CVPR 2026丨RoboAgent以五项基础能力突破具身规划瓶颈
这两年,我们对机器人最大的设想之一就是希望他们可以尽快进入家庭,帮我们收拾家务。「把厨房灶台帮我清理一下,之后收拾客厅,最后帮我倒垃圾」。
对人来说,这更像是一件顺手完成的小事。我们会首先确认厨房在哪里,灶台有哪些地方需要清理,是脏污还是物品整理,我们应该先做什么后做什么,是先洗碗筷还是先收拾杂物,还要判断哪些物品是脏的,水槽是否可用;之后再定位客厅在哪里,进一步判断有哪些地方需要收拾等等等等。
但对机器人而言,这不是一条简单的指令,而是一条不断变化的任务链条。

它看到的只是当前视角下的一张图,能够行动的也只是一步步原子动作。每走一步,视野都会改变;每执行一次操作,环境状态也会改变。目标物体可能暂时不可见,动作可能失败,前一步的判断还可能影响后续所有规划。
这正是具身任务规划,Embodied Task Planning,真正困难的地方。
过去两年,视觉语言模型 VLM 已经展现出很强的多模态理解能力。它们能看懂图片、能理解语言、能做常识推理,也能生成较完整的行动描述。
但一旦被扔进真实的家庭环境,需要多轮交互、长程推理、扩展上下文分析时,它们就像个新兵蛋子一样——“理论全能,实操抓瞎”。
如何解决这一难题?
近日,北京大学副教授穆亚东及星源智团队共同提出了 RoboAgent 方案,工作也正式入选了CVPR 2026。
RoboAgent采用能力驱动的具身路径规划,将复杂的规划任务分解为一系列更简单的视觉语言问题;同时,设计了一个多阶段训练路径,利用中继监督(intermediate supervision)与多样化数据来源,系统性地优化VLM的规划能力。
论文标题:RoboAgent: Chaining Basic Capabilities for Embodied Task Planning
