基于知识图谱的个性化学习路径推荐系统设计(Python、推荐、计算机专业、15000字、高质量)
摘 要
当前教育数字化转型深入推进,个性化、智能化学习成为教育领域的核心发展趋势,传统学习模式存在学习资源匹配低效、学习路径固化单一、知识体系碎片化、智能答疑滞后等痛点,难以满足学生差异化的学习需求。知识图谱、RAG检索增强生成、本地大模型、智能路径规划算法等技术的融合应用,为智慧学习系统的构建提供了核心技术支撑,在此背景下,研发基于知识图谱的个性化学习路径推荐系统具有重要的教育实践与应用价值。
本基于知识图谱的个性化学习路径推荐系统,采用Spring+Vue前后端分离架构、Java开发语言,整合Neo4j知识图谱数据库、Redis缓存、MySQL关系型数据库,融合Ollama本地大模型与RAG技术搭建本地知识库智能问答模块。系统划分学生端、教师端、管理员端三大功能端口,实现学习资源管理、知识图谱构建与维护、智能学习路径规划(DAG+拓扑排序+路径优化算法)、个性化学习资源推荐、在线测试、学习分析、RAG智能问答等核心功能,为用户提供全流程的个性化智慧学习服务。
经功能测试与验证,系统运行稳定、响应高效,有效解决了传统学习中资源错配、路径模糊、知识理解困难等核心问题,助力学生精准定位学习薄弱点、规划科学学习路径,大幅提升自主学习效率;同时为教师提供资源管理、学情统计工具,为管理员提供用户管理、系统配置、算法优化等运维支撑。系统在个性化教育、智慧学习领域具备广阔的应用前景,对推动教育数字化、智能化升级具有积极的现实意义。
关 键 词:个性化学习;知识图谱;学习路径推荐;RAG;Ollama本地大模型;Neo4j
ABSTRACT
With the in-depth advancement of digital transformation in education, personalized and intelligent learning has become the core development trend in the education field. Traditional learning models suffer from pain points such as inefficient matching of learning resources, fixed and single learning paths, fragmented knowledge systems, and delayed intelligent Q&A, which are difficult to meet the differentiated learning needs of students. The integrated application of technologies such as knowledge graph, RAG (Retrieval-Augmented Generation), local large language model and intelligent path planning algorithm provides core technical support for the construction of intelligent learning systems. Under this background, the development of a knowledge graph-based personalized learning path recommendation system has important educational practice and application value.
