一点想法:验证工程师眼中的AI-ISP
在低光场景下,画面成像一般都很困难,因为光子数少、信噪比(SNR)很低,相机传感器采集到的图像数据中,有效数据量<<图像噪声。为了解决光子数少的问题,可以增加感光度,使用长时间曝光,但是这样不能解决图像噪声问题,且长曝光会引入画面运动模糊的问题,还会存在偏色(有色差)。
在传统的ISP处理侧,使用一些后处理,例如拉伸直方图也可以使得画面变量亮,这样不会引入运动模糊,但是画面噪声仍然存在
在物理层面,开大光圈,使用闪光灯等都具有场景上的缺陷。
单帧去噪:难以解决色彩偏差问题
多帧去噪:极端低光场景下对齐算法会失效,且算法依赖burst内部lucky imaging(挑选其中质量最好的帧)
以上的逻辑思路可以通过一个图表来表示:
| 优化手段 | 增强亮度 | 去噪 | 抗运动鬼影 | 色彩还原 | 其他 |
|---|---|---|---|---|---|
| ISO | √√ | × | √ | × | 物理手段,实时处理,成本一般,但增强亮度和抗运动鬼影存在互斥 |
| 光圈 | √√ | √ | √ | - | 物理手段,实时处理,成本一般,景深变浅,影响画面内容 |
| 闪光灯 | √√√ | √ | √√ | ×色温突变 | 物理手段,实时处理,成本较高,使用场景受限 |
| 直方图拉伸 | √√√ | ×放大噪声 | √ | ×逐通道偏色 | 图像后期处理,成本较低 |
| 单帧去噪 | - | √√ | √ | ×难解偏色 | 图像后处理,成本较低 |
| 多帧去噪 | - | √√√ | √低光有鬼影 | √ | 图像后处理,成本一般 |
| AI-ISP | √√ | √√√ | √√ | √√ | 后处理,依赖NPU算力,成本高 |
所以自然而然就引出了,使用AI来解决传统ISP的问题。
二、传统 ISP 管线:每一级在解决什么物理问题
为了理解 AI-ISP“改了什么”,得先知道传统 ISP 在做什么。ISP 的处理流程是为大致串行的处理结构,如上图所示,每一个步骤都是在对图像的原始数据进行一个小方向上的微处理,例如白平衡,去噪等等,处理后的图像数据又传递给下一级。关于ISP pipeline的资料网上很多,这里就只就自己知道的能讲清楚的讲一下。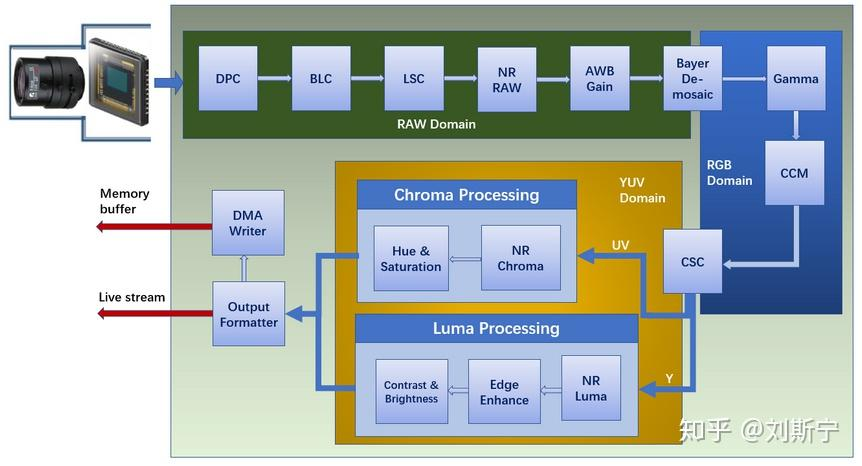
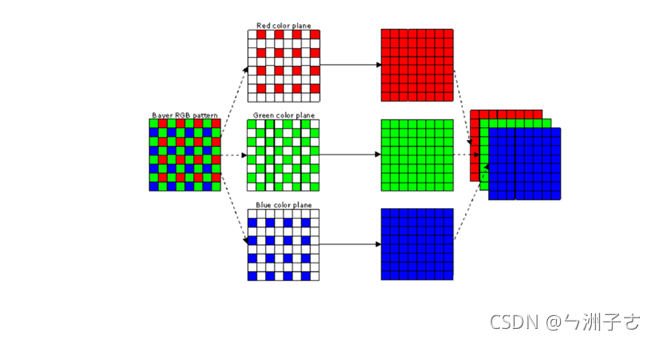
我们先看输入。相机传感器表面覆盖着一层彩色滤光阵列(CFA,最常见的是 Bayer 阵列),每个像素点其实只透过了 R、G、B 三种颜色中的一种。也就是说,传感器原始输出(RAW 域)里,每个位置只有一个颜色分量,另外两个是缺的。所以管线最前端要先做一堆 RAW 域的修补(黑电平校正、坏点校正、阴影校正之类的。。。)这些就是做一些简单的修复,不算ISP的核心。
-
Demosaic(从RAW域变换到RGB域) :把每个像素缺失的两个颜色分量插值补全,从单通道 Bayer 还原成完整的三通道 RGB。本质上就去预测——用一个像素周围的邻域去推测它缺的颜色。从算法角度看其实是是一次次的邻域加权运算,和CNN的卷积核在图上滑动是同一回事。Demosaic 的难点也在这里:当邻域里有高频细节(密集纹理、斜边、栅栏)时,固定规则的插值会猜错,产生摩尔纹和拉链效应。这是传统 demosaic 永远在和画质拉锯的地方。
-
白平衡: 解决的是「光源色温」问题:同一张白纸,在日光下和白炽灯下,传感器读到的 RGB 比例完全不同。传感器在白炽灯下容易对白色信息失真。白平衡通过给 R/G/B 通道乘不同增益,把"应该是白的东西"重新拉回白色。它通常在 RAW 域、demosaic 前后完成,本质是估计光源、再做通道缩放——估得准不准,全靠场景假设,这种假设本身就具有限制,不能自适应去白平衡。