论文链接:https://arxiv.org/abs/2604.07774
开源链接:https://github.com/woyut/RoboAgent_CVPR26
一句话总结就是:
RoboAgent 把一个过去容易被「大模型推理能力」笼统概括的问题,重新拆回了机器人系统真正需要面对的过程:探索、定位、状态理解、动作解码和失败恢复。
为什么VLM 自己搞不定?”
现在的 VLM 很强,但具身规划对模型提出的要求并不是「看图回答问题」。
在具身路径规划任务中,机器人接收的是一个任务指令和连续的第一视角观察。它每一步都要输出原子动作,动作会改变环境状态,下一步观察又会反过来影响规划。
这里面的难点至少有三层。探索、状态理解和失败恢复。
传统方法通常有两种处理方式。
一种是让 VLM 直接输出动作序列。这样做路径短,但模型要在一个输出里同时完成指令理解、目标推断、环境分析、动作生成和进度监控。中间某个环节出错,系统是没有办法知道错误出自哪里。
另一种是给模型加 CoT 推理,让它先思考再行动。这个方向能改善一定推理表现,但自由生成的思考过程缺乏原则化接口,也很难获得逐步监督。像在ALFWorld这类需要探索+操作的仿真环境里,问题会层层叠加,导致模型崩掉。
更棘手的是,奖励信号极其稀疏。可能走了20步才判断成败。用纯强化学习(RL)训练,模型往往在无效探索中耗光步数。而单纯模仿专家轨迹,又无法泛化到没见过的新场景。
目前的VLM,其实没办法搞定具身路径规划。
RoboAgent 的核心拆解
RoboAgent瞄准的就是上面这个难题。它把规划拆成一系列更小的、VLM本来就擅长的视觉-语言子问题。 整体框架可以理解为一个 scheduler 加五类能力。
Scheduler 负责查看任务进度,决定当前该调用什么能力。五类能力分别对应具身任务中的关键环节:
-
EG(探索引导):给定目标物体,根据常识推断最可能的位置,预测最有可能的探索方向以找到该物体。
