Werewolf-Agent 多智能体狼人杀中DSPy应用
一、问题的起点:prompt 工程的缺点
做狼人杀 AI 的头几周,我对于提示词部分就是用这样方式进行设计的:
看起来很正常。但当游戏角色从 1 个变成 8 个,每个人有不同的规则约束(女巫有解药和毒药、守卫不能连守、狼人白天要伪装身份……),prompt 越来越多,冲突越来越多,改一个地方会意外破坏另一个地方的效果。
更根本的问题是:我不知道这个prompt是不是"最好的"。调参全靠感觉,直觉告诉你"这句话放这儿可能更好",但没有验证方法,没有量化指标,模型表现差了也不清楚是prompt问题、数据问题还是模型本身的问题。
二、DSPy 是什么:一种语言模型编程的方法论
DSPy 的文档第一句话通常是“用声明式的方式编程语言模型”。在我的理解中:
DSPy 把 prompt 工程从"手工写文本"升级成了"定义问题结构 + 让系统搜索最优解"。
传统的prompt工程结果判定全靠我们感觉来判断如何,那么,DSPy是如何进行的呢?
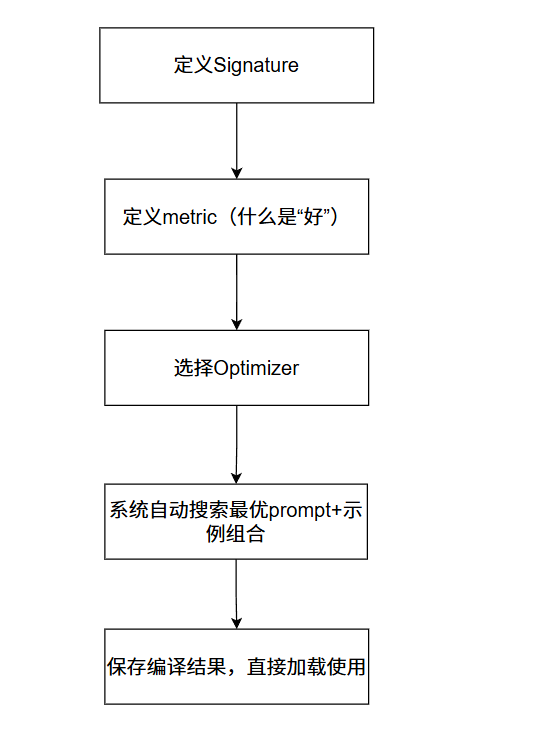
这不是换了一个工具,是换了一种编程思路:通过定义目标函数来选择最优解,而不是在手动构造解决方案。
接下来,我们就从DSPy的结构来分别介绍其核心组件。
三、Signature:把你的问题"翻译"成 DSPy 能理解的形式
签名 (Signatures):以声明式方式定义任务的输入输出规格,例如用 "question -> answer" 定义问答任务。编译器会根据签名自动生成和优化提示词,替代传统手写提示。
我最初的 Signature 是这样写的:
class SeerAction(dspy.Signature):
game_state = dspy.InputField()
check_target = dspy.OutputField()能用,但很差。因为game_state是一个随意命名的字段,DSPy不知道这个字段里装的是什么数据、格式是什么样的。模型的推理质量取决于模型能否从自然语言描述里推断出字段含义。后来我改成了这样:
class SeerNightAction(dspy.Signature):
"""
你是狼人杀游戏中的预言家。重要规则(必须严格遵守):
1. 【禁止自查】check_target 绝不能等于 seer_id。
2. 【只能查存活】check_target 必须是存活玩家。
3. 推理必须结合:存活人物情况 + 别人发言 + 查验结果 + 白天投票。
"""
seer_id = dspy.InputField(
desc="你自己的玩家ID,例如 'Bot5'"
)
game_state = dspy.InputField(
desc="游戏状态,包含:存活玩家列表、发言摘要..."
