组会一:具身智能研究
具身智能方向:
具身智能的目标:具身智能(Embodied AI)旨在开发具有物理形态的智能系统,使其能够在真实世界环境中感知、决策、行动和学习,被认为是一种实现人工通用智能(AGI)的有前途的方法。
挑战:要使智能体在开放、无结构和动态的环境中达到人类水平的智能,以执行通用任务仍然是一个挑战。
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支。它不像监督学习那样需要“标签”,也不像无监督学习那样寻找“隐藏结构”,而是通过智能体(Agent)与环境(Environment)的交互,学习如何从状态(State)映射到动作(Action),以最大化累积的奖励(Reward)。
分层自主决策VS端到端的自主决策
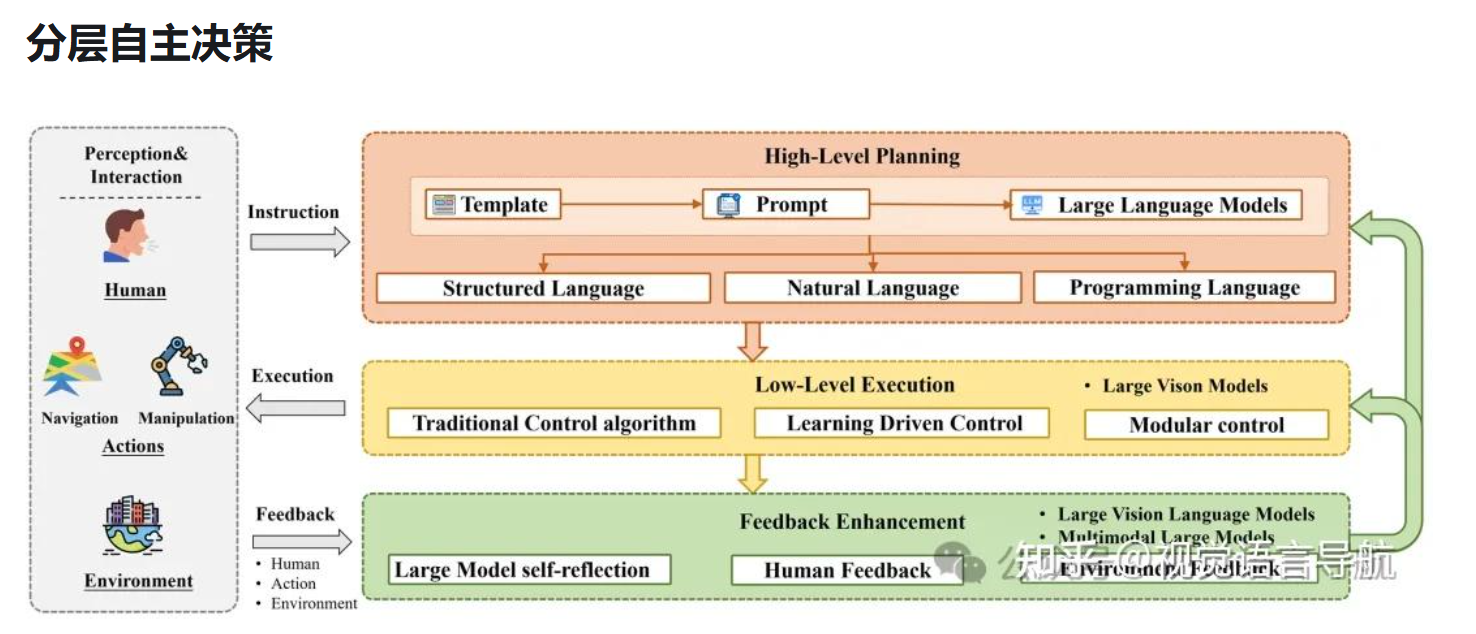
高层规划,低层执行,反馈增强
高层规划的目标是根据任务指令和感知到的环境信息生成合理的计划。主要方式有结构化语言规划和自然语言规划
-
自然语言规划:就像你和朋友用日常对话来商量。“我们先飞到昆明,然后租车,第一天去滇池,第二天走高速去大理,路上大概要4个小时……”
-
结构化语言规划:就像你用一个项目管理软件或编程代码来规划。你会定义任务、子任务、依赖关系和状态变量。
低层执行:低层执行的实现涉及控制理论、机器学习和机器人工程学,其发展经历了从传统控制算法到基于学习的控制,再到模块化控制的过程:
反馈层:大模型可以作为任务规划器、评估器和优化器,从而在没有外部干预的情况下迭代优化决策过程。智能体获取动作反馈,自主检测和分析失败的执行情况,并从以往的任务中持续学习。
反馈可能来自大模型自身、人类或外部环境
端到端自主决策
端到端自主决策的核心是将多模态输入(例如视觉观察和语言指令)直接映射到动作输出,而不是像分层决策那样将感知、规划和执行分解为不同的模块。这种决策方式主要通过视觉 - 语言 - 行动(VLA)模型实现。
视觉-语言-动作模型:
看、说、动的智能体:这是大型视觉模型与机器人学的结合,目的是为机器人打造一个通用的"大脑"。除了"看懂"环境,它最关键的能力是输出动作。
