2026年江西省研究生数学建模竞赛3题:电子健康记录数据补全及其优化算法完整思路、代码、模型、文章,全网首发高质量分享!
2026年江西省研究生数学建模竞赛3题:电子健康记录数据补全及其优化算法完整思路、代码、模型、文章,全网首发高质量分享!
赛题全文
2026年江西省研究生数学建模竞赛题
电子健康记录数据补全及其优化算法
问题背景
数字化医疗时代下,电子健康记录(EHR)是恶性肿瘤无创早期筛查、患病风险预判的关键临床数据源。相较于基于问卷调查的生活习惯等获取的数据,电子健康记录(Electronic Health Record, EHR)涵盖的病史、症状和相关疾病等因素与目标疾病发生更接近,它能有效地识别目标疾病[1]。 但由于受设备故障、体检漏检、录入失误、受试者失访拒访、中途退出随访等因素影响,EHR中的缺失数据非常普遍,这会引发诸如偏差来源异质性和统计功效损失等分析问题[1]。直接使用含缺失的EHR数据开展建模与患病预测, 会造成模型参数偏移、预测结果失真,大幅降低肿瘤筛查结论可靠性,阻碍数据驱动精准医疗落地应用[2]。
缺失数据补全是EHR数据预处理的核心环节,主流填补方法包括通过数据降维和机器学习模型挖掘数据图结构信息[3]、SVD-PCA低秩降维重构[4]和NMF(非负矩阵分解)等算法,这些算法已经运用于各类数据的修补,也是临床医学缺失值修复的基本方法。
本次建模依托总样本量20333例患者临床数据集,单患者体征矩阵行数区间8~336行,统一固定41项生命体征检测指标;其中包含700份规格为36行×41列的标准化样本,样本普遍存在缺失值(NaN)。
本选题要求参赛队伍选取标准化子集完成全部建模任务,围绕数据预处理、NMF缺失补全、PCA关键指标挖掘、多算法精度对比开展数学建模,实现肿瘤高危生理指标筛选与EHR最优补全算法择优。
建模任务
任务1 数据预处理:缺失率计算、数据归一化与低维数据补全
考虑附件2中training_setA的第一个文件p000001.psv,统计前40个生命特征以及缺失信息,选择前36个特征变量,找出其中缺失率小于90%的前11个特征标量.
从training_setA中筛选50份36×41规格患者临床数据矩阵,采用归一化方法统一指标量纲,消除维度差异;精准标记矩阵内所有NaN缺失位置,为后续补全提供位置依据。
设待补全数值矩阵如下:
选取两种以上的方法完成该矩阵的缺失值补全,说明不同方法的特点.
任务2 完整数据集PCA主成分分析建模
NMF缺失填充:基于清洗完毕的有效数据(附件2中的training_setA)构造观测矩阵A,结合临床数据稀疏特性合理选定分解秩r, 构建带非负约束的NMF低秩逼近模型A≈WH, 通过迭代算法求解非负矩阵W和H, 实现全部缺失点位数值填充,生成无缺失完整数据集.
Z-score标准化方法对数据集进行标准化处理,消除各生命体征指标量纲干扰,基于标准化数据求解指标协方差矩阵;
对协方差矩阵进行特征分解,将特征值按从大到小排列,提取第一和第二主成分对应的特征向量,计算所有样本在两类主成分上的得分;
分别计算第一、第二主成分的方差贡献率,量化单个主成分对原始数据信息的解释占比。
任务3 基于PCA结果的临床数据规律挖掘
根据双主成分方差贡献率与指标载荷系数,筛选与主成分相关性较高的生命体征参数,确定影响患者生理状态的关键预警指标;
分别对NMF补全前残缺原始数据、补全后完整数据开展同等条件PCA运算,对比补全前后主成分组成、方差贡献率变化,定量评价NMF非负低秩补全对EHR数据质量与数据分析有效性的提升效果。
任务4 多算法、多缺失率下补全精度对比与最优模型筛选
结合临床场景常规10%~20%样本脱落现象与高缺失极端工况,设置10%、20%、30%、40%、50%五档缺失比例,在基准完整数据集上随机掩码生成对应缺失样本;
选取SVD-PCA、NMF和相关算法逐一完成缺失填充,以相对平方误差RSE作为量化评价指标, 统计各算法在不同缺失比例下的误差结果;
综合补全精度、模型稳定性、算法计算复杂度,筛选适配EHR数据最优缺失补全模型。
附件说明
附录1:数据集字段释义、样本分布说明、各项生命体征指标医学正常参考值域
附录2:原始实验RSE对照数据表
参考文献
仉率杰. 面向大规模EHR稀疏数据的疾病数字筛查因果贝叶斯网络模型研究[D]. 山东:山东大学, 2025.
张茹. 基于真实世界数据的代谢相关脂肪性肝病风险预测模型构建及高危人群风险管理效果评价[D]. 江苏:南京医科大学,2023.
张鼎文. 基于机器学习的急诊数据分析与风险预测[D]. 四川:电子科技大学,2024.
王素. 基于不动点迭代算法的矩阵补全[D]. 江苏:南京航空航天大学,2022.
H Kristiina, S Kaija, N Pirkko, Definition, structure, content, use and impacts of electronic health records: A review of the research literature, International Journal of Medical Informatics, 2008, 77(5) 291-304.
A E Johnson, L Bulgarelli, L Shen, et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci Data 10, 1 (2023). https://doi.org/10.1038/s41597-022-01899-x.
赛题图片
第二主成分的方差贡献率,量化单个主成分对原始数据信息的解释占比。
原赛题要求
第二主成分的方差贡献率,量化单个主成分对原始数据信息的解释占比。
任务3 基于PCA结果的临床数据规律挖掘
根据双主成分方差贡献率与指标载荷系数,筛选与主成分相关性较高的生命体征参数,确定影响患者生理状态的关键预警指标;
分别对NMF补全前残缺原始数据、补全后完整数据开展同等条件PCA运算,对比补全前后主成分组成、方差贡献率变化,定量评价NMF非负低秩补全对EHR数据质量与数据分析有效性的提升效果。
任务4 多算法、多缺失率下补全精度对比与最优模型筛选
结合临床场景常规10%~20%样本脱落现象与高缺失极端工况,设置10%、20%、30%、40%、50%五档缺失比例,在基准完整数据集上随机掩码生成对应缺失样本;
选取SVD-PCA、NMF和相关算法逐一完成缺失填充,以相对平方误差RSE作为量化评价指标, 统计各算法在不同缺失比例下的误差结果;
综合补全精度、模型稳定性、算法计算复杂度,筛选适配EHR数据最优缺失补全模型。
附件说明
附录1:数据集字段释义、样本分布说明、各项生命体征指标医学正常参考值域
附录2:原始实验RSE对照数据表
参考文献
仉率杰. 面向大规模EHR稀疏数据的疾病数字筛查因果贝叶斯网络模型研究[D]. 山东:山东大学, 2025.
张茹. 基于真实世界数据的代谢相关脂肪性肝病风险预测模型构建及高危人群风险管理效果评价[D]. 江苏:南京医科大学,2023.
张鼎文. 基于机器学习的急诊数据分析与风险预测[D]. 四川:电子科技大学,2024.
王素. 基于不动点迭代算法的矩阵补全[D]. 江苏:南京航空航天大学,2022.
H Kristiina, S Kaija, N Pirkko, Definition, structure, content, use and impacts of electronic health records: A review of the research literature, International Journal of Medical Informatics, 2008, 77(5) 291-304.
A E Johnson, L Bulgarelli, L Shen, et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci Data 10, 1 (2023). https://doi.org/10.1038/s41597-022-01899-x.