-
OG(物体定位):做开放词汇检测(即模型能够根据自然语言描述,在图像或场景中定位出训练阶段从未见过的物体或概念),判断当前视野里有没有目标物体。
-
SD(场景描述):用文字描述目标物体的当前状态。
-
AD(动作解码):把导航或操作指令转成具体原子动作(atomic actions)。
-
ES(经验总结):总结由 AD 生成的动作序列的交互结果,并在发生错误时分析失败原因。
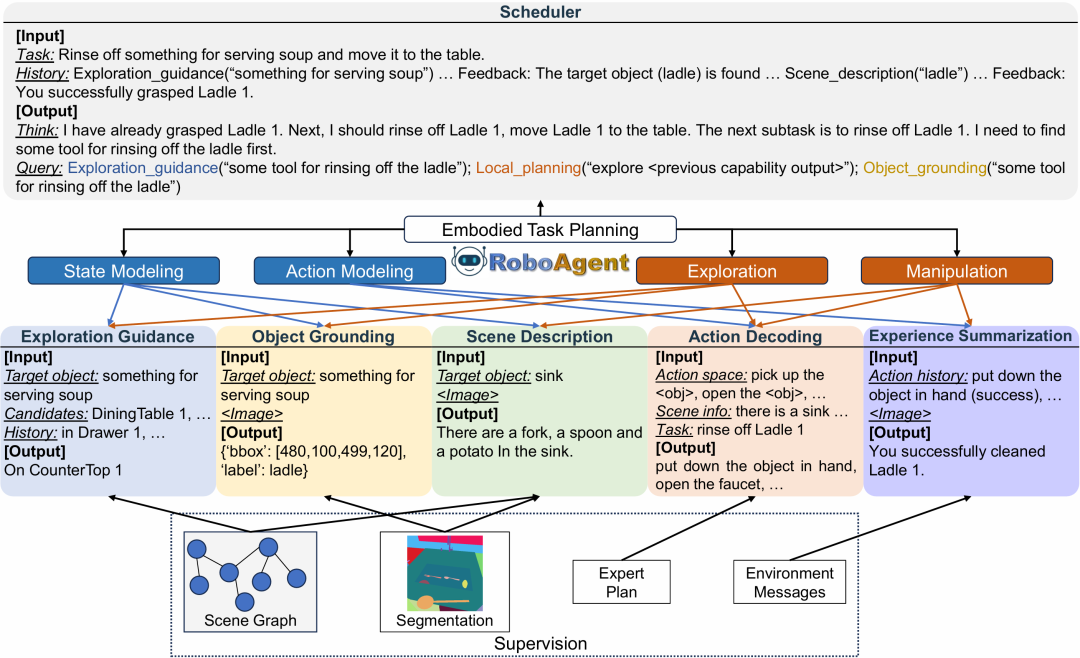
Scheduler 调度五类基础能力,形成可监督的能力链
总结来说,这五类能力对应了机器人长程任务里的两个核心过程:探索和操作。
在探索阶段,EG 先判断去哪里找目标,AD 把探索方向转成导航动作,OG 再判断目标是否进入视野。如果没有找到,scheduler 会继续调用 EG,换一个位置继续找。
在操作阶段,SD 先描述目标状态,AD 生成动作序列,ES 根据执行反馈总结是否成功。如果失败,scheduler 再基于失败原因重新规划。
一个值得注意的地方是,RoboAgent 没有把这些能力做成多个外部工具,也没有依赖封闭模型或独立模块拼接。Scheduler 和所有能力都由同一个 VLM 实现。模型只是通过不同 prompt、不同上下文和不同输入输出格式,在统一框架内扮演不同能力角色。
这就让 RoboAgent 的中间过程变得可解释,也变得可训练。
之前相关算法的问题在于,模型输出一整段动作,成功了就是成功,失败了也只能粗粒度归因。RoboAgent 把中间过程拆开之后,系统可以知道问题到底出在探索、定位、状态描述、动作解码,还是经验总结。
机器人失败一次之后,我们更关心的其实是为什么失败,以及下一次应该纠正哪一个环节。
这种显式的中间步骤上的高质量监督,对机器人训练是有利的,也是更容易学习的。RoboAgent找到了一个比较Solid的做法。
