【2026前端转 AI 全栈指南】第 1 章:前言 · 后端架构 · 章节导览
本章目录
- 1.1 AI 焦虑与学习路径
- 1.2 为什么是面试帮、为什么是这套教程
- 1.3 v1 功能范围与对照
- 1.4 为什么我要做这套教程(免费版)
- 1.5 后端系统技术架构
- 1.6 本教程 v1 的 AI 链路
- 1.7 这门课程和其他 AI 教程有什么不一样
- 1.8 章节导览
- 1.9 源码地址与下一章
1.1 AI 焦虑与学习路径
大家好,我是 面试帮 的作者。
在 AI 快速改变软件开发方式的这几年里,很多开发者心里都会冒同一个问题:
AI 会不会代替大部分程序员?前端、后端是不是「没前途了」?
毕竟现在用大模型写代码,很多时候已经比「刚入门的业务代码」更快、更全。
- 网上一派说:「会!」 —— 于是「前端已死、后端已亡」到处刷屏。
- 另一派说:「不会!」 —— AI 只是工具,替代不了创造力和复杂决策。
两拨人吵来吵去,谁也说服不了谁。
但如果仔细分辨,你会发现:
- 说「会」的很多人,要的是 流量,并不真关心你的职业路径。
- 说「不会」的很多人,要的是 眼前的稳定,未必愿意亲手把 AI 接进项目里试一遍。
所以,靠刷观点是靠不住的。 真正值得自己搞清楚的,是下面这些事:
- AI 到底是什么、能干什么、边界在哪
- AI 在 前端 / 后端 里怎么 稳定落地(不是 Demo 里问一句答一句)
- AI 在 真实商业应用 里长什么样——Prompt、SSE、鉴权、存储、成本
想要驾驭 AI,得先了解 AI。 最好的方式,就是 自己做一个能跑、能讲、能写进简历的全栈项目。
1.2 为什么是面试帮、为什么是这套教程