This knowledge graph-based personalized learning path recommendation system adopts the Spring+Vue front-end and back-end separation architecture and Java programming language, integrates Neo4j knowledge graph database, Redis cache and MySQL relational database, and combines Ollama local large model with RAG technology to build an intelligent Q&A module for the local knowledge base. The system is divided into three functional ports: student terminal, teacher terminal and administrator terminal, and implements core functions such as learning resource management, knowledge graph construction and maintenance, intelligent learning path planning (DAG + topological sorting + path optimization algorithm), personalized learning resource recommendation, online testing, learning analysis and RAG intelligent Q&A, providing users with a full-process personalized intelligent learning service.
Functional testing and verification show that the system runs stably and responds efficiently. It effectively solves the core problems of traditional learning such as resource mismatch, vague paths and difficult knowledge understanding, helps students accurately locate weak learning points and plan scientific learning paths, and greatly improves the efficiency of independent learning. At the same time, it provides teachers with tools for resource management and learning situation statistics, and provides administrators with operation and maintenance support such as user management, system configuration and algorithm optimization. The system has broad application prospects in the fields of personalized education and intelligent learning, and has positive practical significance for promoting the digital and intelligent upgrading of education.
KEY WORDS: Personalized Learning; Knowledge Graph; Learning Path Recommendation; RAG; Ollama Local Large Model; Neo4j
目 录
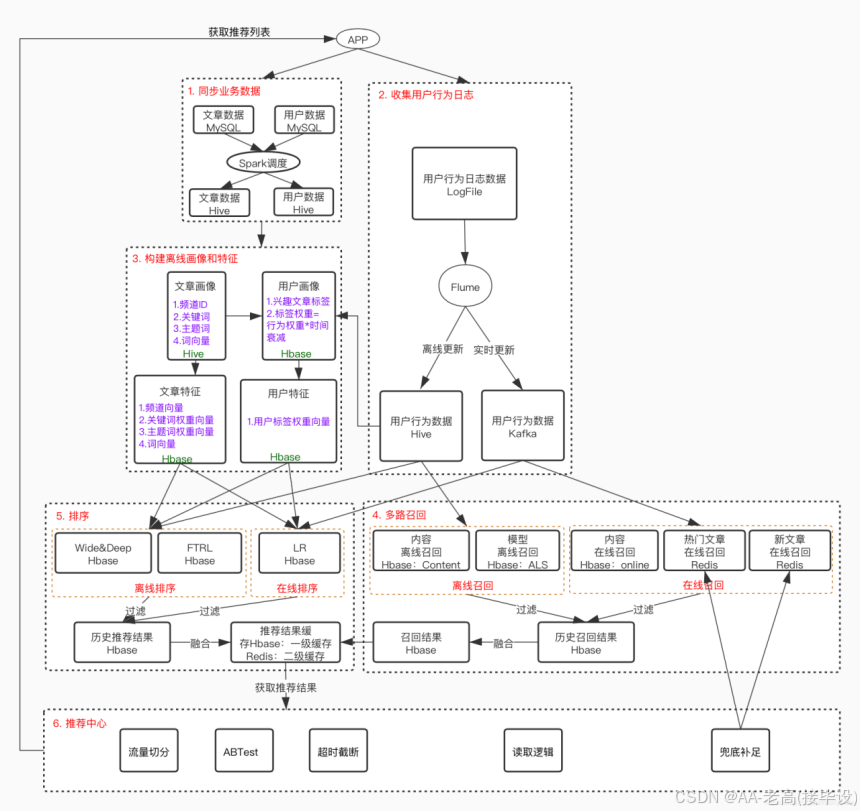
基于知识图谱的个性化学习路径推荐系统构建流程图如图3.1所示。首先进行学习领域相关知识的本体设计构建,根据本体设计开展详细的数据源采集,采用Python爬虫技术获取课程资源、知识点解析、教育文献等学习相关数据,并运用自然语言处理方法抽取知识点、课程、学习目标、用户特征、学习行为等实体信息及其相互关系。接着,使用Neo4j数据库完成数据存储,构建学习领域知识图谱,建立各实体间的关系网络(如知识点前置依赖、课程覆盖知识点、用户薄弱知识点等)。
用户可完成注册操作,注册后支持常规登录与自动登录功能。系统通过爬虫技术采集全网学习资源、对接教育平台API获取用户学习行为数据,用于知识图谱迭代与推荐模型优化,保障推荐策略的时效性与精准性。用户完成知识水平测评后,系统检索学习领域知识图谱,展示知识点关联关系、适配课程、学习进度节点等信息。最后系统实时追踪用户学习行为(如答题正确率、学习时长、课程完成度),基于存储于Neo4j图数据库的知识图谱动态调整学习路径,推荐类型涵盖基础补差、进阶提升、专项突破等。
-
- 本体构建
在进行学习数据集成时,本体能够有效解决数据异构性问题。数据异构性主要体现在语法、模式和语义三个方面:语法异构指数据存储格式、编码规则等差异,如学习笔记的TXT格式与课程大纲的XML格式不同;模式异构表现为不同学习平台的数据库表结构、字段定义不一致,如“学习时长”字段部分平台记为“学习耗时”、部分记为“学习分钟数”;语义异构则源于同一概念在不同系统中的含义差异,如“初等代数知识点”在不同教材中涵盖的内容范围不同。本体通过语义描述和逻辑推理两大功能化解这些问题:语义描述能对学习领域数据进行标准化的概念定义和属性说明,统一不同数据源的语义表达(如统一“知识点难度”的分级标准);逻辑推理则基于本体定义的规则和关系,推导隐含知识(如由“用户未掌握知识点A”和“知识点B依赖知识点A”,推导用户暂不适合学习知识点B),自动处理数据间的关联与冲突,实现异构学习数据的有效整合与协同应用。
在学习领域知识图谱构建中,本体构建是核心环节,其有助于梳理学习领域知识体系,定义知识点、课程、用户、学习目标、学习资源等类,以及“前置依赖”“覆盖”“掌握程度”等关系和“难度等级”“学习风格”等属性。进行本体构建时,首先需明确个性化学习路径推荐系统需解决的核心问题(如用户知识缺口识别、学习路径适配规则、课程与知识点匹配逻辑等),并将这些问题整理为Excel表格,依据问题内容拆解核心概念与关联逻辑,进而构建本体。在此基础上,开展知识抽取与关系抽取工作,并依托本体框架建立图数据库。
文本数据包含教材内容、教育学术文献、课件讲义、用户学习笔记等。教材内容与课件讲义是学科知识的核心载体,详细记载了知识点的定义、逻辑关联、学习要求;教育学术文献涵盖学习路径设计、个性化教育的理论与方法,为推荐策略提供理论支撑;用户学习笔记则反映学习者对知识点的理解程度与学习难点。
结构化数据以学习管理系统(LMS)的用户成绩、答题记录、学习时长、课程完成度,以及课程目录体系为代表。学习管理系统数据完整记录了用户从注册到学习的全流程行为,课程目录体系为知识点的层级划分提供了标准。半结构化数据如教育论坛的学习经验分享、在线课程评论、学习类APP的用户反馈,能反映学习者在实际学习中遇到的问题、对课程的评价以及学习偏好;教育类网站则提供了丰富的科普知识、学习方法指导和行业前沿内容。
