论文阅读笔记——Mapping the Landscape of Generative AI in Network Monitoring and ManagementGenAI—赋能网络监控与管理综述
最近读了一篇综述论文:Mapping the Landscape of Generative AI in Network Monitoring and Management。这篇文章发表于 IEEE Transactions on Network and Service Management,系统梳理了 Gen AI 在网络监控与管理中的应用场景、模型类型、数据集、平台、面临的挑战和未来方向。
1. 应用场景 (Use Cases)
论文首先把 GenAI 在网络监控与管理中的应用归纳为五类:网络流量生成、网络流量分类、网络入侵检测、网络系统日志分析,以及网络数字助理。这个分类基本覆盖了从“数据构造”到“状态理解”,再到“辅助决策和操作”的完整链条。
1.1 网络流量生成
网络流量生成,简单说就是让模型生成看起来像真实网络流量的数据。生成的内容可以是流的统计特征,比如包大小、包到达间隔、流持续时间,也可以进一步生成接近完整 PCAP 的流量轨迹。
这个任务的重要性在于:很多网络研究都受限于数据不足。尤其是网络安全、异常检测和故障诊断场景中,真实异常样本往往少、不完整、不方便公开,甚至涉及隐私和安全风险。如果 GenAI 能生成高保真的网络流量,就可以用于数据增强、压力测试、安全验证和模型训练。
不过这里的关键难点也很明显:生成的数据不能只是“格式像”,还要“行为像”。也就是说,模型不仅要生成合法的数据结构,还要保留协议逻辑、时间相关性、流量分布和攻击行为特征。否则,生成数据虽然看起来丰富,但对下游模型训练反而可能产生误导。
从研究启发来看,网络流量生成可以服务于故障诊断中的“故障样本稀缺”问题。例如,真实网络中的链路拥塞、丢包、重传、突发延迟等故障数据不一定容易采集,如果能通过生成模型构造不同强度、不同组合、不同拓扑位置下的异常流量,就能为故障检测和根因定位模型提供更丰富的训练场景。
