够生成衔接连贯的分块;但左侧橙色框中出现了桥梁错位、分块之间存在缝隙与断层等问题。
4.5 多场景实验
4.4节的单场景实验已经验证:向量集表示可以有效处理高度多变的场景分块,同时本文的外补绘制模型能够实现大规模户外场景的快速生成。但仅基于单一场景训练时,模型生成的子场景会高度贴近训练数据,即便可以生成部分全新布局,内容多样性依旧有限(详见补充材料)。
为验证模型的泛化能力,同时检验NuiScene43数据集构建流程的有效性,本文基于向量集主干网络,在原有单一场景的基础上额外加入3个场景开展联合训练。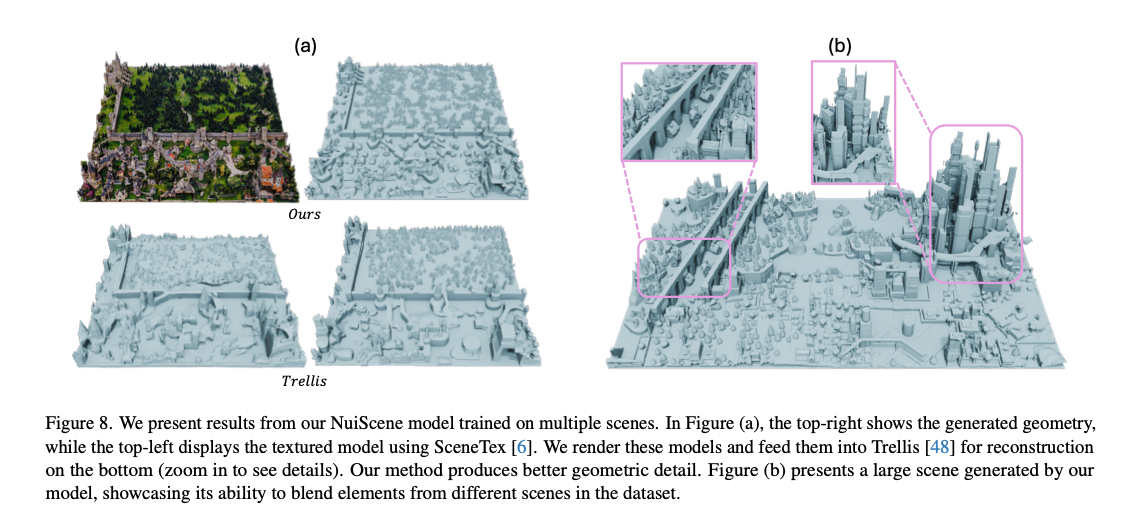
图8 (b) 本文多场景训练模型生成的大尺度场景。图中紫色框标注区域展示了模型融合不同原始场景元素(乡村民居、引水渠、摩天大楼)的效果。
图8(b)展示了多场景训练模型的生成结果。可以明显看到,模型能够融合乡村民居、引水渠、摩天大楼等来自不同原始场景的元素,而这类元素组合在训练数据中并不存在。该结果一方面证明模型具备良好的泛化能力,另一方面也验证了本文的数据集预处理方案,能够将风格差异极大的场景统一为可联合训练的标准数据,让模型实现不同环境分块的自然拼接。
本文还将所提方法与目前性能顶尖的图像转三维物体生成模型Trellis[48]开展对比,实验采用未进行网格简化的TRELLIS-image-large版本。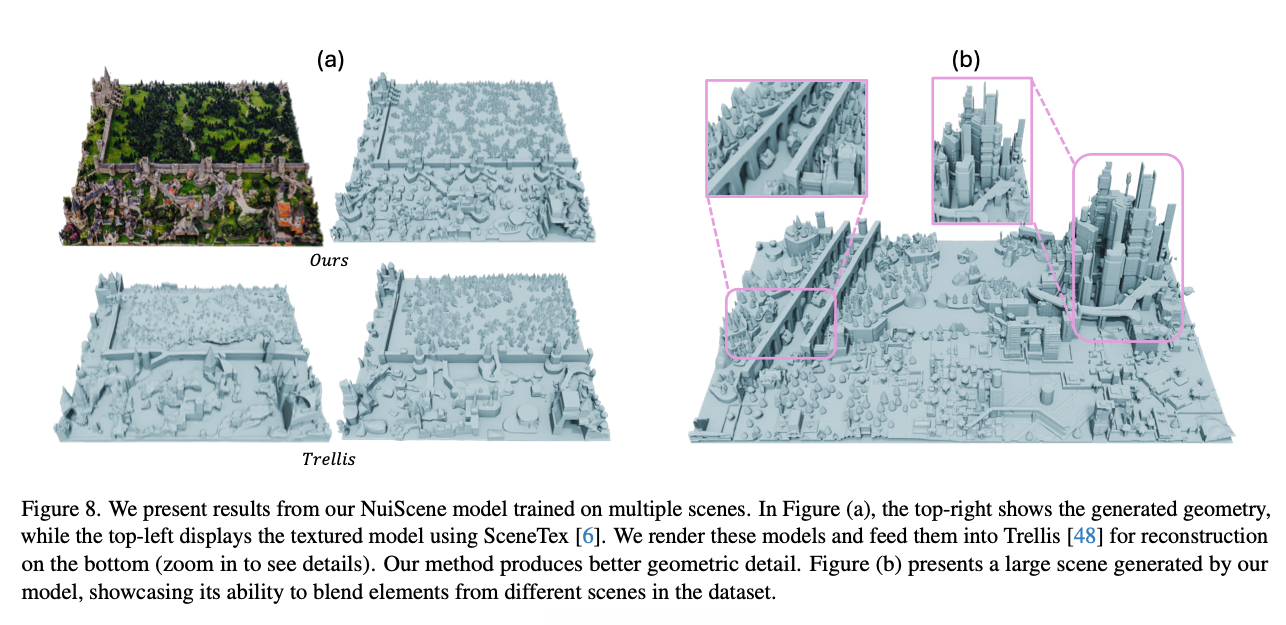
图8 (a) 本文模型与Trellis模型的效果对比。右上方为本文方法生成的几何结构,左上方是使用SceneTex[6]添加纹理后的效果;下方为对应渲染图输入Trellis后得到的重建结果(放大可查看细节)。本文方法生成的几何细节更加丰富。
由图8(a)可见,Trellis生成的几何结构细节较为粗糙。这类模型将完整场景映射为单一隐特征,该结构使其很难在大尺度环境中保留精细的几何信息。而本文对每一个场景分块进行独立编码,既能够生成细节更丰富的结构,也天然支持无边界场景的拓展。这也暴露出现有三维物体生成模型的核心缺陷:无法适配无边界大场景生成任务。
5 局限性
本研究目前仍存在多处局限,具体如下:
第一,现有方案需要离线预采样大量场景分块,会产生极高的存储开销,因此现阶段仅能使用少量场景完成训练。若采用效率更高的在线分块采样方案,就可以充分使用完整的NuiScene43数据集进行训练,同时还有望改善分块间连贯性不足的问题,缓解模型忽略上下文条件、生成结构断裂或分块错位的现象。
第二,本文的生成模型暂不支持人为控制与条件生成,原因是尚未为场景分块添加语义标签。后续可结合大基础模型[1,22]半自动生成语义图、文本描述等标注信息,在训练阶段引入条件约束,实现可控场景生成。该问题也是[27,31,33,47]等现有同类方法普遍存在的短板。
第三,模型仅能感知局部区域信息,缺少全局上下文建模能力,无法完成大范围的整体布局规划。未来可以探索具备全局规划能力的模型,模拟人工设计思路,生成路网连贯、整体布局合理的大型城区等场景。
最后,随着三维数据集[9]不断丰富,本研究希望能够打通两类主流技术路线的壁垒:一类是以WonderWorld[51]为代表、依托文生图像二维先验实现开放域虚拟世界生成的方法;另一类是直接基于三维数据训练的生成模型。从技术发展脉络来看,DreamFusion[35]依托文生图像先验实现物体级三维生成,而Trellis等模型直接基于三维数据训练,获得了更快的生成速度与更优的内容一致性。本文同样采用三维数据监督训练,但数据集规模仍有提升空间。后续计划通过半自动化流程完善数据集构建流水线,进一步扩充数据规模。即便如此,本文所构建的数据集也可作为无边界户外场景生成领域的标准评测基准。