获取这些数据的途径多样,既可通过公开教育数据集(如国家中小学智慧教育平台开放数据、教育科研机构共享数据集)获取权威、规范的数据,也能利用网络抓取技术从海量互联网教育资源中筛选有用内容,还可借助API接口与学校、在线教育平台实现数据对接,保障数据的实时性与准确性。
数据预处理环节需针对不同类型数据开展针对性处理:对于文本数据,剔除乱码、无关字符、重复的知识点解析内容;对于结构化数据,修正错误的格式(如日期格式不统一)和数据录入错误(如成绩录入偏差);对于半结构化数据,筛选并去除广告、无意义评论、灌水内容等无用信息。数据标准化是关键环节,通过统一不同数据源的数据格式(如学习时长统一为“分钟”、成绩统一为百分制)、知识点命名规则(如“一元二次方程”统一替换“二次方程(一元)”),确保数据一致性。运用自然语言处理技术对文本数据进行分词、词性标注、关键词提取,挖掘核心知识点与学习难点;对结构化数据进行归一化处理,消除量纲差异(如将不同学科的成绩转化为标准分)。
实体识别与关系抽取环节,主要利用机器学习与自然语言处理算法(如BERT模型、依存句法分析),从数据中识别出知识点、课程、用户、学习目标等实体,并确定实体间的关联关系,如“知识点-前置依赖”“课程-覆盖知识点”“用户-薄弱知识点”等。知识融合旨在解决数据冲突与不一致问题,将来自不同数据源的同一实体与关系信息(如不同平台对“微积分入门”课程覆盖知识点的不同描述)进行整合,形成统一、准确的知识表示。最终,借助图数据库技术,将处理后的数据以图结构存储,其中节点代表实体,边表示关系,构建出直观、高效的学习领域知识图谱,为个性化学习路径推荐提供核心知识支撑。
在本系统设计中,知识抽取是核心技术环节。知识抽取的目标是从大量非结构化或半结构化教育文本与行为数据中,提取出与个性化学习路径推荐相关的有效信息,包括知识点名称、知识点层级、课程信息、学习方法、用户学习特征、知识点掌握程度等。首先,通过自然语言处理技术(如命名实体识别、关系抽取、语义角色标注、依存句法分析等),从教材、课程大纲、教育文献、用户学习行为记录等来源中识别学习领域的实体与关系。实体涵盖具体的知识点(如“三角函数诱导公式”)、课程(如“高中数学必修一同步课程”)、学习方法(如“错题复盘法”)、用户特征(如“视觉型学习者”)等;关系则体现实体间的相互联系,如“诱导公式是三角函数的子知识点”“错题复盘法适用于薄弱知识点巩固”“某用户未掌握诱导公式知识点”。通过构建实体-关系图谱,将碎片化的学习信息转化为结构化知识,便于后续的路径推理与推荐。
通过对大量标注的教育数据(如人工标注的知识点关联数据集、用户学习行为标签数据集)进行模型训练,可进一步提升对教育文本与行为数据的理解和抽取能力。为保障知识质量,需对抽取的知识开展多轮验证与动态更新:采用教育领域专家评审、多数据源交叉核验等手段,消除信息冗余、错误(如错误标注的知识点依赖关系);结合教育大纲更新、课程内容迭代,实时更新抽取的知识内容。通过这些技术手段,系统能够持续完善学习领域知识图谱,为用户提供精准、贴合学习需求的个性化路径推荐,同时也为教育机构优化课程设计、提升教学效率提供数据支持与决策依据。
基于知识图谱的个性化学习路径推荐系统的设计与实现在技术层面具备较强可行性。首先,Python作为核心开发语言,拥有丰富的开源库与工具链:Scrapy、BeautifulSoup等爬虫框架可高效抓取互联网教育资源,NLTK、Spacy、jieba等自然语言处理库能完成教育文本的分词、实体识别等操作,TensorFlow、PyTorch等深度学习框架可支撑个性化推荐算法的训练与优化,具备强大的数据处理与算法实现能力。