1.2 网络流量分类
网络流量分类是传统网络测量和网络管理中的经典任务,目标是判断一段流量属于什么协议、什么应用、什么服务,或者是否经过 VPN/Tor 等封装。过去常见方法主要依赖机器学习或深度学习模型,从流量统计特征、包序列、payload 或时序特征中学习分类边界。
论文中比较有意思的观点是:可以把网络流量看作一种互联网语言。自然语言中有词、句子和上下文,网络流量中也有包、流、会话和时间顺序。于是,类似 BERT、Transformer、Mamba 这样的序列建模方法就有了用武之地。模型可以先在大量未标注流量上做预训练,学习通用的流量表示,再针对具体任务进行微调。
这种思路和 NLP 中“预训练 + 下游任务微调”的范式非常相似。它的价值在于:网络分类任务往往面临标签不足、场景变化快、跨数据集泛化差等问题。如果能训练出一个较通用的网络流量基础模型,就有可能减少每个任务从零训练模型的成本。
1.3 网络入侵检测
网络入侵检测可以看作网络流量分类的特殊场景,但它的目标更加偏向安全:判断流量是否异常、是否恶意,以及属于哪类攻击。论文中把相关工作进一步区分为误用检测和异常检测。误用检测依赖已知攻击标签,异常检测则更关注从正常行为中识别偏离模式。
GenAI 对入侵检测的帮助主要体现在两个方面。第一,它可以增强模型的上下文理解能力。很多攻击并不是单个包或单条流就能判断出来的,而是体现在一段时间内的行为序列中。第二,它可以通过预训练和迁移学习提高模型对新威胁的适应能力。
但是,网络安全场景中使用 GenAI 也有风险。攻击者可能故意构造对抗样本,让模型误判;模型生成的恶意流量也可能被滥用。因此,在入侵检测中使用生成式模型,不能只看准确率,还要关注鲁棒性、可解释性和安全边界。
1.4 网络系统日志分析