面试帮上线已经一个月了,真实使用用户已经突破了500+,是一个真正的商业级别的项目。
真实项目效果,请大家打开 mianshibang.cn 体验;这里贴两张 面试帮 核心页面截图:
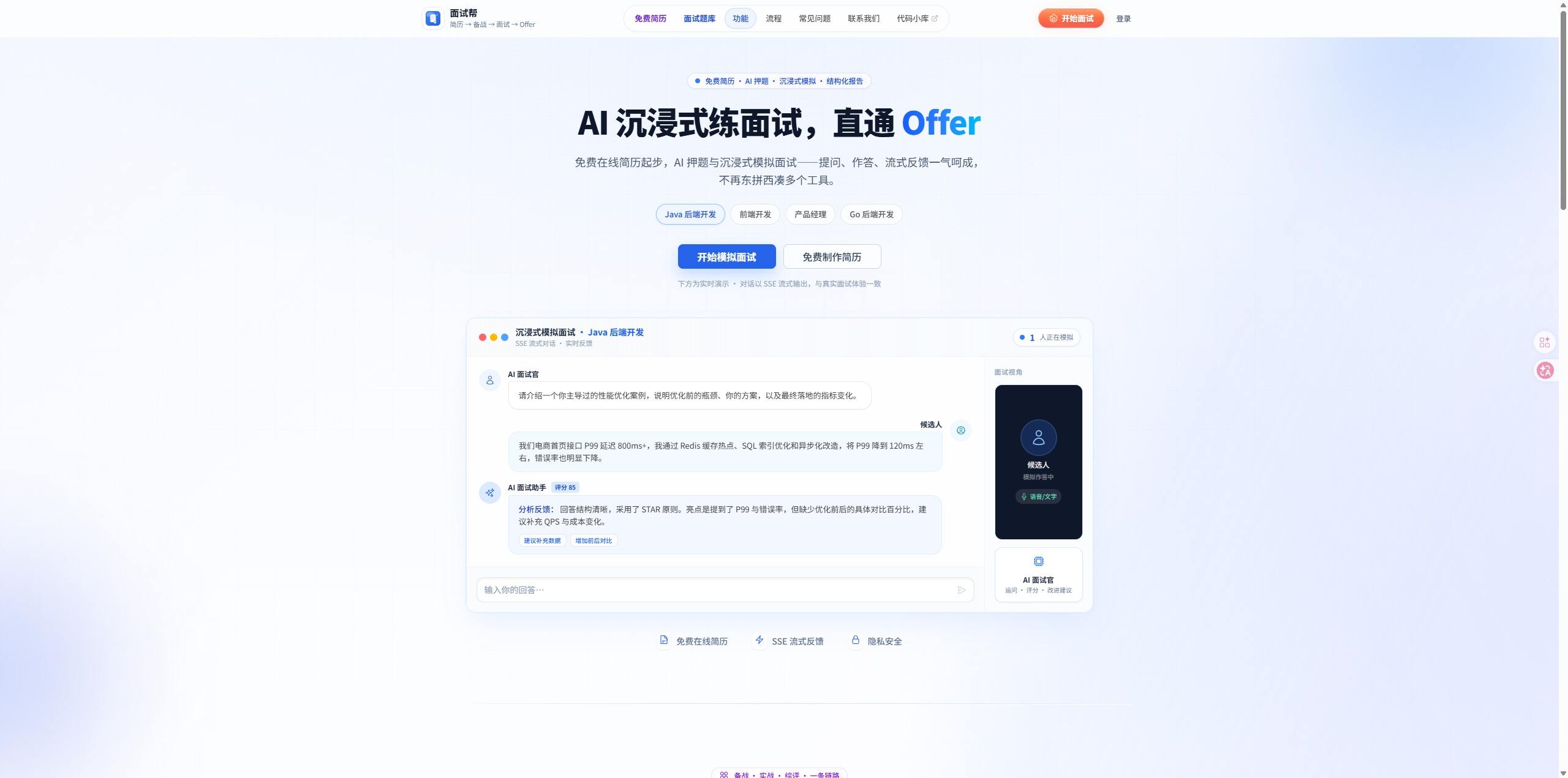
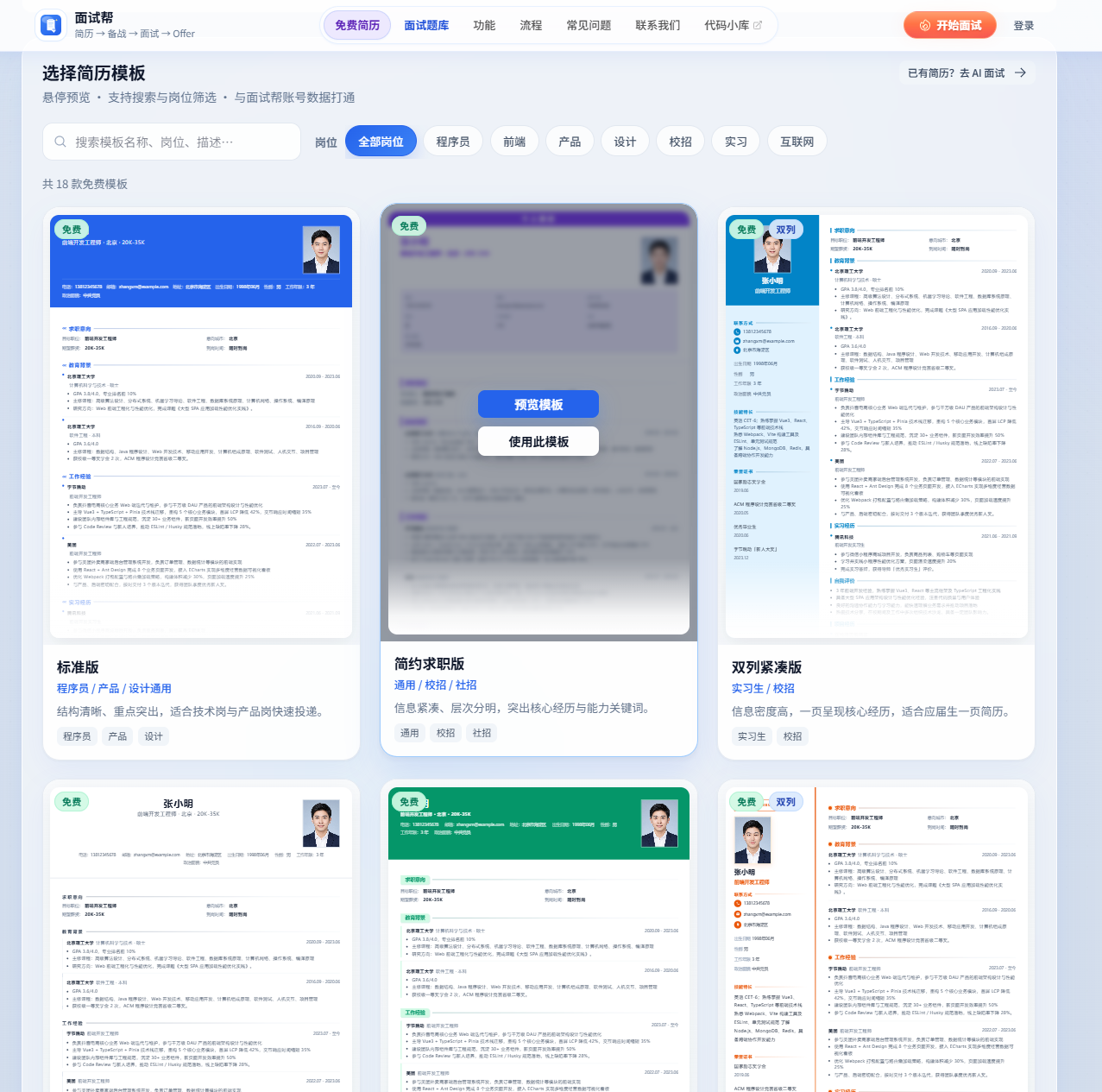
面试帮在线简历效果图
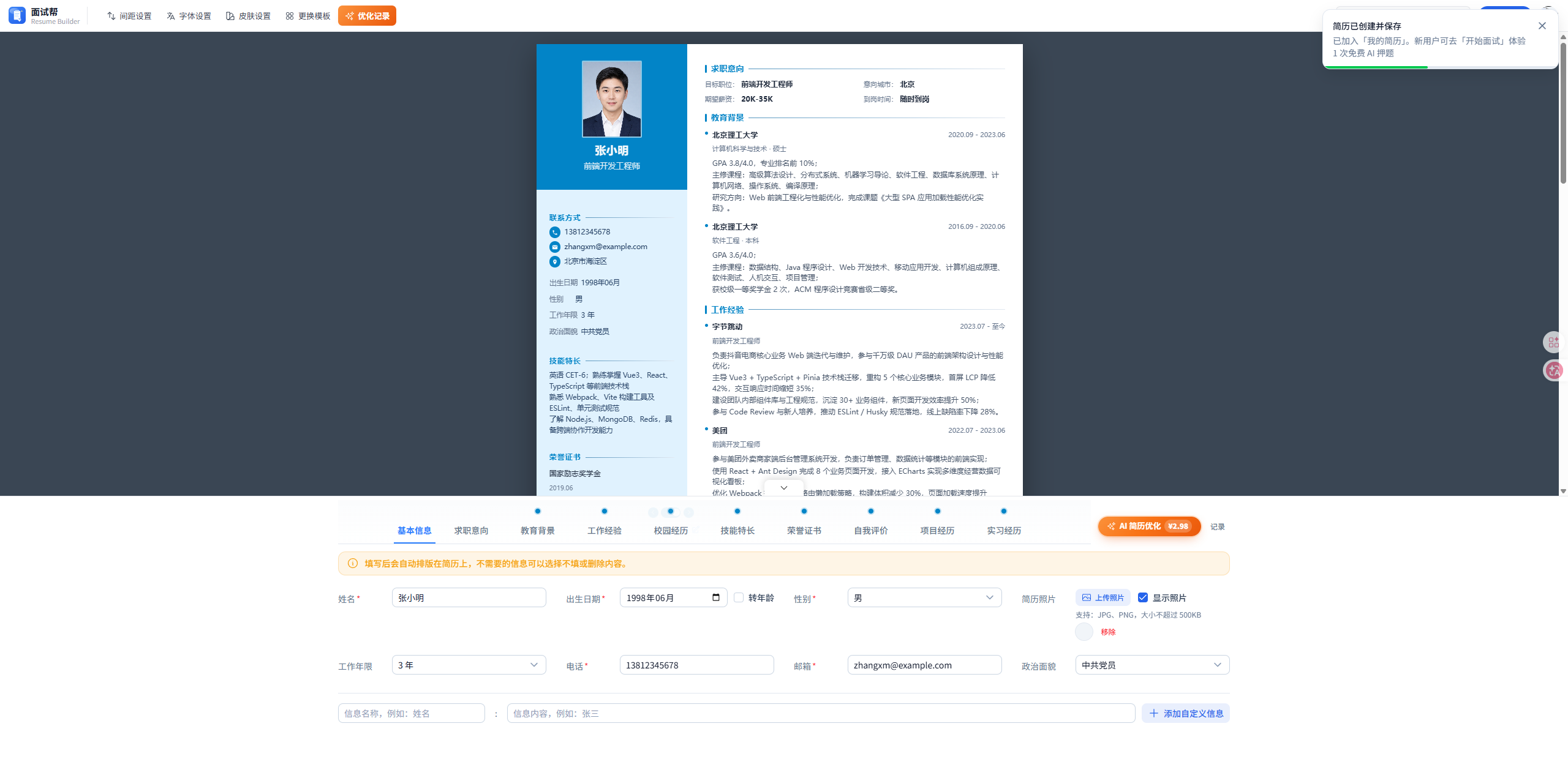
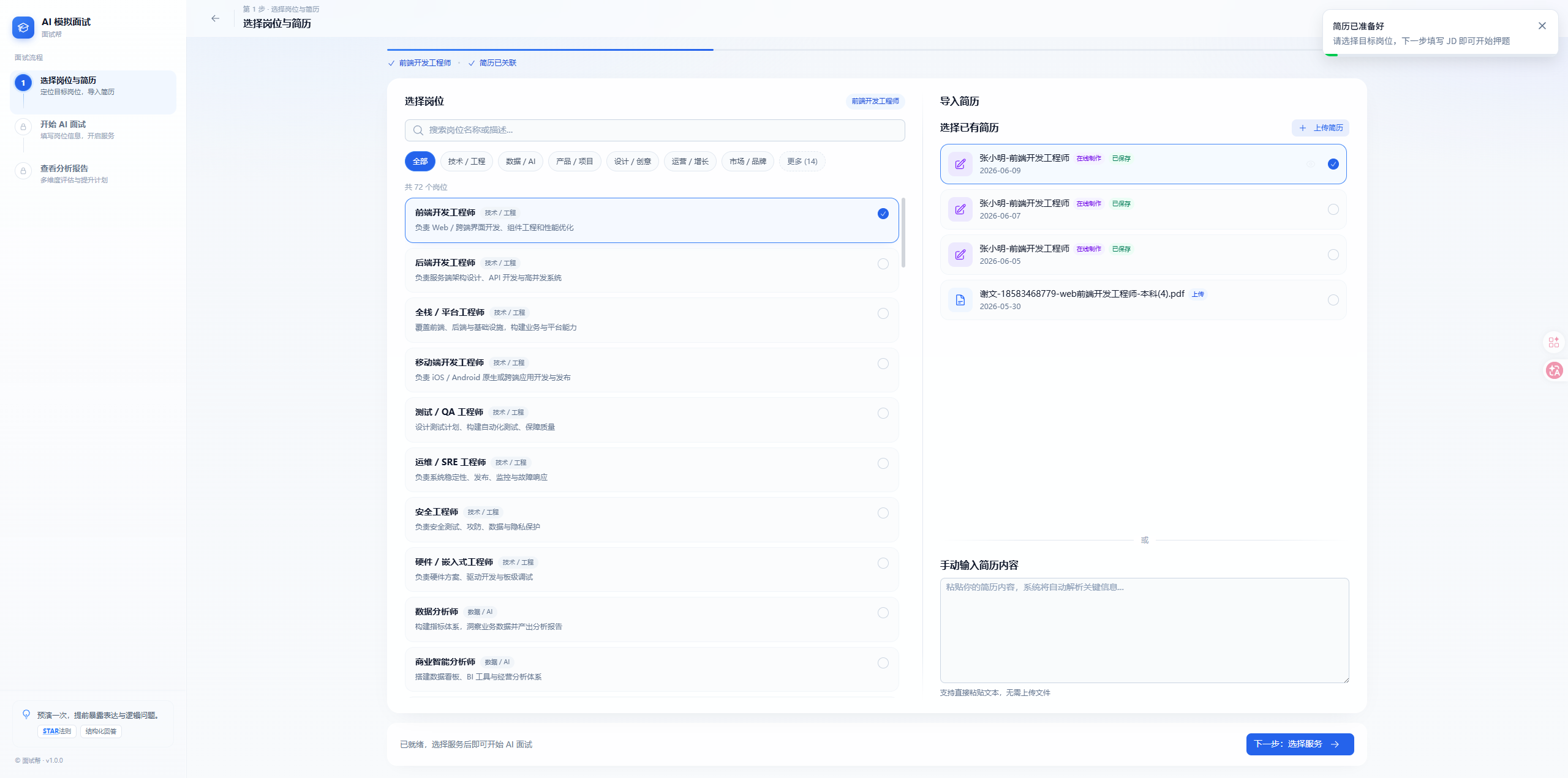
面试帮 AI 押题报告效果图
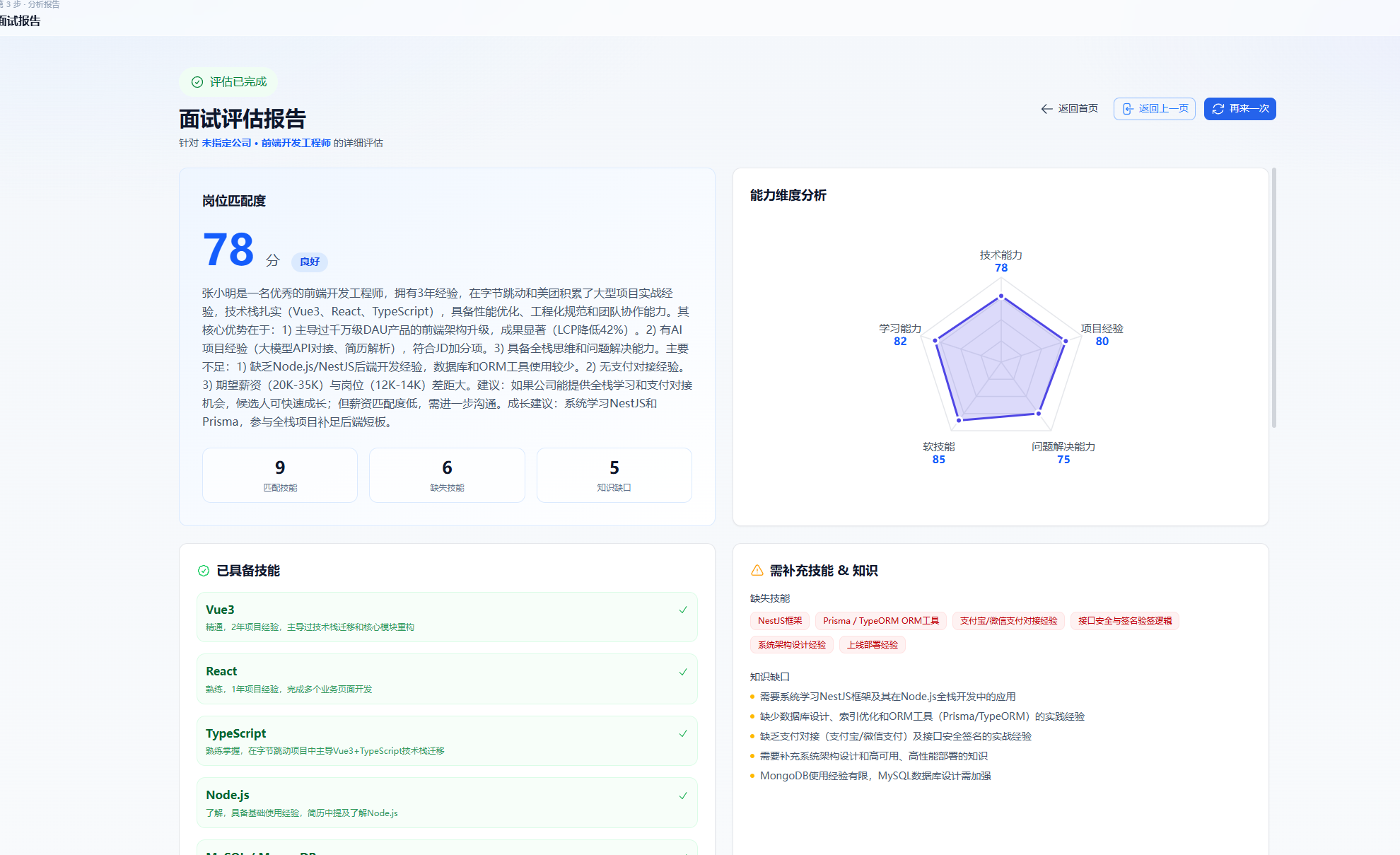
我用业余时间独立做了 面试帮:在线简历 → JD 押题 → 模拟面试 → 报告复盘,已经上线并在持续迭代(Nuxt 4 + NestJS + MongoDB + 大模型 API)。
这不是 PPT 里的假想项目,而是:
- 真实用户注册、做简历、走 AI 链路
- 真实支付、权限、帮币与次数体系(商业版)
- 真实踩过的坑:SSE 中断、Prompt 格式跑偏、PDF 与预览不一致……
今天(2026 年 6 月),我(做了 6 年前端、3 年全栈)把其中 最适合学习、最适合面试讲解 的核心链路,抽成开源教学项目 ai-interview-lab(AI 求职助手) —— 系列名 《前端转 AI 全栈 · 面试专用》。
本系列分 前端 + 后端 两条线:本章重点讲后端视角的整体架构(前端从第 5 章展开)。
1.3 v1 功能范围与对照
v1 要实现的核心链路
账号密码 注册/登录(JWT)
→ 上传 PDF 简历 / 在线编辑
→ PDF 解析 → 结构化简历文本
→ 粘贴岗位 JD
