用 Agent 搭建网页内容采集与结构化处理流水线
用 Agent 搭建网页内容采集与结构化处理流水线
摘要:当采集目标不只是正文,而是标题、价格、作者、发布时间、链接和页面截图时,可以把网页处理拆成多个可验证步骤。本文用 URL 转 JSON、链接提取和网站截图接口演示一个更像工程系统的网页内容 Agent。
关键词:网页内容采集 Agent、URL 转 JSON API、链接提取 API、网站截图 API、结构化数据抽取
为什么需要流水线
很多网页采集需求一开始只是“帮我看一下这个页面”,最后会变成“把页面里的字段提出来,保留截图证据,继续追踪页面里的相关链接”。如果所有动作都交给大模型直接完成,结果往往难复现,也不方便重试。
更好的方式是让 Agent 做调度:先决定要抽取什么字段,再调用网页 API,最后把结果写入数据库或审核队列。
Agent 工作流
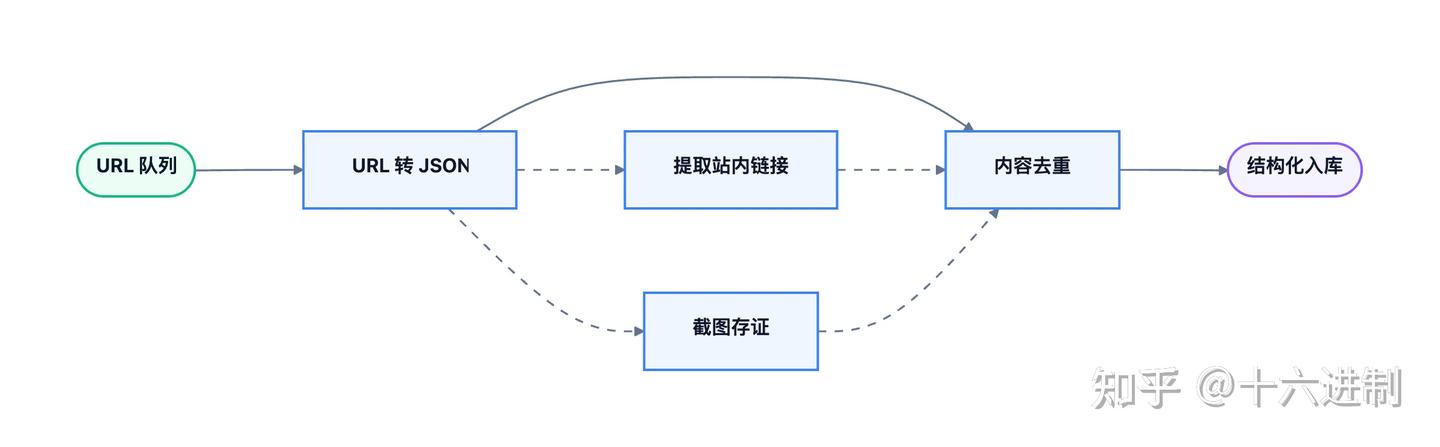
接口编排
| 能力 | 接口 | 请求方式 | 适合场景 |
|---|---|---|---|
| 语义化抽取字段 | 语义化获取站点 JSON 结构内容 | POST | 从页面提取标题、价格、作者、摘要等指定字段 |
| 提取页面链接 | 网页 URL 链接提取 | GET | 构建后续采集队列或发现关联页面 |
| 保留页面状态 | 网站截图与 HTML 快照 | POST | 保存页面截图和 HTML 快照,便于复核 |
调用示例
curl -X POST "https://api.gugudata.com/websitetools/url2json?appkey=YOUR_APPKEY&url=https%3A%2F%2Fexample.com%2Fproduct%2F10001&prompt=%E6%8F%90%E5%8F%96%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E3%80%81%E4%BB%B7%E6%A0%BC%E3%80%81%E5%93%81%E7%89%8C%E3%80%81%E4%B8%BB%E8%A6%81%E5%8F%82%E6%95%B0%E5%92%8C%E9%A1%B5%E9%9D%A2%E6%91%98%E8%A6%81%EF%BC%8C%E8%BF%94%E5%9B%9E%20JSON%E3%80%82"
curl -G "https://api.gugudata.com/websitetools/url2links" \
--data-urlencode "appkey=YOUR_APPKEY" \
--data-urlencode "url=https://example.com/product/10001"
curl -X POST "https://api.gugudata.com/websitetools/url2snapshot?appkey=YOUR_APPKEY&url=https%3A%2F%2Fexample.com%2Fproduct%2F10001&responseFormat=url&fullPage=true&width=1920&height=1080"
Agent 如何决策
Agent 不需要每次都调用所有接口。一个实用策略是:
| 页面类型 | 建议动作 |
|---|---|
| 文章页 | URL 转 JSON,提取标题、作者、发布时间和摘要 |