问题二完整解答:NMF补全与PCA主成分分析
6.1 Q2KL-NMF与PCA统一链路
本文在Q2KL-NMF与PCA统一链路中,以Q1清洗后的training_setA有效数据为输入对象,将50份患者时间序列展开为样本-指标矩阵,形成1800个样本、11个生命体征变量的建模数据。该链路的核心目的不是直接解释临床机制,而是先在原始NaN结构受控的条件下完成低秩非负补全,再在无缺失矩阵上进行PCA降维,为后续主成分载荷解释和指标筛选提供一致的数据基础。
变量与约束设置围绕观测值保护和非负低秩表示展开。本文记原始有效数据为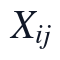 ,观测掩码为
,观测掩码为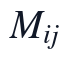 ,非负平移量为
,非负平移量为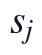 ,NMF建模矩阵为
,NMF建模矩阵为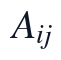 ,样本因子矩阵和指标载荷矩阵分别为
,样本因子矩阵和指标载荷矩阵分别为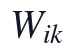 与
与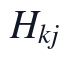 。其中,用于区分真实观测位置与原始缺失位置,
。其中,用于区分真实观测位置与原始缺失位置, 需满足非负约束,观测位置在补全过程中保持原始值不被覆盖,缺失位置才由低秩重构结果填充。
需满足非负约束,观测位置在补全过程中保持原始值不被覆盖,缺失位置才由低秩重构结果填充。
为使NMF适用于含负值或中心化后变量,本文先按变量列进行非负化处理,并保留原始缺失结构:
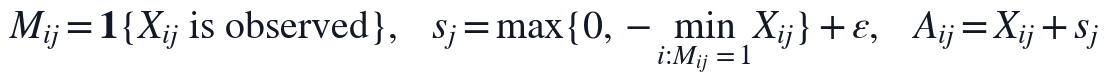
该变量关系保证进入NMF的矩阵满足非负要求,同时不改变掩码所记录的缺失位置。后续KL散度损失只在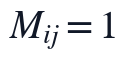 的位置计算,使真实观测值承担拟合约束,原始缺失值不作为监督标签参与误差计算;在完成重构后,再对补全值执行反平移,恢复到各生命体征变量的原始量纲口径。
的位置计算,使真实观测值承担拟合约束,原始缺失值不作为监督标签参与误差计算;在完成重构后,再对补全值执行反平移,恢复到各生命体征变量的原始量纲口径。
实现步骤上,本文首先读取Q1固定的11变量有效矩阵及NaN掩码,构造非负观测矩阵;随后采用NNDSVDa初始化KL-NMF模型,以减少初值选择对分解方向的影响;分解秩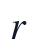 在候选范围内根据观测重构误差、信息准则惩罚和多次初始化一致性综合确定。固定秩后,通过KL散度NMF的乘法更新求解
在候选范围内根据观测重构误差、信息准则惩罚和多次初始化一致性综合确定。固定秩后,通过KL散度NMF的乘法更新求解 和
和 ,并以
,并以 在原始缺失位置生成补全值,而观测位置继续保留中的原始记录。
在原始缺失位置生成补全值,而观测位置继续保留中的原始记录。
从输出链路看,本节依次生成NMF观测矩阵、分解秩选择依据、非负矩阵、无缺失完整数据集、Z-score标准化数据、协方差矩阵、特征值与特征向量以及样本主成分得分。PCA阶段只使用NMF补全后的完整矩阵,先按列标准化以消除不同生命体征量纲差异,再计算协方差矩阵并进行特征分解,从而使缺失补全结果与第一、第二主成分提取处于同一数据口径下。
6.2 本轮所有Q2输出均来自Q1固定的同一
本轮所有Q2输出均来自Q1固定的同一11变量矩阵,样本规模为1800,建模对象为清洗后按“患者时刻样本—生命体征指标”展开的有效EHR矩阵。本文将原始有效数据记为X,观测掩码记为M,其中真实观测位置进入NMF拟合,原始缺失位置仅在重构后接受补全。变量与约束的核心在于同时保持三点:NMF输入必须非负,W与H必须满足非负低秩分解要求,原始观测值在补全过程中不得被重构值覆盖。
为使含负值或归一化后可能出现负偏移的指标满足NMF输入条件,本文按指标列构造非负平移量,并用掩码矩阵保留原始缺失结构。
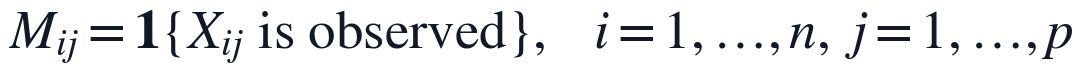
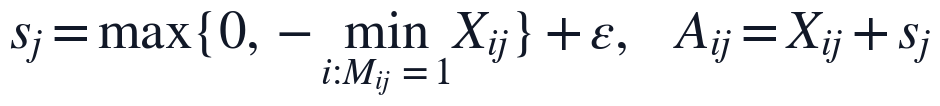
其中,A为进入KL-NMF的非负观测矩阵,s_j为第j个指标的平移参数,epsilon用于避免零值引起的数值不稳定。M_{ij}=1的位置代表题面附件中真实存在的观测值,M_{ij}=0的位置代表Q1标记的NaN缺失点,因此后续损失函数只在真实观测位置累积误差,缺失点不被当作监督标签参与训练。
考虑电子健康记录变量非负化后仍具有偏态、稀疏和潜在低秩相关结构,本文采用带观测掩码的KL散度NMF刻画A与WH之间的差异,并加入轻量复杂度惩罚以抑制不必要的因子放大。
\min_{W,H\ge 0}\ J_r(W,H)=\sum_{i=1}^{n}\sum_{j=1}^{p}M_{ij}\left[A_{ij}\log\frac{A_{ij}+\epsilon}{(WH)_{ij}+\epsilon}-A_{ij}+(WH)_{ij}\right]+\lambda\left(\|W\|_{1}+\|H\|_{1}\right)
该目标函数中的W_{ik}表示第i个样本在第k个潜在生理因子上的非负强度,H_{kj}表示第k个潜在因子对第j个指标的非负载荷。约束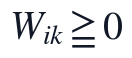 、
、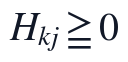 保证分解结果具有非负可解释性;掩码M保证模型只学习原始观测数据中的关联结构;补全时采用
保证分解结果具有非负可解释性;掩码M保证模型只学习原始观测数据中的关联结构;补全时采用 于M_{ij}=1的观测位置,采用(WH)_{ij}于M_{ij}=0的缺失位置,从而实现“观测值保持、缺失值补全”的约束关系。
于M_{ij}=1的观测位置,采用(WH)_{ij}于M_{ij}=0的缺失位置,从而实现“观测值保持、缺失值补全”的约束关系。
为减少初始值对秩选择和补全矩阵的影响,本文使用NNDSVDa初始化构造W和H的非负起点,再在固定候选秩下执行KL散度乘法更新。初始化先提取观测矩阵的主要低秩方向,并用观测均值尺度填补零元素。
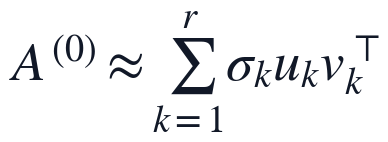

在此基础上,候选秩r限制在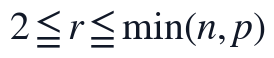 的低秩区间内,并按观测重构误差、BIC近似惩罚和复杂度惩罚综合筛选,最终选定r=2。实现步骤上,本文先由Q1输出读取同一有效矩阵和同一NaN掩码,再对候选r逐一初始化和迭代,记录候选秩误差与信息准则,随后只保留最终r=2对应的一组W、H、补全矩阵、秩选择依据和PCA输入,避免不同输出来自不同数据链路或不同NMF解。
的低秩区间内,并按观测重构误差、BIC近似惩罚和复杂度惩罚综合筛选,最终选定r=2。实现步骤上,本文先由Q1输出读取同一有效矩阵和同一NaN掩码,再对候选r逐一初始化和迭代,记录候选秩误差与信息准则,随后只保留最终r=2对应的一组W、H、补全矩阵、秩选择依据和PCA输入,避免不同输出来自不同数据链路或不同NMF解。