6 结论
本文提出NuiScene方法,可用于生成风格多样、范围广阔的户外场景。针对户外场景高度变化剧烈、场景分块难以高效压缩的核心难题,本文采用向量集完成场景分块编码;同时设计显式外补绘制扩散模型,在提升场景连贯性的同时缩短推理耗时。为推动该领域研究,本文构建了NuiScene43数据集,其中包含大量风格各异的中大型户外场景,可支撑多类异质场景的联合训练。
内补绘制:补全场景中间的缺失区域(比如去掉照片里的一个人)
外补绘制:从已有场景的边缘向外,补画周围全新的未知区域(比如把一张照片的左右两边拉长)
显式:实现方式 —— 训练时就专门教模型做这个任务,推理时直接用
思考
现有3D场景生成研究大多聚焦室内固定层高场景,传统三平面、稠密特征网格这类空间结构化隐特征难以适配高度起伏剧烈的户外城堡、摩天建筑群,同时主流无限场景外扩方案依赖RePaint等基于反复重采样的修复式外绘策略,推理速度极慢且相邻分块几何衔接连贯性差,另外缺少经过尺度统一、地面几何标准化处理的高质量户外场景数据集支撑异构场景联合训练,以上现实痛点构成了本方法的研究动机;
整套方法完整流程为:首先对Objaverse原始模型做过滤筛选、尺度标注对齐、地面几何修正、体素占据网格转换等预处理,构建NuiScene43标准化户外场景数据集,从场景中采用重叠四分块策略采样训练样本,训练阶段搭建VAE+条件扩散模型架构,VAE将尺寸可变的场景分块统一编码为固定维度向量集隐特征,再以2×2四分块网格为单元训练具备多掩码条件模式的显式外补绘制扩散模型;推理时采用光栅扫描滑动窗口策略,从初始2×2特征网格逐块向外条件生成完整隐特征网格,全部生成完毕后逐个送入VAE解码器还原3D占据网格,再通过移动立方体算法得到完整几何网格,可选接入预训练SceneTex工具,通过Blender自定义蛇形相机多视角渲染监督迭代优化纹理场,输出带完整纹理的可视化3D大场景;
本方法核心创新包含四点:一是采用向量集隐表示替代传统三平面结构,实现不同竖直高度分块的统一紧凑编码,大幅降低高起伏户外场景的内存开销,二是设计显式外补绘制扩散范式,训练时就针对性学习相邻完整分块的条件外扩任务,摒弃RePaint重复重采样逻辑,三是构建NuiScene43标准化户外场景数据集,完成尺度、地面几何统一,支持多异构场景联合训练,四是光栅扫描式并行推理策略可进一步加速大场景生成;
应用效果上,该模型既可在单城堡场景内无缝向外无限扩建同风格建筑,也能在4场景、13场景联合训练后融合不同城市、古堡风格生成全新连贯大型户外场景,定量重建IoU指标显著优于三平面基线,几何细节保留完整,不会出现结构漂浮、空洞破碎等问题;相较于三平面、RePaint基线方法,向量集隐特征压缩效率更高、细节重建精度更强,显式外绘方案不存在分块衔接断层、生成崩溃缺陷,同时推理速度大幅领先,在RTX 2080 Ti显卡上生成21×21分块大场景时,RePaint方案隐特征生成耗时1022.20s,本方法显式外绘仅需215.92s,解码耗时虽略有增加,但总推理耗时更低;