-
去噪:在暗光下,光子少、信噪比低,传感器读出的就是一片噪点,就像开头的图片。降噪在 RAW 域做,对信噪比的贡献最高(因为噪声还没被后续非线性运算放大),所以传统ISP倾向于尽早降噪。它同样是邻域运算:用周围像素估计当前像素的"真值"。传统方法(双边滤波、NLM、3DNR 时域降噪)的两难是——降噪强了细节糊掉,降噪弱了噪点还在,这个"度"是人工调参调出来的,换个场景就得重调。
-
HDR 合成 / Tone mapping 处理动态范围问题:真实世界从暗处阴影到强光窗口的亮度跨度,远超传感器单次曝光能记录的范围。HDR 通过多帧不同曝光合成、再用 tone mapping 把高动态范围压回显示器能显示的 8bit。难点是合成时的运动物体会产生鬼影(因为在物体或镜头极快移动抓取的两帧图变化过大),tone mapping 压缩时又容易丢掉局部对比度。
-
色彩校正:用一个 3×3 矩阵把传感器的"设备相关"色彩,映射到标准色彩空间(让红的更准、绿的更绿)。Gamma 做非线性映射,匹配人眼对亮度的感知(人眼对暗部更敏感)。最后的锐化和色度降噪在 YUV 域收尾,提升主观清晰度。
总结下来,这里面的ISP流程多数都有一个特点,就是人工设计、人工调参,很多时候是需要取舍的,根据不同的场景去配一个适合的“经验值”。在光照充足、动态范围正常的场景下配一个值;在进入极暗、强逆光、高速运动这些极限场景,再配一个值;而且恶劣场景下配的这些参数还可能失效——demosaic 出摩尔纹、降噪失败、HDR 鬼影、暗光下色彩偏色。这些失效点,就是 AI-ISP 要解决的问题。
三、学术界:用 AI 替换「特定」模块
传统 ISP 失效的地方就可以用神经网络把它换掉。目前论文里,被 AI 化得最多的,就是上一节里那几个问题:去噪、HDR / tone mapping、低光增强、demosaic、超分。用AI去替代这些模块也是有收益的(只是说哪些模块的收益更高,哪些的收益容易达到边际)。
而且这些任务都能拿到成对的训练数据——一张带噪/低光的输入,配一张干净/正常曝光的目标,网络要做的就是学会这个映射。
实际上,神经网络替换 ISP 模块,做的事情和传统模块在数学形态上是一样的——还是邻域运算、还是在像素上滑窗卷积。区别只在于,传统模块的滤波核是工程师手工设计的固定规则,而 CNN 的核是从成千上万对图像里学出来的。这也是为什么这些网络通常是轻量级的 CNN 或 U-Net 结构:它们要替换的本来就是局部的、空间相关的像素操作,不需要特别花哨的架构。
具体落到怎么换,已知的有两条路线:
第一条是"端到端一张网":放弃ISP pipeline,训一个网络直接把 RAW Bayer 映射成最终 RGB。代表作是 Ignatov 等人的PyNET《Replacing Mobile Camera ISP with a Single Deep Learning Model》。通过一个金字塔结构的 CNN,隐式地学会了 demosaic、降噪、白平衡、色彩校正、去摩尔纹等所有 ISP 步骤,输入手机传感器 RAW、输出对标单反的成片。同一思路的还有 Chen 等人的《Learning to See in the Dark》(SID),它直接在 RAW 数据上用全卷积网络,替换掉大部分传统管线来处理极低照度成像。这条路线追求的是"画质天花板"——网络全局优化,不受人工管线分阶段误差累积的拖累。不过这个用于端侧可行性不大,对算力的要求过高。端侧一般不允许有这么多层网络。SID的工作与之类似,但是参数量少一点,单张图片的推理是零点几秒,而且是全分辨率RAW上做密集卷积计算。对于端侧来说,实时帧率处理能力和功耗都估计还是过重了。通过训练网络替换整个ISP的可能性对于端侧的可行性不太大。