核心能力:让机器人可以根据自然语言指令,在真实世界中自主规划并执行复杂的物理任务。
大模型的增强方式:①上下文学习:通过精心设计的提示使大模型能够实现零样本泛化,无需额外训练和调整即可处理新任务。②X of Thoughts:包括链式思考(Chain of Thoughts, CoT)和树形思考(Tree of Thoughts, ToT)等推理框架③检索增强生成:从外部知识库中检索相关信息,并将其输入到大模型中以产生准确的响应。④强化学习从人类反馈
VLA主要组成部分:标记化与表示,多模态信息融合,动作解标记化
标记化与表示:VLA 模型使用视觉、语言、状态和动作四种标记类型来编码多模态输入,为基于上下文的动作生成奠定基础。视觉标记和语言标记将环境场景和指令编码为嵌入向量,形成任务和上下文的基础。
多模态信息融合:通过交叉模态注意力机制(通常在 Transformer 架构内实现),将视觉标记、语言标记和状态标记融合为统一的嵌入向量,用于决策。
动作解标记化:将融合后的嵌入向量传递给自回归解码器(通常在 Transformer 架构内实现),以生成一系列对应于低层次控制信号或高层次运动原语的动作标记。
分层与端到端决策的比较
| 维度 | 分层决策 | 端到端决策 |
|---|---|---|
| 核心理念 | 分模块处理(感知→规划→控制) | 单一模型,输入直接到输出 |
| 可解释性 | 高(可定位哪个模块出错) | 低(黑箱,难以追溯原因) |
| 数据需求 | 较少(可结合规则与少量数据) | 极大(需海量全覆盖数据) |
| 安全性 | 高(易验证,可控) | 低(难验证,长尾问题) |
| 应用成熟度 | 工业标准(所有量产自动驾驶) | 研究前沿(极少安全级部署) |
具身学习方式:
模仿学习(让智能体通过观察专家的示范来学习策略的方法,而不是通过传统的试错(强化学习)来自己摸索),强化学习(与环境的试错交互来学习策略),迁移学习(它允许智能体通过在相关目标任务上使用从源任务中学到的知识来加速学习),元学习(一种学习如何学习的范式,其核心是通过在大量任务上训练,获得快速适应新任务的能力)