日志分析是我认为最接近 AIOps 的应用场景之一。网络设备、服务器、容器、应用系统都会持续产生大量日志,这些日志包含状态变化、错误提示、异常事件和系统行为痕迹。传统日志分析任务包括日志解析、日志摘要、异常检测、故障定位等。
论文中提到,LLM 在日志分析中的优势比较自然,因为日志本身往往是半结构化文本。相比纯流量数据,日志更接近大模型熟悉的语言形式。模型可以用于日志模板抽取、错误摘要、异常解释,甚至通过提示词直接回答“这段日志说明了什么问题”。
这对网络故障诊断很有启发。很多实际运维问题并不是缺少数据,而是数据太多、太碎、太分散。告警、日志、指标和工单之间缺乏统一解释,导致人工排查成本高。如果大模型能够把日志内容转化为“故障假设”“异常链路”“可能根因”“建议操作”,它就不只是一个文本摘要工具,而可以成为运维诊断流程中的推理组件。
当然,日志分析中的大模型也不能完全依赖“看起来合理”的生成结果。运维场景需要可验证、可追溯、可复现。比如模型判断某个服务异常,最好能指出依据来自哪几条日志、哪些指标变化、哪个时间窗口,而不是只给出一个笼统结论。
1.5 网络数字助理
网络数字助理是论文中非常值得关注的一类应用。它包括两种方向:一种是面向文档和标准的问答助手,帮助用户理解 RFC、3GPP 标准、设备手册等复杂文本;另一种是面向网络操作的助手,帮助生成配置、解释拓扑、辅助故障排查和执行管理任务。
这类应用和当前 LLM Agent 的发展非常相关。通用大模型已经具备较强的自然语言交互能力,但网络管理不是普通问答,而是涉及严格语义、复杂约束和高风险操作的专业任务。比如生成路由器配置,如果多一个参数、少一个约束,就可能造成网络不可达。因此,论文也强调了验证模块的重要性:模型生成的结果必须经过规则校验、仿真验证或工具检查。
从我的研究角度看,网络数字助理可能是未来最容易形成系统原型的方向。因为它天然适合和 RAG、工具调用、知识库、拓扑分析、日志检索、配置验证等模块结合。一个比较合理的研究路径是:先不追求让大模型“直接控制网络”,而是让它成为一个“工具增强型诊断助手”,通过调用外部工具完成证据检索、异常定位、候选根因排序和操作建议生成。