固定r=2后,本文采用乘法更新求解非负矩阵,分母中加入正则项和epsilon以保持迭代数值稳定,且每一项均由M控制其是否参与拟合。
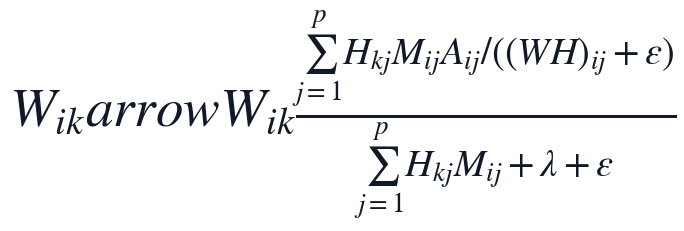
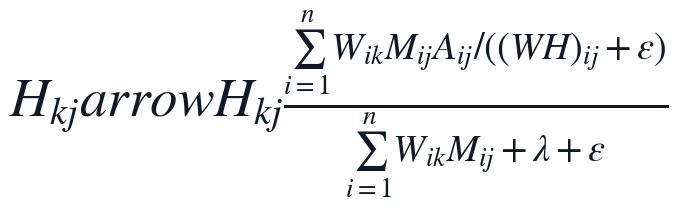
乘法更新天然保持W和H非负,缺失位置因M_{ij}=0不贡献拟合误差。迭代结束后,本文先在非负尺度上形成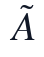 ,再按列减去s_j反平移得到
,再按列减去s_j反平移得到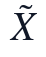 ,并在观测位置保留X_{ij}原值。由此得到的无缺失完整数据集继续作为PCA唯一输入,后续result_table、metrics、W/H、秩选择依据和PCA输出均对应同一NMF解。
,并在观测位置保留X_{ij}原值。由此得到的无缺失完整数据集继续作为PCA唯一输入,后续result_table、metrics、W/H、秩选择依据和PCA输出均对应同一NMF解。
NMF阶段输出观测矩阵A、分解秩r=2、非负矩阵W与H以及无缺失完整数据集;PCA阶段在上执行Z-score标准化、协方差矩阵计算和特征分解,提取前两个主成分特征向量、样本得分和方差贡献率。
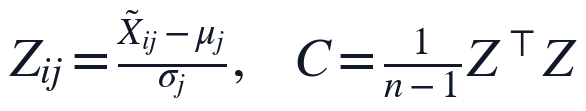

其中,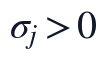 是标准化阶段的数值约束,C表示标准化后11个指标之间的协方差结构,q_k为第k个主成分方向,T_{ik}为样本得分。计算结果中,第一主成分方差贡献率为0.4187,第二主成分方差贡献率为0.1891,前两主成分累计方差贡献率为0.6079,说明该统一链路在完成缺失补全后,能够用二维主成分空间概括超过六成的标准化指标协方差信息。
是标准化阶段的数值约束,C表示标准化后11个指标之间的协方差结构,q_k为第k个主成分方向,T_{ik}为样本得分。计算结果中,第一主成分方差贡献率为0.4187,第二主成分方差贡献率为0.1891,前两主成分累计方差贡献率为0.6079,说明该统一链路在完成缺失补全后,能够用二维主成分空间概括超过六成的标准化指标协方差信息。
6.3 PCA在NMF补全后的完整矩阵上进行
本文在NMF补全得到的无缺失完整矩阵上继续执行PCA,即PCA在NMF补全后的完整矩阵上进行。设Q1清洗并筛选后的样本数为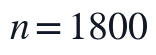 ,变量数为
,变量数为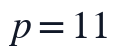 ,原始有效数据元素记为,观测掩码记为。NMF阶段输出的低秩重构矩阵用于原始缺失位置,真实观测位置保持不变,从而形成完整矩阵,该矩阵是后续标准化、协方差分解和主成分得分计算的唯一输入对象。
,原始有效数据元素记为,观测掩码记为。NMF阶段输出的低秩重构矩阵用于原始缺失位置,真实观测位置保持不变,从而形成完整矩阵,该矩阵是后续标准化、协方差分解和主成分得分计算的唯一输入对象。
为明确变量与约束,本文首先将NMF补全结果写为观测保持与缺失填充的组合形式,保证PCA分析不改变原始观测信息。
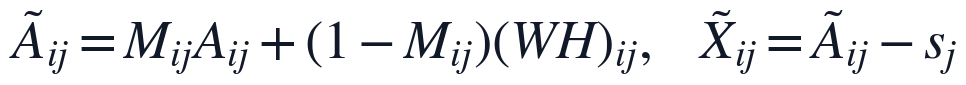
其中,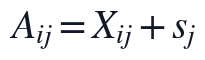 为非负化后的建模矩阵,为秩
为非负化后的建模矩阵,为秩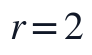 下求得的非负因子矩阵,为第
下求得的非负因子矩阵,为第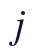 个指标的平移量。该约束使观测位置仍采用原始数据,缺失位置才由低秩结构给出补全值,避免PCA阶段混入未定义或重复覆盖的观测信息。
个指标的平移量。该约束使观测位置仍采用原始数据,缺失位置才由低秩结构给出补全值,避免PCA阶段混入未定义或重复覆盖的观测信息。
由于11个生命体征指标存在量纲差异,本文对完整矩阵按列进行Z-score标准化,并要求参与标准化的指标方差非零;若代码中遇到极小方差,则通过数值保护项避免除零。标准化变量构造为:
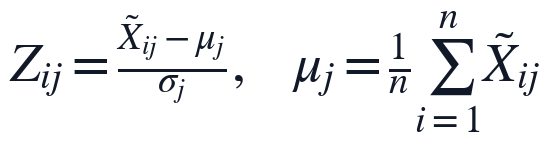
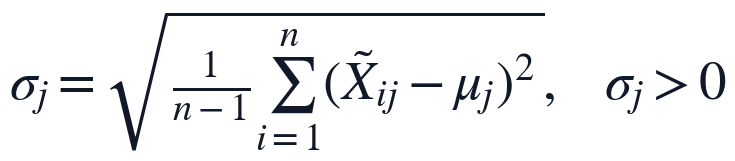
其中, 为PCA输入矩阵,
为PCA输入矩阵,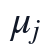 和
和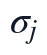 分别为补全后第个指标的样本均值与样本标准差。该处理将不同单位的生命体征映射到同一尺度,使协方差矩阵反映指标间共同变化关系,而不是受原始量纲大小支配。
分别为补全后第个指标的样本均值与样本标准差。该处理将不同单位的生命体征映射到同一尺度,使协方差矩阵反映指标间共同变化关系,而不是受原始量纲大小支配。
在完成标准化后,本文计算标准化矩阵的协方差矩阵,并对其进行特征分解。协方差矩阵和特征方程定义为:
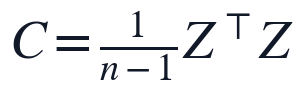
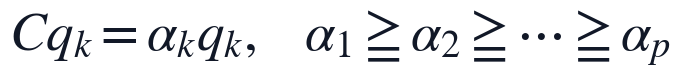
其中, 表示11个标准化指标之间的协方差结构,
表示11个标准化指标之间的协方差结构,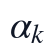 为第
为第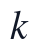 个主成分对应的特征值,
个主成分对应的特征值,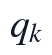 为对应特征向量。求解时按特征值降序排列,提取前两个特征向量作为第一、第二主成分方向;本问得到的前两项特征值分别为4.6084和2.0818,对应方差贡献率分别为0.4187和0.1891,前两主成分累计解释比例为0.6079。
为对应特征向量。求解时按特征值降序排列,提取前两个特征向量作为第一、第二主成分方向;本问得到的前两项特征值分别为4.6084和2.0818,对应方差贡献率分别为0.4187和0.1891,前两主成分累计解释比例为0.6079。
实现步骤上,本文先读取同一条Q1清洗数据链路得到的有效矩阵与NaN掩码,再调用NMF阶段选定的分解结果生成完整矩阵;随后按列计算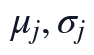 ,构造,计算,并调用对称矩阵特征分解得到特征值、特征向量和样本投影得分。主成分得分与方差贡献率按下式核算:
,构造,计算,并调用对称矩阵特征分解得到特征值、特征向量和样本投影得分。主成分得分与方差贡献率按下式核算:
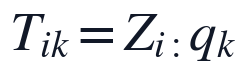
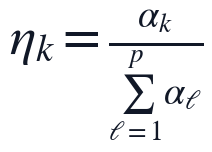