→ LangChain + DeepSeek 生成押题 + 匹配度分析
→ SSE 推送进度 → 评估报告页 + 历史记录
教程 vs 面试帮
| 功能模块 | 本教程 v1 ai-interview-lab |
商业产品 面试帮 |
|---|---|---|
| 定位 | 教学 · 开源 · 按章 tag | 完整商业产品 |
| 登录注册 | ✅ 账号 + 密码,JWT | 微信 OAuth、邮箱等 |
| 简历输入 | ✅ 在线编辑 + PDF 上传解析 | 多模板、云端 PDF、优化 diff |
| AI 栈 | ✅ LangChain + DeepSeek | 多模型工厂、LangChain 链式编排 |
| 简历解析 | ✅ PDF/文本 → 结构化内容 | 完整解析 + OSS 签名预览 |
| JD 押题 | ✅ Prompt + 题目生成 | 同链路 + 次数/帮币体系 |
| 评估报告 | ✅ 匹配度、技能 gap、报告页 | 完整雷达图、多步 Pipeline |
| SSE | ✅ 进度推送(长任务不超时) | 押题进度 SSE;模拟面 token 流 |
| 代码 | 独立仓库 | 生产环境,教程不直接开源 |
后续版本 / 暂不实现(视反响再加)
| 功能 | 计划 |
|---|---|
| 邮箱登录 | 后续附录 |
| 微信登录 | 后续 / 见面试帮 |
| 微信支付 / 支付宝 | 后续 / 见面试帮 |
| 多轮对话模拟面试 | 后续专题 / 见面试帮 |
| 700+ 面试题库 | 仅面试帮 |
| AI 简历优化 diff | 仅面试帮 |
教程 = 面试帮核心 AI 链路的教学实现版(账号 JWT + PDF 解析 + LangChain + 报告),不是阉割 Demo。
