2026年本地大模型运行指南:你的显卡够用吗?显存与量化策略全解析!
2026 年,本地部署大模型的门槛已经低到离谱。你手里那张"打游戏都嫌老"的显卡,可能正在吃灰,而它本可以替你跑一个 7B 甚至 14B 的模型。
先泼一盆冷水:你的显卡到底能不能跑?
答案是:大概率能。
如果你的电脑是 2022 年以后买的,显卡在 RTX 3060 及以上,或者 Mac 在 M2 及以上——你已经具备了本地跑大模型的硬件基础。不是"勉强能开机"的那种能,是"可以流畅对话、写代码、做摘要"的能。
很多人被模型卡上的"最低配置"吓退。那些数字通常过于乐观或过于保守,实战中参考价值有限。真正决定你能不能跑的,只有两件事:显存大小和量化策略。
🔑 要点
显存是硬门槛,量化是软技能。理解了这两点,你就能用手里的硬件跑出远超预期的效果。
一个公式算清显存需求
本地跑大模型,内存开销主要来自三部分:
显存估算
所需内存 ≈ 模型权重 + KV cache + 系统开销
模型权重是最大头。一个 7B 模型有 70 亿参数,FP16 精度下每个参数占 2 字节,仅权重就需要 14 GB。这就是为什么 8GB 显存跑不了 7B 模型的 FP16 版本——还没算上 KV cache 就已经爆了。
KV cache 是推理过程中缓存的键值对,和上下文长度成正比。7B 模型在 8K 上下文下约占用 1–2 GB,32K 上下文下膨胀到 4–8 GB。做长文档 RAG 时,KV cache 甚至能超过权重本身。
系统开销包括推理框架的内存占用、操作系统预留等,通常额外需要 10–20%。
💡 提示
实战中,在纯权重大小的基础上预留 20–30% 余量比较安全。FP16 的 7B 模型实际需要约 18 GB 可用内存,而不是纸面上的 14 GB。
这就引出了本地 LLM 中最重要的概念:量化(Quantization)。
量化:全篇最重要的概念
量化就是把模型权重从高精度浮点数压缩为低精度整数表示。质量略有下降,但内存节省非常显著。
量化格式对照表
格式 每参数比特 7B模型 14B模型 32B模型 70B模型 相对FP16质量
─────────────────────────────────────────────────────────────────────
FP16 16 14.0 GB 28.0 GB 64.0 GB 140 GB 基准
Q8_0 8.5 7.5 GB 15.0 GB 34.0 GB 75 GB ~99%
Q6_K 6.6 5.8 GB 11.5 GB 26.5 GB 58 GB ~98%
Q5_K_M 5.7 5.0 GB 10.0 GB 23.0 GB 50 GB ~97%
Q4_K_M 4.8 4.2 GB 8.5 GB 19.5 GB 42 GB ~95%
Q3_K_M 3.9 3.4 GB 7.0 GB 16.0 GB 35 GB ~90%
Q2_K 3.0 2.6 GB 5.5 GB 12.0 GB 27 GB 显著退化
数据来源:llama.cpp 量化规范及社区实测,2026 年 4 月
🔑 要点
**Q4_K_M 是默认最佳平衡点。**除非有特殊理由,否则就用它。日常对话、代码补全、文档摘要,Q4_K_M 的质量损失几乎感知不到。
Q5_K_M 或 Q6_K 适合显存充裕、对质量有要求的场景——比如 RAG(检索增强生成)问答、代码推理、数学计算。Q8_0 仅在内存非常充裕、追求接近 FP16 质量时使用。Q3_K_M 及更低仅在没有其他选择时使用,质量下降肉眼可见。
⚠️ 注意
一个反直觉的结论:如果不得不降到 Q3 才能塞进去,不如换个小模型用 Q5 跑。 7B Q5 的质量通常好于 14B Q3。
四档显卡配置对照表(收藏级)
这是本文的核心。请根据你的硬件对号入座。
第一档:入门 / 笔记本日常使用
显存 : 8–12 GB
代表硬件 : RTX 4060 8GB / 4070 8GB / 3060 12GB
MacBook Air M2/M3 16GB
可流畅运行: 3B–8B 模型(Q4_K_M)
速度 : 15–35 tokens/s
推荐模型:
• Qwen 2.5 7B Instruct Q4_K_M — 中文表现优秀
• Llama 3.1 8B Instruct Q4_K_M — 通用基线
• Gemma 3 9B Q4_K_M — 效率高,Google 出品
第二档:性价比甜点(大多数人在这一档)
显存 : 16–24 GB
代表硬件 : RTX 4070 Ti Super 16GB / 4080 16GB
RTX 3090 24GB / 4090 24GB
MacBook Pro M4 Pro 48GB
可流畅运行: 14B(Q5/Q6)、32B(Q4)
速度 : 25–80 tokens/s
推荐模型:
• Qwen 2.5 14B Instruct Q5_K_M — 多语言通用王者
• Qwen 2.5 32B Instruct Q4_K_M — 越级表现的明星模型
• DeepSeek-R1-Distill-Qwen-32B Q4 — 这一档最强推理模型
💡 提示
RTX 3090 24GB 在 2026 年依然是性价比之王。二手市场价格合理,24GB 显存能覆盖绝大多数场景。4090 的优势在速度,不在容量。
第三档:进阶用户 / 小团队工作站
显存 : 32–48 GB
代表硬件 : RTX A6000 48GB、RTX 3090 × 2(48GB)
RTX 5090 32GB、Mac Studio M4 Max 64–128GB
可流畅运行: 32B(Q6/Q8)、70B(Q4)
速度 : 70B 级别 10–25 tokens/s
推荐模型:
• DeepSeek-R1-Distill-Llama-70B Q4 — 开源推理天花板
• Qwen 2.5 72B Instruct Q4_K_M — 多语言旗舰
• Qwen 2.5 Coder 32B Q6_K — 高质量代码专用模型
第四档:发烧友 / 生产服务器
显存 : 80 GB+
代表硬件 : H100 80GB、A100 80GB
RTX 6000 Ada 48GB × 2
Mac Studio M3/M4 Ultra 192–512GB
可流畅运行: 70B(Q8)、100B+、MoE 模型
速度 : 高度取决于配置
这一档才能现实地跑动 DeepSeek-V3(671B MoE,激活 37B)
这类模型。对绝大多数读者而言属于过度配置。
实测速度参考(2026 年 4 月数据)
单用户、约 4K 上下文、Q4_K_M 量化下的推理速度:
推理速度(tokens/s)
硬件 8B Q4 14B Q4 32B Q4 70B Q4
────────────────────────────────────────────────────────
MacBook Air M3 16GB 22 OOM OOM OOM
Mac mini M4 24GB 30 18 OOM OOM
MacBook Pro M4 Pro 48GB 45 28 14 OOM
Mac Studio M4 Max 128GB 70 50 28 14
RTX 3060 12GB 60 offload offload offload
RTX 3090 24GB 110 75 35 offload
RTX 4090 24GB 140 95 45 offload
RTX 3090 × 2 (48GB) 110 75 50 22
RTX 5090 32GB 170 115 60 offload
OOM = 内存不足;offload = 部分卸载到 CPU,吞吐量下降 5–10 倍
数据来源:Simplico 实测及社区基准测试,2026 年 4 月
几个值得注意的细节:RTX 4090 比 3090 快约 25–30%,但两者显存都是 24GB。如果你主要跑 32B 及以下模型,3090 的性价比更高。RTX 5090 的 32GB 显存是消费级首次突破 24GB 天花板,但 70B Q4 仍然装不下——需要 42GB+。
💡 提示
Mac Studio M4 Max 128GB 能单设备跑 70B,这是统一内存架构的独特优势。代价是速度比双 3090 慢约 40%。
Ollama vs llama.cpp:选哪个工具?