Neo4j图数据库具备卓越的图形数据存储与查询能力,能够高效存储和检索复杂的学习领域三元组数据(如“用户-薄弱知识点-三角函数”),结合Cypher查询语言,系统可快速匹配知识点关联关系与用户特征,实现学习路径的高效推理。此外,Flask、Django等轻量级Web框架可搭建稳定的用户交互界面,满足用户登录、测评、路径查看等交互需求;协同过滤算法、知识图谱路径推理算法等成熟的推荐技术,可结合学习领域特性进行适配优化,保障推荐结果的精准性与实时性。依托这些成熟、开源且易用的技术体系,本系统在技术实现上具备高可行性。
从经济角度来看,本系统的设计与实现具备良好的可行性。首先,核心开发工具与框架(Python、Neo4j社区版、Flask等)均为开源免费,大幅降低了开发阶段的工具成本;数据采集环节以公开教育资源、免费API对接、开源数据集为主,无需高额购买商业数据,进一步压缩前期投入。系统运行阶段,除非面临大规模用户并发访问或海量数据存储需求,普通服务器与数据库的维护成本较低,且可通过云服务器按需付费模式灵活控制成本。
从收益端来看,本系统具备明确的商业价值:可面向K12学校、职业教育机构、在线教育平台提供定制化的个性化学习路径推荐服务,收取技术服务费;面向C端用户,可推出基础免费+增值服务(如一对一路径规划、专属学习资源推荐)的盈利模式;还可通过与教育出版社、教辅机构合作,实现精准内容推广与广告植入。结合当前个性化教育的市场需求,系统有望吸引教育机构投资与商业合作,中长期可实现成本回收与可持续盈利,经济可行性较高。
从社会角度而言,本系统的设计与实现具备显著的社会价值与可行性。当前教育领域普遍存在“统一教学模式适配性差”的问题,不同学习者的知识基础、学习风格、学习节奏差异显著,传统统一化的学习路径难以满足个性化需求,导致部分学习者效率低下、学习兴趣不足。本系统可基于知识图谱精准识别用户的知识缺口与学习偏好,为不同特征的学习者规划适配的学习路径(如为基础薄弱者推荐补差型路径,为学有余力者推荐拓展型路径),帮助学习者提升学习效率、降低学习焦虑。
系统可助力教育资源的均衡化分配:偏远地区学校、师资薄弱机构可依托系统获取标准化、个性化的学习路径规划能力,弥补优质教育资源不足的短板;对于教育工作者,系统可提供学习者的知识掌握数据与路径优化建议,辅助教师开展精准教学。此外,系统能培养学习者的自主学习能力,帮助其建立科学的学习方法,提升全民学习素养。
本系统契合个性化教育的发展趋势,能够解决当前教育场景的实际痛点,具备极高的社会可行性与推广价值。
系统自顶向下分为五层:用户层(学生/教师/管理员)、前端展示层(Vue3界面)、后端服务层(Spring Boot接口)、数据支撑层(多数据库+缓存)、智能引擎层(RAG+Ollama+路径算法)。层间通过标准接口通信,降低模块依赖,提升维护效率。系统核心领域划分如表4.1所示,明确学习资源、知识图谱、用户、智能服务四大核心领域,支撑全功能落地。
表4.1 系统核心知识领域划分
|
一级领域 |
二级领域 |
详细内容 |
|
学习资源 |
资源类型 |
视频、文档、PPT、音频 |
|
资源管理 |
上传、编辑、删除、关联知识点 |
|
|
知识图谱 |
知识点 |
基础知识点、进阶知识点、薄弱知识点 |
|
关系类型 |
前置依赖、相关关联、资源覆盖、题目测试 |
|
|
用户体系 |
角色分类 |
学生、教师、管理员 |
|
用户数据 |
学习行为、答题记录、用户画像 |
|
|
智能服务 |
路径规划 |
DAG + 拓扑排序 + Dijkstra/A * 算法 |
|
智能问答 |
RAG 检索 + Ollama 本地大模型生成 |
系统通过定义实体与关系的层级关联,构建标准化知识逻辑:知识点间存在前置依赖关系,学习资源与知识点为覆盖关系,测试题目与知识点为测试关系,知识点间存在相关关系。基于知识图谱的类与个体关系定义如表4.2所示,为学习路径推理、资源推荐、智能问答提供数据依据。
表4.2 基于知识图谱的类与个体关系定义
|
类别 |
具体关系 |
示例 |
|
知识点依赖关系 |
基础知识点为进阶知识点的前置 |
Matplotlib 基础是折线图绘制的前置 |