世界模型和扩散模型:
世界模型(World Model)是近年来人工智能领域,尤其是在强化学习和自动驾驶中,一个非常核心的前沿概念。简单来说,它试图让AI在自己的“脑海”中建立一个对现实世界运行规律的模拟器。
-
扩散模型是生成器:擅长“画”出逼真的画面、视频。它的核心竞争力是视觉质量和多样性。
-
世界模型是物理引擎:擅长“计算”出世界的未来状态。它的核心竞争力是预测准确性和因果逻辑。
-
当前趋势:两者正在走向融合,用扩散模型强大的生成能力来构建更强大的世界模型,这被视为通向通用世界模型(GWM)的关键一步。
任务的最终目标:
模仿学习框架下:多步决策控制的迁移(policy net 的imitation learning) + 语义推理 (text2motion 或其他vla技术) + DMP (动态运动基元,用于运动轨迹的迁移)
1. 多步决策控制的迁移:
Policy Net (策略网络):一个神经网络,它的功能是 “看到当前状态 → 直接输出要做的动作”。这是模仿学习中实现控制的核心组件。
迁移:泛化能力的提高
策略网络 π 的目标是计算一个条件概率分布,或者直接输出一个确定性的动作:
-
随机性策略 (Stochastic Policy):
动作 = π(状态 | θ)。网络输出的是动作的概率分布(如高斯分布的均值和方差),常用于需要探索的环境。 -
确定性策略 (Deterministic Policy):
动作 = μ(状态 | θ)。网络直接输出一个具体的动作值,常用于模仿学习(直接模仿专家的做法)。
2. 语义推理
让机器人能理解自然语言或物体之间的逻辑关系。不仅仅是看到“一个圆形的红色物体”,而是知道“这是一个苹果,是可以吃的”。
关键技术有
-
Text2Motion:一类技术,输入是自然语言指令(如“请把那个红杯子递给我”),输出是具体的运动轨迹或动作序列。
-
VLA (视觉-语言-动作模型):当前最前沿的模型架构,它融合了视觉(看懂图像)、语言(理解指令)和动作(输出控制信号)三大能力。
3. DMP