三阶段训练:从模仿到自我纠错,再到专家引导
光有架构不够,怎么训练这个VLM让它学会“调用能力”?RoboAgent 设计了一套三阶段路径规划(planning pipeline),充分利用模拟器的内部特权信息(物体位置、实例分割、动作成败反馈)。
这些信息在实际推理时不可用,但训练时能提供高质量监督。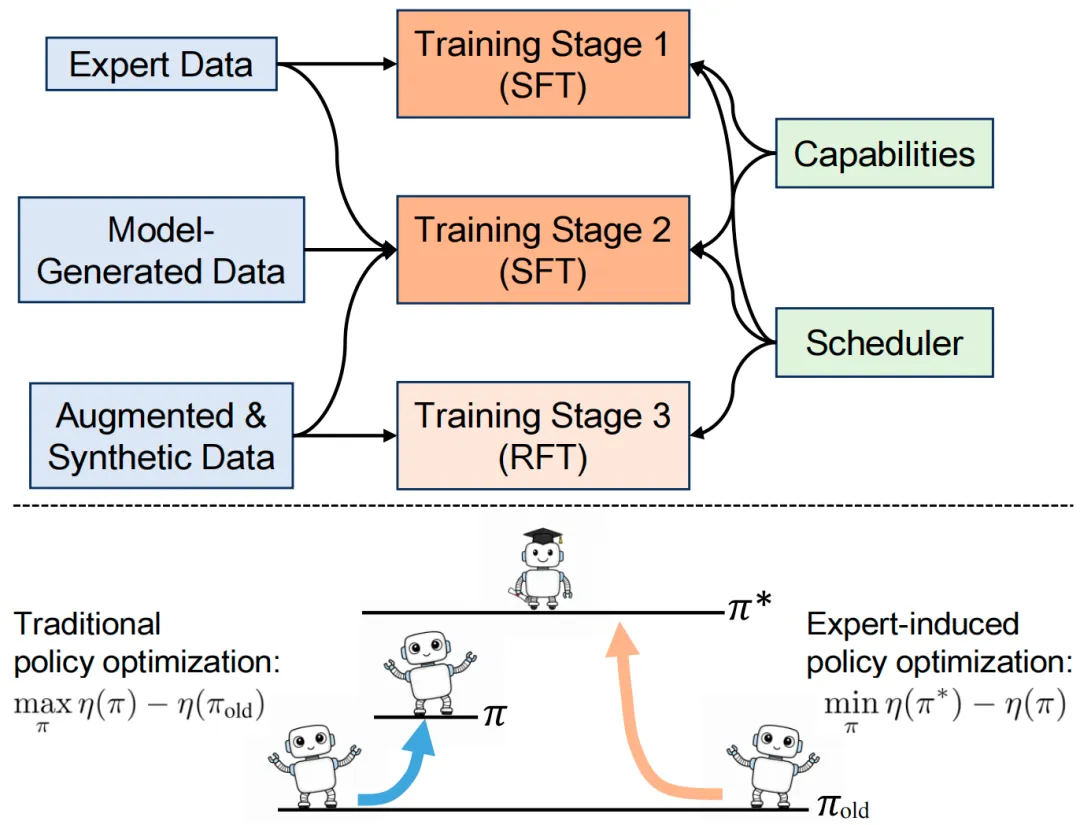
RoboAgent三阶段路径规划pipeline
我们一个个来看。
第一阶段:专家轨迹监督
把ALFRED数据集里的专家轨迹拆成探索子目标和操作子目标,转换成能力调用序列,并自动生成思维链。用这些数据做有监督微调,共生成640k个训练样本。
RoboAgent 使用 ALFRED 训练集中的专家轨迹,把原本连续的专家计划拆成探索子目标和操作子目标,再转成能力调用序列。比如一个「清洗勺子并放到桌上」的任务,可以被拆成找勺子、抓勺子、找清洗工具、清洗勺子、找桌子、放到桌子上。
用这些数据做有监督微调,共生成640k个训练样本。
这一步是有监督微调,但它不只监督最终动作,还监督每个能力的输出。
仿真器中的特权信息被充分利用起来。
场景图可以告诉模型目标物体真正在哪,用来监督 EG。实例分割 mask 可以转成目标物体的 bounding box,用来监督 OG。局部可见的场景图可以转成文字描述,用来监督 SD。环境反馈可以告诉动作是否成功及失败原因,用来监督 ES。专家动作序列则直接监督 AD。
这些信息在推理时机器人看不到,但训练时可以作为高质量标注。
这其实也是仿真的价值之一。仿真不只是用来跑更多 episode,更重要的是它能提供现实世界里很难便宜获得的中间状态、真实标签和失败原因。
第二阶段:模型生成数据训练
只看专家轨迹会带来一个问题:模型在推理时会进入专家轨迹之外的状态。一旦偏离,单纯的模仿学习就很难恢复。