训练资源方面,单场景VAE训练可使用2块GPU耗时36.1小时完成,扩充批次使用4块L40S GPU可压缩至21.6小时,但会出现轻微过拟合,多场景联合训练可根据样本量灵活扩展GPU数量;推理硬件依托RTX 2080 Ti即可完成完整大场景生成,隐特征扩散生成、占据网格解码两个阶段耗时可拆分统计,无需重采样迭代,大场景生成耗时线性可控,支持任意尺寸无边界场景连续扩展。
补充材料

图9. 在13个场景上训练的向量集扩散模型的额外生成结果。我们分别展示了两个场景的顶部航拍放大图和底部街景图。这里展示的场景大小为16×46。
A. NuiScene43数据集
我们从Objaverse中筛选场景,得到43个高质量的中大型场景(A.1节)。为了在场景之间建立统一的尺度,我们对场景进行相对尺度标注,将它们对齐到统一的尺度下(A.2节)。最后,我们通过采样点云、调整地面几何结构并将其转换为占据网格,对原始的Objaverse网格文件进行预处理,以用于训练(A.3节)。此外,我们还描述了用于从场景中采样四分块的采样图(A.4节)以及一些数据集统计信息(A.5节)。所有43个NuiScene43场景的可视化效果,请访问我们的数据集页面 https://3dlghcvc.github.io/NuiScene43-Dataset。
A.1 筛选
我们首先使用DuoduoCLIP[25]的12个物体帧多视图嵌入对Objaverse[10]进行筛选。我们使用余弦相似度,通过文本和图像查询嵌入来检索场景,然后通过人工标注和基于DuoduoCLIP嵌入训练的神经网络筛选进行细化,将最初的37000个场景减少到2000个。由于人工处理所有场景进行尺度标注和地面对齐是不切实际的,我们选择了43个较大的场景用于初步实验。
A.2 尺度标注
为了在所有场景之间建立统一的尺度,我们首先将所有场景归一化到 [ − 1 , 1 ] [-1,1] [−1,1]区间。然后随机选择一个场景作为锚点,将其尺度设置为1。将其余每个场景与锚点进行比较,从多个角度视觉对齐树木或建筑物等元素,调整其尺度,以确保视觉上连贯的相对大小。由于这些场景是艺术家创作的,其比例可能更注重美学效果而非现实世界的准确性,因此不存在绝对正确的尺度。相反,我们近似出视觉上一致的缩放比例,并记录每个场景的分配尺度,锚点场景保持为1不变。
A.3 几何处理
点云和占据网格:所有场景网格首先使用Wang等人[43]提出的方法转换为符号距离函数(SDF),我们在Taichi[17]中重新实现了该方法以加快转换速度。使用A.2节中得到的尺度调整SDF转换的体素网格分辨率,以强制在所有场景之间实现统一的尺度。然后通过对SDF值进行阈值处理,将其转换为占据网格。最后,应用多次洪水填充操作来填充场景中的孔洞。对每个场景的占据网格应用移动立方体算法后,从中采样点云。

地面修正:我们观察到筛选出的场景具有各种不同的地面几何结构,从平面到厚体积都有。为了解决这个问题,我们在每个场景中识别出最低的地面水平,并在占据网格中强制该水平以下具有统一的5个体素厚度,以确保所有场景的地面几何结构一致。
A.4 分块采样
为了从场景中采样训练分块,我们首先从俯视图计算一张alpha图。接下来,使用大小为 ( 100 , 100 ) (100,100) (100,100)(即四分块沿x轴和z轴的大小)的全1卷积核,对整个场景进行卷积操作。然后将得到的卷积图在值为 100 × 100 100 \times 100 100×100处进行阈值处理,以确定有效的采样位置。这确保了所有采样的分块都包含被占据的区域,避免了场景中的孔洞或边界区域。
一、先搞懂:这个 100×100 全 1 卷积,到底在计算什么?