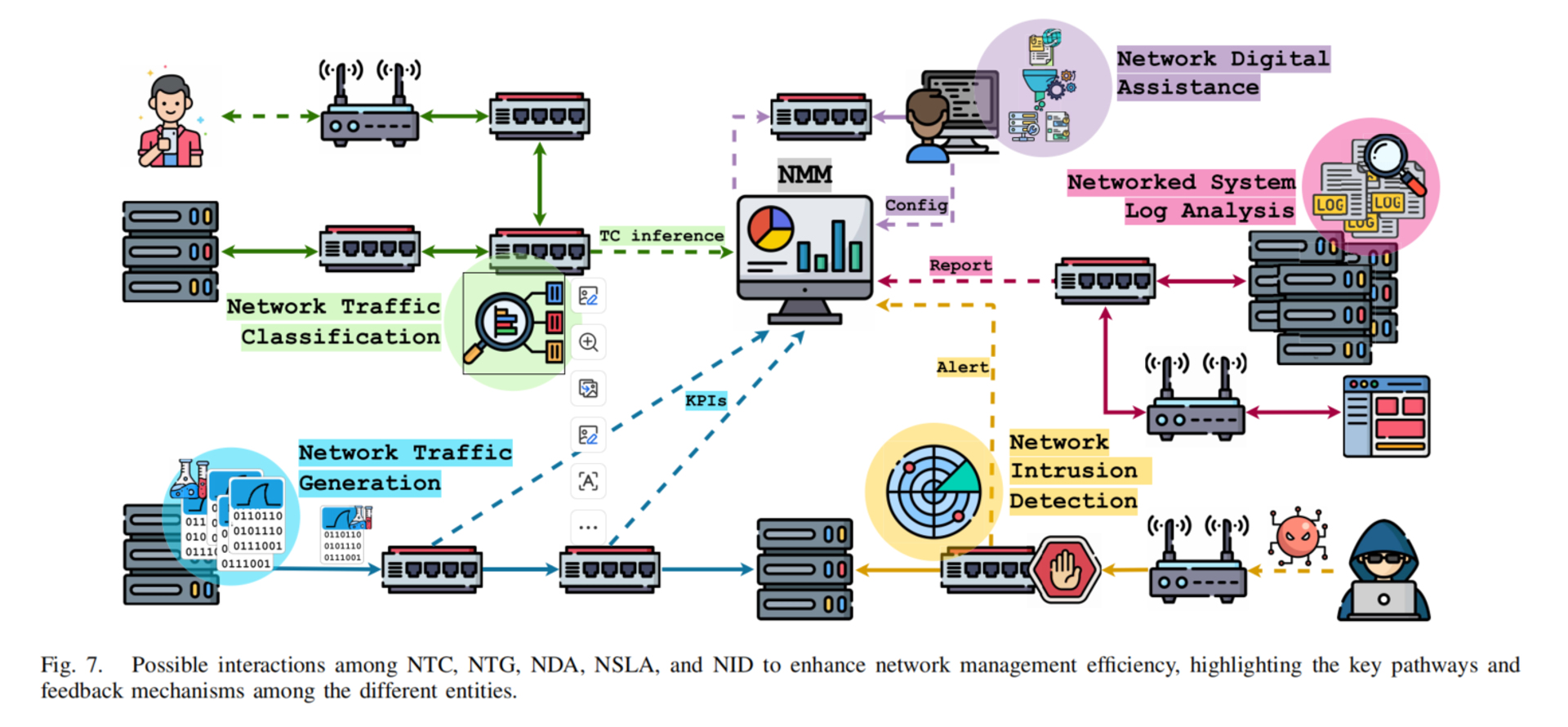
2. 模型类型 (Models)
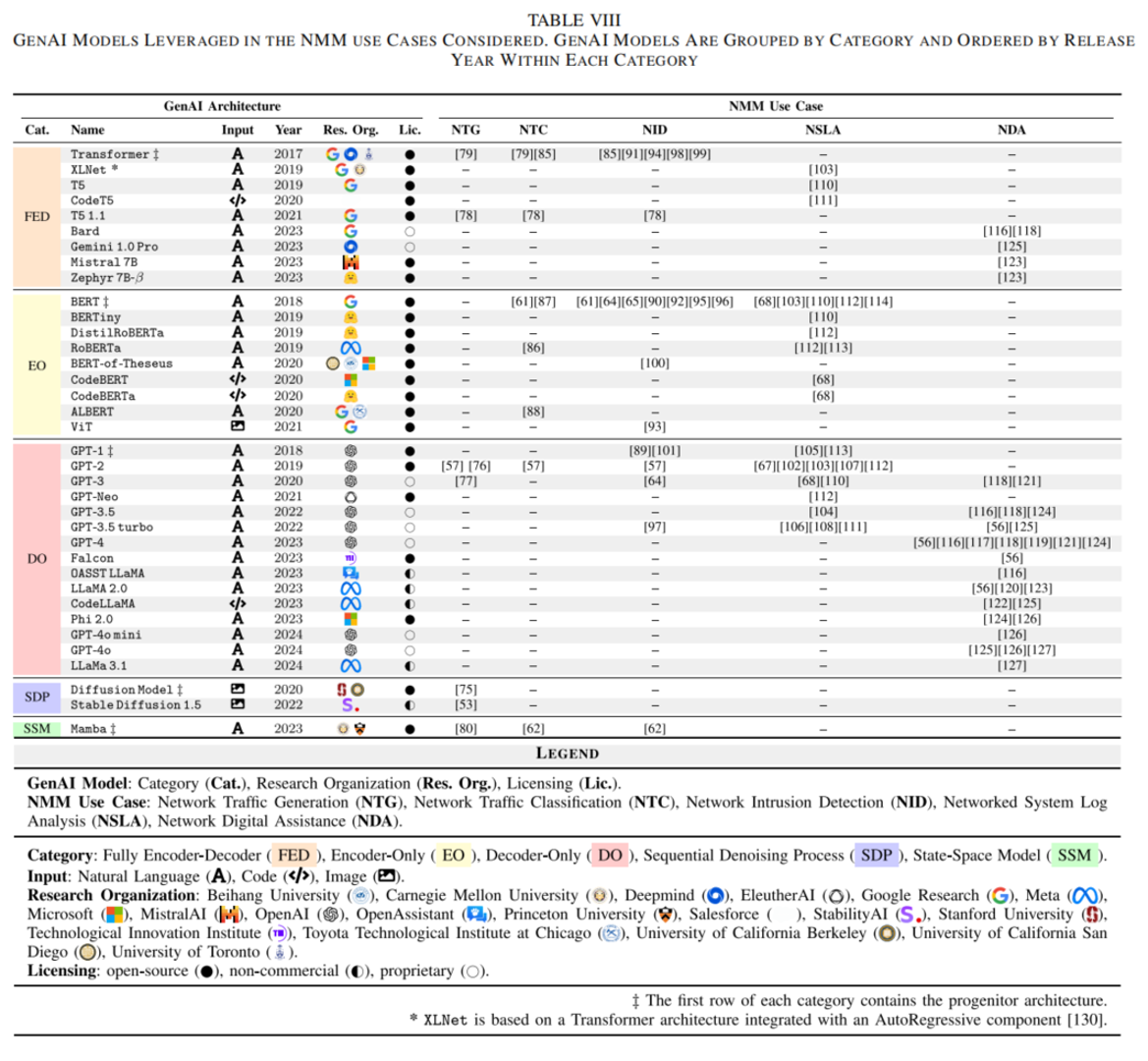
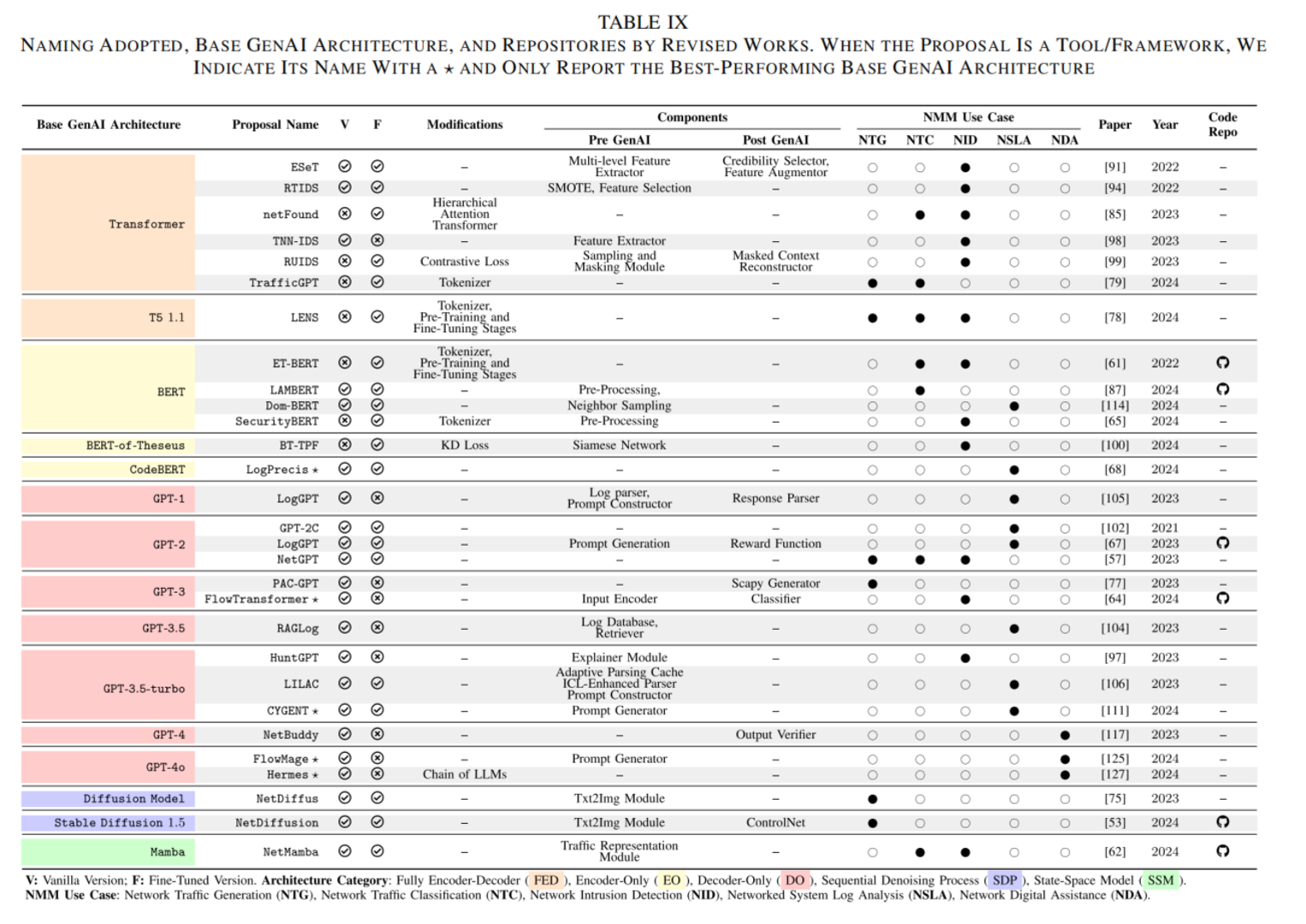
论文把当前与网络监控管理相关的 GenAI 模型分成几类:Transformer 系列、扩散模型、状态空间模型,还提到了一些训练和优化策略。这个视角很重要,因为“GenAI for Network”并不等于“ChatGPT for Network”。不同网络任务的数据形态不同,适合的模型也不同。
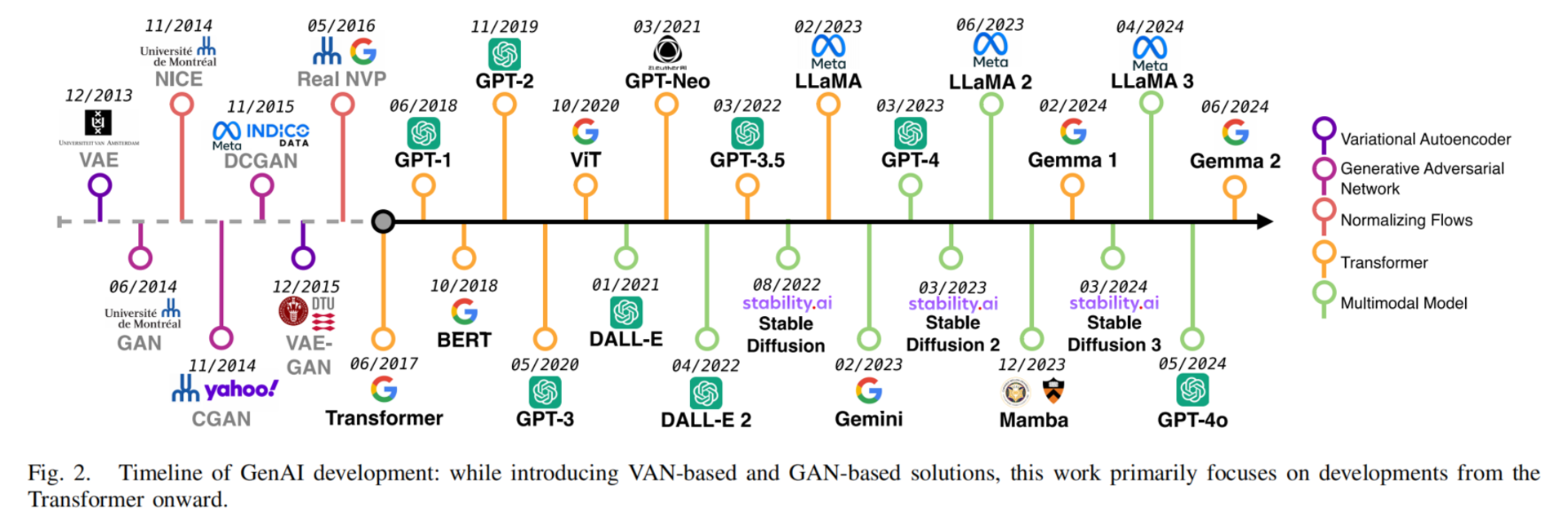
作者将现有模型分为以下几类:
2.1 Transformer 系列:当前最主要的基础架构
Transformer 是当前大多数语言模型的基础。论文进一步把 Transformer 系列分为三类:Encoder-Decoder、Encoder-Only 和 Decoder-Only。
Encoder-Decoder 适合输入和输出都是序列的任务,比如翻译、摘要和结构转换。在网络场景中,它可以用于把自然语言需求转成配置,或者把网络日志转成摘要和解释。
Encoder-Only 的代表是 BERT,它更擅长理解和分类。网络流量分类、入侵检测、日志异常检测等任务都可以用这类模型。它不一定负责生成长文本,而是负责把输入编码成高质量表示,再用于判断类别或异常。
Decoder-Only 的代表是 GPT、LLaMA、Phi 等,它们更适合生成式任务,例如问答、代码生成、配置生成和对话式网络助手。论文中很多网络数字助理相关工作都使用了这一类模型。
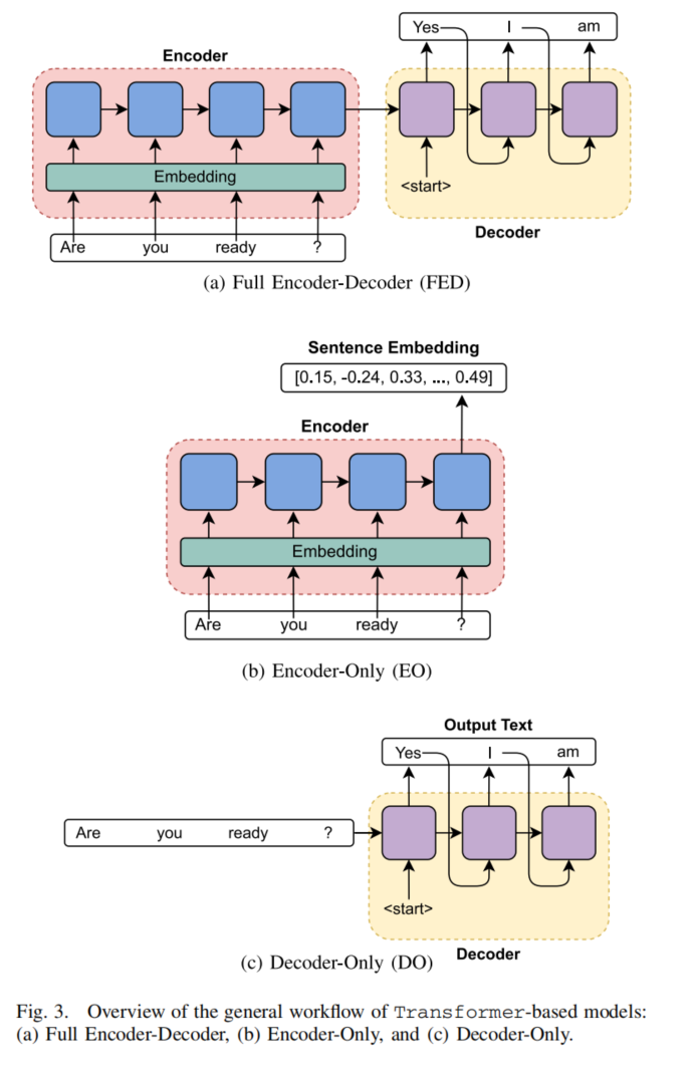