第二条是"选择性 AI 化":保留传统管线的骨架,只把对画质影响最大的几个模块换成网络,其余沿用成熟的传统算法。这样的手段相对来讲,牺牲一部分画质上限,但是算力、成本更可控。而且相对没那么黑盒,验证的时候出了问题,可以分解出更多的中间节点来进行定位。
。对于实现产业化落地更现实一些。
四、现有的量产AI-ISP芯片
现有量产芯片主要是三种路线:
(1)语义协同模式。
也就是AI去对画面做语义分割(实时&离线)再让传统 ISP 对每个层分别施加不同的降噪、锐化、色彩处理等等。AI实际上还是扮演的“视觉神经”的角色。好处是适用于一些对算力要求不高的端侧场景。不过个人认为这种属于AI+ISP,狭义上不算AI-ISP。高通、苹果的部分ISP相关芯片算就是这个思路,
(2)强ISP+强AI模式。
这种就是现有ISP处理图像,然后外挂一个NPU,通过AI去根据ISP处理好的图像优化视频/图像质量。这种AI实现的是图像/视频成像完毕后的“后处理”模块,扮演一些图像识别,视频监测的功能,从功能层面上将ISP和AI相对独立的,耦合性没那么强。这种外挂NPU的方式也是目前国内ISP+NPU的主流处理模式。
(3)模块替换式。
这种个人认为是最符合AI-ISP定义的,就是AI直接去替换掉一个或多个(甚至全部的)传统ISP的处理流程(比如HDR,Demosaic等),构建一个新的AI-ISP处理架构,相当于把AI和ISP嵌合到一起,输出的yuv图直接就是AI的结果。
上述三种AI-ISP模式是完全不同的技术路线,不能说谁更好,相对来讲,AI与ISP的嵌合程度越高,画质提升的潜力越高,但是也往往面临黑盒程度上升,算力开销大,研发成本高,这取决于市场,算力预算和不同应用场景。对于验证来说,难点和重点也不一样:语义协同模式主要要调控制链路,也就是AI分割的结果,这个数据激励(或者是配置)给到ISP模块的合理性,给的对不对;强AI+强ISP模式主要看ISP和NPU之间的数据流,带宽这些是否匹配,满足性能要求(类似传统SOC的验证思路);模块替换模式就要看网络模块的顶点容差(怎么确保一定误差内的验证的完备性)。
五、验证视角:AI-ISP 真正难的不是「跑得对」,而是「怎么定义对」
ISP 和多数IP在工程形态上类似,都是流式像素管线。一帧图像按行流入,经过一级级处理流出,中间靠 line buffer 缓存邻域、靠 DMA 搬运、靠 AXI 总线对接,靠 backpressure 做流控,靠帧级握手做同步,靠 register model 配置参数。但是在 scoreboard 这一环,它标准是不确定的。传统 ISP 的比对数据是c_model生成的,在绝大多数下,这个数据是准确无误的,可以被认为是金标准。而 AI-ISP 的 golden 是一个浮点训练出来的神经网络。此外部署形态变了:网络训练时是 FP32 浮点,落到芯片上跑的是定点/量化的 NPU的精度会低一点,浮点模型量化成定点也会带来误差。所以这时候的比对应该是一种“容差”比对,在错误率可接受的范围内就算比对通过。按照对误差的容忍度进行区分,有以下几种区分标准:
(1)像素级容差:定点结果和浮点参考的逐像素差异,要落在量化误差预算内(比如绝对误差 ≤ 某阈值,或满足量化规格推导出的误差界)。这要求把量化引入的误差建模并量化,而不是凭感觉拍一个阈值。
(2)图像质量指标:用 PSNR、SSIM 这类感知指标设阈值——比如 DUT 输出相对参考图 PSNR ≥ 40dB 才算过。这本质上是把"对不对"从一个布尔判断,变成了一个带容差的质量判断。