RoboAgent 让第一阶段模型在训练任务上自己跑,收集成功和失败轨迹,再用仿真器内部的信息为每一次能力调用构建纠正性监督。
比如模型判断「去柜子找叉子」,但仿真器显示叉子在抽屉里,系统就可以对 EG 的输出进行纠正。模型识别错了目标物体,也可以用分割 mask 和真实类别去修正 OG。动作生成不符合状态,也可以用场景图和专家子计划重新生成监督。
这一步接近 DAgger 思路,核心是让模型从自己犯过的错误中获得纠错信号。
从失败中学习的重要性已经被全行业所意识到。真实机器人未来一定会面对偏离专家轨迹的情况,能不能从失败状态重新回到正确轨道,往往比在干净环境中模仿专家动作更接近实际部署需求。
第三阶段:专家策略引导的强化微调
RoboAgent 提出了 EIPO,Expert-Induced Policy Optimization。它主要训练 scheduler,让模型更好地决定当前应该调用哪些能力。
传统强化学习在长程具身任务里经常遇到稀疏奖励问题。机器人走了很多步,最后才知道任务成败,模型很难判断到底是哪一步决策贡献了成功,哪一步造成了失败。
EIPO 的思路是用专家调度策略计算每个状态和动作对的专家优势。也就是说,系统不再只用最终任务成功与否来回传信号,而是用专家策略判断当前调用是否推动了任务进展。
这会让训练信号更稳定。尤其在长程任务里,scheduler 的职责不是直接执行动作,而是判断下一步该探索、该定位、该操作,还是该根据失败反馈重新规划。EIPO 给这个调度过程提供了更细粒度的优化目标。
为了让 scheduler 看到更多复杂状态,RoboAgent还构造了带错误恢复的合成轨迹。比如 OG 偶尔返回目标未找到,ES 偶尔返回操作失败,scheduler 必须学会重新探索或回滚到前一个子任务。
实验结果:3B模型性能超过7B和GPT-4o