其中,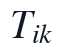 为第
为第 个样本在第个主成分上的坐标,
个样本在第个主成分上的坐标,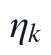 为该主成分的方差贡献率。该流程输出NMF补全后的无缺失完整数据集、Z-score标准化数据集、指标协方差矩阵、协方差矩阵特征值排序结果、第一和第二主成分特征向量、全部样本前两主成分得分以及两项方差贡献率;主成分得分散点结果用于呈现样本在二维主成分空间中的分布,协方差结构结果用于支撑PCA分解的变量相关基础。
为该主成分的方差贡献率。该流程输出NMF补全后的无缺失完整数据集、Z-score标准化数据集、指标协方差矩阵、协方差矩阵特征值排序结果、第一和第二主成分特征向量、全部样本前两主成分得分以及两项方差贡献率;主成分得分散点结果用于呈现样本在二维主成分空间中的分布,协方差结构结果用于支撑PCA分解的变量相关基础。
6.4 核心结果、图表证据与题目响应
本文在清洗后的同一有效数据矩阵上完成KL散度NMF补全与PCA分析,样本数为1800,变量数为11,最终选定NMF分解秩为r=2。补全后完整数据经Z-score标准化并进行协方差矩阵特征分解,第一主成分特征值为4.6084,方差贡献率为0.4187;第二主成分特征值为2.0818,方差贡献率为0.1891;前两主成分累计方差贡献率为0.6079。该结果表明,两个主成分已经能够概括补全后标准化EHR矩阵中约六成的总体方差信息,低秩补全与降维解释在同一数据链路下保持一致。
表6-1 NMF分解秩r及选择依据表
| 分解秩r | 观测重构误差 | BIC近似值 | 稳定性 | 选择评分 | 是否选定 |
|---|---|---|---|---|---|
| 2 | 0.1198274404155422 | -48185.39207859832 | 0.997483817834546 | 0.1698526022371968 | 是 |
| 3 | 0.0993984926801102 | -37670.24145265534 | 0.9951490901190962 | 0.1794470017789192 | 否 |
| 4 | 0.0808275491055663 | -27943.2625240034 | 0.9952418418171736 | 0.1908751306873946 | 否 |
| 5 | 0.0737673655348228 | -13645.744324690211 | 0.9944474193155768 | 0.213822891341667 | 否 |
| 6 | 0.0659953783775552 | -137.46553298622894 | 0.9937222627920008 | 0.2360581557496351 | 否 |
| 7 | 0.0625724445207033 | 15670.464466984078 | 0.9931829664676116 | 0.2626406148560272 | 否 |
分解秩r在2至7之间逐步考察,观测重构误差由0.1198降至0.0626,说明提高秩可继续降低拟合残差,但同时BIC近似值跨度较大,范围为-48185.39至15670.46,提示模型复杂度需要约束。任务2在样本数1800、变量数11条件下选取KL-NMF的r=2,前两主成分累计方差贡献率为0.6079,虽未追求最低重构误差,但以较低秩保留主要结构,便于后续补全算法解释和稳定实施。
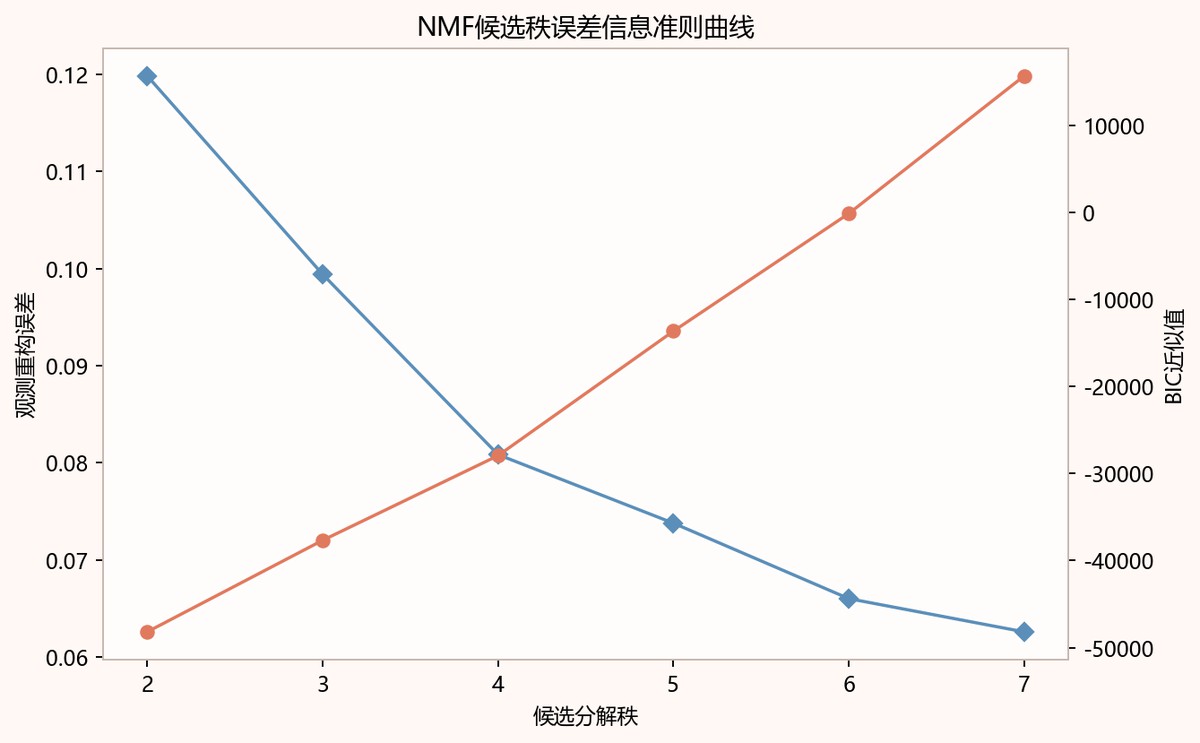
图中横轴为候选分解秩、左轴为观测重构误差、右轴为BIC近似值。蓝色误差曲线随秩从2到7持续下降,r=2约0.12、r=7约0.063;橙色BIC曲线整体上升,r=2处最低。结合样本数1800和变量数11,选择KL-NMF秩r=2具有信息准则上的优势。
核心结果表格中,NMF部分给出了观测矩阵A、分解秩r、非负矩阵W和H以及补全后的无缺失完整数据集;PCA部分进一步给出Z-score标准化数据、指标协方差矩阵、特征值排序结果、前两主成分特征向量和样本主成分得分。特征值序列由4.6084、2.0818、1.1128、1.0278逐步下降,说明前两个方向承载了更集中的方差结构,而后续成分对总体变异的边际解释能力相对降低。第一主成分对应的特征向量在多个变量上呈现较大的绝对权重,第二主成分则在部分指标上形成与第一主成分不同的方向组合,使二维主成分得分能够同时保留主要整体差异与次级结构差异。
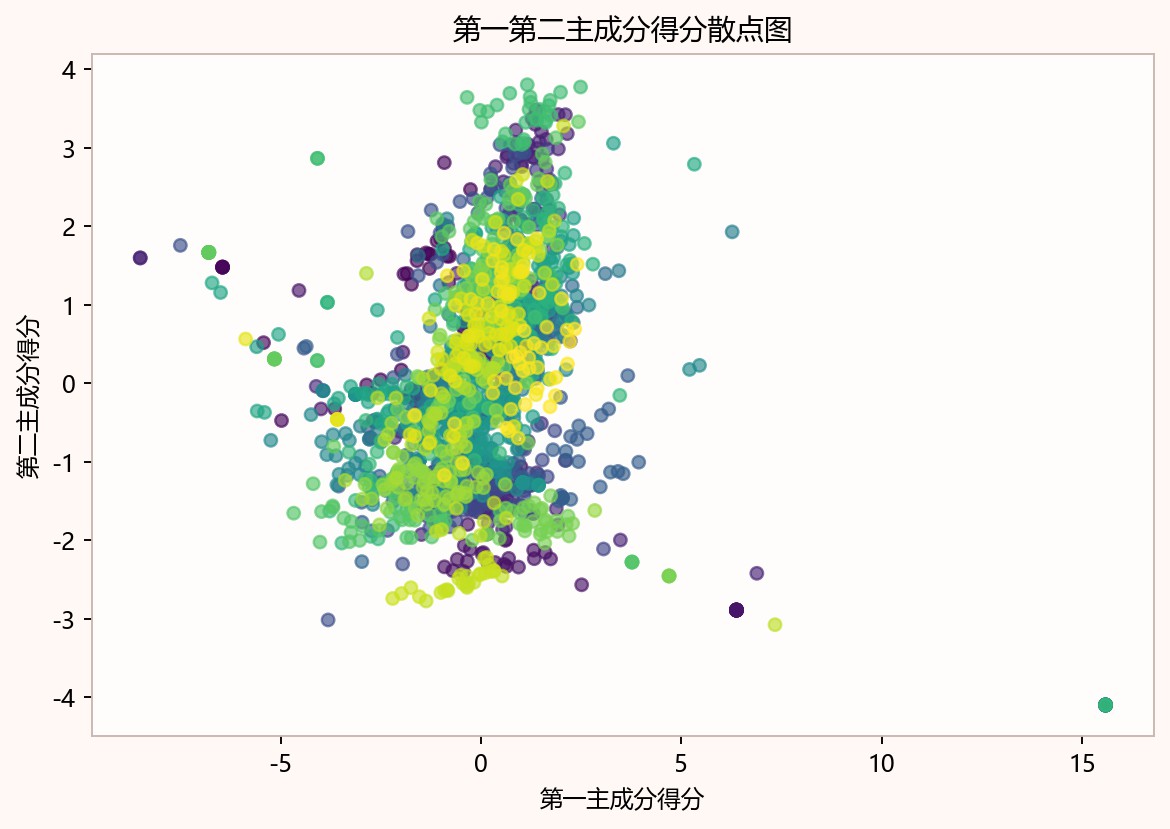
散点图横轴为第一主成分得分、纵轴为第二主成分得分,点云主要集中在x约-3到3、y约-2.5到3.5之间,并呈纵向拉伸的弯曲带状结构。颜色从紫到黄显示样本在低维空间中连续过渡,少量离群点延伸到x约15和y约-4附近,说明前两主成分能概括主要差异但仍有极端样本。
代表性图像进一步支撑了上述数值判断。NMF候选秩误差与信息准则曲线中,r=2处兼顾了观测重构误差下降和复杂度控制,继续增加秩带来的解释增益趋于有限,因此将r=2作为后续补全的统一低秩设定。主成分得分散点分布反映出样本在第一、第二主成分方向上的投影差异,说明补全后的完整矩阵不仅可用于填补缺失位置,也可形成可比较的低维样本表示。指标协方差结构热力图则反映了标准化后变量间仍存在成组相关关系,这为PCA能够在前两个方向集中解释0.6079的方差信息提供了结构性依据。
表6-2 NMF矩阵H表
| Age | Gender | HR | Resp | MAP | O2Sat | SBP | Unit1 | DBP | Temp | Glucose |
|---|---|---|---|---|---|---|---|---|---|---|
| 20.702258394194313 | 0.21904557589040252 | 35.99495901228892 | 7.8468339244137155 | 33.79580537263771 | 38.31139672512507 | 50.95133034462718 | 0.2570895272011309 | 26.055254072770353 | 14.694725306072604 | 39.18552247704203 |
| 16.41738913045585 | 0.057895521200925754 | 4.731383021766137 | 0.752629405506641 | 1e-08 | 9.051251157087561 | 1.0132251932120282e-08 | 1e-08 | 1e-08 | 3.469424274468317 | 74.44654662403448 |
在KL-NMF取分解秩r=2时,1800个样本、11个变量被压缩为两个潜在成分,前两主成分累计方差贡献率为0.6079,说明低秩结构已能解释主要共变信息。预览记录中Age取16.417至20.702、均值18.56,波动较小;Gender均值0.1385,取值集中;HR范围4.731至35.995、均值20.363,离散程度最突出,提示心率相关信息在潜在特征中具有较强区分作用,可作为后续补全优化的重要权重依据。