硬件确定了,下一步是选推理框架。2026 年最主流的两个选择:
❌ Ollama —— 主打"一行命令跑模型"
优点:上手极快,模型库丰富,自动处理下载和配置。适合新手和不想折腾的人。
缺点:控制力弱,高级优化选项少,默认量化策略偏保守。
✅ llama.cpp —— 底层推理引擎,控制力最强
优点:支持最精细的量化选项、KV cache 量化、CPU/GPU 混合卸载、长上下文优化。性能天花板最高。
缺点:需要手动配置,学习曲线陡峭。
🔑 要点
刚入门 → Ollama,先跑起来再说
追求极致性能 → llama.cpp,配合合适的量化参数
做 RAG / Agent → llama.cpp 或 vLLM,需要精细控制内存分配
Mac 用户 → MLX 框架,Apple Silicon 原生优化,速度比 llama.cpp 快 20–40%
三个常见踩坑
1
OOM(显存溢出)
现象:模型加载到一半报错,或者对话中途崩溃。
排查:检查当前量化级别,尝试降低一级(Q5 → Q4)。检查上下文长度,超过 8K 时 KV cache 会急剧膨胀。关闭其他占用显存的程序。
2
CPU 回退(offload)
现象:模型能加载,但生成速度极慢(< 5 tokens/s)。
原因:显存不够,部分层被卸载到内存甚至硬盘。RTX 3060 12GB 跑 14B 模型时常见。
解决:换更小的模型,或换更高量化。加显存是最直接的方案。
3
长上下文崩溃
现象:短对话正常,一上传长文档就 OOM。
原因:KV cache 随上下文长度线性增长。32B 模型在 32K 上下文下,KV cache 可能占 16 GB+。
解决:开启 KV cache 量化(llama.cpp 支持 Q8/Q4 KV cache)。缩短文档分段长度。
升级建议:什么时候该换显卡?
先问自己三个问题:
- 你现在的显卡是不是已经榨干了? 很多人还没试过 Q4_K_M、没调过上下文长度、没关过浏览器后台,就急着升级。
- 你真正需要的模型是多大? 90% 的日常任务,8B–14B 模型足够。别为了一个月用一次的 70B 去买新卡。
- 你的瓶颈是显存还是速度? 显存不够只能换卡,速度不够可以尝试框架优化(llama.cpp 比 Ollama 快 30%+)。
2026 年的升级优先级:
• 8GB 显存 → 12GB 或 16GB(解锁 14B 模型)
• 12GB 显存 → 24GB(解锁 32B 模型,性价比最高的一步)
• 24GB 显存 → 48GB 或更高(解锁 70B 模型,进入工作站级别)
如果你现在用的是 RTX 3060 12GB 或更高,先别急着换。把本文的对照表收藏好,按量化策略调一调,你可能发现手里的卡还能再战一年。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
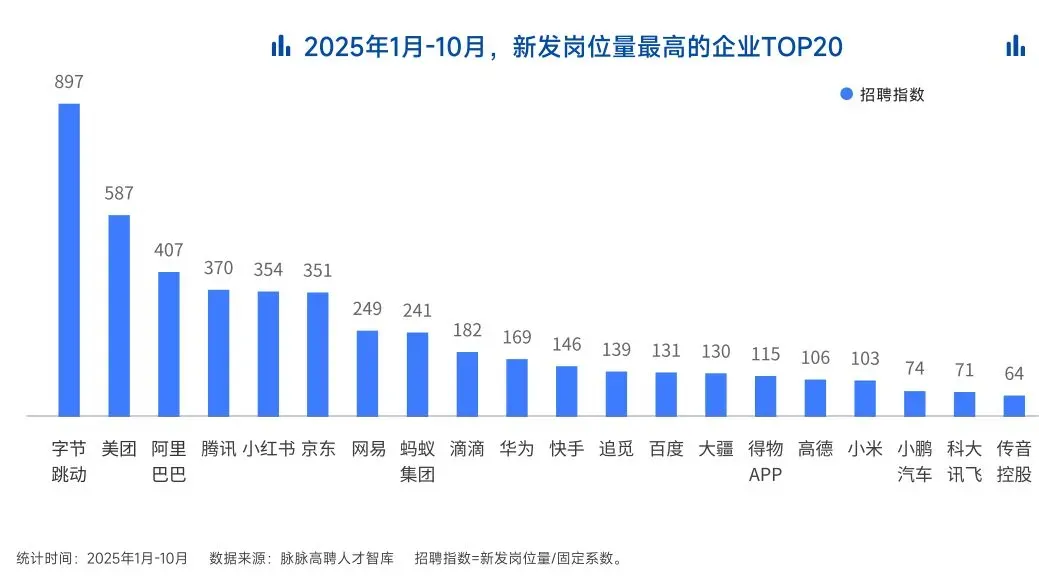
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献179条内容
已为社区贡献179条内容

所有评论(0)