论文里的操作省略了一个关键的前置步骤:俯视图 alpha 图的定义。 首先,从 3D 占据网格生成 2D 俯视图 alpha 图:对于每个 (x,z) 坐标,只要该坐标下任意高度 y 有被占据的体素,alpha 图对应位置就为 1;否则为 0。 这张 alpha 图是一张单通道的二值图,大小和场景的水平尺寸完全相同(比如城堡场景就是 1059×1059)。
此时,用 100×100 的全 1 卷积核、步长为 1 对这张二值图做卷积,输出的每个像素值,就是以该像素为中心的 100×100 窗口内,所有像素的总和。 换句话说:
卷积输出值 = 该位置作为四分块中心时,整个四分块 100×100 水平区域内,有被占据体素的 (x,z) 坐标的总数。
进一步通过做阈值处理,就能精确筛选出所有 “内部无空洞、完全在场景内” 的有效四分块中心位置。
接下来,计算深度变化图。对于每个像素,计算其所在核窗口内的平均深度,并减去该像素的深度值,取绝对值得到深度平均偏差。为了避免采样过于平坦的区域,我们过滤掉深度变化低于2.5的采样位置。采样图的示例如图10所示。
卷积阈值:过滤掉有空洞、在边界外的无效分块
深度变化阈值:过滤掉过于平坦、缺乏训练价值的分块
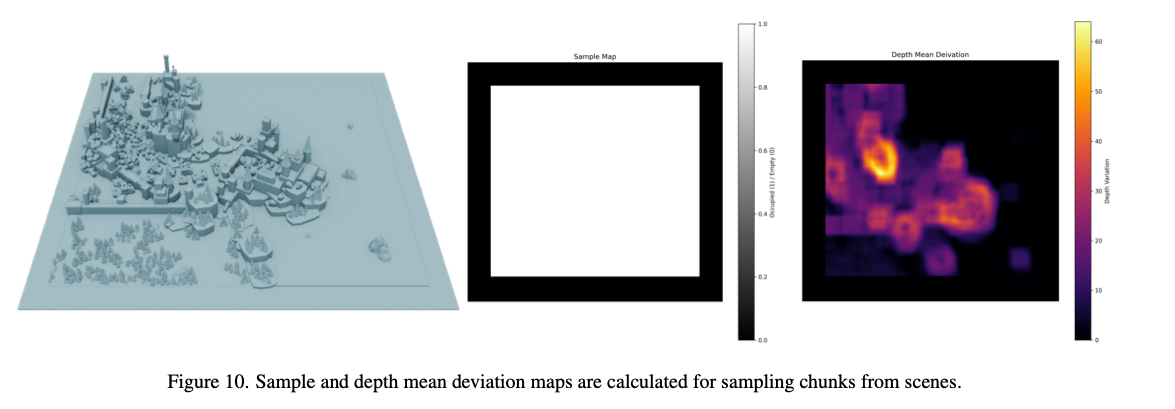
图10. 计算得到的用于从场景中采样分块的采样图和深度平均偏差图。
最后,应用最远点采样(FPS)从所有有效的采样位置中选择四分块。这有助于最大限度地减少分块之间的过度重叠,同时确保训练时对场景的最大覆盖。
A.5 NuiScene43统计信息
表6展示了NuiScene43的统计信息,包括每个类别的场景数量以及可采样的四分块总数。分块数量是通过对前面讨论的采样图进行深度变化阈值处理后求和得到的。请注意,这些分块可能存在重叠,因为我们考虑了所有有效的x和z坐标。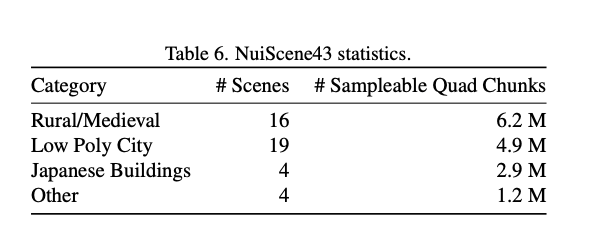
表6. NuiScene43统计信息。
B. 实现细节
B.1 4场景训练
我们在原始的单场景基础上,额外添加了3个场景来训练主论文中的4场景模型。这3个额外的场景如图11所示。
图11. 用于训练4场景模型的三个额外场景。顶部的两个子场景是从一个大型Objaverse场景中拆分出来的,用于计算占据网格。所有场景都具有固定的地面几何结构,其网格是通过对占据网格应用移动立方体算法提取得到的。
B.2 光栅扫描顺序生成