一种经典的机器人运动控制方法。它的特点是能把一个示教的轨迹(比如人拉着机械臂画一个圆)编码成一组数学公式。这组公式天然具有稳定性和可调节性。只要对相关参数进行修改,就可以很轻松的完成模型的泛化指令。
实战演习
在github上下载了一个关于DMP的模块(movement_primitives),并搭建一个虚拟环境运行了里面的相关例子
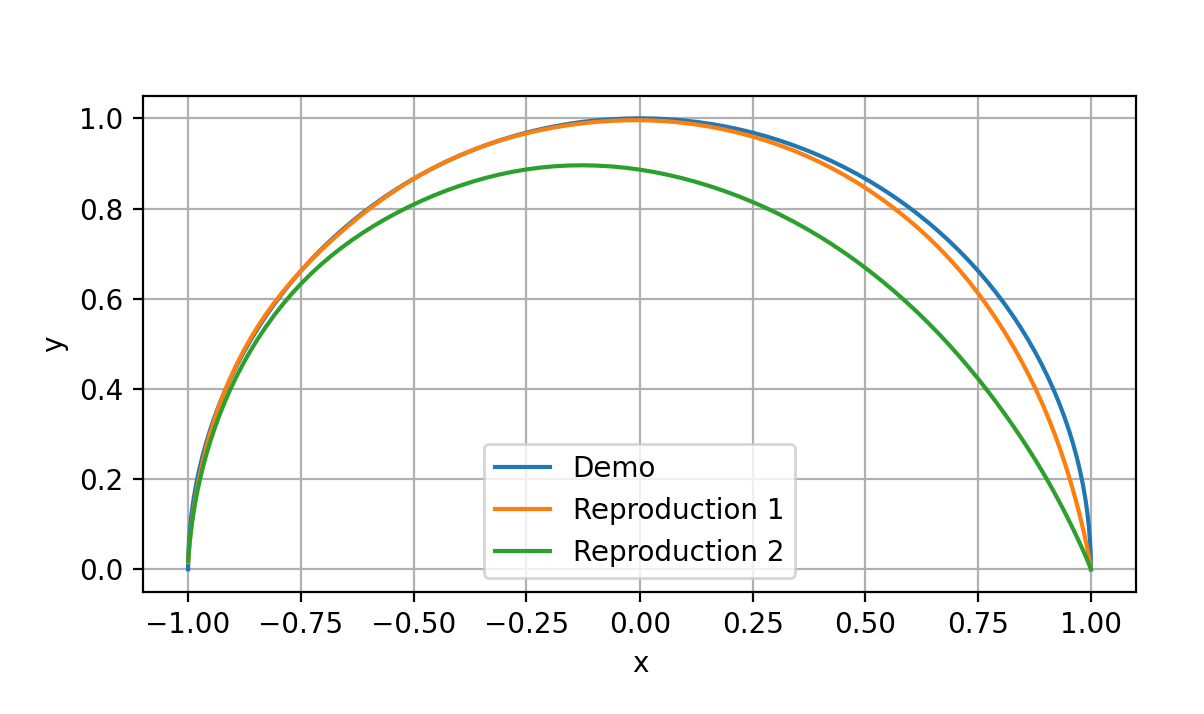
1.在2d_gain.py文件下,改变刚度和阻尼参数,得到不同的曲线
dmp1 = DMP(
n_dims=2,
execution_time=1.0,
dt=dt,
n_weights_per_dim=10,
int_dt=0.0001,
alpha_y=np.array([25.0, 25.0]),
beta_y=np.array([6.25, 6.25]),
)
dmp2 = DMP(
n_dims=2,
execution_time=1.0,
dt=dt,
n_weights_per_dim=10,
int_dt=0.0001,
alpha_y=np.array([25.0, 10.0]), # note different alpha_y
beta_y=np.array([6.25, 3.0]), # note different beta_y
)
2. potential_filed.py文件下定义了一个势场,绿黄红线分别代表三种不同的运动轨迹,T表示时间
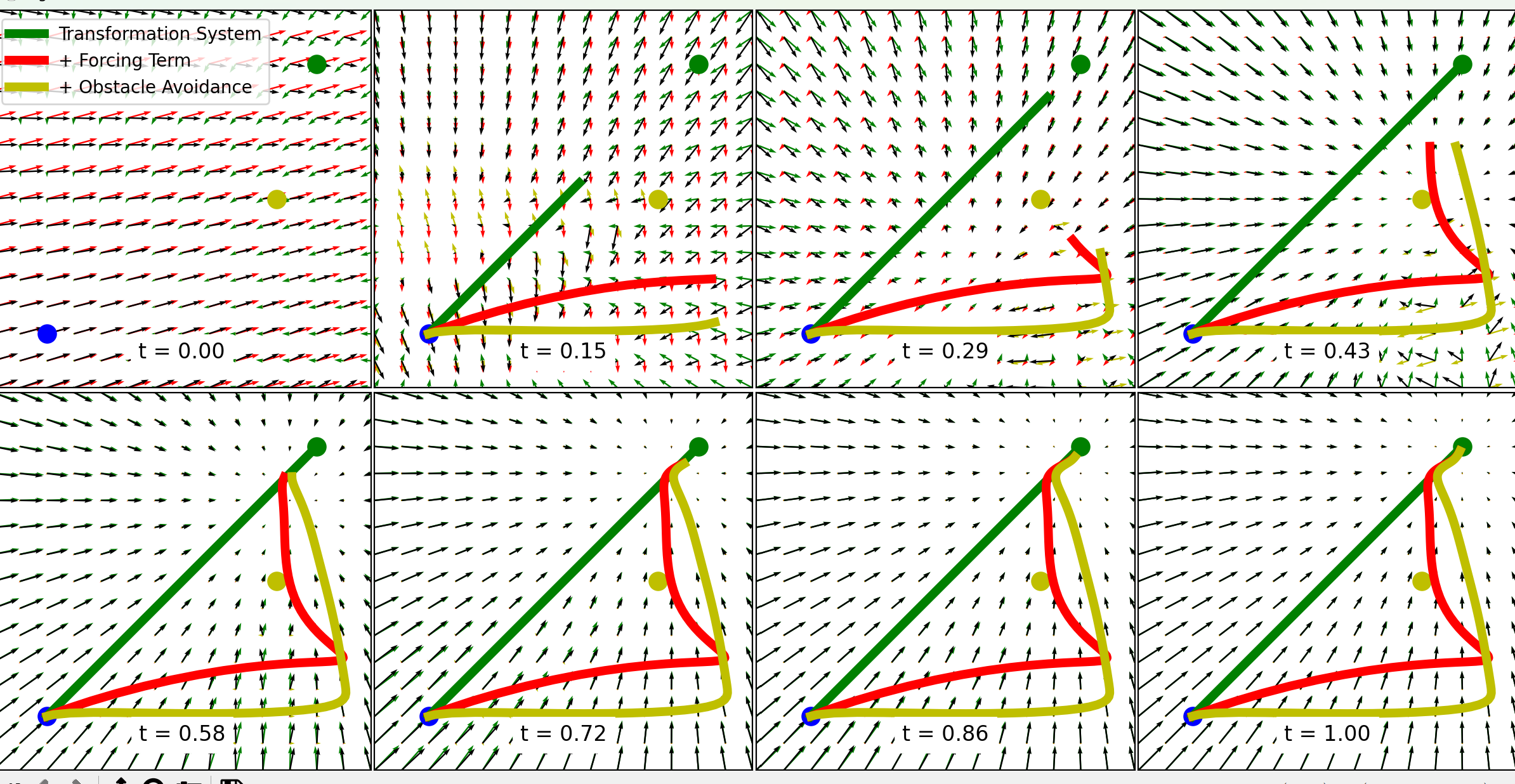
各个线表示的轨迹如下表
| 轨迹 | 核心组件 | 模拟场景 | 一句话总结 |
|---|---|---|---|
| 绿线 | 只有变换系统 | 简单的位置移动(A点 → B点) | "走直线,不管形状" |
| 红线 | 变换 + 强迫项 | 模仿学习复杂轨迹 | "学会老师傅的走法" |
| 黄线 | 变换 + 强迫项 + 耦合项 | 动态避障 | "学会走法,还会躲坑 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)