对网络研究来说,选择哪类 Transformer 不应只看模型名气,而要看任务目标。如果目标是分类和检测,BERT 类模型可能更合适;如果目标是解释、问答和操作建议,GPT/LLaMA 类模型更自然;如果目标是结构转换,比如从意图到配置,则 Encoder-Decoder 或带工具调用的 Decoder-Only 模型都值得考虑。
2.2 扩散模型:用于生成高质量网络数据
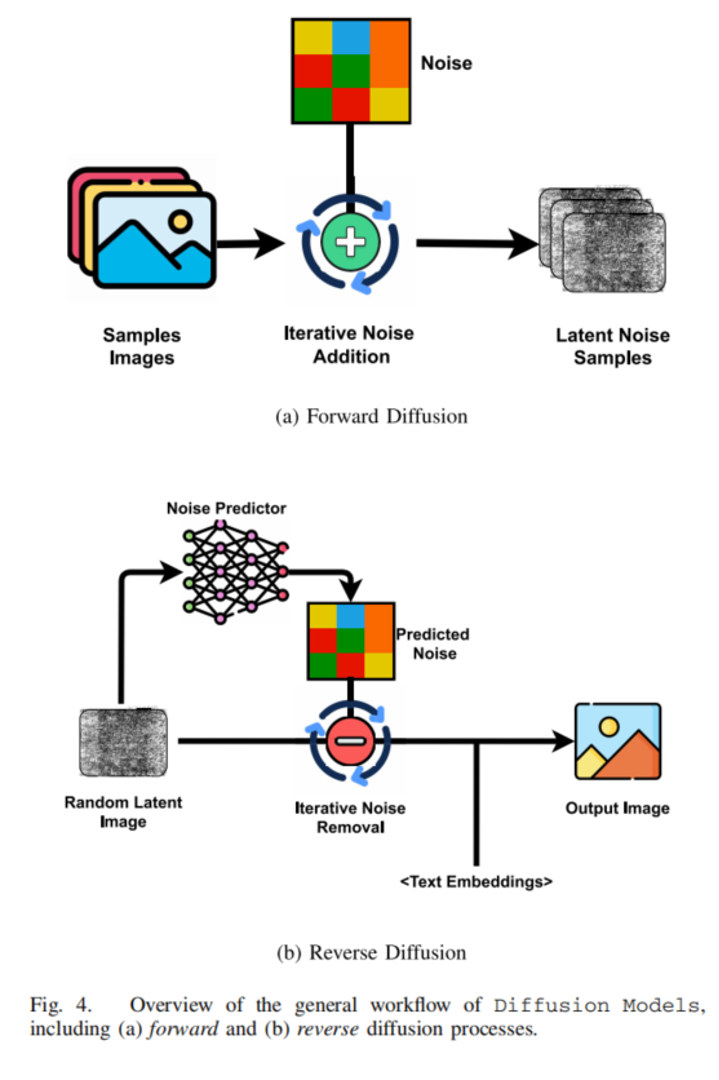
扩散模型最初在图像生成中表现突出,其核心思想是先逐步给数据加噪声,再学习如何从噪声中恢复数据。论文中提到,扩散模型也开始被用于网络流量生成。由于网络流量可以通过某些方式转成类似图像或时序图的表示,因此扩散模型可以学习这些表示的分布,再生成新的样本。
2.3 状态空间模型:面向长序列和高效率的新选择
论文还讨论了以 Mamba 为代表的选择性状态空间模型 SSM。它的优势是处理长序列时效率更高,不像 Transformer 的注意力机制那样容易受到序列长度的平方复杂度限制。
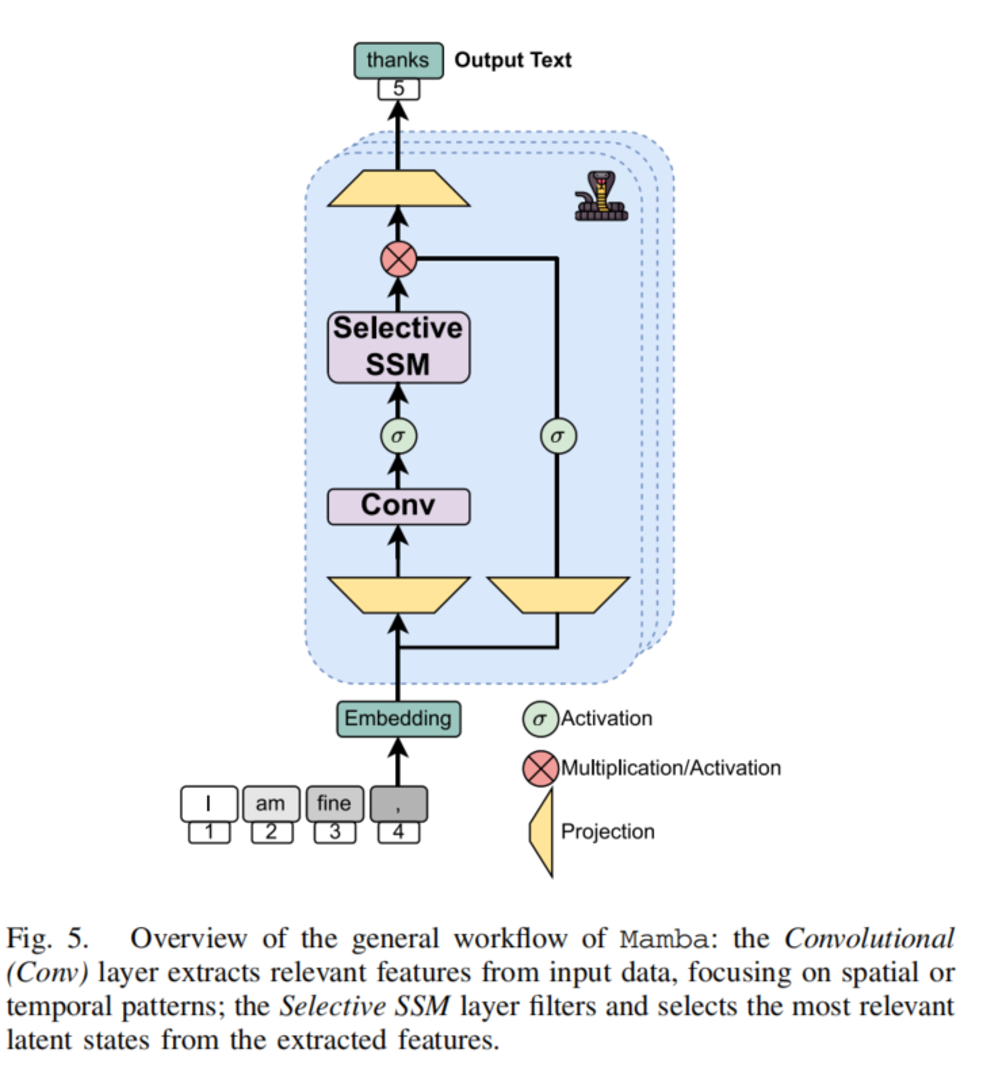
这对网络数据很有意义,因为网络监控天然存在长序列问题:长时间指标、持续流量、日志事件序列、告警演化链路,都可能远超普通文本上下文长度。如果未来要做在线网络故障诊断,一个模型不仅要看当前时刻,还要看故障发生前的一段演化过程。Mamba 这类架构可能适合做长时间窗口下的网络状态建模。
2.4 优化策略
论文还提到两类重要优化策略:参数高效微调和量化。前者的代表是 LoRA,它通过只训练少量额外参数来降低微调成本;后者则通过降低模型权重精度来减少存储和推理开销。
这部分对实际研究非常关键。网络监控与管理很多时候需要在线处理,不能只在离线实验中跑得好。模型越大,推理延迟、部署成本和维护难度越高。因此,在网络场景中,轻量化、领域微调、小模型、RAG 和工具增强可能比单纯追求“大参数量”更现实。