算法1展示了我们在推理阶段使用的光栅扫描顺序生成算法,该算法利用了在四种不同配置下训练的扩散模型。该算法概述了如何使用四种不同的掩码配置,以现有分块为条件进行连续且无边界的生成。在算法的第19行,我们使用DDPM调度器进行50步去噪。得到大型的隐特征网格后,使用解码器解码占据网格,然后通过移动立方体算法得到最终的网格。
可以观察到,一旦在当前行生成了一个四分块,就可以开始生成下一行。这允许沿场景的反对角线进行并行化,极大地加快了大型场景的采样速度。然而,内存使用会变得不稳定,并随场景大小而变化。为了一致性和简洁性,我们在论文中使用了顺序光栅扫描顺序(算法1)。更多细节请参考我们的实现代码。

B.3 场景纹理细节
SceneTex[6]提供了三种相机模式²用于渲染图像和纹理优化,即球形相机、Blender相机和BlenderProc相机。对于3D-Front[12]中的小型室内场景,球形相机足以捕捉场景的精细细节并生成高质量的纹理。然而,对于大型户外场景,预定义的球形相机轨迹往往无法全面覆盖整个场景,会遗漏重要的场景细节。因此,我们选择Blender相机模式,为每个场景手动设置关键帧相机轨迹。这使得我们能够更精细地控制场景细节的捕捉,从而提升纹理质量。
² https://github.com/daveredrum/SceneTex
更具体地说,我们首先将每个场景归一化到以世界原点为中心的 [ − 1 , 1 ] 3 [-1,1]^3 [−1,1]3空间范围内。然后,定义一个类似蛇形扫描的相机轨迹,以指定的帧率捕捉整个场景,如图12所示。每一帧都将由SceneTex渲染,训练期间会采样所有渲染的图像来优化场景级纹理。请注意,为了加快优化速度,我们使用Blender的“简化几何”和“按距离合并”功能(距离为0.001米)压缩场景,直到其大小小于20MB。这可能会降低大型场景的几何质量,但这仅用于纹理生成目的。我们鼓励读者关注生成场景的未纹理化几何细节。图13展示了更多原始几何及其对应纹理的示例。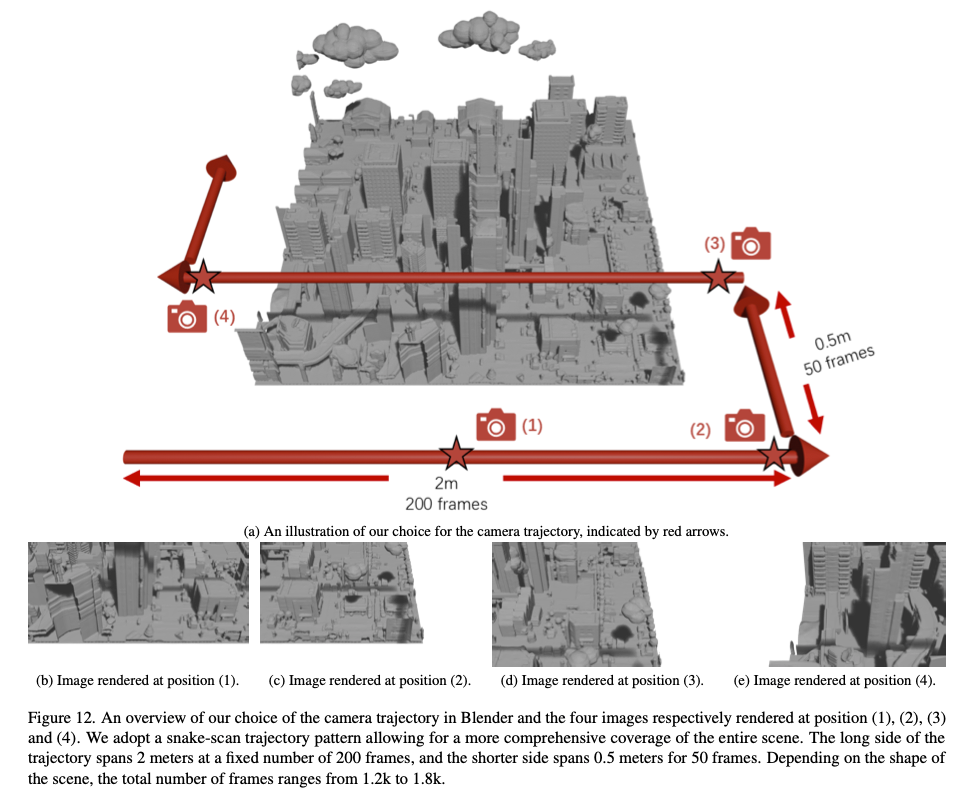
图12. 我们在Blender中选择的相机轨迹概览,以及分别在位置(1)、(2)、(3)、(4)处渲染的四张图像。我们采用蛇形扫描轨迹模式,能够更全面地覆盖整个场景。轨迹的长边跨度为2米,固定为200帧;短边跨度为0.5米,为50帧。根据场景的形状,总帧数在1200到1800之间。

图13. 四个生成场景及其对应纹理的示例(1)至(4)。(1)使用提示词“一个有建筑、城堡和树木的美丽小镇”进行纹理映射。(2)(3)使用提示词“一个有建筑和周边环境的大城市”进行纹理映射。(4)使用提示词“一个有建筑和树木、天空中有云的现代城市”进行纹理映射。