微信 / 支付 / 模拟面等 v1 不做,避免教程写不完;完整体验请上 mianshibang.cn。
1.4 为什么我要做这套教程(免费版)
说直白一点:多余的时间,就想做这么一件事,也可以记录和积累项目经验。
如果大家感兴趣,希望 多多关注、点赞、评论,给我一些持续更新的动力。
| 层级 | 内容 | 说明 |
|---|---|---|
| CSDN 专栏 | 第 1~6 章 | 免费发布,跟文档就能搭环境、写简历、做 JWT |
| GitHub | ai-interview-lab |
按章打 tag,源码随教程开源 |
| AI 核心章 | LangChain、押题、报告 | 视专栏反响,可继续免费或整理完整版文档 |
| 商业完整版 | 模拟面、支付、题库 | 上 面试帮 体验 |
1.5 后端系统技术架构
下面是你将要搭建的 真实可部署 的后端形态。教学版做了裁剪,但 分层与模块划分 与商业项目一致,面试能讲清楚:
┌──────────────────────────────────────────────────────────────┐
│ 表现层 · Nuxt 4 (apps/web) │
│ 登录注册 / 简历编辑 / PDF 上传 / JD 输入 / 报告页 / 历史 │
└────────────────────────────┬─────────────────────────────────┘
│ HTTP / SSE
┌────────────────────────────▼─────────────────────────────────┐
│ 应用层 · NestJS (apps/api) │