从运行机理看,KL-NMF只在观测掩码标记的真实观测位置计算拟合偏差,缺失位置由低秩重构值生成,同时观测位置保持原始数值不被覆盖。NNDSVDa初始化使W和H从与数据主要方向一致的非负起点出发,减少了初值对补全矩阵和秩选择的影响。随后PCA并非在原始残缺矩阵上直接求解,而是在NMF生成的无缺失完整数据集上执行标准化、协方差分解和得分计算,因此主成分特征值、特征向量、方差贡献率和样本得分具有统一的数据基础。
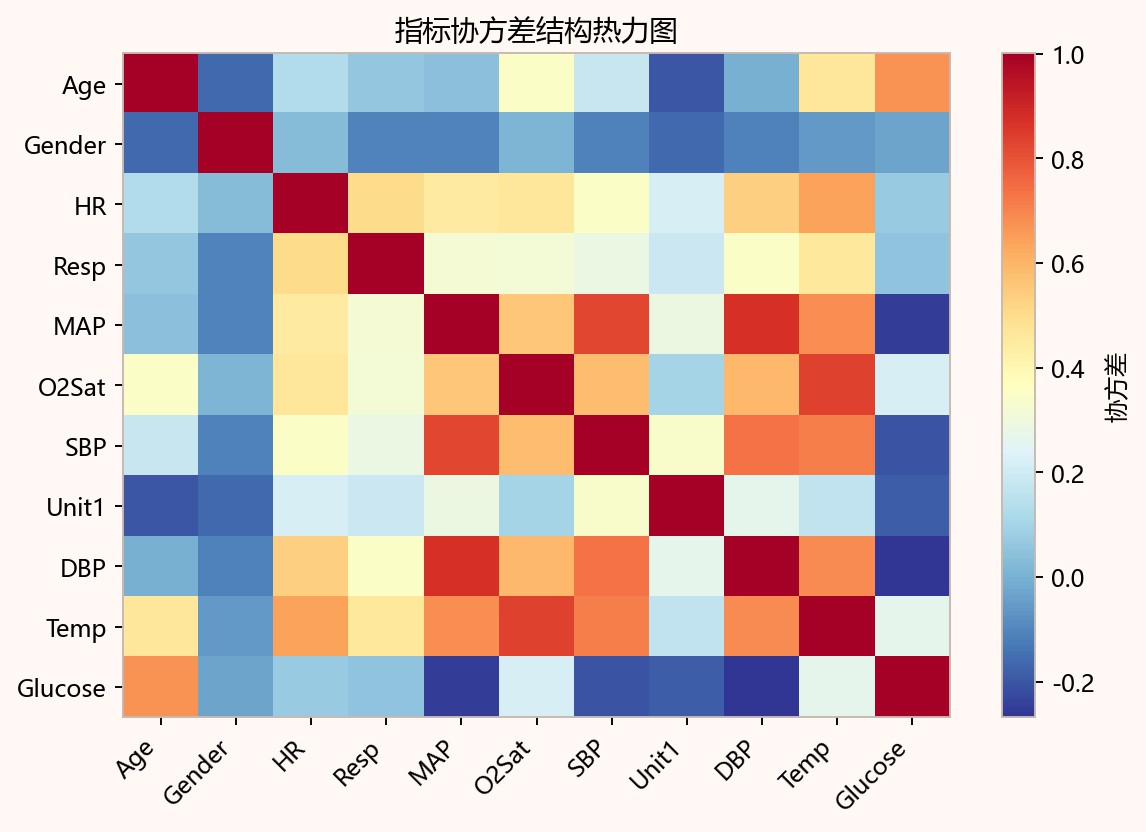
热力图横纵轴均为Age、Gender、HR、Resp、MAP、O2Sat、SBP、Unit1、DBP、Temp、Glucose等11项指标,对角线为深红色1.0。MAP、SBP、DBP与Temp、O2Sat之间多呈暖色,协方差较高;Glucose与MAP、SBP、DBP等出现深蓝负相关区域,Age与Gender、Unit1也偏蓝,体现变量间结构差异。
围绕关键输出,本文得到的r=2、W和H矩阵、NMF补全完整数据集、Z-score标准化矩阵、协方差矩阵、特征值排序、前两主成分特征向量、全部样本二维主成分得分以及0.4187和0.1891两项方差贡献率,构成了第二问从缺失补全到主成分解释的完整结果链条。该结果说明,非负低秩结构能够在不改变真实观测值的前提下补齐EHR矩阵,PCA则将补全后的多指标信息压缩到两个主要解释方向,为后续识别主要生理状态差异提供了可计算的低维表示。
表6-3 NMF矩阵W表
| 潜在因子1 | 潜在因子2 |
|---|---|
| 3.3447208513718865 | 0.7989947511496908 |
| 2.0969129669114754 | 2.3741582764449998 |
| 2.3716539671634433 | 1.7958946542436742 |
| 2.336542940757503 | 1.847810158625141 |
| 2.4700107391708266 | 1.5655370380047766 |
| 2.4801581114627598 | 1.628431469495933 |
| 2.4131604033367524 | 1.7269487617095836 |
| 2.1597078135750056 | 2.332423041370877 |
仅展示前 8 行,完整表格已保留在本地分享包中。
潜在因子1的取值整体高于潜在因子2,均值分别为2.545和0.4504,说明在r=2的KL-NMF分解下,样本主要由第一潜在结构贡献。潜在因子1范围为1.421至3.345,波动相对集中;潜在因子2范围为0至2.421,虽均值较低但存在零值和较高个体差异,提示其更可能刻画少数样本中的补充性特征。结合1800个样本、11个变量及前两主成分累计方差贡献率0.6079,二维潜在表示已保留主要信息,可为后续缺失模式识别和数据补全过程提供较简洁、可解释的低维权重依据。
问题三
问题三图表结果:PCA结果解释与临床规律挖掘
关键图表与结果
表7-1 NMF补全效果定量评价表
| 补全前后方差贡献率变化 | 前k高载荷变量重合率 | 载荷余弦相似度 | 高相关变量数量 | 关键预警指标数量 |
|---|---|---|---|---|
| 0.2297595273360633 | 0.5 | -0.5561470663910407 | 6 | 5 |
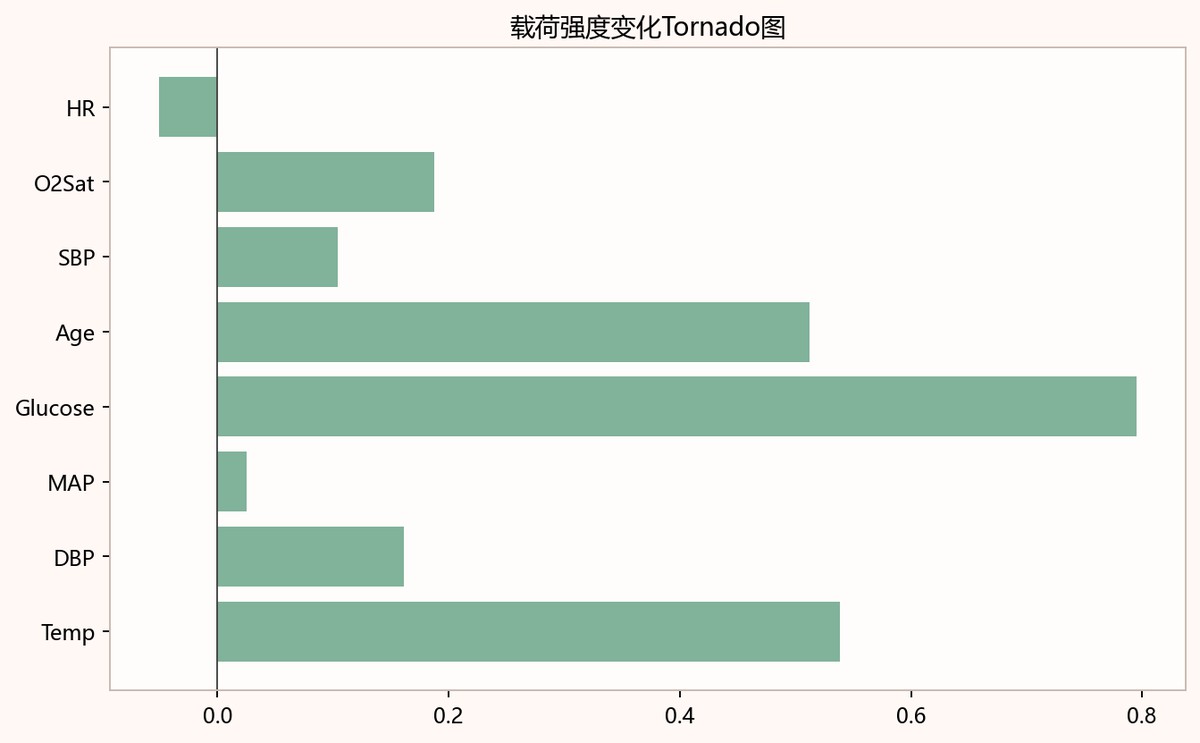
图7-1 载荷强度变化Tornado图
表7-2 关键预警指标筛选结果表
| 生命体征参数 | 补全前第一主成分载荷 | 补全前第二主成分载荷 | 补全前综合载荷强度 | 补全后第一主成分载荷 | 补全后第二主成分载荷 | 补全后综合载荷强度 | 旋转后第一因子载荷 | 旋转后第二因子载荷 | 医学归类 | 是否高相关参数 | 是否关键预警指标 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Temp | 0.08843164021259854 | -0.4179685130795896 | 0.4272210586062601 | -0.9156560598525907 | 0.3061172296348774 | 0.9654707547223289 | -0.8723170881891923 | 0.413759200353579 | 代谢状态 | 是 | 是 |
| DBP | 0.6830789974196011 | 0.3118200501872 | 0.7508852511632621 | -0.8648245962980003 | -0.29000591186464153 | 0.9121540501902305 | -0.8933707711008941 | -0.18415666325451333 | 循环系统 | 是 | 是 |
| MAP | 0.8663406847038788 | 0.17086668824266601 | 0.8830297883560906 | -0.8615294329951908 | -0.28623101291951286 | 0.907833220737127 | -0.8896465261303017 | -0.1808043561926328 | 循环系统 | 是 | 是 |
| Glucose | 0.08402918382194095 | -0.07380898086189933 | 0.1118421628441339 | 0.002177938766513696 | 0.9070333469822025 | 0.9070359617760517 | 0.11098069130129519 | 0.9002208185291508 | 代谢状态 | 是 | 是 |
| SBP | 0.7362172175114882 | 0.1704299562254758 | 0.7556865496615481 | -0.8382730759462946 | -0.18994251349607938 | 0.8595230702486528 | -0.8550062320101448 | -0.08800142904229277 | 循环系统 | 是 | 是 |
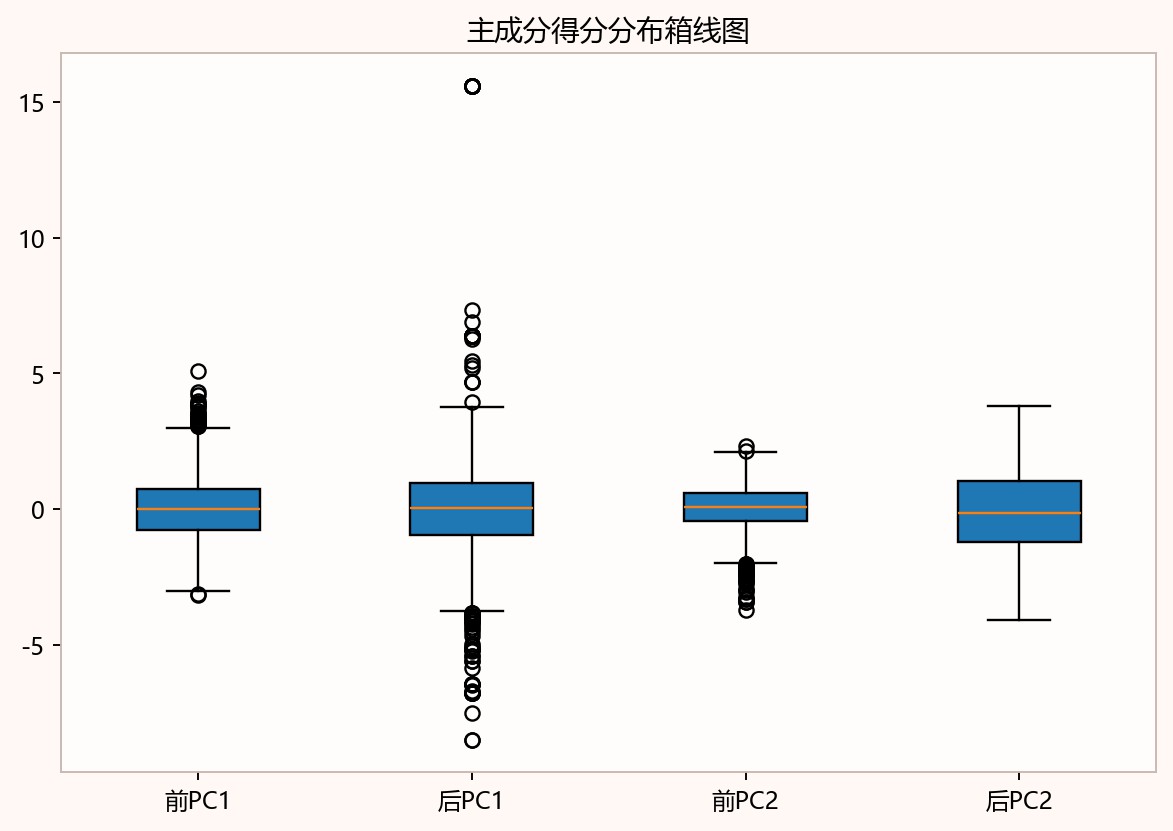
图7-2 主成分得分分布箱线图
表7-3 指标载荷系数结果表
| 生命体征参数 | 补全前第一主成分载荷 | 补全前第二主成分载荷 | 补全前综合载荷强度 | 补全后第一主成分载荷 | 补全后第二主成分载荷 | 补全后综合载荷强度 | 旋转后第一因子载荷 | 旋转后第二因子载荷 | 医学归类 | 是否高相关参数 | 是否关键预警指标 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Temp | 0.08843164021259854 | -0.4179685130795896 | 0.4272210586062601 | -0.9156560598525907 | 0.3061172296348774 | 0.9654707547223289 | -0.8723170881891923 | 0.413759200353579 | 代谢状态 | 是 | 是 |