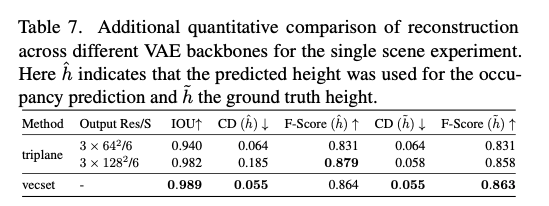
表7. 单场景实验中不同VAE主干网络的重建额外定量对比。其中 h ^ \hat{h} h^表示使用模型预测的高度进行占据预测, h ~ \tilde{h} h~表示使用真实高度。



C. 额外结果
C.1 单场景结果
三平面 3 × 128 2 3 \times 128^2 3×1282:表7展示了输出分辨率为 3 × 128 2 3 \times 128^2 3×1282的三平面基线结果。我们可以看到,其IOU优于低分辨率的三平面基线,并且在使用真实高度时优于向量集模型。然而,我们注意到 C D ( h ^ ) CD(\hat{h}) CD(h^)出现了大幅增加。通过检查具有较大CD值的分块,我们发现当预测高度大于真实高度时,模型会产生漂浮伪影。这可能是由于更高的分辨率在特征查询过程中对空间混叠或量化伪影更加敏感。对于该分辨率,将尺度因子调整为 S = 8.5 S=8.5 S=8.5可能更为合适,但由于训练成本过高,我们没有重新训练模型。这些结果凸显了空间结构化隐特征对场景边界和S等超参数的敏感性。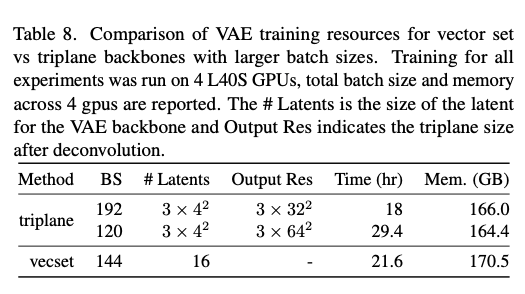
表8. 使用更大批次大小时,向量集与三平面主干网络的VAE训练资源对比。所有实验均在4块L40S GPU上运行,报告了所有GPU上的总批次大小和内存使用量。# Latents是VAE主干网络的隐特征大小,Output Res表示反卷积后的三平面大小。
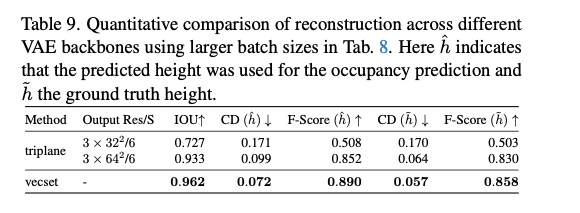
表9. 使用表8中更大批次大小的不同VAE主干网络的重建定量对比。其中 h ^ \hat{h} h^表示使用模型预测的高度进行占据预测, h ~ \tilde{h} h~表示使用真实高度。
更大批次大小:我们最初在所有配置上尝试了更大的批次大小,使用4块GPU,结果如表8所示,目的是加快训练速度。对于向量集模型,这将训练时间从2块GPU的36.1小时(主论文配置)减少到了21.6小时。然而,这导致了过拟合,如表9所示,并且还影响了高度预测的准确性,如图14所示,模型低估了高度,导致分块的部分区域未被重建。相比之下,三平面主干网络受过拟合的影响较小。我们推测这是由于三平面的空间局部性,查询点从固定的三平面位置检索特征;而向量集主干网络允许查询从所有特征向量中聚合信息,虽然具有更大的容量,但也更容易过拟合。尽管如此,这也表明了单场景训练的局限性。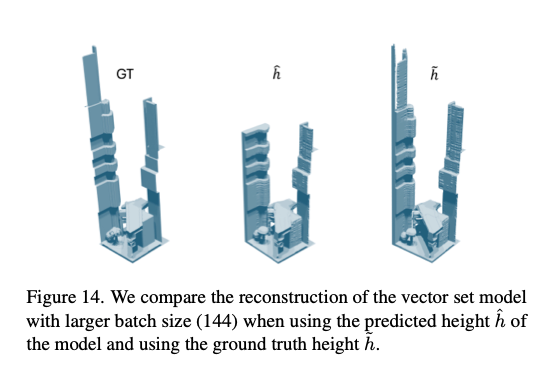