RoboAgent 的实验结果还是比较亮眼的。
基座模型是 Qwen2.5-VL-3B。训练只使用 ALFRED 训练集,评估覆盖 EB-ALFRED、ALFWorld 视觉环境、ALFWorld 文本环境,以及跨模拟器的 EB-Habitat 和 LoTa-WAH。
在 EB-ALFRED 上,RoboAgent 平均成功率达到 67.0%,超过 WAP、REBP、RoboGPT-R1 等微调方法,也超过 GPT-4o 的零样本平均结果。在视觉外观分项上,它达到 78%,明显高于 GPT-4o 的 46%。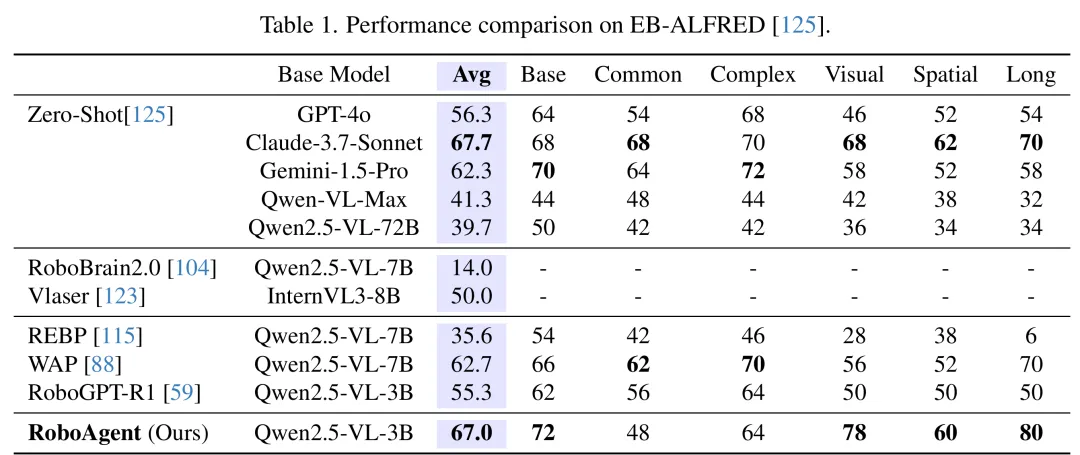
RoboAgent 在EB-ALFRED上的结果
在 ALFWorld 视觉环境中,RoboAgent 平均成功率达到 77.6%,相比 GPT-4o 的 24.0% 和 SEEA-R1 的 36.0% 有显著提升。尤其在 Pick、Clean、Look 等任务类别中,显式探索和物体定位带来的优势很明显。这主要得益于EG/OG带来的显式探索,让模型学会优先检查最可能有物体的容器(如“杯子”大概率在“橱柜”而非“马桶”上),而非盲目乱走。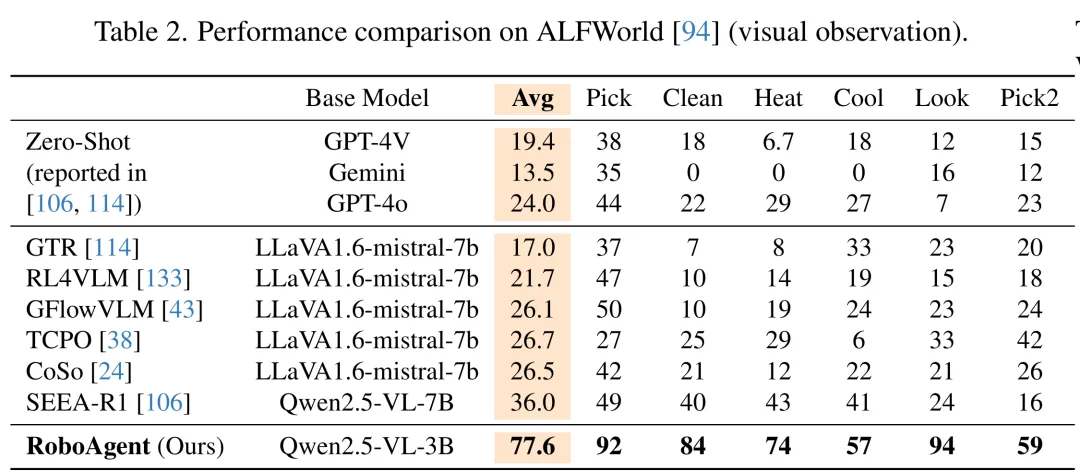
ALFWorld视觉观察结果
在 ALFWorld 文本环境中,RoboAgent 在未见场景上达到 94.0%,超过 DynaMind 等基于更大 LLM 的方法。这说明能力驱动的规划范式并不完全依赖视觉输入,它学到的是一种更通用的任务推进机制。这说明能力驱动的范式具备模态无关的泛化力,图像能力可以无缝迁移到文本输入。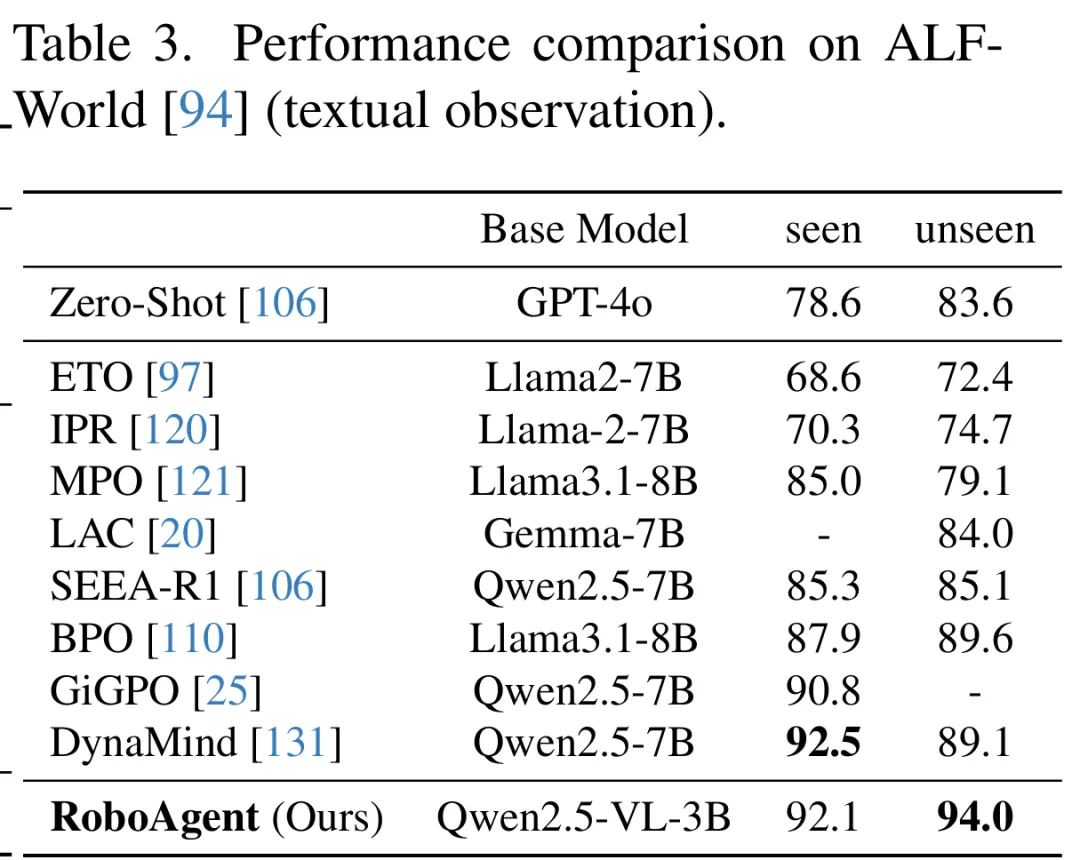
ALFWorld 文本环境结果