| DBP | 0.6830789974196011 | 0.3118200501872 | 0.7508852511632621 | -0.8648245962980003 | -0.29000591186464153 | 0.9121540501902305 | -0.8933707711008941 | -0.18415666325451333 | 循环系统 | 是 | 是 |
| MAP | 0.8663406847038788 | 0.17086668824266601 | 0.8830297883560906 | -0.8615294329951908 | -0.28623101291951286 | 0.907833220737127 | -0.8896465261303017 | -0.1808043561926328 | 循环系统 | 是 | 是 |
| Glucose | 0.08402918382194095 | -0.07380898086189933 | 0.1118421628441339 | 0.002177938766513696 | 0.9070333469822025 | 0.9070359617760517 | 0.11098069130129519 | 0.9002208185291508 | 代谢状态 | 是 | 是 |
| Age | -0.3462791303503905 | -0.11654120843656306 | 0.36536432417530473 | -0.26498419357893815 | 0.8364102995296925 | 0.8773817937511754 | -0.16272458573943077 | 0.8621598002702058 | 人口学变量 | 是 | 否 |
| SBP | 0.7362172175114882 | 0.1704299562254758 | 0.7556865496615481 | -0.8382730759462946 | -0.18994251349607938 | 0.8595230702486528 | -0.8550062320101448 | -0.08800142904229277 | 循环系统 | 是 | 是 |
| O2Sat | 0.06952646601475763 | 0.6497212295134499 | 0.6534306432644327 | -0.7916511407628752 | 0.28331581739634215 | 0.8408206592717137 | -0.7519433484027516 | 0.37624537452436263 | 呼吸系统 | 否 | 否 |
| HR | 0.3746014051525035 | -0.6373850230072465 | 0.7393144664458949 | -0.684838083239498 | 0.07300413252711965 | 0.688718232386211 | -0.6711332556847711 | 0.15463814773576068 | 循环系统 | 否 | 否 |
仅展示前 8 行,完整表格已保留在本地分享包中。
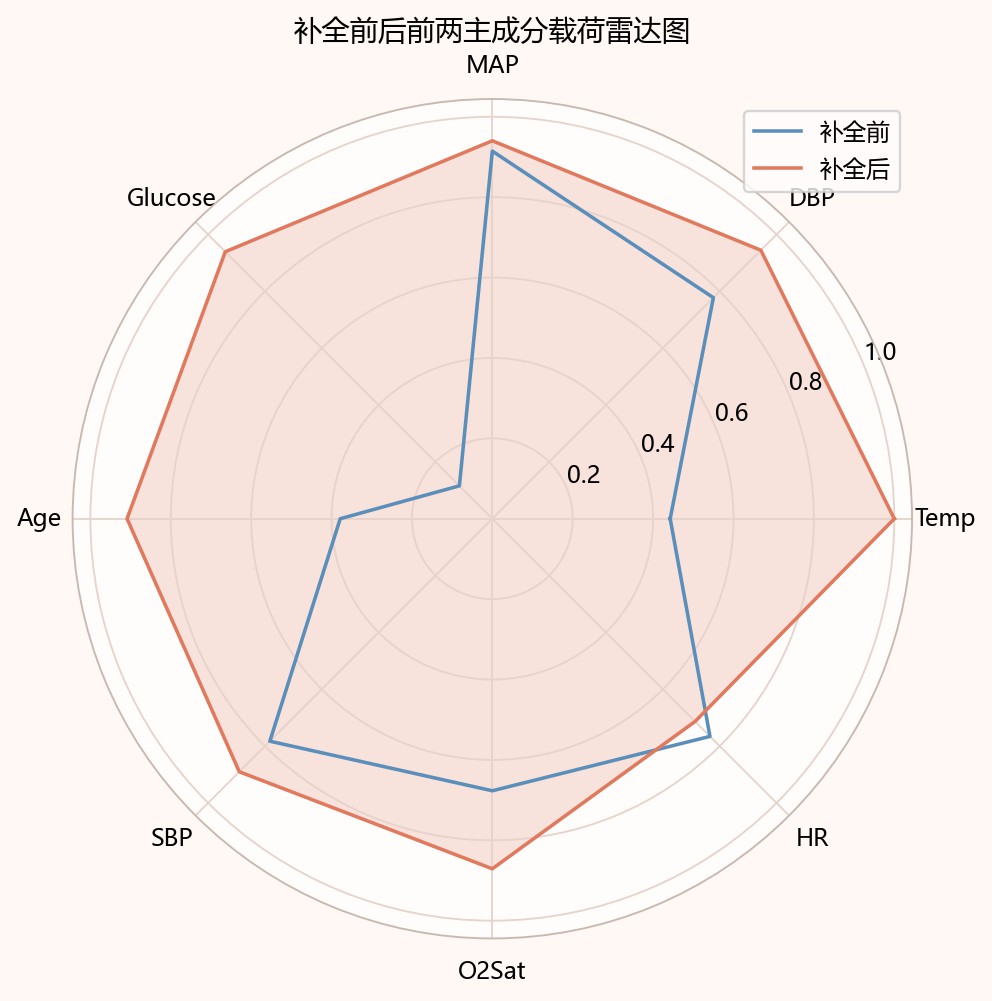
图7-3 补全前后前两主成分载荷雷达图
表7-4 补全前协方差矩阵表
| 变量名 | Age | Gender | HR | Resp | MAP | O2Sat | SBP | Unit1 | DBP | Temp | Glucose |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Age | 0.98 | -0.19458790303560503 | -0.07637062542942877 | -0.08167538891581275 | -0.1875171869931665 | -0.16680213774580557 | -0.021237286809663386 | -0.24828922051142524 | -0.28021418490461325 | -0.038225993561482215 | 0.014428583496552527 |
| Gender | -0.19458790303560503 | 0.98 | 0.021487988303345848 | -0.12388100058805573 | -0.14865759937047449 | 0.05306446004365413 | -0.16155645673130126 | -0.16144496012040796 | -0.15677415842611622 | 0.10347494041663571 | -0.02795847390306522 |
| HR | -0.07637062542942877 | 0.021487988303345848 | 0.98 | 0.39073141148074814 | 0.21868206108901028 | -0.23958637882994305 | 0.04303036772265843 | 0.1594840682240576 | 0.14506785747141732 | 0.18969681161639654 | 0.03066966144166962 |
| Resp | -0.08167538891581275 | -0.12388100058805573 | 0.39073141148074814 | 0.98 | 0.1372309479820131 | -0.23271466217387599 | 0.07027177996218983 | 0.14956123873607088 | 0.02731761469413197 | 0.15569437592432017 | 0.04304652285770104 |
| MAP | -0.1875171869931665 | -0.14865759937047449 | 0.21868206108901028 | 0.1372309479820131 | 0.98 | 0.07856564392024654 | 0.7124962973240194 | 0.20787857558182168 | 0.5857491585547855 | -0.004998145568392877 | 0.016617579772273378 |
| O2Sat | -0.16680213774580557 | 0.05306446004365413 | -0.23958637882994305 | -0.23271466217387599 | 0.07856564392024654 | 0.98 | 0.055877601190472824 | -0.005288240334417631 | 0.176360461278117 | -0.05869753010914565 | 0.00048593953978819077 |