| 列表页 | 先提取链接,再把详情页加入队列 |
| 商品页 | URL 转 JSON,同时保留截图作为价格证据 |
| 低可信页面 | 只记录链接和截图,不自动入库 |
返回处理
URL 转 JSON 的 Data 结构会随 prompt 变化,因此自己的程序要先定义目标字段,再校验返回结果。链接提取结果建议去重后入队,并记录来源页面。截图或快照结果要和结构化字段绑定,方便之后人工复核。
工程注意点
- prompt 要短而明确,说明目标字段,不要把业务规则全部塞进抽取指令。
- 采集队列需要限速和失败重试,避免因为外部页面波动导致任务堆积。
- 对重复 URL 做规范化,例如去掉无意义的追踪参数。
- 对结构化结果设置字段级校验,缺少关键字段时进入人工审核。
标准架构拆解
网页内容采集 Agent 更像一个小型数据管道,而不是单次 API 调用。推荐拆成以下模块:
| 模块 | 责任 |
|---|---|
| URL 队列 | 保存待处理 URL、优先级、来源和重试次数 |
| 抽取策略 | 根据页面类型选择 URL 转 JSON、链接提取或截图 |
| 数据校验 | 校验必填字段、字段类型和来源一致性 |
| 证据存储 | 保存截图、HTML 快照、原始 URL 和处理时间 |
| 审核出口 | 将低置信度或缺字段记录交给人工复核 |
这个架构的重点是把“抽取”和“决策”分开。接口负责返回页面内容或结构化字段,Agent 负责判断下一步是入库、重试、继续发现链接,还是转人工。
数据流与接口边界
建议把页面处理分为三种路径:
| 路径 | 触发条件 | 输出 |
|---|---|---|
| 详情页抽取 | 页面包含明确实体或产品内容 | 结构化 JSON |
| 列表页发现 | 页面包含大量详情链接 | 候选 URL 队列 |
| 证据保留 | 页面内容会变化或需要复核 | 截图与快照 |
URL 转 JSON 的 prompt 应固定模板化,例如“提取标题、价格、品牌、摘要”。不要让用户随意输入复杂 prompt 直接进入生产任务,否则后续字段会不稳定。链接提取结果也应先经过域名过滤和去重,再进入下一轮采集。
可靠性与观测
可观测性建议至少包含:
| 指标 | 说明 |
|---|---|
| queued_url_count | 当前待处理 URL 数 |
| extraction_success_rate | 结构化抽取成功率 |
| required_field_missing_rate | 必填字段缺失率 |
| screenshot_success_rate | 证据截图成功率 |
| duplicate_url_rate | 链接重复率 |
当某个域名连续失败时,可以自动降级:只保存 URL 和截图,不继续做结构化抽取。这样能避免单个站点异常拖垮整个队列。
落地清单
- 每个 URL 只保留一个规范化主键,避免重复采集。
- prompt 模板版本化,字段变更时能追溯历史结果。
- 截图和结构化数据使用同一个任务 ID 绑定。
- 列表页发现的链接不要立即全量抓取,先入队并限速。
- 缺少核心字段的记录不要自动发布,进入审核池。
可扩展方向
这个流水线可以接入 SEO 巡检、内容审核、知识库构建或竞品监控。Agent 的价值不是替代所有规则,而是根据页面类型选择合适工具,并把异常情况交给人或后续任务处理。
相关接口

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)