│ AuthModule(JWT) │ ResumeModule │ PdfModule │ QuizModule │
│ │ AiModule(LangChain + DeepSeek) │
└────────────┬───────────────────────────────┬─────────────────┘
│ │
┌────────────▼────────────┐ ┌────────────▼────────────┐
│ 数据层 · MongoDB │ │ AI · DeepSeek API │
│ users / resumes / │ │ LangChain Prompt+Parser │
│ quiz_records │ │ │
└─────────────────────────┘ └─────────────────────────┘
后端系统技术架构图

设计要点(问题驱动,面试常问):
| 技术选择 | 为什么(对应真实问题) |
|---|---|
| 前后端分离 + Key 放后端 | 前端不能暴露 DeepSeek API Key |
| 账号密码 + JWT | 教学版统一鉴权;与面试帮微信登录解耦 |
| PDF 上传 + 解析 | 用户已有 PDF 简历;解析后供 AI 读 |
| MongoDB 存简历 JSON | 字段灵活;解析结果 + 在线编辑可合并 |
| NestJS 模块化 | Auth / Resume / PDF / Quiz / AI 边界清晰 |
| LangChain | PromptTemplate、JsonOutputParser,与面试帮生产代码同源 |
| SSE 进度推送 | 生成 1~7 分钟,推 progress,完成推 yati-complete(非逐 token 流) |
| 结构化 JSON 输出 | 题目、匹配度、报告字段可落库、可渲染 |
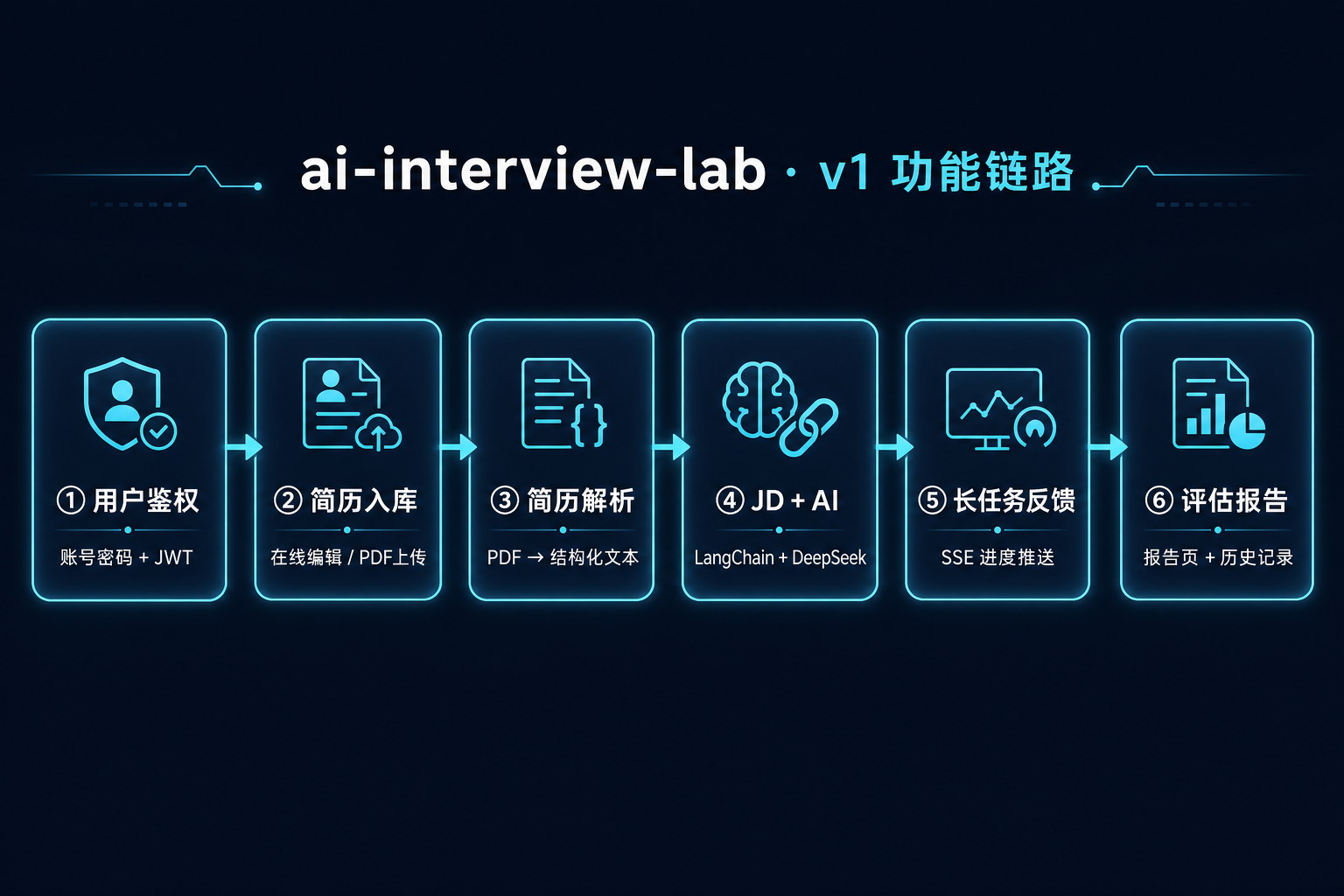
1.6 本教程 v1 的 AI 链路
第一版 不做多轮模拟面,但 报告是完整评估报告(题目 + 匹配度 + 技能 gap 等),与面试帮押题报告同源思路:
| 步骤 | 能力 | 技术点 |
|---|---|---|
| 1 | 用户鉴权 | 账号密码注册登录、JWT Guard |
| 2 | 简历入库 | 在线 JSON 编辑 或 PDF 上传 |
| 3 | 简历解析 | PDF → 文本 → 结构化摘要 |
| 4 | JD + AI | LangChain + DeepSeek:押题 + 匹配度分析 |
| 5 | 长任务反馈 | SSE 进度事件 |
| 6 | 评估报告 | 报告页展示 + 历史记录 |
v1 功能链路图
1.7 这门课程和其他 AI 教程有什么不一样
第一,来自真实产品,不是纯 Demo。
代码思路来自 面试帮 上线实践;教程仓库独立维护,但架构同源。
第二,系统完整,不断层。
NestJS → MongoDB → 账号 JWT → 简历/PDF → LangChain + DeepSeek → SSE 进度 → 评估报告 → Docker 部署。
第三,问题驱动,不是 API 罗列。
- 为什么 PDF 要后端解析?—— 统一文本质量,Prompt 输入可控
- 为什么用 LangChain?—— Prompt 模板、JSON 解析、与生产项目一致