|
资源关联关系 |
学习资源覆盖对应知识点 |
Python 教程视频覆盖数据可视化知识点 |
|
题目测试关系 |
练习题对应测试知识点 |
图表计算题测试 Matplotlib 知识点 |
|
知识关联关系 |
同类知识点互为相关 |
折线图与柱状图互为相关知识点 |
-
- 数据获取
本系统采用多源数据采集模式,结合结构化数据导入、非结构化资源上传、用户行为实时采集、知识图谱批量导入四种方式获取数据,覆盖系统运行全量数据需求。
结构化数据通过Python脚本批量导入与JPA自动创建获取:用户信息、学习资源元数据、题库、答题记录、系统配置等结构化数据,依托MySQL存储,通过kg-extractor目录下的reimport_quiz.py脚本导入题库,通过手动执行SQL插入初始用户数据,后端启动后通过JPA与Flyway自动创建数据表。知识图谱数据通过kg_importer.py脚本批量导入Neo4j,包含知识点、资源、题目等节点与前置依赖、关联等关系,完成基础图谱构建。
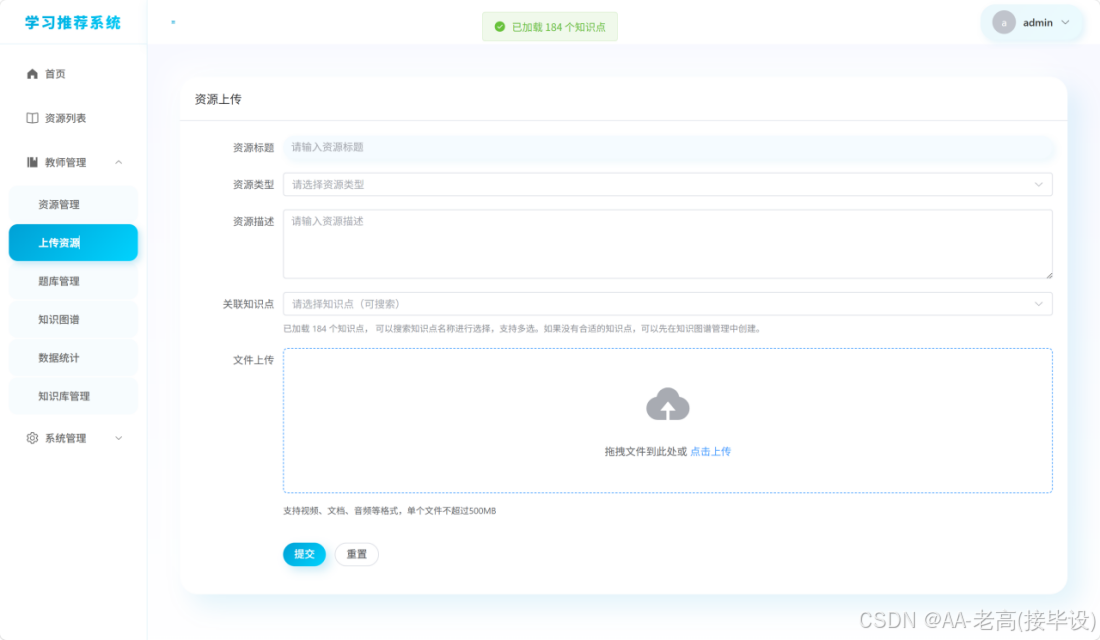
非结构化数据由教师端上传获取:支持视频、文档、PPT、PDF、Word、TXT等格式学习资源与知识库文档,上传后存储于后端uploads/resources目录,其中RAG知识库文档单独存放于rag子目录,为本地知识库构建提供原始数据。
用户行为数据通过后端实时采集获取:记录用户学习时长、资源浏览、答题对错、收藏评价、搜索查询等行为数据,存入MySQL的learning_events表,为用户画像、学习分析、智能推荐提供数据支撑。
-
- 构建知识图谱
(1)读取JSON知识图谱数据
使用Python json库读取本地知识图谱数据,解析为可直接导入Neo4j的结构化数据,代码如下:
python
import json
# 读取知识图谱JSON文件
with open("kg_enhanced.json", "r", encoding="utf-8") as f:
kg_data = json.load(f)
(2)创建实体节点
通过Neo4j官方驱动连接数据库,循环创建知识点、资源、题目三类节点,代码如下:
python
from neo4j import GraphDatabase
# 连接Neo4j
uri = "neo4j://localhost:7687"
user = "neo4j"
password = "110873520"
driver = GraphDatabase.driver(uri, auth=(user, password))
def create_nodes(data):
with driver.session() as session:
# 创建知识点节点
for kp in data["knowledge_points"]:
session.run("""
CREATE (kp:KnowledgePoint {name: $name, desc: $desc, chapter: $chapter})
""", name=kp["name"], desc=kp["description"], chapter=kp["chapter"])
# 创建资源节点
for res in data["resources"]:
session.run("CREATE (r:Resource {title: $title, type: $type})",
title=res["title"], type=res["file_type"])
# 创建题目节点
for q in data["questions"]:
session.run("CREATE (q:Question {content: $content})", content=q["content"])