(3)数值一致性分级:实践中往往分层——NPU 算子层面追求 bit-true(定点实现和量化参考模型逐 bit 对齐,这部分仍可 bit-accurate);而整条 AI-ISP 管线的端到端输出,则退到指标容差比对。把"哪一层能 bit-true、哪一层只能容差"切清楚,是验证方案设计的关键。
围绕这个核心转变,验证环境也要跟着升级:
- Model-in-the-loop / 协同仿真。golden 不再是一段 C 参考模型,而是要把训练框架(PyTorch/ONNX)里的模型拉进验证流程,做软硬协同——用浮点模型和量化后模型分别生成参考,喂给 scoreboard 做分层比对。这对验证工程师提了个新要求:得能读懂量化流程,知道 per-tensor / per-channel 量化、scale/zero-point 是怎么算的,否则连参考模型都对不齐。
- NPU 数据流与量化的验证。AI-ISP 的算力靠 NPU,那 NPU 的数据流(weight/output/row stationary 之类的复用策略)、量化算子、pre/post-process 单元本身就是验证对象。这里可以展开的内容就太多了,数据流的验证,包括数据流调度、硬件的tiling是否正确,缓存的双缓冲,权重和激活的DMA编排,让正确的数据在对应时刻到达正确的PE…;定点运算的验证,比如数据向上取整还是向下取整,saturation截的对不对,加法器位宽够不够…;pre/post-proces单元,比如layout转换,padding,激活函数查表,池化等等对不对…
- 功能覆盖率的重心转移。一般IP验证里收的 coverage 大多是spec要求的内容——各种类型、配置组合、特性组合等等。AI-ISP 的功能中也有类似的比如不同算子、张量形状、通道数、量化配置的组合…除此之外,覆盖率收集还要考虑"图像内容场景":低光、高动态、强逆光、高速运动这些 corner case 不再是spec要求的的排列组合,而是输入数据分布,这些场景更抽象,也更贴近真实场景。怎么构造覆盖这些场景的激励、怎么定义"覆盖到了暗光场景",是一套新的覆盖率思维。

| 传统IP验证 | AI-ISP验证 | |
|---|---|---|
| 覆盖空间 | 中(以spec状态为主) | 配置组合x输入数据分布 |
| 可枚举性 | 可枚举 | 图像空间连续,需要按照场景分类 |
| 边界用例 | 异常语法、码流边界 | 低光/HDR/逆光/高速运动 |
总结来说,其实就是传统ISP难以解决极暗、高速运动场景。AI-ISP可以为这个提供一条解决路径。但是AI-ISP的架构究竟是什么,以及AI在ISP中扮演什么样的角色,这个角色轻重如何,这个还是一个很tricky的问题。站在验证角度,需要考虑的就是验证思路要转变:工作量大了很多,而且要逐渐抛弃bit-exact的思维。
参考:
CVPR2018《Learning to See in the Dark》
CVPR2020《Replacing Mobile Camera ISP with a Single Deep Learning Model》
Proceedings of the IEEE《Efficient Processing of Deep Neural Networks: A Tutorial and Survey》
知乎:刘斯宁Understanding ISP Pipeline
海思NPU:Hi3519DV500
知乎:AI ISP未来有哪些发展趋势
高通“认知ISP”:Snapdragon 8 Gen 2

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)