)
check_target = dspy.OutputField(
desc="查验目标玩家ID,必须是存活玩家且不能等于 seer_id"
)
reasoning = dspy.OutputField(
desc="推理过程,必须结合存活人物情况进行分析",
prefix="推理:"
)这里有四个关键的设计原则:
1. 字段名要有语义game_state不如alive_players + death_records + recent_speeches清晰。字段名越具体,DSPy的prompt自动生成质量越高。
2. 字段描述(desc)是prompt的核心desc的内容会直接影响模型对字段的理解。"玩家ID"不如"你自己被分配的玩家标识,例如'Bot5'"具体。把格式示例和约束条件都写进去。
3. prefix参数控制输出格式reasoning字段加上了prefix="推理:",这让模型的输出天然带有这个前缀,在解析时不容易混淆。同理,proposal字段用prefix="提议:",speech字段用prefix="发言:"。
4. 把规则写进Signature的docstring,而不是只放在desc Signature的顶层docstring是模型的系统指令,描述的是角色身份和行为规则,这是prompt里权重最高的部分。字段级别的desc只描述单个字段,两者的作用不同,不能互相替代。
四、Module:把 Signature 变成可执行的推理单元
模块 (Modules):封装了特定LLM调用模式的抽象层,可自由组合构建复杂流程。常用内置模块包括:dspy.ChainOfThought(实现思维链)、dspy.ReAct(构建智能体Agent)、dspy.Refine(迭代优化输出)和 dspy.BestOfN(多候选生成并选最优)。
有了 Signature,你需要把它变成一个可以调用函数。DSPy 提供了两种主要方式:
方式一:直接使用dspy.Predict(无推理链)
class SeerModule(dspy.Module):
def __init__(self):
super().__init__()
self.night_action = dspy.Predict(SeerNightAction)
def forward(self, seer_id, death_records, game_state, known_info, day_vote_info):
return self.night_action(
seer_id=seer_id,
death_records=death_records,
game_state=game_state,
known_info=known_info,
day_vote_info=day_vote_info,
)方式二:使用dspy.ChainOfThought(强制推理链)
class SeerModule(dspy.Module):
def __init__(self):
super().__init__()
self.night_action = dspy.ChainOfThought(SeerNightAction)
def forward(self, ...):
return self.night_action(...)两者的区别是:dspy.Predict直接输出结果,dspy.ChainOfThought强制模型先生成推理过程再输出结果。对于狼人杀推理场景,ChainOfThought 是更合适的选择,因为:
1. 推理过程本身就是游戏状态评估的一部分,可以用来做审计
2. ChainOfThought 的中间输出能让 metric 对"推理质量"做细粒度评估
3. 在 DSPy 编译阶段,ChainOfThought 更容易被自动优化器识别和调整
五、Metric:不只是打分,是定义问题本身
Metric(评估指标)是一个函数,它定义了"什么样的输出是好的"。它是优化器(Teleprompt)的评分标准,告诉编译器"朝哪个方向优化"。
我最早写的 metric 只有一行:
def seer_metric(example, pred, trace=None):
return 1.0 if pred.check_target == example.check_target else 0.0结果:模型的准确率上去了,但出现"自查"这个bug。因为这个 metric只衡量"答案对不对",不衡量"有没有违规"。
改进后的 metric 把规则遵守作为独立维度:
def _is_rule_compliant(example, pred):
if pred.check_target == example.seer_id:
return False # 自查违规
alive_players = _extract_alive_players(example.game_state)
if alive_players and pred.check_target not in alive_players:
return False # 查死人违规
return True
def seer_combined_metric(example, pred, trace=None):
rule_score = 1.0 if _is_rule_compliant(example, pred) else 0.0
answer_score = 1.0 if pred.check_target == example.check_target else 0.0
reasoning_score = seer_reasoning_quality(example, pred)
# 0.4 规则 + 0.4 答案 + 0.2 推理质量
return 0.4 * rule_score + 0.4 * answer_score + 0.2 * reasoning_scoreMetric 的天花板就是系统能力的上限。如果你只衡量"对不对",系统就只学会答对题。如果你不衡量推理质量,系统就只会输出最短的推理路径,哪怕那个推理是空洞的。
六、Optimizers:根据打分选择最优解
优化器 (Optimizers):即“编译器”,通过分析训练数据和指标自动优化整个程序。常用策略包括BootstrapFewShot(生成Few-shot示例)、MIPROv2(综合优化)和COPRO(生成并优化任务指令)。
我一开始使用的是BootstrapFewShot,但是每次都只会选择同一个Few-shot,导致大模型每次输出的结果都相差不大,这里我就准备换一个优化器,最终我选择了MIPROv2作为我们项目的优化器,这是我们的一个优化器的参数配置:
optimizer = MIPROv2(
metric=seer_combined_metric,
num_candidates=10, # 候选 prompt 数量
max_bootstrapped_demos=4, # 自助采样的示例上限
max_labeled_demos=8, # 直接作为 few-shot 的示例上限
metric_threshold=0.85, # 达到 85% 就提前停止
)
compiled = optimizer.compile(
module(),
trainset=trainset,
num_trials=12, # 搜索次数(这里是 compile 的参数)
requires_permission_to_run=False,
)写在最后:DSPy 教会我的最重要的事
用 DSPy 做狼人杀 AI,我最大的感受不是“这个工具真好用”,而是重新理解了什么叫“定义问题”。传统编程追问的是“怎么让模型输出正确答案”,而在 DSPy 的框架里,问题变成了“怎么定义什么是正确答案”——听起来差不多,实际上天差地别。
前者的答案是“写更好的 prompt”,后者的答案则是把对问题的理解翻译成可量化的 metric,这要求你对问题本身有足够深的把握,才能设计出正确的目标函数。DSPy 并不会帮你理解问题,它只能在你真正理解问题之后,帮你找到更好的解法——这个顺序不能颠倒。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)