create_nodes(kg_data)
driver.close()
(3)创建实体关系
根据关系类型,批量创建PREREQUISITE、COVERS、TESTS、RELATED_TO四类关系,代码如下:
python
def create_relationships(data):
with driver.session() as session:
# 前置依赖关系
for rel in data["prerequisite"]:
session.run("""
MATCH (a:KnowledgePoint {name: $from}), (b:KnowledgePoint {name: $to})
CREATE (a)-[:PREREQUISITE]->(b)
""", from=rel["from"], to=rel["to"])
# 资源覆盖知识点关系
for rel in data["covers"]:
session.run("""
MATCH (r:Resource {title: $from}), (kp:KnowledgePoint {name: $to})
CREATE (r)-[:COVERS]->(kp)
""", from=rel["from"], to=rel["to"])
create_relationships(kg_data)
(4)数据验证与可视化
导入完成后,在Neo4j浏览器执行Cypher语句验证数据:
cypher
// 查询所有知识点节点
MATCH (kp:KnowledgePoint) RETURN kp LIMIT 10;
// 查询知识点依赖关系
MATCH (a)-[r:PREREQUISITE]->(b) RETURN a,r,b LIMIT 10;
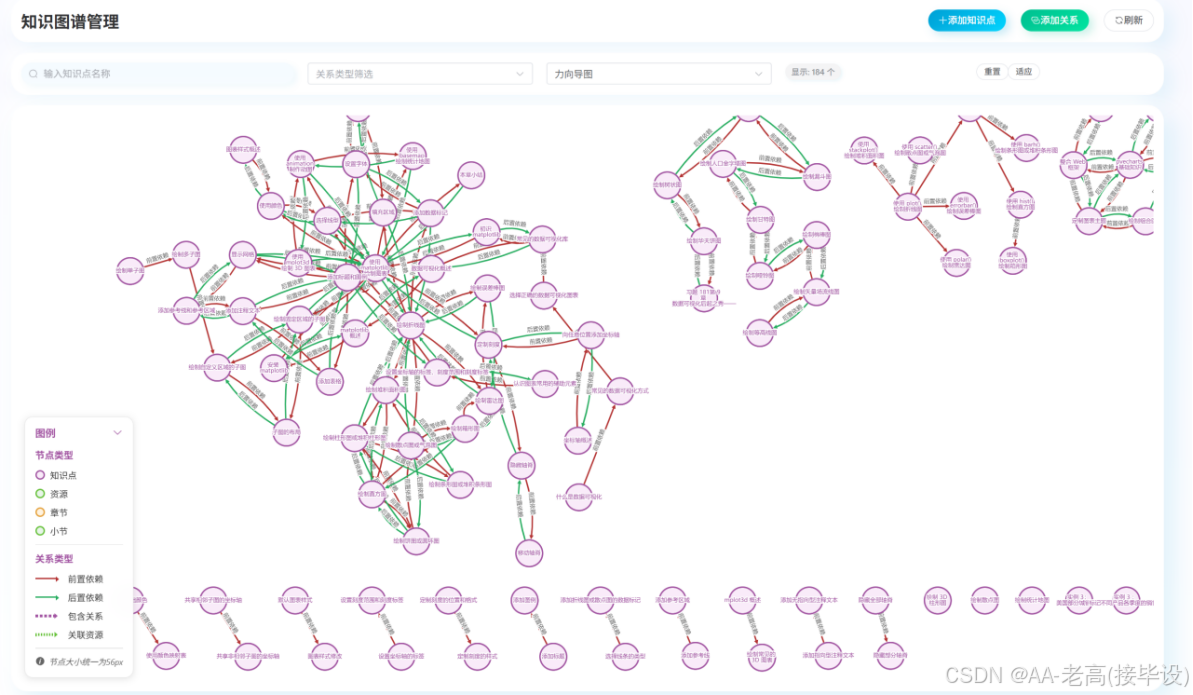
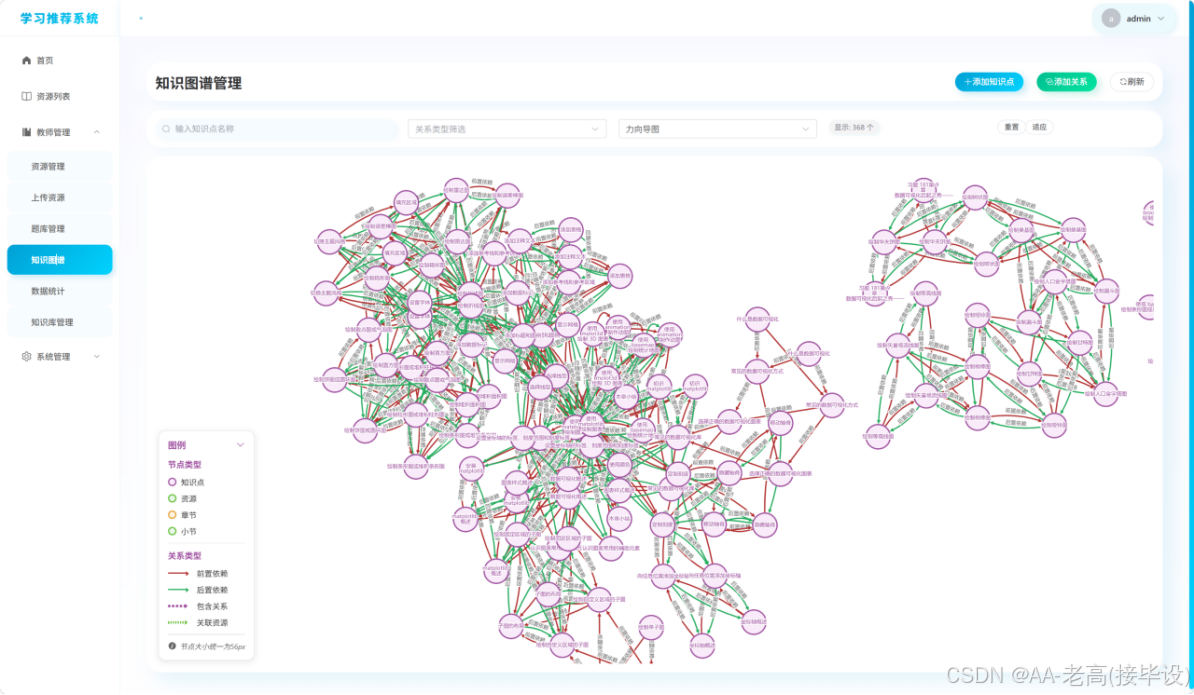
最终形成包含45个知识点节点、80条关系的学习领域知识图谱,数据结构规范、关系清晰,可支撑学习路径规划、关联资源推荐、知识检索等核心功能,知识图谱部分内容如图5.5所示。
-
-
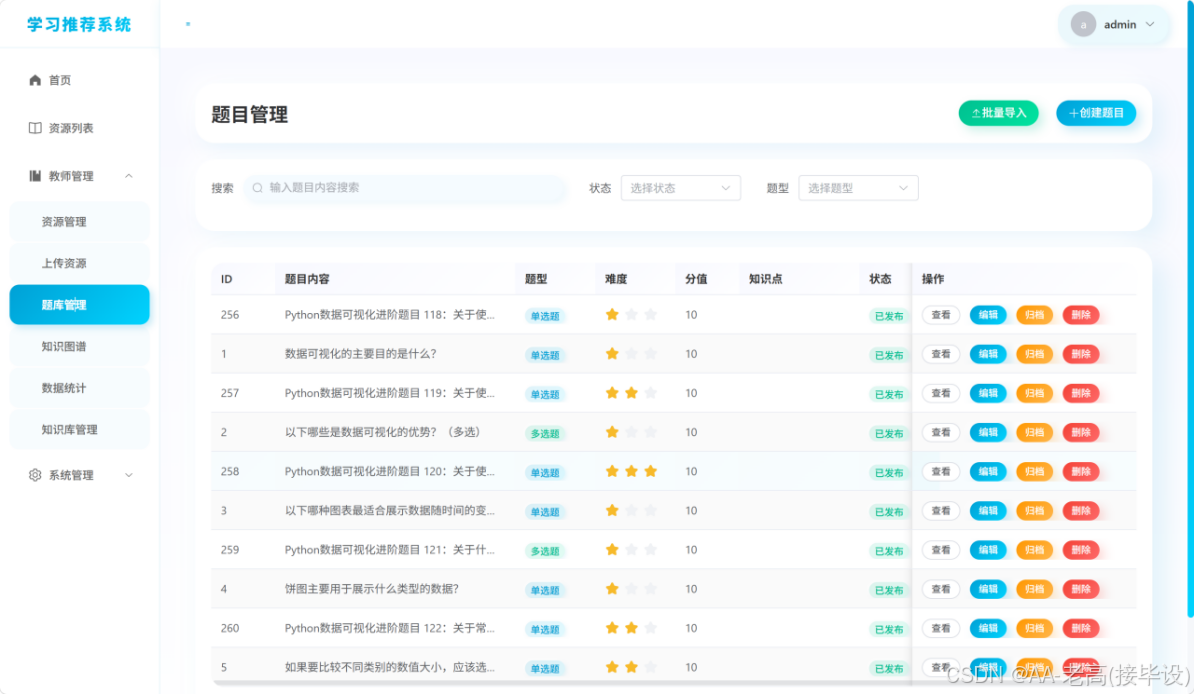
- 学习资源管理功能测试
-
本系统学习资源管理测试结果如表 6.2 所示:
表 6.2 学习资源管理测试结果
|
测试内容 |
测试用例 |
预测结果 |
实际结果 |
结论 |
|
资源上传 |
教师端上传视频 / 文档 / PPT |
资源上传成功并关联对应知识点 |
资源上传完成且知识点关联正常 |
资源上传功能通过测试 |
|
资源浏览 |
学生端筛选浏览学习资源 |
按类型 / 难度展示对应学习资源 |
正确展示符合条件的资源列表 |
资源浏览功能通过测试 |
|
资源检索 |
搜索资源关键词 |
精准匹配并展示相关资源 |
检索结果与关键词高度匹配 |
资源检索功能通过测试 |

图 6.3 学习资源管理测试结果
-
-
- 知识图谱功能测试
-
本系统知识图谱测试结果如表 6.3 所示:
表 6.3 知识图谱测试结果
|
测试内容 |
测试用例 |
预测结果 |
实际结果 |
结论 |
|
图谱构建 |
导入知识点与关系数据 |
成功生成知识点节点与关联关系 |
知识图谱节点、关系创建完整 |
图谱构建功能通过测试 |
|
图谱查看 |
学生端查看知识图谱 |
可视化展示知识点网络与掌握程度 |
图谱正常渲染,颜色标识掌握状态 |
图谱可视化功能通过测试 |
|
图谱管理 |
教师端添加知识点与依赖 |
成功新增知识点并绑定前置关系 |
知识点与依赖关系更新生效 |
图谱管理功能通过测试 |

图 6.4 知识图谱功能测试结果
-
-
- 智能学习路径规划功能测试
-
本系统智能学习路径规划测试结果如表 6.4 所示:
表 6.4 学习路径规划测试结果
|
测试内容 |
测试用例 |
预测结果 |
实际结果 |
结论 |
|
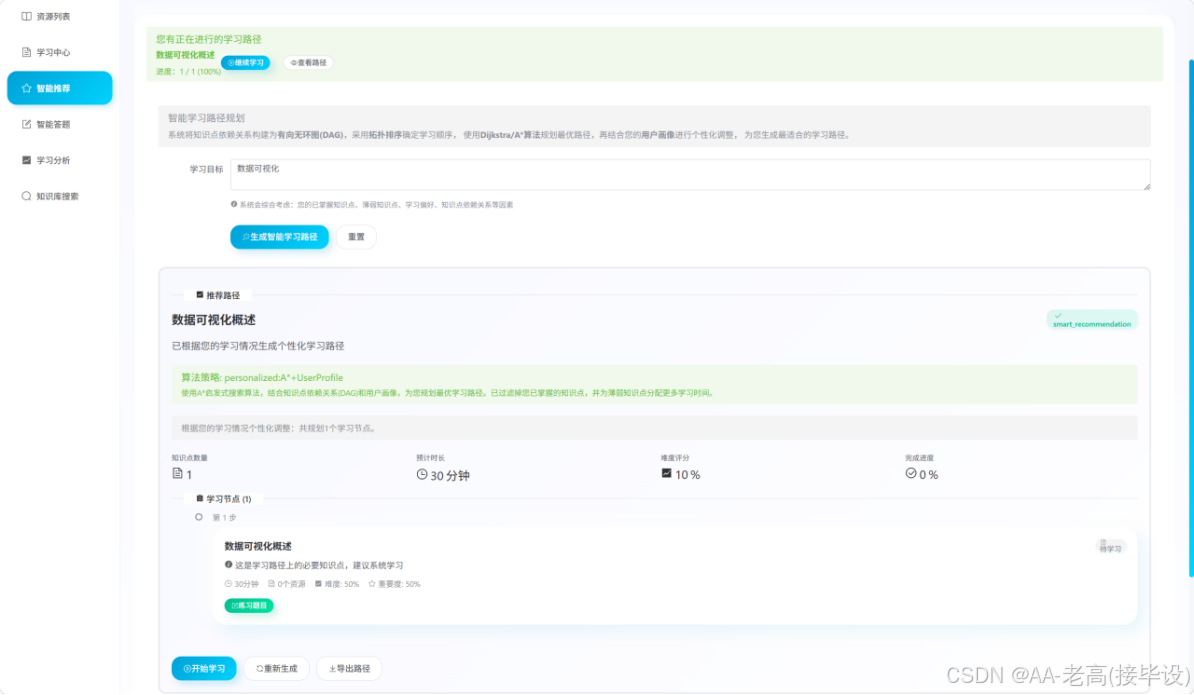
路径生成 |
输入学习目标生成路径 |
基于 DAG + 算法生成个性化路径 |
生成符合知识逻辑的最优学习路径 |
路径生成功能通过测试 |
|
路径适配 |
根据薄弱点调整路径 |
自动优先推荐薄弱知识点学习 |
路径动态适配学习情况更新 |
路径适配功能通过测试 |
|
路径导出 |
点击导出学习路径 |
成功导出学习计划文件 |
学习路径文件导出并可正常查看 |
路径导出功能通过测试 |

图 6.5 智能学习路径规划测试结果
-
-
- 在线测试功能测试
-
本系统在线测试功能测试结果如表 6.5 所示:
表 6.5 在线测试测试结果
|
测试内容 |
测试用例 |
预测结果 |
实际结果 |
结论 |
|
智能组卷 |
选择知识点智能生成试卷 |
按难度与知识点生成对应题目 |
成功生成符合要求的测试试卷 |
智能组卷功能通过测试 |
|
在线答题 |
完成题目并提交答案 |
系统自动批改并统计正确率 |
自动批改完成,成绩统计准确 |
在线答题功能通过测试 |
|
错题收录 |
答错题目自动存入错题本 |
错题自动收录并标注知识点 |
错题正常收录,关联知识点清晰 |
错题本功能通过测试 |
-
-
- 学习分析功能测试
-
本系统学习分析功能测试结果如表 6.6 所示:
表 6.6 学习分析测试结果
|
测试内容 |
测试用例 |
预测结果 |
实际结果 |
结论 |
|
进度统计 |
查看个人学习进度 |
展示学习时长、完成资源数量 |
准确展示学习数据与统计图表 |
进度统计功能通过测试 |
|
薄弱点分析 |
查看知识点掌握情况 |
标识未掌握知识点并给出建议 |
精准识别薄弱知识点并推送练习 |
薄弱点分析功能通过测试 |
|
学情统计 |
教师端查看学生学习数据 |
展示班级整体学习情况统计 |
正常展示学生学习数据与趋势 |
学情统计功能通过测试 |
-
-
- RAG 知识库智能问答功能测试
-
本系统 RAG 智能问答测试结果如表 6.7 所示:
表 6.7 RAG 智能问答测试结果
|
测试内容 |
测试用例 |
预测结果 |
实际结果 |
结论 |
|
知识库检索 |
输入问题搜索本地文档 |
检索匹配相关文档片段 |
精准返回关联文档与参考来源 |
知识库检索功能通过测试 |
|
AI 智能回答 |
发起知识点相关提问 |
Ollama 模型结合 RAG 生成答案 |
生成准确、有据可依的回答内容 |
智能问答功能通过测试 |
|
文档管理 |
教师端上传 PDF 构建知识库 |
文档自动分块并关联知识点 |
文档处理完成,可正常检索 |
知识库管理功能通过测试 |
-
-
- 管理员系统运维功能测试
-
本系统管理员运维功能测试结果如表 6.8 所示:
表 6.8 管理员运维测试结果
|
测试内容 |
测试用例 |
预测结果 |
实际结果 |
结论 |
|
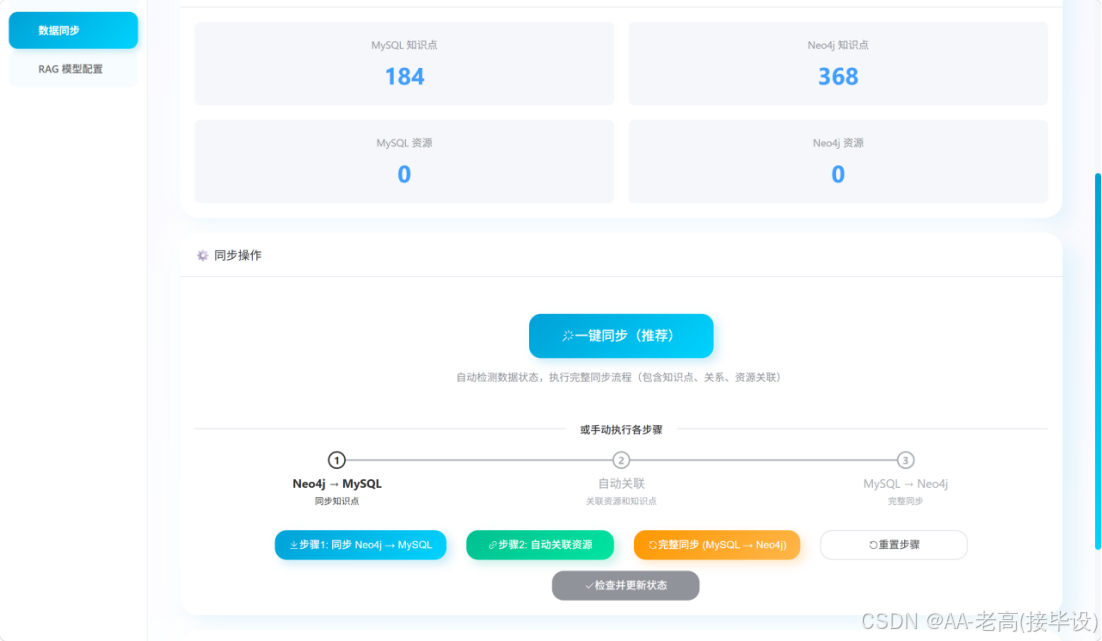
数据同步 |
点击同步 Neo4j 与 MySQL 数据 |
知识点数据双向同步一致 |
数据同步完成,无缺失与错误 |
数据同步功能通过测试 |
|
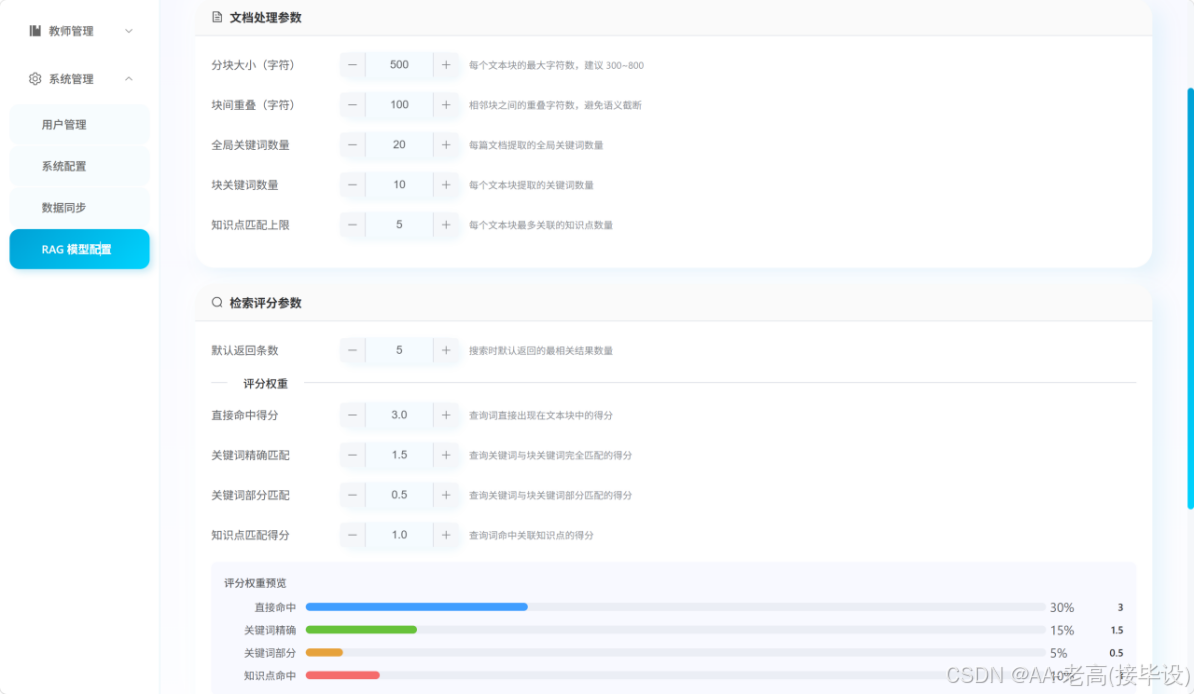
RAG 配置 |
修改知识库分块与模型参数 |
配置保存并实时生效 |
参数修改成功,系统按配置运行 |
RAG 配置功能通过测试 |
|
用户管理 |
管理员禁用 / 编辑用户账号 |
账号状态更新并生效 |
成功修改用户信息与状态 |
用户管理功能通过测试 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)