3. 数据与平台 (Datasets & Platforms)
论文专门梳理了 GenAI for NMM 中使用的数据集和平台。这个部分对做实验的人很有参考价值,因为网络方向最大的问题之一就是数据。
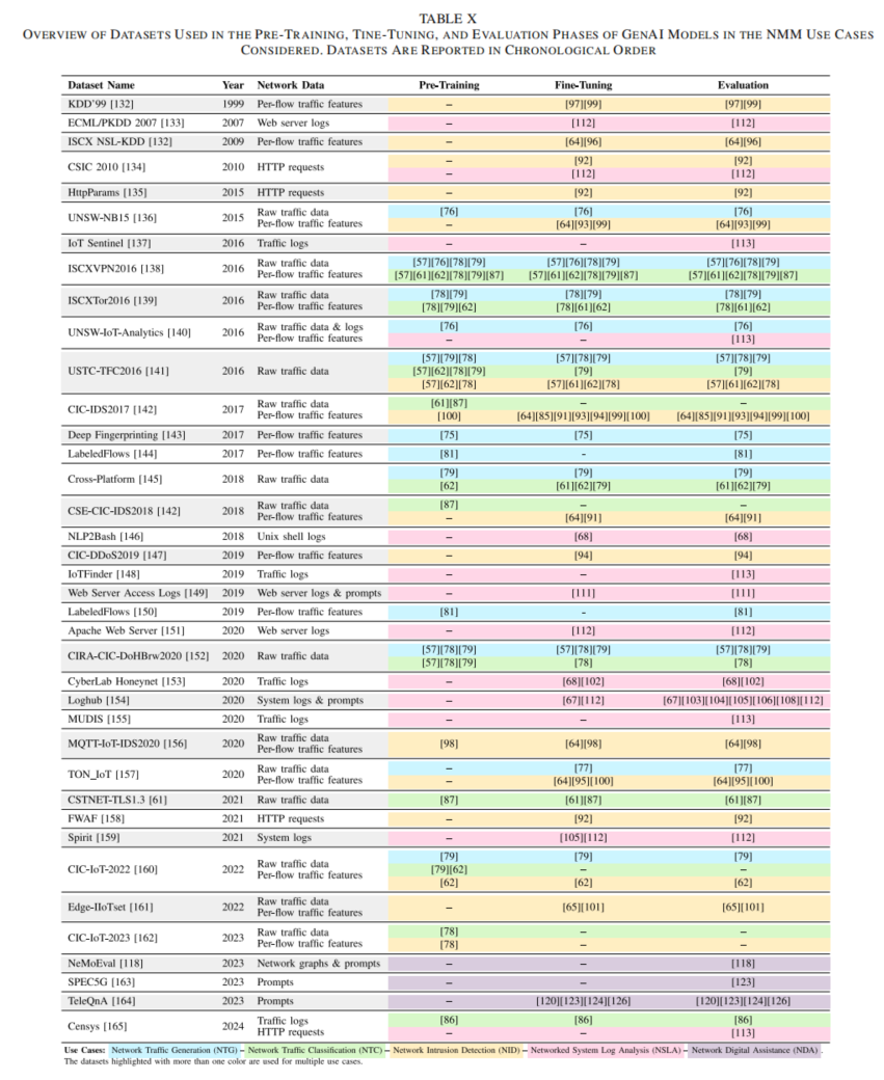
从数据集来看,网络流量分类和入侵检测常用的数据集包括 ISCXVPN2016、USTC-TFC2016、CIC-IDS2017、CICIoT2023 等;日志分析常用 Loghub 等日志数据集;网络数字助理则会用到 TeleQnA、TaleQnAD 等面向电信知识问答的数据集。
但是论文也提醒了一个很现实的问题:很多公开数据集并不能很好代表真实网络场景。有些数据集过旧,有些来自小规模实验环境,有些经过严重匿名化,还有些数据集本身存在标注或生成方式的问题。因此,如果直接拿公开数据集做实验,很容易得到“论文效果很好、实际场景很弱”的结果。
平台方面,论文提到了 OpenAI、Amazon Bedrock、Microsoft Azure AI、Google Vertex AI、Hugging Face、Nvidia NIM、IBM Watson、Cloudflare AI 等平台。可以看出,GenAI 研究越来越依赖平台化工具:预训练、微调、部署、推理、监控都可以在平台上完成。
不过对于学术研究来说,我更关注开源模型和可复现实验。论文也指出,目前很多工作没有公开代码或微调后的模型,这会影响社区复现和继续改进。对于我们自己做研究,最好从一开始就考虑代码、数据处理流程、prompt、工具调用流程和评价指标的可复现性。
4. 挑战与未来方向
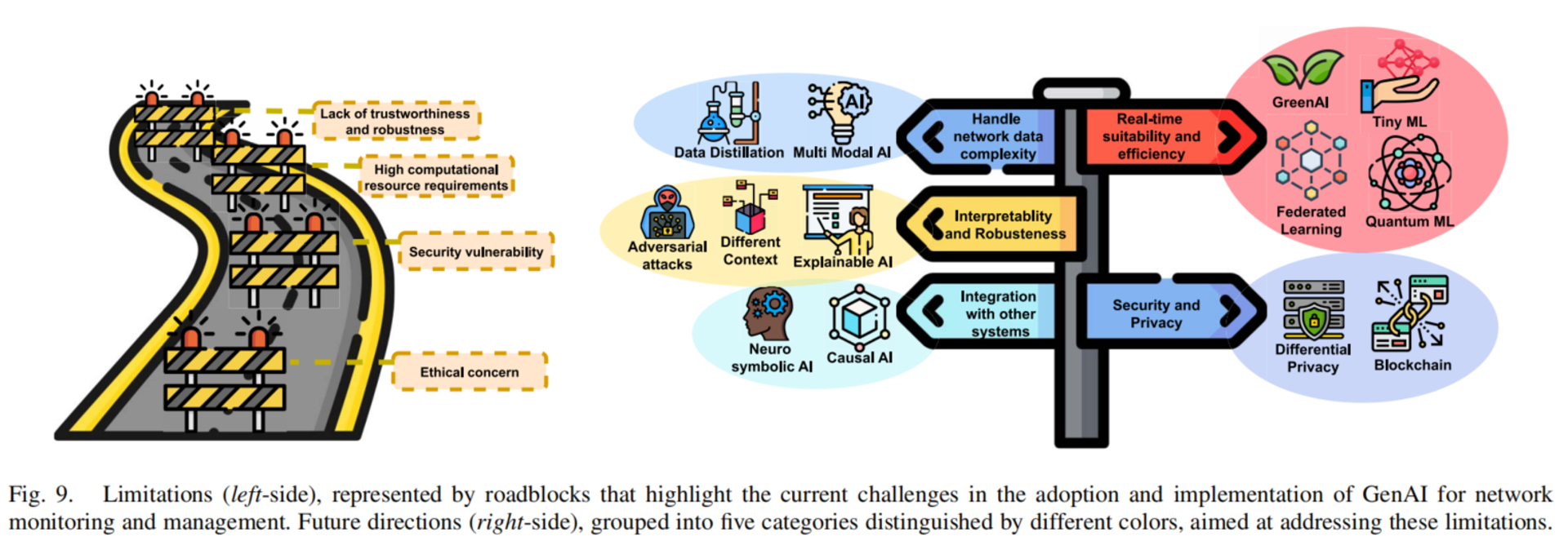
这篇综述并没有盲目乐观地说 GenAI 可以解决所有网络问题,而是明确指出了几个限制。