- 为什么用 SSE?—— 生成耗时长,推进度防超时(押题是进度 SSE,不是逐 token)
- 为什么 JSON 约束输出?—— 报告字段要能落库、前端要能渲染
第四,前端转全栈友好。
默认你会 Vue;NestJS作为后端语言,支持纯ts,作为前端开发人员转后端的最优解,我们在正式项目开始前,会对nestjs做一个整体的教学,小白不用担心无法上手,老手可以跳过这一节。
第五,范围清晰。
v1 聚焦 一条 AI 评估链路;微信 / 支付 / 模拟面后置,教程能写完、你能学完。
1.8 章节导览
以下为本系列 完整章节(CSDN 按章发布):
| 章 | 标题 | 文档 |
|---|---|---|
| 1 | 前言与章节导览 | 本文 |
| 2 | 开发环境准备 | 开发环境准备 |
| 3 | NestJS 框架基础 | NestJS简易教学 |
| 4 | MongoDB 与简历领域模型 | 简历领域模型与MongoDB设计 |
| 5 | 项目架构与 Nuxt 4 简历前端 | Nuxt简历编辑与模板渲染 |
| 6 | JWT 认证(账号密码) | 用户模块与JWT鉴权 |
| — | 简历 CRUD 全链路联调 | 简历CRUD接口与联调(穿插第 5~6 章后) |
| 7 | PDF 上传与简历解析 | PDF上传与解析 |
| 8 | LangChain + DeepSeek | AI服务封装与大模型对接 |
| 9 | JD 押题 + SSE 进度 | JD押题Prompt与SSE流式 |
| 10 | 评估报告与历史 | 报告页与历史记录 |
| 11 | 部署与上线 | 部署与上线 |
章节导览思维导图
建议学习顺序:
第 1 章(本文)
→ 第 2 章(开发环境 + 项目骨架)