图14. 我们对比了使用更大批次大小(144)的向量集模型在使用模型预测高度 h ^ \hat{h} h^和真实高度 h ~ \tilde{h} h~时的重建效果。
评估指标:遵循3DShape2Vecset[52]的方法,我们报告了IOU、倒角距离(CD)和F-Score用于VAE重建评估。然而,我们发现CD和F-Score的可靠性较低。当通过移动立方体提取表面时,必须选择一个水平集阈值,由于离散网格分辨率的限制,这可能会导致与真实值相比出现间隙。这个问题对不同高度的分块影响不成比例:对于较高的分块,由于每个分块采样的点数相同,单位面积的点数可能更少,从而可能导致更高的CD和更低的F-Score。因此,这些指标在单场景训练和4场景训练等不同配置之间不完全具有可比性。在我们的实验中,报告值的较大差异更具有指示意义,而较小的变化可能反映了水平集间隙带来的噪声。总体而言,IOU在不同场景配置之间更为可靠和具有可比性。
细节层次:在图15中,我们可视化了推理阶段不同分辨率下的占据预测结果,通过移动立方体算法生成了三平面和向量集模型的不同细节层次(LoD)。50是训练时使用的原始分块沿x轴和z轴的大小,y轴根据高度预测进行缩放。我们发现,将分块大小减半可以提供相当的细节,同时减少场景的内存使用。然而,进一步减小到13会导致树木和建筑物的细节明显丢失。
图15. 这里展示了推理阶段使用不同占据网格分辨率进行预测,并通过移动立方体算法生成结果的效果。底部的数字表示分块沿x轴和z轴的大小。50是训练时使用的原始分块大小。
额外可视化:我们在图16中展示了向量集扩散模型的额外结果,在图17中展示了RePaint基线的结果。
图16. 在单场景上训练的向量集扩散模型的额外结果。这里展示的场景大小为21×21。
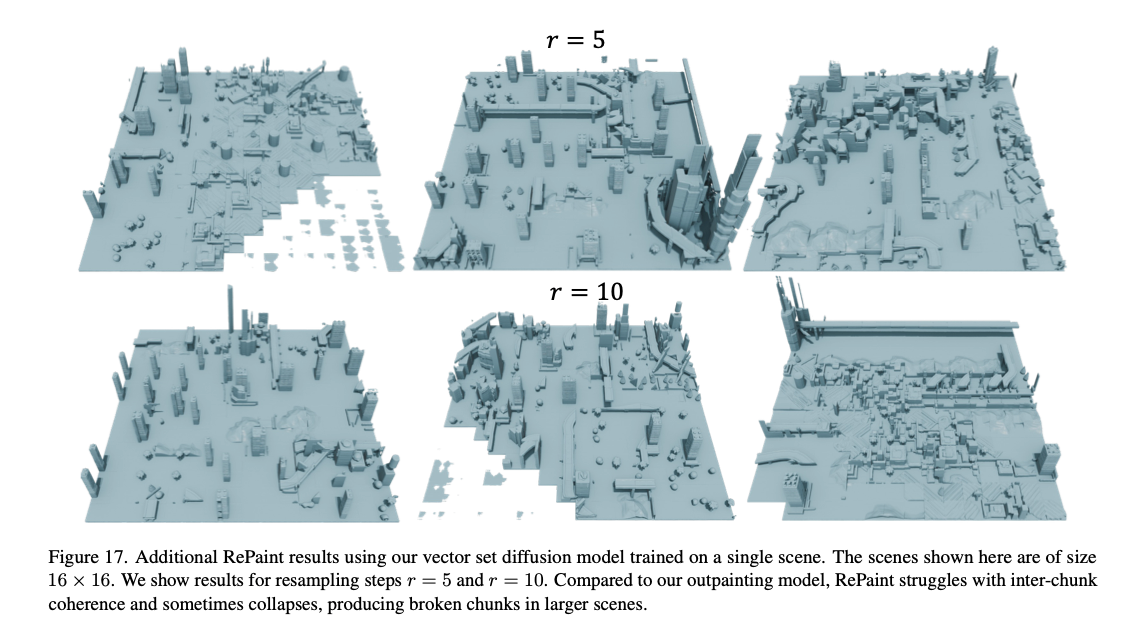
图17. 在单场景上训练的向量集扩散模型的额外RePaint结果。这里展示的场景大小为16×16。我们展示了重采样步数 r = 5 r=5 r=5和 r = 10 r=10 r=10的结果。与我们的外补绘制模型相比,RePaint在分块间连贯性方面表现不佳,并且有时会崩溃,在更大的场景中产生破碎的分块。
C.2 4场景
在本节的4场景实验中,我们遵循主论文中的相同GPU配置,并将4个场景的采样分块数量增加到30万个。训练集和验证集仍然按照95%-5%的比例划分。对于扩散模型评估,我们从场景和扩散模型中各采样3万个四分块进行评估。定量结果如表10和表11所示,分别展示了VAE重建和扩散生成质量。我们可以看到,向量集模型的IOU保持了其性能,而三平面模型略有下降。向量集模型在所有指标上均优于三平面模型。