| SBP | -0.021237286809663386 | -0.16155645673130126 | 0.04303036772265843 | 0.07027177996218983 | 0.7124962973240194 | 0.055877601190472824 | 0.98 | 0.2736563146157151 | 0.3264648477255531 | 0.06855436405528245 | 0.02865840914987051 |
| Unit1 | -0.24828922051142524 | -0.16144496012040796 | 0.1594840682240576 | 0.14956123873607088 | 0.20787857558182168 | -0.005288240334417631 | 0.2736563146157151 | 0.98 | 0.07533514484272769 | 0.059059012685978296 | 0.09321266639367394 |
仅展示前 8 行,完整表格已保留在本地分享包中。
result table
| 数据状态 | 第一主成分方差贡献率 | 第二主成分方差贡献率 | 双主成分方差贡献率 | 补全前后方差贡献率变化 | 前k高载荷变量重合率 | 载荷余弦相似度 | 高相关变量数量 | 关键预警指标数量 |
|---|---|---|---|---|---|---|---|---|
| 补全前残缺原始数据 | 0.22572605040732158 | 0.1523747184431505 | 0.37810076885047206 | |||||
| 补全后完整数据 | 0.4187123545466455 | 0.18914794163988988 | 0.6078602961865354 | |||||
| 0.2297595273360633 | 0.5 | -0.5561470663910407 | 6.0 | 5.0 |
问题四
问题四图表结果:多算法多缺失率补全精度对比
关键图表与结果
表8-1 五档缺失样本规模统计表
| 缺失比例 | 重复次数 | 遮蔽位置数 |
|---|---|---|
| 0.1 | 20 | 7040 |
| 0.2 | 20 | 14080 |
| 0.3 | 20 | 21120 |
| 0.4 | 20 | 28160 |
| 0.5 | 20 | 35200 |
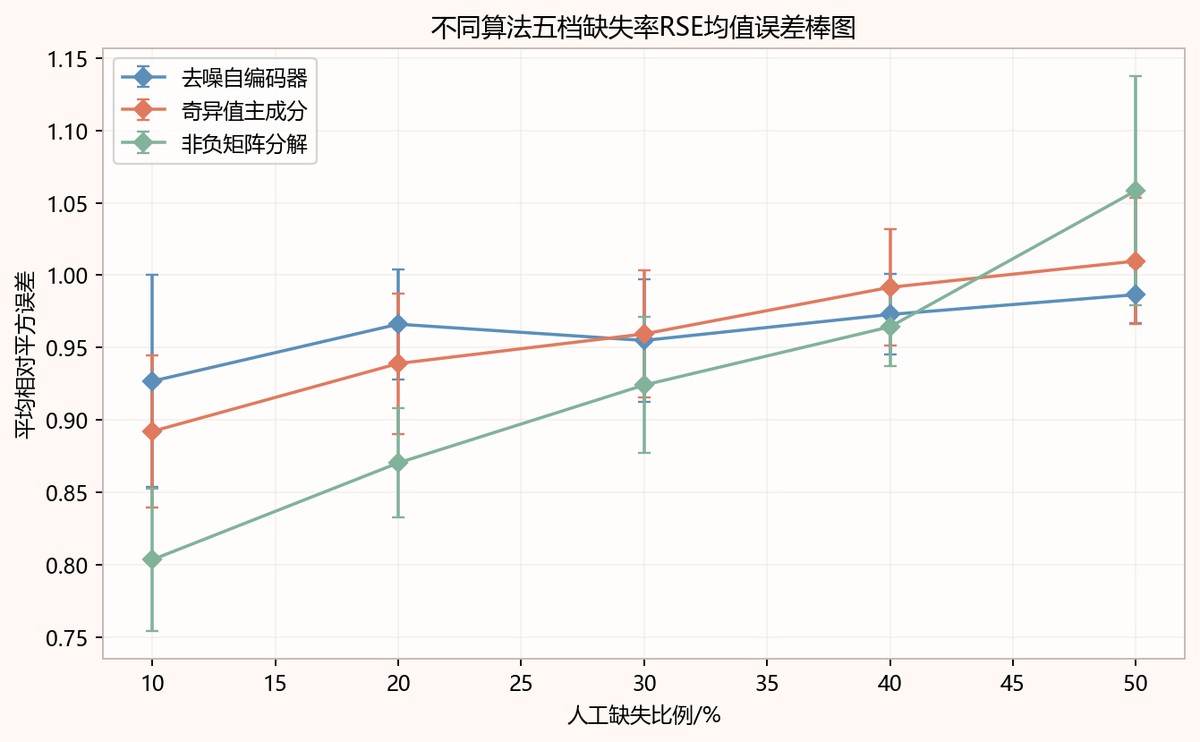
图8-1 不同算法五档缺失率RSE均值误差棒图
表8-2 五档随机掩码样本清单表
| 缺失比例 | 重复编号 | 缺失样本 | 掩码样本 | 遮蔽位置数 | 样本文件是否保存 |
|---|---|---|---|---|---|
| 0.1 | 1 | 缺失样本_10_重复1.csv | 掩码样本_10_重复1.csv | 352 | 是 |
| 0.1 | 2 | 缺失样本_10_重复2.csv | 掩码样本_10_重复2.csv | 352 | 是 |
| 0.1 | 3 | 缺失样本_10_重复3.csv | 掩码样本_10_重复3.csv | 352 | 是 |
| 0.1 | 4 | 352 | 否 | ||
| 0.1 | 5 | 352 | 否 | ||
| 0.1 | 6 | 352 | 否 | ||
| 0.1 | 7 | 352 | 否 | ||
| 0.1 | 8 | 352 | 否 |
仅展示前 8 行,完整表格已保留在本地分享包中。
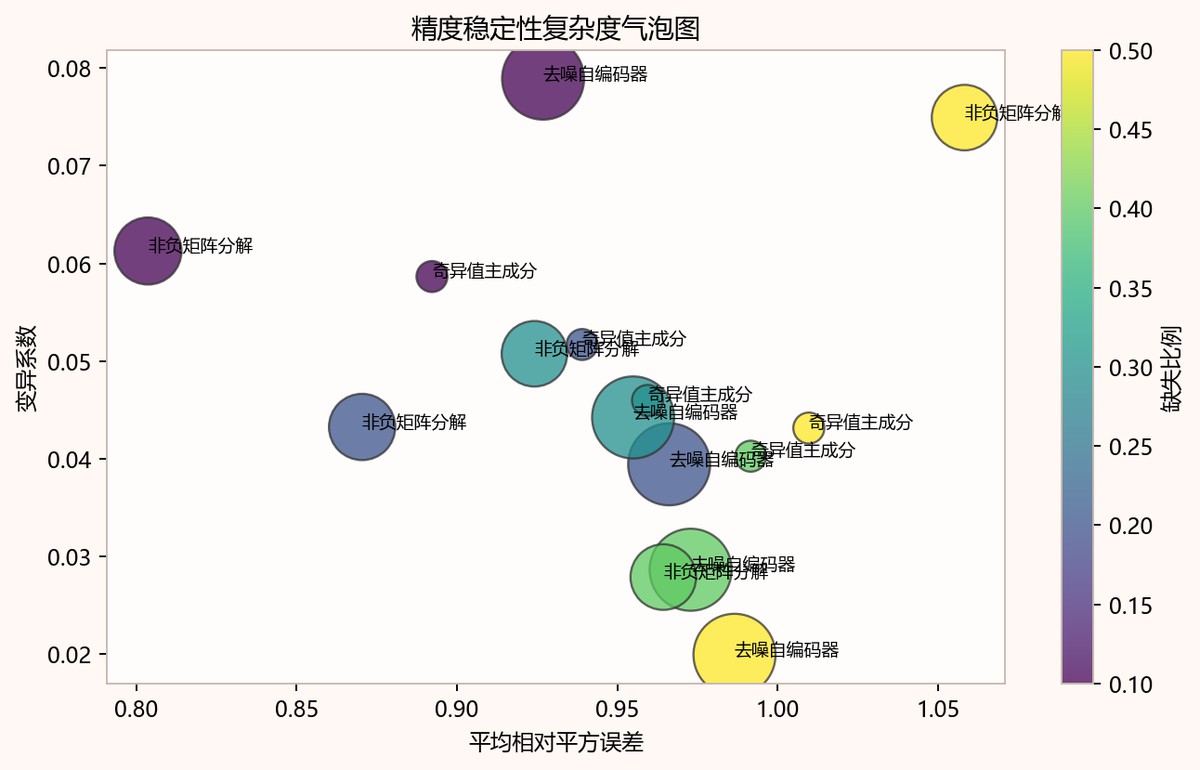
图8-2 精度稳定性复杂度气泡图
表8-3 去噪自编码器补全结果10表
| Age | Gender | HR | Resp | MAP | O2Sat | SBP | Unit1 | DBP | Temp | Glucose |
|---|---|---|---|---|---|---|---|---|---|---|
| 83.14 | 0.0 | 124.17343915274907 | 26.846814988799558 | 113.03753392675733 | 135.37282863755695 | 170.41797601690726 | 0.8598917102889096 | 87.14755059297723 | 51.92180492121468 | 190.5470330946885 |
| 83.14 | 0.0 | 108.0 | 18.02195022276741 | 77.0 | 92.0 | 123.0 | 0.6203972844238236 | 62.87550644455755 | 36.11 | 223.12632173159125 |
| 83.14 | 0.0 | 124.1734391527505 | 26.84681498879989 | 113.03753392675895 | 135.37282863755823 | 132.98033638279358 | 0.859891710288922 | 87.14755059297848 | 51.92180492121516 | 190.54703309468567 |
| 83.14 | 0.0 | 104.0 | 28.0 | 81.33 | 99.47314137719968 | 123.80824578110787 | 0.6454647999922921 | 65.41602426662462 | 42.36579243496269 | 215.80481244864907 |
| 83.14 | 0.0 | 102.0 | 32.0 | 79.5526826605805 | 89.0 | 132.0 | 0.7220842638495399 | 73.18117917719401 | 36.67 | 110.06802239622677 |
| 83.14 | 0.0 | 106.0 | 17.900751102120115 | 75.67 | 91.0 | 137.0 | 0.6411294999575444 | 64.97665456791869 | 42.174744267761646 | 216.36174030144528 |
| 83.14 | 0.0 | 102.0 | 24.0 | 75.67 | 107.66509118906058 | 103.0 | 0.5754346265682664 | 58.318674954599445 | 41.290530510178435 | 267.94933142505204 |
| 45.82 | 0.0 | 90.0 | 23.0 | 69.33 | 95.0 | 128.0 | 1.0 | 61.40533288486016 | 35.32678489812968 | 94.20377236764186 |
仅展示前 8 行,完整表格已保留在本地分享包中。
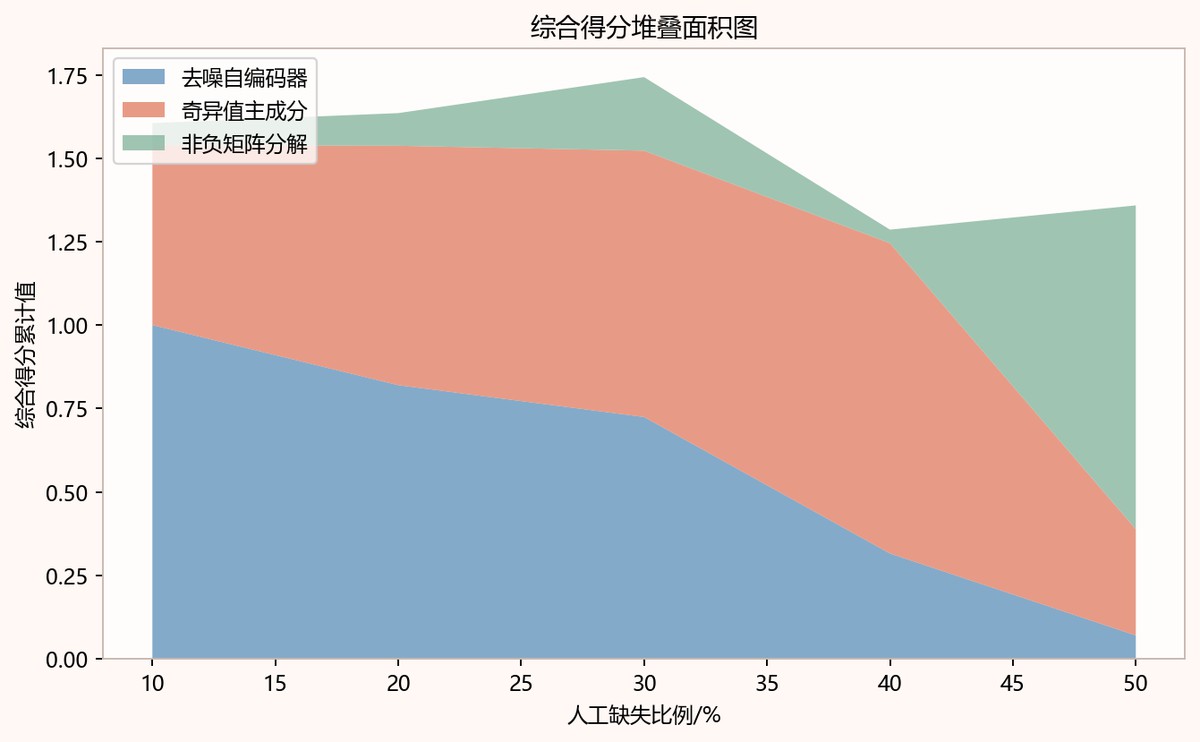
图8-3 综合得分堆叠面积图