→ NestJS 简易教学
→ 第 4~6 章
→ 第 7~9 章(AI 核心)
→ 第 10~11 章
1.9 源码地址与下一章
源码地址
GitHub 仓库 ai-interview-lab 随教程按章发布,暂时未公开,首发第 2 章后开放。
前端工程目录预览(第 5 章实现)
第 5 章会在 apps/web(Nuxt 4)里做简历编辑器;此处先建立目录预期:
apps/web/
├── nuxt.config.ts
├── app/
│ ├── app.vue
│ ├── pages/
│ │ ├── index.vue # 首页
│ │ ├── login.vue # 登录注册(第 6 章)
│ │ └── resume/
│ │ ├── index.vue # 简历列表
│ │ └── edit.vue # 编辑 + 预览(第 5 章)
│ └── components/
│ └── resume/
│ ├── forms/
│ └── templates/
├── composables/
│ └── useResumeApi.ts
└── middleware/
└── auth.ts
下一章预告
第 2 章 · 开发环境准备(2.1~2.5)将完整讲解:
- Node.js、pnpm、TypeScript、VS Code、Git
- NestJS 项目创建、MongoDB 安装
- Nuxt 4 联调与
pnpm dev双端启动
第 1 章不要求你现在就装齐环境;读完前言,直接跟第 2 章即可。
完整商业产品体验:面试帮 mianshibang.cn

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)