第一是可信性和鲁棒性问题。 大模型常被视为“黑盒”,我们很难完全理解它为什么给出某个判断。在网络运维中,这会带来很大风险。比如模型说“根因可能是链路拥塞”,但如果不能给出证据链,运维人员很难信任它。
第二是资源消耗问题。 大模型训练和推理都需要较高算力,而网络管理很多任务又要求实时性。这意味着单纯把超大模型部署到网络现场并不现实,需要考虑小模型、模型压缩、边缘部署、增量学习等方法。
第三是安全风险。 GenAI 本身可能受到对抗攻击,也可能生成错误配置、错误解释或不安全操作。尤其是当模型具有工具调用能力时,必须加入权限控制、验证机制和人工确认环节。
第四是数据隐私和伦理问题。 网络数据可能包含用户行为、设备信息和业务特征,如果直接用于训练模型,可能带来隐私泄露风险。因此,联邦学习、差分隐私、安全多方计算等技术可能会在未来发挥作用。
论文给出的未来方向包括实时性与效率、网络数据复杂性处理、可解释性与鲁棒性、与现有系统集成、安全与隐私等。我结合自己的研究兴趣,认为以下几个方向尤其值得关注。
1. 工具增强型 LLM Agent
网络管理任务通常不是一个模型输入输出就能完成的。它需要查日志、看指标、理解拓扑、调用诊断脚本、验证配置、生成报告。因此,LLM 更适合作为“调度者”和“解释者”,而不是孤立的预测模型。
一个可行框架是:LLM Agent 接收用户问题或告警事件,然后调用日志检索工具、指标分析工具、拓扑查询工具、故障知识库和仿真验证工具,最后生成可解释的诊断结论。这样既能发挥大模型的语言理解和任务规划能力,又能避免它凭空生成结论。
2. 多模态数据融合
真实故障往往不会只体现在一类数据中。流量异常、指标波动、日志报错、告警关联、拓扑位置变化可能同时出现。如果只看单一模态,很容易误判。
因此,未来的网络故障诊断模型应当能够融合多源数据:时间序列指标、系统日志、网络拓扑、流量特征和运维文本。GenAI 的价值不一定是替代所有传统模型,而是把这些分散信息组织成统一的诊断上下文。
3. 可解释性是网络场景中的刚需