甚至跨模拟器的EB-Habitat和LoTa-WAH上,效果都还不错,全是未见过的新场景、新指令。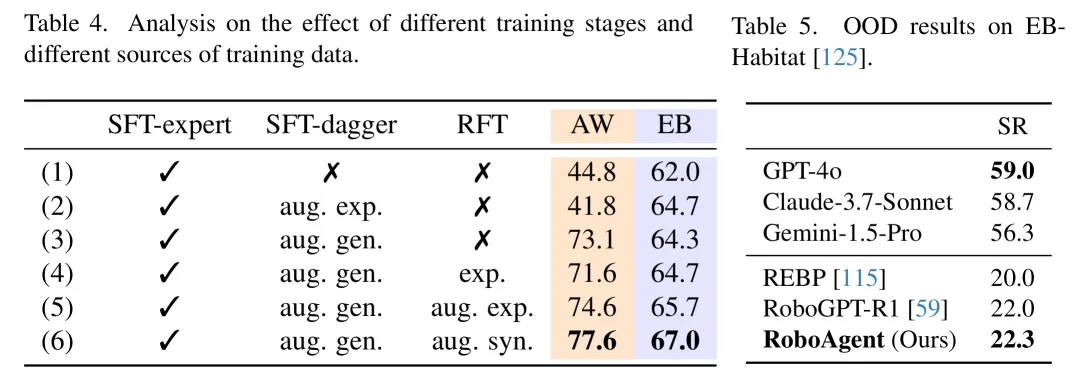
这些结果最值得讨论的地方,我们觉得不是一个 3B 模型在某些 benchmark 上超过了更大的模型。整篇文章学习下来的感受是,长程具身规划的瓶颈并不完全来自参数规模。
大模型当然重要,但如果系统没有把任务拆成可调用能力,没有把中间过程转成监督,没有在失败轨迹中学习纠错,模型能力很容易停留在「理解得不错,执行起来不稳」的状态。
RoboAgent 提供的启发是,在具身智能里,模型能力需要被组织起来。
VLM 的感知、语言、常识、推理能力,需要被嵌入一个持续交互的规划框架中,才能真正转化为机器人任务能力。
边界很清楚,视觉和跨域仍是最大短板
当然,RoboAgent 并不是一个已经解决具身规划所有问题的系统。
从论文结果看,它在跨模拟器泛化上仍然有一定的边界。在 EB-Habitat 这类 OOD 环境中,RoboAgent 虽然优于部分开源微调方法,但与 GPT-4o、Claude-3.7-Sonnet等闭源大模型仍有差距。
错误分析给出了一定的指引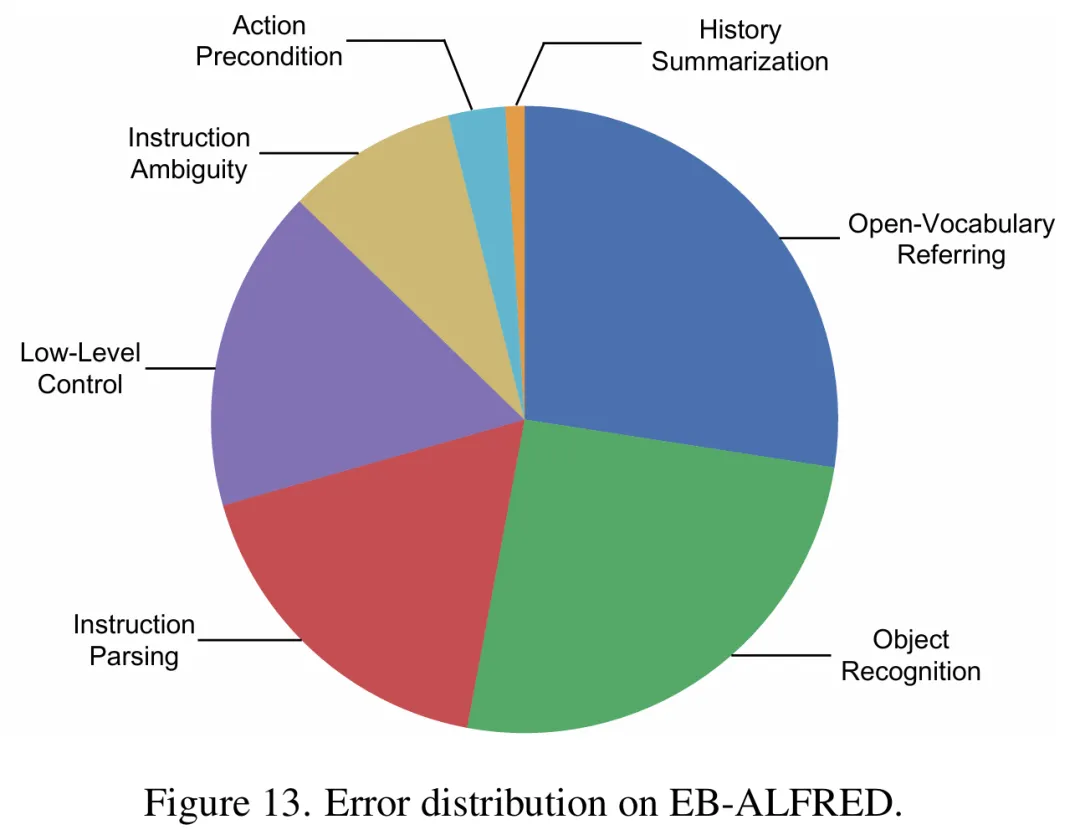

在 EB-ALFRED 中,相当多失败来自视觉 grounding。目标物体太小、被遮挡、开放词汇描述过于模糊,都会导致 OG 识别失败。部分错误来自复杂指令解析,部分来自低层控制或模拟器交互限制。
在 ALFWorld 中,物体识别、探索失败、低层控制、动作前置条件遗漏,仍然是主要问题。
这些边界说明,RoboAgent 解决的是「如何组织 VLM 能力进行长程规划」的问题,还没有彻底解决视觉识别、跨域迁移、真实机器人控制和动作精度问题。
从这个角度去看,RoboAgent 更像是高层规划与能力调度层的探索,也提供了一个很工程化的中间层:把大模型能力拆成接口,把接口变成训练对象,再让训练对象进入长程任务闭环。