表8-4 去噪自编码器补全结果20表
| Age | Gender | HR | Resp | MAP | O2Sat | SBP | Unit1 | DBP | Temp | Glucose |
|---|---|---|---|---|---|---|---|---|---|---|
| 83.14 | 0.0 | 124.17343915274907 | 26.846814988799558 | 113.03753392675733 | 135.37282863755695 | 170.41797601690726 | 0.8598917102889096 | 87.14755059297723 | 51.92180492121468 | 190.5470330946885 |
| 83.14 | 0.0 | 108.0 | 29.0 | 77.0 | 92.0 | 123.0 | 0.6172510467659978 | 62.87550644455755 | 36.11 | 223.12632173159125 |
| 65.165463077711 | 0.0 | 124.1734391527505 | 22.50842062697029 | 113.03753392675895 | 99.1887110679536 | 170.4179760169097 | 0.7132279665119992 | 87.14755059297848 | 51.92180492121516 | 190.54703309468567 |
| 83.14 | 0.0 | 104.0 | 28.0 | 81.33 | 92.0 | 132.0 | 0.6378477329036963 | 65.41602426662462 | 42.36579243496269 | 215.80481244864907 |
| 61.427303509860614 | 0.0 | 102.0 | 20.558654747586992 | 94.0 | 89.0 | 120.32155960610905 | 0.7220842638495399 | 73.18117917719401 | 36.67 | 110.06802239622677 |
| 83.14 | 0.49803480029786806 | 106.0 | 25.0 | 78.95027872781556 | 91.0 | 137.0 | 0.6078879575235495 | 64.97665456791869 | 42.174744267761646 | 216.36174030144528 |
| 83.14 | 0.0 | 102.0 | 24.0 | 75.67 | 96.98088176768096 | 103.0 | 0.6465481157669204 | 58.318674954599445 | 37.04455908067323 | 267.94933142505204 |
| 45.82 | 0.0 | 90.0 | 23.0 | 81.54738768609153 | 95.0 | 128.0 | 1.0 | 62.63801108082375 | 37.63918450593519 | 94.20377236764186 |
仅展示前 8 行,完整表格已保留在本地分享包中。
result table
| 算法 | 缺失比例 | 平均相对平方误差 | 误差标准差 | 平均补全精度 | 平均运行时间 | 变异系数 | 归一化误差 | 归一化波动 | 归一化运行时间 | 综合得分 |
|---|---|---|---|---|---|---|---|---|---|---|
| 非负矩阵分解 | 0.1 | 0.8036391243706771 | 0.04923952861688342 | 0.1963608756293229 | 0.009906155004864558 | 0.06127069616649289 | 0.0 | 0.12903085832607705 | 0.6143985427331883 | 0.06623345249001705 |
| 奇异值主成分 | 0.1 | 0.8922158926675354 | 0.05233295713781058 | 0.10778410733246453 | 0.00274461499939207 | 0.05865503805506931 | 0.718726300173344 | 0.0 | 0.0 | 0.539044725130008 |
| 去噪自编码器 | 0.1 | 0.9268804309368834 | 0.07315552873585823 | 0.07311956906311665 | 0.014400794998800847 | 0.07892660832404702 | 1.0 | 1.0 | 1.0 | 1.0 |
| 非负矩阵分解 | 0.2 | 0.8704338903366713 | 0.03763995957997511 | 0.12956610966332877 | 0.009796350001124665 | 0.04324275513373368 | 0.0 | 0.3118052244133414 | 0.5953616684654496 | 0.09780025718698293 |
| 奇异值主成分 | 0.2 | 0.9390532302621153 | 0.04853912713430774 | 0.06094676973788462 | 0.0024846300002536736 | 0.05168943098221116 | 0.716535174183652 | 1.0 | 0.0 | 0.7174013806377391 |
| 去噪自编码器 | 0.2 | 0.9661993773605595 | 0.03808348333006228 | 0.033800622639440524 | 0.014765769999939948 | 0.03941576057941418 | 1.0 | 0.0 | 1.0 | 0.8200000000000001 |
| 非负矩阵分解 | 0.3 | 0.9241689381657301 | 0.04689397926660418 | 0.07583106183427002 | 0.008559199997398537 | 0.05074178251394985 | 0.0 | 1.0 | 0.5779181948255026 | 0.2204542736377852 |
| 去噪自编码器 | 0.3 | 0.954955488327513 | 0.04222735586887699 | 0.04504451167248705 | 0.013122835000103805 | 0.04421918757992458 | 0.8727346788970811 | 0.0 | 1.0 | 0.7245510091728109 |
仅展示前 8 行,完整表格已保留在本地分享包中。
通用版论文完整预览大图

完整获取如下👇👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)