图18. 在4个场景上训练的向量集扩散模型的额外结果。这里展示的场景大小为21×21。
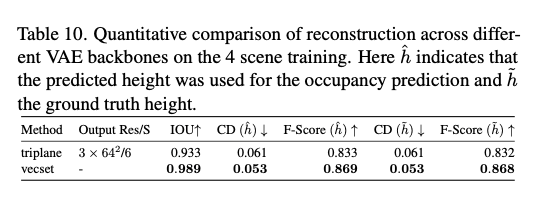
表10. 在4个场景上训练的不同VAE主干网络的重建定量对比。其中 h ^ \hat{h} h^表示使用模型预测的高度进行占据预测, h ~ \tilde{h} h~表示使用真实高度。
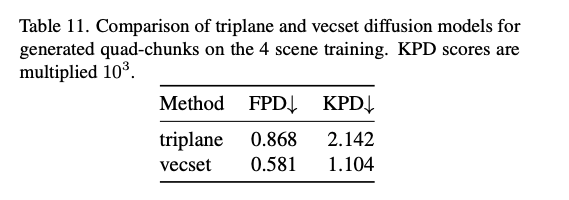
表11. 在4个场景上训练的三平面和向量集扩散模型的生成四分块对比。KPD分数乘以 10 3 10^3 103。
额外可视化:我们在图18中展示了在4个场景上训练的向量集扩散模型的额外结果。
C.3 13场景
为了进一步证明我们的模型在扩展方面的潜力,我们从NuiScene43的13个场景中采样了28万个分块(采样配置可在此处获取:https://github.com/3dlg-hcvc/NuiScene),并使用与之前相同的设置进行训练。
提升重建效果:在之前的向量集设置下,在13个场景上训练的VAE模型的IOU下降到了0.968,这是由于与单场景或4场景相比,场景的变化更大。提升VAE性能的一个简单方法是在训练时直接增加特征向量的数量 V V V。然而,正如三平面模型所示,这会增加内存使用并减慢扩散训练速度。相反,受三平面反卷积层的启发,我们引入了一个类似像素洗牌[40]的层来对向量集数量进行上采样,随后添加额外的自注意力层。这在不增加隐特征大小的情况下提升了模型的容量。具体来说,我们添加了一个额外的投影层来增加通道数,并从通道维度重塑为向量令牌。我们将其上采样到512个向量集,并在查询坐标的交叉注意力层之前添加了3个自注意力层。这将IOU提升到了0.983。
图19. 在13个场景上训练的向量集扩散模型的额外结果。这里展示的场景大小为21×21。
在图20中,我们展示了模型之间的定性对比。尽管训练场景数量增加,原始向量集模型已经能够很好地重建场景。添加的改进进一步增强了精细细节的重建效果。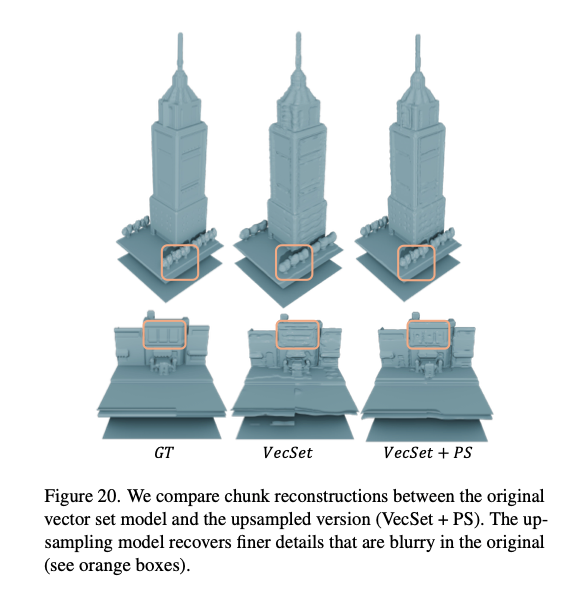
图20. 我们对比了原始向量集模型和上采样版本(VecSet + PS)的分块重建效果。上采样模型恢复了原始模型中模糊的更精细细节(见橙色框)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)