写在最后
具身智能这两年的发展,很大程度上来自大模型能力向机器人系统迁移。
从π0、π0.5、π0.7,再到后面的强化学习、世界模型、世界动作模型。大脑能力的发展速度确实很快,但越接近人类真实的日常需求,我们就越会发现,具身智能的突破还有很长的路要走。
机器人能力并不会因为接入一个更强的 VLM 就自然形成。视觉理解、语言推理和动作生成之间,还缺少一套稳定的过程组织方式。
长程任务的难点,往往出现在中间环节。目标没找到、物体识别错、动作执行失败,对真实机器人来说,这些问题会高频出现在任务执行过程中,本身就是机器人走向真实环境必须处理的常态。
也正因此,VLM 本身的能力还有相当大的释放空间。
RoboAgent 给出的启发,正在于此。它通过合适的调用机制,将这些中间环节显式拆开,让探索、定位、状态理解、动作解码和失败恢复进入一个更清晰的能力链条。
这让 VLM 的能力从一次性推理输出,进一步进入持续交互的规划流程中。模型的感知、语言和常识推理能力,只有被有效组织起来,才更有可能转化为机器人可执行、可纠错、可推进的任务能力。
复杂任务从来不是一次推理完成的。
对机器人来说,学会把能力组织起来,本身就是智能走向真实世界的重要一步。
重磅!
全网首个!具身智能开源知识库来啦(技术/产业/投融资/上下游)
推荐阅读
我们用低成本的机械臂完成pi0/pi0.5/GR00T/世界模型等VLA任务~
VLA+RL方向首个系统教程来啦!Online RL/Offline RL/test time RL等~
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
1v1 科研论文辅导来啦!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)