在普通问答场景中,用户可能只关心答案是否有用;但在网络运维场景中,用户必须知道答案为什么成立。尤其是故障定位、入侵检测和配置生成,错误结果可能造成业务中断。
因此,未来研究不能只报告 accuracy、F1-score,还应该评价解释质量、证据完整性、定位路径是否合理、建议操作是否可验证。也就是说,网络智能运维中的 GenAI 评价体系应该更加接近“可执行诊断报告”的质量评价,而不仅是分类准确率。
4. 联邦学习可以和 GenAI for NMM 结合
论文在未来方向中提到了联邦学习,这一点我觉得很值得展开。网络数据通常分散在不同设备、不同边缘节点、不同运营环境中,很难集中到一个地方训练模型。同时,网络数据又涉及隐私和安全,直接上传原始数据并不现实。
如果将联邦学习与 GenAI 结合,可以让不同节点在本地保留数据,只上传模型更新或中间表示。这对于跨域网络故障诊断、边缘网络智能运维、IoT 安全检测等场景都很有意义。
5. 总结
总体来看,Mapping the Landscape of Generative AI in Network Monitoring and Management 是一篇很适合作为方向入门的综述。它没有局限在“大模型问答”这个狭窄视角,而是从网络流量、入侵检测、日志分析、数字助理、数据集、平台和未来挑战等多个维度系统梳理了 GenAI 在网络监控与管理中的应用版图。
对我来说,这篇文章最大的意义在于帮助我确认了一点:网络智能运维与 GenAI 的结合不是简单地“把 ChatGPT 接到网络系统上”,而是要解决网络数据如何表示、网络任务如何定义、模型如何与工具协同、结果如何验证、系统如何安全落地等一系列问题。
未来真正有价值的研究,可能不是做一个更会聊天的网络助手,而是做一个能够理解网络状态、调用诊断工具、融合多源证据、生成可解释结论,并能在真实约束下辅助运维决策的智能系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)